
- 1AI大模型探索之路-训练篇22: ChatGLM3微调实战-从原理到应用的LoRA技术全解_chatglm3 模型训练的原理
- 2关于docker安装RabbitMQ_rabbitmq 3.7镜像
- 3【CS224N-2019】斯坦福CS224N-2019自然语言处理----作业详解
- 4生命在于学习——文件解析_apache解析漏洞版本
- 5VMware Workstation Pro各版本下载(2024.5.5之后)(Windows与Linux安装包不限速网盘)_vmware workstation版本有哪些
- 60day,你究竟是个啥?_最新oday inurl
- 7Linux-Arm环境下配置编译qt-everywhere及交叉编译环境_qt-everywhere configure
- 8收藏 !Python最全函数总结(77个常用函数)_python函数
- 9使用Proverif分析TLS 1.3协议
- 10第3篇-使用charles工具抓取ios手机https包_charles怎么抓ios手机包
基于TensorFlow Lite的人声识别在端上的实现
赞
踩

通过TensorFlow Lite,移动终端、IoT设备可以在端上实现声音识别,这可以应用在安防、医疗监护等领域。来自阿里巴巴闲鱼技术互动组仝辉和上叶通过TensorFlow Lite实现了一套完整的提取声音特征,模型训练和生成端上模型方案。
转载声明:本文转自公众号【闲鱼技术】
摘要
现有的人声识别绝大部分在服务端实现,这会带来如下两方面的问题:
当网络较差的情况下会造成较大的延时,带来较差的用户体验。
当访问量较大的情况下,会大量占用服务端资源。
为解决以上两个问题,我们选择在客户端上实现人声识别功能。本文使用机器学习的方法识别人声。采用的框架是谷歌的TensorFlow Lite框架,该框架跟它的名字一样具有小巧的特点。在保证精度的同时,框架的大小只有300KB左右,且经过压缩后产生的模型是TensorFlow模型的四分之一[1]。因此,TensorFlow Lite框架比较适合在客户端上使用。
为了提高人声的识别率,需要提取音频特征作为机器学习框架的输入样本。本文使用的特征提取算法是基于人耳听觉机理的梅尔倒频谱算法[2]。
由于在客户端上使用人声识别比较耗时,在工程上需要做很多优化,优化方面如下:
指令集加速:引入ARM指令集,做多指令集优化,加速运算。
多线程加速:对于耗时的运算采用多线程并发处理。
模型加速:选用支持NEON优化的模型,并预加载模型减少预处理时间。
算法加速:I) 降低音频采样率。II) 选取人声频段(20Hz~20KHz),剔除非人声频段。 III) 合理分窗和切片,防止过度计算。IV) 静音检测,减少不必要的时间片段。
1.概述
1.1 人声识别流程
人声识别分为训练和预测两个部分。训练指的是生成预测模型,预测是利用模型产生预测结果。
首先介绍下训练的过程,分为以下三个部分:
