
- 1【路径规划】基于强化学习Q-Learing实现栅格地图路径规划matlab源码_强化学习移动机器人路径规划
- 2Vue | Element UI Plus 完美解决el-dialog双滚动条、页面抖动问题_element plus 弹窗模态框有滚动条
- 3新版PyCharm Conda环境找不到可执行文件_pycharm2024找不到conda的exe
- 4jenkins+gitlab自动化部署springboot项目_jenkins 2.4
- 5单片机模拟IIC和SPI: 调试RTC(RX8010) 和Flash(GD25Q128)
- 6Springboot+Vue项目-基于Java+MySQL的校园二手书交易平台系统(附源码+演示视频+LW)
- 7逻辑卷管理-LVM
- 8从单个节点到集群:OpenTSDB集群设计与部署_opentsdb部署
- 9A*算法弊端及解决思路_为什么调用a*算法两次就会报异常
- 10电子科大~数据库系统原理与开发期末复习完整版_电子科技大学数据库期末复习
NLP(三十四)使用keras-bert实现序列标注任务_基于bert的半自动标注
赞
踩
对于不同的NLP任务,使用BERT等预训练模型进行微调无疑是使用它们的最佳方式。在网上已经有不少的项目,或者使用TensorFlow,或者使用Keras,或者使用PyTorch对BERT进行微调。本系列文章将致力于应用keras-bert对BERT进行微调,完成基础的NLP任务,比如文本多分类、文本多标签分类以及序列标注等。
keras-bert是Python的第三方模块,它方便我们使用Keras来调用BERT,借助几行代码就可以轻松地完成模型构建,能依据不同的文本任务进行模型训练,获得不错的效果。
本文将介绍如何keras-bert实现序列标注任务。
项目结构
本项目结构如下:
所使用的Python第三方模块如下:
keras_bert==0.83.0
Keras==2.2.4
seqeval==0.0.10
keras_contrib==2.0.8
matplotlib==3.3.1
numpy==1.16.4
Flask==1.1.2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
代码分析
在util.py脚本中,我们设置了训练集和测试集的路径以及模型参数,代码如下:
# -*- coding: utf-8 -*-
# 数据相关的配置
event_type = "example"
train_file_path = "./data/%s.train" % event_type
test_file_path = "./data/%s.test" % event_type
# 模型相关的配置
MAX_SEQ_LEN = 128 # 输入的文本最大长度
BATCH_SIZE = 32 # 模型训练的BATCH SIZE
EPOCH = 10 # 模型训练的轮次
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
数据集的格式为BIO标注序列,每个样本用空行隔开,每行为一个字符加标签,example数据集(人民日报实体识别数据集)格式示例如下:
海 O 钓 O 比 O 赛 O 地 O 点 O 在 O 厦 B-LOC 门 I-LOC 与 O 金 B-LOC 门 I-LOC 之 O 间 O 的 O 海 O 域 O 。 O

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
load_data.py为数据读取脚本,代码如下:
# -*- coding: utf-8 -*- import json from util import train_file_path, event_type # 读取数据集 def read_data(file_path): # 读取数据集 with open(file_path, "r", encoding="utf-8") as f: content = [_.strip() for _ in f.readlines()] # 读取空行所在的行号 index = [-1] index.extend([i for i, _ in enumerate(content) if ' ' not in _]) index.append(len(content)) # 按空行分割,读取原文句子及标注序列 sentences, tags = [], [] for j in range(len(index)-1): sent, tag = [], [] segment = content[index[j]+1: index[j+1]] for line in segment: sent.append(line.split()[0]) tag.append(line.split()[-1]) sentences.append(''.join(sent)) tags.append(tag) # 去除空的句子及标注序列,一般放在末尾 sentences = [_ for _ in sentences if _] tags = [_ for _ in tags if _] return sentences, tags # 读取训练集数据 # 将标签转换成id def label2id(): _, train_tags = read_data(train_file_path) # 标签转换成id,并保存成文件 unique_tags = [] for seq in train_tags: for _ in seq: if _ not in unique_tags and _ != "O": unique_tags.append(_) label_id_dict = {"O": 0} label_id_dict.update(dict(zip(unique_tags, range(1, len(unique_tags)+1)))) with open("%s_label2id.json" % event_type, "w", encoding="utf-8") as g: g.write(json.dumps(label_id_dict, ensure_ascii=False, indent=2)) if __name__ == '__main__': label2id()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
以example.train为例,运行上述脚本,会生成标签文件example_label2id.json,如下:
