
- 1python教学网站免费,python自学平台_realpython官网花钱吗
- 2文心一言 4.0 ERNIE-Bot 4.0 :ERNIE-Bot 4.0 大模型深度测试体验报告_文心大模型4.0版本下载
- 3FPGA-VGA显示图像_基于fpga的vga显示设计方案
- 4网络数据包在链路层、网络层转发过程(转发)_ping链路中数据包发送流程
- 5【嵌入式】基于STC89C52RC的51单片机学习(一)_stc89c52rc单片机io接口和vccio接口区别
- 6主题:non-fast-forward 错误提示
- 7Java计算时间差、日期差总结_java算时间差
- 8【IOS】testfilght邀请流程_testflight邀请码
- 9ssh设置别名 ,登录_ssh 别名登录
- 10矩阵的相似性度量的常用方法_矩阵相似度
机器学习简史及发展趋势预测_机器学习的发展史
赞
踩
0.概述
机器学习的发展和人工智能发展是离不开的,机器学习是人工智能研究发展到一定阶段的必然产物。人工智能的研究历史有着一条从以“推理”为重点,到以“知识”为重点,再到以“学习”为重点的自然、清晰的脉络。下面是人工智能发展的三个时期:
-
推理期: 时间为1950s~1970s,人们认为只要给机器赋予逻辑推理能力,机器就能具有智能。这一阶段的代表性工作主要有A. Newell和H. Simon的“逻辑理论家”程序以及此后的“通用问题求解”程序等,这些工作在当时取得了令人振奋的成果。例如,“逻辑理论家”程序在1952年证明了著名数学家罗素和怀特海的名著《数学原理》中的38条定理,在1963年证明了全部的52 条定理,而且定理 2.85甚至比罗素和怀特海证明得更巧妙。A.Newell和H.Simon因此获得了1975年图灵奖。然而,随着研究向前发展,人们逐渐认识到,仅具有逻辑推理能力是远远实现不了人工智能的。E.A. Feigenbaum等人认为,要使机器具有智能,就必须设法使机器拥有知识。
-
知识期: 时间为1970s~1980s,在这一时期,大量专家系统问世,在很多领域做出了巨大贡献。E.A. Feigenbaum 作为“知识工程”之父在 1994 年获得了图灵奖。但是,专家系统面临“知识工程瓶颈”,简单地说,就是由人来把知识总结出来再教给计算机是相当困难的。于是,一些学者想到,如果机器自己能够学习知识该多好。
-
学习期: 时间为1980s~现在,机器学习开始受到重视,成为一个独立的学科领域并开始快速发展、各种机器学习技术百花齐放的时期。事实上,图灵在1950年提出图灵测试的文章中就已经提到了机器学习的可能,而1950s其实已经开始有机器学习相关的研究工作,主要集中在基于神经网络的连接主义学习方面,代表性工作主要有F.Rosenblatt的感知机、B.Widrow的Adaline等。尤其是在2012年以后,随着机器学习的子领域深度学习的飞速发展,以“学习”为主要实现方式的人工智能成为目前的主流。
对于人工智能(AI),机器学习(ML),深度学习(DL),用几张图直观对比如下,从提出概念的时间上来看也很清楚:
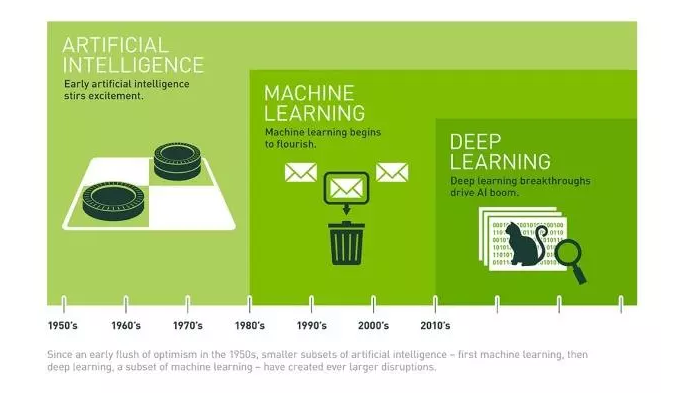
人工智能AI:模拟人脑,辨认哪个是苹果,哪个是橙子。

机器学习ML:根据特征在水果摊买橙子,随着见过的橙子和其他水果越来越多,辨别橙子的能力越来越强,不会再把香蕉当橙子。
机器学习强调“学习”而不是程序本身,通过复杂的算法来分析大量的数据,识别数据中的模式,并做出一个预测--不需要特定的代码。在样本的数量不断增加的同时,自我纠正完善“学习目的”,可以从自身的错误中学习,提高识别能力。

深度学习DL:超市里有3种苹果和5种橙子,通过数据分析比对,把超市里的品种和数据建立联系,通过水果的颜色、形状、大小、成熟时间和产地等信息,分辨普通橙子和血橙,从而选择购买用户需要的橙子品种。
1. 机器学习简史
哲学上的三大终极问题:是谁?从哪来?到哪去?用在任何地方都是有意义的。
——尼古拉斯·沃布吉·道格拉斯·硕德
虽然人工智能并不是最近几年才兴起的,但在它一直作为科幻元素出现在大众视野中。自从AlphaGo战胜李世石之后,人工智能突然间成了坊间谈资,仿佛人类已经造出了超越人类智慧的机器。而人工智能的核心技术机器学习及其子领域深度学习一时间成了人们的掌上明珠。面对这个从天而降的“怪物”,乐观者有之,悲观者亦有之。但追溯历史,我们会发现机器学习的技术爆发有其历史必然性,属于技术发展的必然产物。而理清机器学习的发展脉络有助于我们整体把握机器学习,或者人工智能的技术框架,有助于从“道”的层面理解这一技术领域。这一节就先从三大究极哲学问题中的后两个——从哪来、到哪去入手,整体把握机器学习,而后再从“术”的角度深入学习,解决是谁的问题。

