
- 1linux下git更新工具,Linux下更新git版本
- 2SQLite安装与使用 (Linux)_linux sql什么工具打开
- 32022年第三届MathorCup高校数学建模挑战赛——大数据竞赛 赛道B 北京移动用户体验影响因素研究 问题一建模方案及代码实现详解_mathorcup大数据竞赛优秀论文
- 4飞凌嵌入式i.MX 8M Plus开发板的OTA远程升级方案_i.mx emmc分区
- 5探索Crazysiri的`chineseholiday`:智能处理中国节假日的Python库
- 6Java自学路线总结,已Get腾讯Offer_腾讯核心技术学习路线总结图
- 7简单易用的一站式研发管理平台 :免费使用 、本地安装、研发管理、测试管理、数字大屏、CI CD、接口测试、缺陷管理_一站式研发平台
- 8利用MaxKB+Ollama:搭建智能问答系统_Ubuntu部署maxkb
- 9Redis的缓存问题_redis缓存内容一般是前端上传还是后端上传
- 10自编码、自回归、Seq2Seq的区别是什么?_自回归 自编码
LangChain初探:为你的AI应用之旅导航
赞
踩

先来个温馨的小提醒:
这篇文章虽然较为全面地介绍了 LangChain,但都是点到为止,只是让你了解一下它的皮毛而已,适合小白选手。
So,如果你是 LangChain 的小白,看完之后还是一头雾水,那就请毫不留情地,狠狠地 … 给我点赞吧!有了你的鼓励,我会再接再厉的!(ง •_•)ง
What?
丹尼尔:蛋兄,刚刚听到别人在说 LangChain,你知道是啥玩意吗?
蛋先生:哦,LangChain 啊,一个开发框架
丹尼尔:开发啥的框架?
蛋先生:一个用于开发语言模型驱动的应用的框架
丹尼尔:哦,开发这种应用,不就是写写 Prompt 提示语,调调语言模型 API 的事么?
蛋先生:没错。但 LangChain 使得 Prompt 的编写,API 的调用更加标准化
丹尼尔:就这样吗?
蛋先生:当然不止,它还有很多很酷的功能
丹尼尔:比如?
蛋先生:它可以连接外部数据源,根据输入检索相关数据作为上下文给到语言模型,使得语言模型可以回答训练数据之外的问题。这是由 LangChain 的 Retrieval 来实现的
丹尼尔:太酷了,我想到了一个场景,比如通过它来连接客服的回答话术库,这样就可以让语言模型摇身一变,变成一个专业的客服了
蛋先生:恩,这是一个很好的场景
丹尼尔:还有其它更酷的功能吗?
蛋先生:它可以让语言模型来自行决定采取哪些行动
丹尼尔:这个就不是很明白了
蛋先生:接着你那个客服的例子继续说。如果用户问的问题是关于公司产品的,我们就想让语言模型使用客服的话术库来回答;如果是其它问题,就让语言模型用它自己的知识来直接回答。如果是你,你会怎么实现?
丹尼尔:我想我会先通过语言模型来判断用户的问题是否关于公司产品。如果是,就走连接话术库的逻辑;如果不是,就走让语言模型直接回答的逻辑
蛋先生:恩,你这种就是 hardcode 逻辑的方式。还有一种更加 amazing 的 方式,就是让语言模型自行决定采取哪种行为。这个由 LangChain 的 Agent 来实现。
丹尼尔:听上去太酷了,怎么用呢?
蛋先生:莫急,待我慢慢道来
Why?
丹尼尔:蛋兄,你刚刚说到 LangChain 使得 Prompt 的编写,API 的调用更加标准化,标准化了肯定是好的,但好处很大吗?我用语言模型的 SDK 不也用得好好的吗?
蛋先生:那你先给一个使用 SDK 与语言模型交互的例子呗
丹尼尔:这还不简单,我就用这个吧:fireworks.ai (注:这个平台提供免费的资源,访问也方便)
from fireworks.client import Fireworks
client = Fireworks(api_key="<FIREWORKS_API_KEY>")
response = client.chat.completions.create(
model="accounts/fireworks/models/llama-v2-7b-chat",
messages=[{
"role": "user",
"content": "Who are you?",
}],
)
print(response.choices[0].message.content)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
输出:
Hello! I'm just an AI assistant, here to help you in any way I can. My purpose is to provide helpful and respectful responses, always being safe and socially unbiased. I'm here to assist you in a positive and ethical manner, and I'm happy to help you with any questions or tasks you may have. Is there anything specific you would like me to help you with?