{
"O": 0,
"B-LOC": 1,
"I-LOC": 2,
"B-PER": 3,
"I-PER": 4,
"B-ORG": 5,
"I-ORG": 6
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
model.py为模型结构脚本,代码如下:
# -*- coding: utf-8 -*- import json from keras.layers import * from keras.models import * from keras.optimizers import * from keras_bert import load_trained_model_from_checkpoint from keras_contrib.layers import CRF from keras_contrib.losses import crf_loss from keras_contrib.metrics import crf_accuracy from util import event_type # 创建BERT-BiLSTM-CRF模型 class BertBilstmCRF: def __init__(self, max_seq_length, lstm_dim): self.max_seq_length = max_seq_length self.lstmDim = lstm_dim self.label = self.load_label() # 抽取的标签 def load_label(self): label_path = "./{}_label2id.json".format(event_type) with open(label_path, 'r', encoding='utf-8') as f_label: label = json.loads(f_label.read()) return label # 模型 def create_model(self): model_path = "./chinese_L-12_H-768_A-12/" bert = load_trained_model_from_checkpoint( model_path + "bert_config.json", model_path + "bert_model.ckpt", seq_len=self.max_seq_length ) # make bert layer trainable for layer in bert.layers: layer.trainable = True x1 = Input(shape=(None,)) x2 = Input(shape=(None,)) bert_out = bert([x1, x2]) lstm_out = Bidirectional(LSTM(self.lstmDim, return_sequences=True, dropout=0.2, recurrent_dropout=0.2))(bert_out) crf_out = CRF(len(self.label), sparse_target=True)(lstm_out) model = Model([x1, x2], crf_out) model.summary() model.compile( optimizer=Adam(1e-4), loss=crf_loss, metrics=[crf_accuracy] ) return model
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
模型为BERT+BiLSTM+CRF,其中对BERT进行微调,模型结构(以example数据集为例)如下:
__________________________________________________________________________________________________ Layer (type) Output Shape Param # Connected to ================================================================================================== input_3 (InputLayer) (None, None) 0 __________________________________________________________________________________________________ input_4 (InputLayer) (None, None) 0 __________________________________________________________________________________________________ model_5 (Model) multiple 101382144 