
深度学习 图像分类
前言 (Foreword)
Computer vision is a subject to convert images and videos into machine-understandable signals. With these signals, programmers can further control the behavior of the machine based on this high-level understanding. Among many computer vision tasks, image classification is one of the most fundamental ones. It not only can be used in lots of real products like Google Photo’s tagging and AI content moderation but also opens a door for lots of more advanced vision tasks, such as object detection and video understanding. Due to the rapid changes in this field since the breakthrough of Deep Learning, beginners often find it too overwhelming to learn. Unlike typical software engineering subjects, there are not many great books about image classification using DCNN, and the best way to understand this field is though reading academic papers. But what papers to read? Where do I start? In this article, I’m going to introduce 10 best papers for beginners to read. With these papers, we can see how this field evolve, and how researchers brought up new ideas based on previous research outcome. Nevertheless, it is still helpful for you to sort out the big picture even if you have already worked in this area for a while. So, let’s get started.
计算机视觉是将图像和视频转换成机器可理解的信号的主题。 利用这些信号,程序员可以基于这种高级理解来进一步控制机器的行为。 在许多计算机视觉任务中,图像分类是最基本的任务之一。 它不仅可以用于许多实际产品中,例如Google Photo的标记和AI内容审核,而且还为许多更高级的视觉任务(例如目标检测和视频理解)打开了一扇门。 自从深度学习的突破以来,由于该领域的快速变化,初学者经常发现它太笨拙,无法学习。 与典型的软件工程学科不同,没有很多关于使用DCNN进行图像分类的书籍,而了解该领域的最佳方法是阅读学术论文。 但是要读什么论文? 我从哪说起呢? 在本文中,我将为初学者介绍10篇最佳论文。 通过这些论文,我们可以看到该领域是如何发展的,以及研究人员如何根据以前的研究成果提出新的想法。 但是,即使您已经在此领域工作了一段时间,对您进行总体整理还是很有帮助的。 因此,让我们开始吧。
1998年:LeNet (1998: LeNet)
Gradient-based Learning Applied to Document Recognition
基于梯度的学习在文档识别中的应用
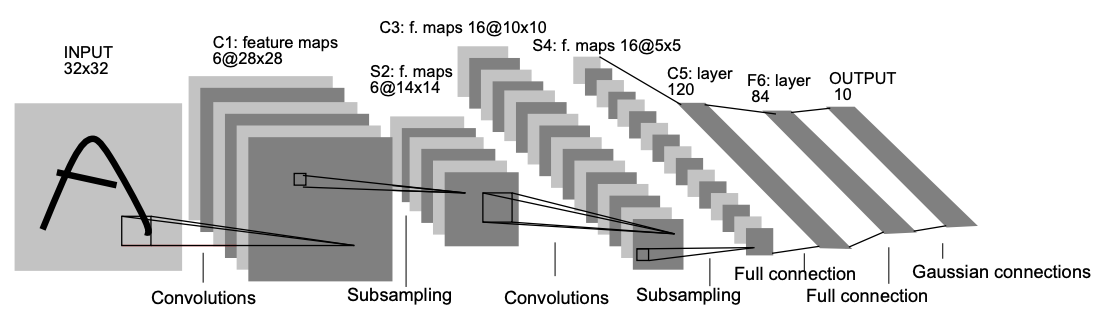
Introduced in 1998, LeNet sets a foundation for future image classification research using the Convolution Neural Network. Many classical CNN techniques, such as pooling layers, fully connected layers, padding, and activation layers are used to extract features and make a classification. With a Mean Square Error loss function and 20 epochs of training, this network can achieve 99.05% accuracy on the MNIST test set. Even after 20 years, many state-of-the-art classification networks still follows this pattern in general.
LeNet于1998年推出,为使用卷积神经网络的未来图像分类研究奠定了基础。 许多经典的CNN技术(例如池化层,完全连接的层,填充和激活层)用于提取特征并进行分类。 借助均方误差损失功能和20个训练周期,该网络在MNIST测试集上可以达到99.05%的精度。 即使经过20年,仍然有许多最先进的分类网络总体上遵循这种模式。
2012年:AlexNet (2012: AlexNet)
ImageNet Classification with Deep Convolutional Neural Networks
深度卷积神经网络的ImageNet分类
Although LeNet achieved a great result and showed the potential of CNN, the development in this area stagnated for a decade due to limited computing power and the amount of the data. It looked like CNN can only solve some easy tasks such as digit recognition, but for more complex features like faces and objects, a HarrCascade or SIFT feature extractor with an SVM classifier was a more preferred approach.
尽管LeNet取得了不错的成绩并展示了CNN的潜力,但是由于计算能力和数据量有限,该领域的发展停滞了十年。 看起来CNN只能解决一些简单的任务,例如数字识别,但是对于更复杂的特征(如人脸和物体),带有SVM分类器的HarrCascade或SIFT特征提取器是更可取的方法。
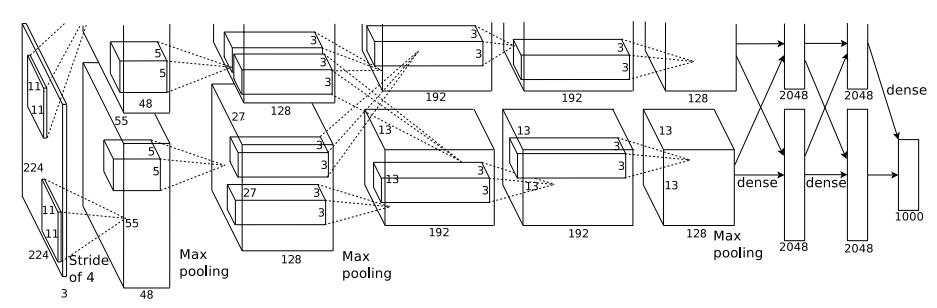
However, in 2012 ImageNet Large Scale Visual Recognition Challenge, Alex Krizhevsky proposed a CNN-based solution for this challenge and drastically increased ImageNet test set top-5 accuracy from 73.8% to 84.7%. Their approach inherits the multi-layer CNN idea from LeNet, but increased the size of CNN a lot. As you can see from the diagram above, the input is now 224x224 compared with LeNet’s 32x32, also many Convolution kernels have 192 channels compared with LeNet’s 6. Although the design isn’t changed much, with hundreds of more times of parameters, the network’s ability to capture and represent complex features improved hundreds of times too. To train such as a big model, Alex used two GTX 580 GPU with 3GB RAM for each, which pioneered a trend of GPU training. Also, the use of ReLU non-linearity also helped to reduce computation cost.