图1 机器学习发展史(图片来源:Brief History of Machine Learning)
在图1中,按时间轴顺序事件详情如下:
-
1943年【NN基础理论】,McCulloch和Pitts提出了神经网络层次结构模型,确立了神经网络的计算模型理论,从而为机器学习的发展奠定了基础
-
1950年【重要事件】,Turing提出了著名的“图灵测试”,使人工智能成为了科学领域的一个重要研究课题
-
1957年【NN第一次崛起】,Rosenblatt提出了Perceptron(感知器)概念,用Rosenblatt算法对Perceptron进行训练。并且首次用算法精确定义了自组织自学习的神经网络数学模型,设计出了第一个计算机神经网络(NN算法),开启了NN研究活动的第一次兴起
-
1958年【正式LR】,Cox给Logistic Regression方法正式命名,用于解决美国人口普查任务
-
1959年【重要事件】,Samuel设计了一个具有学习能力的跳棋程序,曾经战胜了美国保持8年不败的冠军。这个程序向人们初步展示了机器学习的能力,Samuel将机器学习定义为无需明确编程即可为计算机提供能力的研究领域
-
1960年【NN发展】,Widrow用delta学习法则来对Perceptron进行训练,可以比Rosenblatt算法更有效地训练出良好的线性分类器(最小二乘法问题)
-
1962年【雏形CNN】,Hubel和Wiesel发现了猫脑皮层中独特的神经网络结构可以有效降低学习的复杂性,从而提出著名的Hubel-Wiese生物视觉模型,该模型卷积神经网络(CNN)的雏形,这之后提出的神经网络模型也均受此启迪
-
1963年【雏形SVM】,Vapnik和Chervonenkis发明原始支持向量方法,即起决定性作用的样本为支持向量(SVM算法)
-
1969年【NN第一次停滞】,Minsky和Papert出版了对机器学习研究有深远影响的著作《Perceptron》,其中对于机器学习基本思想的论断:解决问题的算法能力和计算复杂性,影响深远且延续至今。文章中提出了著名的线性感知机无法解决异或问题,打击了NN社区,从那以后NN研究活动直到1980s都萎靡。
-
1971年【重要事件】,Vapnik和Chervonenkis提出VC维概念,描述了假设空间和模型复杂度,衡量了经验误差和泛化误差的逼近程度,它给诸多机器学习方法的可学习性提供了坚实的理论基础
-
1980年【重要事件】,在美国卡内基梅隆大学举行了第一届机器学习国际研讨会,标志着机器学习研究在世界范围内兴起,该研讨会也是著名会议ICML的前身
-
1981年【NN第二次崛起】,Werbos提出多层感知机,解决了线性模型无法解决的异或问题,第二次兴起了NN研究
-
1984年【重要事件】,Leslie Valiant提出概率近似正确学习(Probably approximately correct learning,PAC learning),是机器学习的数学分析的框架,它将计算复杂度理论引入机器学习,描述了机器学习的有限假设空间的可学习性,无限空间的VC维相关的可学习性等问题。
-
1984年【决策树】,Breiman发表分类回归树(CART算法,一种决策树)
-
1986年【决策树】,Quinlan提出ID3算法(一种决策树)
-
1986年【NN的BP算法】,Rumelhart,Hinton和Williams联合在《Nature》杂志发表了著名的反向传播算法(BP算法)
-
1989年【正式CNN】,Yann和LeCun提出了目前最为流行的卷积神经网络(CNN)计算模型,推导出基于BP算法的高效训练方法,并成功地应用于英文手写体识别
-
1995年【正式SVM】,Vapnik和Cortes发表软间隔支持向量机(SVM算法),开启了随后的机器学习领域NN和SVM两大社区的竞争
-
1995年【NN第二次停滞】,自1995年到随后的10年,NN研究发展缓慢,SVM在大多数任务的表现上一直压制着NN,并且Hochreiter的工作证明了NN的一个严重缺陷-梯度爆炸和梯度消失问题
-
1997年【Adaboost】,Freund和Schapire提出了另一种可靠的机器学习方法-Adaboost,
-
2001年【随机森林】,Breiman发表随机森林方法(Random forest),Adaboost在对过拟合问题和奇异数据容忍上存在缺陷,而随机森林在这两个问题上更加鲁棒。
-
2005年【NN第三次崛起】,经过多年的发展,NN众多研究发现被现代NN大牛Hinton, LeCun, Bengio, Andrew Ng和其它老一辈研究者整合,NN随后开始被称为深度学习(Deep Learning),迎来了第三次崛起.
