
- 1黑马程序员——Java基础---String类和StringBuffer
- 2[图解]SysML和EA建模住宅安全系统-01_sysml和ea区别
- 3力扣 1888. 使二进制字符串字符交替的最少反转次数(前缀和+滑动窗口)_现有一个二进制串,你可以进行任意次操作,每次操作选择相邻的三个位置,将其翻转。
- 4最详细的 K8S 学习笔记总结
- 5八、SpringCloud-RabbitMQ + Spring AMQP 消息队列_rabbitmq 版本控制
- 6Linux repo包安装Nginx
- 7手把手教如何用Linux下IIO设备(附代码)
- 8哈希表&位图&topk&一致性哈希算法_布隆过滤器 topk
- 92005-2020年A股数据挖掘:谁是最大的牛股?【附Python分析源码】
- 10OpenCV 图像处理一(阈值处理、形态学操作【连通性,腐蚀和膨胀,开闭运算,礼帽和黑帽,内核】)_我在vscode学opencv 图像处理一
DiT架构大一统:一个框架集成图像、视频、音频和3D生成,可编辑、能试玩
赞
踩
ChatGPT狂飙,世界已经不是之前的样子。
新建了免费的人工智能中文站https://ai.weoknow.com
新建了收费的人工智能中文站ai人工智能工具
每天给大家更新可用的国内可用chatGPT资源


更多资源欢迎关注

基于 Diffusion Transformer(DiT)又迎来一大力作「Flag-DiT」,这次要将图像、视频、音频和 3D「一网打尽」。
今年 2 月初,Sora 的发布让 AI 社区更加看到了基础扩散模型的潜力。连同以往出现的 Stable Diffusion、PixArt-α 和 PixArt-Σ,这些模型在生成真实图像和视频方面取得了显著的成功。这意味着开始了从经典 U-Net 架构到基于 Transformer 的扩散主干架构的范式转变。
值得注意的是,通过这种改进的架构,Sora 和 Stable Diffusion 3 可以生成任意分辨率的样本,并表现出对 scaling 定律的严格遵守,即增加参数大小可以实现更好的结果。
不过,推出者们只对自家模型的设计选择提供有限的指导,并且缺乏详细的实现说明和公开的预训练检查点,限制了它们在社区使用和复刻方面的效用。并且,这些方法是针对特定任务(例如图像或视频生成任务)量身定制的,这阻碍了潜在的跨模态适应性。
为了弥补这些差距,上海 AI Lab、港中文和英伟达的研究者联合推出了 Lumina-T2X 系列模型,通过基于流(Flow-based)的大型扩散 Transformers(Flag-DiT)打造,旨在将噪声转换为图像、视频、多视图 3D 对象和基于文本描述的音频。
其中,Lumina-T2X 系列中最大的模型包括具有 70 亿参数的 Flag-DiT 和一个多模态大语言模型 SPHINX。SPHINX 是一个文本编码器,它具有 130 亿参数,能够处理 128K tokens。