基于梅尔倒频谱算法,提取声音特征,并将其转换成频谱图片。
将人声频谱作为正样本,动物声音和杂音等非人声作为负样本,交由神经网络模型训练。
基于训练产生的文件,生成端上可运行的预测模型。
简而言之,人声识别训练的流程分为三个部分,提取声音特征,模型训练和生成端上模型。最后,是人声识别的部分:先提取声音特征,然后加载训练模型即可获得预测结果。
1.2 人工智能框架
2017年11月,谷歌曾在 I/O 大会上宣布推出 TensorFlow Lite,这是一款 TensorFlow用于移动设备和嵌入式设备的轻量级解决方案。可以在多个平台上运行,从机架式服务器到小型 IoT 设备。但是随着近年来机器学习模型的广泛使用,出现了在移动和嵌入式设备上部署它们的需求。而 TensorFlow Lite 允许设备端的机器学习模型的低延迟推断。
本文基于的TensorFlow Lite是谷歌研发的人工智能学习系统,其命名来源于本身的运行原理。Tensor(张量)意味着N维数组,Flow(流)意味着基于数据流图的计算,TensorFlow为张量从流图的一端流动到另一端计算过程。TensorFlow是将复杂的数据结构传输至人工智能神经网中进行分析和处理过程的系统。
下图展示了TensorFlow Lite的架构设计[1]:

图1.1 TensorFlow Lite架构图
2.梅尔倒频谱算法
2.1 概述
本章中声音识别的算法--梅尔倒频谱算法[2]分为如下几步,将会再后续小节中详细介绍。
输入声音文件,解析成原始的声音数据(时域信号)。
通过短时傅里叶变换,加窗分帧将时域信号转变为频域信号。
通过梅尔频谱变换,将频率转换成人耳能感知的线性关系。
通过梅尔倒谱分析,采用DCT变换将直流信号分量和正弦信号分量分离[3]。
提取声音频谱特征向量,将向量转换成图像。
加窗分帧是为了满足语音在时域的短时平稳特性,梅尔频谱变换是为了将人耳对频率的感知度转化为线性关系,倒谱分析的重点是理解傅里叶变换,任何信号都可以通过傅里叶变换而分解成一个直流分量和若干个正弦信号的和。
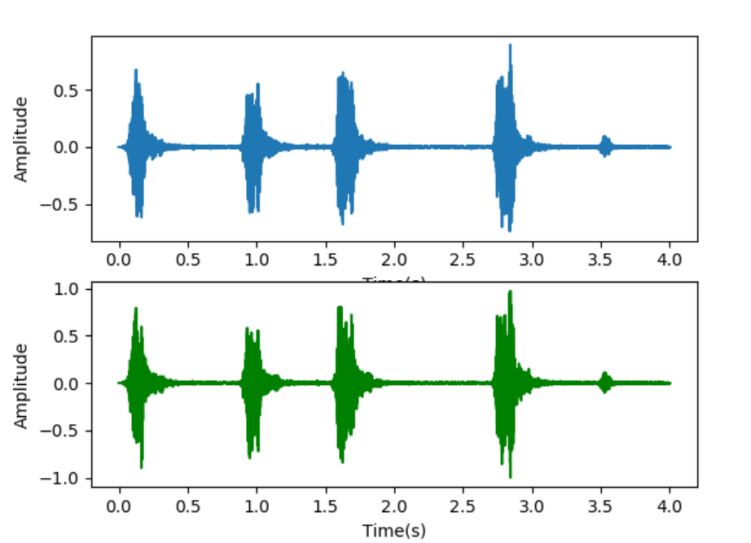
图2.1 声音的时域信号
图2.1是声音的时域信号,直观上很难看出频率变化规律。图2.2是声音的频域信号,反映了能够反映出声音的音量和频率等信息。图2.3是经过梅尔倒频谱的声音特征,能够提取声音。

图2.2 声音的频域信号
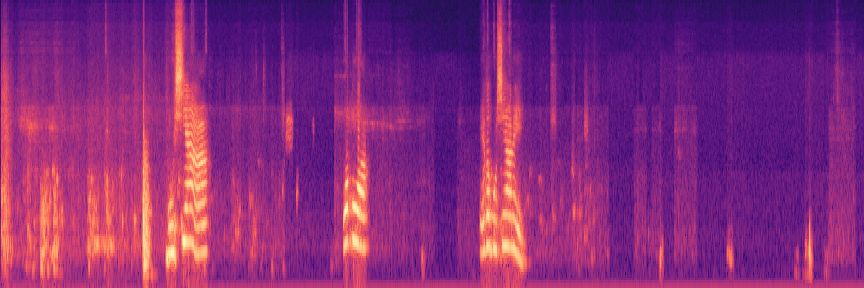
图2.3 声音的倒频谱特征
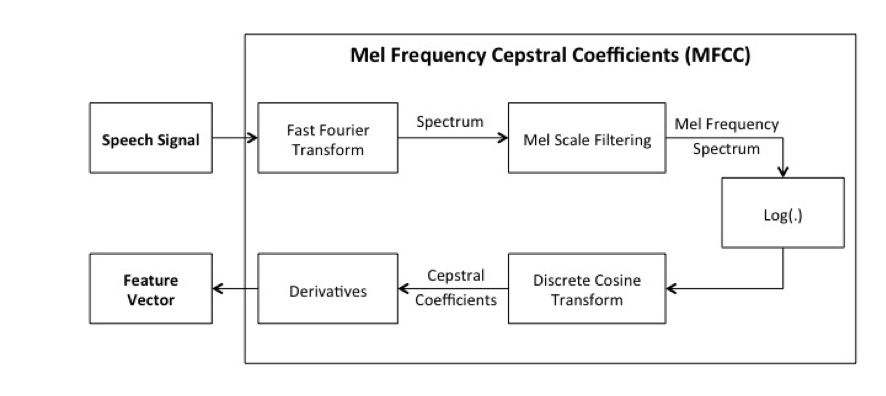
图2.4 梅尔倒频谱算法实现流程
2.2 短时傅里叶变换
声音信号是一维的时域信号,直观上很难看出频率变化规律。如果通过傅里叶变换把它变到频域上,虽然可以看出信号的频率分布,但是丢失了时域信息,无法看出频率分布随时间的变化。为了解决这个问题,很多时频分析手段应运而生。短时傅里叶,小波,Wigner分布等都是常用的时频域分析方法。