1.1 诞生并奠定基础时期
1949, Hebb, Hebbian Learning theory
赫布于1949年基于神经心理的提出了一种学习方式,该方法被称之为赫布学习理论。大致描述为:
假设反射活动的持续性或反复性会导致细胞的持续性变化并增加其稳定性,当一个神经元A能持续或反复激发神经元B时,其中一个或两个神经元的生长或代谢过程都会变化。
Let us assume that the persistence or repetition of a reverberatory activity (or “trace”) tends to induce lasting cellular changes that add to its stability.… When an axon of cell A is near enough to excite a cell B and repeatedly or persistently takes part in firing it, some growth process or metabolic change takes place in one or both cells such that A’s efficiency, as one of the cells firing B, is increased
从人工神经元或人工神经网络角度来看,该学习理论简单地解释了循环神经网络(RNN)中结点之间的相关性关系(权重),即:当两个节点同时发生变化(无论是positive还是negative),那么节点之间有很强的正相关性(positive weight);如果两者变化相反,那么说明有负相关性(negative weight)。
1950, Alan Turing, The Turing test
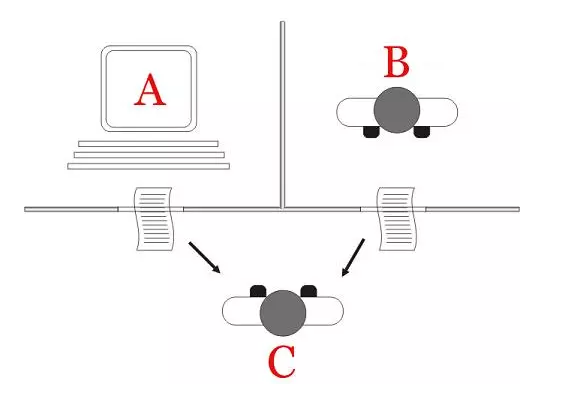
图二 图灵测试(图片来源:维基百科)
1950年,阿兰·图灵创造了图灵测试来判定计算机是否智能。图灵测试认为,如果一台机器能够与人类展开对话(通过电传设备)而不能被辨别出其机器身份,那么称这台机器具有智能。这一简化使得图灵能够令人信服地说明“思考的机器”是可能的。
2014年6月8日,一个叫做尤金·古斯特曼的聊天机器人成功让人类相信它是一个13岁的男孩,成为有史以来首台通过图灵测试的计算机。这被认为是人工智能发展的一个里程碑事件。
1952, Arthur Samuel, “Machine Learning”

图三 塞缪尔(图片来源:Brief History of Machine Learning)
1952,IBM科学家亚瑟·塞缪尔开发了一个跳棋程序。该程序能够通过观察当前位置,并学习一个隐含的模型,从而为后续动作提供更好的指导。塞缪尔发现,伴随着该游戏程序运行时间的增加,其可以实现越来越好的后续指导。通过这个程序,塞缪尔驳倒了普罗维登斯提出的机器无法超越人类,像人类一样写代码和学习的模式。他创造了“机器学习”这一术语,并将它定义为:
可以提供计算机能力而无需显式编程的研究领域
a field of study that gives computer the ability without being explicitly programmed.
1957, Rosenblatt, Perceptron

图四 感知机线性分类器(图片来源:维基百科)
1957年,罗森·布拉特基于神经感知科学背景提出了第二模型,非常的类似于今天的机器学习模型。这在当时是一个非常令人兴奋的发现,它比赫布的想法更适用。基于这个模型罗森·布拉特设计出了第一个计算机神经网络——感知机(the perceptron),它模拟了人脑的运作方式。罗森·布拉特对感知机的定义如下:
感知机旨在说明一般智能系统的一些基本属性,它不会因为个别特例或通常不知道的东西所束缚住,也不会因为那些个别生物有机体的情况而陷入混乱。
The perceptron is designed to illustrate some of the fundamental properties of intelligent systems in general, without becoming too deeply enmeshed in the special, and frequently unknown, conditions which hold for particular biological organisms.
3年后,维德罗首次使用Delta学习规则(即最小二乘法)用于感知器的训练步骤,创造了一个良好的线性分类器。
1967年,The nearest neighbor algorithm
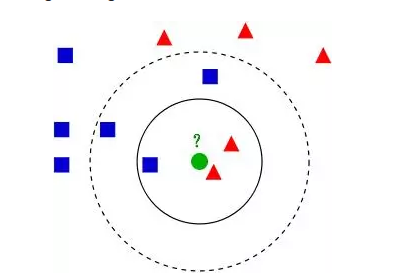
图五 kNN算法(图片来源:维基百科)
1967年,最近邻算法(The nearest neighbor algorithm)出现,使计算机可以进行简单的模式识别。kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。这就是所谓的“少数听从多数”原则。
1969, Minsky, XOR problem

图六 XOR问题,数据线性不可分
1969年马文·明斯基提出了著名的XOR问题,指出感知机在线性不可分的数据分布上是失效的。此后神经网络的研究者进入了寒冬,直到 1980 年才再一次复苏。
1.2 停滞不前的瓶颈时期
从60年代中到70年代末,机器学习的发展步伐几乎处于停滞状态。无论是理论研究还是计算机硬件限制,使得整个人工智能领域的发展都遇到了很大的瓶颈。虽然这个时期温斯顿(Winston)的结构学习系统和海斯·罗思(Hayes Roth)等的基于逻辑的归纳学习系统取得较大的进展,但只能学习单一概念,而且未能投入实际应用。而神经网络学习机因理论缺陷也未能达到预期效果而转入低潮。
