
- 1字节跳动安全Ai挑战赛-基于文本和多模态数据的风险识别总结_多模态文本检测
- 2腾讯云linux远程桌面连接不上去,腾讯云服务器无法远程桌面连接的解决办法
- 3【C++、python】使用OpenCV处理RAW图像数据(读取raw文件、切割raw为图片、根据灰度阈值分割raw输出点云txt、三维模型分割)_c++怎么将raw图转为4个通道
- 4文件上传--Upload-labs--Pass12--(POST)00绕过_upload files pass-12
- 5三入职场 - 你可以从我身上学到这些(附毕业Vlog)
- 6Enigma Virtual Box 9.2非常棒的单文件打包工具
- 7Agent AI智能体的未来角色、发展路径及其面临的挑战_agent还可以应用于教育、医疗、游戏等领域,为人们提供更加智能化、个性化的服务和
- 8git 子仓库(submodule)操作_gitlab submodule
- 9计算机设计文献参考,优秀计算机设计论文参考文献 计算机设计论文参考文献数量是多少...
- 10Vue面试题学起来
OrangePi AIpro 开箱初体验及语音识别样例
赞
踩
OrangePi AIpro 开箱初体验及语音识别样例
一、 前言
首先非常感谢官方大大给予这次机会,让我有幸参加此次活动。


OrangePi AIpro联合华为精心打造,采用昇腾AI技术路线,具体为4核64位处理器+AI处理器,集成图形处理器,支持8TOPS AI算力,拥有8GB/16GB LPDDR4X,可以外接32GB/64GB/128GB/256GB eMMC模块,支持双4K高清输出。并且OrangePi AIpro引用了相当丰富的接口,包括两个HDMI输出、GPIO接口、Type-C电源接口、支持SATA/NVMe SSD 2280的M.2插槽、TF插槽、千兆网口、两个USB3.0、一个USB Type-C 3.0、一个Micro USB(串口打印调试功能)、两个MIPI摄像头、一个MIPI屏等,预留电池接口,可广泛适用于AI边缘计算、深度视觉学习及视频流AI分析、视频图像分析、自然语言处理、智能小车、机械臂、人工智能、无人机、云计算、AR/VR、智能安防、智能家居等领域,覆盖 AIoT各个行业。 Orange Pi AIpro支持Ubuntu、openEuler操作系统,满足大多数AI算法原型验证、推理应用开发的需求,总之是非常的nice。
二、 开发板介绍
1、 接口详情
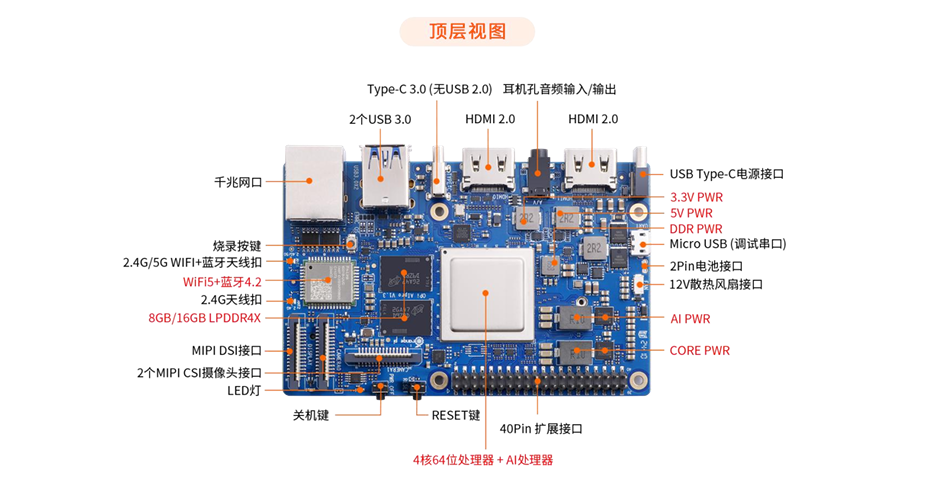


如图所见,我们看到它的功能是十分丰富的,并且还支持接入其他外设接口,扩展非常的方便。
2、 烧录镜像
2.1、事先准备
首先我们需要准备:OrangePi AIpro(包括主板和电源)、SD卡(用于装载镜像运行开发板)、读卡器(这里配置选择USB)、PC(笔记本或台式机)、显示器、双头HDMI线、键盘(可以外接USB)、鼠标(可以外接USB)。
2.2、烧写镜像到SD卡
(1)下载资料
我们打开官方网站,点击下载按钮,下载资料。

