
- 1深度生成模型阅读笔记(二)——自回归模型
- 2《认知觉醒》+《认知驱动》_认知觉醒pdf
- 3【python笔记】pandas读取csv_python pandas读取csv文件
- 4安装postman及汉化_postman汉化包
- 5构建无忧:探索 Linux 项目自动化构建神器-make/Makefile_makefile 自动化工程
- 6巨杉数据库sequoiadb助理工程师(SCDA)初级考试笔记(一)_巨衫数据库捉取快照的命令是什么
- 7SLAM导航机器人零基础实战系列:(二)ROS入门——9.熟练使用rviz
- 8权限管理和设置测试的测试点_项目测试点权限管理检查表怎么填
- 9Go最新使用Golang Web3库进行区块链开发_go语言有web3库吗(4),经典实战教程_go区块链教程
- 10使用neo4j-import工具导入数据
Apache Doris 2.0-beta 盲测性能 10 倍提升,更统一的多场景极速分析体验!_doris 数据高频写入
赞
踩
亲爱的社区小伙伴们,我们很高兴地向大家宣布,Apache Doris 2.0-beta 版本已于 2023 年 7 月 3 日正式发布!在 2.0-beta 版本中有超过 255 位贡献者为 Apache Doris 提交了超过 3500 个优化与修复,欢迎大家下载使用!
下载链接:https://doris.apache.org/download
GitHub 源码:https://github.com/apache/doris/tree/branch-2.0
在今年年初举办的 Doris Summit 年度峰会上,我们曾发布了 Apache Doris 的 2023 年 Roadmap 并提出了新的愿景:
我们希望用户可以基于 Apache Doris 构建多种不同场景的数据分析服务、同时支撑在线与离线的业务负载、高吞吐的交互式分析与高并发的点查询;通过一套架构实现湖和仓的统一、在数据湖和多种异构存储之上提供无缝且极速的分析服务;也可通过对日志/文本等半结构化乃至非结构化的多模数据进行统一管理和分析、来满足更多样化数据分析的需求。
这是我们希望 Apache Doris 能够带给用户的价值,不再让用户在多套系统之间权衡,仅通过一个系统解决绝大部分问题,降低复杂技术栈带来的开发、运维和使用成本,最大化提升生产力。
面对海量数据的实时分析难题,这一愿景的实现无疑需要克服许多困难,尤其是在应对实际业务场景的真实诉求中更是遭遇了许多挑战:
- 如何保证上游数据实时高频写入的同时保证用户的查询稳定;
- 如何在上游数据更新及表结构变更的同时保证在线服务的连续性;
- 如何实现结构化与半结构化数据的统一存储与高效分析;
- 如何同时应对点查询、报表分析、即席查询、ETL/ELT 等不同的查询负载且保证负载间相互隔离?
- 如何保证复杂 SQL 语句执行的高效性、大查询的稳定性以及执行过程的可观测性?
- 如何更便捷地集成与访问数据湖以及各种异构数据源?
- 如何在大幅降低数据存储和计算资源成本的同时兼顾高性能查询?
- ……
秉持着“将易用性留给用户、将复杂性留给自己”的原则,为了克服以上一系列挑战,从理论基础到工程实现、从理想业务场景到极端异常 Case、从内部测试通过到大规模生产可用,我们耗费了更多的时间与精力在功能的开发、验证、持续迭代与精益求精上。值得庆祝的是,在经过近半年的开发、测试与稳定性调优后,Apache Doris 终于迎来了 2.0-beta 版本的正式发布!而这一版本的成功发布也使得我们的愿景离现实更进一步!
盲测性能 10 倍以上提升!
全新的查询优化器
高性能是 Apache Doris 不断追求的目标。过去一年在 Clickbench、TPC-H 等公开测试数据集上的优异表现,已经证明了其在执行层以及算子优化方面做到了业界领先,但从 Benchmark 到真实业务场景之间还存在一定距离:
- Benchmark 更多是真实业务场景的抽象、提炼与简化,而现实场景往往可能面临更复杂的查询语句,这是测试所无法覆盖的;
- Benchmark 查询语句可枚举、可针对性进行调优,而真实业务场景的调优极度依赖工程师的心智成本、调优效率往往较为低下且过于消耗工程师人力;
基于此,我们着手研发了现代架构的全新查询优化器,并在 Apache Doris 2.0-beta 版本全面启用。全新查询优化器采取了更先进的 Cascades 框架、使用了更丰富的统计信息、实现了更智能化的自适应调优,在绝大多数场景无需任何调优和 SQL 改写即可实现极致的查询性能,同时对复杂 SQL 支持得更加完备、可完整支持 TPC-DS 全部 99 个 SQL。
我们对全新查询优化器的执行性能进行了盲测,仅以 TPC-H 22 个 SQL 为例 ,全新优化器在未进行任何手工调优和 SQL 改写的情况下 查询耗时,盲测性能提升了超过 10 倍!而在数十个 2.0 版本用户的真实业务场景中,绝大多数原始 SQL 执行效率得以极大提升,真正解决了人工调优的痛点!