图2.5 FFT变换和STFT变换示意图
通过傅里叶变换可以得到信号的频谱。信号的频谱的应用非常广泛,信号的压缩、降噪都可以基于频谱。然而傅里叶变换有一个假设,那就是信号是平稳的,即信号的统计特性不随时间变化。声音信号就不是平稳信号,在很长的一段时间内,有很多信号会出现,然后立即消失。如果将这信号全部进行傅里叶变换,就不能反映声音随时间的变化。
本文采用的短时傅里叶变换(STFT)是最经典的时频域分析方法。短时傅里叶变换(STFT)是和傅里叶变换(FT)相关的一种数学变换,用以确定时变信号其局部区域正弦波的频率与相位。它的思想是:选择一个时频局部化的窗函数,假定分析窗函数h(t)在一个短时间间隔内是平稳的,使f(t)h(t)在不同的有限时间宽度内是平稳信号,从而计算出各个不同时刻的功率谱。短时傅里叶变换使用一个固定的窗函数,通常使用的窗函数有汉宁窗、海明窗、Blackman-Haris窗等。本文中采用了海明窗,海明窗是一种余弦窗,能够很好地反映某一时刻能量随时间的衰减关系。
因此,本文的STFT公式在原先傅里叶变换公式
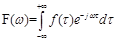
公式的基础上加了窗函数,因此STFT公式变换为
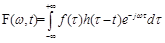
其中,

为海明窗函数。
图2.6 基于海明窗的STFT变换
2.3 梅尔频谱
声谱图往往是很大的一张图,为了得到合适大小的声音特征,往往把它通过梅尔标度滤波器组,变换为梅尔频谱。什么是梅尔滤波器组呢?这里要从梅尔标度说起。
梅尔标度,由Stevens,Volkmann和Newman在1937年命名。我们知道,频率的单位是赫兹(Hz),人耳能听到的频率范围是20-20000Hz,但人耳对Hz这种标度单位并不是线性感知关系。例如如果我们适应了1000Hz的音调,如果把音调频率提高到2000Hz,我们的耳朵只能觉察到频率提高了一点点,根本察觉不到频率提高了一倍。如果将普通的频率标度转化为梅尔频率标度,映射关系如下式所示:
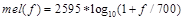
经过上述公式,则人耳对频率的感知度就成了线性关系[4]。也就是说,在梅尔标度下,如果两段语音的梅尔频率相差两倍,则人耳可以感知到的音调大概也相差两倍。
让我们观察一下从Hz到梅尔频率(Mel)的映射图,由于它们是Log的关系,当频率较小时,梅尔频率随Hz变化较快;当频率很大时,梅尔频率的上升很缓慢,曲线的斜率很小。这说明了人耳对低频音调的感知较灵敏,在高频时人耳是很迟钝的,梅尔标度滤波器组启发于此。
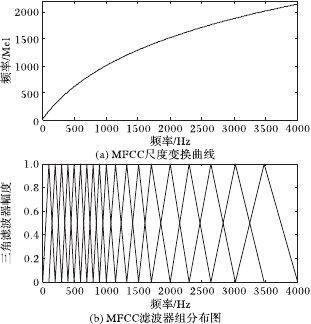
图2.7 频率转梅尔频率示意图