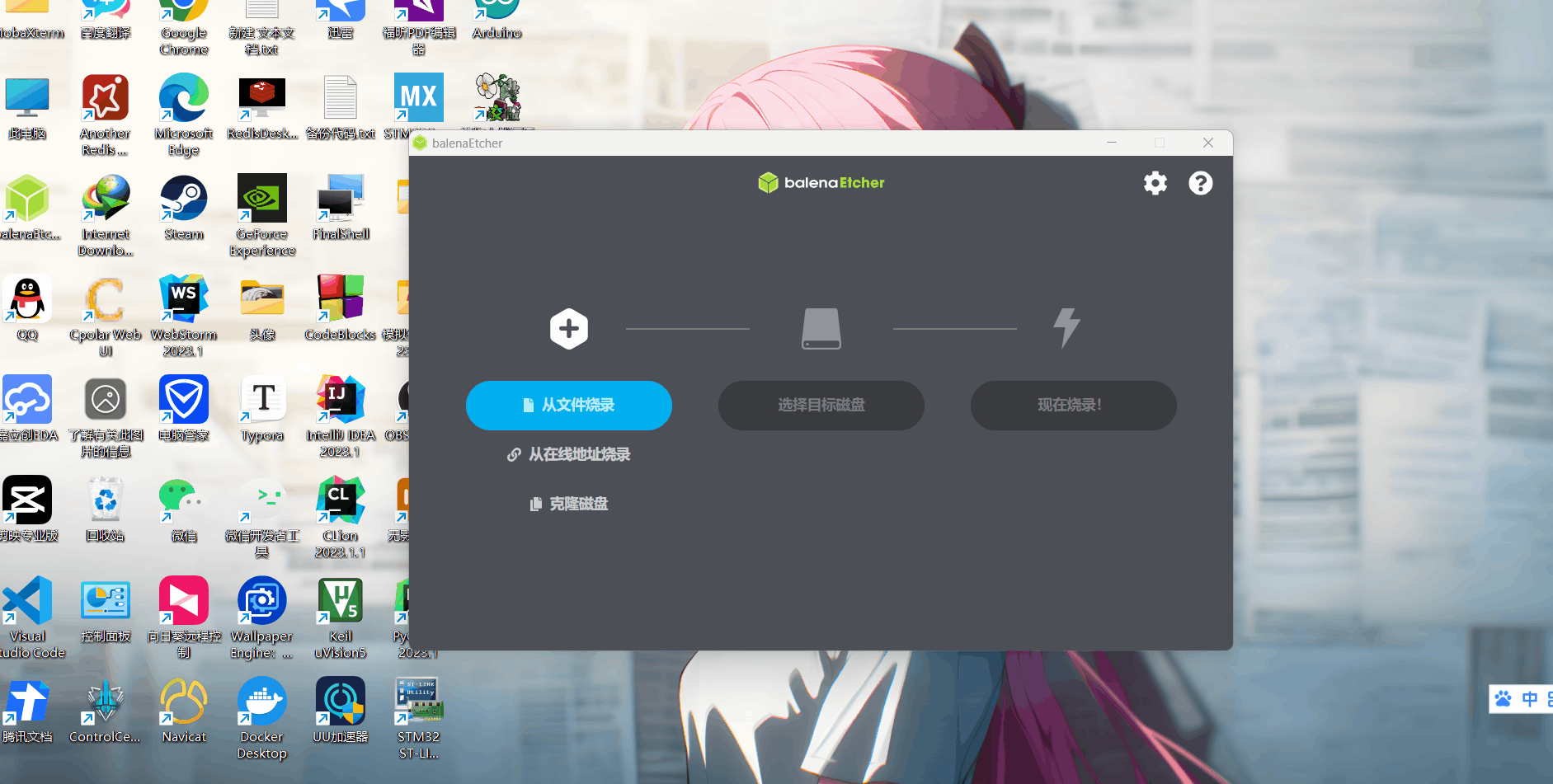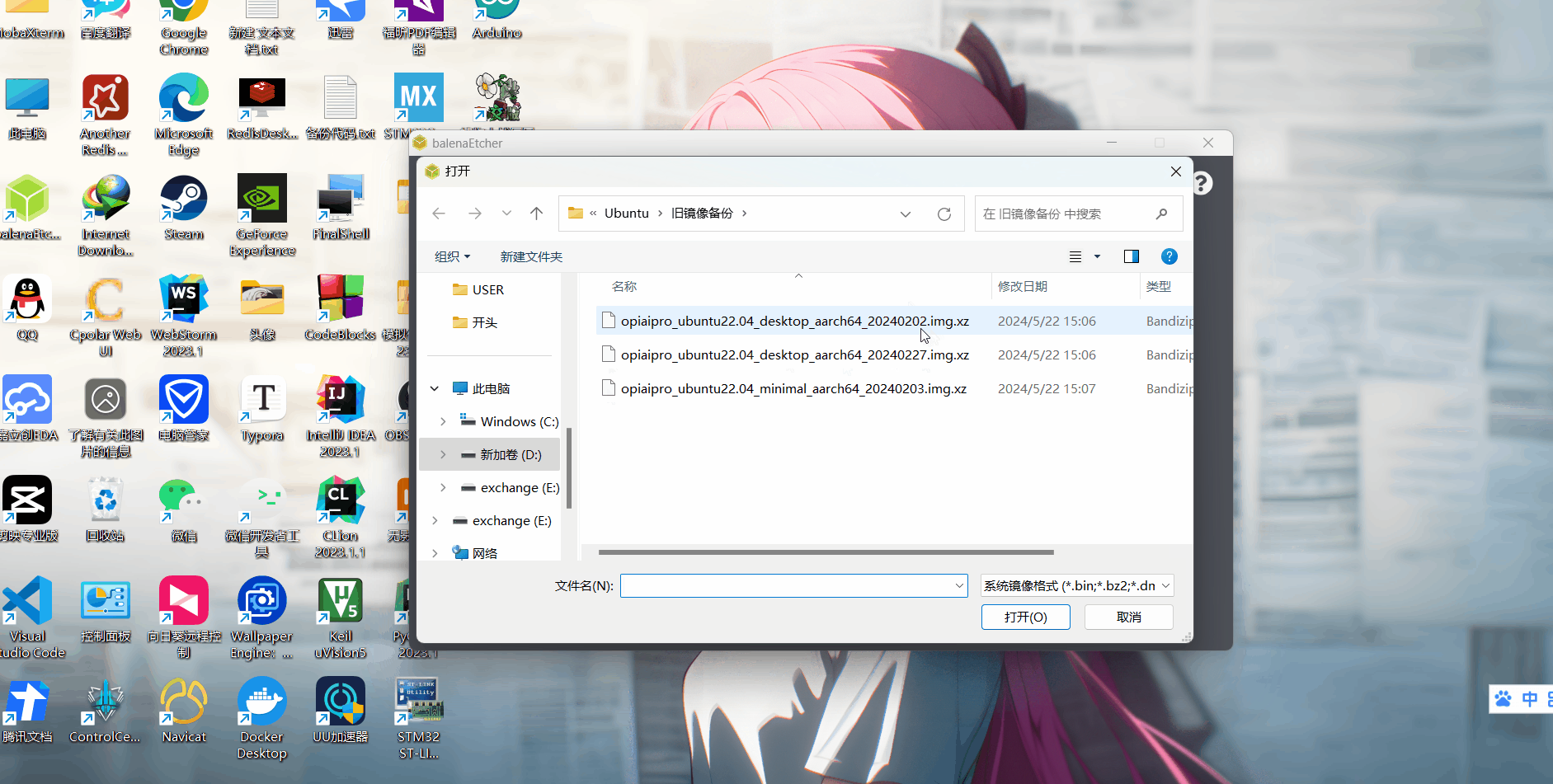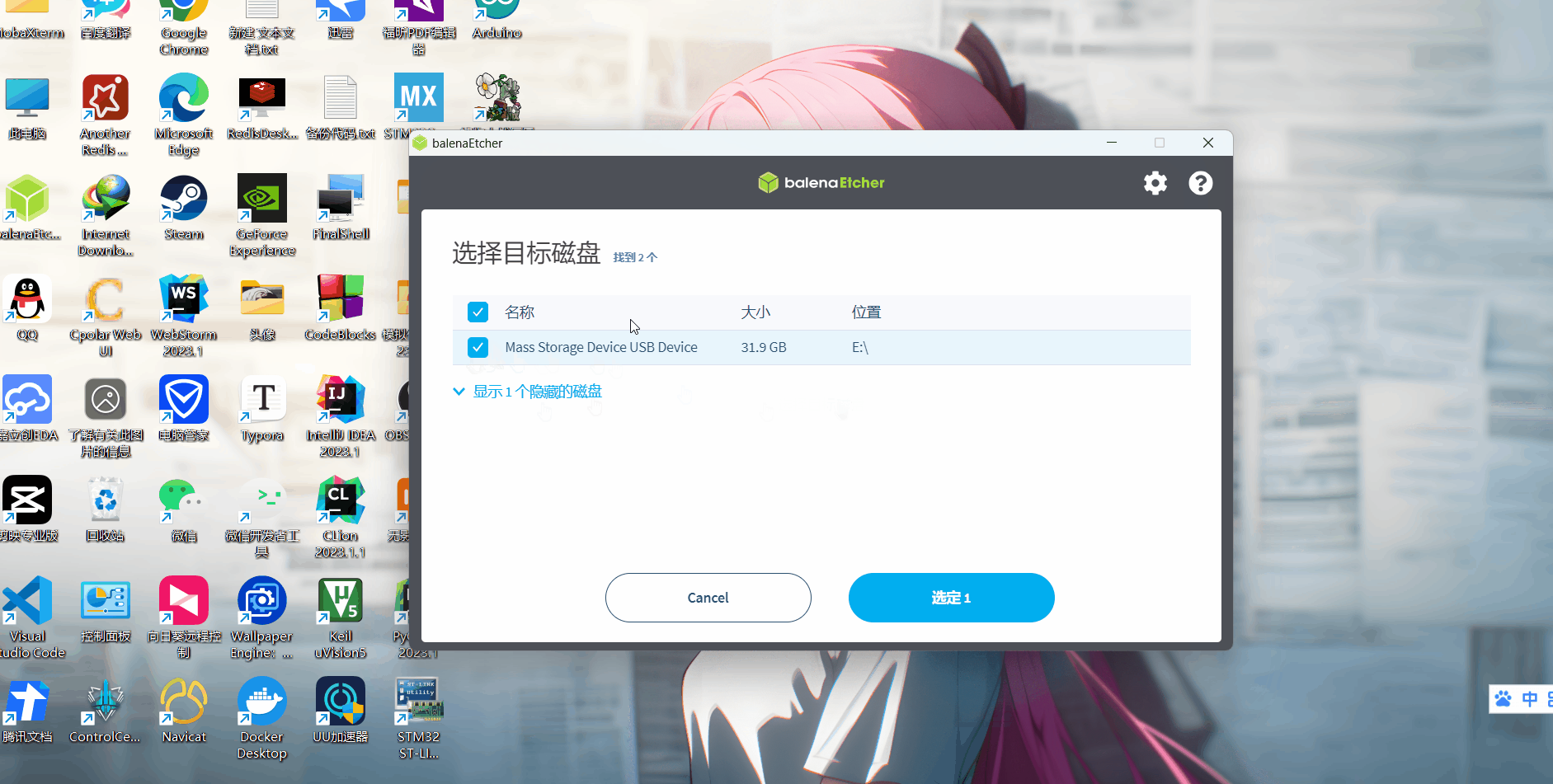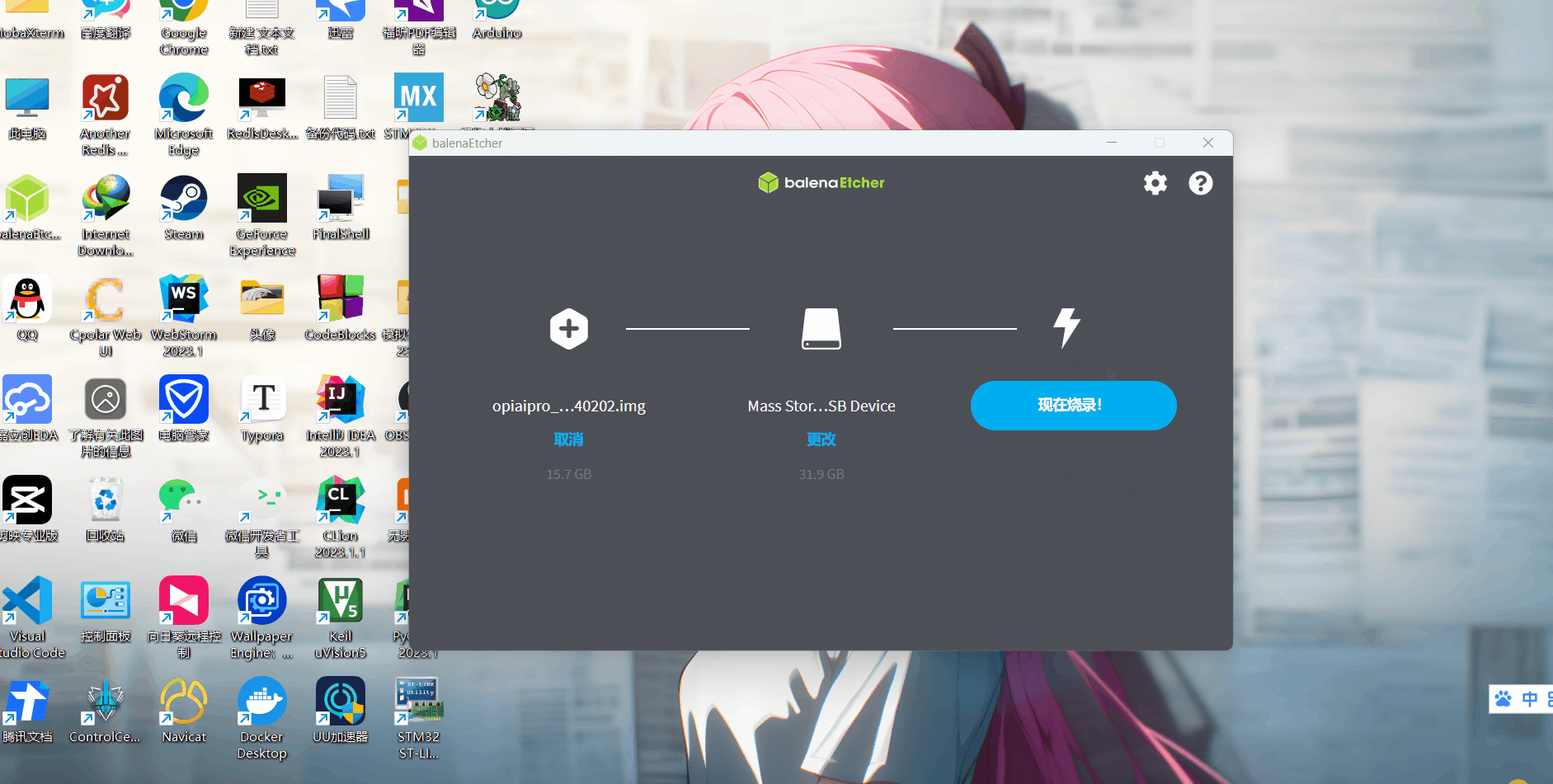
