
- 1python123题目——特殊数列求和_用户输入一个小于10的正整数n,求1 + 12 + 123 + 1234 + …… 的前n项的和。当
- 2软件测试常用的7种方法,最后一个是升职加薪关键!(零基础小白转行IT互联网高效进阶)_软件测试方法
- 3Mac m1安装AWVS
- 4USB Hub
- 5Data truncation: Incorrect datetime value: ‘0000-00-00 00:00:00.000‘ for column ‘createTime‘ at row
- 6倒计时3天!点击查看openGauss Summit 2023关键词
- 7wazuh4.7利用python脚本发送告警信息到飞书机器人_wazuh 配置告警
- 8python做数据查询系统_[Python实战] 功能简单的数据查询及可视化系统
- 9Golang入门
- 10[MySQL] error 1292 数据类型错误_truncated incorrect double value: 'a
【NLP基础知识五】文本分类之神经网络文本分类、多标签分类_nlp 文本分类
赞
踩
如果你是NLP领域初学者,欢迎关注我的博客,我不仅会分享理论知识,更会通过实例和实用技巧帮助你迅速入门。我的目标是让每个初学者都能轻松理解复杂的NLP概念,并在实践中掌握这一领域的核心技能。
通过我的博客,你将了解到:
- NLP的基础概念,为你打下坚实的学科基础。
- 实际项目中的应用案例,让你更好地理解NLP技术在现实生活中的应用。
- 学习和成长的资源,助你在NLP领域迅速提升自己。
不论你是刚刚踏入NLP的大门,还是这个领域的资深专家,我的博客都将为你提供有益的信息。一起探索语言的边界,迎接未知的挑战,让我们共同在NLP的海洋中畅游!期待与你一同成长,感谢你的关注和支持。欢迎任何人前来讨论问题。
【NLP基础知识一】词嵌入(Word Embeddings)
【NLP基础知识二】词嵌入(Word Embeddings)之“Word2Vec:一种基于预测的方法”
【NLP基础知识三】词嵌入(Word Embeddings)之“GloVe:单词表示的全局向量”
【NLP基础知识四】文本分类
4、神经网络文本分类
流程概括
让神经网络学习有用的特征,而非手动定义特征。
- 1
基于神经网络的分类的主要思想是:可以使用神经网络获得输入文本的特征表示。我们将输入token的词嵌入(Embedding)传入神经网络,用于提供输入文本的向量表示。 之后,再使用该向量用于分类。
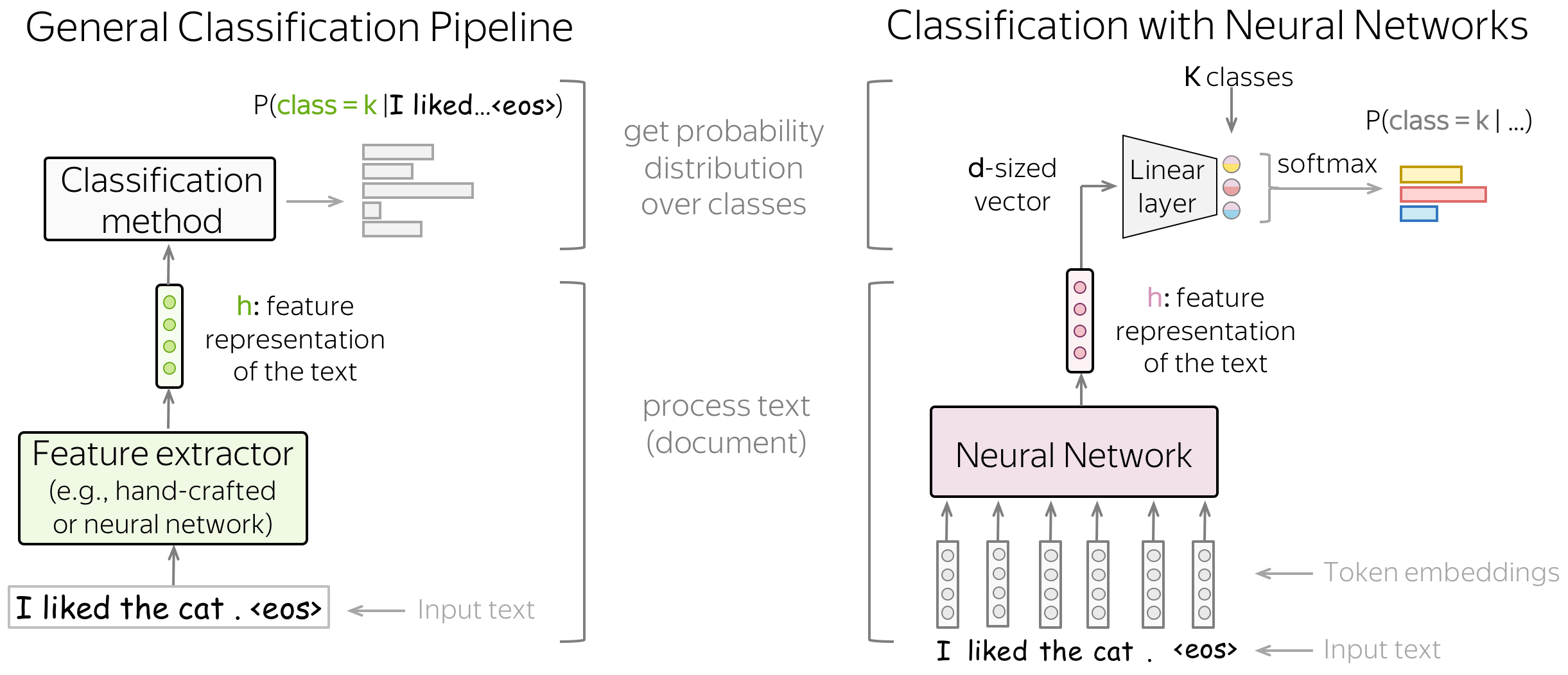
在处理神经网络时,我们可以以非常简单的方式考虑分类部分(即如何从文本的向量表示中获取类别概率)。
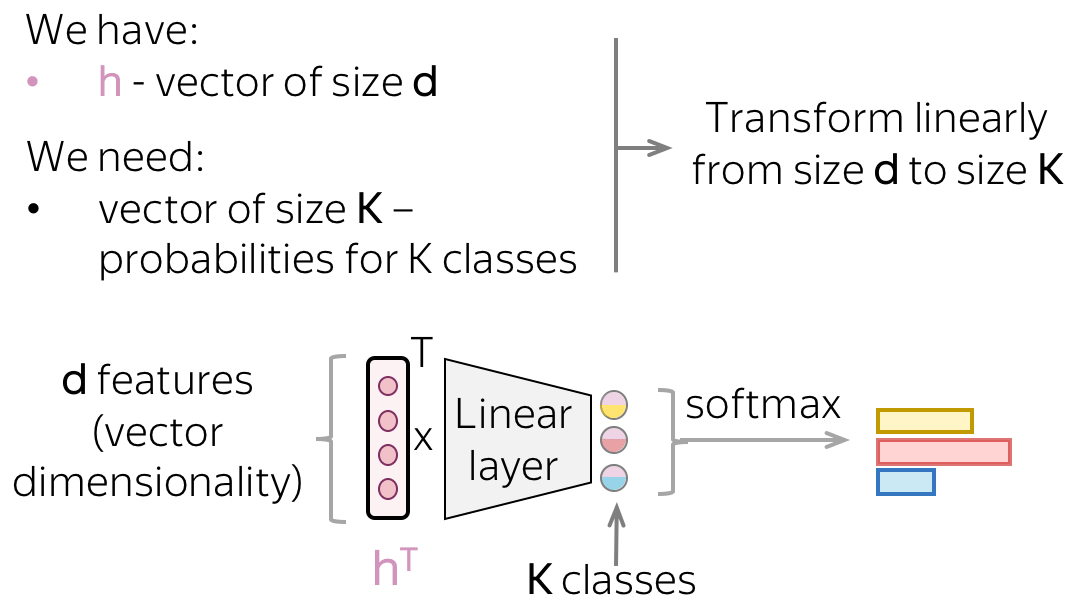
经过神经网络的文本向量表示的维度为
d
d
d。而最终,我们需要一个大小为
K
K
K(
K
K
K 个类别的概率)的向量。 要从
d
d
d 大小得到
K
K
K 大小的向量,我们可以使用线性层。 一旦我们有了一个
K
K
K 大小的向量,剩下的就是应用 softmax 操作将原始数字转换为类概率。
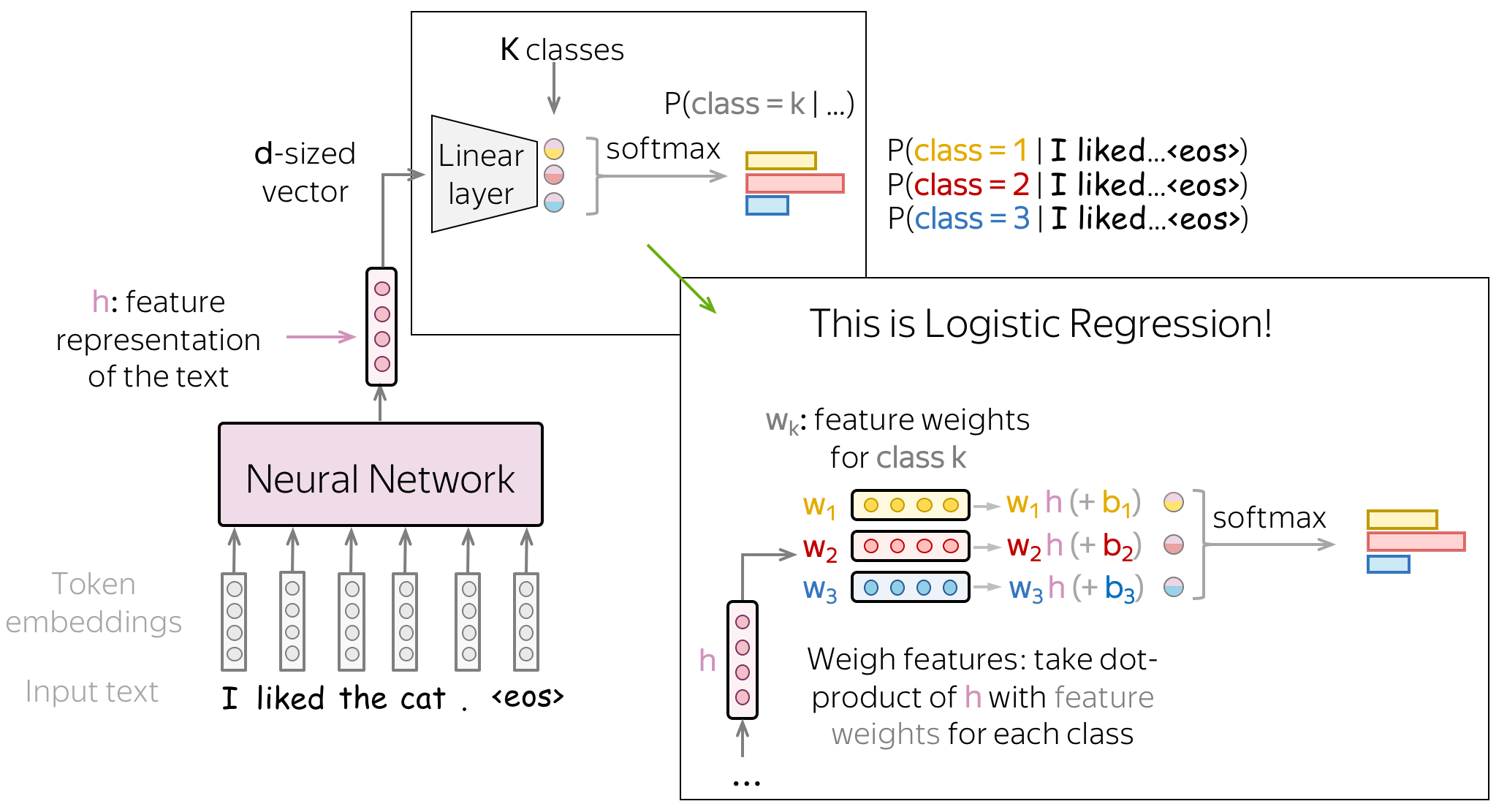
分类部分:仍是逻辑斯蒂回归!