1.3 希望之光重新点亮
1981, Werbos, Multi-Layer Perceptron (MLP)
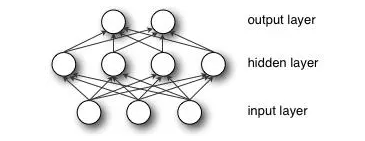
图七 多层感知机(或者人工神经网络)
伟博斯在1981年的神经网络反向传播(BP)算法中具体提出多层感知机模型。虽然BP算法早在1970年就已经以“自动微分的反向模型(reverse mode of automatic differentiation)”为名提出来了,但直到此时才真正发挥效用,并且直到今天BP算法仍然是神经网络架构的关键因素。有了这些新思想,神经网络的研究又加快了。
在1985-1986年,神经网络研究人员(鲁梅尔哈特,辛顿,威廉姆斯-赫,尼尔森)相继提出了使用BP算法训练的多参数线性规划(MLP)的理念,成为后来深度学习的基石。
1986, Quinlan, Decision Trees
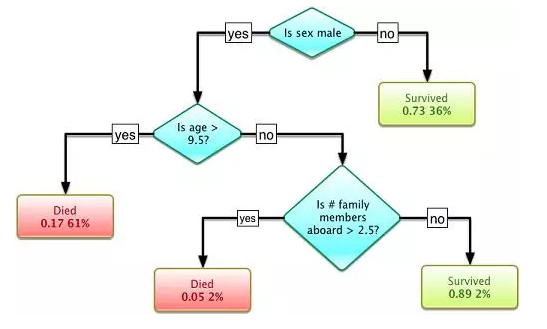
图八 决策树(图片来源:维基百科)
在另一个谱系中,昆兰于1986年提出了一种非常出名的机器学习算法,我们称之为“决策树”,更具体的说是ID3算法。这是另一个主流机器学习算法的突破点。此外ID3算法也被发布成为了一款软件,它能以简单的规划和明确的推论找到更多的现实案例,而这一点正好和神经网络黑箱模型相反。
决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单一输出,若欲有复数输出,可以建立独立的决策树以处理不同输出。数据挖掘中决策树是一种经常要用到的技术,可以用于分析数据,同样也可以用来作预测。
在ID3算法提出来以后,研究社区已经探索了许多不同的选择或改进(如ID4、回归树、CART算法等),这些算法仍然活跃在机器学习领域中。
1.4 现代机器学习的成型时期
1990, Schapire, Boosting

图九 Boosting算法(图片来源:百度百科)
1990年, Schapire最先构造出一种多项式级的算法,这就是最初的Boosting算法。一年后 ,Freund提出了一种效率更高的Boosting算法。但是,这两种算法存在共同的实践上的缺陷,那就是都要求事先知道弱学习算法学习正确的下限。
1995年,Freund和schapire改进了Boosting算法,提出了 AdaBoost (Adaptive Boosting)算法,该算法效率和Freund于1991年提出的 Boosting算法几乎相同,但不需要任何关于弱学习器的先验知识,因而更容易应用到实际问题当中。
Boosting方法是一种用来提高弱分类算法准确度的方法,这种方法通过构造一个预测函数系列,然后以一定的方式将他们组合成一个预测函数。他是一种框架算法,主要是通过对样本集的操作获得样本子集,然后用弱分类算法在样本子集上训练生成一系列的基分类器。
1995, Vapnik and Cortes, Support Vector Machines (SVM)
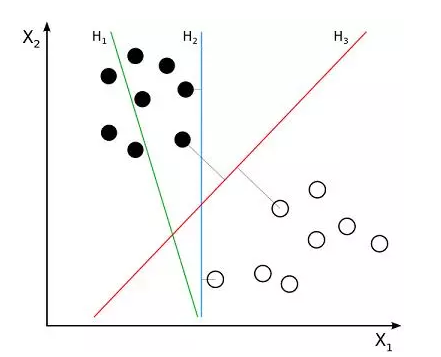
图十 支持向量机(图片来源:维基百科)
支持向量机的出现是机器学习领域的另一大重要突破,该算法具有非常强大的理论地位和实证结果。那一段时间机器学习研究也分为NN和SVM两派。然而,在2000年左右提出了带核函数的支持向量机后。SVM在许多以前由NN占据的任务中获得了更好的效果。此外,SVM相对于NN还能利用所有关于凸优化、泛化边际理论和核函数的深厚知识。因此SVM可以从不同的学科中大力推动理论和实践的改进。
而神经网络遭受到又一个质疑,通过Hochreiter等人1991年和Hochreiter等人在2001年的研究表明在应用BP算法学习时,NN神经元饱和后会出现梯度损失(gradient loss)的情况。简单地说,在一定数量的epochs训练后,NN会产生过拟合现象,因此这一时期NN与SVM相比处于劣势。
2001, Breiman, Random Forests(RF)
决策树模型由布雷曼博士在2001年提出,它是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一大分支——集成学习(Ensemble Learning)方法。随机森林的名称中有两个关键词,一个是“随机”,一个就是“森林”。“森林”我们很好理解,一棵叫做树,那么成百上千棵就可以叫做森林了,这样的比喻还是很贴切的,其实这也是随机森林的主要思想—集成思想的体现。
其实从直观角度来解释,每棵决策树都是一个分类器(假设现在针对的是分类问题),那么对于一个输入样本,N棵树会有N个分类结果。而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出,这就是一种最简单的 Bagging 思想。
1.5 爆发时期
2006, Hinton, Deep Learning
在机器学习发展分为两个部分,浅层学习(Shallow Learning)和深度学习(Deep Learning)。浅层学习起源上世纪20年代人工神经网络的反向传播算法的发明,使得基于统计的机器学习算法大行其道,虽然这时候的人工神经网络算法也被称为多层感知机,但由于多层网络训练困难,通常都是只有一层隐含层的浅层模型。
神经网络研究领域领军者Hinton在2006年提出了神经网络Deep Learning算法,使神经网络的能力大大提高,向支持向量机发出挑战。 2006年,机器学习领域的泰斗Hinton和他的学生Salakhutdinov在顶尖学术刊物《Scince》上发表了一篇文章,开启了深度学习在学术界和工业界的浪潮。