官方工具和ubuntu镜像都在百度网盘,分别根据页面提示提取文件,并在以下目录中获取文件后,保存在PC机上,烧录工具使用的是balenaEtcher。
ubuntu镜像:opiaipro_ubuntu22.04_desktop_aarch64_*.img.xz
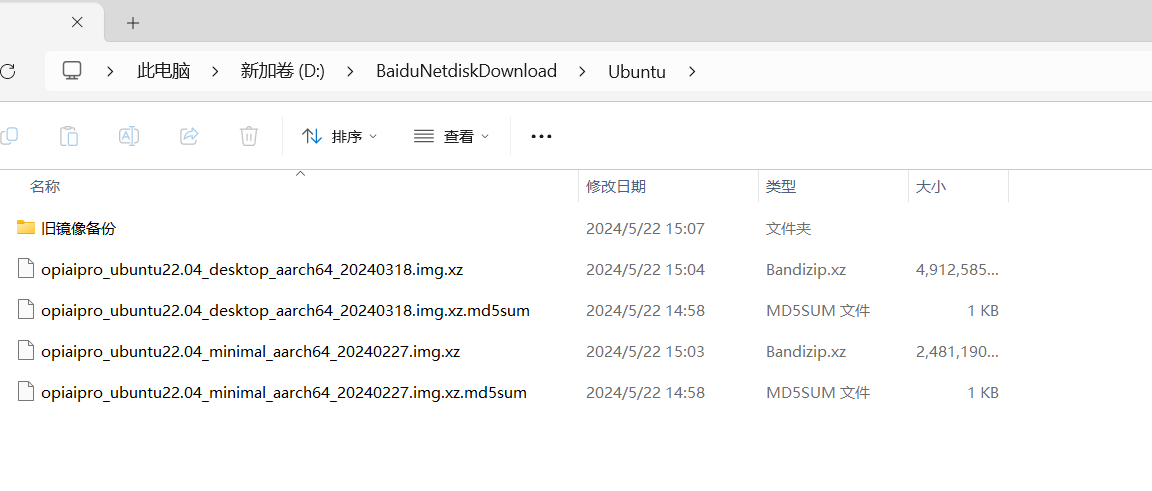

