
热门标签
热门文章
- 1数据结构--数组和链表的区别,以及优缺点,结合两者优点的方法_链表比数组能储存更多信息对吗为什么
- 2安卓ondraw刷新视图,OnDraw的自定义视图无限循环的android
- 3MySQL数据库-DDL与DML_mysql ddl和dml
- 4java调用科大讯飞在线语音合成API --内附完整项目_java接入讯飞模型接口
- 5软件项目管理全套文档模板
- 6大数据基础平台——MapReduce计算框架_创建map函数的python脚本mapper.py
- 7Linux 常用命令与教程_哪条命令同时包含3条或3条以上命令,只执行成功第一条并输出?如果要求全部成功并输
- 8jenkins(docker)安装及应用_docker 安装jenkins
- 9Ubuntu系统提示Sorry, command-not-found has crashed 解决方法_chown -r: command not found
- 10svn迁移到git并保留完整提交记录_svn代码迁移到git 保留日志
当前位置: article > 正文
ERROR Shell: Failed to locate the winutils binary in the hadoop binary path java.io.IOException
作者:小丑西瓜9 | 2024-06-07 16:13:49
赞
踩
failed to locate the winutils binary in the hadoop binary path java.io.ioexc
使用spark时遇到一个非常难绷的问题
ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable E:\hadoop\spark-3.0.0-bin-hadoop2.7\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:382)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:397)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:390)
at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:80)