让我们看一下神经网络分类器。 我们使用输入文本的向量表示的方式与我们使用经典方法的逻辑斯蒂回归的方式完全相同:我们根据每个类的特征权重对特征进行加权。 与经典方法的逻辑斯蒂回归的唯一区别在于特征的来源:它们要么是手动定义的(就像我们之前所做的那样),要么是通过神经网络获得的。
直觉:文本表示指向类表示的方向
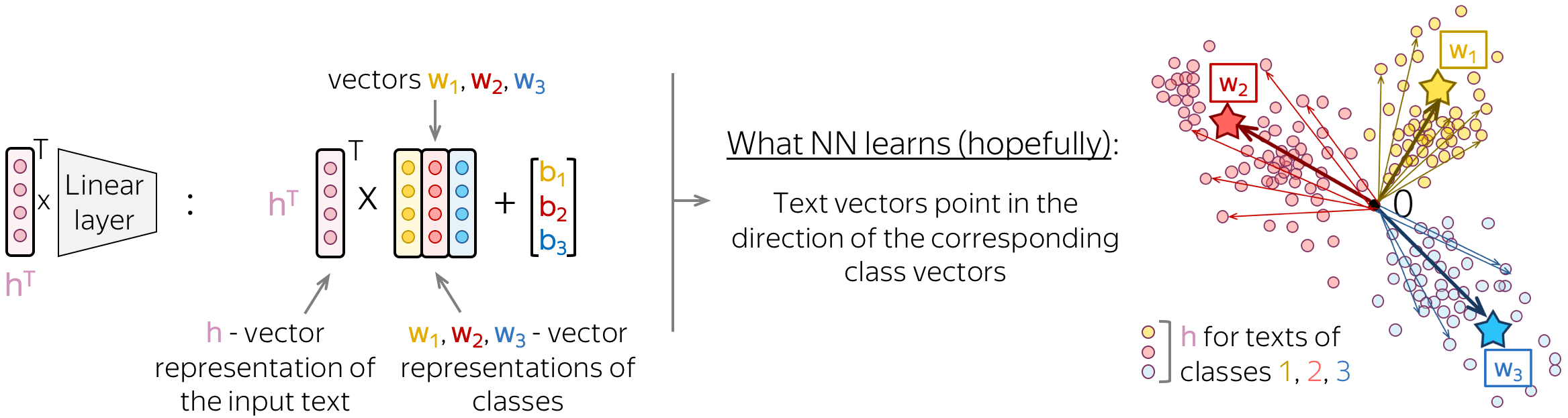
如果我们更仔细地观察这个最后的线性层,我们会看到它的矩阵的列其实就是向量
w
i
w_i
wi。这些向量可以被认为是类的向量表示。一个好的神经网络将学习以这种方式以表示输入文本,即文本向量将指向相应类向量的方向。
训练和交叉熵损失
训练神经网络分类器来预测类的概率分布,直观地说,就是在每一步,我们都会最大化模型分配给正确类别的概率。
标准损失函数是 交叉熵损失 (cross-entropy loss) 。 目标概率分布的交叉熵损失
p
∗
=
(
0
,
…
,
0
,
1
,
0
,
…
)
K
×
1
p^{\ast} = (0, \dots, 0, 1, 0, \dots)_{K\times 1}
p∗=(0,…,0,1,0,…)K×1 (目标标签为 1,其余为 0),并且预测的模型分布为
p
=
(
p
1
,
…
,
p
K
)
,
p
i
=
p
(
i
∣
x
)
p=(p_1, \dots, p_K), p_i=p(i|x)
p=(p1,…,pK),pi=p(i∣x)
L
o
s
s
(
p
∗
,
p
)
=
−
p
∗
log
(
p
)
=
−
∑
i
=
1
K
p
i
∗
log
(
p
i
)
.
Loss(p^{\ast}, p^{})= - p^{\ast} \log(p) = -\sum\limits_{i=1}^{K}p_i^{\ast} \log(p_i).
Loss(p∗,p)=−p∗log(p)=−i=1∑Kpi∗log(pi).
因为只有一个
p
i
∗
p_i^{\ast}
pi∗ 是非零的(目标标签 k 为 1,其余为 0),我们将得到:
L
o
s
s
(
p
∗
,
p
)
=
−
log
(
p
k
)
=
−
log
(
p
(
k
∣
x
)
)
.
Loss(p^{\ast}, p) = -\log(p_{k})=-\log(p(k| x)).
Loss(p∗,p)=−log(pk)=−log(p(k∣x)). 具体的训练样本示例见下图。
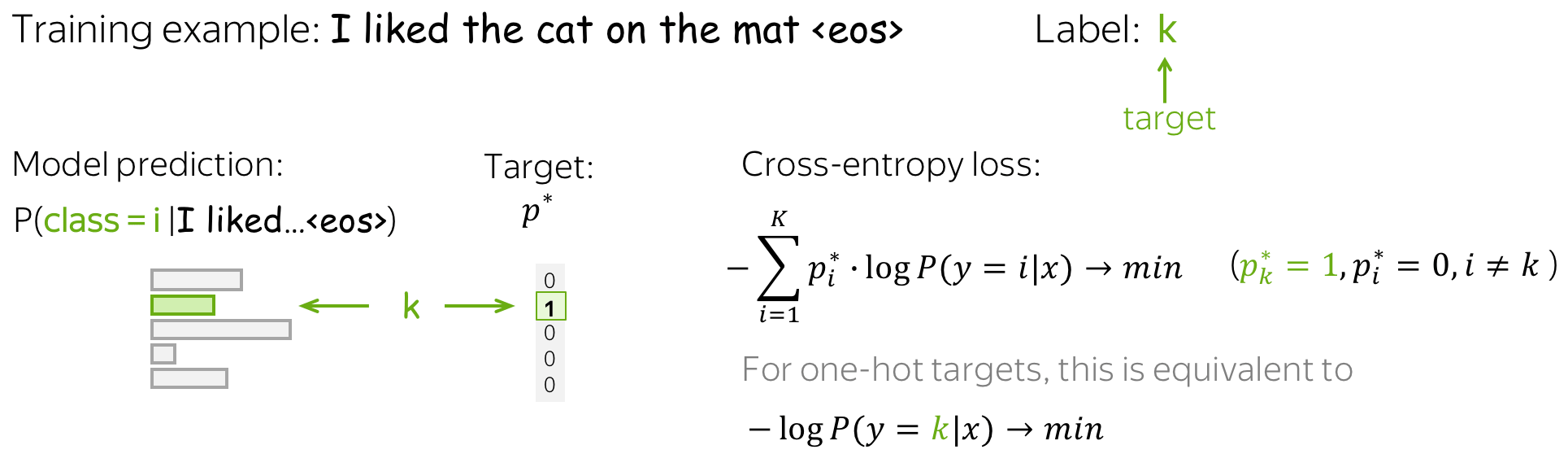
在训练中,我们多次迭代,逐步提高模型权重,具体来说:迭代训练样本(或批量样本)并进行梯度更新。在每一步,我们最大化模型分配给正确类别的概率。同时,也最小化错误类别的概率总和:由于所有概率的总和是恒定的,通过增加一个概率我们减少所有其他概率的总和 ( 编者按:这里我通常想象一群小猫从同一个碗里吃东西: 一只小猫吃得多总是以其他小猫吃得少为代价 )。
训练过程见下图。
概括:这相当于最大化数据似然
不要忘记在谈论最大熵分类器(逻辑回归)时,我们表明最小化交叉熵等同于最大化数据似然。因此,这里我们也试图得到模型参数的 最大似然估计(MLE) 。
文本分类模型
我们需要一个可以为不同长度的输入生成固定大小向量的模型。
- 1
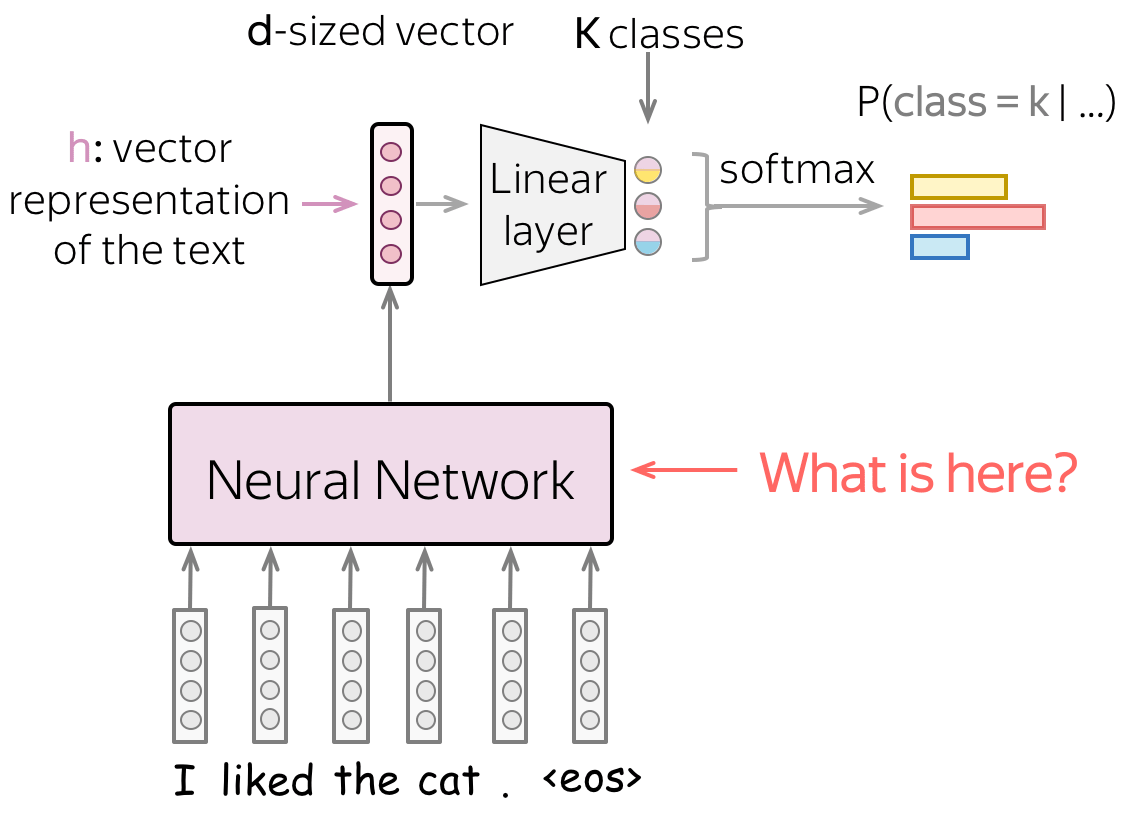
在这一部分中,我们将研究使用神经网络获取输入文本的向量表示的不同方法。请注意,虽然输入文本可以有不同的长度,但文本的向量表示必须具有固定大小:否则,网络将无法“工作”。