-
论文地址:https://arxiv.org/pdf/2405.05945
-
GitHub 地址:https://github.com/Alpha-VLLM/Lumina-T2X
-
模型下载地址:https://huggingface.co/Alpha-VLLM/Lumina-T2I/tree/main
-
论文标题:Lumina-T2X: Transforming Text into Any Modality, Resolution, and Duration via Flow-based Large Diffusion Transformers
具体来讲,基础的文本到图像模型 Lumina-T2I 利用流匹配框架,在精心整理的高分辨率真实图像文本对数据集上进行训练,只需要使用很少的计算资源就能取得真实感非常不错的结果。
如图 1 所示,Lumina-T2I 可以生成任意分辨率和宽高比的高质量图像,并进一步实现高级功能,包括分辨率外推、高分辨率编辑、构图生成和风格一致生成,所有这些都以免训练的方式无缝集成到框架中。
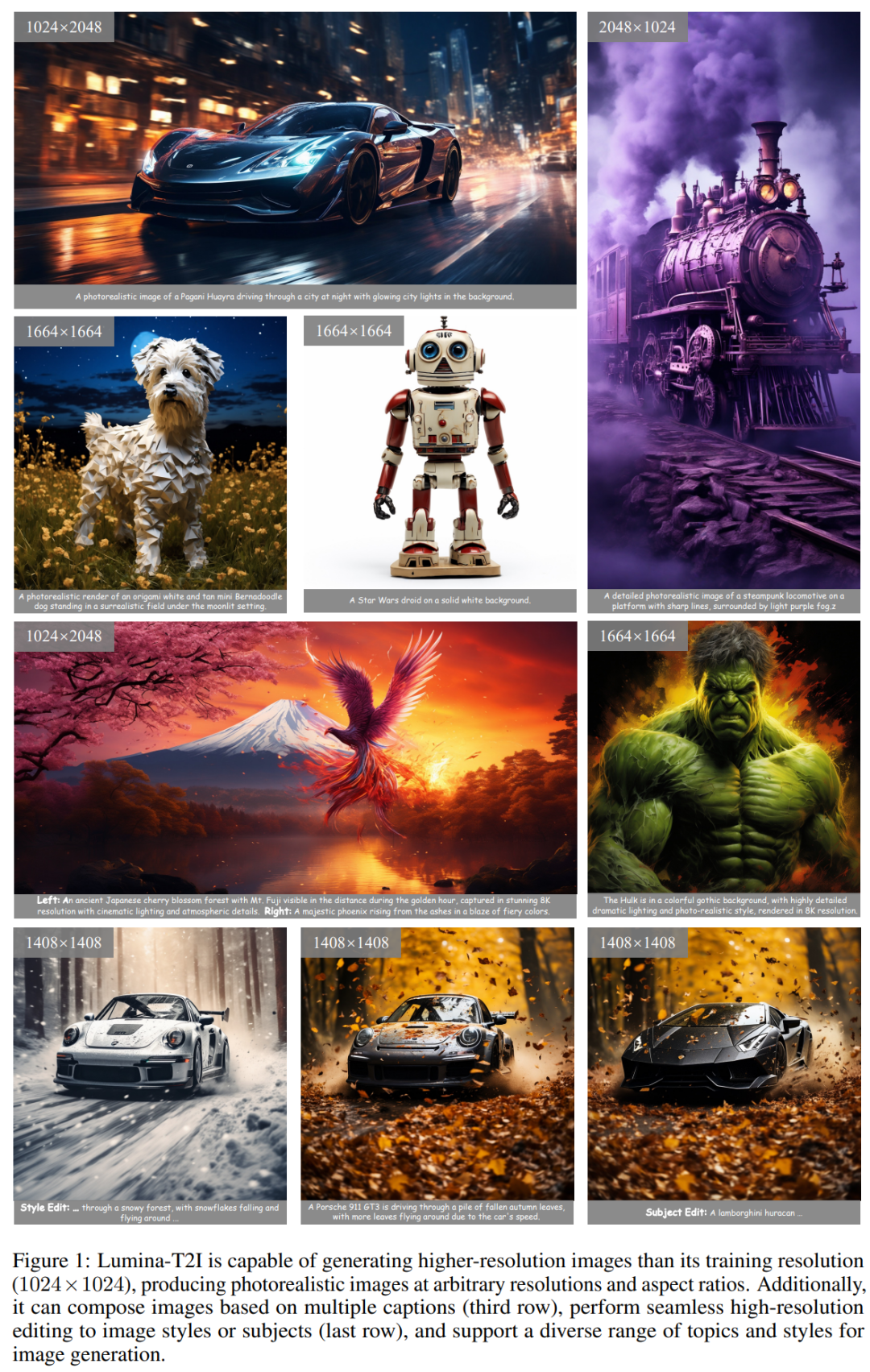
此外,为了增强跨各种模态的生成能力,Lumina-T2X 从头开始对视频 - 文本、多视图 - 文本和语音 - 文本对进行独立训练,从而可以合成视频、多视图 3D 对象以及文本语音指示。例如,Lumina-T2V 仅用有限的资源和时间进行训练,可以生成任何宽高比和时长的 720p 视频,显著缩小了开源模型与 Sora 之间的差距。
我们先来一睹实现效果如何。比如生成视频:

生成单张图像:

3D 生成:

语音生成:

构图生成:

风格一致性生成:

更大分辨率外推:

图像编辑:

可以说,Lumina-T2X 系列模型真正实现了图像、视频、3D 和语音的「大一统」。

目前,研究者已经推出了分别使用 Flag-DiT 2B 和 Gemma 2B 作为文本编码器的 Lumina-Next-T2I 模型,可以在 gradio 上试玩。
-
试用地址 1:http://106.14.2.150:10021/
-
试用地址 2:http://106.14.2.150:10022/
方法概览
Flag-DiT 架构
Flag-DiT 是 Lumina-T2X 框架的主干,它具有显著的稳定性、灵活性和可扩展性。
首先是稳定性。Flag-DiT 建立在 DiT 之上,并结合 ViT-22B 和 LLaMa 来修改,以提高训练稳定性。具体来说,Flag-DiT 将所有 LayerNorm 替换为 RMSNorm,使得训练稳定性增强。
此外,Flag-DiT 在键查询点积注意力计算之前结合键查询归一化(KQ-Norm)。KQ-Norm 的引入旨在通过消除注意力 logits 中极大值来防止损失发散。这种简单的修改可以防止混合精度训练下的发散损失,并有助于以更高的学习率进行优化。Flag-DiT 的详细计算流如图 2 所示。
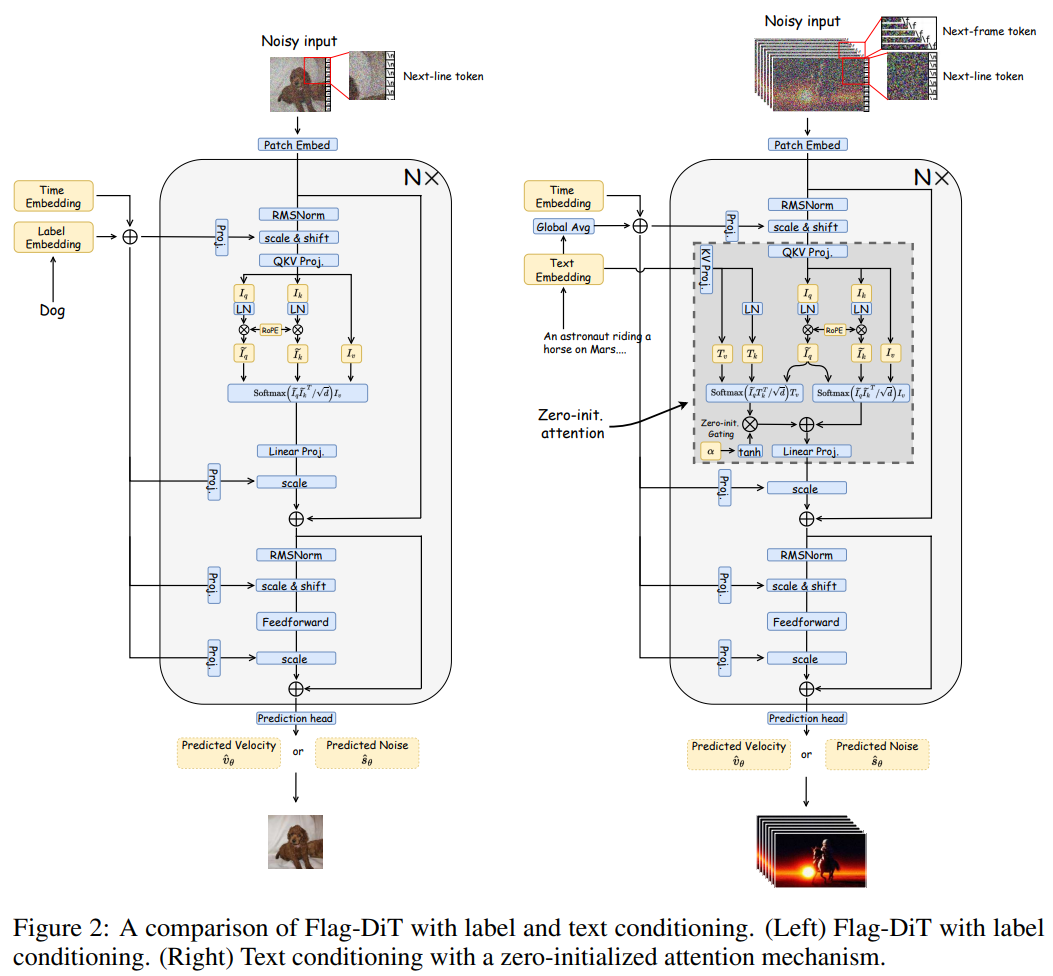
其次是灵活性。DiT 仅支持具有简单标签条件和固定 DDPM 公式的固定分辨率图像生成。为了解决这些问题,研究者首先探究为什么 DiT 缺乏以任意分辨率和比例生成样本的灵活性。他们发现,专为视觉识别任务而设计的 APE 很难泛化到训练之外未见过的分辨率和规模。
因此,受最近展现出强大上下文外推能力的 LLM 的推动,他们用 RoPE 替换了 APE。RoPE 按照以下公式 1 和 2 以分层方式注入相对位置信息。

