
- 1Flink 内核原理与实现-状态原理_flink state实现
- 2gerrit submit撤回_Gerrit使用篇-提交代码,合并代码
- 3关系抽取(三)实体关系联合抽取:CasRel_最新的实体关系抽取工具
- 4webpack-theme-color-replacer自定义element-ui主题
- 5【Unity】天气特效:打雷下雨_unity落雷特效制作
- 6Cognex VisionPro连接USB相机的两种品牌
- 7极其强大的数据统计软件 Stata 安装教程_如何把stata装到硬盘里面
- 8Oracle使用序列触发器实现主键id自动增长_oracle的id自增序列
- 9蚁剑下载、安装_蚁剑 下载 csdn
- 10AI+AR,二维码还能这么玩儿!优质提示词的12个技巧;LLM学习路径和资料汇总;AI二维码工具大盘点 | ShowMeAI日报_quick qr提示词
自适应动态规划 matlab_CVPR 2020丨动态卷积:自适应调整卷积参数,显著提升模型表达能力...
赞
踩

编者按:轻量级卷积神经网络能够在较低的计算预算下运行,却也牺牲了模型性能和表达能力。对此,微软 AI 认知服务团队提出了动态卷积,与传统的静态卷积(每层单个卷积核)相比,根据注意力动态叠加多个卷积核不仅显著提升了表达能力,额外的计算成本也很小,因而对高效的 CNN 更加友好,同时可以容易地整合入现有 CNN 架构中。
轻量级卷积神经网络(light-weight convolutional neural network)因其较低的计算预算而限制了 CNN 的深度(卷积层数)和宽度(通道数),不仅导致模型性能下降,表示能力也会受到限制。
为了解决这个问题,微软的研究员们提出了动态卷积,这种新的设计能够在不增加网络深度或宽度的情况下增加模型的表达能力(representation capacity)。动态卷积的基本思路就是根据输入图像,自适应地调整卷积参数。如图1所示,静态卷积用同一个卷积核对所有的输入图像做相同的操作,而动态卷积会对不同的图像(如汽车、马、花)做出调整,用更适合的卷积参数进行处理。简单地来说,卷积核是输入的函数。

动态卷积
动态卷积没有在每层上使用单个卷积核,而是根据注意力动态地聚合多个并行卷积核。注意力会根据输入动态地调整每个卷积核的权重,从而生成自适应的动态卷积。由于注意力是输入的函数,动态卷积不再是一个线性函数。通过注意力以非线性方式叠加卷积核具有更强的表示能力。
动态网络引入了两部分的额外计算:注意力模型和卷积核的叠加。注意力模型计算复杂度很低,由 avg pool 和两层全卷积组成。得益于小的内核尺寸,叠加多个卷积核在计算上也非常高效。因此,动态卷积引入的额外计算是非常少的。少量的额外计算与显著的表达能力的提升使得动态卷积非常适合轻量级的神经网络。