注:ubuntu镜像我们尽量使用旧版本的,旧版本更稳定,在本人的实际安装中,使用版本为3xx会烧录失败,但在使用旧版本,在本人的亲测下,旧版本的基本不会出现烧录失败的情况,所以下面我所使用的是2xx的。
(2)烧录
将SD卡插入读卡器,再将读卡器插入PC机。


然后启动烧录工具balenaEtcher,根据提示,依次“从文件烧录”-》“选择目标磁盘”-》“开始烧录!”,因为之前烧录了,所以我这里就不点了,烧录需要耐心等待下。

烧录完成之后需要验证,验证也是自动完成的,我们耐心等待,完成之后显示烧录成功。
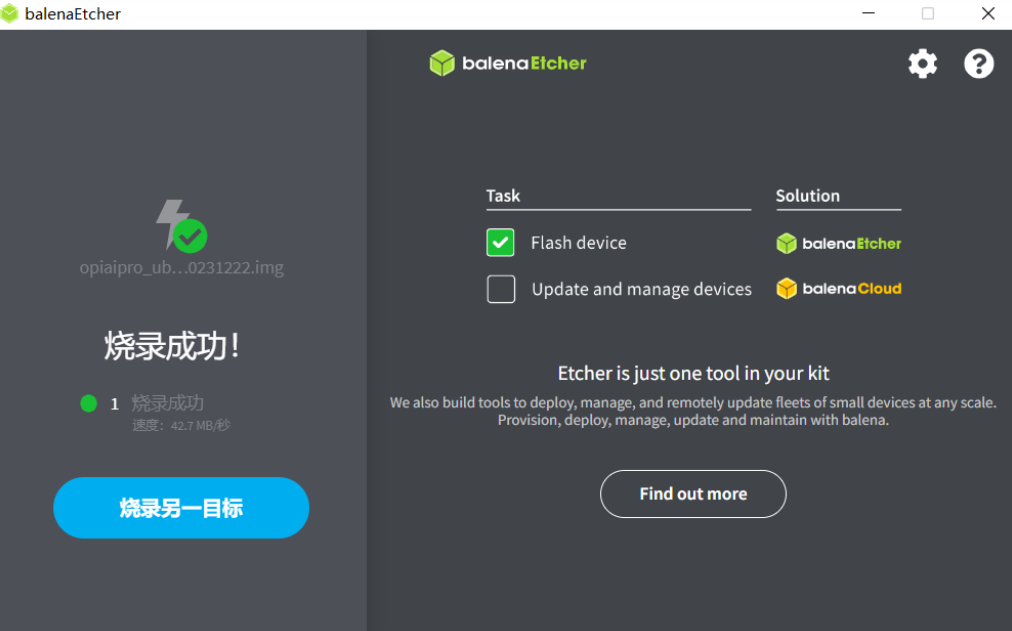

2.3、启动OrangePi AIpro系统
我们将烧录好的SD卡插入开发板的SD插槽,然后将开发板的电源线接上、两个USB接键盘与鼠标、使用双头HDMI线接显示器,如下图。


插入上电完成之后,等待一会,显示器就会显示登录界面了。


输入HwHiAiUser用户名登录密码(默认为Mind@123)登录开发板,进入主界面如下图所示,登录后请修改默认密码,并妥善保管新密码。


三、运行案例:语音识别
1、准备工作
首先为了操作方便,我们可以进入系统然后连接WIFI,打开终端,输入ifconfig 查看IP地址。


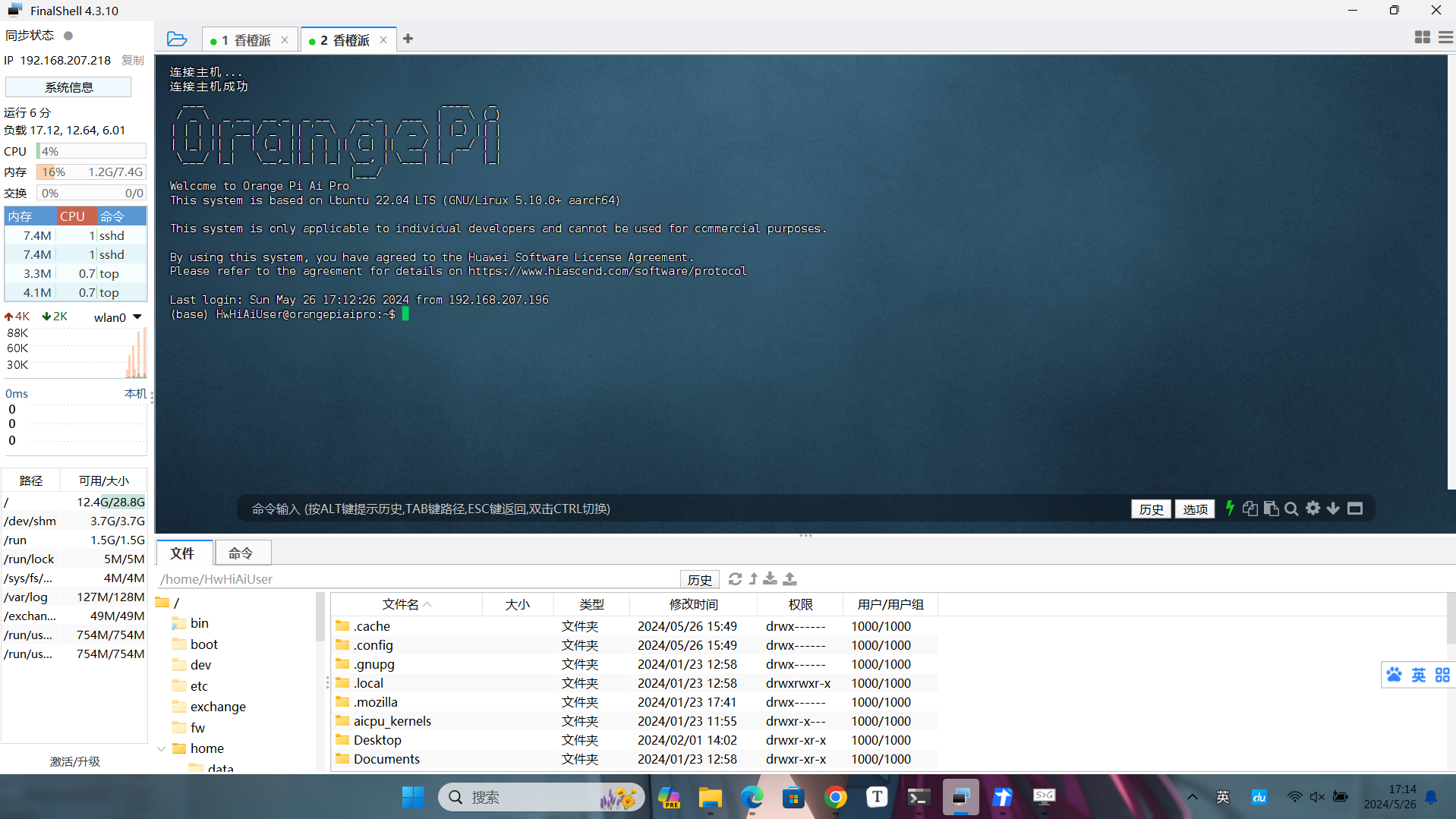
在个人PC 这里打开 FinalShell 工具,使用SSH 连接,填写好名称,主机(这就是IP地址),用户名与密码等参数,点击确定,完成连接。

