- 1Typora + PicGo + Gitee/GitHub 免费搭建个人图床_gitee+github
- 2CONVERT 转换函数的简单使用方法_convert函数
- 3数据结构--带头结点的单向链表_带头结点的单链表
- 4JavaScript 中的数学与时光魔法:Math与Date对象大揭秘
- 5网络运输层之(3)GRE协议
- 6OpenCV安装:最基础的openCV程序运行示例_opencv安装程序
- 7如何利用python选股
- 8数据结构修炼第一篇:时间复杂度和空间复杂度_栈和队列的时间复杂度和空间复杂度
- 9计算机网络管理 常见的计算机网络管理工具snmputil,Mib browser,SNMPc管理软件的功能和异同_snmp网络管理软件
- 10基于n-gram模型的中文分词_ngram分词
试衣不再有界:Tunnel Try-on开启视频试衣应用新纪元
赞
踩

论文:https://arxiv.org/pdf/2404.17571
主页:https://mengtingchen.github.io/tunnel-try-on-page/
一、摘要总结
随着虚拟试衣技术的发展,消费者和时尚行业对于能够在视频中实现高质量虚拟试衣的需求日益增长。这项技术允许用户在不实际穿上衣物的情况下,通过视频序列体验穿着不同服装的效果。尽管基于图像的虚拟试衣方法已经得到了广泛的研究,但视频虚拟试衣面临着保持服装细节和模拟连贯动作的双重挑战,这在以往的研究中并未得到很好的解决。
本文介绍了一种名为“Tunnel Try-on”的新型视频虚拟试衣框架,旨在解决以往方法在处理复杂场景时的不足。该框架的核心思想是在输入视频中挖掘一个“聚焦隧道”(focus tunnel),以便近距离拍摄服装区域,从而更好地保留服装的细微细节。为了生成连贯的动作,研究者们首先利用卡尔曼滤波器(Kalman filter)构建平滑的裁剪框,并注入隧道的位置嵌入到注意力层中,以提高生成视频的连贯性。此外,还开发了一个环境编码器来提取隧道外的上下文信息,作为辅助线索。通过这些技术,Tunnel Try-on不仅保持了服装的精细细节,还合成了稳定和平滑的视频。该方法在视频虚拟试衣领域取得了突破性进展,为电商/时尚行业的实际应用提供了新的可能性,并为未来虚拟试衣应用的研究提供了新的方向。
二、网络结构
a.)核心创新
本文的核心创新主要体现在以下几个方面:
-