我们从仅使用词嵌入的最简单方法开始(在此之上不添加模型)。然后我们看看循环和卷积网络。
基础知识:Bag of Embeddings (BOE) 和加权 BOE
你可以做的最简单的事情是仅使用词嵌入(Word Embedding)而不使用任何神经网络。为了获得所有文本的向量表示,我们可以对所有token的Embedding(Bag of Embeddings)求和,也可以使用这些Embedding的加权和(例如,权重为TF-IDF或其他)。
Bag of Embeddings(理想情况下,连同朴素贝叶斯)应该是任何具有神经网络模型的基线模型:如果你不能做得比这更好,那么根本不值得使用 NN。如果你没有太多数据,可能会出现效果低于基线模型的状况。
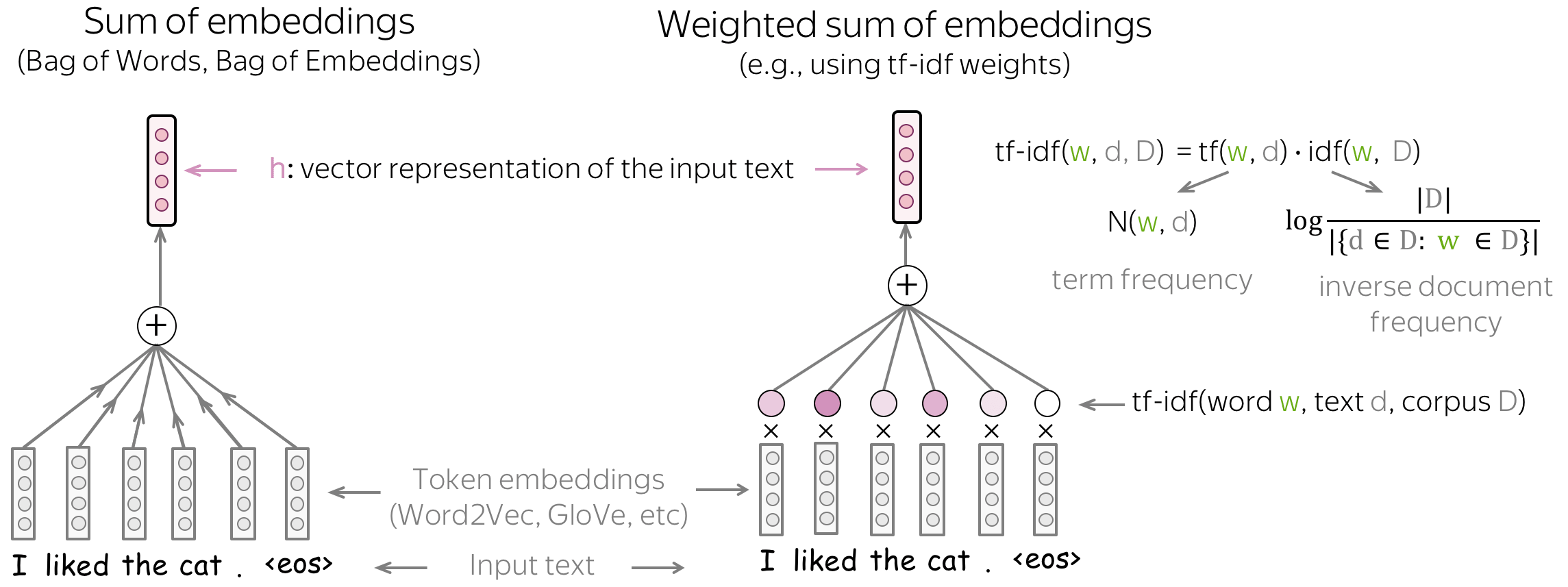
虽然Bag of Embeddings (BOE) 有时称为词袋 (BOW),但请注意, 这两者是非常不同的。 BOE 是嵌入(Embedding)的总和,BOW 是 one-hot 向量的总和: 相较而言,BOE 对语言了解更多。预训练的嵌入(例如 Word2Vec 或 GloVe)能够理解单词之间的相似性。例如, awesome, brilliant, great 在 BOW 中是不相关的特征表示,但在 BOE 中会有相似的词向量表示。
另请注意,如果到这里,想使用嵌入的加权和,可能会要用一种方法来获得权重。然而,这正是我们希望通过使用神经网络来避免的:我们不想引入手动特征,而是让网络学习有用的模式。
BOE作为 SVM 的特征
你可以在 BOE 之上使用 SVM!与经典方法中的支持向量机SVM的唯一区别在于内核的选择,这里 RBF 核更好。
模型:循环(RNN/LSTM/等)
从某种意义上说,循环网络是处理文本的一种自然方式,类似于人类,它们一个接一个地“读取”一系列token并处理信息。 并希望在每一步,神经网络都会“记住”它之前读过的所有内容 (译者注:这里的“所有”是相对而言的理想状况,而受模型及参数限制,会进行一定的遗忘。)
基础知识:循环神经网络(RNN)
- RNN单元
在每一步中,循环网络都会接收一个新的输入向量(例如,token embedding)和之前的序列状态(希望能够对所有之前的信息进行编码)。 使用这个输入,RNN 单元计算它作为输出的新状态。 这个新状态能够有效包含当前输入和先前序列的信息。
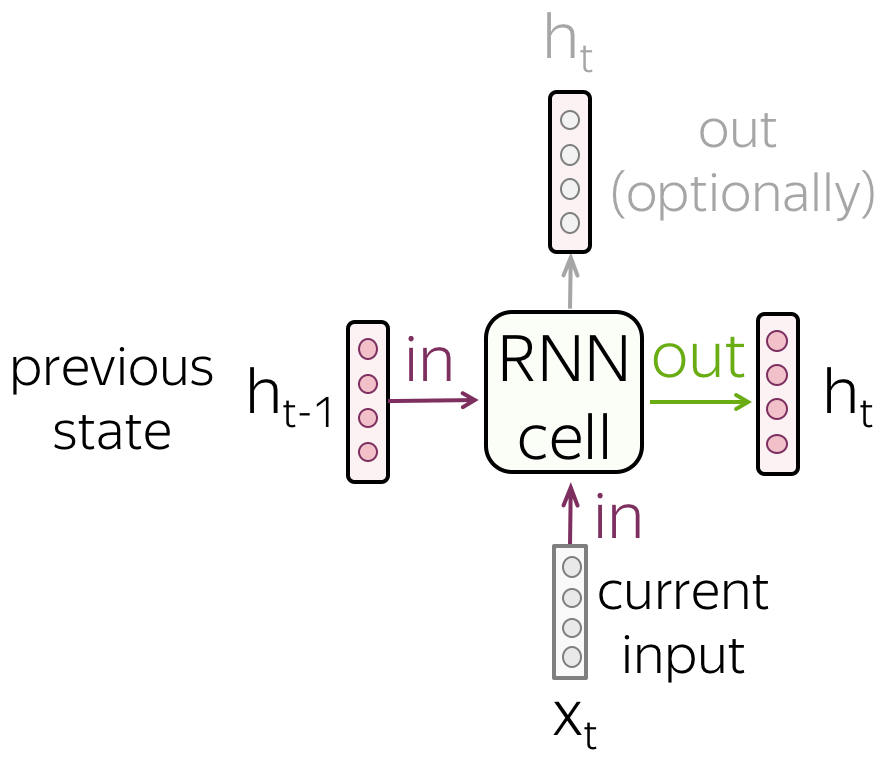
- RNN 读取一系列tokens
如图所示,RNN 逐个标记读取文本标记,在每一步都使用新的token embedding和先前的状态。
请注意, RNN 单元在每一步是相同的 ! - Vanilla RNN
最简单的循环网络, Vanilla RNN,对 h t − 1 h_{t-1} ht−1 和 x t x_t xt 使用线性变换,然后应用非线性函数(最常见的是 tanh \tanh tanh 函数):
h t = tanh ( h t − 1 W h + x t W t ) . h_t = \tanh(h_{t-1}W_h + x_tW_t). ht=tanh(ht−1Wh+xtWt).
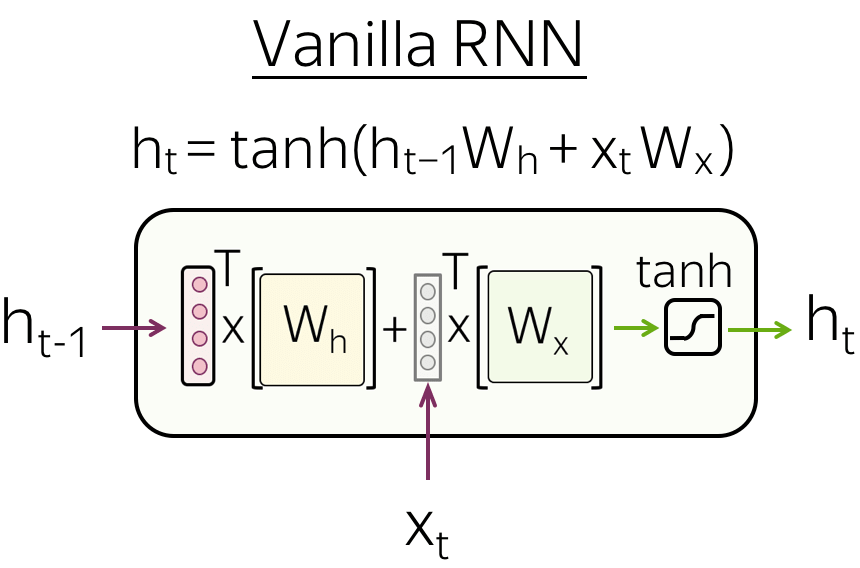
Vanilla RNN 存在梯度消失和爆炸的问题。为了缓解这个问题,更复杂的循环单元(例如 LSTM、GRU 等)对输入执行多个操作并使用门(gates)。有关 RNN 基础知识的更多详细信息,请查看 Colah 的博客文章.