input_3[0][0] input_4[0][0] __________________________________________________________________________________________________ bidirectional_2 (Bidirectional) (None, None, 200) 695200 model_5[1][0] __________________________________________________________________________________________________ crf_2 (CRF) (None, None, 7) 1470 bidirectional_2[0][0] ================================================================================================== Total params: 102,078,814 Trainable params: 102,078,814 Non-trainable params: 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
数据集介绍
本文将会对三个实体识别的数据集进行测试,以下是三个数据集的简单介绍。
- 人民日报命名实体识别数据集(example.train 28046条数据和example.test 4636条数据),共3种标签:地点(LOC), 人名(PER), 组织机构(ORG)
- 时间识别数据集(time.train 1700条数据和time.test 300条数据),共1种标签:TIME
- CLUENER细粒度实体识别数据集(cluener.train 10748条数据和cluener.test 1343条数据),共10种标签:地址(address),书名(book),公司(company),游戏(game),政府(goverment),电影(movie),姓名(name),组织机构(organization),职位(position),景点(scene)
模型训练
模型训练的脚本model_train.py的代码如下:
# -*- coding: utf-8 -*- import json import numpy as np import matplotlib.pyplot as plt from keras.preprocessing.sequence import pad_sequences from keras.callbacks import EarlyStopping from keras.callbacks import ReduceLROnPlateau from keras_bert import Tokenizer from util import event_type from util import MAX_SEQ_LEN, BATCH_SIZE, EPOCH, train_file_path, test_file_path from load_data import read_data from model import BertBilstmCRF # 读取label2id字典 with open("{}_label2id.json".format(event_type), "r", encoding="utf-8") as h: label_id_dict = json.loads(h.read()) id_label_dict = {v: k for k, v in label_id_dict.items()} # 载入数据 config_path = './chinese_L-12_H-768_A-12/bert_config.json' checkpoint_path = './chinese_L-12_H-768_A-12/bert_model.ckpt' dict_path = './chinese_L-12_H-768_A-12/vocab.txt' token_dict = {} with open(dict_path, 'r', encoding='utf-8') as reader: for line in reader: token = line.strip() token_dict[token] = len(token_dict) class OurTokenizer(Tokenizer): def _tokenize(self, text): R = [] for c in text: if c in self._token_dict: R.append(c) else: R.append('[UNK]') # 剩余的字符是[UNK] return R tokenizer = OurTokenizer(token_dict) # 预处理输入数据 def PreProcessInputData(text): word_labels = [] seq_types = [] for sequence in text: code = tokenizer.encode(first=sequence, max_len=MAX_SEQ_LEN) word_labels.append(code[0]) seq_types.append(code[1]) return word_labels, seq_types # 预处理结果数据 def PreProcessOutputData(text): tags = [] for line in text: tag = [0] for item in line: tag.append(int(label_id_dict[item.strip()])) tag.append(0) tags.append(tag) pad_tags = pad_sequences(tags, maxlen=MAX_SEQ_LEN, padding="post", truncating="post") result_tags = np.expand_dims(pad_tags, 2) return result_tags if __name__ == '__main__': # 读取训练集和测试集数据 input_train, result_train = read_data(train_file_path) input_test, result_test = read_data(test_file_path) for sent, tag in zip(input_train[:10], result_train[:10]): print(sent, tag) for sent, tag in zip(input_test[:10], result_test[:10]): print(sent, tag) # 训练集 input_train_labels, input_train_types = PreProcessInputData(input_train) result_train = PreProcessOutputData(result_train) # 测试集 input_test_labels, input_test_types = PreProcessInputData(input_test) result_test = PreProcessOutputData(result_test) early_stopping = EarlyStopping(monitor='val_loss', min_delta=0.0001, patience=3, verbose=1, mode='auto') reduce_lr = ReduceLROnPlateau(monitor='val_loss', min_delta=0.0004, patience=2, factor=0.1, min_lr=1e-6, mode='auto', verbose=1) model = BertBilstmCRF(max_seq_length=MAX_SEQ_LEN, lstm_dim=64).create_model() history = model.fit(x=[input_train_labels, input_train_types], y=result_train, batch_size=BATCH_SIZE, epochs=EPOCH, validation_data=[[input_test_labels, input_test_types], result_test], verbose=1, callbacks=[early_stopping, reduce_lr], shuffle=True) # 保存模型 model.save("{}_ner.h5".format(event_type)) # 绘制loss和acc图像 plt.subplot(2, 1, 1) epochs = len(history.history['loss']) plt.plot(range(epochs), history.history['loss'], label='loss') plt.plot(range(epochs), history.history['val_loss'], label='val_loss') plt.legend() plt.subplot(2, 1, 2) epochs = len(history.history['crf_accuracy']) plt.plot(range(epochs), history.history['crf_accuracy'], label='crf_accuracy') plt.plot(range(epochs), history.history['val_crf_accuracy'], label='val_crf_accuracy') plt.legend() plt.savefig("%s_loss_acc.png" % event_type)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
模型使用的预训练模型为BERT中文预训练文件:chinese_L-12_H-768_A-12。
分别对上述三个数据集进行模型训练,结果汇总如下:
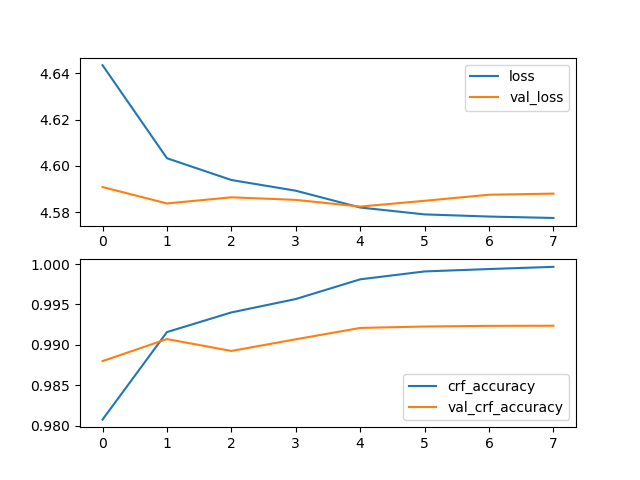
人民日报命名实体识别数据集
模型参数:MAX_SEQ_LEN=128, BATCH_SIZE=32, EPOCH=10
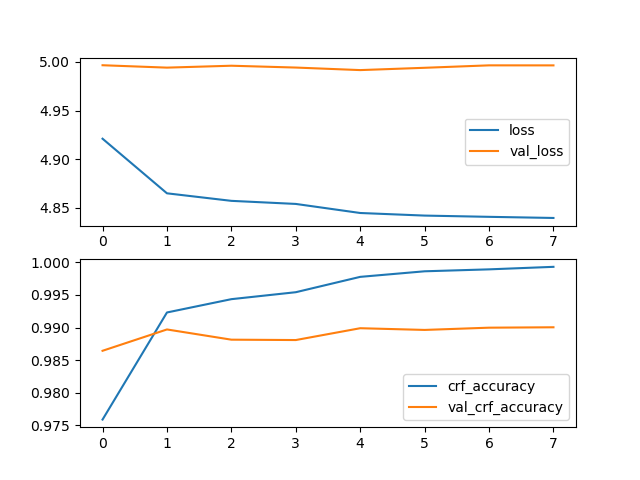
时间识别数据集
模型参数:MAX_SEQ_LEN=256, BATCH_SIZE=8, EPOCH=10
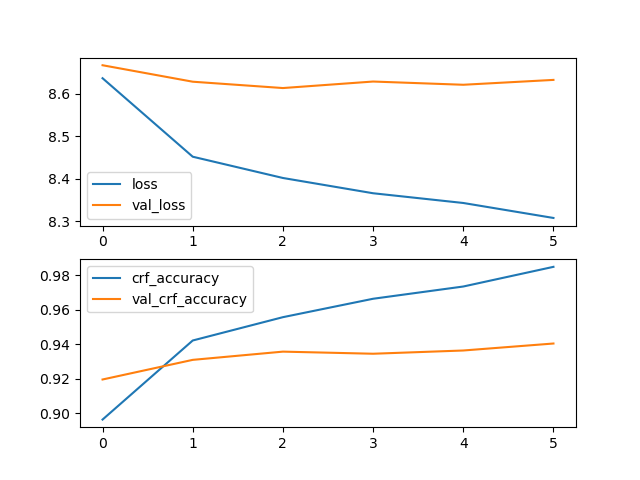
CLUENER细粒度实体识别数据集
模型参数:MAX_SEQ_LEN=128, BATCH_SIZE=32, EPOCH=10
模型评估
模型评估脚本model_evaluate.py脚本的代码如下:
