
- 1SSLException异常解读与解决
- 2基于脉冲神经网络的物体检测
- 3git常用命令使用
- 4以“1+3”范式打造线网级多专业智能运维体系,全面提升城市轨交运营质量与效率
- 5Kafka Streams介绍及在idea中的配置
- 6通过域控服务器修改域成员计算机本地管理员账户密码
- 7spacy.load报错_spacy.load("zh")
- 8Android-黑科技保活实现原理揭秘,字节跳动社招面试流程
- 9网易java程序员面试_网易Java程序员两轮面试,这些问题你能答上几个?
- 10Hugging Face Transformers 学习1_can't load the configuration of 'distilbert-base-u
依存句法分析总结
赞
踩
1. 基本概念
依存句法分析(Dependency Parsing,DP)通过分析语言单位内成分之间的依存关系,揭示其句法结构。直观来讲,就是分析句子中的“主谓宾”、“定状补”这些语法成分,并分析各成分的关系。对句法结构进行分析,一方面是语言理解的自身需求,句法分析是语言理解的基础,另外一方面,句法分析也为其他自然语言处理任务提供支持。比如:句法驱动的统计机器翻译需要对源语言或目标语言进行句法分析。
1.1 谓词
依存句法认为“谓词”中的动词是一个句子的核心,其他成分与动词直接或者间接的产生联系。
1.2 依存理论
依存理论中,“依存”指的是词与词之间处于支配与被支配的关系,这种关系具有方向性。处于支配地位的词称之为支配者(head),处于被支配地位的成分称之为从属者(dependency)。
依存语法存在一个基本假设,句法分析核心是词与词的依存关系,一个依存关系连接两个词:head和dependency。依存关系可以细分为不同类型,表示具体的两个词的依存关系。
1.3 依存关系
| 关系类型 | Tag | Description | Example |
|---|---|---|---|
| 主谓关系 | SBV | subject-verb | 我送她一束花 (我 <– 送) |
| 动宾关系 | VOB | 直接宾语,verb-object | 我送她一束花 (送 –> 花) |
| 间宾关系 | IOB | 间接宾语,indirect-object | 我送她一束花 (送 –> 她) |
| 前置宾语 | FOB | 前置宾语,fronting-object | 他什么书都读 (书 <– 读) |
| 兼语 | DBL | double | 他请我吃饭 (请 –> 我) |
| 定中关系 | ATT | attribute | 红苹果 (红 <– 苹果) |
| 状中结构 | ADV | adverbial | 非常美丽 (非常 <– 美丽) |
| 动补结构 | CMP | complement | 做完了作业 (做 –> 完) |
| 并列关系 | COO | coordinate | 大山和大海 (大山 –> 大海) |
| 介宾关系 | POB | preposition-object | 在贸易区内 (在 –> 内) |
| 左附加关系 | LAD | left adjunct | 大山和大海 (和 <– 大海) |
| 右附加关系 | RAD | right adjunct | 孩子们 (孩子 –> 们) |
| 独立结构 | IS | independent structure | 两个单句在结构上彼此独立 |
| 核心关系 | HED | head | 指整个句子的核心 |
2. 基本方法
-
基于转移的方法
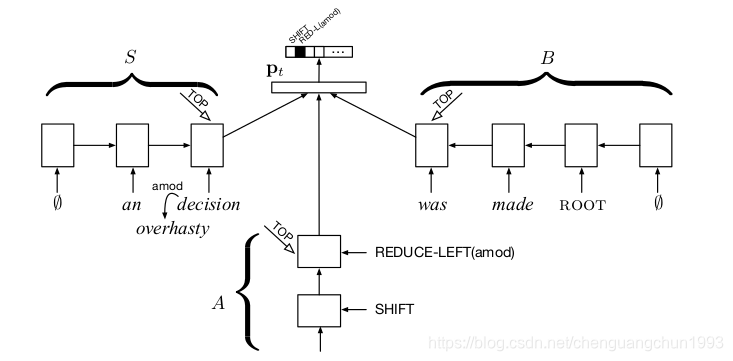
基于转移的方法通过shift-reduce两个基本动作,将序列转为树结构。首先用一个 buffer 来存储所有未处理的输入句子,并用一个栈来存储当前的分析状态。动作可以分为:
- shift,即将 buffer 中的一个词移到栈中;
- l e f t _ a r c ( x ) left\_arc(x) left_arc(x),即栈顶两个词 a,b 为 a<-b 的依赖关系,关系种类为 x;
- r i g h t _ a r c ( x ) right\_arc(x) right_arc(x),即栈顶两个词 a,b 为 a->b 的依赖关系,关系种类为 x。后两种动作为 reduce 动作。
目前,基于转移的方法最好模型是stack lstm。 通过三个 LSTM 来分别建模栈状态、待输入序列和动作序列。 其中因为栈需要入栈和出栈,因此作者提出了一个 Stack LSTM 来建模栈状态。
论文地址: https://arxiv.org/pdf/1505.08075.pdf
-
基于图的方法
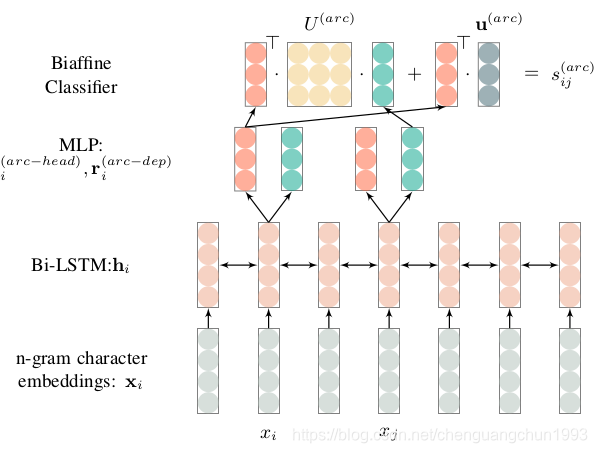
目前的依存句法分析中,最流行的方法是基于图的方法经典的方法是 Biaffine 模型。直接用神经网络来预测每两个词之间存在依存关系的概率,这样我们就得到一个全连接图,图上每个边代表了节点 a 指向节点 b 的概率。然后使用MST等方法来来将图转换为一棵树。
Biaffine 模型其实和我们目前全连接自注意力模型非常类似。Biaffine 模型十分简单,并且容易理解,并且在很多数据集上都取得了目前最好的结果。

论文地址:https://arxiv.org/pdf/1611.01734.pdf
-
联合模型(深度学习)
-
词性标注&句法分析
联合词性标注和句法分析的模型有很多,可以是基于转移的方法,也可以是基于图的方法,这里介绍一个简单思路。首先利用lstm来预测词性,然后联合词性信息和词信息一起用另外一个lstm来建模,并用Biaffine模型来做句法分析。