但是,在2012年ImageNet大规模视觉识别挑战赛中,Alex Krizhevsky提出了基于CNN的解决方案来应对这一挑战,并将ImageNet测试仪的top-5准确性从73.8%大大提高到84.7%。 他们的方法继承了LeNet的多层CNN想法,但大大增加了CNN的大小。 从上图可以看到,与LeNet的32x32相比,现在的输入为224x224,与LeNet的6相比,许多卷积内核具有192个通道。尽管设计没有太大变化,但参数却有数百次,网络捕获和表示复杂特征的能力也提高了数百倍。 为了进行大型模型训练,Alex使用了两个具有3GB RAM的GTX 580 GPU,这开创了GPU训练的先河。 同样,使用ReLU非线性也有助于降低计算成本。
In addition to bringing many more parameters for the network, it also explored the overfitting issue brought by a larger network by using a Dropout layer. Its Local Response Normalization method didn’t get too much popularity afterward but inspired other important normalization techniques such as BatchNorm to combat with gradient saturation issue. To sum up, AlexNet defined the de facto classification network framework for the next 10 years: a combination of Convolution, ReLu non-linear activation, MaxPooling, and Dense layer.
除了为网络带来更多参数外,它还通过使用Dropout层探讨了较大的网络带来的过拟合问题。 其局部响应归一化方法此后并没有获得太大的普及,但启发了其他重要的归一化技术(例如BatchNorm)来解决梯度饱和问题。 综上所述,AlexNet定义了未来十年的实际分类网络框架:卷积,ReLu非线性激活,MaxPooling和Dense层的组合。
2014年:VGG (2014: VGG)
Very Deep Convolutional Networks for Large-Scale Image Recognition
用于大型图像识别的超深度卷积网络
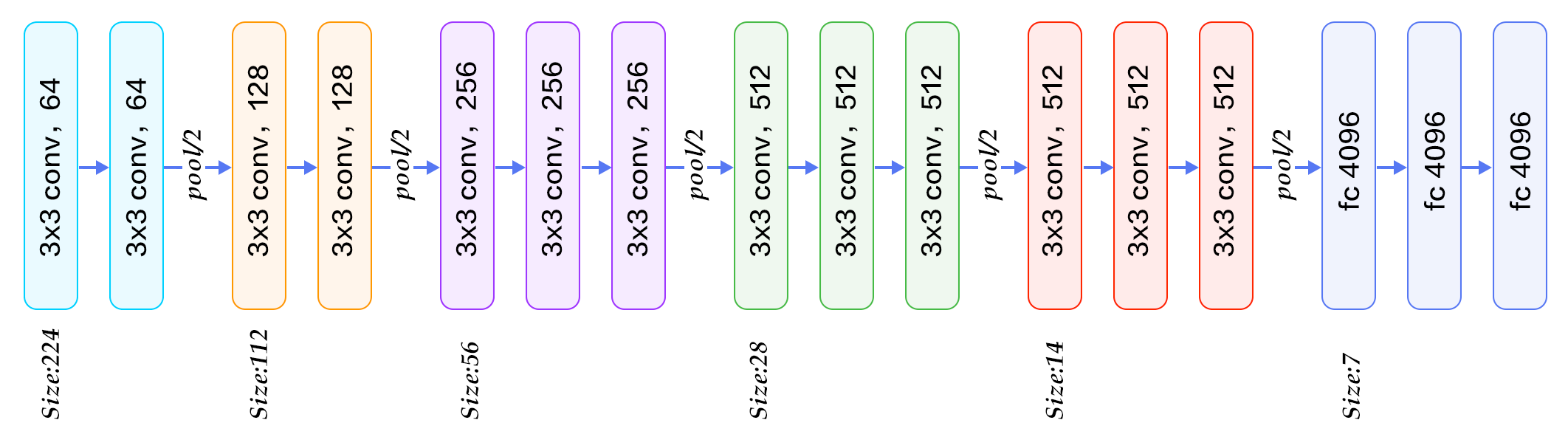
With such a great success of using CNN for visual recognition, the entire research community blew up and all started to look into why this neural network works so well. For example, in “Visualizing and Understanding Convolutional Networks” from 2013, Matthew Zeiler discussed how CNN pick up features and visualized the intermediate representations. And suddenly everyone started to realize that CNN is the future of computer vision since 2014. Among all those immediate followers, the VGG network from Visual Geometry Group is the most eye-catching one. It got a remarkable result of 93.2% top-5 accuracy, and 76.3% top-1 accuracy on the ImageNet test set.
在使用CNN进行视觉识别方面取得了巨大成功,整个研究界都大吃一惊,所有人都开始研究为什么这种神经网络能够如此出色地工作。 例如,在2013年出版的“可视化和理解卷积网络”中,马修·齐勒(Matthew Zeiler)讨论了CNN如何获取特征并可视化中间表示。 突然之间,每个人都开始意识到CNN自2014年以来就是计算机视觉的未来。在所有直接关注者中,Visual Geometry Group的VGG网络是最吸引眼球的网络。 在ImageNet测试仪上,top-5的准确度达到93.2%,top-1的准确度达到了76.3%。
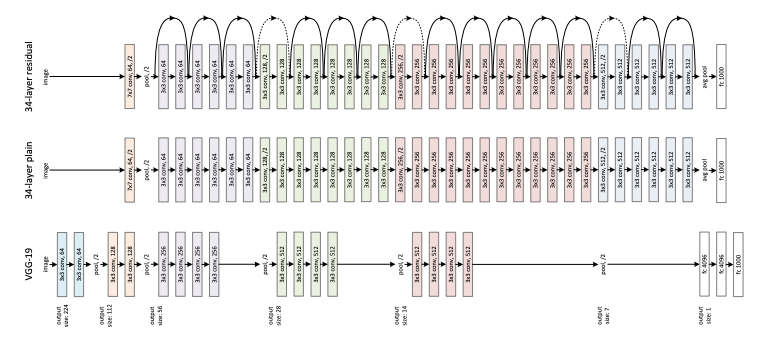
Following AlexNet’s design, the VGG network has two major updates: 1) VGG not only used a wider network like AlexNet but also deeper. VGG-19 has 19 convolution layers, compared with 5 from AlexNet. 2) VGG also demonstrated that a few small 3x3 convolution filters can replace a single 7x7 or even 11x11 filters from AlexNet, achieve better performance while reducing the computation cost. Because of this elegant design, VGG also became the back-bone network of many pioneering networks in other computer vision tasks, such as FCN for semantic segmentation, and Faster R-CNN for object detection.
遵循AlexNet的设计,VGG网络有两个主要更新:1)VGG不仅使用了像AlexNet这样的更广泛的网络,而且使用了更深的网络。 VGG-19具有19个卷积层,而AlexNet中只有5个。 2)VGG还展示了一些小的3x3卷积滤波器可以代替AlexNet的单个7x7甚至11x11滤波器,在降低计算成本的同时实现更好的性能。 由于这种优雅的设计,VGG也成为了其他计算机视觉任务中许多开拓性网络的骨干网络,例如用于语义分割的FCN和用于对象检测的Faster R-CNN。
With a deeper network, gradient vanishing from multi-layers back-propagation becomes a bigger problem. To deal with it, VGG also discussed the importance of pre-training and weight initialization. This problem limits researchers to keep adding more layers, otherwise, the network will be really hard to converge. But we will see a better solution for this after two years.