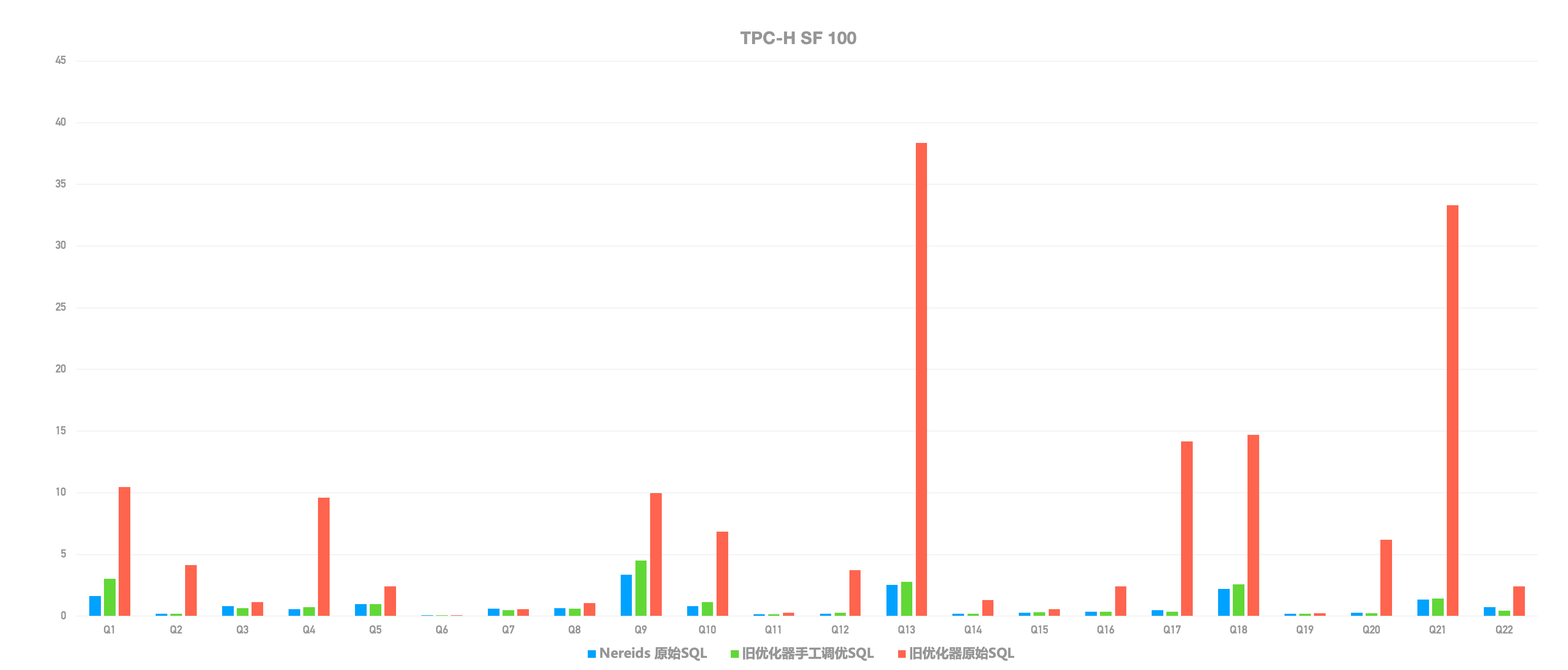
参考文档:https://doris.apache.org/zh-CN/docs/dev/query-acceleration/nereids
如何开启:SET enable_nereids_planner=true 在 Apache Doris 2.0-beta 版本中全新查询优化器已经默认开启,通过调用 Analyze 命令收集统计信息。
自适应的 Pipeline 执行引擎
过去 Apache Doris 的执行引擎是基于传统的火山模型构建,为了更好利用多机多核的并发能力,过去我们需要手动设置执行并发度(例如将 parallel_fragment_exec_instance_num 这一参数从默认值 1 手工设置为 8 或者 16),在存在大量查询任务时存在一系列问题:
- 大查询、小查询需要设置不同的instance 并发度,系统不能做到自适应调整;
- Instance 算子占用线程阻塞执行,大量查询任务将导致执行线程池被占满、无法响应后续请求,甚至出现逻辑死锁;
- Instance 线程间的调度依赖于系统调度机制,线程进行反复切换将产生额外的性能开销;
- 在不同分析负载并存时,Instance 线程间可能出现 CPU 资源争抢的情况,可能导致大小查询、不同租户之间相互受影响;
针对以上问题,Apache Doris 2.0 引入了 Pipeline 执行模型作为查询执行引擎。在 Pipeline 执行引擎中,查询的执行是由数据来驱动控制流变化的, 各个查询执行过程之中的阻塞算子被拆分成不同 Pipeline,各个 Pipeline 能否获取执行线程调度执行取决于前置数据是否就绪,因此实现了以下效果:
- Pipeline 执行模型通过阻塞逻辑将执行计划拆解成 Pipeline Task,将 Pipeline Task 分时调度到线程池中,实现了阻塞操作的异步化,解决了 Instance 长期占用单一线程的问题。
- 可以采用不同的调度策略,实现 CPU 资源在大小查询间、不同租户间的分配,从而更加灵活地管理系统资源。
- Pipeline 执行模型还采用了数据池化技术,将单个数据分桶中的数据进行池化,从而解除分桶数对 Instance 数量的限制,提高 Apache Doris 对多核系统的利用能力,同时避免了线程频繁创建和销毁的问题。
通过 Pipeline 执行引擎,Apache Doris 在混合负载场景中的查询性能和稳定性都得以进一步提升。
参考文档:https://doris.apache.org/zh-CN/docs/dev/query-acceleration/pipeline-execution-engine
如何开启:Set enable_pipeline_engine = true该功能在 Apache Doris 2.0 版本中将默认开启,BE 在进行查询执行时默认将 SQL 的执行模型转变 Pipeline 的执行方式。parallel_pipeline_task_num代表了 SQL 查询进行查询并发的 Pipeline Task 数目。Apache Doris 默认配置为0,此时 Apache Doris 会自动感知每个 BE 的 CPU 核数并把并发度设置为 CPU 核数的一半,用户也可以实际根据自己的实际情况进行调整。对于从老版本升级的用户,建议用户将该参数设置成老版本中parallel_fragment_exec_instance_num的值。
查询稳定性进一步提升
多业务资源隔离
随着用户规模的极速扩张,越来越多的用户将 Apache Doris 用于构建企业内部的统一分析平台。这一方面需要 Apache Doris 去承担更大规模的数据处理和分析,另一方面也需要 Apache Doris 同时去应对更多分析负载的挑战,而其中的关键在于如何保证不同负载能够在一个系统中稳定运行。
Apache Doris 2.0 版本中基于 Pipeline 执行引擎增加了 Workload 管理器 ,通过对 Workload 进行分组管理,以保证内存和 CPU 资源的精细化管控。