# -*- coding: utf-8 -*- # 利用seqeval模块对序列标注的结果进行评估 import numpy as np from keras.models import load_model from keras_bert import get_custom_objects from keras_contrib.layers import CRF from keras_contrib.losses import crf_loss from keras_contrib.metrics import crf_accuracy from seqeval.metrics import classification_report from load_data import read_data from util import event_type, test_file_path from model_train import PreProcessInputData, id_label_dict custom_objects = get_custom_objects() for key, value in {'CRF': CRF, 'crf_loss': crf_loss, 'crf_accuracy': crf_accuracy}.items(): custom_objects[key] = value model = load_model("%s_ner.h5" % event_type, custom_objects=custom_objects) # 对单句话进行预测 def predict_single_sentence(text): # 测试句子 word_labels, seq_types = PreProcessInputData([text]) # 模型预测 predicted = model.predict([word_labels, seq_types]) y = np.argmax(predicted[0], axis=1) predict_tag = [id_label_dict[_] for _ in y] return predict_tag[1:-1] if __name__ == '__main__': # 读取测试集数据 input_test, result_test = read_data(test_file_path) for sent, tag in zip(input_test[:10], result_test[:10]): print(sent, tag) # 测试集 i = 1 true_tag_list = [] pred_tag_list = [] for test_text, true_tag in zip(input_test, result_test): print("Predict %d samples" % i) pred_tag = predict_single_sentence(text=test_text) true_tag_list.append(true_tag) if len(true_tag) <= len(pred_tag): pred_tag_list.append(pred_tag[:len(true_tag)]) else: pred_tag_list.append(pred_tag+["O"]*(len(true_tag)-len(pred_tag))) i += 1 print(classification_report(true_tag_list, pred_tag_list, digits=4))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
分别对上述三个数据集进行模型评估(模型参数同上),结果汇总如下:
- 人民日报命名实体识别数据集
precision recall f1-score support
LOC 0.9330 0.8986 0.9155 3658
ORG 0.8881 0.8902 0.8891 2185
PER 0.9692 0.9469 0.9579 1864
micro avg 0.9287 0.9079 0.9182 7707
macro avg 0.9291 0.9079 0.9183 7707
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 时间识别数据集
precision recall f1-score support
TIME 0.8428 0.8753 0.8587 441
micro avg 0.8428 0.8753 0.8587 441
macro avg 0.8428 0.8753 0.8587 441
- 1
- 2
- 3
- 4
- 5
- CLUENER细粒度实体识别数据集
precision recall f1-score support
name 0.8476 0.8758 0.8615 451
scene 0.6569 0.6734 0.6650 199
position 0.7455 0.7788 0.7618 425
organization 0.7377 0.7849 0.7606 344
game 0.7423 0.8432 0.7896 287
address 0.6070 0.6236 0.6152 364
company 0.7264 0.7978 0.7604 366
movie 0.7687 0.7533 0.7609 150
government 0.7860 0.8279 0.8064 244
book 0.8041 0.7829 0.7933 152
micro avg 0.7419 0.7797 0.7603 2982
macro avg 0.7420 0.7797 0.7601 2982
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
可以看到,BERT+BiLSTM+CRF(对BERT进行微调)的模型效果是相当不错的,在某种程序上是可以作为baseline的。
模型预测
模型预测脚本model_predict.py的脚本代码如下:
# -*- coding: utf-8 -*- import numpy as np from pprint import pprint from keras.models import load_model from keras_bert import get_custom_objects from keras_contrib.layers import CRF from keras_contrib.losses import crf_loss from keras_contrib.metrics import crf_accuracy from util import event_type from model_train import PreProcessInputData, id_label_dict # 将BIO标签转化为方便阅读的json格式 def bio_to_json(string, tags): item = {"string": string, "entities": []} entity_name = "" entity_start = 0 iCount = 0 entity_tag = "" for c_idx in range(min(len(string), len(tags))): c, tag = string[c_idx], tags[c_idx] if c_idx < len(tags)-1: tag_next = tags[c_idx+1] else: tag_next = '' if tag[0] == 'B': entity_tag = tag[2:] entity_name = c entity_start = iCount if tag_next[2:] != entity_tag: item["entities"].append({"word": c, "start": iCount, "end": iCount + 1, "type": tag[2:]}) elif tag[0] == "I": if tag[2:] != tags[c_idx-1][2:] or tags[c_idx-1][2:] == 'O': tags[c_idx] = 'O' pass else: entity_name = entity_name + c if tag_next[2:] != entity_tag: item["entities"].append({"word": entity_name, "start": entity_start, "end": iCount + 1, "type": entity_tag}) entity_name = '' iCount += 1 return item # 加载训练好的模型 custom_objects = get_custom_objects() for key, value in {'CRF': CRF, 'crf_loss': crf_loss, 'crf_accuracy': crf_accuracy}.items(): custom_objects[key] = value model = load_model("%s_ner.h5" % event_type, custom_objects=custom_objects) # 测试句子 text = "经过工作人员两天的反复验证、严密测算,记者昨天从上海中心大厦得到确认:被誉为上海中心大厦“定楼神器”的阻尼器,在8月10日出现自2016年正式启用以来的最大摆幅。" word_labels, seq_types = PreProcessInputData([text]) # 模型预测 predicted = model.predict([word_labels, seq_types]) y = np.argmax(predicted[0], axis=1) tag = [id_label_dict[_] for _ in y] # 输出预测结果 result = bio_to_json(text, tag[1:-1]) pprint(result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
在新样本上进行预测,输出的效果也很不错,示例预测结果如下:
- 人民日报命名实体识别数据集
{'entities': [{'end': 17, 'start': 16, 'type': 'LOC', 'word': '欧'},
{'end': 50, 'start': 48, 'type': 'LOC', 'word': '英国'},
{'end': 63, 'start': 62, 'type': 'LOC', 'word': '欧'},
{'end': 72, 'start': 69, 'type': 'PER', 'word': '卡梅伦'},
{'end': 78, 'start': 73, 'type': 'PER', 'word': '特雷莎·梅'},
{'end': 86, 'start': 85, 'type': 'LOC', 'word': '欧'},
{'end': 102, 'start': 95, 'type': 'PER', 'word': '鲍里斯·约翰逊'}],
'string': '当2016年6月24日凌晨,“脱欧”公投的最后一张选票计算完毕,占投票总数52%的支持选票最终让英国开始了一段长达4年的“脱欧”进程,其间卡梅伦、特雷莎·梅相继离任,“脱欧”最终在第三位首相鲍里斯·约翰逊任内完成。'}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
{'entities': [{'end': 6, 'start': 0, 'type': 'ORG', 'word': '台湾“立法院'},
{'end': 30, 'start': 29, 'type': 'LOC', 'word': '台'},
{'end': 38, 'start': 35, 'type': 'PER', 'word': '蔡英文'},