随着网络的深入,从多层反向传播中消失的梯度成为一个更大的问题。 为了解决这个问题,VGG还讨论了预训练和体重初始化的重要性。 这个问题限制了研究人员继续添加更多的层,否则,网络将很难融合。 但是两年后,我们将为此找到更好的解决方案。
2014年:GoogLeNet (2014: GoogLeNet)
Going Deeper with Convolutions
卷积更深
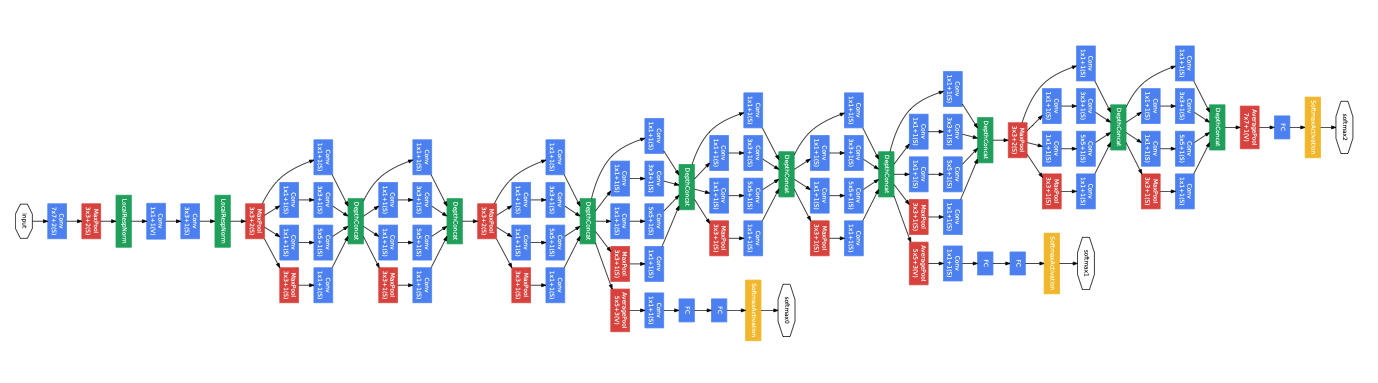
VGG has a good looking and easy-to-understand structure, but its performance isn’t the best among all the finalists in ImageNet 2014 competitions. GoogLeNet, aka InceptionV1, won the final prize. Just like VGG, one of the main contributions of GoogLeNet is to push the limit of the network depth with a 22 layers structure. This demonstrated again that going deeper and wider is indeed the right direction to improve accuracy.
VGG具有漂亮的外观和易于理解的结构,但在ImageNet 2014竞赛的所有决赛入围者中,其性能都不是最好的。 GoogLeNet(又名InceptionV1)获得了最终奖。 就像VGG一样,GoogLeNet的主要贡献之一就是采用22层结构来突破网络深度的限制。 这再次证明,进一步深入确实是提高准确性的正确方向。
Unlike VGG, GoogLeNet tried to address the computation and gradient diminishing issues head-on, instead of proposing a workaround with better pre-trained schema and weights initialization.
与VGG不同,GoogLeNet试图直接解决计算和梯度递减问题,而不是提出具有更好的预训练模式和权重初始化的解决方法。
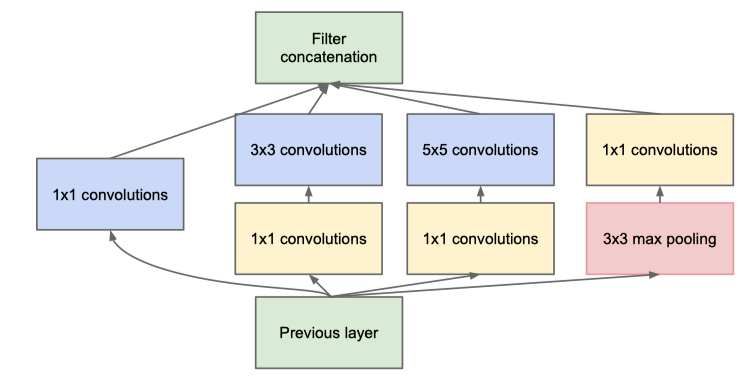
First, it explored the idea of asymmetric network design by using a module called Inception (see diagram above). Ideally, they would like to pursuit sparse convolution or dense layers to improve feature efficiency, but modern hardware design wasn’t tailored to this case. So they believed that a sparsity at the network topology level could also help the fusion of features while leveraging existing hardware capabilities.
首先,它使用称为Inception的模块探索了非对称网络设计的思想(请参见上图)。 理想情况下,他们希望采用稀疏卷积或密集层来提高特征效率,但是现代硬件设计并非针对这种情况而定制。 因此,他们认为网络拓扑级别的稀疏性还可以在利用现有硬件功能的同时,帮助融合功能。
Second, it attacks the high computation cost problem by borrowing an idea from a paper called “Network in Network”. Basically, a 1x1 convolution filter is introduced to reduce dimensions of features before going through heavy computing operation like a 5x5 convolution kernel. This structure is called “Bottleneck” later and widely used in many following networks. Similar to “Network in Network”, it also used an average pooling layer to replace the final fully connected layer to further reduce cost.
其次,它通过借鉴论文“网络中的网络”来解决高计算成本的问题。 基本上,引入1x1卷积滤波器以在进行繁重的计算操作(如5x5卷积内核)之前减小特征的尺寸。 以后将该结构称为“ Bottleneck”,并在许多后续网络中广泛使用。 类似于“网络中的网络”,它还使用平均池层代替最终的完全连接层,以进一步降低成本。
Third, to help gradients to flow to deeper layers, GoogLeNet also used supervision on some intermediate layer outputs or auxiliary output. This design isn’t quite popular later in the image classification network because of the complexity, but getting more popular in other areas of computer vision such as Hourglass network in pose estimation.
第三,为了帮助梯度流向更深的层次,GoogLeNet还对某些中间层输出或辅助输出使用了监督。 由于其复杂性,该设计后来在图像分类网络中并不十分流行,但是在计算机视觉的其他领域(例如,Hourglass网络)的姿势估计中越来越流行。
As a follow-up, this Google team wrote more papers for this Inception series. “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift” stands for InceptionV2. “Rethinking the Inception Architecture for Computer Vision” in 2015 stands for InceptionV3. And “Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning” in 2015 stands for InceptionV4. Each paper added more improvement over the original Inception network and achieved a better result.