在过去版本中 Apache Doris 通过资源标签的方式进行了多租户资源隔离,可以通过节点资源划分来避免不同业务间的相互干扰,而 Workload Group 实现了更精细化的资源管控方式,通过将 Query 与 Workload Group 相关联,可以限制单个 Query 在 BE 节点上的 CPU 和内存资源的百分比,并可以配置开启资源组的内存软限制。当集群资源紧张时,将自动 Kill 组内占用内存最大的若干个查询任务以减缓集群压力。当集群资源空闲时,一旦 Workload Group 使用资源超过预设值时,多个 Workload 将共享集群可用空闲资源并自动突破阙值,继续使用系统内存以保证查询任务的稳定执行。
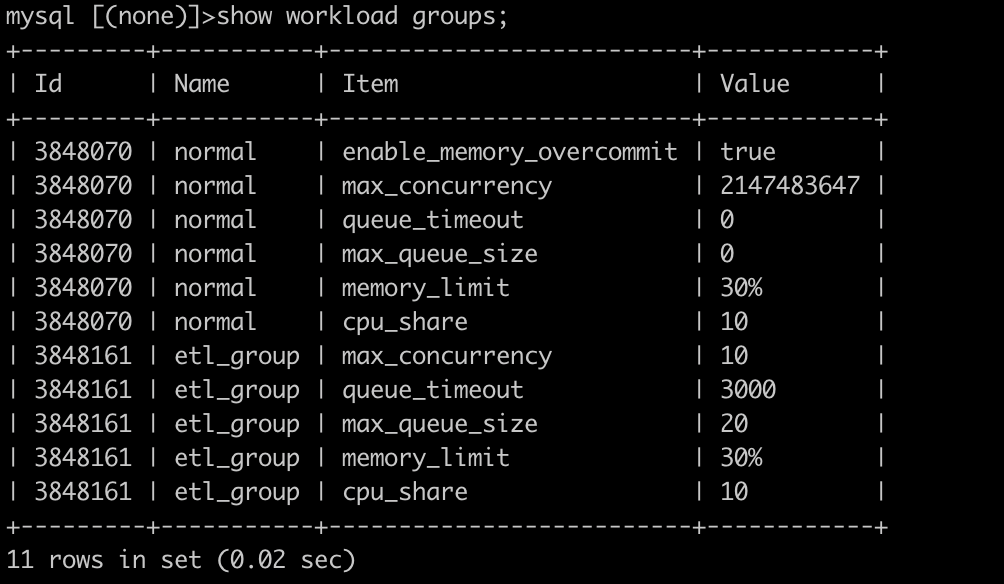
create workload group if not exists etl_group
properties (
"cpu_share"="10",
"memory_limit"="30%",
"max_concurrency" = "10",
"max_queue_size" = "20",
"queue_timeout" = "3000"
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
可以通过 Show 命令来查看创建的 Workload Group,例如:
作业排队
同时在 Workload Group 中我们还引入了查询排队的功能,在创建 Workload Group 时可以设置最大查询数,超出最大并发的查询将会进行队列中等待执行。
max_concurrency当前 Group允许的最大查询数,超过最大并发的查询到来时会进入排队逻辑;max_queue_size查询排队的长度,当队列满了之后,新来的查询会被拒绝;queue_timeout查询在队列中等待的时间,如果查询等待时间超过等待时间查询将会被拒绝,时间单位为毫秒;

参考文档:https://doris.apache.org/zh-CN/docs/dev/admin-manual/workload-group/
彻底告别 OOM
在内存充足时内存管理通常对用户是无感的,但真实场景中往往面临着各式各样的极端 Case,这些都将为内存性能和稳定性带来挑战,尤其是在面临内存资源消耗巨大的复杂计算和大规模作业时,由于内存 OOM 导致查询失败甚至可能造成 BE 进程宕机。
因此我们逐渐统一内存数据结构、重构 MemTracker、开始支持查询内存软限,并引入进程内存超限后的 GC 机制,同时优化了高并发的查询性能等。在 2.0 版本中我们引入了全新的内存管理框架,通过有效的内存分配、统计、管控,在 Benchmark、压力测试和真实用户业务场景的反馈中,基本消除了内存热点以及 OOM 导致 BE 宕机的问题,即使发生 OOM 通常也可依据日志定位内存位置并针对性调优,从而让集群恢复稳定,对查询和导入的内存限制也更加灵活,在内存充足时让用户无需感知内存使用。
通过以上一系列优化,Apache Doris 2.0 版本在应对复杂计算以及大规模 ETL/ELT 操作时,内存资源得以有效控制,系统稳定性表现更上一个台阶。
详细介绍:https://mp.weixin.qq.com/s/Z5N-uZrFE3Qhn5zTyEDomQ
高效稳定的数据写入
更高的实时数据写入效率
导入性能进一步提升
聚焦于实时分析,我们在过去的几个版本中在不断增强实时分析能力,其中端到端的数据实时写入能力是优化的重要方向,在 Apache Doris 2.0 版本中,我们进一步强化了这一能力。通过 Memtable 不使用 Skiplist、并行下刷、单副本导入等优化,使得导入性能有了大幅提升:
- 使用 Stream Load 对 TPC-H 144G lineitem 表原始数据进行三副本导入 48 buckets 的 Duplicate 表,吞吐量提升 100%。
- 使用 Stream Load 对 TPC-H 144G lineitem 表原始数据进行三副本导入 48 buckets 的 Unique Key 表,吞吐量提升 200%。
