
- 1MongoDB性能最佳实践:硬件和操作系统配置_mongodb性能最佳实践:硬件和操作系统配置
- 2Python实现机器学习(下)— 数据预处理、模型训练和模型评估_python 建立模型和模型训练
- 3PLC工业网关,实现PLC联网
- 4keil5创建寄存器编程模板_怎么在keil里设定寄存器
- 5半天学会深度学习故障识别!从入门到发文!CNN,BiLSTM,GRU,LSTM,TCN和CNN-LSTM,CNN-GRU全家桶!_[链接]半天学会深度学习预测,从入门到发文!cnn,bilstm,gru,lstm,tcn和cnn-
- 6高可用 Prometheus:问题集锦_prometheus高可用方案
- 7Matlab无基础快速上手1(遗传算法框架)
- 8git修改远程仓库的分支名称_git修改远程仓库名称
- 9若依新建模块后接口404_ruoyi新增模块,系統接口404
- 10什么是数字化?为什么需要数字化?
POLAR DB for mysql_polardb java
赞
踩
POLARDB for MySQL 版评测及同类横向对比
一、前言
“在数据库的选择上,MySQL成为中国开发者的最爱。相比SQLServer相对保守的数据库特点,中国开发者更喜欢开放性的数据库,同时又考虑到价格问题,那么Oracle不菲的价格也挡住了很大一批开发者。由于开源、价格等因素,在数据库选择上,要么是低价、开源的MySQL,要么就是高大上的Oracle。——云栖社区《2017中国开发者调查报告》
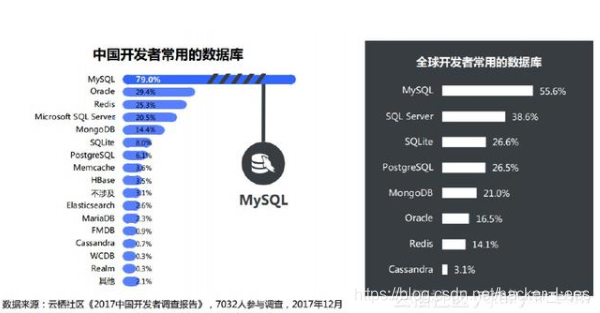
根据云栖社区《2017中国开发者调查报告》我们可以了解到在全球范围内特别是国内 MySQL 都有着非常高的使用率,有大量的产品和项目是依赖于 MySQL 作为关系型数据库的,因此在 MySQL 上进行进一步的优化和改造是大有可为的,于是便有了 MySQL 的衍生版包括有:MariaDB、Percona、AliSQL、PhxSQL 等等,但 MySQL 本身其实是一款“轻量级”数据库,相较 SQL Server 和 Oracle 等商业数据库其实是有所不足的。因此各类兼容 MySQL 生态的新型数据库开始出现。
2017年是各类新型数据库的落地年,各种NewSQL纷纷结束蛰伏期并开始商业化输出,特别是各类基于 MySQL 生态和兼容 MySQL 协议的新数据库产品也开始不断发展并开始商业输出,有包括在 OLTP 上进一步优化的 POLARDB、Aurora、X-DB等等,还有兼容 OLTP 和 OLAP 场景的 HTAP 上优化的 HybridDB、TiDB、BaikalDB 等等。
本文要将的主角是 —— POLARDB ,POLARDB 是在2017年9月发布并进入公测阶段的,并在18年4月结束公测正式进入商业阶段并不断发布新功能完善体验。值得一提的是同样也在17年10月腾讯云联合 PingCAP 发布基于 TiDB 的 HTAP 数据库,但截至发文依旧停留在测试阶段。
二、介绍
“POLARDB 是阿里云自研的全新一代云数据库,与 MySQL 100%兼容,性能最高提升至MySQL的6倍,满足企业级OLTP(在线事务处理)并兼顾结构化数据并发查询场景。既融合了商业数据库稳定可靠、高性能、可扩展的特征,又具有开源数据库简洁开放的优势,而成本只有商用数据库的 1/10。POLARDB采用存储和计算分离架构,能提供存储自动扩容、计算规格弹性升降、故障快速恢复和数据备份容灾服务。”
POLARDB 对 MySQL 进行了一定改造,MySQL 其实至发布以来就是基于单机开发的数据库,但是单机单节点势必是会遭遇性能瓶颈。于是乎,对于 MySQL 有了两个方向的改造。
一种是读写分离方案,因为在很多网站常见下其实大家走的读请求更多,就女士逛淘宝,看了非常多的商品可能才下那么一单甚至单都不下就添加了一个收藏。
三、通点举例