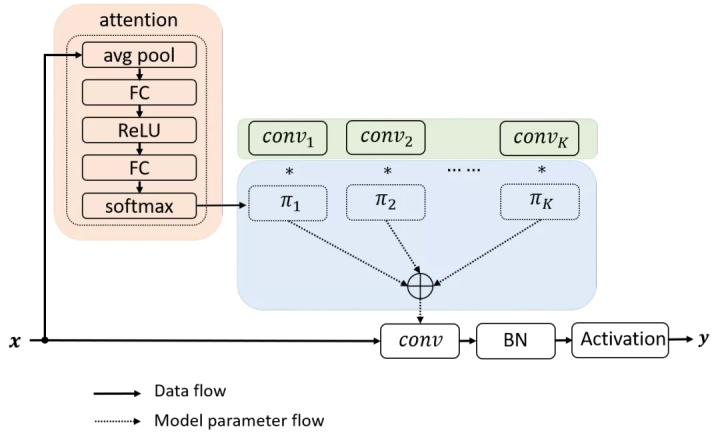
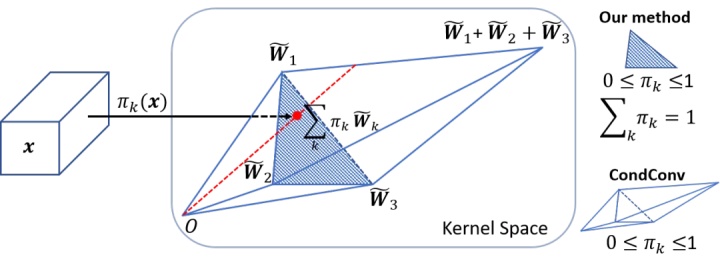
动态卷积网络的难点在于多个卷积核和注意力模型的共同学习。这个困难会随着网络深度的增加而增加。本文提出,解决这个问题有两个关键点。首先,限制注意力的取值将简化注意力模型的学习。注意力取值的限制将缩小多个卷积的叠加核的取值空间。文中将注意力取值限制在0与1之间,同时所有注意力的和为1。如图3所示,如果使用3个卷积核,注意力在0与1之间把叠加核限制在两个三棱锥中,注意力的和为1把叠加核进一步限制在以这三个卷积核为顶点的三角形中。对于这两个限制,softmax 是一个很自然的选择。
其次,限制注意力接近均匀分布有利于多个卷积核在训练初期同时学习。对于这个要求,softmax 就显得不那么合适了,因为 softmax 输出更稀疏的注意力。因此,温度(temperature)被引入到 softmax。接近均匀分布的注意力可以通过使用较大的温度来实现。文章也提到温度淬火(temperature annealing)有助于准确度的进一步提升。
实验结果
实验结果显示,动态卷积在 ImageNet 分类和 COCO 关键点检测两个视觉任务上均具有显著的提升。例如,通过在 SOTA 架构 Mobilenet 上简单地使用动态卷积,ImageNet 分类的 top-1 准确度提高了 2.3%,而 FLOP 仅增加了 4%,在 COCO 关键点检测上实现了 2.9 的 AP 增益。在关键点检测上,动态卷积在 backbone 和 head 上同样有效。
文章还对学习到的动态卷积进行了检测(inspection)来证实学到的卷积是不是真的动态。通过与多种静态叠加以及注意力的洗牌(shuffle)的对比,证实了注意力确实对不同的输入进行了动态调整。文中的对比试验也有一些有趣的发现,比如动态卷积在网络深层带来的提升明显高于浅层。同时,动态卷积在更浅或者更窄网络的提升更明显。
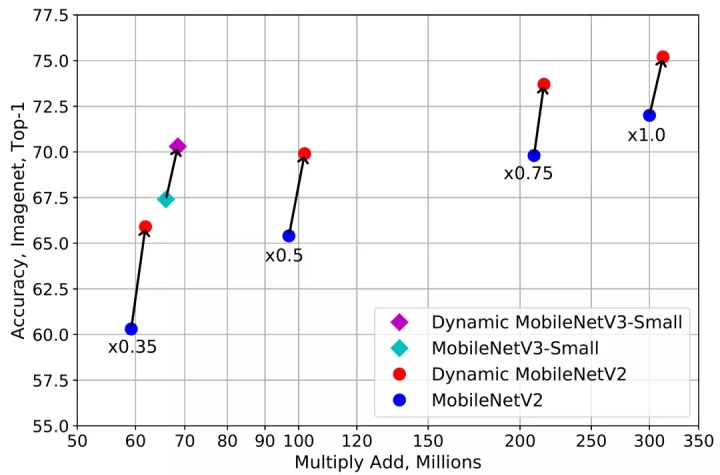
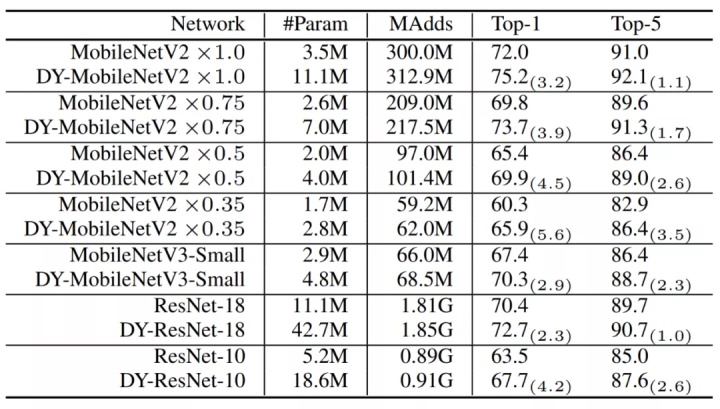
论文链接:
https://arxiv.org/abs/1912.03458
本文作者:陈寅鹏、戴希洋、刘梦尘、陈冬冬、袁路、刘自成
本账号为微软亚洲研究院的官方知乎账号。本账号立足于计算机领域,特别是人工智能相关的前沿研究,旨在为人工智能的相关研究提供范例,从专业的角度促进公众对人工智能的理解,并为研究人员提供讨论和参与的开放平台,从而共建计算机领域的未来。
微软亚洲研究院的每一位专家都是我们的智囊团,你在这个账号可以阅读到来自计算机科学领域各个不同方向的专家们的见解。请大家不要吝惜手里的“邀请”,让我们在分享中共同进步。
也欢迎大家关注我们的微博和微信 (ID:MSRAsia) 账号,了解更多我们的研究。