- 1
- 2
蛋先生:很好,再给另外一个语言模型的例子呗
丹尼尔:额,一样的操作啊,你这是在消遣我吗?好吧,那我就再给一个百度的文心一言的例子
import os
import qianfan
os.environ["QIANFAN_AK"] = "<QIANFAN_AK>"
os.environ["QIANFAN_SK"] = "<QIANFAN_SK>"
chat_comp = qianfan.ChatCompletion()
resp = chat_comp.do(messages=[{
"role": "user",
"content": "Who are you?"
}])
print(resp.body['result'])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
输出:
您好,我是百度研发的知识增强大语言模型,中文名是文心一言,英文名是ERNIE Bot。我能够与人对话互动,回答问题,协助创作,高效便捷地帮助人们获取信息、知识和灵感。
- 1
- 2
蛋先生:Good,现在假设我一开始使用 fireworks 来开发应用,过程中发现效果不太理想,想换成文心一言呢?
丹尼尔:Oh~,各个语言模型的 SDK 的接口定义是不一样的,替换起来确实麻烦。来吧,是时候开始你的表演了
蛋先生:我们直接来看下通过 LangChain 使用 fireworks 和 文心一言 的代码示例吧,毕竟 No Code No BB 嘛
- fireworks LangChain 示例
import os
from langchain_community.chat_models.fireworks import ChatFireworks
os.environ["FIREWORKS_API_KEY"] = '<FIREWORKS_API_KEY>'
model = ChatFireworks(model="accounts/fireworks/models/llama-v2-13b-chat")
res = model.invoke("Who are you?")
print(res.content)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 文心一言 LangChain 示例
import os
from langchain_community.chat_models import QianfanChatEndpoint
os.environ["QIANFAN_AK"] = "<QIANFAN_AK>"
os.environ["QIANFAN_SK"] = "<QIANFAN_SK>"
model = QianfanChatEndpoint(model="ERNIE-Bot-turbo")
res = model.invoke("Who are you?")
print(res.content)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
丹尼尔:好像看出来了,标准化之后,要更换语言模型变得非常方便了,只需要更换下 model 的实例化就行了
蛋先生:是的,这只是个最简单的例子,LangChain 还有很多种优雅的方式来切换不同的模型。从此以后我们就可以专注于 Prompt 的开发了。语言模型嘛,哪个合适换哪个
How?
丹尼尔:好了,我决定入坑 LangChain 了,那咱们进一步聊聊?
蛋先生:当然可以!我们从简单到复杂,结合代码和流程图来展示 LangChain 的一些用法。先来最简单的代替 SDK 的用法,这个上边已经有提到了
res = model.invoke("tell me a short joke about a cat")
print(res.content)
- 1
- 2
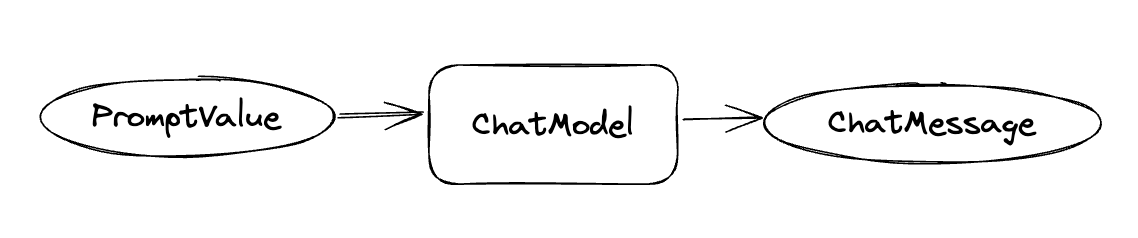
丹尼尔:恩,这个 so easy,一瞄就懂
蛋先生:OK,那接下来我们来使用 PromptTemplate,通过变量的方式来控制模板里的部分内容
from langchain_core.prompts import ChatPromptTemplate
...
prompt = ChatPromptTemplate.from_template("tell me a short joke about {topic}")
chain = prompt | model
res = chain.invoke({"topic": "a cat"})
print(res.content)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

丹尼尔:使用 PromptTemplate 的方式来写 prompt,确实比字符串的拼接要优雅不少
蛋先生:再加个简单的输出转换吧
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
...
prompt = ChatPromptTemplate.from_template("tell me a short joke about {topic}")
output_parser = StrOutputParser()
chain = prompt | model | output_parser
res = chain.invoke({"topic": "a cat"})
print(res)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

丹尼尔:终于知道为啥叫 chain 了
蛋先生:继续?