最后,研究者根据经验,使用更大的参数和更多的训练样本扩展了 Flag-DiT。具体来讲,他们探索在标签条件 ImageNet 生成基准上将参数大小从 600M 扩大到 7B。
Lumina-T2X 整体流程
如图 3 所示,Lumina-T2X 在训练过程中主要由四个组件组成,接下来进行一一介绍。
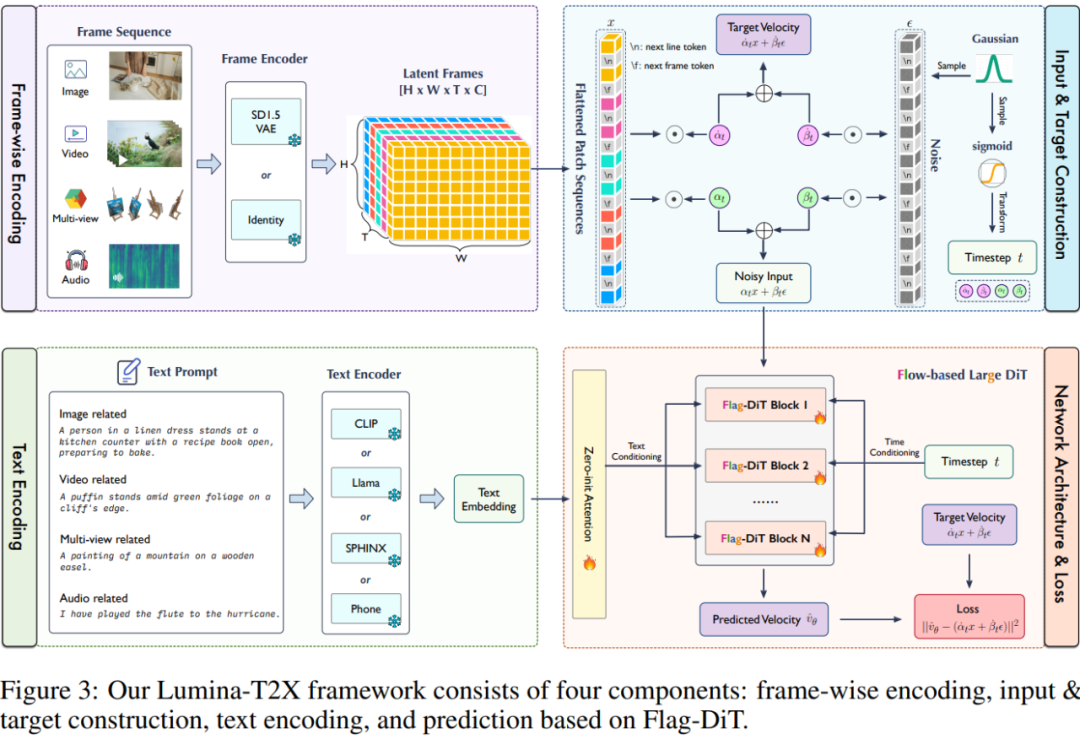
不同模态的逐帧编码。在 Lumina-T2X 框架中统一不同模态的关键是将图像、视频、多视图图像和语音频谱图视为长度为 T 的帧序列,然后利用特定模态的编码器来将这些输入转换为形状为 [H, W, T, C] 的潜在框架。
使用多种文本编码器进行文本编码。对于文本条件生成,研究者使用预先训练的语言模型对文本提示进行编码。他们结合了各种大小不一的文本编码器,其中包括 CLIP、LLaMA、SPHINX 和 Phone 编码器,针对各种需求和模态进行量身定制,以优化文本调整。
输入和目标构建。Lumina-T2X 在流匹配中采用线性插值方案来构建输入和目标,具体如下公式 4 和 6 所示,简单灵活。并且,受到中间时间步对于扩散模型和流模型都至关重要的观察启发, 研究者在训练期间采用时间重采样策略从对数范数分布中采样时间步。


网络架构和损失。研究者使用 Flag-DiT 作为去噪主干。给定噪声输入,Flag-DiT 块通过调控机制注入添加了全局文本嵌入的扩散时间步,并使用如下公式 9 通过零初始化注意力来进一步集成文本调整。