这篇文章有两个主要的讯息:1)很多隐层的人工神经网络具有优异的特征学习能力,学习得到的特征对数据有更本质的刻划,从而有利于可视化或分类;2)深度神经网络在训练上的难度,可以通过“逐层初始化”( layer-wise pre-training)来有效克服,在这篇文章中,逐层初始化是通过无监督学习实现的。
2015年,为纪念人工智能概念提出60周年,LeCun、Bengio和Hinton推出了深度学习的联合综述。
深度学习可以让那些拥有多个处理层的计算模型来学习具有多层次抽象的数据的表示。这些方法在许多方面都带来了显著的改善,包括最先进的语音识别、视觉对象识别、对象检测和许多其它领域,例如药物发现和基因组学等。深度学习能够发现大数据中的复杂结构。它是利用BP算法来完成这个发现过程的。BP算法能够指导机器如何从前一层获取误差而改变本层的内部参数,这些内部参数可以用于计算表示。深度卷积网络在处理图像、视频、语音和音频方面带来了突破,而递归网络在处理序列数据,比如文本和语音方面表现出了闪亮的一面。
当前统计学习领域最热门方法主要有deep learning和SVM(supportvector machine),它们是统计学习的代表方法。可以认为神经网络与支持向量机都源自于感知机。
神经网络与支持向量机一直处于“竞争”关系。SVM应用核函数的展开定理,无需知道非线性映射的显式表达式;由于是在高维特征空间中建立线性学习机,所以与线性模型相比,不但几乎不增加计算的复杂性,而且在某种程度上避免了“维数灾难”。而早先的神经网络算法比较容易过训练,大量的经验参数需要设置;训练速度比较慢,在层次比较少(小于等于3)的情况下效果并不比其它方法更优。
神经网络模型貌似能够实现更加艰难的任务,如目标识别、语音识别、自然语言处理等。但是,应该注意的是,这绝对不意味着其他机器学习方法的终结。尽管深度学习的成功案例迅速增长,但是对这些模型的训练成本是相当高的,调整外部参数也是很麻烦。同时,SVM的简单性促使其仍然最为广泛使用的机器学习方式。
1.6 启示与未来的发展
人工智能机器学习是诞生于20世纪中叶的一门年轻的学科,它对人类的生产、生活方式产生了重大的影响,也引发了激烈的哲学争论。但总的来说,机器学习的发展与其他一般事物的发展并无太大区别,同样可以用哲学的发展的眼光来看待。
机器学习的发展并不是一帆风顺的,也经历了螺旋式上升的过程,成就与坎坷并存。其中大量的研究学者的成果才有了今天人工智能的空前繁荣,是量变到质变的过程,也是内因和外因的共同结果。
机器学习的发展诠释了多学科交叉的重要性和必要性。然而这种交叉不是简单地彼此知道几个名词或概念就可以的,是需要真正的融会贯通:
统计学家弗莱德曼早期从事物理学研究,他是优化算法大师,而且他的编程能力同样令人赞叹;
乔丹教授既是一流的计算机学家,又是一流的统计学家,而他的博士专业为心理学,他能够承担起建立统计机器学习的重任;
辛顿教授是世界最著名的认知心理学家和计算机科学家。虽然他很早就成就斐然,在学术界声名鹊起,但他依然始终活跃在一线,自己写代码。他提出的许多想法简单、可行又非常有效,被称为伟大的思想家。正是由于他的睿智和身体力行,深度学习技术迎来了革命性的突破。
…
深度学习的成功不是源自脑科学或认知科学的进展,而是因为大数据的驱动和计算能力的极大提升。可以说机器学习是由学术界、工业界、创业界(或竞赛界)等合力造就的。学术界是引擎,工业界是驱动,创业界是活力和未来。学术界和工业界应该有各自的职责和分工。学术界的职责在于建立和发展机器学习学科,培养机器学习领域的专门人才;而大项目、大工程更应该由市场来驱动,由工业界来实施和完成。
对于机器学习的发展前途,中科院数学与系统科学研究院陆汝铃老师在为南京大学周志华老师的《机器学习》一书作序时提出了六大问题,我觉得这些问题也许正是影响机器学习未来发展方向的基本问题,因此我摘录其中五个在此(有两个问题属于同一个主题,合并之):
-
问题一:在人工智能发展早期,机器学习的技术内涵几乎全部是符号学习,可是从二十世纪九十年代开始,统计机器学习有一匹黑马横空出世,迅速压倒并取代了符号学习的地位。人们可能会问,符号学习是否被彻底忽略了?他还能成为机器学习的研究对象吗?它是否能继续在统计学习的阴影里苟延残喘?
第一种观点:退出历史舞台——没有人抱有这种想法。
第二种观点:统计学习和符号学习结合起来——王珏教授认为,现在机器学习已经到了一个转折点,统计学习要想进入一个更高级的形式,就应该和知识相结合,否则就会停留于现状而止步不前。
第三种观点:符号学习还有翻身之日——Chandrasekaran教授认为机器学习并不会回到“河西”,而是随着技术的进步逐渐转向基本的认知科学。
-
问题二:统计机器学习的算法都是基于样本数据独立同分布的假设,但自然界现象千变万化,哪里有那么多独立同分布?那么“独立同分布”条件对于机器学习来说是必需的吗?独立同分布的不存在一定是不可逾越的障碍吗?
迁移学习也许会给问题的解决带来一丝曙光?
-
问题三:近年来出现了一些新的动向,比如深度学习。但他们真的代表机器学习新的方向吗?
包括周志华老师在内的一些学者认为深度学习掀起的热潮大过它本身的贡献,在理论和技术上并没有太多的创新,只不过硬件技术的革命使得人们能采用原来复杂度很高的算法,从而得到更精细的结果。
-
问题四:机器学习研究出现以来,我们看到的主要是从符号方法到统计方法的演变,用到的数学主要是概率统计。但是今天数学之大,就像大海,难道只有统计方法适合于在机器学习方面的应用?
目前流行学习已经“有点意思了”,但数学理论的介入程度远远不够,有待更多数学家参与,开辟新的模式、理论和方法。
-
问题五:大数据时代的出现,有没有给机器学习带来本质性的影响?
大数据时代给机器学习带来了前所未有的机遇,但是同样的统计、采样方法相较以前有什么本质不同吗?又从量变过渡到质变吗?数理统计方法有没有发生质的变化?大数据时代正在呼吁什么样的机器学习方法?哪些方法又是大数据研究的驱动而产生的呢?