3、 播放音频与录音
2.1、播放音频
准备好3.5mm口的耳机,将耳机插入开发板的3.5mm耳机接口中。


然后接下来进入到音频测试程序所在的目录中,打开FinalShell 工具,敲指令。
- sudo-i # 切换管理员权限,输入密码进入
- cd /opt/opi_test/audio
输入ls 查看目录下的文件,当然 FinalShell 也会已树形文件结构实时同步文件信息。
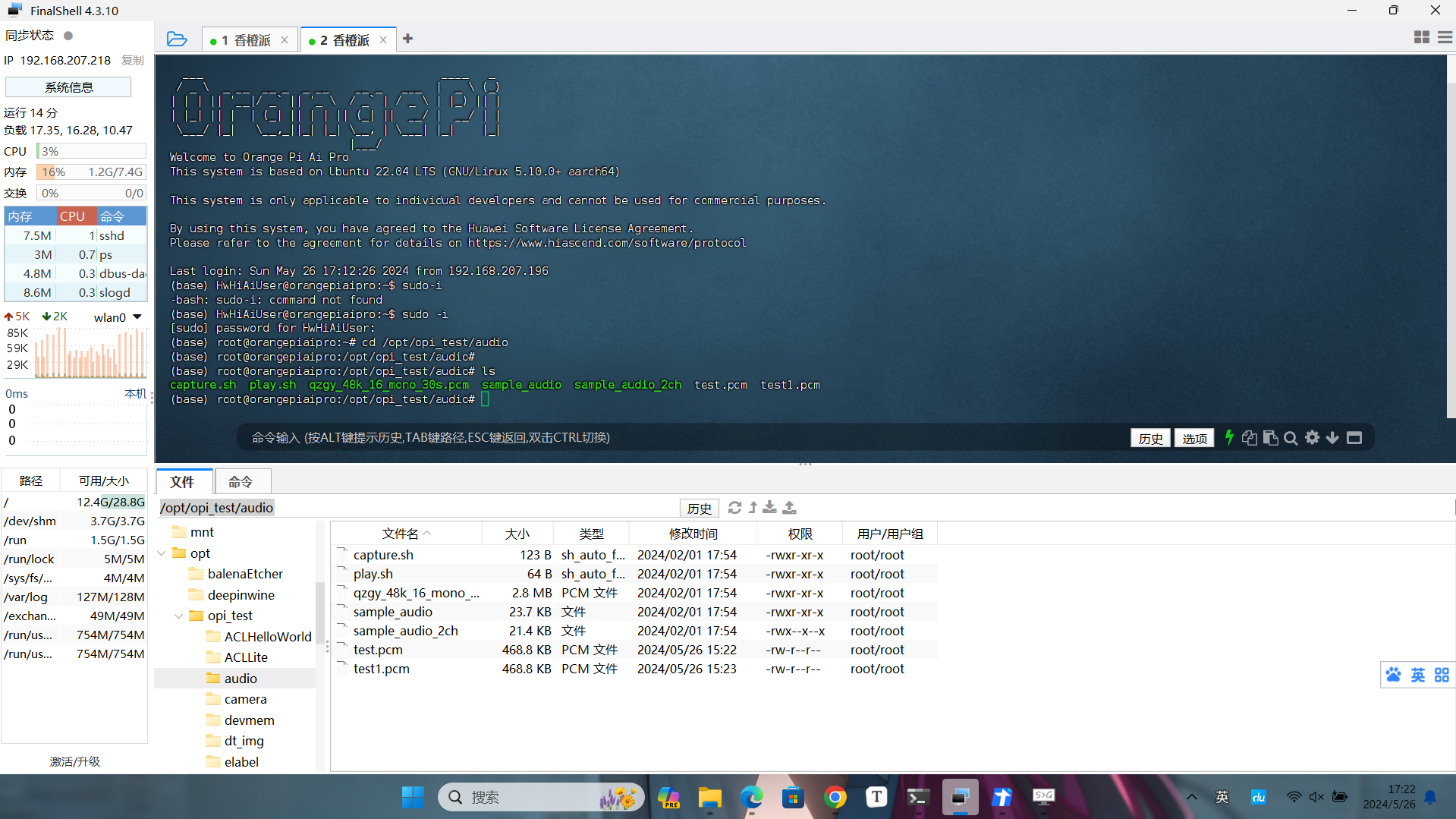

使用下的命令就可以播放测试音频到耳机了。
./sample_audio play 2 qzgy_48k_16_mono_30s.pcm2.2、效果演示
由于3.5mm耳机外放声音有点小,所以这里就使用音响的方式记录下来。
https://www.bilibili.com/video/BV1nr421L7q9
2.3、录音播放
首先将带MIC功能的耳机插入开发板的3.5mm耳机接口中。
然后进入音频测试程序所在的目录中,执行下面的指令。
- sudo -i
- cd /opt/opi_test/audio
然后可以使用下面的命令录制一段5秒钟的音频。
./sample_audio capture test05.pcm录音完成后会在当前目录下生成一个test05.pcm的录音文件,然后使用下面的命令可以将录制的音频文件播放到耳机。
./sample_audio play 2 test05.pcm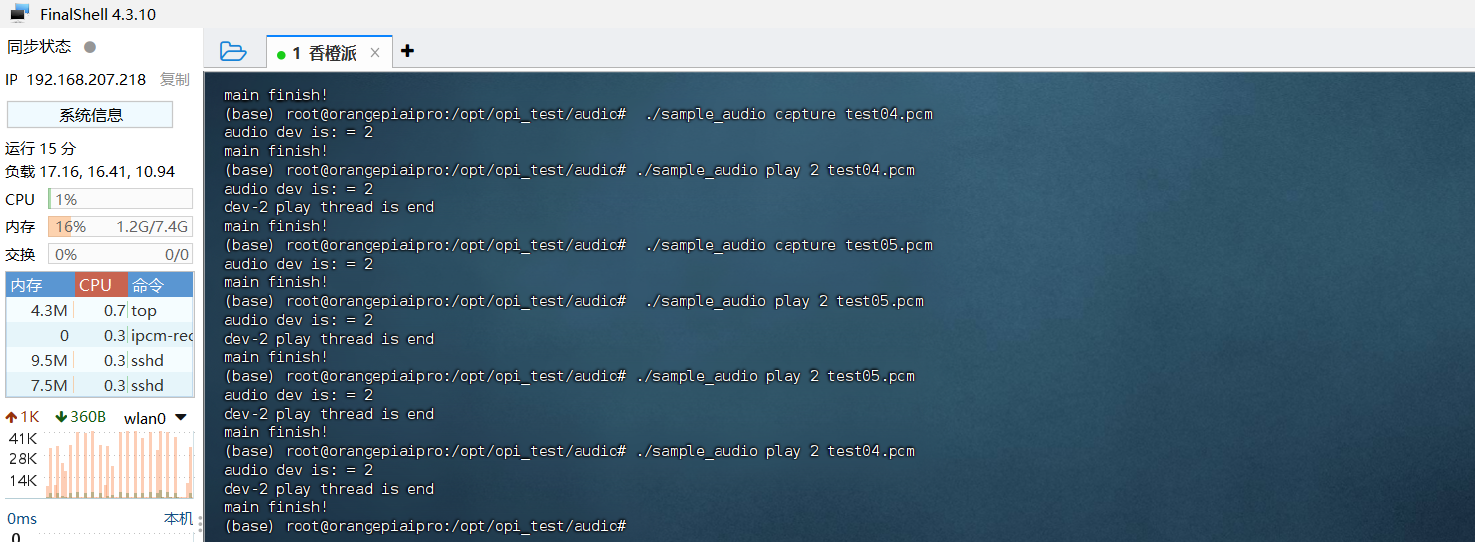