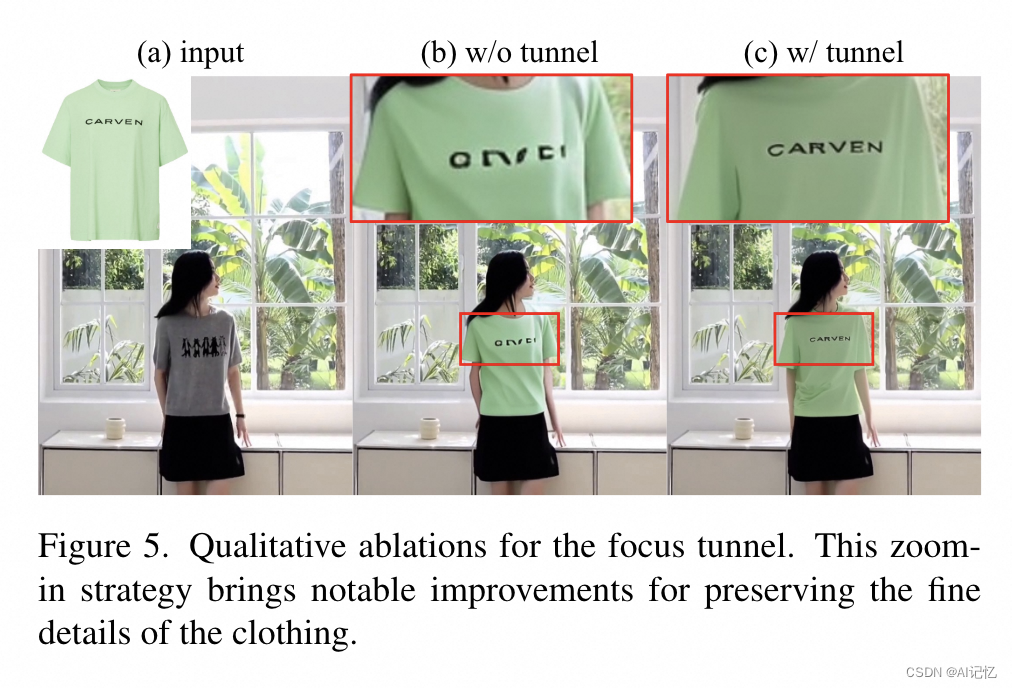
聚焦隧道(Focus Tunnel):提出了一种新的视频处理策略,通过在视频中创建一个聚焦隧道来放大服装区域,从而更好地捕捉和保留服装的细微特征。
-
隧道平滑和嵌入(Tunnel Smoothing and Embedding):使用卡尔曼滤波器对隧道坐标进行平滑处理,并引入隧道嵌入机制,以增强视频帧之间的连贯性和一致性。
-
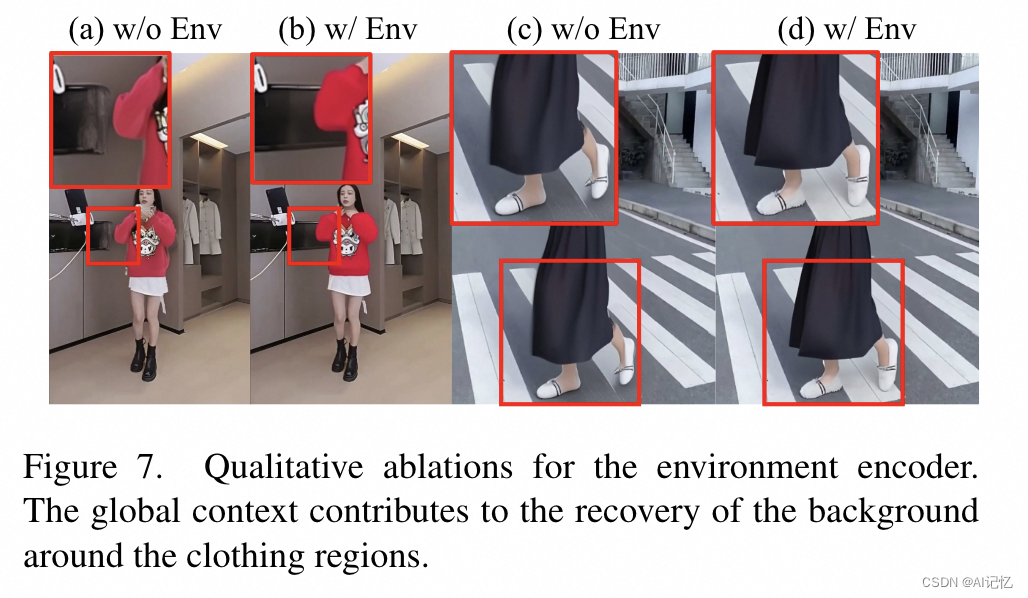
环境编码器(Environment Encoder):开发了一种新的编码器,用于提取并融合视频中隧道区域外的全局上下文信息,以改善背景生成的质量。
-
扩散模型应用:将扩散模型应用于视频虚拟试衣,利用其在图像生成中的优势,提高了视频试衣结果的质量和真实感。
b.)核心网络
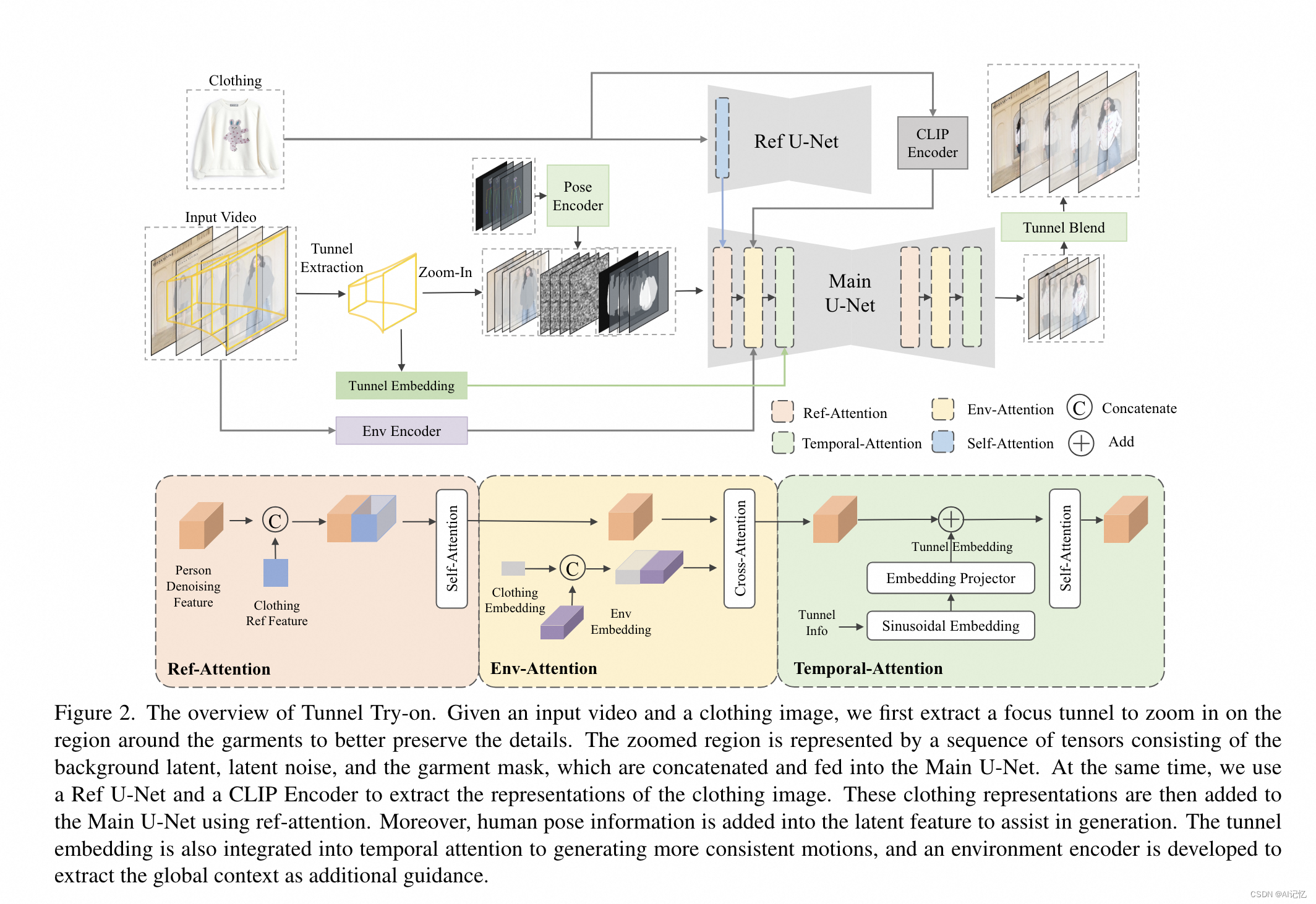
Tunnel Try-on的网络结构包括以下几个关键组件:
-
主网络(Main U-Net):作为基础的图像试衣模型,使用掩码视频帧、潜在噪声和衣物无关掩码作为输入。
-
参考网络(Ref U-Net):用于编码参考服装的细粒度特征。
-