作为后续行动,该Google团队为此Inception系列撰写了更多论文。 “批处理规范化:通过减少内部协变量偏移来加速深度网络训练”代表InceptionV2。 2015年的“重新思考计算机视觉的Inception架构”代表InceptionV3。 2015年的“ Inception-v4,Inception-ResNet和残余连接对学习的影响”代表InceptionV4。 每篇论文都对原始的Inception网络进行了更多改进,并取得了更好的效果。
2015年:批量标准化 (2015: Batch Normalization)
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
批量归一化:通过减少内部协变量偏移来加速深度网络训练
The inception network helped researchers to reach a superhuman accuracy on the ImageNet dataset. However, as a statistic learning method, CNN is very much constrained to the statistic nature of a specific training dataset. Therefore, to achieve better accuracy, we usually need to pre-calculate the mean and standard deviation of the entire dataset and use them to normalize our input first to ensure most of the layer inputs in the network are close, which translates to better activation responsiveness. This approximate approach is very cumbersome, and sometimes doesn’t work at all for a new network structure or a new dataset, so the deep learning model is still viewed as difficult to train. To address this problem, Sergey Ioffe and Chritian Szegedy, the guy who created GoogLeNet, decided to invent something smarter called Batch Normalization.
初始网络帮助研究人员在ImageNet数据集上达到了超人的准确性。 但是,作为一种统计学习方法,CNN非常受特定训练数据集的统计性质的限制。 因此,为了获得更好的精度,我们通常需要预先计算整个数据集的平均值和标准偏差,并使用它们首先对我们的输入进行归一化,以确保网络中的大多数层输入都紧密,从而转化为更好的激活响应。 这种近似方法非常麻烦,有时对于新的网络结构或新的数据集根本不起作用,因此深度学习模型仍然被认为很难训练。 为了解决这个问题,创建GoogLeNet的人Sergey Ioffe和Chritian Szegedy决定发明一种更聪明的东西,称为“批标准化”。

The idea of batch normalization is not hard: We can use the statistics of a series of mini-batch to approximate the statistics of the whole dataset, as long as we train for long enough time. Also, instead of manually calculating the statistics, we can introduce two more learnable parameters “scale” and “shift” to have the network learn how to normalize each layer by itself.
批量规范化的想法并不难:只要训练足够长的时间,我们就可以使用一系列小批量的统计数据来近似整个数据集的统计数据。 此外,代替手动计算统计信息,我们可以引入两个更多可学习的参数“缩放”和“移位”,以使网络学习如何单独对每一层进行规范化。
The above diagram showed the process of calculating batch normalization values. As we can see, we take the mean of the whole mini-batch and calculate the variance as well. Next, we can normalize the input with this mini-batch mean and variance. Finally, with a scale and a shift parameter, the network will learn to adapt the batch normalized result to best fit the following layers, usually ReLU. One caveat is that we don’t have mini-batch information during inference, so a workaround is to calculate a moving average mean and variance during training, and then use these moving averages in the inference path. This little innovation is so impactful, and all later networks start to use it right away.
上图显示了计算批次归一化值的过程。 如我们所见,我们取整个小批量的平均值,并计算方差。 接下来,我们可以使用此最小批量均值和方差对输入进行归一化。 最后,通过比例尺和位移参数,网络将学会调整批标准化结果以最适合以下层,通常是ReLU。 一个警告是我们在推理期间没有小批量信息,因此一种解决方法是在训练期间计算移动平均值和方差,然后在推理路径中使用这些移动平均值。 这项小小的创新是如此具有影响力,所有后来的网络都立即开始使用它。
2015年:ResNet (2015: ResNet)
Deep Residual Learning for Image Recognition
深度残差学习用于图像识别
2015 may be the best year for computer vision in a decade, we’ve seen so many great ideas popping out not only in image classification but all sorts of computer vision tasks such as object detection, semantic segmentation, etc. The biggest advancement of the year 2015 belongs to a new network called ResNet, or residual networks, proposed by a group of Chinese researchers from Microsoft Research Asia.
2015年可能是十年来计算机视觉最好的一年,我们已经看到很多伟大的想法不仅出现在图像分类中,而且还出现了各种各样的计算机视觉任务,例如对象检测,语义分割等。 2015年属于一个新的网络,称为ResNet,即残差网络,该网络由来自Microsoft Research Asia的一组中国研究人员提出。
As we discussed earlier for VGG network, the biggest hurdle of getting even deeper is the gradient vanishing issue, i.e, derivatives become smaller and smaller when back-propagate through deeper layers, and eventually reaches a point that modern computer architecture can’t really represent meaningfully. GoogLeNet tried to attack this by using auxiliary supervision and asymmetric inception module, but it only alleviates the problem to a small extent. If we want to use 50 or even 100 layers, will there be a better way for the gradient to flow through the network? The answer from ResNet is to use a residual module.
正如我们之前在VGG网络中讨论的那样,变得更深层的最大障碍是梯度消失问题,即,当向后传播穿过更深层时,导数变得越来越小,最终达到现代计算机体系结构无法真正代表的地步。有意义地。 GoogLeNet尝试通过使用辅助监管和非对称启动模块来对此进行攻击,但只能在一定程度上缓解该问题。 如果我们要使用50甚至100层,是否会有更好的方法让渐变流过网络? ResNet的答案是使用残差模块。
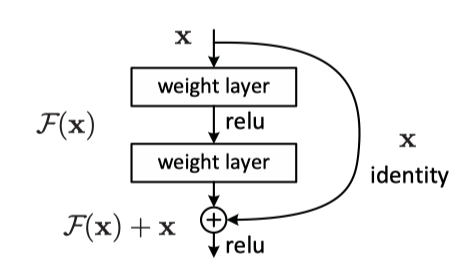
ResNet added an identity shortcut to the output, so that each residual module can’t at least predict whatever the input is, without getting lost in the wild. Even more important thing is, instead of hoping each layer fit directly to the desired feature mapping, the residual module tries to learn the difference between output and input, which makes the task much easier because the information gain needed is less. Imagine that you are learning mathematics, for each new problem, you are given a solution of a similar problem, so all you need to do is to extend this solution and try to make it work. This is much easier than thinking of a brand new solution for every problem you run into. Or as Newton said, we can stand on the shoulders of giants, and the identity input is that giant for the residual module.
ResNet在输出中添加了身份标识快捷方式,因此每个残差模块至少都不能预测输入是什么,而不会迷路。 甚至更重要的是,残差模块不是希望每个层都直接适合所需的特征映射,而是尝试了解输出和输入之间的差异,这使任务变得更加容易,因为所需的信息增益较小。 想象一下,您正在学习数学,对于每个新问题,都将得到一个类似问题的解决方案,因此您所需要做的就是扩展此解决方案并使其生效。 这比为您遇到的每个问题想出一个全新的解决方案要容易得多。 或者像牛顿所说,我们可以站在巨人的肩膀上,身份输入就是剩余模块的那个巨人。
In addition to identity mapping, ResNet also borrowed the bottleneck and Batch Normalization from Inception networks. Eventually, it managed to build a network with 152 convolution layers and achieved 80.72% top-1 accuracy on ImageNet. The residual approach also becomes a default option for many other networks later, such as Xception, Darknet, etc. Also, thanks to its simple and beautiful design, it’s still widely used in many production visual recognition systems nowadays.