循环神经网络文本分类
在这里,我们(终于!)看看如何使用循环模型进行文本分类。你将在此处看到的所有内容都将适用于所有循环单元,并且在本部分中,“RNN”指的是普遍意义上的的循环单元(例如 vanilla RNN、LSTM、GRU 等)。
让我们回忆一下我们需要什么:
我们需要一个可以为不同长度的输入生成固定大小向量的模型。
- 1
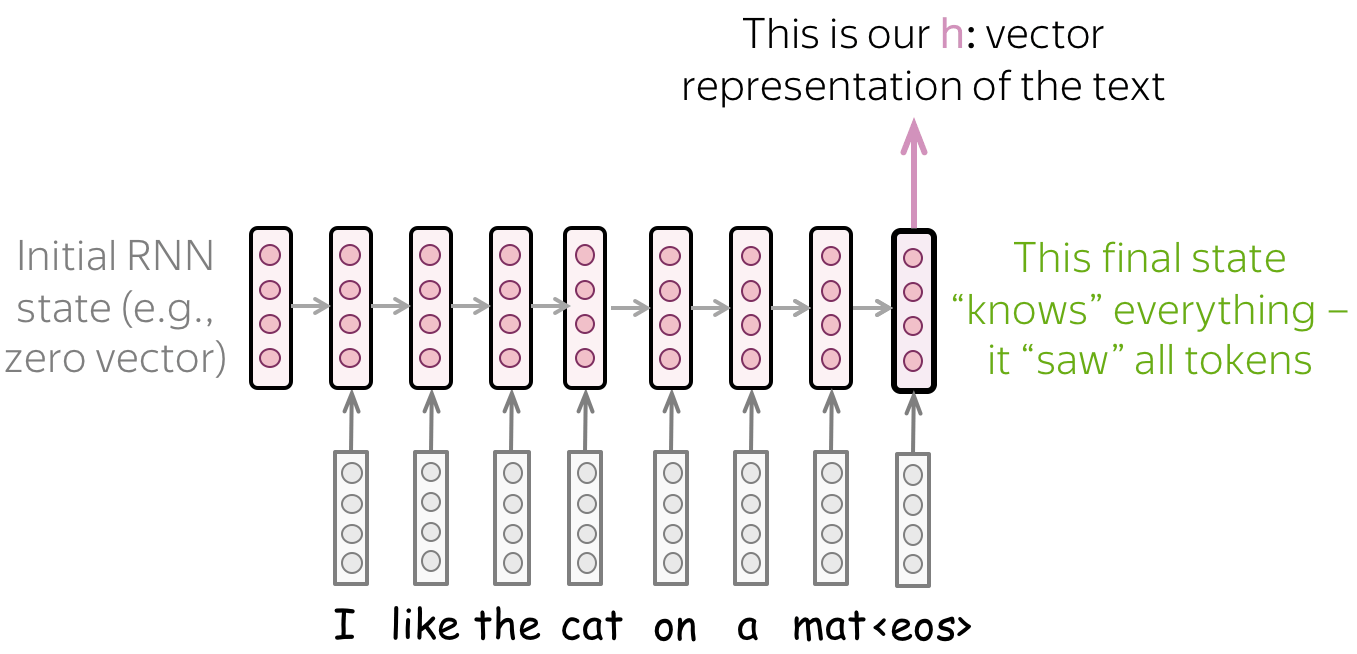
- 简单模型:阅读文本,获取最终状态
最简单的循环模型是一层 RNN 网络。在这个网络中,我们必须采用更了解输入文本的状态。因此,我们必须使用最后一个状态,只有这个状态才能看到所有输入token。
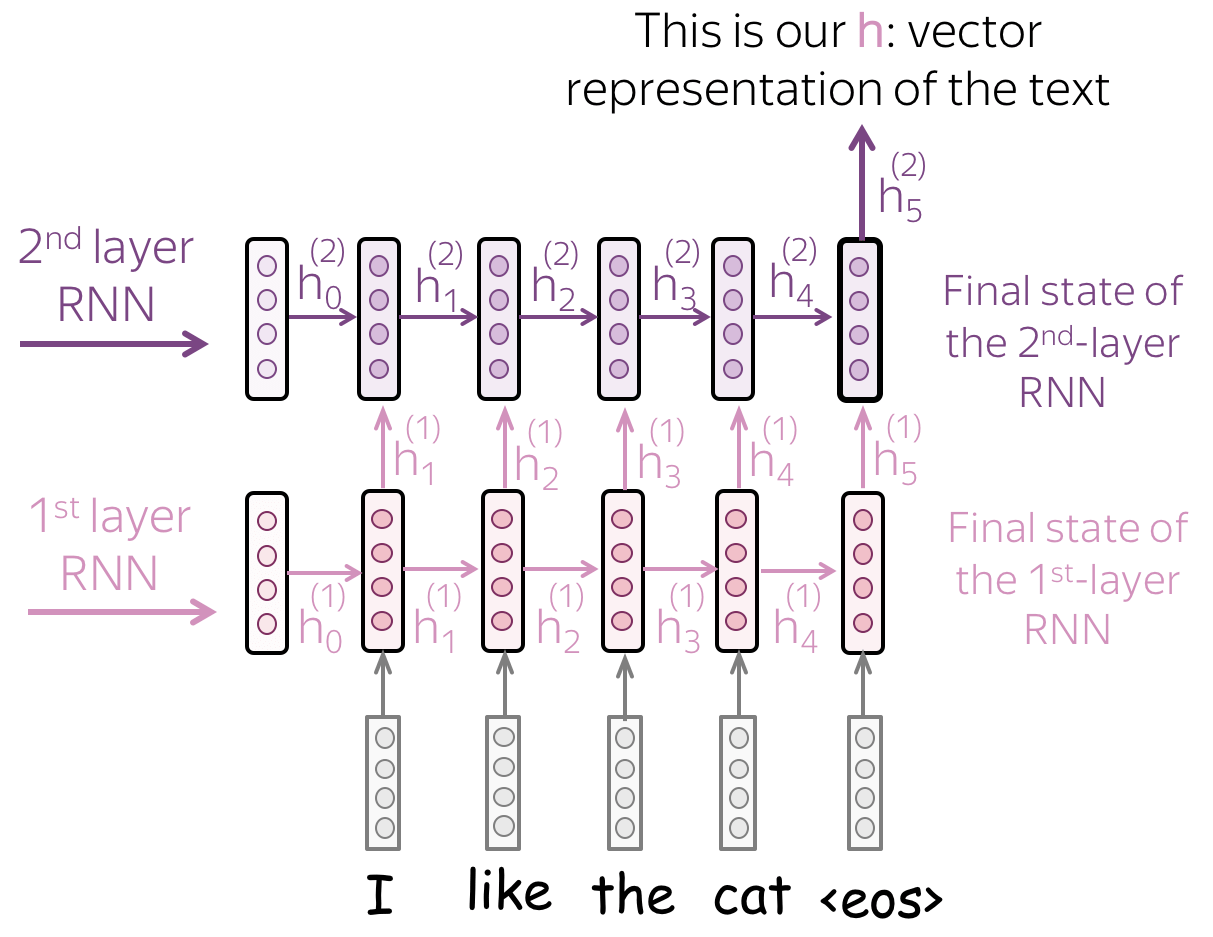
- 多层模型:将状态从一层 RNN 传递到下一层
为了获得更好的文本表示,你可以堆叠多个层。在这种情况下,较高 RNN 的输入是来自前一层的表示。
主要假设是,通过多层,较低层将捕获局部现象(例如,短语),而较高层将能够学习更多抽象概念(例如,主题)。
- 双向模型:使用前向和后向RNN 的最终状态。
以前的方法可能有一个问题:最后一个状态很容易“忘记”早期的token。即使是像 LSTM 这样的强大模型仍然会受到影响!
为了避免这种情况,我们可以使用两个 RNN: 前向,从左到右读取输入, 后向,从右到左读取输入。 然后我们可以使用两个模型的最终状态:一个会更好地记住文本的最后部分,另一个类似地也会很好地记住文本的开头部分。这些状态可以连接,求和,或其他。这就是你的选择了!

- 组合模型:随心所欲!
你可以结合上面的想法。例如,在多层网络中,某些层可以朝相反的方向移动,等等。
模型:卷积(CNN)
卷积模型的详细描述在卷积模型补充文章中。在本章该部分中,我们只考虑用于文本分类的卷积。
用于图像的卷积和平移不变性
卷积网络最初是为计算机视觉任务而开发的。因此,让我们首先了解图像卷积模型背后的直觉。
想象一下,我们想要将图像分类为几个类别,例如猫、狗、飞机等。在这种情况下,如果你在图像上找到一只猫,你并不关心 这只猫在图像上的什么位置:你只关心它是否存在在某个地方。

卷积网络针对图像的每个局部应用相同的操作:这就是它们提取特征的方式。每个操作都在寻找与模式的匹配,并且网络会学习哪些模式是有用的。随着层数的增加,学习模式变得越来越复杂:从早期层的线条到上层非常复杂的模式(例如,整只猫或狗)。你可以查看分析与解释 章节中的示例。
这个属性被称为 平移不变性: 平移是因为我们谈论的是空间的变化, 不变性是因为我们认为它在此处无关紧要。
文本卷积
对于图像,一切都很清楚:例如我们能够移动一只猫,因为我们不在乎猫在哪里。但是文本呢?乍一看,这不是那么简单:我们不能轻易移动短语,因为意思会改变,或者我们会得到一些没有多大意义的东西。
但是,在某些应用程序中,我们可以想到相同的直觉。假设我们想要对文本进行分类,但不是像图像中那样对猫/狗进行分类,而是对正面/负面情绪进行分类。然后有一些单词和短语可能是非常有用的“线索”(例如 it’s been great, bored to death, absolutely amazing, the best ever等) ,以及其他根本不重要的。我们不太在乎我们在文本中看到 bored to death 在文本哪一部分哪来理解情绪,对吧?