- 使用 insert into select 对 TPC-H 144G lineitem 表进行导入 48 buckets 的 Duplicate 表,吞吐量提升 50%。
- 使用 insert into select 对 TPC-H 144G lineitem 表进行导入 48 buckets 的 Unique Key 表,吞吐提升 150%。
数据高频写入更稳定
在高频数据写入过程中,小文件合并和写放大问题以及随之而来的磁盘 I/O和 CPU 资源开销是制约系统稳定性的关键,因此在 2.0 版本中我们引入了 Vertical Compaction 以及 Segment Compaction,用以彻底解决 Compaction 内存问题以及写入过程中的 Segment 文件过多问题,资源消耗降低 90%,速度提升 50%,内存占用仅为原先的 10%。
详细介绍:https://mp.weixin.qq.com/s/BqiMXRJ2sh4jxKdJyEgM4A
数据表结构自动同步
在过去版本中我们引入了毫秒级别的 Schema Change,而在最新版本 Flink-Doris-Connector 中,我们实现了从 MySQL 等关系型数据库到 Apache Doris 的一键整库同步。在实际测试中单个同步任务可以承载数千张表的实时并行写入,从此彻底告别过去繁琐复杂的同步流程,通过简单命令即可实现上游业务数据库的表结构及数据同步。同时当上游数据结构发生变更时,也可以自动捕获 Schema 变更并将 DDL 动态同步到 Doris 中,保证业务的无缝运行。
详细介绍:https://mp.weixin.qq.com/s/Ur4VpJtjByVL0qQNy_iQBw
主键模型支持部分列更新
在 Apache Doris 1.2 版本中我们引入了 Unique Key 模型的 Merg-on-Write 写时合并模式,在上游数据高频写入和更新的同时可以保证下游业务的高效稳定查询,实现了实时写入和极速查询的统一。 而 2.0 版本我们对 Unique Key 模型进行了全面增强。在功能上,支持了新的部分列更新能力,在上游多个源表同时写入时无需提前处理成宽表,直接通过部分列更新在写时完成 Join,大幅简化了宽表的写入流程。
在性能上,2.0 版本大幅增强了 Unique Key 模型 Merge-on-Write 的大数据量写入性能和并发写入能力,大数据量导入较 1.2 版本有超过 50% 的性能提升,高并发导入有超过 10 倍的性能提升,并通过高效的并发处理机制来彻底解决了 publish timeout(Error -3115) 问题,同时由于 Doris 2.0 高效的 Compaction 机制,也不会出现 too many versions (Error-235) 问题。这使得 Merge-on-Write 能够在更广泛的场景下替代 Merge-on-Read 实现,同时我们还利用部分列更新能力来降低 UPDATE 语句和 DELETE 语句的计算成本,整体性能提升约 50%。
部分列更新的使用示例(Stream Load):
例如有表结构如下
mysql> desc user_profile;
+------------------+-----------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------------+-----------------+------+-------+---------+-------+
| id | INT | Yes | true | NULL | |
| name | VARCHAR(10) | Yes | false | NULL | NONE |
| age | INT | Yes | false | NULL | NONE |
| city | VARCHAR(10) | Yes | false | NULL | NONE |
| balance | DECIMALV3(9, 0) | Yes | false | NULL | NONE |