- 1
- 2
- 3
- 4
- 5
- 6
困扰我2个小时,我一开始以为是Hadoop没有下载问题,就下载了,没用,然后又以为版本问题,又换了spark和Hadoop对应的版本。然而问题没有解决。最后去stackOverFlow才找到解决办法
话不多说,解决方法如下:(注意:无需下载Hadoop)
问题的原因是Winutils.exe 用于运行 SPARK 的 shell 命令。当你需要在不安装Hadoop的情况下运行Spark时,需要这个文件。
步骤如下:
1. 从以下位置下载 hadoop 2.7.1 的 winutils.exe
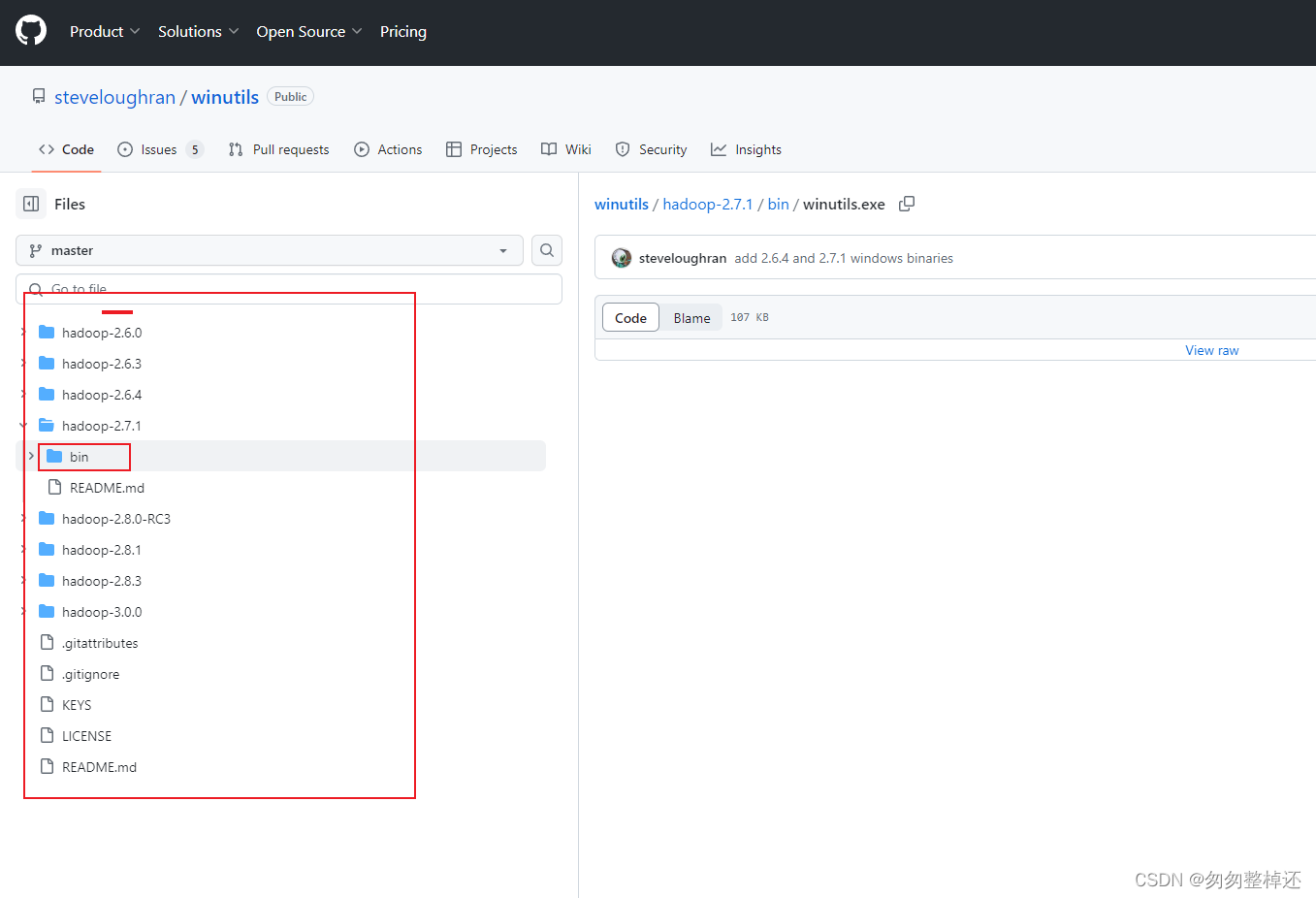
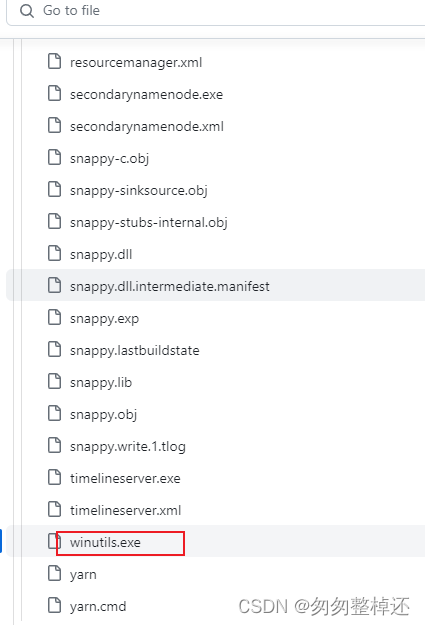
地址:https://github.com/steveloughran/winutils/blob/master/hadoop-2.7.1/bin/winutils.exe [注意:如果使用单独的 hadoop 版本,请务必下载winutils 来自 GITHUB 上相应 hadoop 版本文件夹,位置如上所述。]【见注解一】
2. 在 C:盘中创建一个文件夹“winutils”。在文件夹“winutils”内创建一个文件夹“bin”,并将 winutils.exe 复制到该文件夹中。因此 winutils.exe 的位置将是**C:\winutils\bin\winutils.exe**
3. 现在,打开环境变量并设置 HADOOP_HOME=C:\winutils [注意:请不要 在HADOOP_HOME中添加\bin,并且无需在 Path 中设置 HADOOP_HOME]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
注解一:GitHub上按照所需版本选bin下的winutils.exe
如果有其他情况可以去该帖子看看:
Stack Overflow
最后吐槽一句,spark团队很牛,但是这种小bug太多了,尤其是我用jdk17版本,有些问题只能降低到11或者8才行
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/686105
推荐阅读
相关标签