典型模型:卷积+池化块
按照上面的直觉,我们想检测一些模式,但我们不太关心这些模式到底在哪里。此行为通过两层实现:
- 卷积:查找与模式匹配的内容(如我们在上面看到的猫头);
- 池化:聚合这些匹配的位置(局部或全局)。
用于文本分类的典型卷积模型如图所示。为了获得输入文本的向量表示,将卷积层应用于词嵌入,然后是非线性(通常是 ReLU)和池化操作。这种表示用于分类的方式与其他网络类似。
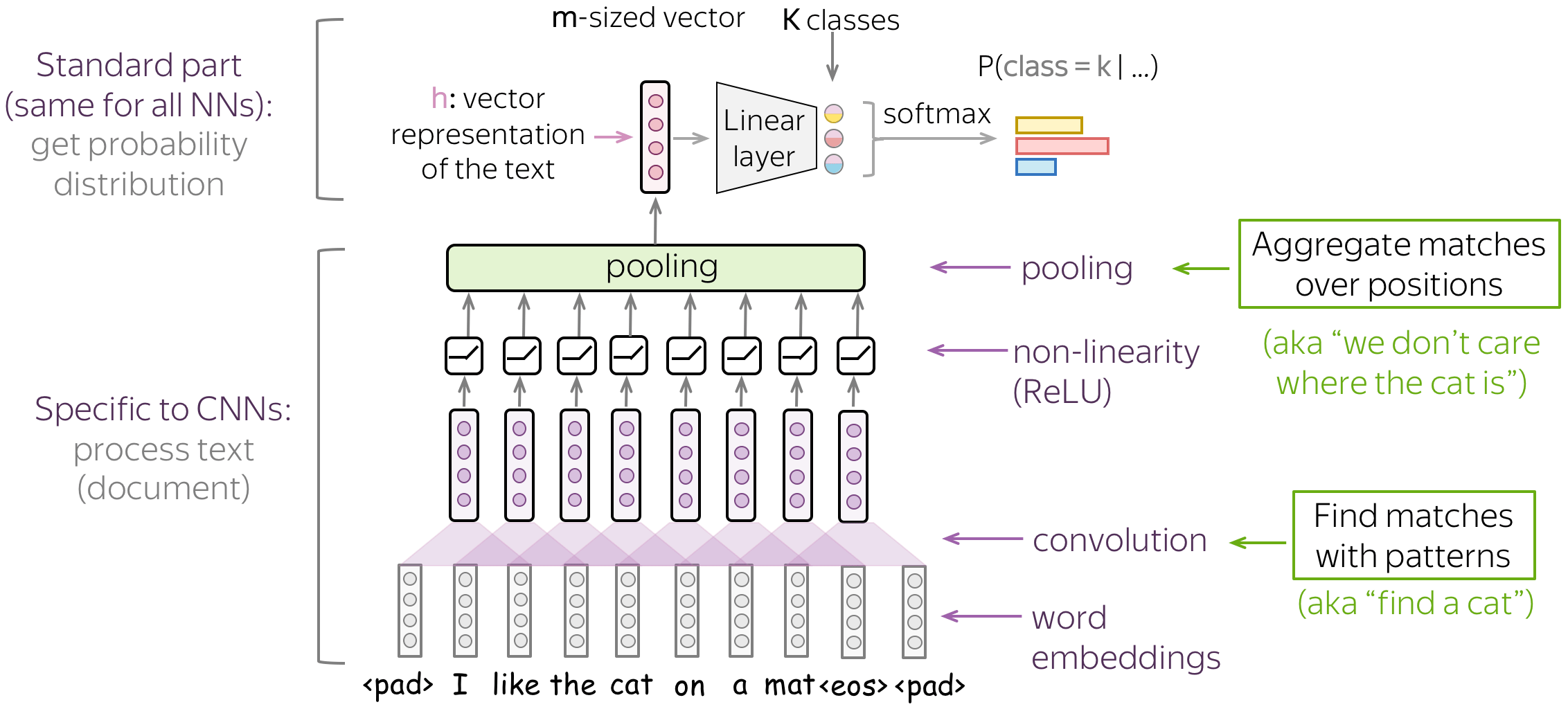
在下文中,我们将详细讨论主要的构建模块、卷积和池化,然后考虑总体建模。
基础知识:文本的卷积层
卷积神经网络最初是为计算机视觉任务而开发的,例如图像分类(猫与狗等)。卷积的想法是用滑动窗口遍历图像,并对每个窗口应用相同的 卷积Filter操作。
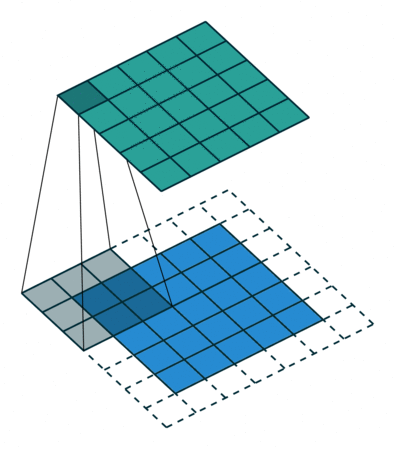
该图(取自 仓库)显示了一个Filter的卷积过程 底部是输入图像,Filter顶部是输出。由于图像具有二维(宽度和高度),因此卷积是二维的。
与图像不同,文本只有一维:这里的卷积是一维的:看插图。
卷积是应用于每个窗口的线性运算
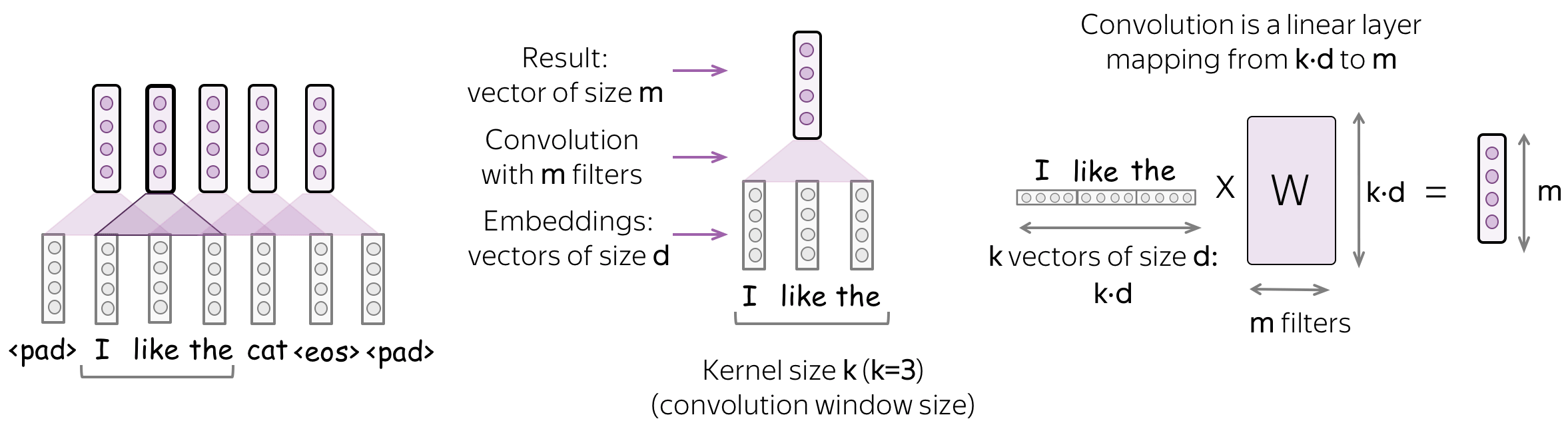
卷积是应用于每个输入窗口的线性层(后面是非线性层)。 正式地,让我们假设
- ( x 1 , … , x n ) (x_1, \dots, x_n) (x1,…,xn) - 输入词的表示 x i ∈ R d x_i\in \mathbb{R}^d xi∈Rd;
- d d d (输入通道) - 输入Embedding的大小;
- k k k (卷积核大小) - 卷积窗口的长度(上图中 k = 3 k=3 k=3);
-
m
m
m (输出通道) - 卷积Filter的数量(即卷积产生的通道数)。
那么卷积就是一个线性层 W ∈ R ( k ⋅ d ) × m W\in\mathbb{R}^{(k\cdot d)\times m} W∈R(k⋅d)×m 。对于一个大小为 k k k 的窗口 ( x i , … x i + k − 1 ) (x_i, \dots x_{i+k-1}) (xi,…xi+k−1),卷积将这些向量拼接起来:
u i = [ x i , … x i + k − 1 ] ∈ R k ⋅ d u_i = [x_i, \dots x_{i+k-1}]\in\mathbb{R}^{k\cdot d} ui=[xi,…xi+k−1]∈Rk⋅d
然后乘以卷积矩阵:
F i = u i × W . F_i = u_i \times W. Fi=ui×W.
卷积使用滑动窗口遍历输入,并对每个窗口应用相同的线性变换。
直觉:每个Filter都提取一个特征
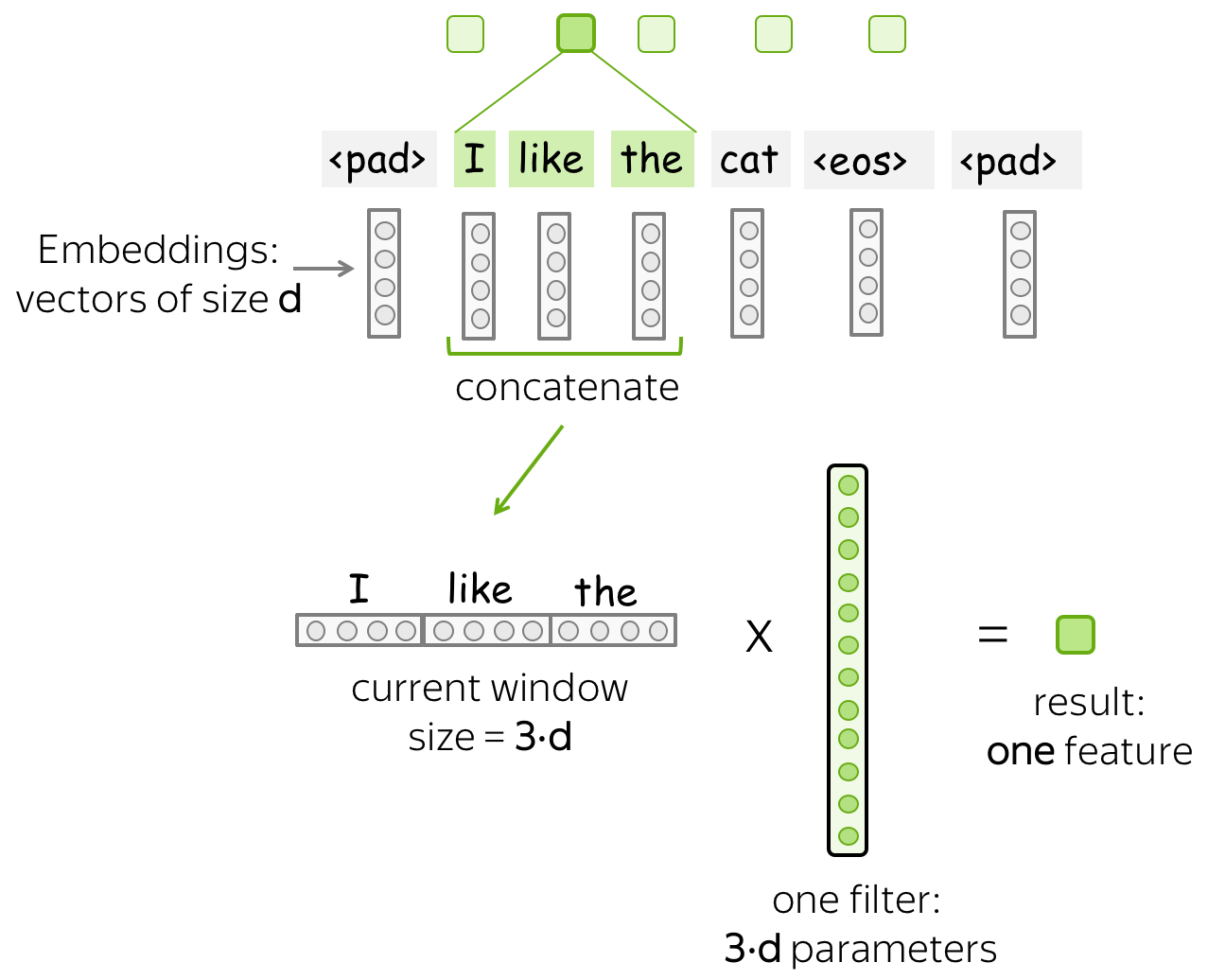
直观地说,卷积中的每个Filter都会提取一个特征。
- 一个Filter - 一个特征提取器
Filter考虑了当前窗口中的向量表示并将它们线性转换为单个特征。 形式上,对于一个窗口 u i = [ x i , … x i + k − 1 ] ∈ R k ⋅ d u_i = [x_i, \dots x_{i+k-1}]\in\mathbb{R}^{k\cdot d} ui=[xi,…xi+k−1]∈Rk⋅d , Filter f ∈ R k ⋅ d f\in\mathbb{R}^{k\cdot d} f∈Rk⋅d 计算了窗口内元素的点积:
F i ( f ) = ( f , u i ) . F_i^{(f)} = (f, u_i). Fi(f)=(f,ui).