| last_access_time | DATETIME | Yes | false | NULL | NONE |
+------------------+-----------------+------+-------+---------+-------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
用户希望批量更新最近 10s 发生变化的用户的余额和访问时间,可以把数据组织在如下 csv 文件中
1,500,2023-07-03 12:00:01
3,23,2023-07-03 12:00:02
18,9999999,2023-07-03 12:00:03
- 1
- 2
- 3
然后通过 Stream Load,增加 Header partial_columns:true,并指定要导入的列名即可完成更新
curl --location-trusted -u root: -H "partial_columns:true" -H "column_separator:," -H
"columns:id,balance,last_access_time" -T /tmp/test.csv http://127.0.0.1:48037/api/db1/user_profile/_stream_load
- 1
- 2
极致弹性与存算分离
过去 Apache Doris 凭借在易用性方面的诸多设计帮助用户大幅节约了计算与存储资源成本,而面向未来的云原生架构,我们已经走出了坚实的一步。
从降本增效的趋势出发,用户对于计算和存储资源的需求可以概括为以下几方面:
- 计算资源弹性:面对业务计算高峰时可以快速进行资源扩展提升效率,在计算低谷时可以快速缩容以降低成本;
- 存储成本更低:面对海量数据可以引入更为廉价的存储介质以降低成本,同时存储与计算单独设置、相互不干预;
- 业务负载隔离:不同的业务负载可以使用独立的计算资源,避免相互资源抢占;
- 数据管控统一:统一 Catalog、统一管理数据,可以更加便捷地分析数据。
存算一体的架构在弹性需求不强的场景具有简单和易于维护的优势,但是在弹性需求较强的场景有一定的局限。而存算分离的架构本质是解决资源弹性的技术手段,在资源弹性方面有着更为明显的优势,但对于存储具有更高的稳定性要求,而存储的稳定性又会进一步影响到 OLAP 的稳定性以及业务的存续性,因此也引入了 Cache 管理、计算资源管理、垃圾数据回收等一系列机制。
而在与 Apache Doris 社区广大用户的交流中,我们发现用户对于存算分离的需求可以分为以下三类:
- 目前选择简单易用的存算一体架构,暂时没有资源弹性的需求;
- 欠缺稳定的大规模存储,要求在 Apache Doris 原有基础上提供弹性、负载隔离以及低成本;
- 有稳定的大规模存储,要求极致弹性架构、解决资源快速伸缩的问题,因此也需要更为彻底的存算分离架构;
为了满足前两类用户的需求,Apache Doris 2.0 版本中提供了可以兼容升级的存算分离方案:
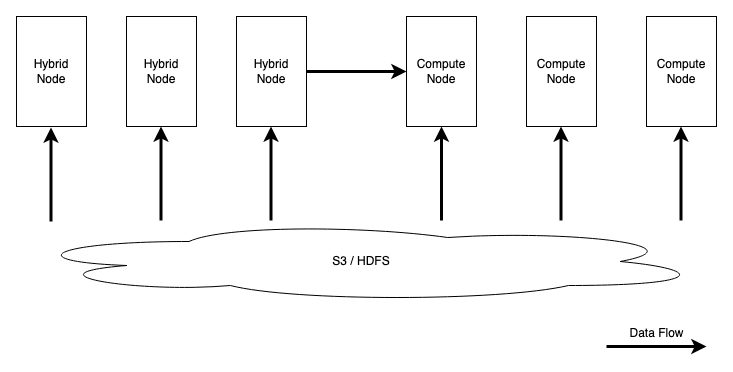
第一种,计算节点。2.0 版本中我们引入了无状态的计算节点 Compute Node,专门用于数据湖分析。相对于原本存储计算一体的混合节点,Compute Node 不保存任何数据,在集群扩缩容时无需进行数据分片的负载均衡,因此在数据湖分析这种具有明显高峰的场景中可以灵活扩容、快速加入集群分摊计算压力。同时由于用户数据往往存储在 HDFS/S3 等远端存储中,执行查询时查询任务会优先调度到 Compute Node 执行,以避免内表与外表查询之间的计算资源抢占。
参考文档:https://doris.apache.org/zh-CN/docs/dev/advanced/compute_node