-
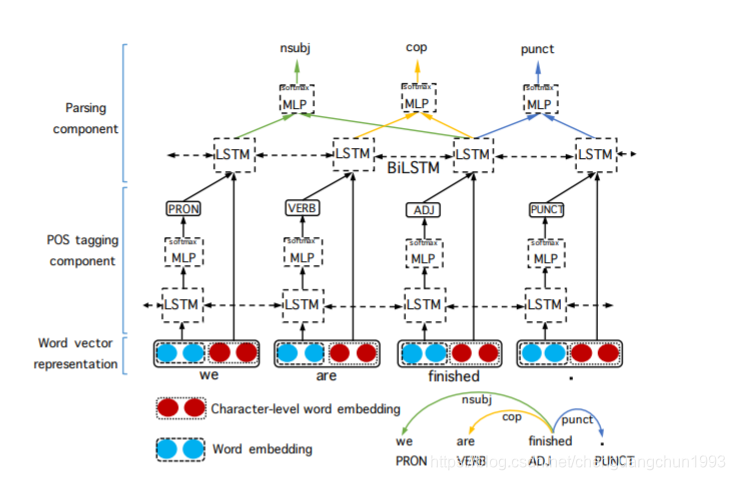
论文地址: https://arxiv.org/pdf/1807.03955.pdf
-
中文分词&句法分析
中文的句法分析是基于词级别的,所以在句法分析之前,会做分词。为了避免流水线模式的错误积累,很容易想到的就是分词和词法分析联合建模。
这里主要介绍一下邱希鹏教授实验室提出的模型:joint CWS。
其中两个关键点:
- biaffine parsing
- ‘app’ 作为特殊的依赖关系
其实方法很简单,只需要将词内部的字之间加上一个特殊的依赖关系“app”,然后将词级别的依存关系转换为字级别的依存关系。并且用 biaffine 模型来进行同时预测。
论文地址:https://arxiv.org/pdf/1904.04697.pdf
3. 常用工具
https://www.jianshu.com/p/867bd48cd9ad
3.1 LTP
-
安装
pip install pyltp- 1
-
下载数据包
ltp_data_v3.4.0: 链接: https://pan.baidu.com/s/1aDrb95ylZHoTPKJY6K1Slw 密码: ehe2
-
测试代码
from pyltp import Parser, Postagger, Segmentor text = 'HanLP是一系列模型与算法组成的自然语言处理工具包,目标是普及自然语言处理在生产环境中的应用。' # 分词 segmentor = Segmentor() segmentor.load("/home/sunshine/datasets/other/ltp_data_v3.4.0/cws.model") tokens = segmentor.segment(text) # 词性 postagger = Postagger() postagger.load('/home/sunshine/datasets/other/ltp_data_v3.4.0/pos.model') postags = postagger.postag(tokens) # 依存句法分析 parser = Parser() parser.load('/home/sunshine/datasets/other/ltp_data_v3.4.0/parser.model') arcs = parser.parse(tokens, postags) i = 1 result = zip(tokens, postags, arcs) for item in result: print(i, item[0], item[1], item[2].head, item[2].relation) i += 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
1 HanLP ws 2 SBV 2 是 v 0 HED 3 一 m 4 ATT 4 系列 q 5 ATT 5 模型 n 8 SBV 6 与 c 7 LAD 7 算法 n 5 COO 8 组成 v 12 ATT 9 的 u 8 RAD 10 自然 n 11 ATT 11 语言 n 12 SBV 12 处理 v 2 VOB 13 工具包 n 12 VOB 14 , wp 2 WP 15 目标 n 16 SBV 16 是 v 2 COO 17 普及 v 16 VOB 18 自然 n 19 ATT 19 语言 n 20 ATT 20 处理 v 17 VOB 21 在 p 26 ATT 22 生产 v 23 ATT 23 环境 n 24 ATT 24 中 nd 21 POB 25 的 u 21 RAD 26 应用 v 20 VOB 27 。 wp 2 WP- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
3.2 stanfordNLP
3.2.1 StanordCoreNLP
Github地址:https://github.com/Lynten/stanford-corenlp
官网:https://stanfordnlp.github.io/CoreNLP/
-
安装
pip install stanfordcorenlp- 1
-
安装java环境(略)
-
下载数据包
链接: https://pan.baidu.com/s/1kD3gaxVwvxZGaEN3EDedvA 提取码: m72n
数据包下载之后,解压stanford-corenlp-full-2018-02-27.zip,将stanford-chinese-corenlp-2018-02-27-models.jar拷贝至stanford-corenlp-full-2018-02-27.zip解压目录。
-
测试代码
from stanfordcorenlp import StanfordCoreNLP text = 'HanLP是一系列模型与算法组成的自然语言处理工具包,目标是普及自然语言处理在生产环境中的应用。' nlp = StanfordCoreNLP("/home/sunshine/datasets/other/standfordCoreNLP/stanford-corenlp-full-2018-02-27", lang='zh') tokens = nlp.word_tokenize(text) postags = nlp.pos_tag(text) result = nlp.dependency_parse(text) i = 1 for item in zip(tokens, postags, result): print(i, item[0], item[1][1], item[2][1], item[2][2]) i += 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