2.4、演示视频
https://www.bilibili.com/video/BV12J4m1378V
https://www.bilibili.com/video/BV137421Z711
四、 运行语音识别
在镜像中预装了JupyterLab软件。Jupyter Lab软件是一个基于web的交互式开发环境,集成了代码编辑器、终端、文件管理器等功能,使得开发者可以在一个界面中完成各种任务。并且我们在镜像中也预置了一些可以在JupyterLab软件中运行的AI应用样例。这些样例都是使用Python编写的,并调用了Python版本的AscendCL编程接口。本章节介绍如何登录jupyterlab并在jupyterlab中运行 这些预置的AI应用样例。
1、 启动JupyterLab
首先登录Linux系统桌面,然后打开终端,再切换到保存AI应用样例的目录下。
cd /home/HwHiAiUser/samples/notebooks然后执行start_notebook.sh脚本启动 Jupyter Lab。
./start_notebook.sh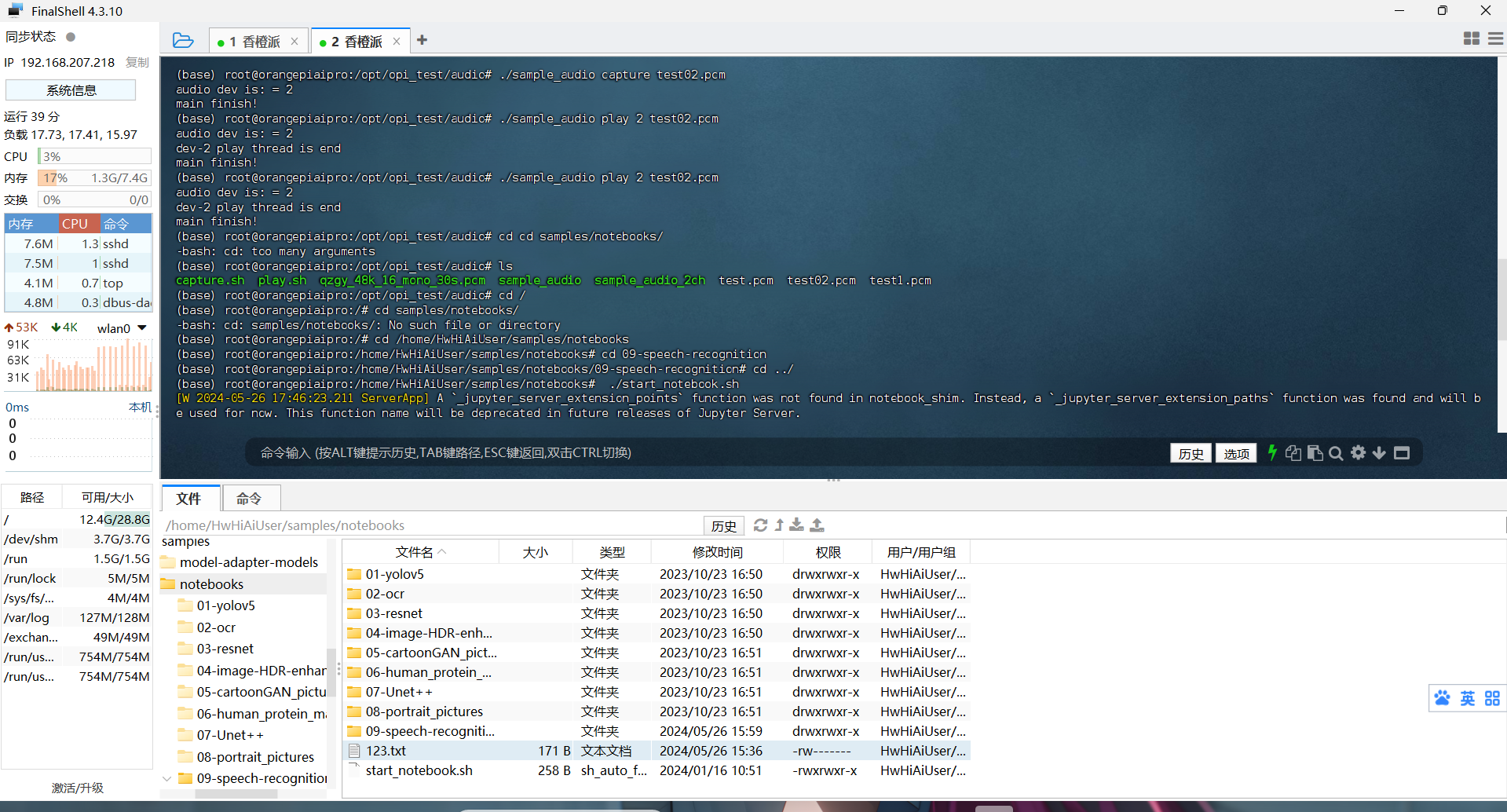

在执行该脚本后,终端会出现如下打印信息,在打印信息中会有登录Jupyter Lab的网址链接。
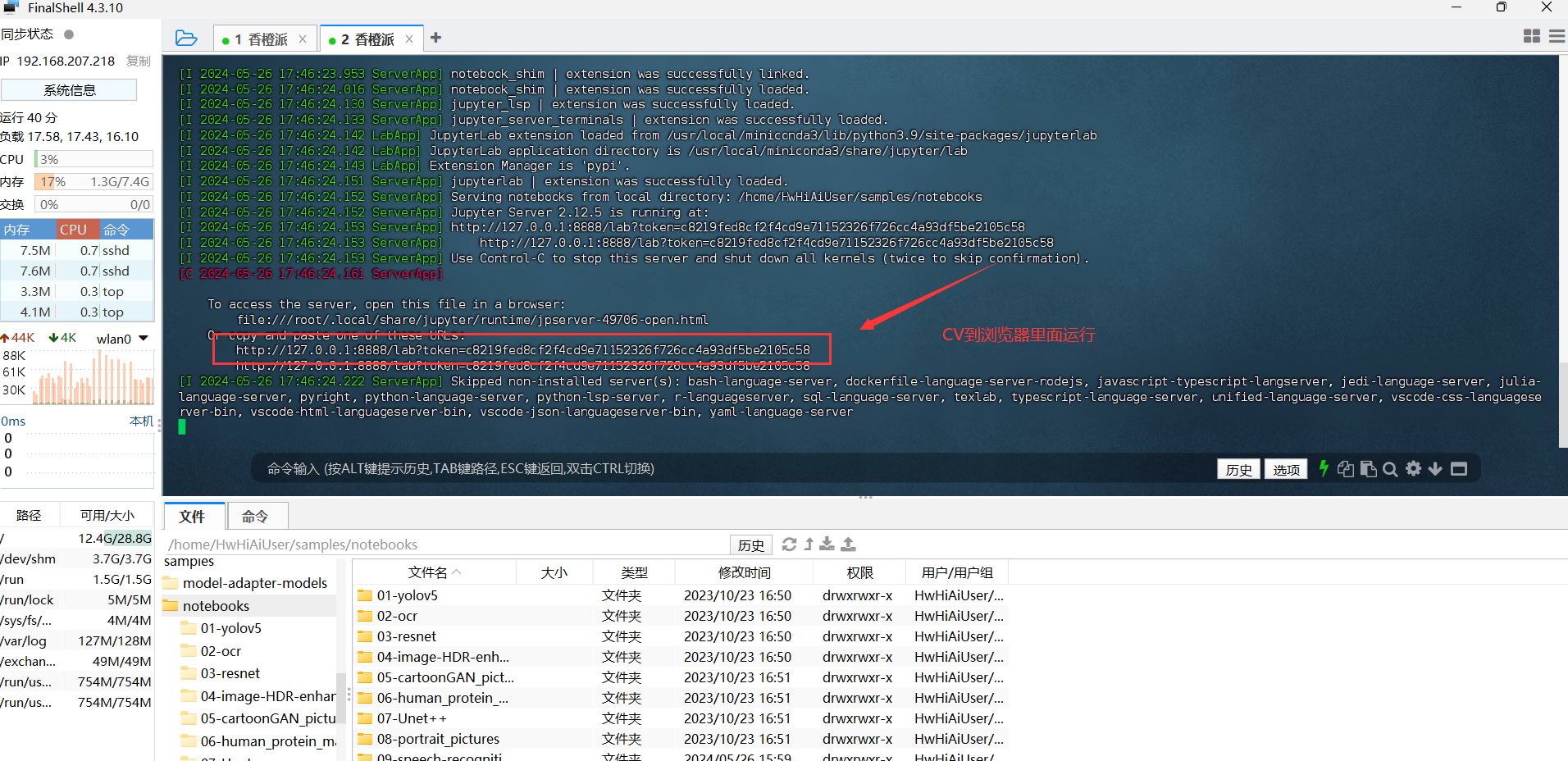
登录Jupyter Lab后的界面如下所示,左侧文件管理器中是9个AI应用样例和 Jupyter Lab 启动脚本。