{'end': 66, 'start': 64, 'type': 'LOC', 'word': '台湾'}],
'string': '台湾“立法院”“莱猪(含莱克多巴胺的猪肉)”表决大战落幕,台当局领导人蔡英文24日晚在脸书发文宣称,“开放市场的决定,将会是未来台湾国际经贸走向世界的关键决定”。'}
- 1
- 2
- 3
- 4
- 5
{'entities': [{'end': 9, 'start': 7, 'type': 'LOC', 'word': '印度'},
{'end': 14, 'start': 12, 'type': 'LOC', 'word': '南海'},
{'end': 27, 'start': 25, 'type': 'LOC', 'word': '印度'},
{'end': 30, 'start': 28, 'type': 'LOC', 'word': '越南'},
{'end': 45, 'start': 43, 'type': 'LOC', 'word': '印度'},
{'end': 49, 'start': 47, 'type': 'PER', 'word': '莫迪'},
{'end': 53, 'start': 51, 'type': 'LOC', 'word': '南海'},
{'end': 90, 'start': 88, 'type': 'LOC', 'word': '南海'}],
'string': '最近一段时间,印度政府在南海问题上接连发声。在近期印度、越南两国举行的线上总理峰会上,印度总理莫迪声称南海行为准则“不应损害该地区其他国家或第三方的利益”,两国总理还强调了所谓南海“航行自由”的重要性。'}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 时间识别数据集
{'entities': [{'end': 8, 'start': 0, 'type': 'TIME', 'word': '去年11月30日'}],
'string': '去年11月30日,李先生来到茶店子东街一家银行取钱,准备购买家具。输入密码后,'}
- 1
- 2
{'entities': [{'end': 19, 'start': 10, 'type': 'TIME', 'word': '上世纪80年代之前'},
{'end': 24, 'start': 20, 'type': 'TIME', 'word': '去年9月'},
{'end': 47, 'start': 45, 'type': 'TIME', 'word': '3年'}],
'string': '苏北大量农村住房建于上世纪80年代之前。去年9月,江苏省决定全面改善苏北农民住房条件,计划3年内改善30万户,作为决胜全面建成小康社会补短板的重要举措。'}
- 1
- 2
- 3
- 4
{'entities': [{'end': 8, 'start': 6, 'type': 'TIME', 'word': '两天'},
{'end': 23, 'start': 21, 'type': 'TIME', 'word': '昨天'},
{'end': 61, 'start': 56, 'type': 'TIME', 'word': '8月10日'},
{'end': 69, 'start': 64, 'type': 'TIME', 'word': '2016年'}],
'string': '经过工作人员两天的反复验证、严密测算,记者昨天从上海中心大厦得到确认:被誉为上海中心大厦“定楼神器”的阻尼器,在8月10日出现自2016年正式启用以来的最大摆幅。'}
- 1
- 2
- 3
- 4
- 5
- CLUENER细粒度实体识别数据集
{'entities': [{'end': 5, 'start': 0, 'type': 'organization', 'word': '四川敦煌学'},
{'end': 13, 'start': 11, 'type': 'scene', 'word': '丹棱'},
{'end': 44, 'start': 41, 'type': 'name', 'word': '胡文和'}],
'string': '四川敦煌学”。近年来,丹棱县等地一些不知名的石窟迎来了海内外的游客,他们随身携带着胡文和的著作。'}
- 1
- 2
- 3
- 4
{'entities': [{'end': 19, 'start': 14, 'type': 'address', 'word': '茶店子东街'}],
'string': '去年11月30日,李先生来到茶店子东街一家银行取钱,准备购买家具。输入密码后,'}
- 1
- 2
{'entities': [{'end': 3, 'start': 0, 'type': 'name', 'word': '罗伯茨'},
{'end': 10, 'start': 4, 'type': 'movie', 'word': '《逃跑新娘》'},
{'end': 23, 'start': 16, 'type': 'movie', 'word': '《理发师佐翰》'},
{'end': 38, 'start': 32, 'type': 'name', 'word': '亚当·桑德勒'}],
'string': '罗伯茨的《逃跑新娘》不相伯仲;而《理发师佐翰》让近年来顺风顺水的亚当·桑德勒首尝冲过1亿$'}
- 1
- 2
- 3
- 4
- 5
总结
本项目已经开源,Github地址为:https://github.com/percent4/keras_bert_sequence_labeling 。
后续将会继续介绍如何使用keras-bert实现文本多分类和文本多标签分类,欢迎大家关注~
最后,还想感谢一下所有致力于开源项目的同仁们,感谢你们的努力,感谢你们的付出,感谢你们的铺路。
2020年12月26日于上海浦东