1 HanLP NR 0 12 2 是 VC 12 1 3 一 CD 12 2 4 系列 M 11 3 5 模型 NN 3 4 6 与 CC 7 5 7 算法 NN 7 6 8 组成 VV 8 7 9 的 DEC 11 8 10 自然 NN 8 9 11 语言 NN 11 10 12 处理 VV 12 11 13 工具包 NN 12 13 14 , PU 12 14 15 目标 NN 17 15 16 是 VC 17 16 17 普及 VV 12 17 18 自然 NN 19 18 19 语言 NN 17 19 20 处理 VV 17 20 21 在 P 23 21 22 生产 NN 23 22 23 环境 NN 26 23 24 中 LC 23 24 25 的 DEG 23 25 26 应用 NN 20 26 27 。 PU 12 27- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
-
依存句法解释
> > ROOT:要处理文本的语句 > > IP:简单从句 > > NP:名词短语 > > VP:动词短语 > > PU:断句符,通常是句号、问号、感叹号等标点符号 > > LCP:方位词短语 > > PP:介词短语 > > CP:由‘的’构成的表示修饰性关系的短语 > > DNP:由‘的’构成的表示所属关系的短语 > > ADVP:副词短语 > > ADJP:形容词短语 > > DP:限定词短语 > > QP:量词短语 > > NN:常用名词 > > NR:固有名词 > > NT:时间名词 > > PN:代词 > > VV:动词 > > VC:是 > > CC:表示连词 > > VE:有 > > VA:表语形容词 > > AS:内容标记(如:了) > > VRD:动补复合词 > > CD: 表示基数词 > > DT: determiner 表示限定词 > > EX: existential there 存在句 > > FW: foreign word 外来词 > > IN: preposition or conjunction, subordinating 介词或从属连词 > > JJ: adjective or numeral, ordinal 形容词或序数词 > > JJR: adjective, comparative 形容词比较级 > > JJS: adjective, superlative 形容词最高级 > > LS: list item marker 列表标识 > > MD: modal auxiliary 情态助动词 > > PDT: pre-determiner 前位限定词 > > POS: genitive marker 所有格标记 > > PRP: pronoun, personal 人称代词 > > RB: adverb 副词 > > RBR: adverb, comparative 副词比较级 > > RBS: adverb, superlative 副词最高级 > > RP: particle 小品词 > > SYM: symbol 符号 > > TO:”to” as preposition or infinitive marker 作为介词或不定式标记 > > WDT: WH-determiner WH限定词 > > WP: WH-pronoun WH代词 > > WP$: WH-pronoun, possessive WH所有格代词 > > WRB:Wh-adverb WH副词 > > > > 关系表示 > > abbrev: abbreviation modifier,缩写 > > acomp: adjectival complement,形容词的补充; > > advcl : adverbial clause modifier,状语从句修饰词 > > advmod: adverbial modifier状语 > > agent: agent,代理,一般有by的时候会出现这个 > > amod: adjectival modifier形容词 > > appos: appositional modifier,同位词 > > attr: attributive,属性 > > aux: auxiliary,非主要动词和助词,如BE,HAVE SHOULD/COULD等到 > > auxpass: passive auxiliary 被动词 > > cc: coordination,并列关系,一般取第一个词 > > ccomp: clausal complement从句补充 > > complm: complementizer,引导从句的词好重聚中的主要动词 > > conj : conjunct,连接两个并列的词。 > > cop: copula。