如下图所示,12个三角滤波器组成滤波器组,低频处滤波器密集,门限值大,高频处滤波器稀疏,门限值低。恰好对应了频率越高人耳越迟钝这一客观规律。上图所示的滤波器形式叫做等面积梅尔滤波器(Mel-filter bank with same bank area),在人声领域(语音识别,说话人辨认)等领域应用广泛。
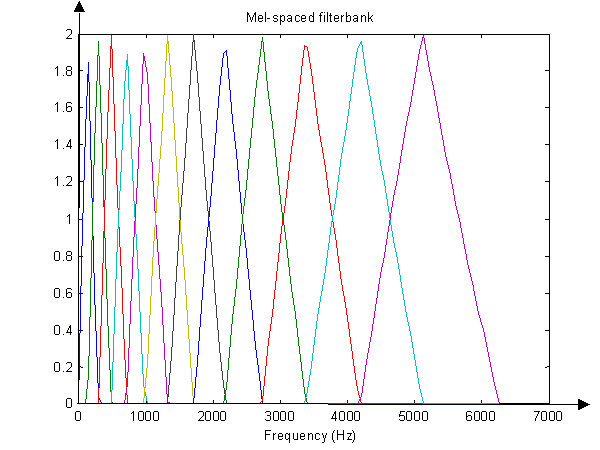
图2.8 梅尔滤波器组示意图
2.4 梅尔倒频谱
基于2.3的梅尔对数谱,采用DCT变换将直流信号分量和正弦信号分量分离,最后得到的结果称为梅尔倒频谱。
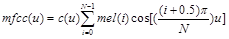
其中

由于梅尔倒频谱输出的是向量,还不能用图片显示,需要将其转换成图像矩阵。需要将输出向量的范围 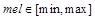 线性变换到图像的范围
线性变换到图像的范围 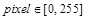
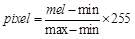

图2.9 绘图颜色标度示意图
2.5 算法处理速度优化
由于算法需要在客户端上实现,因此需要对速度做一定的改进[5]。优化方面如下:
指令集加速:由于算法有大量的加法和乘法矩阵运算,因此引入arm指令集,做多指令集优化,加速运算。速度可以提高4~8倍[6]。
算法加速:I) 选取人声频段(20Hz~20KHz),并剔除非人声频段减少冗余计算。II) 降低音频采样率,由于人耳对过高的采样率不敏感,因此降低采样率 可以减少不必要的数据计算。III) 合理分窗和切片,防止过度计算。IV) 静音检测,减少不必要的时间片段。
采样频率加速:如果音频的采样频率过高,选择下采样,处理的频率最高设定为32KHz。
多线程加速:将音频拆分为多个片段,采用多线程并行处理。并根据机器的能力配置线程数,默认为4个线程。

图2.10 算法工程端选取的参数
3.人声识别模型
3.1模型选择
卷积神经网络(Convolutional Neural Networks-简称CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。
20世纪60年代,Hubel和Wiesel在研究猫脑皮层中用于局部敏感和方向选择的神经元时发现其独特的网络结构可以有效地降低反馈神经网络的复杂性,继而提出了卷积神经网络。现在,CNN已经成为众多科学领域的研究热点之一,特别是在模式分类领域,由于该网络避免了对图像的复杂前期预处理,可以直接输入原始图像,因而得到了更为广泛的应用。 K.Fukushima在1980年提出的新识别机是卷积神经网络的第一个实现网络。随后,更多的科研工作者对该网络进行了改进。其中,具有代表性的研究成果是Alexander和Taylor提出的“改进认知机”,该方法综合了各种改进方法的优点并避免了耗时的误差反向传播。