F i ( f ) F_i^{(f)} Fi(f) (提取的“特征”)的数量是将Filter f f f 应用于窗口 ( x i , … x i + k − 1 ) (x_i, \dots x_{i+k-1}) (xi,…xi+k−1) 后的结果。
- m 个Filter:m 个特征提取器
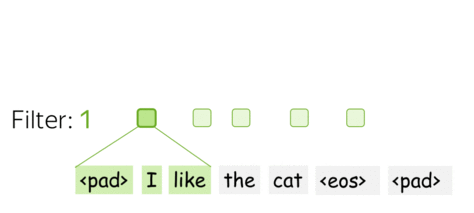
一个Filter提取一个单一的特征。通常情况下,我们想要许多特征:为此,我们必须采取几个Filter。每个Filter读取一个输入文本并提取一个不同的特征 - 请看图。Filter的数量就是你想得到的输出特征的数量。如果有 m m m 个Filter而不是一个,我们上面讨论的卷积层的大小将变成 ( k ⋅ d ) × m (k\cdot d)\times m (k⋅d)×m
这是并行完成的! 请注意,虽然我向你展示了 CNN 如何“读取”文本,但实际上这些计算是并行完成的。
基础知识:池化操作
在一个卷积从每个窗口中提取 m m m 个特征之后,一个池化层总结了某个区域的特征。池化 层用于减少输入维度,从而减少网络使用的参数数量。
- 最大池化和平均池化
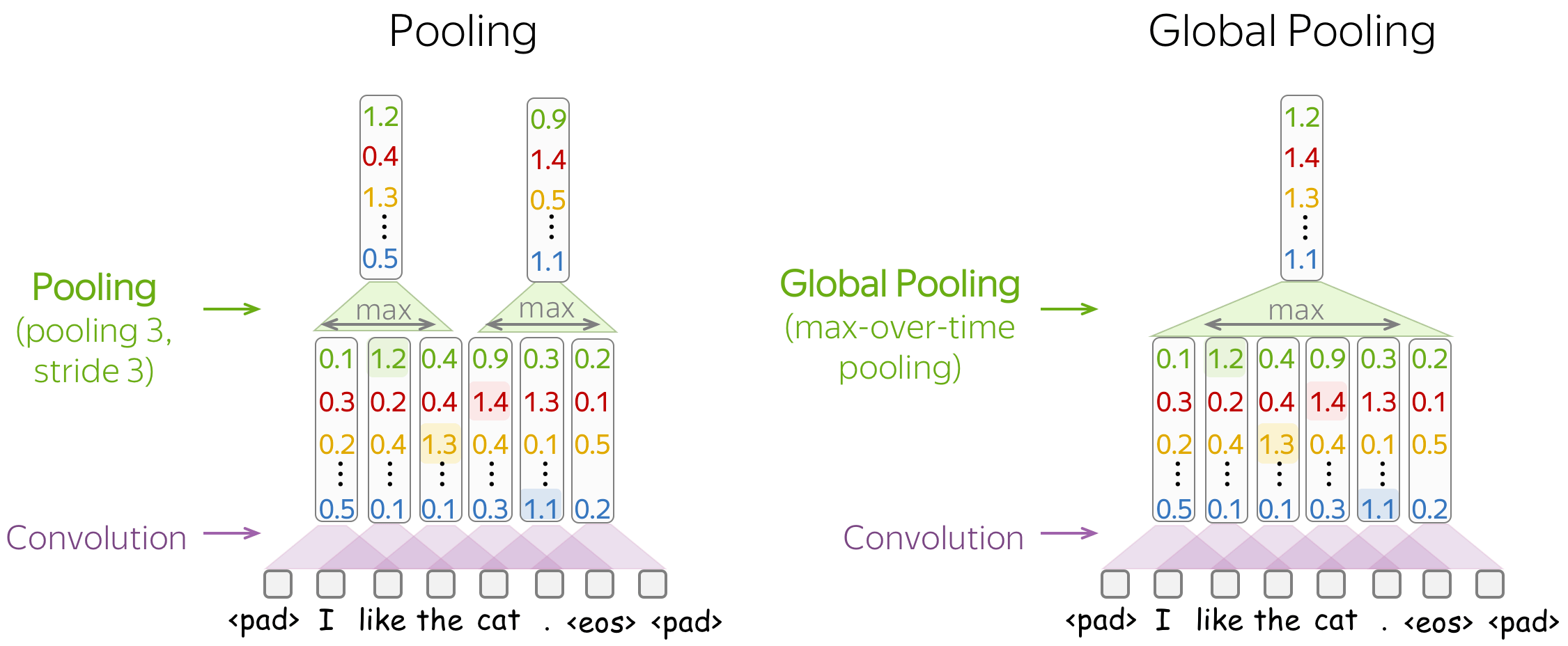
最流行的是最大池化(max-pooling):它在每个维度上取最大值,即取每个特征的最大值。

直观地说,每个特征在看到某种模式时都会“触发”:图像中的视觉模式(线条、纹理、猫爪等)或文本模式(例如短语)。在池化操作之后,我们有一个向量来说明输入中出现了哪些模式。
均值池化(Mean-pooling) 的工作方式类似,但计算每个特征的均值而不是最大值。 - 池化和全局池化
与卷积类似,池化应用于多个元素的窗口。池化也有步幅参数,最常见的方法是使用非重叠窗口的池化。为此,你必须将 步长(stride) 参数设置为与池大小相同。如下图所示。
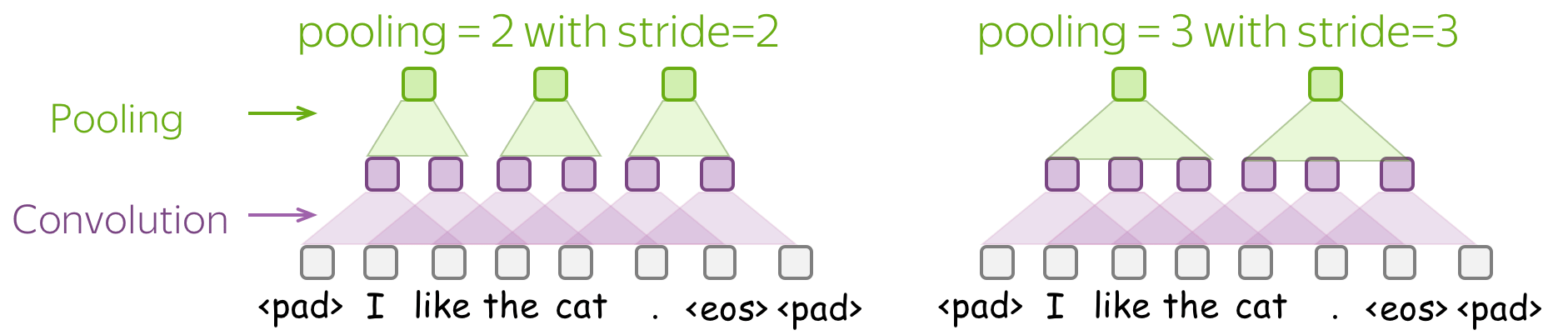
池化和全局池化 之间的区别在于,池化独立应用于每个窗口中的特征,而全局池化对整个输入执行。对于文本,通常使用全局池化来获得表示整个文本的单个向量;这种全局池化称为 max-over-time pooling,其中“时间”轴从第一个输入token到最后一个输入token。
用于文本分类的卷积神经网络
现在,当我们了解卷积和池化的工作原理后,让我们来进行建模。首先,让我们回顾一下我们需要什么:
我们需要一个可以为 不同 长度的输入生成 固定大小 向量的模型。
- 1
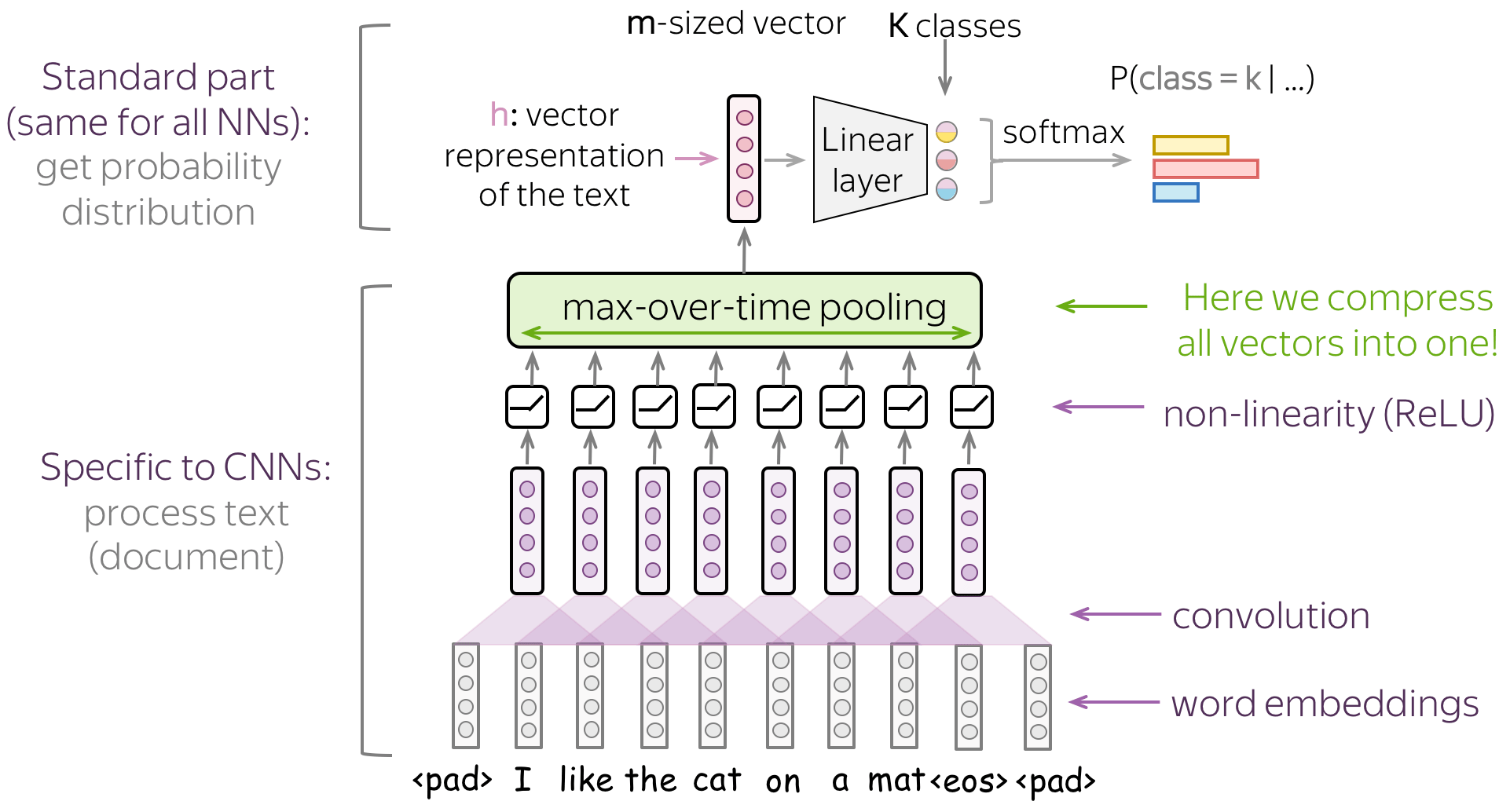
因此,我们需要构建一个将文本表示为单个向量的卷积模型。 文本分类的基本卷积模型如图所示。它几乎和我们之前看到的一样:唯一改变的是我们指定了使用的池化类型。