2、启动智能语音识别
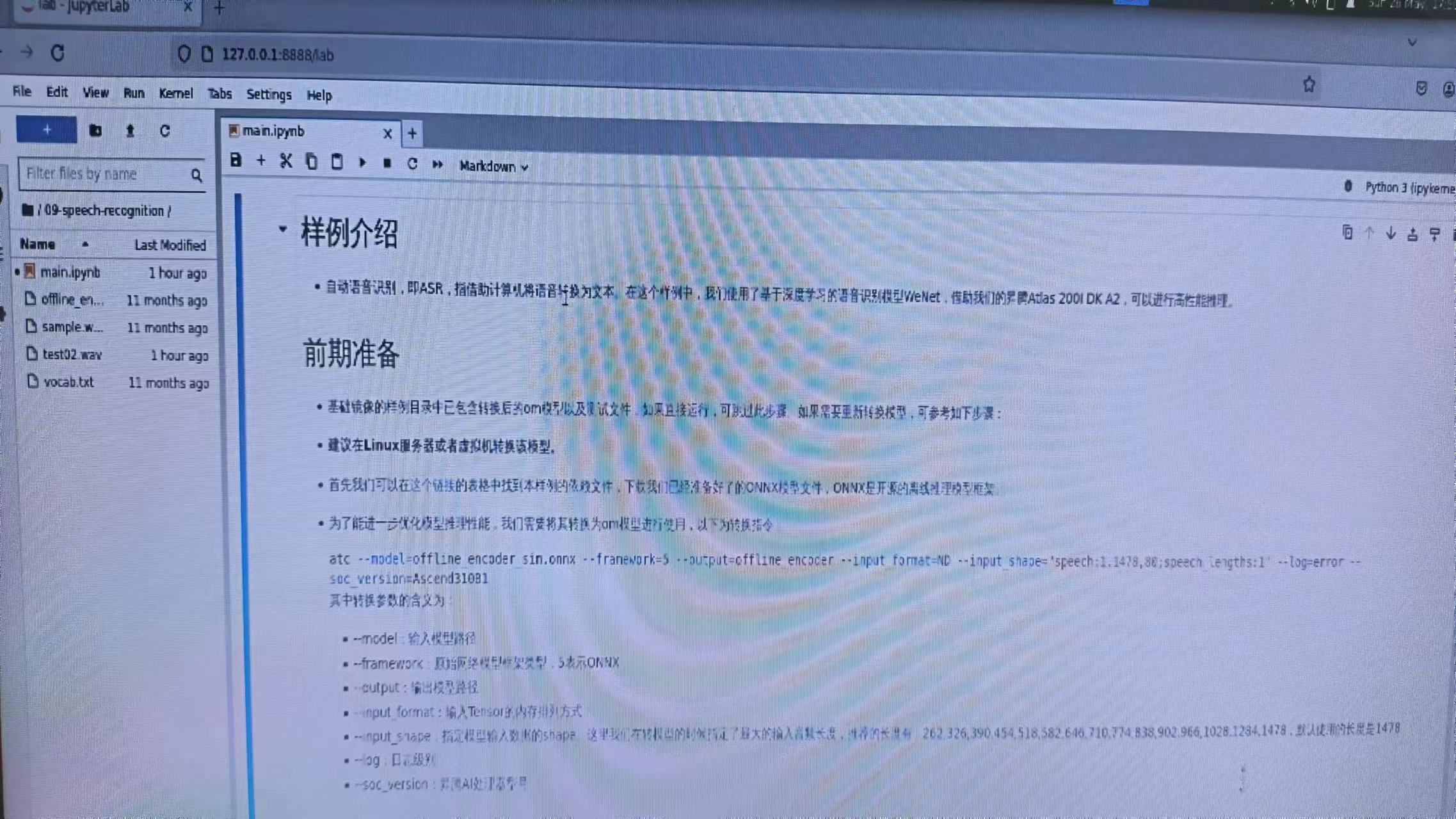
首先在Jupyter Lab界面双击“09-speech-recognition”,进入到该目录下,在该目录下有运行该示例的所有资源,其中mian.ipynb是在JupyterLab中运行该样例的文件,双击打开main.ipynb,在右侧窗口中会显示main.ipynb文件中的内容,单击按钮运行样例,在弹出的对话框中单击“Restart”按钮,此时该样例开始运行。