Lumina-T2X 系列
Lumina-T2X 系列模型包括了 Lumina-T2I、Lumina-T2V、LuminaT2MV 和 Lumina-T2Speech。对于每种模态,Lumina-T2X 都经过了针对不同场景优化的多配置独立训练,例如不同的文本编码器、VAE 潜在空间和参数大小。具体如图 17 所示。
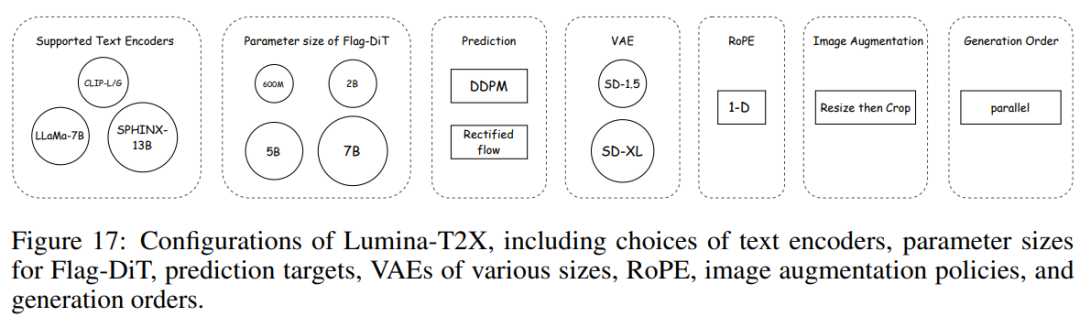
Lumina-T2I 的高级应用
除了基本的文本生成图像之外,文本到图像版本的 Lumina-T2I 还支持更复杂的视觉创作,并作为基础模型产生富有创造力的视觉效果。这包括分辨率外推、风格一致性生成、高分辨率图像编辑和构图生成。
与以往使用多种方法解决这些任务的策略不同,Lumina-T2I 可以通过 token 操作统一解决这些问题,如图 4 所示。
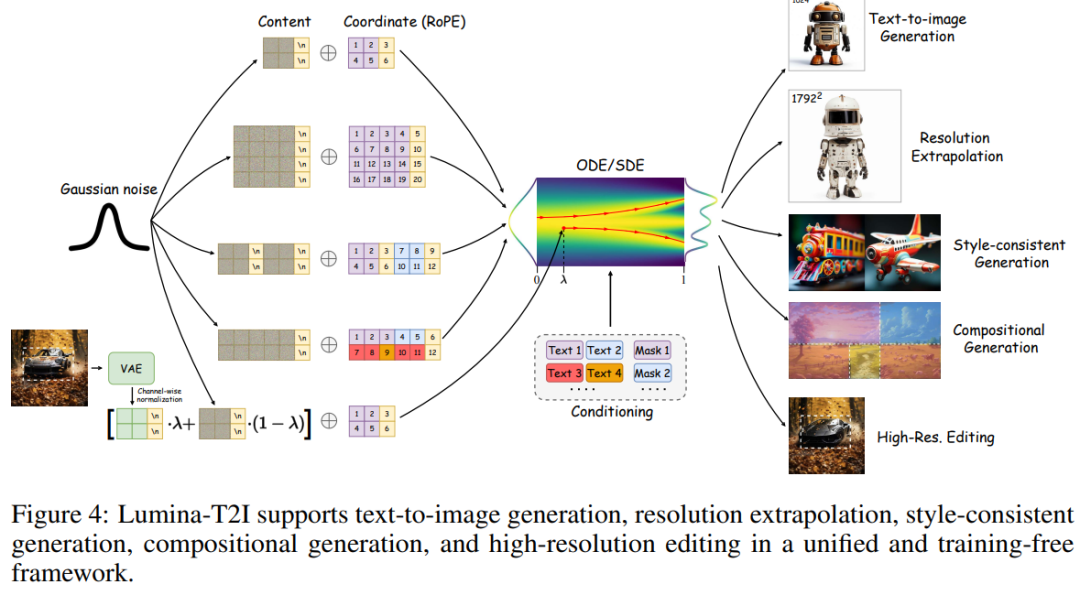
免调整分辨率外推。RoPE 的平移不变性增强了 Lumina-T2X 的分辨率外推潜力,使其能够生成域外分辨率的图像。Lumina-T2X 分辨率最高可以外推到 2K。
风格一致性生成。基于 Transformer 的扩散模型架构使得 Lumina-T2I 自然地适合风格一致性生成等自注意力操作应用。
构图生成。研究者只将此操作应用于 10 个注意力交叉层,以确保文本信息被注入到不同的区域。同时保持自注意层不变,以确保最终图像的连贯、和谐。
高分辨率编辑。除了高分辨率生成之外,Lumina-T2I 还可以执行图像编辑,尤其是对于高分辨率图像。
实验结果
在 ImageNet 上验证 Flag-DiT
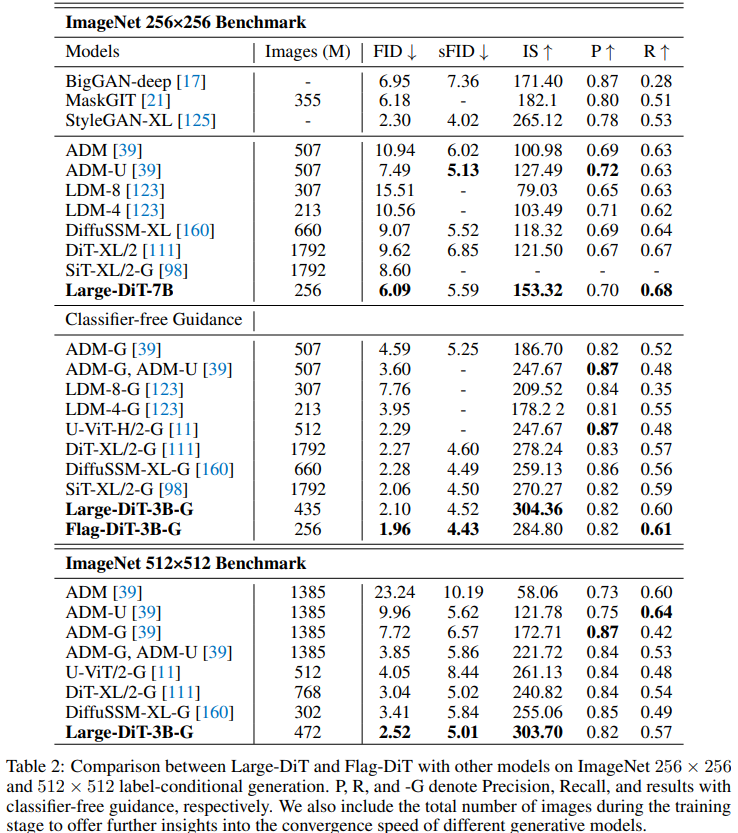
研究者在有标签条件的 256×256 和 512×512 ImageNet 上进行实验,以验证 Flag-DiT 相对于 DiT 的优势。Large-DiT 是 Flag-DiT 的特化版本,采用了 DDPM 算法 ,以便与原始 DiT 进行公平比较。研究者完全沿用了 DiT 的设置,但做了以下修改,包括混合精度训练、大学习率和架构修改套件(如 QK-Norm、RoPE 和 RMSNorm)。