2.机器学习基本概念
权威定义:
Arthur samuel: 在不直接针对问题进行编程的情况下,赋予计算机学习能力的一个研究领域。
Tom Mitchell: 对于某类任务T和性能度量P,如果计算机程序在T上以P衡量的性能随着经验E而自我完善,那么就称这个计算机程序从经验E学习。
其实随着学习的深入,慢慢会发现机器学习越来越难定义,因为涉及到的领域很广,应用也很广,现在基本成为计算机相关专业的标配,但是在实际的操作过程中,又慢慢会发现其实机器学习也是很简单的一件事,我们最的大部分事情其实就是两件事情,一个是分类,一个是回归。比如房价的预测、股价的预测等是回归问题,情感判别、信用卡是否发放等则是属于分类。现实的情况 一般是给我们一堆数据,我们根据专业知识和一些经验提取最能表达数据的特征,然后我们再用算法去建模,等有未知数据过来的时候我们就能够预测到这个是属于哪个类别或者说预测到是一个什么值以便作出下一步的决策。比如说人脸识别系统,目的是作为一个验证系统,可能是一个权限管理,如果是系统中的人则有权限否则没有权限,首先给到我们的数据是一堆人脸的照片,第一步要做的事情是对数据进行预处理,然后是提取人脸特征,最后选择算法比如说SVM或者RF等等,算法的最终选择设计到评价标准,这个后面具体讲,这样我们就建立了一个人脸识别的模型,当系统输入一张人脸,我们就能够知道他是不是在系统之中。机器学习的整个流程不过就这几步,最后不过就是参数寻优,包括现在如火如荼的机器学习。
当我们判断是否要使机器学习时,可以看看是不是以下的场景
-
人类不能手动编程;
-
人类不能很好的定义这个问题的解决方案是什么;
-
人类不能做i到的需要极度快速决策的系统;
-
大规模个性化服务系统;

3. 机器学习分类
3.1 监督式学习 Supervised Learning
在监督式学习下,每组训练数据都有一个标识值或结果值,如客户流失对应1,不流失对应0。在建立预测模型的时候,监督式学习建立一个学习过程,将预测的结果与训练数据的实际结果进行比较,不断的调整预测模型,直到模型的预测结果达到一个预期的准确率。
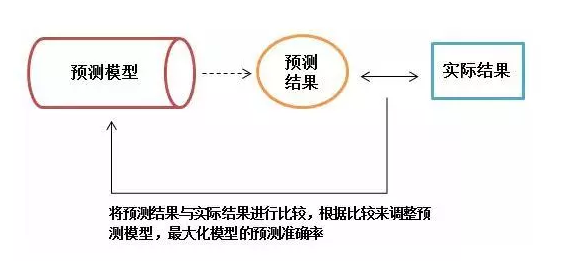
分类 Classification
-
K最近邻 K-Nearest Neighbor (KNN)
-
朴素贝叶斯 Naive Bayes
-
决策树 Decision Tree:C4.5、分类回归树 Classification And Regression Tree (CART)
-
支持向量机器 Support Vector Machine (SVM)
回归 Regression
-
线性回归 linear regression
-
局部加权回归 Locally weighted regression
-
逻辑回归 logistic Regression
-
逐步回归 stepwise regression
-
多元自适应回归样条法 multivariate adaptive regression splines
-
局部散点平滑估计 Locally estimated scatter plot smoothing ( LOESS )
-
岭回归 Ridge Regression
-
Least Absolute Shrinkage and Selection Operator ( LASSO )
-
弹性网络 Elastic Net
-
多项式回归 Polynomial Regression
排序 Rank
-
单文档分类 Pointwise:McRank
-
文档对方法(Pairwise):Ranking SVM、RankNet、Frank、RankBoost
-
文档列表方法(Listwise):AdaRank、SoftRank、LambdaMART
匹配学习
-
人工神经网络:感知神经网络 Perception Neural Network、反向传递 Back Propagation、Hopfield网络、自组织映射 Self-Organizing Map ( SOM )、学习矢量量化 Learning Vector Quantization ( LVQ )
3.2 半监督学习
在半监督学习方式下,训练数据有部分被标识,部分没有被标识,这种模型首先需要学习数据的内在结构,以便合理的组织数据来进行预测。算法上,包括一些对常用监督式学习算法的延伸,这些算法首先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测。如深度学习:
深度学习 Deep Learning
深度学习是 监督学习的匹配学习中人工神经网络延伸出来发展出来的。
-
受限波尔兹曼机 Restricted Boltzmann Machine ( RBM )
-
深度信念网络 Deep Belief Networks ( DBN )
-
卷积网络 Convolutional Network
-
栈式自编码 Stacked Auto-encoders
3.3 无监督学习 Unsupervised Learning
在非监督式学习中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。
聚类 Cluster
-
K均值 k-means
-
最大期望算法 Expectation Maximization ( EM )
-
降维方法 Dimensionality Reduction:主成分分析Principal Component Analysis ( PCA )、偏最小二乘回归 Partial Least Squares Regression ( PLS )、Sammon映射 Sammon Mapping、多维尺度分析 Multidimensional Scaling ( MDS )、投影寻踪 Projection Pursuit、RD
关联规则 Association Rule
-
Apriori
-
Eclat
3.4 强化学习 Reinforcement Learning