第二种,冷热分层。在存储方面,冷热数据数据往往面临不同频次的查询和响应速度要求,因此通常可以将冷数据存储在成本更低的存储介质中。在过去版本中 Apache Doris 支持对表分区进行生命周期管理,通过后台任务将热数据从 SSD 自动冷却到 HDD,但 HDD 上的数据是以多副本的方式存储的,并没有做到最大程度的成本节约,因此对于冷数据存储成本仍然有较大的优化空间。在 Apache Doris 2.0 版本中推出了冷热数据分层功能 ,冷热数据分层功能使 Apache Doris 可以将冷数据下沉到存储成本更加低廉的对象存储中,同时冷数据在对象存储上的保存方式也从多副本变为单副本,存储成本进一步降至原先的三分之一,同时也减少了因存储附加的计算资源成本和网络开销成本。通过实际测算,存储成本最高可以降低超过 70%!
参考文档:https://doris.apache.org/zh-CN/docs/dev/advanced/cold_hot_separation
后续计算节点会支持查询冷数据和存储节点的数据,从而实现能兼容升级的存算分离方案。
 而为了满足第三类用户的需求,我们还将把 SelectDB Cloud 存算分离方案贡献回社区。这一方案在性能、功能成熟度、系统稳定性等方面经历了上百家企业生产环境的考验,后续功能合入的实际进展我们也将及时同步。
而为了满足第三类用户的需求,我们还将把 SelectDB Cloud 存算分离方案贡献回社区。这一方案在性能、功能成熟度、系统稳定性等方面经历了上百家企业生产环境的考验,后续功能合入的实际进展我们也将及时同步。
10 倍以上性价比的日志分析方案
从过去的实时报表和 Ad-hoc 等典型 OLAP 场景到 ELT/ETL、日志检索与分析等更多业务场景,Apache Doris 正在不断拓展应用场景的边界,而日志数据的统一存储与分析正是我们在 2.0 版本的重要突破。
过去业界典型的日志存储分析架构难以同时兼顾 高吞吐实时写入、低成本大规模存储与高性能文本检索分析,只能在某一方面或某几方面做权衡取舍。而在 Apache Doris 2.0 版本中,我们引入了全新倒排索引、以满足字符串类型的全文检索和普通数值/日期等类型的等值、范围检索,同时进一步优化倒排索引的查询性能、使其更加契合日志数据分析的场景需求,同时结合过去在大规模数据写入和低成本存储等方面的优势,实现了更高性价比的日志分析方案。
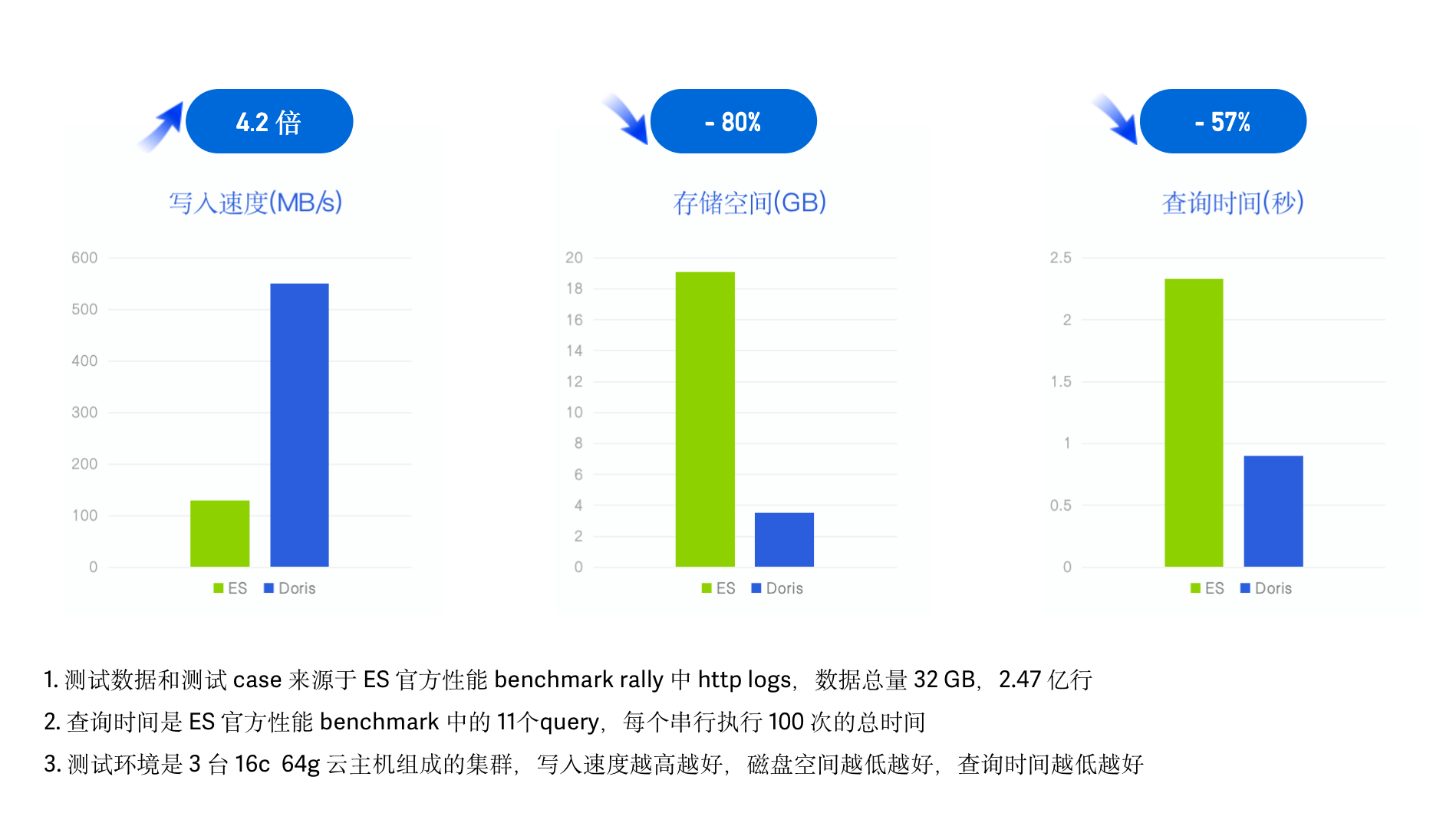
在相同硬件配置和数据集的测试表现上,Apache Doris 相对于 ElasticSearch 实现了日志数据写入速度提升 4 倍、存储空间降低 80%、查询性能提升 2 倍,再结合 Apache Doris 2.0 版本引入的冷热数据分层特性,整体性价比提升 10 倍以上。
除了日志分析场景的优化以外,在复杂数据类型方面,我们增加了全新的数据类型 Map/Struct,包括支持以上类型的高效写入、存储、分析函数以及类型之间的相互嵌套,以更好满足多模态数据分析的支持。
详细介绍:https://mp.weixin.qq.com/s/WJXKyudW8CJPqlUiAro_KQ
更全面、更高性能的数据湖分析能力
在 Apache Doris 1.2 版本中,我们发布了 Multi-Catalog 功能,支持了多种异构数据源的元数据自动映射与同步,实现了数据湖的无缝对接。依赖 数据读取、执行引擎、查询优化器方面的诸多优化,在标准测试集场景下,Apache Doris 在湖上数据的查询性能,较 Presto/Trino 有 3-5 倍的提升。
在 2.0 版本中,我们进一步对数据湖分析能力进行了加强,不但支持了更多的数据源,同时针对用户的实际生产环境做了诸多优化,相较于 1.2 版本,能够在真实工作负载情况下显著提升性能。
更多数据源支持
- 支持 Hudi Copy-on-Write 表的 Snapshot Query 以及 Merge-on-Read 表的 Read Optimized Query,后续将支持 Incremental Query 和 Time Trival。参考文档:https://doris.apache.org/zh-CN/docs/dev/lakehouse/multi-catalog/hudi