若干秒后,在窗口中出现了如下内容。我们可以看到模型对测试语音进行推理, 识别出了语音中的文本信息为“智能语音作为智能时代人机交互的关键接口各行业 爆发式的场景需求驱动行业发展进入黄金期”。
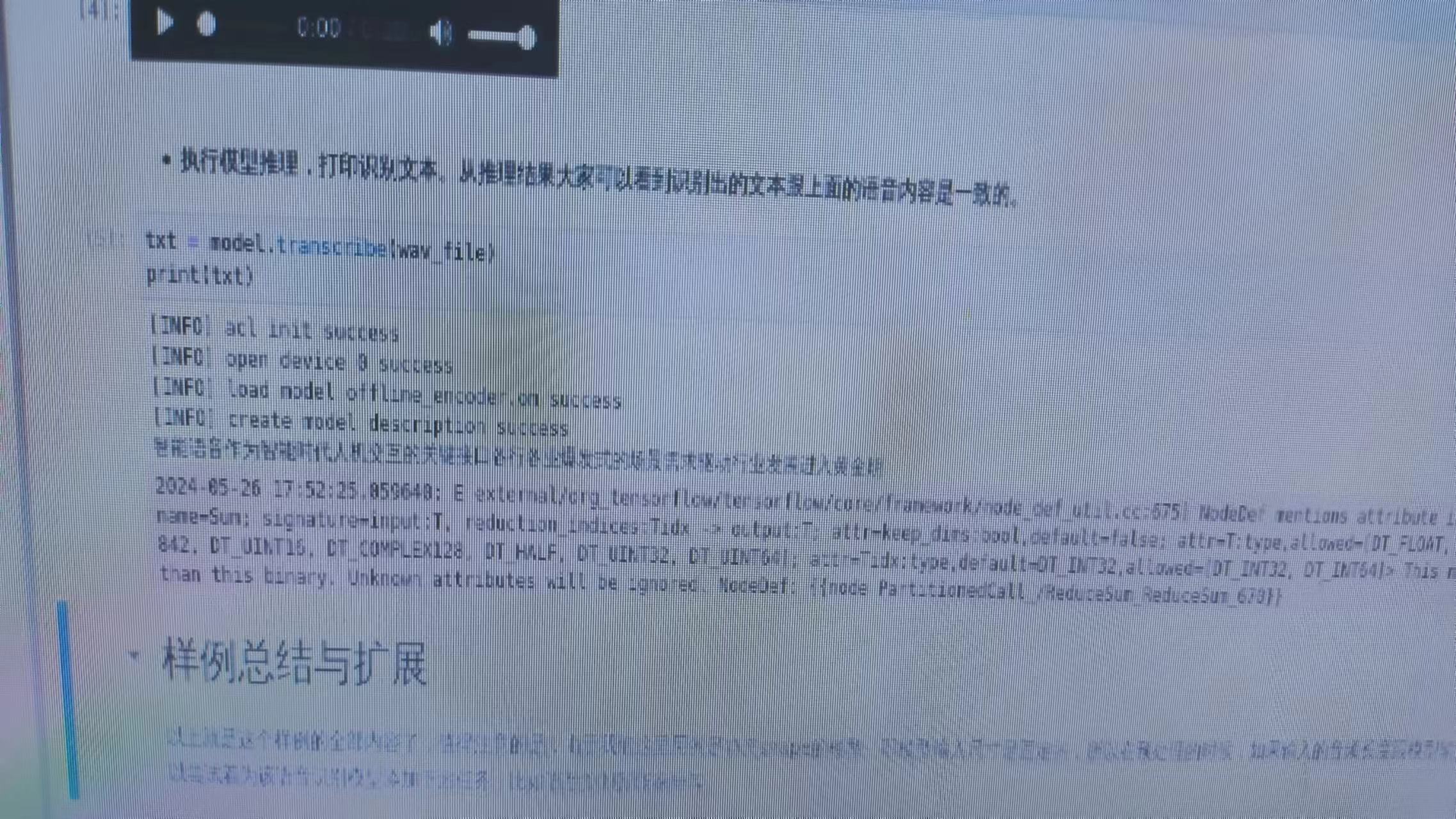
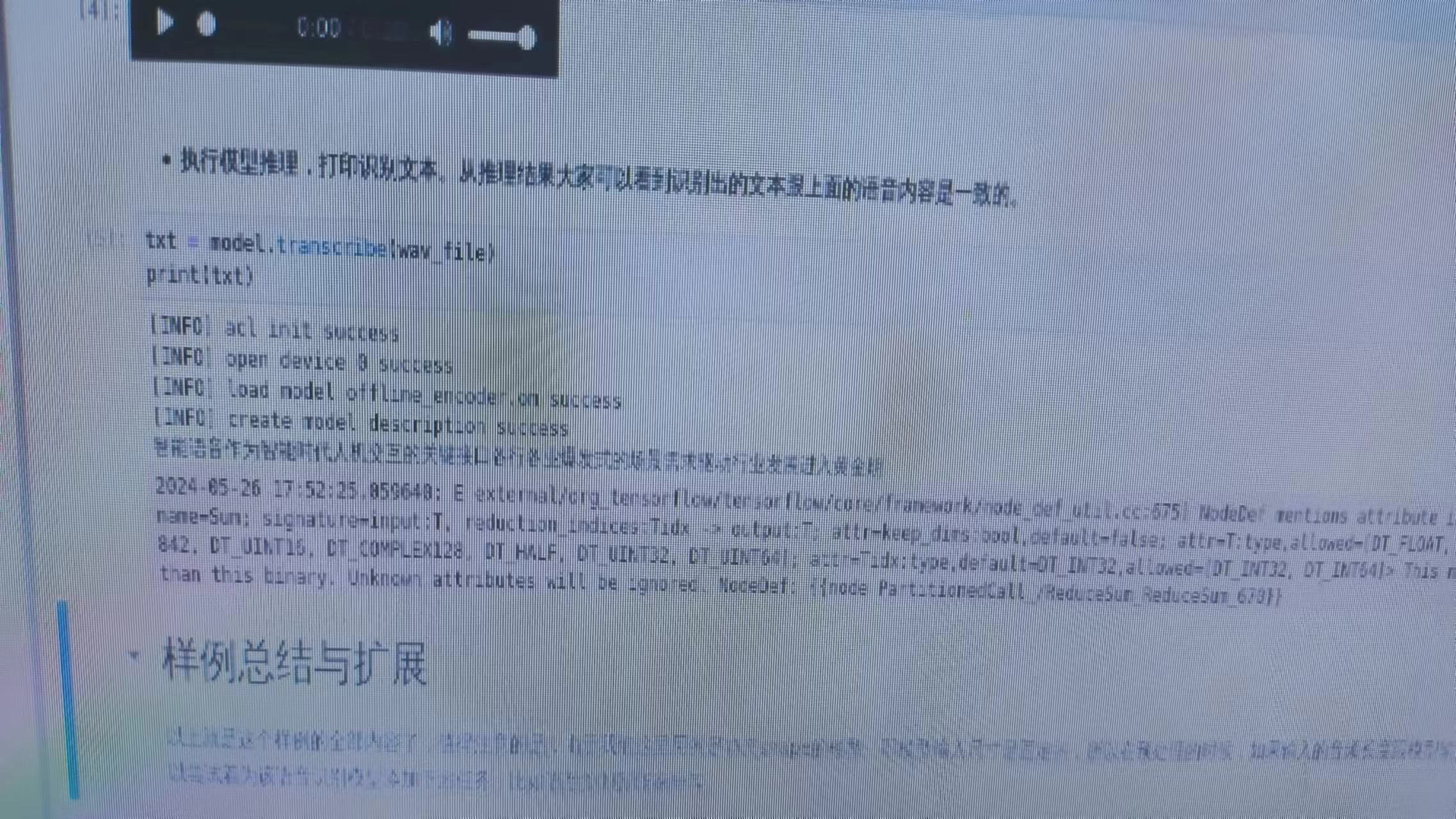
测试语音的保存路径如下所示
/home/HwHiAiUser/samples/notebooks/09-speech-recognition/sample.wav我们可以自己修改音频文件,然后实现语音转文字效果。
至此,演示案例就完成了,在开发板上可以外接一个小型的显示器,当我们需要录音时,自动连接蓝牙点击按钮进行录音,然后将文件保存下来,自动执行转文字效果,实现实时翻译器或在线文字转换功能。
五、 总结
综上所述,我们可以看出OrangePi AIpro是一款非常优秀AI开发板,不仅演示的案例,它的内部还有许多非常实用的功能,例如目标检测、卡通图像生成、人像分割与背景替换等,功能使用是真的强大。
体验下来,开发板真的很不错,无论对于刚毕业的小白新手还是别的某一领域的大牛想学习,都很友好,容易上手,官方的手册也是十分的详细;并且随着未来科技的不断发展,我相信越来越多的领域都会开始向AI靠拢,从制造业到人们的出行,OrangePi AIpro展现出未来带来巨大价值。
剧透一下:后续会把上述的实时翻译器给做出来,以及智能家居联合使用,敬请期待。