除了身份映射之外,ResNet还从Inception网络借用了瓶颈和批处理规范化。 最终,它成功构建了具有152个卷积层的网络,并在ImageNet上实现了80.72%的top-1准确性。 剩余方法也成为以后许多其他网络(例如Xception,Darknet等)的默认选项。而且,由于其简单美观的设计,它在当今的许多生产视觉识别系统中仍得到广泛使用。
There’re many more invariants came out by following the hype of the residual network. In “Identity Mappings in Deep Residual Networks”, the original author of ResNet tried to put activation before the residual module and achieved a better result, and this design is called ResNetV2 afterward. Also, in a 2016 paper “Aggregated Residual Transformations for Deep Neural Networks”, researchers proposed ResNeXt which added parallel branches for residual modules to aggregate outputs of different transforms.
通过追踪残差网络的炒作,还有更多不变式出现。 在“深层残差网络中的身份映射”中,ResNet的原始作者试图将激活放在残差模块之前,并获得了更好的结果,此设计此后称为ResNetV2。 此外,在2016年的论文《深度神经网络的聚合残差变换》中,研究人员提出了ResNeXt,该模型为残差模块添加了并行分支,以汇总不同变换的输出。
2016年:Xception (2016: Xception)
Xception: Deep Learning with Depthwise Separable Convolutions
Xception:具有深度可分卷积的深度学习
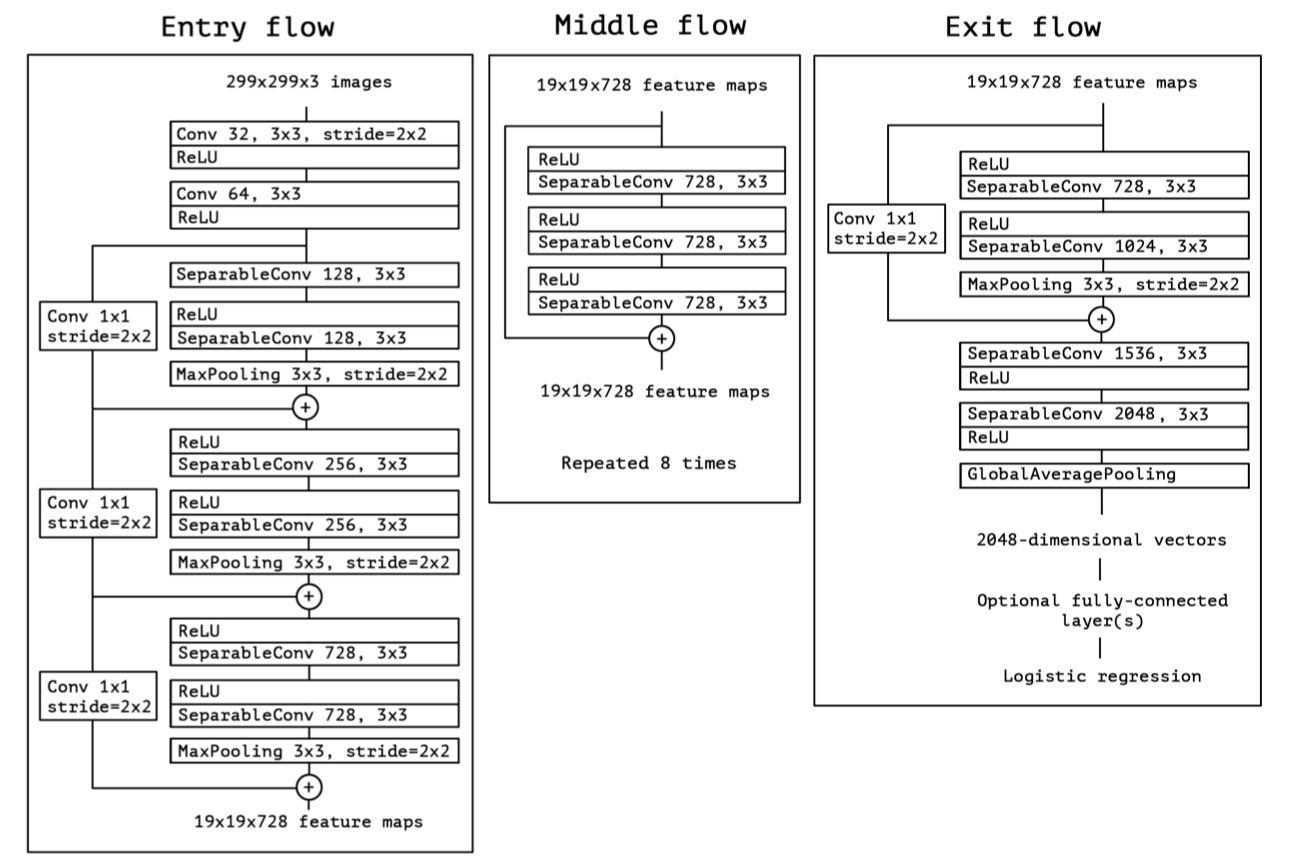
With the release of ResNet, it looked like most of the low hanging fruits in the image classifier were grabbed already. Researchers started to think about what is the internal mechanism of the magic of CNN. Since cross-channel convolution usually introduces a ton of parameters, the Xception network chose to investigate this operation to understand a full picture of its effect.
随着ResNet的发布,图像分类器中的大多数低挂水果看起来已经被抢走了。 研究人员开始考虑CNN魔术的内部机制是什么。 由于跨通道卷积通常会引入大量参数,因此Xception网络选择调查此操作以了解其效果的全貌。
Like its name, Xception originates from the Inception network. In the Inception module, multiple branches of different transformations are aggregated together to achieve a topology sparsity. But why this sparsity worked? The author of Xception, also the author of the Keras framework, extended this idea to an extreme case where one 3x3 convolution file correspond to one output channel before a final concatenation. In this case, these parallel convolution kernels actually form a new operation called depth-wise convolution.
就像它的名字一样,Xception源自Inception网络。 在Inception模块中,将不同转换的多个分支聚合在一起以实现拓扑稀疏性。 但是为什么这种稀疏起作用了? Xception的作者,也是Keras框架的作者,将这一思想扩展到了一种极端情况,在这种情况下,一个3x3卷积文件对应于最后一个串联之前的一个输出通道。 在这种情况下,这些并行卷积内核实际上形成了一个称为深度卷积的新操作。

As shown in the diagram above, unlike traditional convolution where all channels are included for one computation, depth-wise convolution only computes convolution for each channel separately and then concatenate the output together. This cuts the feature exchange among channels, but also reduces a lot of connections, hence result in a layer with fewer parameters. However, this operation will output the same number of channels as input (Or a smaller number of channels if you group two or more channels together). Therefore, once the channel outputs are merged, we need another regular 1x1 filter, or point-wise convolution, to increase or reduce the number of channels, just like regular convolution does.