在之前的讨论中,我们总是给定一个样本x,然后给或者不给标识值或结果值(给了就是监督式学习,不给就是无监督式学习)。之后对样本进行拟合、分类、聚类或者降维等操作。然而对于很多序列决策或者控制问题,很难有这么规则的样本。比如,四足机器人的控制问题,刚开始都不知道应该让其动那条腿,在移动过程中,也不知道怎么让机器人自动找到合适的前进方向。
强化学习要解决的是这样的问题:一个能感知环境的自治agent,怎样通过学习选择能达到其目标的最优动作。这个很具有普遍性的问题应用于学习控制移动机器人,在工厂中学习最优操作工序以及学习棋类对弈等。当agent在其环境中做出每个动作时,施教者会提供奖励或惩罚信息,以表示结果状态的正确与否。例如,在训练agent进行棋类对弈时,施教者可在游戏胜利时给出正回报,而在游戏失败时给出负回报,其他时候为零回报。agent的任务就是从这个非直接的,有延迟的回报中学习,以便后续的动作产生最大的累积效应。
-
Q-Learning
-
时间差学习 Temporal difference learning
3.5 其他
集成算法
集成算法用一些相对较弱的学习模型独立地就同样的样本进行训练,然后把结果整合起来进行整体预测。
-
Boosting
-
Bootstrapped Aggregation ( Bagging )
-
AdaBoost
-
堆叠泛化 Stacked Generalization
-
梯度推进机 Gradient Boosting Machine ( GBM )
-
随机森林 Random Forest
4.机器学习发展10大趋势预测
“分析时代”目前仍处于起步阶段,它为我们带来众多值得期待且为之兴奋的构想与承诺。在今天的文章中,BigML公司副总裁AtakanCetinsoy将披露2017年中他眼中的机器学习技术及相关生态系统发展趋势。
每一年结束时,技术专家们总会着眼于新的十二个月,思考其熟知的技术方案将在下一阶段迎来怎样的变化趋势。在BigML公司,我们结合2016年中机器学习技术的发展与演变,尝试解析其在新一年内的未来前景。
首先需要强调的是,企业需要吹散围绕在机器学习概念周遭的炒作迷雾,探索将其切实引入自身业务体系的有效途径。更具体地讲,企业需要通过严谨决策立足内部环境选定平台,并逐步建立规模较小且易于实现的机器学习项目,从而尝试利用自有数据集。随着时间推移,此类增量型项目将带来积极的反馈,并最终实现决策自动化,甚至帮助敏捷性机器学习团队彻底改变其所在行业的运营常态。
按照惯例,我们首先回顾机器学习技术在实际应用层面的发展历程:
机器学习已经形成一种不可逆转的历史性趋势,我们需要立足于此考量如何进行跨部门日常事务处理并将自身业务与市场整体经济状况加以结合。
在36年的发展历程中,众多企业一直在努力消化、采用并从机器学习技术的发展进步与相关最佳实践中获益。然而,鲜有企业能够真正将其转化为自身业务优势。
出现了一大批所谓“新晋专家”,他们只读过几本相关书籍或者参加了几堂网络课程,就开始堂而皇之地借助廉价资本“改变”世界。与此同时,众多顶级科技企业则在尽可能“招募”真正了解机器学习技能的人才,希望借此为蓬勃发展的AI经济储备能量。
另外,相当一部分立足机器学习领域诞生的初创企业则胸怀“独角兽”雄心踏上征程,然而必须承认,他们自认为能够利用神奇的新型机器学习算法实现的通用型、低成本、可扩展解决方案往往只是种一厢情愿。
2017年,在经历了此前的一系列本可避免的挫折之后,我们预计机器学习生态系统将最终开始向正确的方向推进。
在开始讨论具体预测之前,还需要强调点:2016年是极为重要的一年,因为在这一年中全球最具价值的五家企业史无前例地全部由科技企业充当。这五家公司皆拥有几项共通性特征,其中包括大规模网络效应、以数据为中心的企业文化以及建立在尖端分析模式之上的新型增值服务经济思路。
更重要的是,这些企业一直在宣传其理念与意图,并将机器学习视为其未来进化的重要支点。随着优步及Airbnb等独角兽企业的加入,科技行业在世界经济中的主导地位很可能在未来几年中继续保持,而这也将受到世界经济大规模数字化转型浪潮的强势推动。
不过,这又提出了一个可能决定数万亿美元走向的新问题:传统企业(例如掌握着大量数据的非技术企业以及由大型企业部分解散并转化而成的小型技术厂商)该如何适应并成为这一新兴价值链中的组成部分?它们又该如何在生存之余,在新的时代下茁壮成长?
就目前来看,相当一部分企业都坚持以僵化且经验指导性思路理解商业智能系统、继续采用陈旧的工作站类传统基础、利用简单的回归模式统计系统运行状态,这意味着其无法捕捉到现实生活中反映出的具体趋势,更遑论准确预测用例的复杂性。
与此同时,这些企业面对着大量专有数据得不到充分利用的困境。根据麦肯锡全球研究院发布的《分析时代:数据驱动型世界下的竞争》报告所言,其曾在2011年报告中提到的现代分析技术至今仅实现了不足30%,这还不算过去五年来涌现的各种新型技术方案。
更糟糕的是,各行业间的数据技术发展态势呈现出严重的失衡现象(着眼于美国,医疗卫生行业的数字化技术采纳度低至10%,而智能手机领域则高达60%),这意味着已经出现了前所未有的分析能力与竞争水平分化态势。
尽管实际情况还达不到各大供应商及研究企业的宣传水平(例如‘认知计算’、‘机器智能’甚至是‘智能机器’等炒作性概念),但机器学习已经真正成为商业词汇中的重要组成部分,并为众多企业带来了广泛且可观的潜在发展空间。这种巨大的机遇意味着将有更多传统及初创企业在2017年开始自己的机器学习探索之旅。睿智的企业会努力从失败案例中汲取经验教训,并利用新型技术成果扩大自身竞争优势。然而考虑到人类在面对新兴事物时表现出的一贯愚蠢与保守态度,我们将以较为悲观的态度探讨以下十项发展趋势:
预测一:机器学习将成为实现“大数据”的重要途径
大数据运动中的种种教训还将反复重演,而技术专家们也将从中意识到只有将多种具备实用性的“大数据”解决方案加以结合方能实际其既定目标。
总体而言,“大数据”代表的是能够昭示未来的数据,就这么简单。Gartner公司最近已经在其炒作周期报告中将“大数据”条目剔除,这意味着其已经正式步入实施阶段。这一切都将高度强调分析能力的重要意义,特别是机器学习在引导客户利用智能化应用涉及数据技术相关项目中扮演的重要角色。另外,以往饱受诟病的样本分析方案将成为一类重要工具,帮助企业探索出此类应用场景下的新型预测性用例。
