
- 1键盘延迟测试_职业选手量身定制可更换轴体,罗技G PRO X 游戏键盘评测
- 2个性化的Github主页,让你脱颖而出。_github个人主页有什么用
- 3海思嵌入式开发-001-简介+参考资源_小海思嵌入式开发社区
- 4高级项目管理师/高项考试十大管理论文模板_软考高项基于一个主题的十大管理论文
- 5前端常见的五大安全威胁附解决方案_csp前端安全问题
- 6超详细SpringBoot+Vue项目部署(两个Vue项目)
- 7怎么查看python版本?有几种方法?
- 8Java数组详解_from myarray import myarray x=myarray(1,2,3,4,5,6)
- 9【人工智能】— 有信息搜索、最佳优先搜索、贪心搜索、A*搜索_无信息搜索策略和有信息搜索策略
- 10大四毕业前如何快速拿到一份高薪IT技术offer?_大四 计算机提前公司offer
何恺明编年史之深度残差网络ResNet_何凯明resnet
赞
踩
前言
图像分类是计算机视觉任务的基石,在目标监测、图像分割等任务中需要使用骨干网咯,将浅层的视觉特征映射到深层的语义特征,以发现高层数据的分布式特征表示。在ILSVRC2015分类任务竞赛中,由何恺明提出的深度残差网络ResNet首次超越人类水平,斩获竞赛第一名的同时并拿到2016年CVPR最佳论文。
一、提出ResNet原因
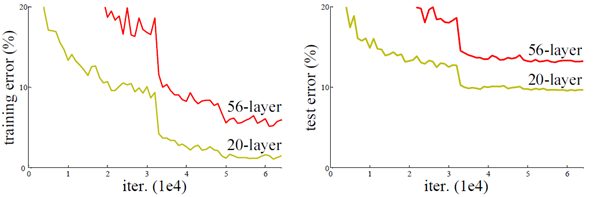
网络是不是越深越好?直到把计算机的性能榨干为止。而在实验中可以发现,随着网络加深,训练集的错误率反而更高,这种现象被称作为“网络退化”。从下图中可以看出,无论是训练集还是验证集,56层的网络比20层的网络都更差,这是因为在运用链式法则反向传播时,梯度或消失、或爆炸。
二、深度残差模块
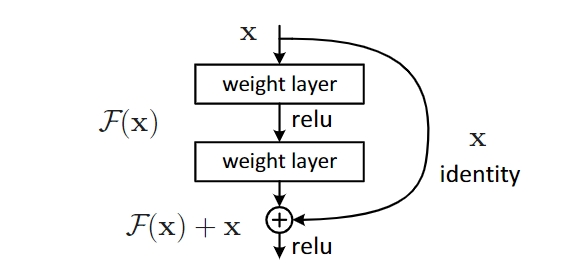
1.数学理论基础
复杂问题简单解决,公式
F
(
x
)
+
x
F(x)+x
F(x)+x在不添加可学习参数的前提下提升了网络性能。极端情况下,权重层(weight layer)已经收敛不再更新任何参数,“网络退化”说明
F
(
x
)
F(x)
F(x)通道向着变坏的方向迭代,而添加的恒等映射(Identity)仅复制上一层的输出特征,一定程度上阻碍了更坏的情况发生。有点类似物理学中的楞次定律,若权重层的网络是不断进化的,恒等映射则同样阻碍更好的情况发生。
y
l
=
h
(
x
l
)
+
F
(
x
l
,
W
l
)
x
l
+
1
=
f
(
y
l
)
2.深度网络结构
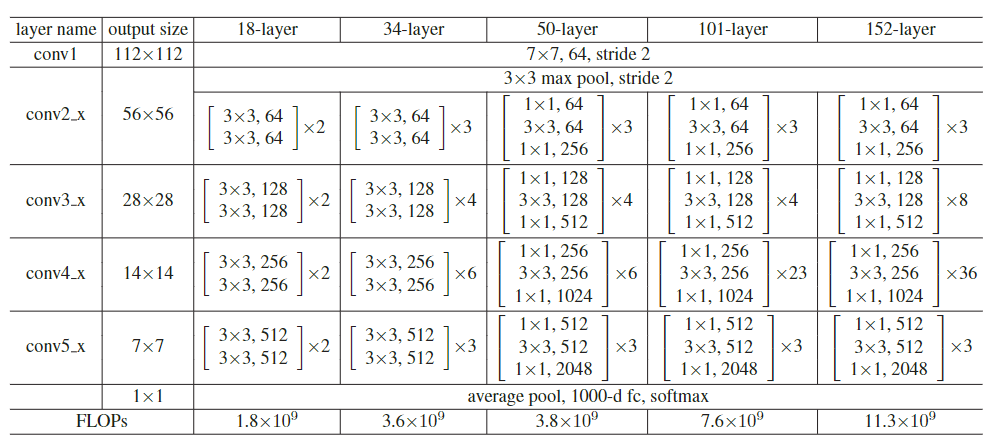
只要保证
F
(
x
)
F(x)
F(x)和
x
x
x相加时的张量维度保持一致,就可以构造出残差模块block,以卷积神经网络为例,[kernel, stride, padding]=[1×1,1,0]和[3×3,1,1]均不会改变张量维度,可以根据图像尺寸大小适当调整卷积核算子,何恺明在论文中给出了几种经典的构造方式,如:resnet50和resnet101。
三、Pytorch代码实现
论文代码复现tips:Block模块应保证输入和输出的张量维度一致,即C=256、512、1024、2048,卷积核的运算亦不会改变特征图的尺寸。flatten展开前使用AdaptiveAvgPool2d将特征图尺寸降为[1, 4096, 1, 1],接fc层就不用考虑维度变换问题。以下代码为resnet50:
import torch import torch.nn as nn class Block(nn.Module): def __init__(self, in_channels, out_channels): super(Block, self).