再介绍 POLARDB 的优越性之前,我们先看看已经是使用体验业内顶尖了的云数据库 MySQL 的一些痛点(友商的其他竞品痛点可能会更多~):
一、 当数据存储容量足够大的时候,备份成为了一件非常复杂的事情,费时费力。 二、 主备模式下,如果主库不出现问题并不会切换到备库, 备库仅仅起到了一个以防万一的作用平时并不能分担压力, 但是却不得不承担备库部分的成本。 三、 在读写分离场下,每添加一个只读库基本上就得购买一个一模一样的存储空间, 如果是一个1T的主库,那么两个只读库的成本就是2个1T。 四、 还是读写分离场景,一个上TB的数据库容量加个只读副本就需要一到两天时间,非常的麻烦。 五、 传统模式下为了保障数据库不会到达 100% 都会预留10%~20% 的容量作为阈值, 到了 80% 就进行升级或者扩容,其实这个时候那个预留的阈值是浪费了的,但是又不得不浪费。 六、 存储容量瓶颈,云计算厂商提供的关系型数据库基本上都有一个问题,那就是存储容量存在瓶颈, 当数据量达到 2T 左右的时候就已经是瓶颈了无法进一步上升, 而部分数据库应用场景恰恰就是需要大容量大存储的。 七、 性能瓶颈,当使用数据库遭遇性能瓶颈的时候其实是很糟心的, 如果是能通过升级配置解决的那倒还行, 如果是因为数据库软件本身的问题而更换数据库软件又意味着更高额的成本和风险。

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
四、产品特性
那么接下来介绍 POLARDB 的产品特性大家就会觉得舒服的多。
五、快照式备份
POLARDB 采用快照(Snapshot)形式的备份模式,并不是说将数据完完整整的备份一份,而是把备份数据的负载均分到创建Snapshot之后的实际数据写发生的时间窗口,以此实现备份、恢复的快速响应。
Snapshot是一种流行的基于存储块设备的备份方案。其本质是采用Copy-On-Write的机制,通过记录块设备的元数据变化,对于发生写操作的块设备进行写时复制,将写操作内容改动到新复制出的块设备上,来实现恢复到快照时间点的数据的目的。Snapshot是一个典型的基于时间以及写负载模型的后置处理机制。POLARDB提供基于Snapshot以及Redo log的机制,在按时间点恢复用户数据的功能上,比传统的全量数据结合Binlog增量数据的恢复方式更加高效。
实测的话,POLARDB的备份在分钟级,两三分钟就可以实现备份,相比云数据库小时级的等待可以说是体验非常棒了。在备份恢复的体验上POLARDB基本上和云数据库体验一致,按备份集和按时间点或者实例备份都可以。

六、FailOver 多活
POLARDB 默认购买就是一个主实例+只读实例形成 Active-Active 模式,其 FailOver 多活机制 可以在主实例宕机后立马选择一个只读实例“赋予”其读写能力,成为一个新的主实例。这样的模式下每一个只读实例都是“备库”,但是这个备库是参与工作的,并不存在浪费的现象。
得益于数据共享(后面会提到)的模式,只读节点的增加无需再进行数据的完全复制,共用一份全量数据和 Redo log,只需要同步元数据信息,支持基本的 MVCC,保证数据读取的一致性即可。这使得系统在主节点发生故障进行 Failover 时候,切换到只读节点的故障恢复时间能缩短到 30 秒以内。
七、分布式共享存储架构
POLARDB使用了第三代分布式共享存储架构,实现了计算节点(主要做SQL解析以及存储引擎计算的服务器)与存储节点(主要做数据块存储,数据库快照的服务器)的分离,提供了即时生效的可扩展能力和运维能力。

由上图我们可以看到,POLARDB通过将数据库文件以及 Redolog 等存放在共享存储设备(POLATSTORE)上而不是一个库一个本地存储。由于数据共享,只读实例的添加就再也不需要对数据进行完全复制了,而是共用一份全量数据和 Redo log,只需要同步元数据信息,这使得系统在主节点发生故障进行Failover时候,切换到只读节点的故障恢复时间能缩短到30秒以内(有没有发现这一句话FailOver那边提过)。系统的高可用能力进一步得到增强。而且,只读节点和主节点之间的数据延迟也可以降低到毫秒级别。