文本分类的基本卷积模型如图所示。 它几乎和我们之前看到的一样:唯一改变的是我们指定了使用的池化类型。 具体来说,在卷积之后,我们使用了 global-over-time pooling 。这是关键操作:它允许将文本压缩为单个向量。模型本身可以不同,但在某些时候它必须使用全局池化将输入压缩到单个向量中。
- 不同内核大小的几个卷积
你可以使用多个具有不同卷积核大小的卷积操作,而不是为你的卷积选择一个固定的卷积核大小。方法很简单:将每个卷积应用于数据,在每个卷积之后添加非线性和全局池化,然后将结果拼接起来(在插图中,为简单起见省略了非线性)。这就是你获得用于分类的数据的矢量表示的方式。
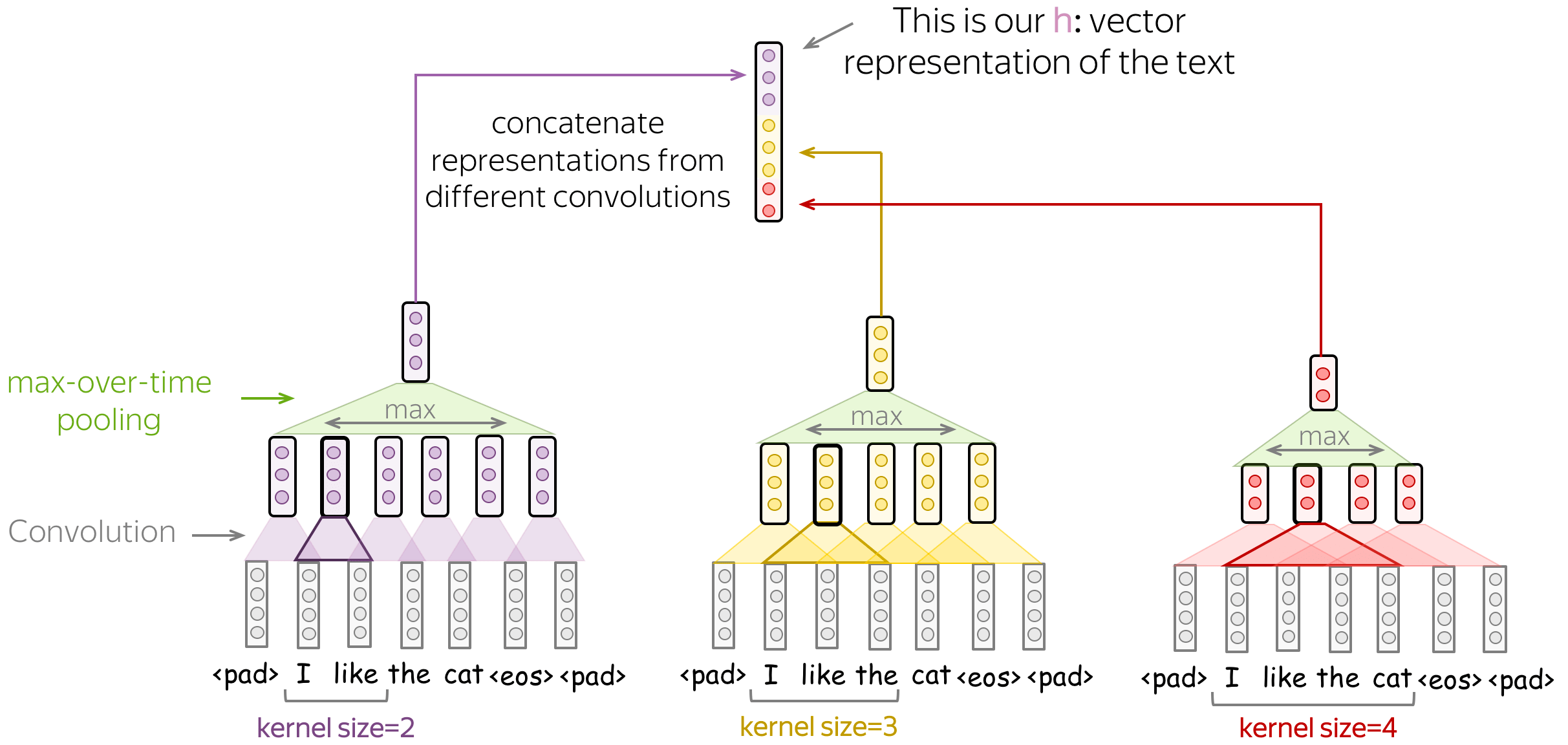
这个想法在论文 Convolutional Neural Networks for Sentence Classification 和许多后续文章中被使用。 - 建模:堆叠几个块 卷积+池化
你可以将多个卷积+池化操作块堆叠在一起,而不是单单的一层。在堆叠几个块之后,你可以应用其他卷积,但要在最后的输出部分使用全局池化。 记住:你必须得到一个固定大小的向量 - 为此,你需要全局池化操作。
当你的文本很长时,这种多层卷积会很有用;例如,如果您的模型是字符级(而不是单词级)。
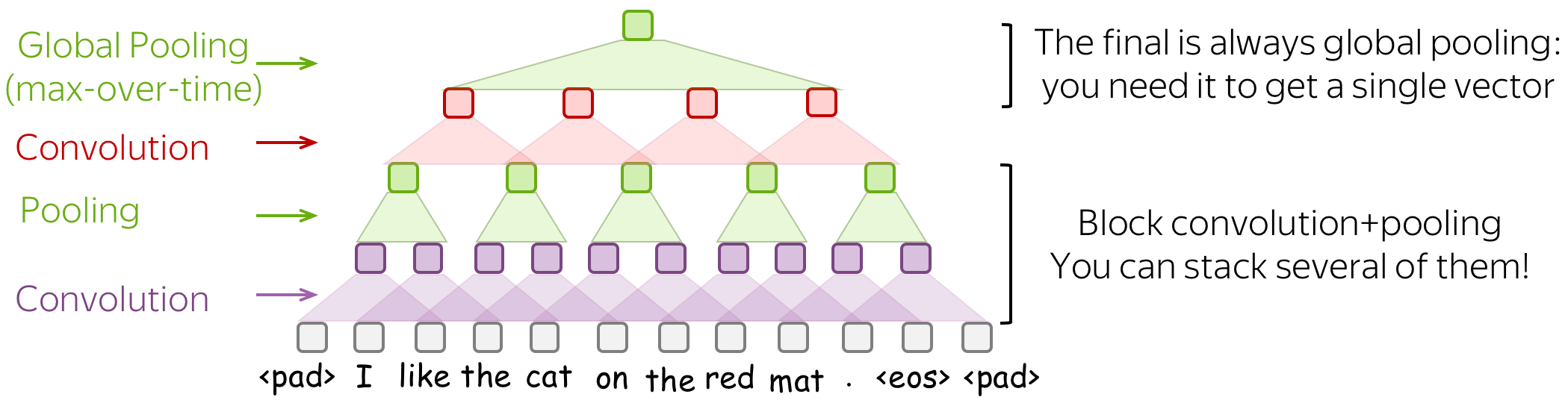
这个想法参考了论文 Character-level Convolutional Networks for Text Classification.
5、多标签分类
多标签 分类与我们之前讨论的 单标签 问题不同,每个输入可以有几个正确的标签。例如,一个推特可以有多个主题标签,一个用户可以有多个感兴趣的主题,等等。
对于多标签问题,我们需要在之前讨论的单标签pipeline中更改两件事:
- 模型(我们如何评估类别概率);
- 损失函数

模型: Softmax → Element-wise Sigmoid
在最后一个线性层之后,我们有对应于
K
K
K 个类别的
K
K
K 个值——这些值是我们必须转换为类别概率的值。
对于单标签问题,我们使用softmax:它将
K
K
K 个值转化为概率分布,即所有概率之和为1。这意味着类共享相同的概率质量: 如果一个类的概率高,其他类可以概率不大。 ( 编者按:再次想象一下,一群小猫从同一个碗里吃东西:一只小猫吃得多总是以牺牲其他小猫吃得少为代价 )。
对于多标签问题,我们将
K
K
K 个值中的每一个值都转换为对应类别的概率,独立于其他类别。 具体来说,我们将 sigmoid 函数应用于每个
K
K
K 值:
σ
(
x
)
=
1
1
+
e
−
x
\sigma(x)=\frac{1}{1+e^{-x}}
