
- 1【已解决】OSError: could not find or load spatialindex_c-64.dll
- 2Linux安装Jenkins结合内网穿透实现远程访问测试软件_jenkins局域网内网访问另一台电脑
- 3解决:Caused by: redis.clients.jedis.exceptions.JedisDataException: WRONGTYPE Operation against a key
- 4基于旭日派的Ros系统小车的再开发——使用python脚本Astra调用深度相机(学习笔记)_ros 小车 astra
- 5Python打造漏洞扫描器 10_python 漏洞扫描
- 6Hadoop介绍:什么是Hadoop?了解Hadoop的应用_简单认识hadoop项目
- 7微信小程序获取图片的宽高,以及如何获取手机设备的宽高?_小程序获取图片宽高
- 8C++ | Leetcode C++题解之第124题二叉树中的最大路径和
- 9建议收藏,详解Python实现进阶版人脸识别_python 人脸识别
- 10【vue video.js】The element or ID supplied is not valid. (videojs) element Ui
Seq2seq模型详解(attention mechanism+evaluation methods +Curriculum +Machine Translation)
赞
踩
0. 引言

seq2seq中文名字就是序列到序列模型。关于他的讲解和探究已经有很多通俗易懂的博客。本篇博客 旨在纪录自己对seq2seq模型的理解,希望读者看到可以有所收获。
1. Seq2seq Framework
序列到序列模型是一种框架结构,它接受一个序列(单词、字母、图像特征等)并输出另一个序列,由编码和解码两部分构成。如在机器翻译任务中,一个序列指的是一系列的词,一个接一个地被处理。同样,输出的也是一系列单词。

Seq2seq的核心结构是 编码器+解码器:
- 编码器处理输入序列中的每一项,将捕获的信息编译成一个向量(对输入序列的编码)。
- 在处理完整个输入序列后,编码器将上下文发送给解码器,解码器开始逐项生成输出序列。
在我们自然语言处理领域,很多问题都可用上述这个框架来做,例如阅读理解、文本摘要、闲聊系统以及看图说话等等。
下面我们简单看看机器翻译领域是如何应用Seq2seq框架来做的。谷歌是最早将序列到序列模型应用到机器翻译中的。在机器翻译的情况下,seq2seq的运行模式,input->encoder->context->decoder->output。其中context(对源文的编码)是一个向量,代表源文的信息。

我们这里以机器翻译简单看一下seq2seq的过程:
文本输入:我们这里以输入法语句子为例子,假设每个单词可以embedding成四维词向量,输入经过嵌入可以如下图所示:

编码器:我们假设编码器为RNN,每个词首先转化为词向量,一个个地输入。在每个时间步接受两个输入:来自输入语句的单词和上一时间步的隐藏状态。对于RNN我们先用预先设定好的隐状态 h 0 h_0 h0来进行初始化。
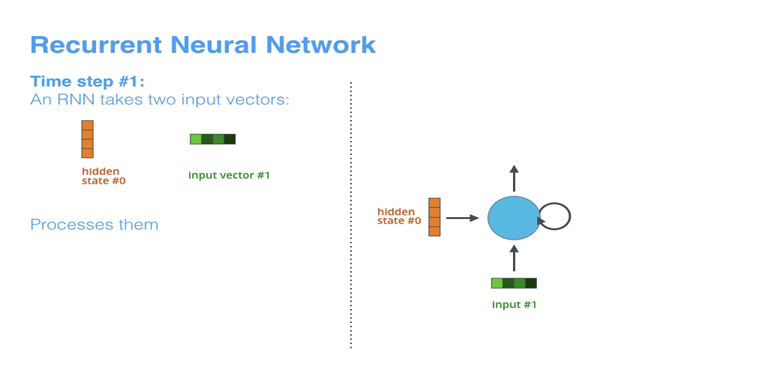
解码器:这里一般来说是将编码器的最后一个隐藏状态传递给解码器当作context信息。