八、存储费用按量付费
POLARDB 的存储计费是按量付费的模式,也就是用多少扣多少,而不是预付费的模式。 云计算方法论中很重要的两点就是 弹性和按量 。相对于 ECS 集群的后付费和流量的按量后付费,数据库的按量后付费其实更可控和可预估,并不会出现天价费用,而且在数据库容量的扩容上用户也的确会遇到不好的体验(痛点那里有提到)。
所以用户会很愿意接受 POLARDB 的按量付费模式。再也不需要为那10%的扩容阈值浪费成本了。
九、大容量存储
POLARDB 支持高达 100TB 的存储容量,是云数据库 2T 容量上限的 50 倍。如果数据库的使用场景中的确需要超大存储再也无须担心了。
十、超高性能
POLARDB 作为一款 云原生 的数据库,在软件设计、产品架构、基础设施上都是顶尖的(如果用最顶尖的可能会违反广告法~)。 在性能上 POLARDB 远超 MySQL ,在特殊场景下最高可以实现6倍于 MySQL。
软件设计上的删繁就简,仅能更进一步。 下面那张图上面出现过,可以看到传统的MySQL下读写分离其实非常的繁琐,而且要写入大量的逻辑日志。POLARDB 在 MySQL 上进行了大量的修改包括有:使用共享存储物理复制、锁优化、日志提交优化、复制性能优化、读节点性能 等等。 同时 POLARDB 是基于 Docker 来隔离资源的,免去了一次虚拟化带来不必要的性能损耗

超规格底层硬件提供更高性能。3D Xpoint、NVMe、RDMA网卡这些名词都是在极客玩家中经常有听到的,它们都意味着超高的性能,同时也意味着高昂的价格。前文中有提到的 POLARSTORE 存储,就是基于这些极致的硬件设备而来的,但是阿里云将他们集成到 POLARSTORE 并以云计算的形式普惠输出,让大家可以用低廉的价格享受最前沿的技术和产品。
软硬件一体化设计,但是软件、硬件单方面的提升都无法成就 600% 于 MySQL 的性能表现,POLARDB 将全新的软件针对最酷的硬件进行优化实现软硬件一体,所以也是非常推荐大家可以阅读一下关于 PolarFS VLDB2018 的 Paper。
(猜测)未来的多主集群(Multi-Master) 机制,这个纯属我瞎猜,但是 POLARDB 大概率是会做的,那就是在多个可用区中创建多个读取主实例。这样一来,应用程序就可以在集群的多个数据库实例中读取和写入数据,极大的扩展分布式写的性能,这简直就是抢 DRDS 的饭碗嘛! 多主集群还会进一步提高高可用性,如果其中的一个主实例发生故障,集群中的其他实例将立即接替该实例,从而在发生实例故障甚至完全 AZ 故障时保持读写可用性,应该是可以做到将应用程序停机时间降到零。
十一、100% MySQL 兼容
POLARDB 针对 MySQL 生态 100% 兼容。 为什么这个都要拿出来说呢? 举两个例子:
一是在本文的第一张图中可以看到 Oracle 在中国有不小的份额并占据第二的位置,为什么?根据我对客户上云的一些经验来看,使用 Oracle 的客户大多都是政企客户,系统依赖 Oracle 有历史包袱,贸然迁出要面临不小的工作量而且出问题了势必会背锅,所以尽管有什么高度兼容 Oracle 的方案,95%也好 99% 也好,势必意味着不可预知的风险。
二是像谷歌的 CLOUD SPANNER 就不兼容已有的数据库生态,这就导致用户必须针对其全新开发而且未来势必对GCP有非常强的依赖,难以脱身。
因此 POLARDB 的 100% 兼容 MySQL 生态绝对是一大特性,让客户可以无痛的就使用高性能的数据库产品来解决现有遭遇的数据库性能、功能瓶颈或者说是使用期新特性来提高业务可靠性和稳定性。
十二、混淆OLTP和OLAP