丹尼尔:继续…
蛋先生:接下来这段代码可能有点长哦
from langchain_community.embeddings import QianfanEmbeddingsEndpoint from langchain_community.document_loaders import WebBaseLoader from langchain_community.vectorstores import faiss from langchain_community.chat_models import QianfanChatEndpoint from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.chains.combine_documents import create_stuff_documents_chain from langchain_core.prompts import ChatPromptTemplate from langchain_core.runnables import RunnableParallel, RunnablePassthrough from langchain_core.output_parsers import StrOutputParser # 1 docs = WebBaseLoader("https://docs.smith.langchain.com").load() embeddings = QianfanEmbeddingsEndpoint() documents = RecursiveCharacterTextSplitter(chunk_size=900).split_documents(docs) vector = faiss.FAISS.from_documents(documents, embeddings) retriever = vector.as_retriever(search_kwargs={'k': 4}) # 2 setup_and_retrieval = RunnableParallel( {"context": retriever, "input": RunnablePassthrough()} ) prompt = ChatPromptTemplate.from_template("""Answer the following question based only on the provided context: <context> {context} </context> Question: {input}""") model = QianfanChatEndpoint(streaming=False, model="ERNIE-Bot-turbo") output_parser = StrOutputParser() # 3 retrieval_chain = setup_and_retrieval | prompt | model | output_parser res = retrieval_chain.invoke("how can langsmith help with testing?") print(res)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
丹尼尔:请把“可能”去掉,谢谢
蛋先生:但逻辑其实并不复杂,主要分为三块
1)加载网页文档,通过 Embeddings 将文档内容转成向量并存储在向量数据库 FAISS 中,retriever 就是一个可以根据输入从向量数据库获取相关文档的检索工具
2)声明 chain 的各个步骤
3)将各个步骤按顺序 chain 起来
丹尼尔:等等,看着有点脑壳疼。Embeddings?向量?向量数据库?
蛋先生:咱们今天是“初探”,所以也只能简单讲讲,不然很多同学就要昏昏欲睡了
丹尼尔:没问题,有个大概印象也好
蛋先生:首先,为什么要将文本转成向量呢?因为通过计算两个向量的距离,我们就可以量化地评估它们的相关性。距离越小,通常意味着文本之间的相关性越高。我们这里是需要检索与输入相关的文档内容,将其作为会话上下文提供给语言模型。如果是整个文档都传过去,是不是就太大了呢?
丹尼尔:哦,原来向量有这么高级的功能啊
蛋先生:没错。然后要将文本转成向量,就需要用到 Embeddings(词嵌入)技术。Embeddings 在历史上有过多种方法,如基于统计的计数方法,基于神经网络的推理方法等。 QianfanEmbeddingsEndpoint 正是一个利用深度学习训练得到的 Embeddings 模型服务,输入为文本,输出为向量