对于以RNN为基础结构的seq2seq结构来说,context的准确表示是一个瓶颈,模型很难处理长句。Bahdanau等人,2014年和Luong等人,2015年提出了解决方案:引入一种称为“注意力机(attention)”的技术,极大地提高了机器翻译系统的质量。注意力机制使模型能够有选择性地关注输入序列的重要相关部分。
2. attention mechanism
注意力机制(Attention mechanism)源于认知科学,指的是人类会有选择性地关注一部分信息而忽略另一部分信息,也就是说,对于不同的信息具有不同程度的关注度。这种机制使得人类能够最大化地利用有限的视觉资源,并且获取最关键的信息。
2014年,谷歌大脑团队应用结合了注意力机制的卷积神经网络在图像分类以及物体检测任务上取得了巨大成功。随后的2015年,在自然语言处理领域,结合了注意力机制的循环神经网络结构也在机器翻译任务上取得了前所未有的成绩。
对于机器翻译来说,在翻译不同词汇的过程中,对源文信息施加不同的注意力(传统机器翻译中的对齐alignment)。
添加注意力后的模型的特点,主要有两个方面:

- 编码器向解码器传递更多的数据,编码器不传递编码阶段的最后一个隐藏状态,而是将所有隐藏状态传递给解码器。
- 注意解码器在产生输出之前执行额外的步骤,为了聚焦于与该解码时间步骤相关的输入部分,解码的每一时刻执行以下操作:通过编码器隐藏状态与解码器当前隐藏状态的相关性,对不同的编码器隐藏状态打分。打分之后的编码器隐藏状态加权相加,并与当前隐藏状态结合,再进行最后的输出运算。
重复下一个时间步骤。

下面我们简单来看看训练后的attention可视化结果:解码中不同的步骤会专注于不同的编码器隐状态。注意,模型并不是预先地将输出的第一个单词与输入的第一个单词对齐。它实际上是从训练阶段学会了如何对齐语言对中的单词。

3. evaluation methods
由于翻译的多样性,无法用一般的方式来评判。一般文本生成的任务,都难以有绝对标准的答案 。我们需要了解人工评估需要依赖哪些指标。机器翻译需要评估的指标比较多,比如充分性、通顺性、精确性等。
充分性:该翻译的信息是否都翻译完全。
通顺性:翻译的文本是否通顺。
精确性:翻译的信息是否精确。
现在流行的评估方式有BLEU和ROUGE。其中BLEU是比较偏向于精确度的,ROUGE是比较偏向召回率的。
3.1 BLEU
核心:比较候选译文和参考译文里的 n-gram 的重合程度,重合程度越高就认为译文质量越高。unigram用于衡量单词翻译的准确性,高阶n-gram用于衡量句子翻译的流畅性。通常取N=1~4,再加权平均。
所以基于词交集和ngram短语交集设计了一个算法:

P
n
P_n
Pn 指 n-gram 的精确率,
W
n
W_n
Wn指 n-gram 的权重。
B
P
BP
BP 是惩罚因子。BP(Brevity Penalty),翻译过来就是"过短惩罚"。因为对于超过参考文献长度的候选译文已经被上述方法处罚,没有必要再处罚它们。但是对于小于参考文献长度的候选译文,我们引入一个过短惩罚因子,高分数的候选译文现在必须在长度、单词选择和单词顺序上与参考译文匹配。
l
r
l_r
lr指参考译文长度。
l
c
l_c
lc指候选译文长度。希望译文更长些。
BLEU的取值范围是
[
0
,
1
]
[0,1]
[0,1],数值越大表示效果越好。
3.2 ROUGE
专注于召回率(关注有多少个参考译句中的 n- gram出现在了输出之中)而非精度(候选译文中的n-gram有没有在参考译文中出现过)。ROUGE 是一种常用的机器翻译和文章摘要评价指标,由 Chin-Yew Lin 提出,其在论文中主要提出了 3种 ROUGE 方法:
- ROUGE-N: 在 N-gram 上计算召回率
- ROUGE-L: 考虑了机器译文和参考译文之间的最长公共子序列
- ROUGE-W: 改进了ROUGE-L,用加权的方法计算最长公共子序列
3.2.1 ROUGE-N
ROUGE-N 主要统计 N-gram 上的召回率,对于 N-gram,可以计算得到 ROUGE-N 分数,计算公式如下:

公式的分母是统计在参考译文中 N-gram 的个数,而分子是统计参考译文与机器译文共有的 N-gram 个数。
3.2.2 ROUGE-L
ROUGE-L 中的 L 指最长公共子序列 (longest common subsequence, LCS),ROUGE-L 计算的时候使用了机器译文 C C C和参考译文 S S S的最长公共子序列,计算公式如下:

公式中的 R L C S R_{LCS} RLCS 表示召回率,而 P L C S P_{LCS} PLCS 表示精确率, F L C S F_{LCS} FLCS 就是 ROUGE-L。一般 beta 会设置为很大的数,因此 F L C S F_{LCS} FLCS 几乎只考虑了 R L C S R_{LCS} RLCS (即召回率)。注意这里 beta 大,则 F F F 会更加关注 R R R,而不是 P P P。如果 beta 很大,则 P L C S P_{LCS} PLCS 那一项可以忽略不计。
3.2.3 ROUGE-W
由于ROUGE-L在计算最长公共子序列时,对于子序列的连续性没有限制,即两个词汇之间可以有任意长度的代沟,但是这不一定是合理的。两个生成文本与参考文本都具有同样的最大公共子序列,此时ROUGE-L的值一样大,但是第一个生成文本的匹配是连续的,而第二个生成文本的匹配是不连续的,因此,应该是第一个生成文本的质量相对好一点才对,所以ROUGE-W在ROUGE-L的基础上对连续性添加一个权重。
3.2.4 ROUGE-S
ROUGE-S 也是对 N-gram 进行统计,但是其采用的 N-gram 允许"跳词 (Skip)",即跳跃二元组(skip bigram)。例如句子 “I have a cat” 的 Skip 2-gram 有: (I, have),(I, a),(I, cat),(have, a),(have, cat),(a, cat)。
4. training mechanism
4.1 Teacher forcing
训练迭代过程早期的RNN预测能力非常弱,几乎不能给出好的生成结果。如果某一个unit产生了垃圾结果,必然会影响后面一片unit的学习。teacher forcing最初的motivation就是解决这个问题的。图下图所示,错误结果会导致后续的学习都受到不好的影响,导致学习速度变慢,难以收敛。

Teacher forcing 每次不使用上一个state的输出作为下一个state的输入,而是直接使用训练数据的标准答案(ground truth)的对应上一项作为下一个state的输入。
Teacher Forcing同样存在缺点: 一直靠老师带的孩子是走不远的。因为依赖标签数据,在训练过程中,模型会有较好的效果,但是在测试的时候因为不能得到ground truth的支持,所以如果目前生成的序列在训练过程中有很大不同,模型就会变得脆弱。也就是说,这种模型的cross-domain能力会更差,也就是如果测试数据集与训练数据集来自不同的领域,模型的performance就会变差。
那有没有解决这个限制的办法呢?
4.2 Teacher Forcing的改进
4.2.1 Beam Search
该方法对词表中每一个单词的预测概率执行搜索,生成多个候选输出序列。通过这种启发式搜索(heuristic search),可减小模型学习阶段performance与测试阶段performance的差异。

4.2.2 Curriculum Learning
如果模型预测的是实值(real-valued)而不是离散值(discrete value),那么beam search就力不从心了。因为beam search方法仅适用于具有离散输出值的预测问题,不能用于预测实值(real-valued)输出的问题。
使用一个概率
p
p
p去选择使用ground truth的输出
y
(
t
)
y(t)
y(t)还是前一个时间步骤模型生成的输出
h
(
t
)
h(t)
h(t)作为当前时间步骤的输入
x
(
+
1
)
x(+1)
x(+1)。这个概率
p
p
p会随着时间的推移而改变,称为计划抽样(scheduled sampling),训练过程中force learning的概率会渐渐变小。一开始老师带着学,后面慢慢放手让学生自主学。
5. Machine Translation
最后我们拿机器翻译为例子,在此总结一下seq2seq模型。如下图所示,训练的时候采用的是Teacher forcing。测试的时候使用的是上一时刻预测出来的token。

简单的seq2seq框架(不含有Attention)的机器翻译示意图如下图示:

Seq2seq+Attention的机器翻译框架如下图所示:

整个前向传播的流程如下所示:

参考资料
1. 注意力用的是过滤器,而非探照灯
https://neu-reality.com/2019/10/how-brain-pays-attention/
2. What is Teacher Forcing for Recurrent Neural Networks?
https://machinelearningmastery.com/teacher-forcing-for-recurrent-neural-networks/