- JDBC Catalog 新增支持 Oceanbase,目前支持包括 MySQL、PostgreSQL、Oracle、SQLServer、Doris、Clickhouse、SAP HANA、Trino/Presto、Oceanbase 等近十种关系型数据库。参考文档:https://doris.apache.org/zh-CN/docs/dev/lakehouse/multi-catalog/jdbc
数据权限管控
- 支持通过 Apache Range 对 Hive Catalog 进行鉴权,可以无缝对接用户现有的权限系统。同时还支持可扩展的鉴权插件,为任意 Catalog 实现自定义的鉴权方式。 参考文档:https://doris.apache.org/zh-CN/docs/dev/lakehouse/multi-catalog/hive
性能进一步优化,最高提升数十倍
- 优化了大量小文件场景以及宽表场景的读取性能。通过小文件全量加载、小 IO 合并、数据预读等技术,显著降低远端存储的读取开销,在此类场景下,查询性能最高提升数十倍。
- 优化了 ORC/Parquet 文件的读取性能,相较于 1.2 版本查询性能提升一倍。
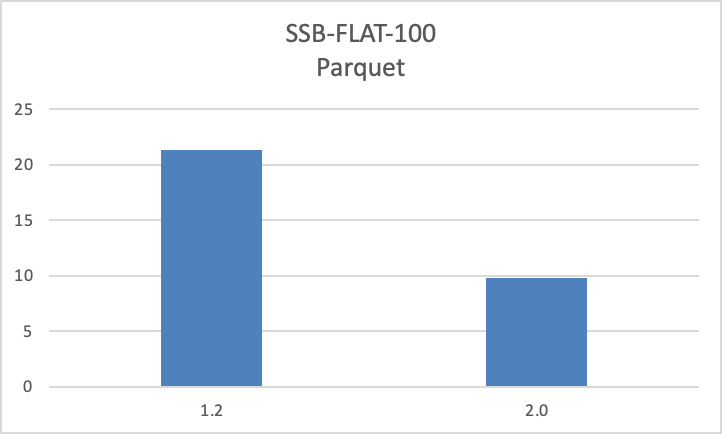
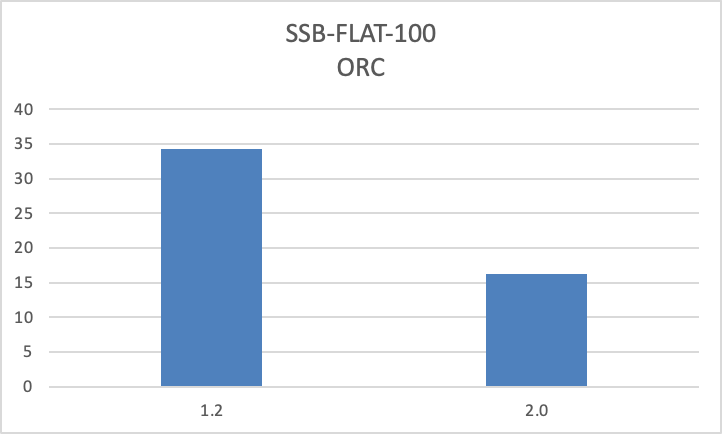
- 支持湖上数据的本地文件缓存。可以利用本地磁盘缓存 HDFS 或对象存储等远端存储系统上的数据,通过缓存加速访问相同数据的查询。在命中本地文件缓存的情况下,通过 Apache Doris 查询湖上数据的性能可与 Apache Doris 内部表持平,该功能可以极大提升湖上热数据的查询性能。参考文档:https://doris.apache.org/zh-CN/docs/dev/lakehouse/filecache
- 支持外表的统计信息收集。和 Apache Doris 内表一样,用户可以通过 Analyze 语句分析并收集指定外表的统计信息,结合 Nereids 全新查询优化器,能够更准确更智能地对复杂 SQL 进行查询计划的调优。以 TPC-H 标准测试数据集为例,无需手动改写 SQL 即可获得最优的查询计划并获得更好的性能表现。 参考文档:https://doris.apache.org/zh-CN/docs/dev/lakehouse/multi-catalog/
- 优化了 JDBC Catalog 的数据写回性能。通过 PrepareStmt 和批量方式,用户通过 INSERT INTO 命令、通过 JDBC Catalog 将数据写回到 MySQL、Oracle 等关系型数据库的性能提升数十倍。
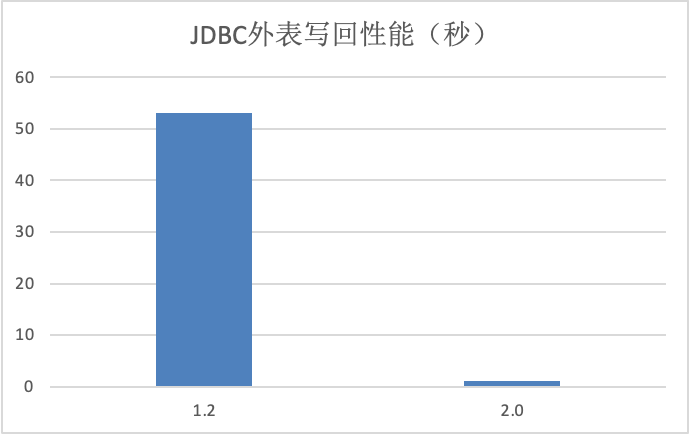
高并发数据服务支持
与复杂 SQL 和大规模 ETL 作业不同,在诸如银行交易流水单号查询、保险代理人保单查询、电商历史订单查询、快递运单号查询等 Data Serving 场景,会面临大量一线业务人员及 C 端用户基于主键 ID 检索整行数据的需求,在过去此类需求往往需要引入 Apache HBase 等 KV 系统来应对点查询、Redis 作为缓存层来分担高并发带来的系统压力。
对于基于列式存储引擎构建的 Apache Doris 而言,此类的点查询在数百列宽表上将会放大随机读取 IO,并且执行引擎对于此类简单 SQL 的解析、分发也将带来不必要的额外开销,往往需要更高效简洁的执行方式。因此在新版本中我们引入了全新的行列混合存储以及行级 Cache,使得单次读取整行数据时效率更高、大大减少磁盘访问次数,同时引入了点查询短路径优化、跳过执行引擎并直接使用快速高效的读路径来检索所需的数据,并引入了预处理语句复用执行 SQL 解析来减少 FE 开销。
通过以上一系列优化,Apache Doris 2.0 版本在并发能力上实现了数量级的提升!在标准 YCSB 基准测试中,单台 16 Core 64G 内存 4*1T 硬盘规格的云服务器上实现了单节点 30000 QPS 的并发表现,较过去版本点查询并发能力提升超 20 倍!基于以上能力,Apache Doris 可以更好应对高并发数据服务场景的需求,替代 HBase 在此类场景中的能力,减少复杂技术栈带来的维护成本以及数据的冗余存储。