POLARDB 的百TB级的存储和高规格软硬件带来的低延时一定程度上模糊了 OLTP 和 OLAP 的边界,在追求数据量实时性的场景下可以更好的进行 OLAP 分析,而避免要将数据库放到数仓然后再进行 OLAP 分析。
十三、性能测试
这里使用 SysBench 1.0.15 进行小规格版本的测试。
十四、测试准备
ECS 自建: 自建 MariaDB 10.1 (基于 MySQL 5.6), 底层服务器:计算型C5 2C4G 150G
SSD云盘
RDS 主实例: 云数据库 MySQL 版 5.6 高可用,2C4G 版
RDS 读写分离: 云数据库 MySQL 版 5.6 高可用,2C4G 版,主实例 + 1个 只读实例
POLARDB 主实例: POLARDB 2C4G ,主实例,不使用只读实例
POLARDB 读写分离: POLARDB 2C4G ,主实例 + 1个只读实例
由于 ECS 自建读写分离场景太费时费力了,就不创建了。
十五、测试命令
略
- 1
十六、测试结果
略
- 1
十七、横向“云”评测
目前阿里云平台上的 MySQL 兼容产品就有: 云数据库 MySQL 版(RDS)、分布式关系型数据库(DRDS)、云数据库POLARDB、HybridDB for MySQL (原PetaData)。 那么有人就会问,四款 MySQL 怎么选怎么用呢?
首先,我们可以看一下一张加入了 POLARDB 的阿里云数据库家族上云指导图:

大致的我们就可以知道,HybridDB for MySQL (原PetaData) 是专门用于 HTAP 场景的,有强 OLAP 需求还是得考虑 HybridDB,不过其为了 OLAP 兼容还是丧失了一些 MySQL 特性的,比如说不支持约束和一些高级特性。
接下来三个数据库当中,都是常见的 MySQL OLTP 场景,而且都可以添加只读实例,同质化很严重。
云数据库 MySQL 版依旧是最简单的 MySQL 目前支持的功能最多,但是性能略有不足,而且所有升级操作都是小时级的操作体验相对不太好。未来的话我认为更适合小规格数据库的入门级使用。
DRDS 和 POLARDB 都有分布式的属性,DRDS 的分布式是实例级的,POLARDB 是共享分布式存储。
DRDS 是集合多台 RDS 的性能来提升性能避免单台数据库的性能瓶颈,适合非常大规模的业务,但是分库分表等操作对操作人员要求较高,必须得需要有一定的数据库功底,要对数据库进行更改,对使用者来说有一定学习成本。DRDS 本身是一款中间件产品(尽管已经划分到数据库分类下了),底层还是依赖于 RDS 实例的,所以 DRDS 离不开 RDS,因此在大规模存储的情况下,我觉得超过2T的存储,DRDS 也吃力,其亮点还是分布式的性能表现优异。
POLARDB 则是一款全新的类型,对 MySQL 有了内核级的改造,在读的能力上大大提升并且性能优异,但是相对来说 写 还是依赖于主实例,DRDS 的分布式可以提升写的能力。 如果 POLARDB 完成了 多主进群(Multi-Master) 的支持的话,写的能力也会大大提升。 并且 POLARDB 不需要修改数据库,使用者可以无痛的切换,而且先进的分布式存储可以让其实现百T级的存储能力。 所以未来 POLARDB 和 DRDS 的竞争也是大有看头。
十八、展望
POLARDB 的特性使得 MySQL 性能有了极大的提高,POLARDB 是一个分布式的理念,POLARDB 的 POLARSOTRE 架构其实是可以延伸到其他开源数据库上的。
未来 POLARDB for PostgreSQL、POLARDB for MongoDB、POLARDB for PPAS 都是非常可期的,未来更高性能的 PG、MongoDB 也是令人向往。
原文链接:https://baijiahao.baidu.com/s?id=1610828839695075926&wfr=spider&for=pc