__init__() self.conv1 = nn.Conv2d(out_channels, in_channels, 1, 1, 0) self.bn1 = nn.BatchNorm2d(in_channels) self.conv2 = nn.Conv2d(in_channels, in_channels, 3, 1, 1) self.bn2 = nn.BatchNorm2d(in_channels) self.conv3 = nn.Conv2d(in_channels, out_channels, 1, 1, 0) self.bn3 = nn.BatchNorm2d(out_channels) self.relu = nn.ReLU() def forward(self, input): x = input f_x = self.bn1(self.conv1(x)) f_x = self.bn2(self.conv2(f_x)) f_x = self.bn3(self.conv3(f_x)) out = self.relu(x + f_x) #精华 return out class Resnet(nn.Module): def __init__(self, n_classes=1000, input_channels=3): super(Resnet, self).__init__() self.conv0 = nn.Conv2d(input_channels, 64, kernel_size=7, stride=2, padding=3) self.bn0 = nn.BatchNorm2d(64) self.relu0 = nn.ReLU() self.conv1 = nn.Conv2d(64, 256, 1, 1, 0) self.bn1 = nn.BatchNorm2d(256) self.relu1 = nn.ReLU() self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) self.layer1 = self._make_layer(64, 256, 3) self.layer2 = self._make_layer(128, 512, 4) self.layer3 = self._make_layer(256, 1024, 6) self.layer4 = self._make_layer(512, 2048, 3) self.avgpool = nn.AdaptiveAvgPool2d(output_size=1) self.flatten = nn.Flatten(start_dim=1, end_dim=-1) self.fc = nn.Linear(4096, n_classes) def _make_layer(self, in_channels, out_channels, num): layers = [] for _ in range(0, num): layers.append(Block(in_channels, out_channels)) layers.append(nn.Sequential( nn.Conv2d(out_channels, out_channels*2, 1, 1, 0), nn.BatchNorm2d(out_channels*2), nn.MaxPool2d(2, 2, 0))) return nn.Sequential(*layers) def forward(self, input): x = self.relu0(self.bn0(self.conv0(input))) x = self.relu1(self.bn1(self.conv1(x))) x = self.maxpool(x) x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) x = self.avgpool(x) x = self.flatten(x) x = self.fc(x) return x def main(): ins = torch.randn(1, 3, 224, 224) model = Resnet() out = model(ins) print('out shape:', out.shape) if __name__ == '__main__': main() """ out shape: torch.Size([1, 1000]) """

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
四、总结
开源框架(Pytorch、PaddlePaddle)都具有Resnet模型的库函数,开发者可以直接调用函数名来训练模型,对于不同场景的任务需求甚至都有预训练好的参数文件。作者在复现代码的过程中,并非一成不变地搬运code,只是保证在每个阶段的输出维度保持一致,对于图像分类任务的精度表现,有待进一步实践验证,越来越想揭开MobileNet和ShffuleNet的面纱。