如上图所示,与传统卷积不同,传统卷积包括所有通道以进行一次计算,深度卷积仅分别计算每个通道的卷积,然后将输出串联在一起。 这减少了通道之间的特征交换,但也减少了很多连接,因此导致具有较少参数的层。 但是,此操作将输出与输入相同数量的通道(如果将两个或多个通道组合在一起,则输出的通道数量将减少)。 因此,一旦合并了通道输出,就需要另一个常规的1x1滤波器或逐点卷积,以增加或减少通道数,就像常规卷积一样。
This idea is not from Xception originally. It’s described in a paper called “Learning visual representations at scale” and also used occasionally in InceptionV2. Xception took a step further and replaced almost all convolutions with this new type. And the experiment result turned out to be pretty good. It surpasses ResNet and InceptionV3 and became a new SOTA method for image classification. This also proved that the mapping of cross-channel correlations and spatial correlations in CNN can be entirely decoupled. In addition, sharing the same virtue with ResNet, Xception has a simple and beautiful design as well, so its idea is used in lots of other following research such as MobileNet, DeepLabV3, etc.
这个想法最初不是来自Xception。 在名为“大规模学习视觉表示”的论文中对此进行了描述,并且在InceptionV2中也偶尔使用。 Xception进一步走了一步,并用这种新型卷积代替了几乎所有的卷积。 实验结果非常好。 它超越了ResNet和InceptionV3,成为一种新的SOTA图像分类方法。 这也证明了CNN中跨通道相关性和空间相关性的映射可以完全解耦。 此外,Xception与ResNet具有相同的优点,它还具有简单美观的设计,因此其思想还用于许多其他后续研究中,例如MobileNet,DeepLabV3等。
2017年:MobileNet (2017: MobileNet)
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application
MobileNets:用于移动视觉应用的高效卷积神经网络
Xception achieved 79% top-1 accuracy and 94.5% top-5 accuracy on ImageNet, but that’s only 0.8% and 0.4% improvement respectively compared with previous SOTA InceptionV3. The marginal gain of a new image classification network is becoming smaller, so researchers start to shift their focus into other areas. And MobileNet led a significant push of image classification in a resource constrained environment.
Xception在ImageNet上实现了79%的top-1准确性和94.5%的top-5准确性,但是与以前的SOTA InceptionV3相比分别仅提高了0.8%和0.4%。 新图像分类网络的边际收益越来越小,因此研究人员开始将注意力转移到其他领域。 在资源受限的环境中,MobileNet领导了图像分类的重大推动。
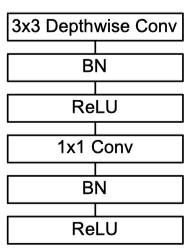
Similar to Xception, MobileNet used a same depthwise separable convolution module as shown above and had an emphasis on the high efficiency and less parameters.
与Xception相似,MobileNet使用与上述相同的深度可分离卷积模块,并着重于高效和较少参数。
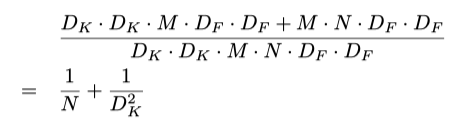
The numerator in the above formula is the total number of parameters required by a depthwise separable convolution. And the denominator is the total number of parameters of a similar regular convolution. Here D[K] is the size of convolution kernel, D[F] is the size of the feature map, M is the number of input channels, N is the number of output channels. Since we separated the calculation of channel and spatial feature, we can turn multiplication into an addition, which is a magnitude smaller. Even better, as we can see from this ratio, the larger the number of output channels is, the more calculation we saved from using this new convolution.
上式中的分子是深度可分离卷积所需的参数总数。 分母是相似的规则卷积的参数总数。 这里D [K]是卷积核的大小,D [F]是特征图的大小,M是输入通道数,N是输出通道数。 由于我们将通道和空间特征的计算分开了,因此我们可以将乘法转化为相加,幅度要小一些。 从这个比率可以看出,更好的是,输出通道数越多,使用这种新卷积节省的计算量就越多。
Another contribution from MobileNet is the width and resolution multiplier. MobileNet team wanted to find a canonical way to shrink model size for mobile devices, and the most intuitive way is to reduce the number of input and output channels, as well as the input image resolution. To control this behavior, a ratio alpha is multiplied with channels, and a ratio rho is multiplied with input resolution (which also affects feature map size). So the total number of parameters can be represented in the following formula:
MobileNet的另一个贡献是宽度和分辨率乘数。 MobileNet团队希望找到一种缩小移动设备模型大小的规范方法,而最直观的方法是减少输入和输出通道的数量以及输入图像的分辨率。 为了控制此行为,比率alpha乘以通道,比率rho乘以输入分辨率(这也会影响要素地图的大小)。 因此,参数总数可以用以下公式表示:
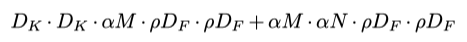
Although this change seems naive in terms of innovation, it has great engineering value because it’s the first time researchers conclude a canonical approach to adjust network for different resource constraints. Also, it kind of summarized the ultimate solution of improving neural network: wider and high-res input leads to better accuracy, thinner and low-res input leads to poorer accuracy.
尽管这种变化在创新方面看似天真,但它具有巨大的工程价值,因为这是研究人员首次得出结论,可以针对不同的资源约束调整网络的规范方法。 此外,它还总结了改进神经网络的最终解决方案:更大和更高的分辨率输入会导致更好的精度,更薄和更低的分辨率输入会导致更差的精度。
Later in 2018 and 2019, the MobiletNet team also released “MobileNetV2: Inverted Residuals and Linear Bottlenecks” and “Searching for MobileNetV3”. In MobileNetV2, an inverted residual bottleneck structure is used. And in MobileNetV3, it started to search the optimal architecture combination using Neural Architecture Search technology, which we will cover next.
在2018年和2019年晚些时候,MobiletNet团队还发布了“ MobileNetV2:反向残差和线性瓶颈”和“正在搜索MobileNetV3”。 在MobileNetV2中,使用了倒置的残留瓶颈结构。 在MobileNetV3中,它开始使用神经体系结构搜索技术来搜索最佳体系结构组合,我们将在后面介绍。
2017年:NASNet (2017: NASNet)
Learning Transferable Architectures for Scalable Image Recognition
学习可扩展的体系结构以实现可扩展的图像识别
Just like image classification for a resource-constrained environment, neural architecture search is another field that emerged around 2017. With ResNet, Inception, and Xception, it seems like we reached an optimal network topology that humans can understand and design, but what if there’s a better and much more complex combination that far exceeds human imagination? A paper in 2016 called “Neural Architecture Search with Reinforcement Learning” proposed an idea to search the optimal combination within a pre-defined search space by using reinforcement learning. As we know, reinforcement learning is a method to find the best solution with a clear goal and reward for the search agent. However, limited by computing power, this paper only discussed the application in a small CIFAR dataset.