一般地,CNN的基本结构包括两层,其一为特征提取层,每个神经元的输入与前一层的局部接受域相连,并提取该局部的特征。一旦该局部特征被提取后,它与其它特征间的位置关系也随之确定下来;其二是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射是一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid, relu等函数作为卷积网络的激活函数,使得特征映射具有位移不变性。此外,由于一个映射面上的神经元共享权值,因而减少了网络自由参数的个数。卷积神经网络中的每一个卷积层都紧跟着一个用来求局部平均与二次提取的计算层,这种特有的两次特征提取结构减小了特征分辨率。
CNN主要用来识别位移、缩放及其他形式扭曲不变性的二维图形。由于CNN的特征检测层通过训练数据进行学习,所以在使用CNN时,避免了显式的特征抽取,而隐式地从训练数据中进行学习;再者由于同一特征映射面上的神经元权值相同,所以网络可以并行学习,这也是卷积网络相对于神经元彼此相连网络的一大优势。卷积神经网络以其局部权值共享的特殊结构在语音识别和图像处理方面有着独特的优越性,其布局更接近于实际的生物神经网络,权值共享降低了网络的复杂性,特别是多维输入向量的图像可以直接输入网络这一特点避免了特征提取和分类过程中数据重建的复杂度。

图3.1 Inception-v3模型
本文选取了精度较高的Inception-v3模型作为人声识别的模型,v3一个最重要的改进是分解,将7x7卷积网络分解成两个一维的卷积(1x7,7x1),3x3也是一样(1x3,3x1),这样的好处,既可以加速计算,使得网络深度进一步增加,增加了网络的非线性,还有值得注意的地方是网络输入从224x224变为了299x299,更加精细设计了35x35/17x17/8x8的模块。
使用TensorFlow Session模块可以实现代码层面的训练和预测功能,具体使用方法详见TensorFlow 官网[7]。
 图3.2 TensorFlow Session使用示意图
图3.2 TensorFlow Session使用示意图
3.2模型样本
有监督的机器学习中,一般需要将样本分成独立的三部分训练集(train set),验证集(validation set)和测试集(test set)。其中训练集用来估计模型,验证集用来确定网络结构或者控制模型复杂程度的参数,而测试集则检验最终选择最优的模型的性能如何。
具体定义如下:
训练集:学习样本数据集,通过匹配一些参数来建立一个分类器。建立一种分类的方式,主要是用来训练模型的。
验证集:对学习出来的模型,调整分类器的参数,如在神经网络中选择隐藏单元数。验证集还用来确定网络结构或者控制模型复杂程度的参数,用来防止模型过拟合现象。
测试集:主要是测试训练好的模型的分辨能力(识别率等)
根据第二章的梅尔倒频谱算法可以得到声音识别的样本文件,将人声频谱作为正样本,动物声音和杂音等非人声作为负样本,交由Inception-v3模型进行训练。