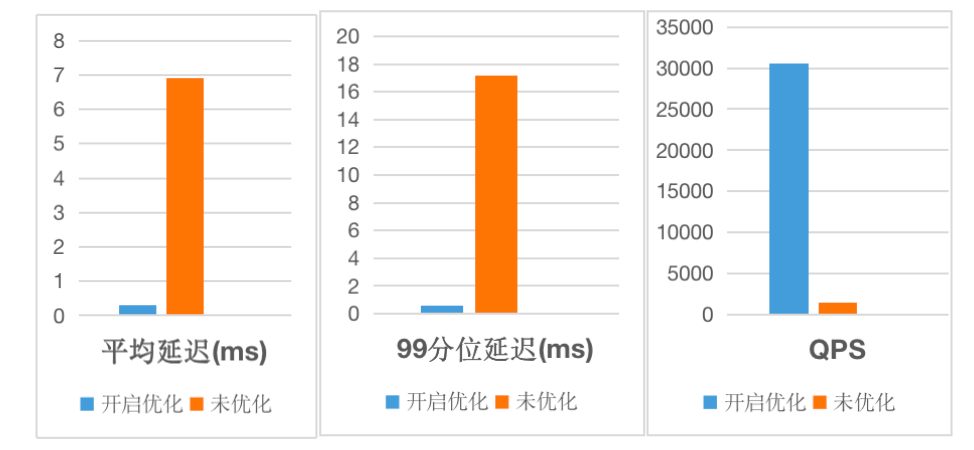
参考文档:https://doris.apache.org/zh-CN/docs/dev/query-acceleration/hight-concurrent-point-query
详细介绍:https://mp.weixin.qq.com/s/Ow77-kFMWXFxugFXjOPHhg
CCR 跨集群数据同步
为了满足用户多集群之间数据同步的需求,在过去需要定期通过 Backup/Restore 命令进行数据备份和恢复,操作较为复杂、数据同步时延高并且还需要中间存储。为了满足用户多集群的数据库表自动同步需求,在 2.0-beta 版本中我们增加了 CCR 跨集群数据同步的功能,能够在库/表级别将源集群的数据变更同步到目标集群、以提升在线服务的数据可用性并更好地实现了读写负载分离以及多机房备份。
支持 Kubernetes 容器化部署
在过去 Apache Doris 是基于 IP 通信的,在 K8s 环境部署时由于宿主机故障发生 Pod IP 漂移将导致集群不可用,在 2.0 版本中我们支持了 FQDN,使得 Apache Doris 可以在无需人工干预的情况下实现节点自愈,因此可以更好应对 K8s 环境部署以及灵活扩缩容。
参考文档:https://doris.apache.org/zh-CN/docs/dev/install/k8s-deploy/
其他升级注意事项
- 1.2-lts 可以滚动升级到 2.0-beta,2.0-alpha 可以停机升级到 2.0-beta;
- 查询优化器开关默认开启 enable_nereids_planner=true;
- 系统中移除了非向量化代码,所以参数将不再生效enable_vectorized_engine;
- 新增参数 enable_single_replica_compaction;
- 默认使用 datev2, datetimev2, decimalv3 来创建表,不支持 datev1,datetimev1, decimalv2 创建表;
- 在 JDBC 和 Iceberg Catalog 中默认使用decimalv3;
- date type 新增 AGG_STATE;
- backend 表去掉 cluster 列;
- 为了与 BI 工具更好兼容,在 show create table 时,将 datev2 和 datetimev2 显示为 date 和 datetime。
- 在 BE 启动脚本中增加了 max_openfiles 和 swap 的检查,所以如果系统配置不合理,be 有可能会启动失败;
- 禁止在 localhost 访问 FE 时无密码登录;
- 当系统中存在 Multi-Catalog 时,查询 information schema 的数据默认只显示 internal catalog 的数据;
- 限制了表达式树的深度,默认为 200;
- array string 返回值 单引号变双引号;
- 对 Doris的进程名重命名为 DorisFE 和 DorisBE;
踏上 2.0 之旅
距离 Apache Doris 2.0-alpha 版本发布已经有一个半月之久,这一段时间内我们在加速核心功能特性开发的同时、还收获到了数百家企业对于新版本的切身体验与真实反馈,这些来自真实业务场景的反馈对于功能的打磨与进一步完善有着极大的帮助。因此 2.0-beta 版本无论在功能的完整度还是系统稳定性上,都已经具备了更佳的使用体验,欢迎所有对于 2.0 版本新特性有需求的用户部署升级。
如果您在调研、测试以及部署升级 2.0 版本的过程中有任何问题,欢迎提交问卷信息,届时将由社区核心贡献者提供 1-1 专项支持。我们也期待 2.0 版本为更多社区用户提供实时统一的分析体验,相信 Apache Doris 2.0 版本会成为您在实时分析场景中的最理想选择。