研究者将其与 SOTA 方法的比较,如表 2 所示,Large-DiT-7B 在不使用无分类指导(CFG)的情况下,在 FID 和 IS 分数上明显超过了所有方法,将 FID 分数从 8.60 降至 6.09。这表明,增加扩散模型的参数可以显著提高样本质量,而无需依赖 CFG 等额外技巧。
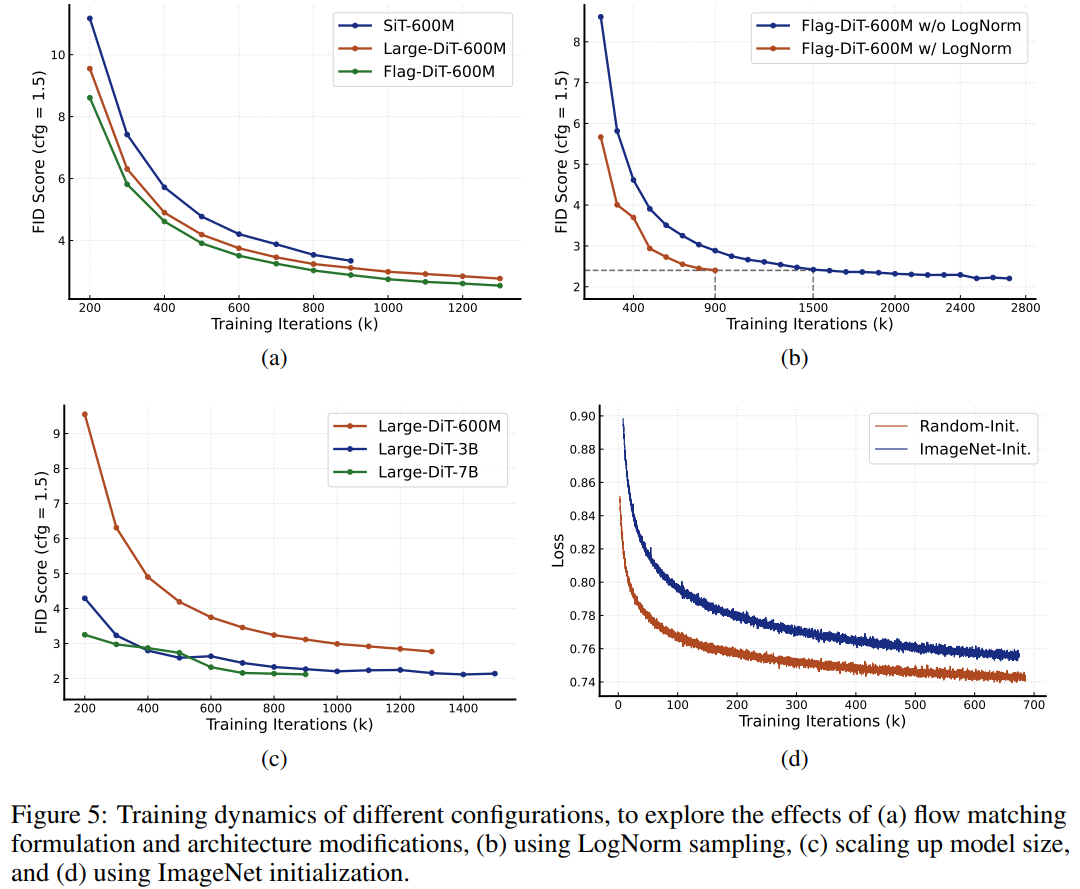
研究者比较了 Flag-DiT、Large-DiT 和 SiT 在 ImageNet 条件生成上的性能,为了进行公平比较,他们将参数大小固定为 600M。如图 5 (a) 所示,在 FID 评估的所有历时中,Flag-DiT 的性能始终优于 Large-DiT。这表明,与标准扩散设置相比,流匹配公式可以改善图像生成。此外,与 SiT 相比,Flag-DiT 的 FID 分数较低,这表明元架构修改(包括 RMSNorm、RoPE 和 K-Q norm)不仅能稳定训练,还能提高性能。
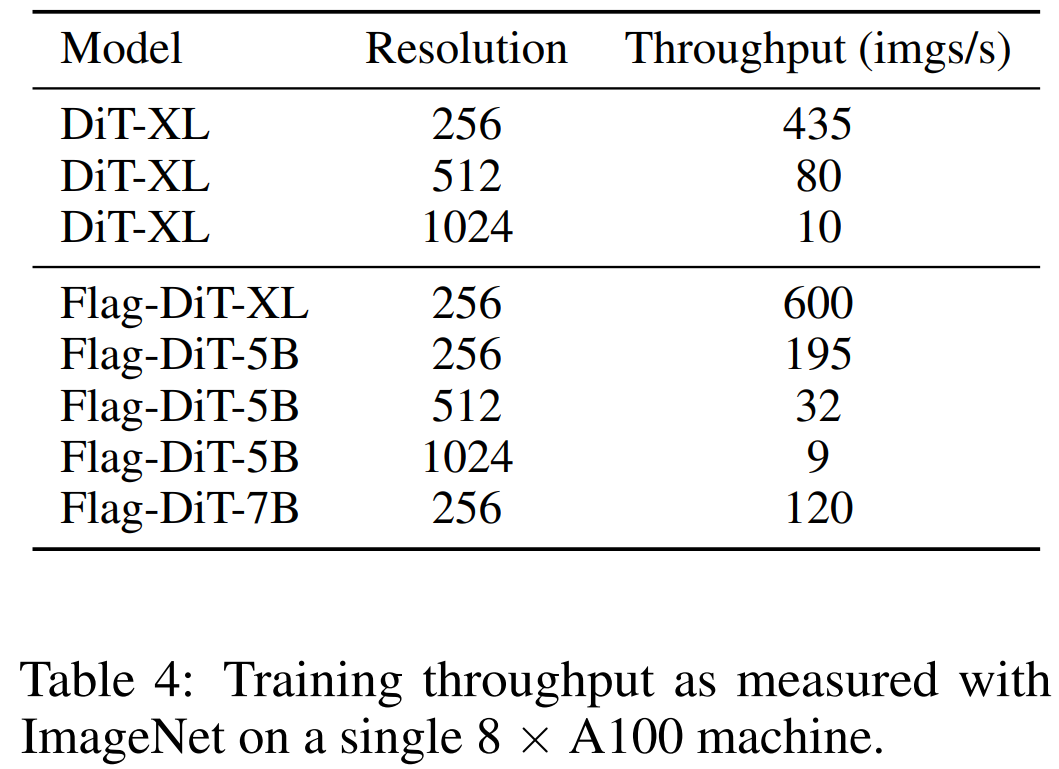
通过混合精度训练提高训练速度 。Flag-DiT 不仅能提高性能,还能提高训练效率和稳定性。如表 4 所示。Flag-DiT 每秒可多处理 40% 的图像。
ImageNet 初始化的影响 PixArt-α 利用 ImageNet 预训练的 DiT(学习像素依赖性)作为后续 T2I 模型的初始化。为了验证 ImageNet 初始化的影响,研究者比较了使用 ImageNet 初始化和从头开始训练的 600M 参数模型的 Lumina-T2I 速度预测损失。如图 5 (d) 所示,从头开始训练的损失水平更低,收敛速度更快。此外,从零开始可以更灵活地选择配置和架构,而不受预训练网络的限制。表 1 所示的简单而快速的训练配方也是根据这一观察结果设计的。
Lumina-T2I 的结果
图 6 中展示了基本的文本到图像生成能力。扩散主干架构和文本编码器的大容量允许生成逼真的高分辨率图像,并能准确理解文本,只需使用 288 个 A100 GPU 天数。