本文采用了TensorFlow作为训练框架,选取人声和非人声各5000个样本作为测试集,1000个样本作为验证集。
3.3 模型训练
样本准备完成后,即可使用Inception-v3模型训练。当训练模型收敛时,即可生成端上可使用的pb模型。模型选取时选择编译armeabi-v7a或者以上版本即可默认打开NEON优化,即打开USE_NEON的宏,能够达到指令集加速的效果。例如CNN网络一半以上的运算都在卷积(conv)运算,使用指令集优化可以至少加速4倍。

图3.3 卷积处理函数
然后经过TensorFlow提供的toco工具生成lite模型,该模型可以直接在客户端上使用TensorFlow Lite框架调用。
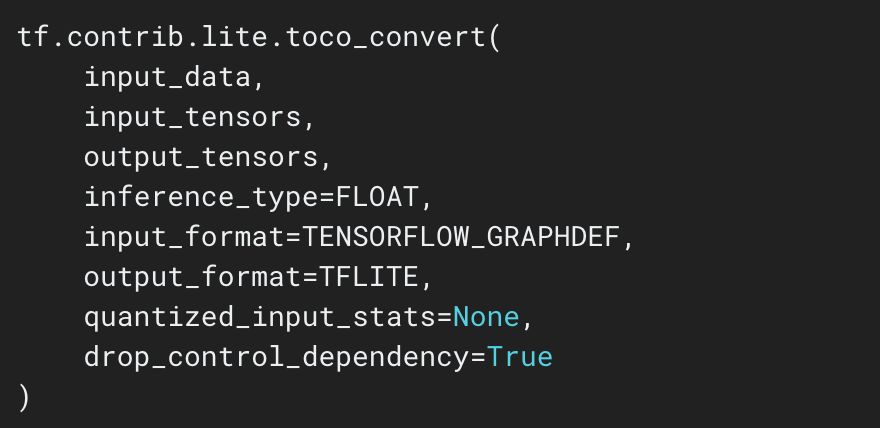
图3.4 toco工具调用接口
3.4 模型预测
对声音文件使用梅尔倒频谱算法提取特征,并生成预测图片。之后使用训练产生的lite模型即可预测,预测结果示意图如下:
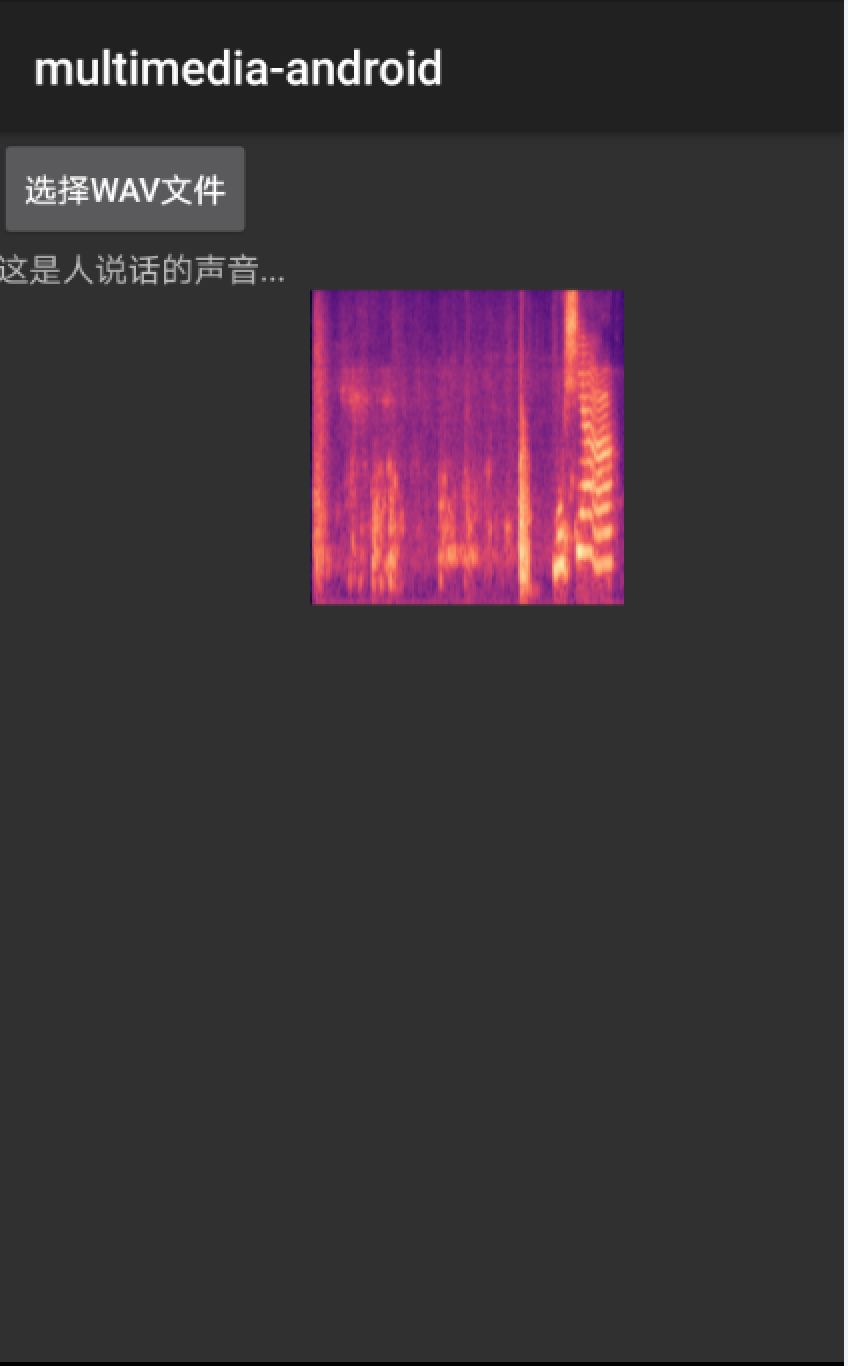
图3.5 模型预测结果
参考文献:
[1] https://www.tensorflow.org/mobile/tflite
[2] 基于MFCC与IMFCC的说话人识别研究[D]. 刘丽岩. 哈尔滨工程大学 . 2008
[3] 一种基于MFCC和LPCC的文本相关说话人识别方法[J]. 于明,袁玉倩,董浩,王哲. 计算机应用. 2006(04)
[4] Text dependent Speaker Identification in Noisy Enviroment[C]. Kumar Pawan,Jakhanwal Nitika,
Chandra Mahesh. International Conference on Devices and Communications . 2011
[5] https://github.com/weedwind/MFCC
[6] https://baike.baidu.com/item/ARM指令集/907786?fr=aladdin
[7] https://www.tensorflow.org/api_docs/python/tf/Session
WebRTCon 2018 上海,期待与你相遇
继2017年第一届LiveVideoStackCon音视频技术大会之后,LiveVideoStack又一次出发——WebRTCon 2018,将于5月在上海举行,这是一次对过去几年WebRTC技术实践与应用落地的总结。
WebRTCon 2018设立了主题演讲,WebRTC与前端,行业应用专场,测试监控和服务保障,娱乐多媒体开发应用实践,WebRTC深度开发,解决方案专场,WebRTC服务端开发,新技术跨界,WebRTC与Codec等多个专场。邀请30余位全球领先的WebRTC技术专家,为参会者带来全球同步的技术实践与趋势解读。