CLIP图像编码器:捕获目标服装图像的高级语义信息。
-
姿态编码器:将人体姿态信息编码为特征,用于辅助视频生成。
-
时间注意力模块(Temporal-Attention):在Main U-Net的每个阶段后插入,用于确保帧之间的平滑过渡。
-
环境编码器(Environment Encoder):由一个冻结的CLIP图像编码器和一个可学习的线性映射层组成,用于提取和融合环境上下文信息。
-
隧道嵌入(Tunnel Embedding):将隧道的位置和大小信息编码为嵌入,注入到时间注意力模块中。
-
训练和测试流程:训练分为两个阶段,第一阶段专注于图像级别的试衣生成,第二阶段整合所有策略和模块,训练视频试衣数据集。
-
后处理:使用高斯模糊技术将生成的试衣视频与原始视频融合,以获得最终的试衣效果。
通过这些创新点和详细的算法流程,Tunnel Try-on能够处理复杂的背景和多样的人体动作,生成高保真的虚拟试衣视频。
三、实验结果
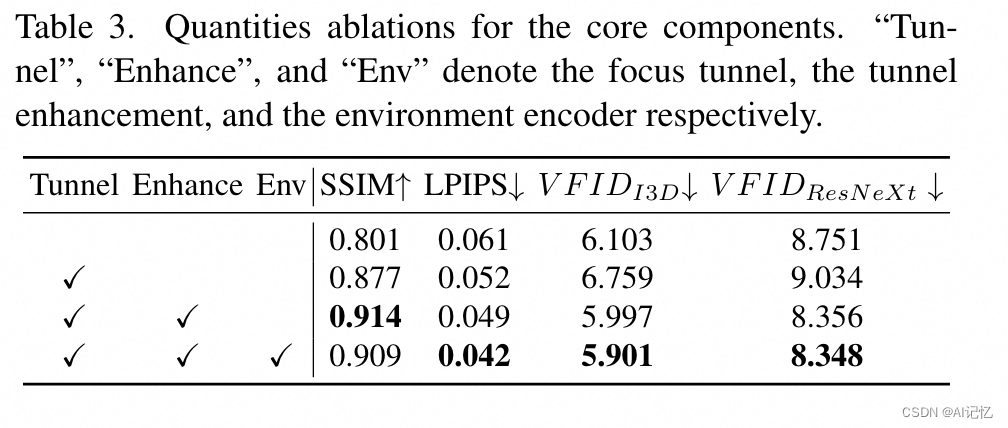
a.)总体指标
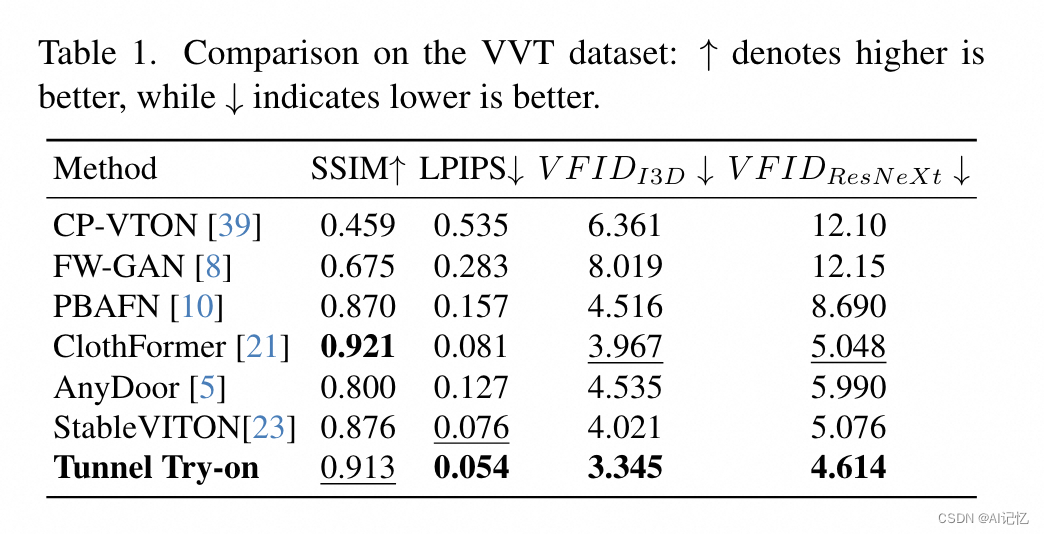
b.)ablation study