分辨率外推法不仅能带来更大比例的图像,还能带来更高的图像质量和更强的细节。如图 7 所示,当分辨率从 1K 外推至 1.5K 时,我们可以发现到生成图像的质量和文本到图像的对齐情况都得到了显著提升。此外,Lumina-T2I 还能进行外推,生成分辨率更低的图像,如 512 分辨率,从而提供了更大的灵活性。

如图 8 所示,通过利用一个简单的注意力共享操作,我们可以观察到生成批次中的强一致性。得益于完全注意力模型架构,研究者获得了与参考文献 [58] 中相媲美的结果,而无需使用任何技巧,如自适应实例规范化(AdaIN)。此外,研究者认为,正如先前的研究所示,通过适当的反转技术,他们可以实现零成本的风格 / 概念个性化,这是未来探索的一个有前景的方向。

如图 9 所示,研究者演示了组合生成 。在这其中可以定义任意数量的 prompt,并为每个 prompt 分配任意区域。Lumina-T2I 成功生成了各种分辨率的高质量图像,这些图像与复杂的输入 prompt 相一致,同时又保持了整体的视觉一致性。这表明,Lumina-T2I 的设计选择提供了一种灵活有效的方法,在生成复杂的高分辨率多概念图像方面表现出色。

研究者对高分辨率图像进行风格和主题编辑。如图 10 所示,Lumina-T2I 可以无缝修改全局样式或添加主题,而无需额外的训练。此外,他们还分析了图像编辑中的启动时间和潜在特征归一化等各种因素,如图 11 所示。