就像针对资源受限环境的图像分类一样,神经体系结构搜索是在2017年左右出现的另一个领域。借助ResNet,Inception和Xception,似乎我们已经达到了人类可以理解和设计的最佳网络拓扑,但是如果有的话一个更好,更复杂的组合,远远超出了人类的想象力? 2016年的一篇论文《带有增强学习的神经体系结构搜索》提出了一种通过使用增强学习在预定搜索空间内搜索最佳组合的想法。 众所周知,强化学习是一种以目标明确,奖励搜索代理商的最佳解决方案的方法。 但是,受计算能力的限制,本文仅讨论了在小型CIFAR数据集中的应用。

With the goal of finding an optimal structure for a large dataset like ImageNet, NASNet made a search space that is tailored for ImageNet. It hopes to design a special search space so that the searched result on CIFAR can also work on ImageNet well. First, NASNet assumes that common hand-crafted module in good networks like ResNet and Xception are still useful when searching. So instead of searching for random connection and operations, NASNet searches the combination of these modules that have been proved to be useful already on ImageNet. Second, the actual searching is still performed on the CIFAR dataset with 32x32 resolution, so NASNet only searches for modules that are not affected by the input size. In order to make the second point work, NASNet predefined two types of module templates: Reduction and Normal. Reduction cell could have reduced feature map compared with the input, and for Normal cell it would be the same.
为了找到像ImageNet这样的大型数据集的最佳结构,NASNet创建了一个针对ImageNet的搜索空间。 它希望设计一个特殊的搜索空间,以便CIFAR上的搜索结果也可以在ImageNet上正常工作。 首先,NASNet假设在良好的网络(如ResNet和Xception)中常用的手工模块在搜索时仍然有用。 因此,NASNet无需搜索随机连接和操作,而是搜索这些模块的组合,这些模块已被证明在ImageNet上已经有用。 其次,实际搜索仍在32x32分辨率的CIFAR数据集上执行,因此NASNet仅搜索不受输入大小影响的模块。 为了使第二点起作用,NASNet预定义了两种类型的模块模板:Reduction和Normal。 与输入相比,归约单元可能具有缩小的特征图,对于法线单元,它是相同的。
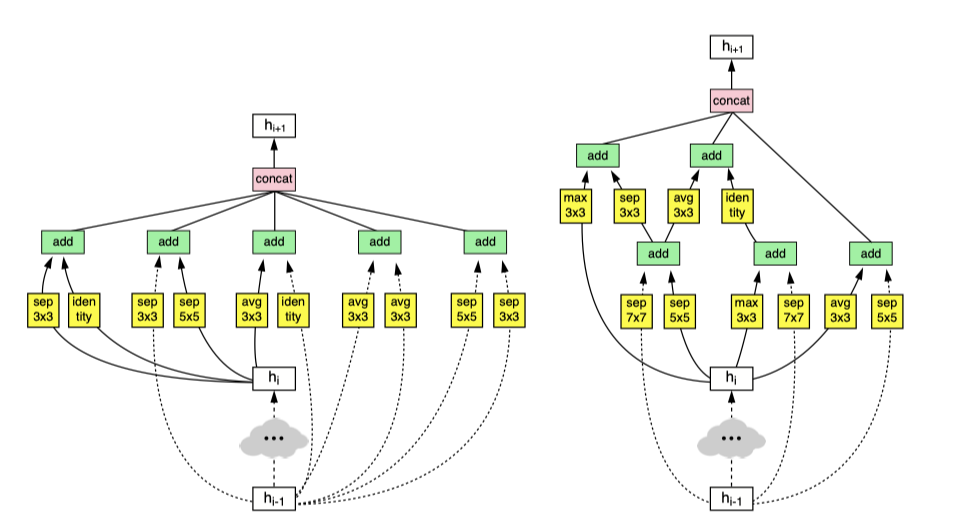
Although NASNet has better metrics than manually design networks, it also suffers from a few drawbacks. The cost of searching for an optimal structure is very high, which is only affordable by big companies like Google and Facebook. Also, the final structure doesn’t make too much sense to humans, hence harder to maintain and improve in a production environment. Later in 2018, “MnasNet: Platform-Aware Neural Architecture Search for Mobile” further extends this NASNet idea by limit the search step with a pre-defined chained-blocks structure. Also, by defining a weight factor, mNASNet gave a more systematic way to search model given specific resource constraints, instead of just evaluating based on FLOPs.
尽管NASNet具有比手动设计网络更好的度量标准,但是它也有一些缺点。 寻找最佳结构的成本非常高,只有像Google和Facebook这样的大公司才能负担得起。 而且,最终结构对人类而言并没有太大意义,因此在生产环境中难以维护和改进。 在2018年晚些时候,“ MnasNet:针对移动平台的神经结构搜索”通过使用预定义的链块结构限制搜索步骤,进一步扩展了NASNet的想法。 另外,通过定义权重因子,mNASNet提供了一种更系统的方法来搜索给定特定资源限制的模型,而不仅仅是基于FLOP进行评估。
2019年:EfficientNet (2019: EfficientNet)
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
EfficientNet:卷积神经网络的模型缩放比例的重新思考
In 2019, it looks like there are no exciting ideas for supervised image classification with CNN anymore. A drastic change in network structure usually only offers a little accuracy improvement. Even worse, when the same network applied to different datasets and tasks, previously claimed tricks don’t seem to work, which led to critiques that whether those improvements are just overfitting on the ImageNet dataset. On the other side, there’s one trick that never fails our expectation: using higher resolution input, adding more channels for convolution layers, and adding more layers. Although very brutal force, it seems like there’s a principled way to scale the network on demand. MobileNetV1 sort of suggested this in 2017, but the focus was shifted to a better network design later.
在2019年,对于CNN进行监督图像分类似乎不再有令人兴奋的想法。 网络结构的急剧变化通常只会带来少许的精度提高。 更糟的是,当同一个网络应用于不同的数据集和任务时,以前声称的技巧似乎不起作用,这引发了人们的批评,即这些改进是否仅适合ImageNet数据集。 另一方面,有一个技巧绝不会辜负我们的期望:使用更高分辨率的输入,为卷积层添加更多通道以及添加更多层。 尽管力量非常残酷,但似乎存在一种按需扩展网络的原则方法。 MobileNetV1在2017年提出了这种建议,但后来重点转移到了更好的网络设计上。

After NASNet and mNASNet, researchers realized that even with the help from a computer, a change in architecture doesn’t yield that much benefit. So they start to fall back to the scaling the network. EfficientNet is just built on top of this assumption. On one hand, it uses the optimal building block from mNASNet to make sure a good foundation to start with. On the other hand, it defined three parameters alpha, beta, and rho to control the depth, width, and resolution of the network correspondingly. By doing so, even without a large GPU pool to search for an optimal structure, engineers can still rely on these principled parameters to tune the network based on their different requirements. In the end, EfficientNet gave 8 different variants with different width, depth, and resolution ratios and got good performance for both small and big models. In other words, if you want high accuracy, go for a 600x600 and 66M parameters EfficientNet-B7. If you want low latency and smaller model, go for a 224x224 and 5.3M parameters EfficientNet-B0. Problem solved.