丹尼尔:大概有点明白了
蛋先生:那我们接着看下流程图
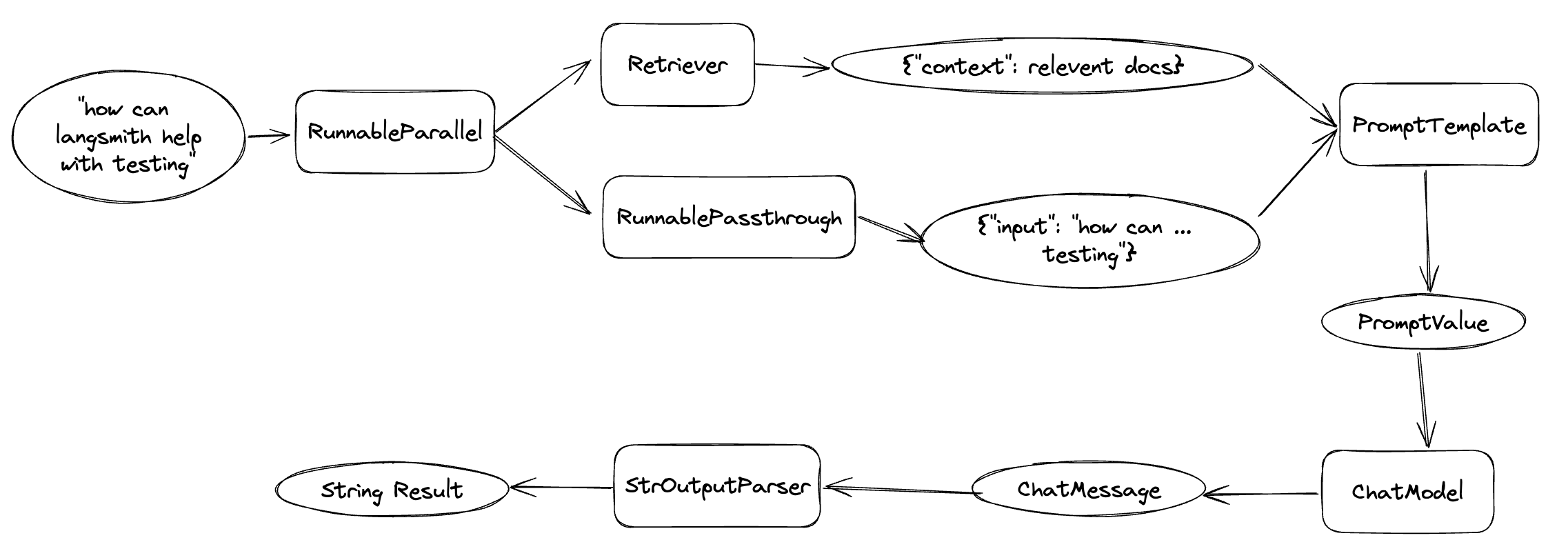
丹尼尔:能否为小弟我解释一下上面这个流程图的前半部分
蛋先生:当然!首先输入是 “how can langsmith help with testing?”;接着有个并行的逻辑,一个是通过 Retriever 根据输入检索相关的文档内容作为 context 的值,另一个则是直接 pass 将输入作为 input 的值;然后就是将数据传给 Prompt 模板,最终就可以得到传给语言模型的 PromptValue 了
丹尼尔:Soga
蛋先生:注意,压轴要登场了哦,现在让我们来请出大名鼎鼎的 Agent 吧
from langchain import hub from langchain.agents import AgentExecutor, create_json_chat_agent from langchain.tools import tool from langchain_community.chat_models.fireworks import ChatFireworks @tool def leng(word: str) -> str: """Please use this tool if you want to find the length of the word.""" return len(word) @tool def lower(word: str) -> str: """Please use this tool if you need to change the word to lowercase.""" return f'dx_{word.lower()}' tools = [leng, lower] model = ChatFireworks(model="accounts/fireworks/models/llama-v2-70b-chat") prompt = hub.pull("hwchase17/react-chat-json") agent = create_json_chat_agent(model, tools, prompt, stop_sequence=False) agent_executor = AgentExecutor( agent=agent, tools=tools, verbose=True, handle_parsing_errors=True, max_iterations=5) res = agent_executor.invoke({"input": "Make this word lowercase: 'Daniel'"}) print(res)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
{'input': "Make this word lowercase: 'Daniel'", 'output': "The lowercase version of 'Daniel' is 'dx_daniel'"}
- 1
丹尼尔:好耶,快点讲解一下吧
蛋先生:首先我们声明了两个工具:一个是 leng(用于求字符串长度),一个是 lower(用于将字符串变成小写)。这里为了证明结果是通过我们的工具来得到结果的,所以特意在 lower 的实现中加了个 dx_ 前缀
丹尼尔:等等,hub.pull("hwchase17/react-chat-json") 是什么神秘代码?
蛋先生:这是 LangChain hub 社区上共享的用于实现 Agent 的众多 Prompt 中的一个,你可以在这里找到很多有用的 Prompt。毕竟,语言工程也是一种艺术,也是需要实践积累的。
丹尼尔:明白,请继续
蛋先生:通过 Agent,语言模型就可以根据输入自行判断应该使用哪个工具了
丹尼尔:哇,这太神奇了!我对它是怎么自行判断很感兴趣
蛋先生:简单来说,语言模型可以根据输入,再根据各个工具的描述,来判断哪个工具更适合,然后将结果输出为可以让 LangChain 理解的执行指令(比如 JSON)
丹尼尔:太棒了!现在我对 LangChain 有了一个大致的了解,希望以后还能跟你继续深入探讨
蛋先生:机会有滴是,咱们后会有期!ヾ( ̄▽ ̄)ByeBye