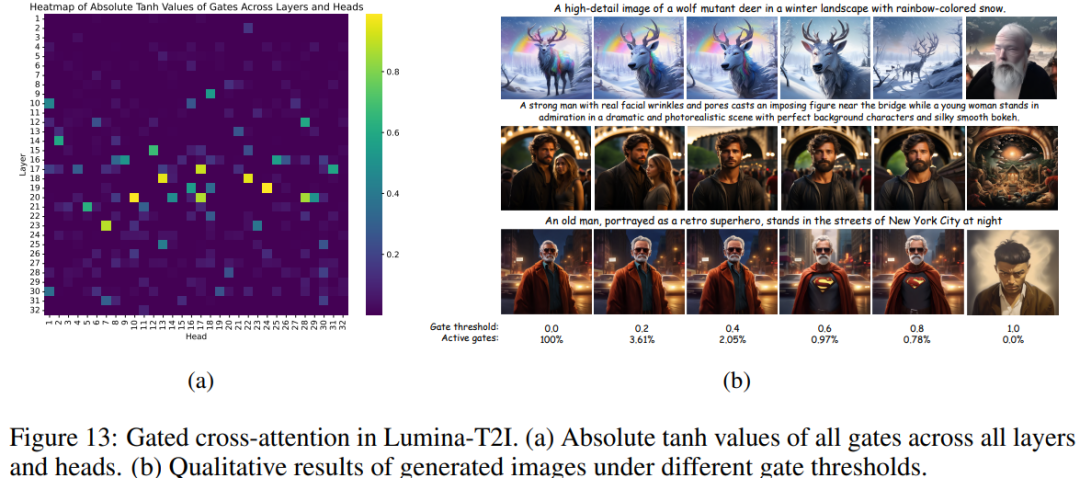
如图 13 (a) 所示,研究者可视化了各层和各头部的门控值,发现大多数门控值接近零,只有少部分显示出显著的重要性。有趣的是,最关键的文本调节头部主要位于中间层,这表明这些层在文本调节中起着关键作用。为了巩固这一观察结果,研究者对低于某一阈值的门控进行了截断,发现 80% 的门控可以在不影响图像生成质量的情况下被停用,如图 13 (b) 所示。这一观察表明,在采样过程中截断大多数交叉注意力操作的可能性,这可以大大减少推理时间。
Lumina-T2V 的结果
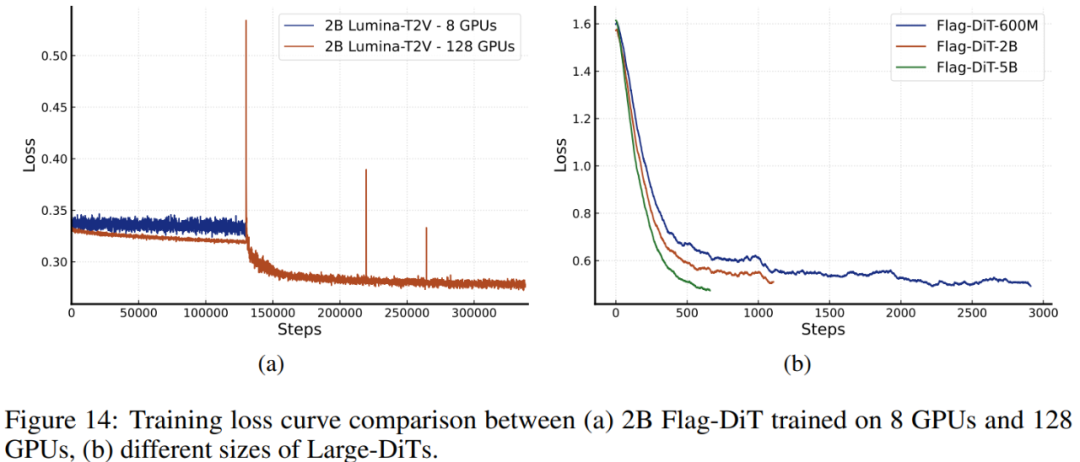
研究者观察到,使用大批量的 Lumina-T2V 能够收敛,而小批量则难以收敛。如图 14 (a) 所示,将批量大小从 32 增加到 1024 会导致损失收敛。另一方面,与 ImageNet 实验中的观察相似,增加模型参数会加速视频生成的收敛速度。如图 14 (b) 所示,当参数大小从 600M 增加到 5B 时,我们能够在相同的训练迭代次数下一致观察到更低的损失。
如图 15 所示,Lumina-T2V 的第一阶段能够生成具有场景动态变化(如场景转换)的短视频,尽管生成的视频在分辨率和持续时间上有限,总 token 数最多为 32K。经过对更长持续时间和更高分辨率视频的第二阶段训练后,Lumina-T2V 能够生成 128K token 的各种分辨率和持续时间的长视频。如图 16 所示,生成的视频展示了时间上的一致性和更丰富的场景动态,表明当使用更多的计算资源和数据时,展现出有希望的扩展趋势。


更多详细内容,请阅读原论文。
机器之心将于2024年6月1日举办「CVPR 2024 线上论文分享会」,将设置 Keynote、 论文分享、企业招聘等环节,就业内关注的 CV 热门主题邀请顶级专家、论文作者与观众做学术交流。
ChatGPT狂飙,世界已经不是之前的样子。
新建了免费的人工智能中文站https://ai.weoknow.com
新建了收费的人工智能中文站ai人工智能工具
每天给大家更新可用的国内可用chatGPT资源
更多资源欢迎关注