继NASNet和mNASNet之后,研究人员意识到,即使有了计算机的帮助,架构的改变也不会带来太大的好处。 因此,他们开始回落到扩展网络。 EfficientNet只是建立在此假设之上的。 一方面,它使用mNASNet的最佳构建基块来确保良好的基础。 另一方面,它定义了三个参数alpha,beta和rho来分别控制网络的深度,宽度和分辨率。 这样,即使没有大型GPU池来搜索最佳结构,工程师仍可以依靠这些原则性参数根据他们的不同要求来调整网络。 最后,EfficientNet提供了8种不同的变体,它们具有不同的宽度,深度和分辨率,并且无论大小模型都具有良好的性能。 换句话说,如果要获得高精度,请使用600x600和66M参数的EfficientNet-B7。 如果您想要低延迟和更小的模型,请使用224x224和5.3M参数EfficientNet-B0。 问题解决了。
阅读更多 (Read More)
If you finish reading above 10 papers, you should have a pretty good grasp of the history of image classification with CNN. If you like to keep learning this area, I’ve also listed some other interesting papers to read. Although not included in the top-10 list, these papers are all famous in their own area and inspired many other researchers in the world.
如果您完成了10篇以上的论文的阅读,您应该对CNN的图像分类历史有了很好的了解。 如果您想继续学习这一领域,我还列出了一些其他有趣的论文供您阅读。 尽管未列入前十名,但这些论文在各自领域都很有名,并启发了世界上许多其他研究人员。
2014年:SPPNet (2014: SPPNet)
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
深度卷积网络中的空间金字塔池用于视觉识别
SPPNet borrows the idea of feature pyramid from traditional computer vision feature extraction. This pyramid forms a bag of words of features with different scales, so it is can adapt to different input sizes and get rid of the fixed-size fully connected layer. This idea also further inspired the ASPP module of DeepLab, and also FPN for object detection.
SPPNet从传统的计算机视觉特征提取中借鉴了特征金字塔的思想。 该金字塔形成了一个具有不同比例尺的特征单词袋,因此它可以适应不同的输入大小并摆脱固定大小的全连接层。 这个想法还进一步启发了DeepLab的ASPP模块以及用于对象检测的FPN。
2016年:DenseNet (2016: DenseNet)
Densely Connected Convolutional Networks
紧密连接的卷积网络
DenseNet from Cornell further extends the idea from ResNet. It not only provides skip connection between layers but also has skip connections from all previous layers.
康奈尔大学的DenseNet进一步扩展了ResNet的想法。 它不仅提供了各层之间的跳过连接,而且还具有来自所有先前各层的跳过连接。
2017年:SENet (2017: SENet)
Squeeze-and-Excitation Networks
挤压和激励网络
The Xception network demonstrated that cross-channel correlation doesn’t have much to do with spatial correlation. However, as the champion of the last ImageNet competition, SENet devised a Squeeze-and-Excitation block and told a different story. The SE block first squeezes all channels into fewer channels using global pooling, applies a fully connected transform, and then “excite” them back to the original number of channels using another fully connected layer. So essentially, the FC layer helped the network to learn attentions on the input feature map.
Xception网络证明,跨通道关联与空间关联关系不大。 但是,作为上届ImageNet竞赛的冠军,SENet设计了一个“挤压和激发”区并讲述了一个不同的故事。 SE块首先使用全局池将所有通道压缩为较少的通道,应用完全连接的转换,然后使用另一个完全连接的层将其“激发”回原来的通道数量。 因此,从本质上讲,FC层帮助网络了解了输入要素图上的注意力。
2017年:ShuffleNet (2017: ShuffleNet)
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
ShuffleNet:一种用于移动设备的极其高效的卷积神经网络
Built on top of MobileNetV2’s inverted bottleneck module, ShuffleNet believes that point-wise convolution in depthwise separable convolution sacrifices accuracy in exchange for less computation. To compensate for this, ShuffleNet added an additional channel shuffling operation to make sure point-wise convolution will not always be applied to the same “point”. And in ShuffleNetV2, this channel shuffling mechanism is further extended to a ResNet identity mapping branch as well, so that part of the identity feature will also be used to shuffle.
ShuffleNet建立在MobileNetV2的倒置瓶颈模块之上,他认为深度可分离卷积中的点式卷积会牺牲准确性,以换取较少的计算量。 为了弥补这一点,ShuffleNet增加了一个额外的通道改组操作,以确保逐点卷积不会始终应用于同一“点”。 在ShuffleNetV2中,此通道改组机制也进一步扩展到ResNet身份映射分支,因此,部分身份功能也将用于改组。
2018:技巧包 (2018: Bag of Tricks)
Bag of Tricks for Image Classification with Convolutional Neural Networks
使用卷积神经网络进行图像分类的技巧包
Bag of Tricks focuses on common tricks used in the image classification area. It serves as a good reference for engineers when they need to improve benchmark performance. Interestingly, these tricks such as mixup augmentation and cosine learning rate can sometimes achieve far better improvement than a new network architecture.
“技巧包”重点介绍在图像分类区域中使用的常见技巧。 当工程师需要提高基准性能时,它可以作为参考。 有趣的是,诸如混合增强和余弦学习速率之类的这些技巧有时可以比新的网络体系结构实现更好的改进。
结论 (Conclusion)
With the release of EfficientNet, it looks like the ImageNet classification benchmark comes to an end. With the existing deep learning approach, there will never be a day we can reach 99.999% accuracy on the ImageNet unless another paradigm shift happened. Hence, researchers are actively looking at some novel areas such as self-supervised or semi-supervised learning for large scale visual recognition. In the meantime, with existing methods, it became more a question for engineers and entrepreneurs to find the real-world application of this non-perfect technology. In the future, I will also write a survey to analyze those real-world computer vision applications powered by image classification, so please stay tuned! If you think there are also other important papers to read for image classification, please leave a comment below and let us know.
随着EfficientNet的发布,ImageNet分类基准似乎即将结束。 使用现有的深度学习方法,除非发生另一种模式转变,否则我们永远不会有一天可以在ImageNet上达到99.999%的准确性。 因此,研究人员正在积极研究一些新颖的领域,例如用于大规模视觉识别的自我监督或半监督学习。 同时,使用现有方法,对于工程师和企业家来说,找到这种不完美技术的实际应用已经成为一个问题。 将来,我还将撰写一份调查报告,以分析那些由图像分类支持的现实世界中的计算机视觉应用程序,请继续关注! 如果您认为还需要阅读其他重要文章以进行图像分类,请在下面发表评论,并告知我们。
Originally published at http://yanjia.li on July 31, 2020
最初于 2020年7月31日 发布在 http://yanjia.li
深度学习 图像分类