σ(x)=1+e−x1
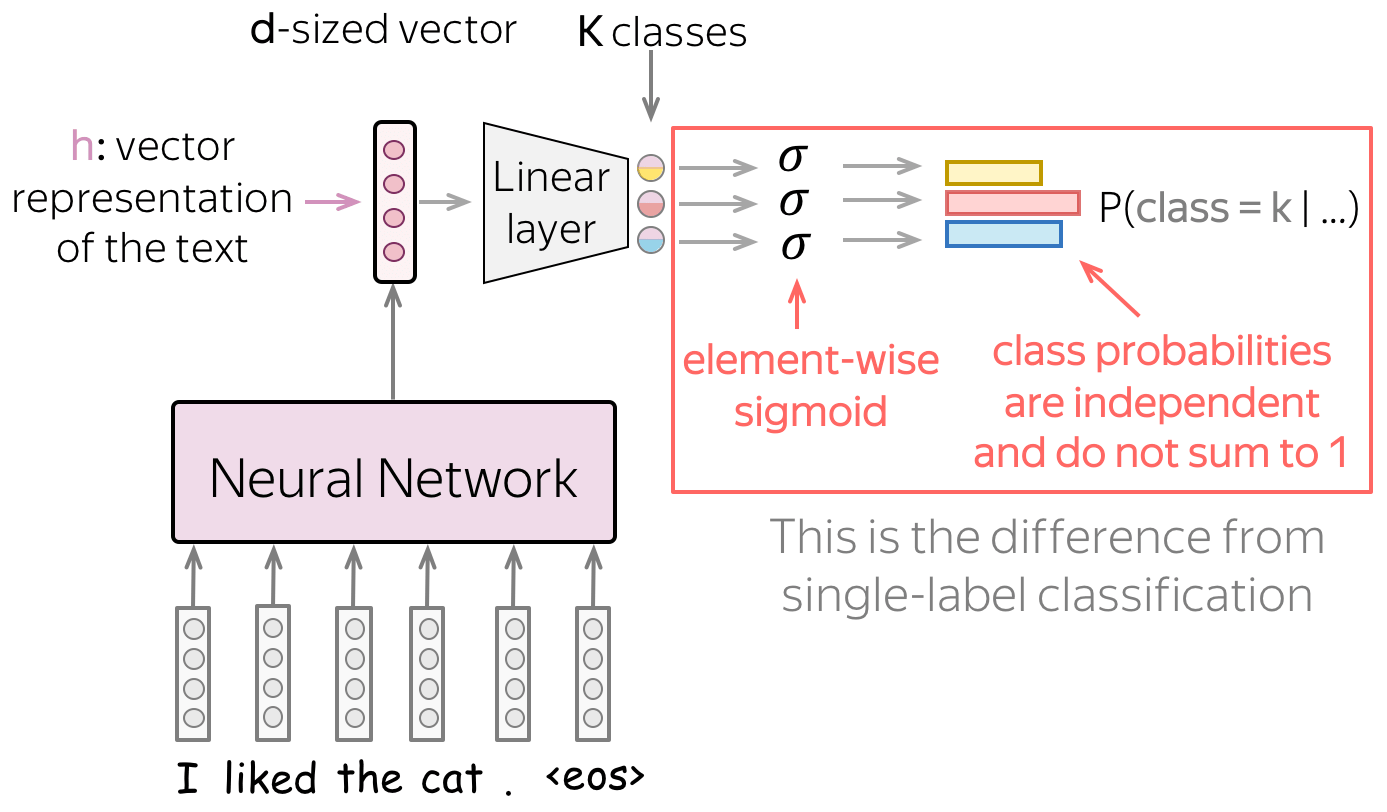
直观地说,我们可以认为多标签分类是
K
K
K 个独立的二进制分类器组合,其中,这些分类器使用相同的文本表示。
损失函数:每个类的二进制交叉熵
损失函数更改以启用多个标签:对于每个类,我们使用二元交叉熵损失。 见下图。
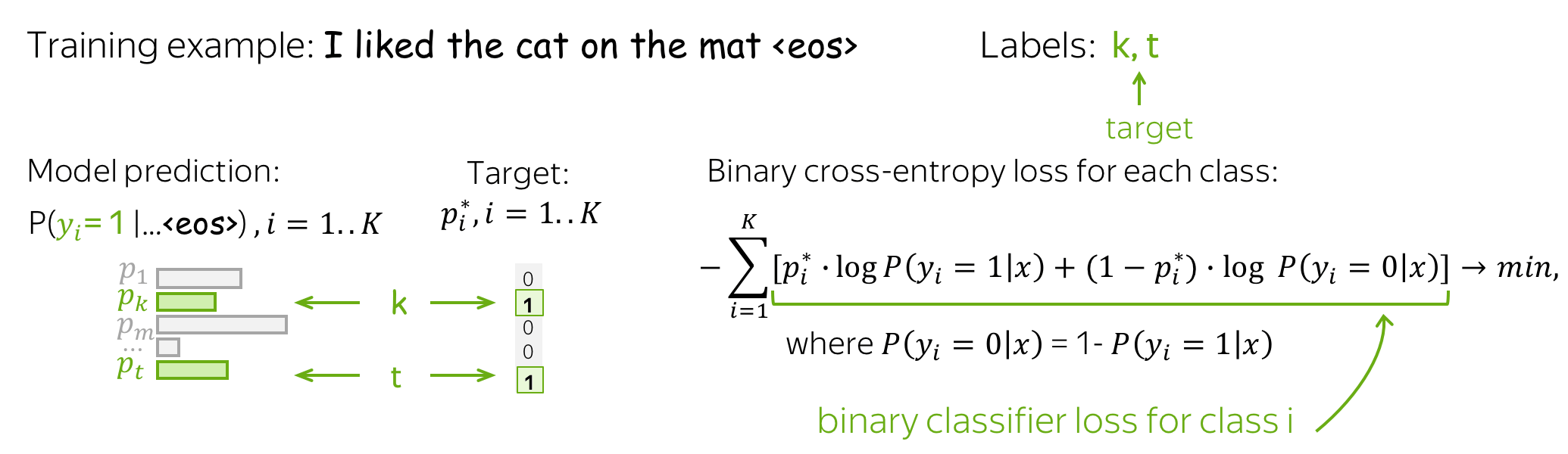
6、实践建议
词嵌入:如何解决他们?
网络的输入由词嵌入表示。 您有三种选择如何为您的模型获取这些嵌入:
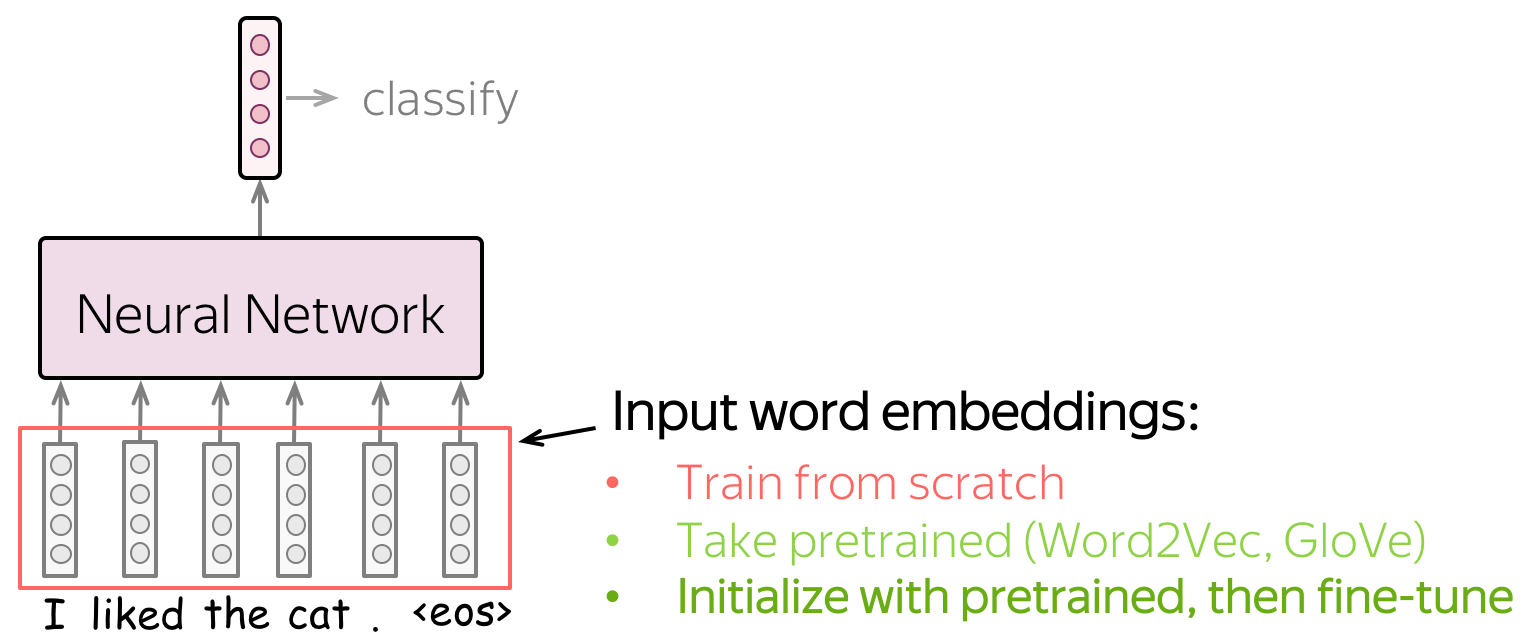
- 作为模型的一部分从头开始训练,
- 接受预训练(Word2Vec、GloVe 等)并固定它们(将它们用作静态向量),
- 使用预训练嵌入进行初始化并使用网络训练它们(“微调(fine-tune)”)。
这三种选择具体该怎么选择呢?实际上,我们往往通过观察模型可用的数据来考虑这些选择。
用于分类的训练数据是需要标签并适用于特定于任务的,但通常带有标签的数据难以得到。 因此,这个语料库可能并不庞大(至少相对而言),或不多样化,或两者兼而有之。
相反,词嵌入的训练数据没有标记,只需要纯文本就足够了。 因此,这些数据集可以是巨大而多样的,这有很多东西可以学习。

现在让我们想想模型会根据我们对Embedding的处理方式学到什么。 - 如果嵌入是从头开始训练的,模型将只“知道”分类数据 - 这可能不足以很好地学习单词之间的关系。
- 但是如果我们使用预训练的嵌入,他们(以及整个模型)将知道一个巨大的语料库 - 他们会学到很多关于这个世界的知识。
- 为了使这些嵌入适应您的特定任务数据,您可以通过对整个网络进行训练来微调这些嵌入 - 这可以带来性能提升(虽然不是很大)。
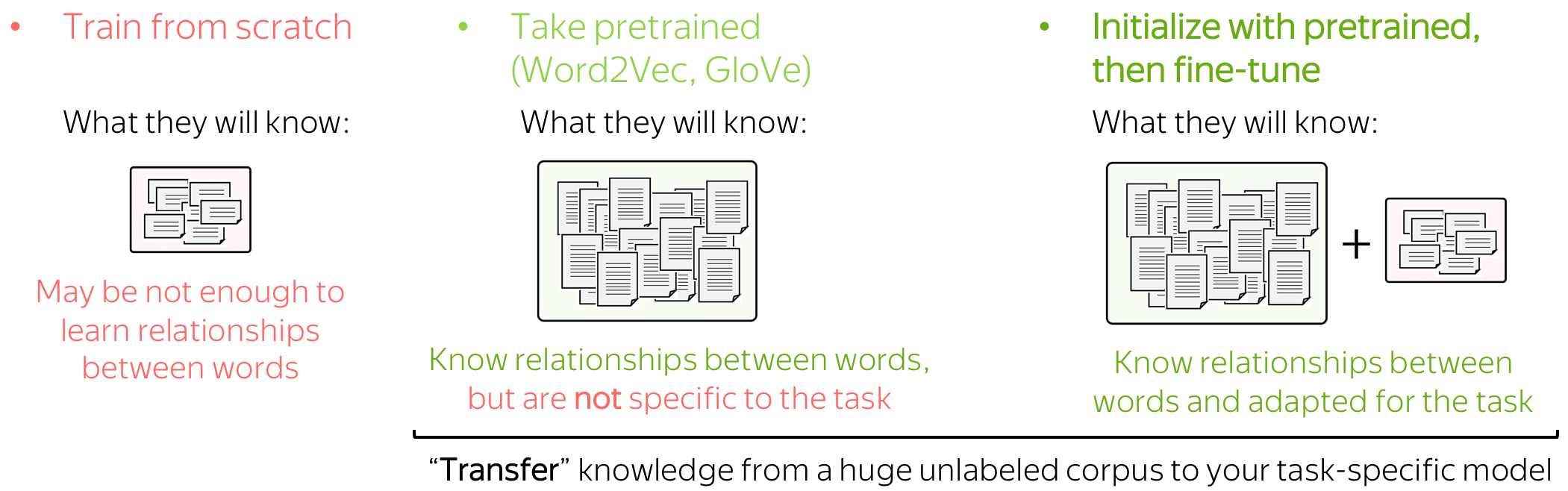
当我们使用预训练Embedding时,就是 迁移学习 的一个典型示例:通过Embedding,我们将其训练数据的知识“迁移”到我们的任务特定模型。我们将在课程的后面部分了解有关迁移学习的更多信息。
在这个充满科技魔力的时代,自然语言处理(NLP)正如一颗璀璨的明星般照亮我们的数字世界。当我们涉足NLP的浩瀚宇宙,仿佛开启了一场语言的奇幻冒险。正如亚历克斯·康普顿所言:“语言是我们思想的工具,而NLP则是赋予语言新生命的魔法。”这篇博客将引领你走进NLP前沿,发现语言与技术的交汇点,探寻其中的无尽可能。不论你是刚刚踏入NLP的大门,还是这个领域的资深专家,我的博客都将为你提供有益的信息。一起探索语言的边界,迎接未知的挑战,让我们共同在NLP的海洋中畅游!期待与你一同成长,感谢你的关注和支持。欢迎任何人前来讨论问题。

