
热门标签
热门文章
- 1html登录页面_登录页html
- 2Ubuntu网络代理设置
- 3opencv 水果识别+UI界面识别系统,可训练自定义的水果数据集_水果识别数据集
- 4机载电脑发布自定义MAVROS消息教程_mavros 增加 msg
- 5vue3富文本编辑器WangEditor_vue3 wangeditor
- 6AFNetworking详细说明_afnetworking 隐私
- 7Stable Diffusion整合包 安装教程!轻松解压,即刻体验!_stable diffusion 整合包
- 8【kafka思考】最小成本的扩缩容副本设计方案,Java开发快速学习_kafka缩容
- 9Spring中使用ElasticSearch实现中文分词全文搜索_spirng使用es进行分词搜索
- 10bug 定位tag
当前位置: article > 正文
基于协同注意力的视觉-语言嵌入用于机器人手术视觉问题定位回答
作者:小丑西瓜9 | 2024-06-09 09:48:04
赞
踩
基于协同注意力的视觉-语言嵌入用于机器人手术视觉问题定位回答
CAT-ViL: Co-attention Gated Vision-Language Embedding for Visual Question Localized-Answering in Robotic Surgery
摘要
- 医学生和初级外科医生经常依赖于资深外科医生和专家来回答他们在学习手术过程中的问题,但专家通常忙于临床和学术工作,很难提供指导。
- 现有基于深度学习的外科视觉问题回答(VQA)系统只能提供简单的答案,而无法给出答案的位置信息。同时,视觉-语言(ViL)嵌入在这类任务中也鲜有研究。
- 因此,一个能够提供视觉问题定位回答(VQLA)的系统对于医学生和初级外科医生学习和理解手术视频会很有帮助。
论文提出了一种基于端到端Transformer的CAT-ViL (Co-Attention gaTed Vision-Language)嵌入模型用于外科VQLA任务,不需要通过检测模型进行特征提取。
代码地址
方法

实验结果
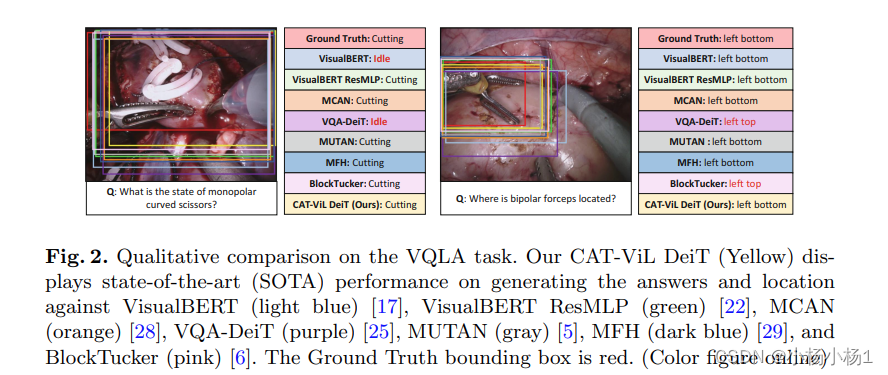
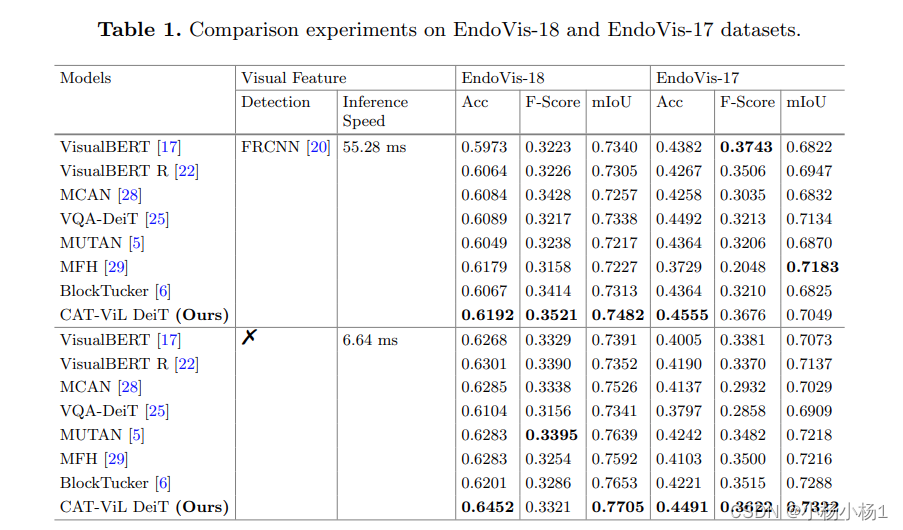
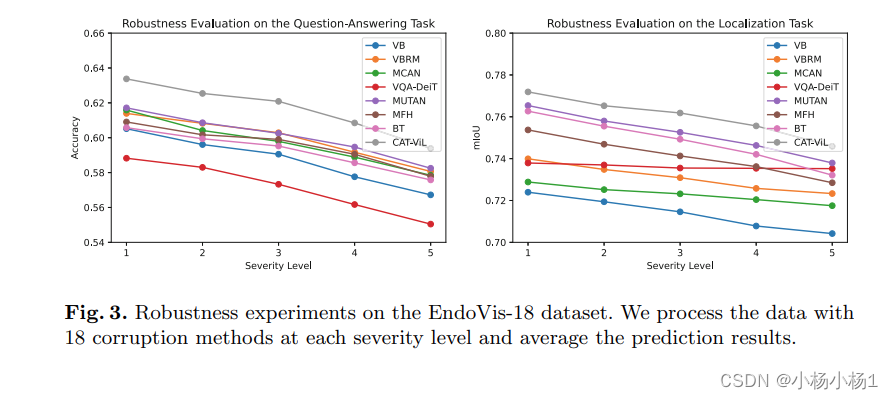
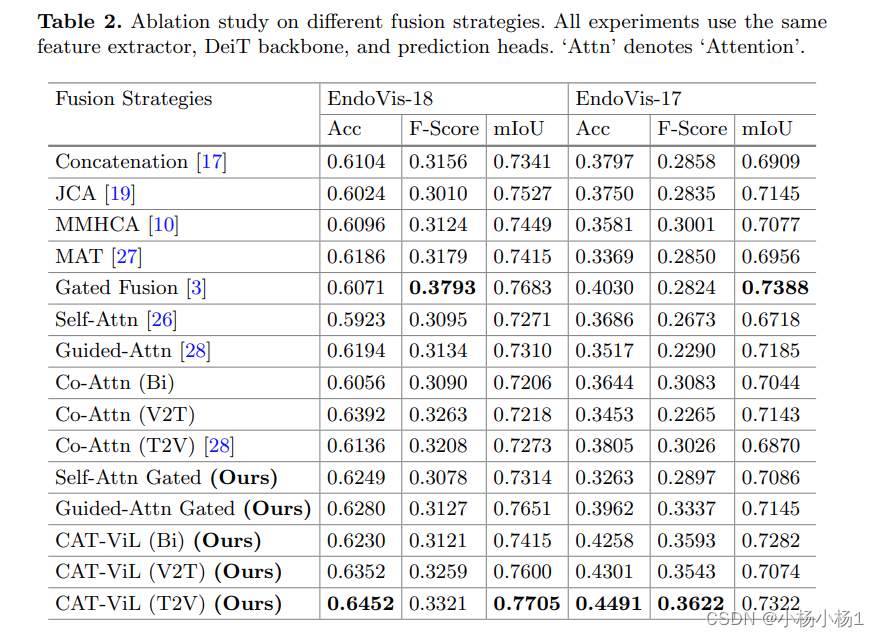
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