预测二:风险投资公司仍将积极为基于算法的初创企业提供资助
风险投资公司仍将继续处于摸索与学习状态,且整个学习过程相缓慢而艰难。风投将继续为具备亮相学术沉淀的算法类初创企业提供资助,而无视由其带来的种种误导性甚至幻想性言论。例如将机器学习作为深度学习的代名词,而完全无视机器学习算法与机器学习模型乃至模型训练与已训练模型预测结果之间的巨大差别。对于相关学科的深入理解将作为一项历史性难题存在,且整体投资行业对此的重视程度依然不够。不过值得肯定的是,已经有一小部分风投类企业开始意识到机器学习发展所将带来的巨大发展平台。
预测三:机器学习人才仍将成为炙手可热的稀缺资源
媒体对于AI及机器学习技术的鼓吹与渲染,将使得相关技术人才继续成为市场的宠儿,而相关投资将被大量集中在年轻学者手中。不过残酷的现实告诉我们,绝大多数算法并不具备广泛适用性,而且其中相当一部分仅仅是在原有基础上做出了少许改进。作为直接结果,大多数机器学习算法都将仅被视为噱头以及疯狂招募相关技术人才的理由。在部分最糟糕的场景下,买方甚至不具备明确的分析技术发展思路,而仅仅是像追随任何一种时代潮流那样关注AI/机器学习技术。
预测四:大多数机器学习相关项目仅停留在PPT演示阶段,而无法带来理想结果
传统企业的高管层将积极雇用咨询公司以帮助自身建立起自上而下的分析战略以及/或者制定复杂的“大数据”技术组件构成方案,然而他们对于洞察结论的可行性以及确切的投资回报水平并没有正确的认识。其中部分原因在于实施数据分析技术的正确数据结构及灵活的计算基础设施当下并不难获取,而且经过36年的持续积累,如今机器学习在廉价计算资源的支持下已经不再是高不可攀的实验室产物。

预测五:深度学习在商业领域的成功范例将寥寥可数
深度学习的各类知名研究成果,例如AlphaGo将继续吸引媒体关注。然而,以语音识别与图像认知为代表的实际应用方案才是真正的发展驱动力,其将帮助这一技术在企业环境下机器学习场景中发挥切实作用。难于解释、高水平技术专家稀缺、高度依赖大规模训练数据集以及极高的计算资源配置需求都将制约深度学习在2017年年内的发展态势。
就目前的情况看,机器学习技术与马球运动颇有几分相似,其能够为您带来与富豪及名人交流的机会,亦能够让您的企业瞬间逼格爆棚,但随之而来的还有昂贵的马术训练服务、保养成本、设备购置开销以及昂贵的俱乐部会费。因此相较于缺少显著研究突破上与独特优势的深度学习,企业通常能够通过关注强化学习及机器学习技术获得更快且更具现实意义的结果。
预测六:基于不确定性的原因与规划性探索将推动机器学习走向新高度
机器学习本身只是AI的一小部分。相当一部分初创企业开始立足不确定性为相关原因与规划性探索工作提供研究应用,而这将切实帮助我们在模式认知之外找到新的技术拓展空间。Facebook公司的MarkZuckerberg就在损害一年的AI/机器学习研究工作之后,拿出了他自己的个人智能化助手“Jarvis”——其基本特性与《钢铁侠》电影中的虚构智能管家大体类似。
预测七:尽管机器学习的部署范围持续扩大,但人类仍将在决策工作中扮演核心角色
部分企业将初步部署速度更快且采取循证性决策方式的机器学习方案,但人类仍将在决策工作中扮演核心角色。智能化应用的早期落伍将集中在特定行业内,但差异化监管框架的存在以及严格失衡的分析能力状况将在经济层面给创新性管理方法、竞争压力、复杂性客户需求、高质量体验及其它一些价值链因素带来相互矛盾的指引意见。
尽管如今机器学习乃至人工智能改变未来的言论甚嚣尘上,但冷静的技术领导者非常清楚,真正的智能系统还需要很长时间才会真正出现。与此同时,企业将慢慢学会信任自己的模型及其预测结论,并意识到此类方案确实能够在多种任务领域带来超越人类的表现。
预测八:敏捷性机器学习将悄然成为AI营销中的主力军
更具现实意义且更为敏捷的机器学习采用方式将悄然在新的一年中占据主导地位。实施团队乐于亲自动手并充分利用丰富的企业数据储备,同时亦能够完全绕过“大数据”相关炒作宣传。他们更为务实,希望利用最具针对性与适用性的预测性手段通过成熟的算法配合小规模采样数据解决问题。
在这一过程中,他们将逐步建立对自身分析能力的信心,在实际产品中部署相关方案,同时添加更多可行用例。由于不再受到数据访问问题与部署工具复杂性的制约,他们能够真正利用数据技术提升核心业务,同时积极尝试风险与回报更高的实验性手段,考虑以预测性用例作为全新品牌营收来源的实现途径。
预测九:MLaaS平台将成为传统企业中机器学习采用工作的“AI主干”
MLaaS平台将在加速敏捷性机器学习实践领域成为“AI主干”。以此为基础,以MLaaS基础设施为根基的新一波应用浪潮将令商业性机器学习方案的实现成本进一步降低,特别是通过以下几种方式实现机器学习“民主化”:
通过消除供应商合约复杂性或者前期投入额度显著降低成本。
提供囊括大量高效算法的预配置框架。
以抽象化方式帮助最终用户摆脱由基础设施设置及管理带来的复杂性因素。
通过RESTAPI及捆绑包提供轻松易行的集成、工作流自动化与部署选项。
预测十:无论是否拥有充足的数据科学家,开发者都将不断向所在企业引入更多机器学习因素
在新的一年中,开发者们将积极投向至机器学习阵营当中——无论企业是否已经具备充足的数据科学家及其他相关人才储备。开发者们将立足于MLaaS平台快速构建并扩展此类应用,并借此对高难度细节问题进行抽象及剥离(例如集群配置与管理、任务队列以及监控与分发等)。“即服务”类方案的普及将允许开发者仅通过精心设计与良好记录的API即可实现机器学习技术应用,而不再需要了解LR(1)解析器以编译并执行其Java代码,或者掌握信息增益或威尔逊评级机制以实现基于决策树的预测性用例。
目前,我们仍处于“分析时代”的早期发展阶段,因此大家应当对光明的未来保持振奋的心态,而非被过去的一些小挫折所打倒。虽然我们在本篇文章中提出了不少相当悲观的预测观点,但这纯粹是为了帮助被兴奋冲昏头脑的朋友们冷静下来,意识到业务成功、数学奥秘、软件与管理最佳实践以及数据科学实现能力之间尚待跨越的鸿沟。
注:上述十大预测主要基于2017年前后给出,到2022年为止,有些如预测所见,有些发展的轨迹却不近相同,未来进一步发展趋势能够从中窥见一些,但仁者见仁智者见智,未来还在期待中......