系动词(如be,seem,appear等),(命题主词与谓词间的)连系 > > csubj : clausal subject,从主关系 > > csubjpass: clausal passive subject 主从被动关系 > > dep: dependent依赖关系 > > det: determiner决定词,如冠词等 > > dobj : direct object直接宾语 > > expl: expletive,主要是抓取there > > infmod: infinitival modifier,动词不定式 > > iobj : indirect object,非直接宾语,也就是所以的间接宾语; > > mark: marker,主要出现在有“that” or “whether”“because”, “when”, > > mwe: multi-word expression,多个词的表示 > > neg: negation modifier否定词 > > nn: noun compound modifier名词组合形式 > > npadvmod: noun phrase as adverbial modifier名词作状语 > > nsubj : nominal subject,名词主语 > > nsubjpass: passive nominal subject,被动的名词主语 > > num: numeric modifier,数值修饰 > > number: element of compound number,组合数字 > > parataxis: parataxis: parataxis,并列关系 > > partmod: participial modifier动词形式的修饰 > > pcomp: prepositional complement,介词补充 > > pobj : object of a preposition,介词的宾语 > > poss: possession modifier,所有形式,所有格,所属 > > possessive: possessive modifier,这个表示所有者和那个’S的关系 > > preconj : preconjunct,常常是出现在 “either”, “both”, “neither”的情况下 > > predet: predeterminer,前缀决定,常常是表示所有 > > prep: prepositional modifier > > prepc: prepositional clausal modifier > > prt: phrasal verb particle,动词短语 > > punct: punctuation,这个很少见,但是保留下来了,结果当中不会出现这个 > > purpcl : purpose clause modifier,目的从句 > > quantmod: quantifier phrase modifier,数量短语 > > rcmod: relative clause modifier相关关系 > > ref : referent,指示物,指代 > > rel : relative > > root: root,最重要的词,从它开始,根节点 > > tmod: temporal modifier > > xcomp: open clausal complement > > xsubj : controlling subject 掌控者 > > 中心语为谓词 > > subj — 主语 > > nsubj — 名词性主语(nominal subject) (同步,建设) > > top — 主题(topic) (是,建筑) > > npsubj — 被动型主语(nominal passive subject),专指由“被”引导的被动句中的主语,一般是谓词语义上的受事 (称作,镍) > > csubj — 从句主语(clausal subject),中文不存在 > > xsubj — x主语,一般是一个主语下面含多个从句 (完善,有些) > > 中心语为谓词或介词 > > obj — 宾语 > > dobj — 直接宾语 (颁布,文件) > > iobj — 间接宾语(indirect object),基本不存在 > > range — 间接宾语为数量词,又称为与格 (成交,元) > > pobj — 介词宾语 (根据,要求) > > lobj — 时间介词 (来,近年) > > 中心语为谓词 > > comp — 补语 > > ccomp — 从句补语,一般由两个动词构成,中心语引导后一个动词所在的从句(IP) (出现,纳入) > > xcomp — x从句补语(xclausal complement),不存在 > > acomp — 形容词补语(adjectival complement) > > tcomp — 时间补语(temporal complement) (遇到,以前) > > lccomp — 位置补语(localizer complement) (占,以上) > > — 结果补语(resultative complement) > > 中心语为名词 > > mod — 修饰语(modifier) > > pass — 被动修饰(passive) > > tmod — 时间修饰(temporal modifier) > > rcmod — 关系从句修饰(relative clause modifier) (问题,遇到) > > numod — 数量修饰(numeric modifier) (规定,若干) > > ornmod — 序数修饰(numeric modifier) > > clf — 类别修饰(classifier modifier) (文件,件) > > nmod — 复合名词修饰(noun compound modifier) (浦东,上海) > > amod — 形容词修饰(adjetive modifier) (情况,新) > > advmod — 副词修饰(adverbial modifier) (做到,基本) > > vmod — 动词修饰(verb modifier,participle modifier) > > prnmod — 插入词修饰(parenthetical modifier) > > neg — 不定修饰(negative modifier) (遇到,不) > > det — 限定词修饰(determiner modifier) (活动,这些) > > possm — 所属标记(possessive marker),NP > > poss — 所属修饰(possessive modifier),NP > > dvpm — DVP标记(dvp marker),DVP (简单,的) > > dvpmod — DVP修饰(dvp modifier),DVP (采取,简单) > > assm — 关联标记(associative marker),DNP (开发,的) > > assmod — 关联修饰(associative modifier),NP|QP (教训,特区) > > prep — 介词修饰(prepositional modifier) NP|VP|IP(采取,对) > > clmod — 从句修饰(clause modifier) (因为,开始) > > plmod — 介词性地点修饰(prepositional localizer modifier) (在,上) > > asp — 时态标词(aspect marker) (做到,了) > > partmod– 分词修饰(participial modifier) 不存在 > > etc — 等关系(etc) (办法,等) > > 中心语为实词 > > conj — 联合(conjunct) > > cop — 系动(copula) 双指助动词???? > > cc — 连接(coordination),指中心词与连词 (开发,与) > > 其它 > > attr — 属性关系 (是,工程) > > cordmod– 并列联合动词(coordinated verb compound) (颁布,实行) > > mmod — 情态动词(modal verb) (得到,能) > > ba — 把字关系 > > tclaus — 时间从句 (以后,积累) > > — semantic dependent > > cpm — 补语化成分(complementizer),一般指“的”引导的CP (振兴,的) > > ``` > ```- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
3.2.2 stanza
github: https://github.com/stanfordnlp/stanza
stanza同样是stanford发布的版本。
-
安装
pip install stanza- 1
-
下载模型
import stanza stanza.download('zh')- 1
- 2
我这里提供一份中文的模型包供大家下载。
链接: https://pan.baidu.com/s/1hb9ATqpOGC9sHBHZ2hNdeg 提取码: fqdm
-
测试代码
import stanza nlp = stanza.Pipeline('zh') # This sets up a default neural pipeline in English doc = nlp("HanLP是一系列模型与算法组成的自然语言处理工具包,目标是普及自然语言处理在生产环境中的应用。") doc.sentences[0].print_dependencies()- 1
- 2
- 3
- 4
('HanLP', '14', 'nsubj') ('是', '14', 'cop') ('一', '4', 'nummod') ('系列', '5', 'clf') ('模型', '8', 'nsubj') ('与', '7', 'cc') ('算法', '5', 'conj') ('组成', '14', 'acl:relcl') ('的', '8', 'mark:relcl') ('自然', '12', 'nmod') ('语言', '12', 'compound') ('处', '13', 'nmod') ('理工', '14', 'nsubj') ('具包', '0', 'root') (',', '14', 'punct') ('目标', '17', 'nsubj') ('是', '14', 'parataxis') ('普及', '17', 'xcomp') ('自然', '20', 'nmod') ('语言', '21', 'nsubj') ('处理', '18', 'ccomp') ('在', '27', 'det') ('生产', '24', 'nmod') ('环境', '22', 'nmod') ('中', '24', 'acl') ('的', '22', 'case:dec') ('应用', '18', 'obj') ('。', '14', 'punct')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
3.3 HaNLP
官网:http://hanlp.linrunsoft.com/
在线演示:http://hanlp.com/
3.3.1 pyhanlp(hanlp1.x)
Github地址:https://github.com/hankcs/pyhanlp
-
安装
pip install pyhanlp- 1
-
下载数据包
data:链接: https://pan.baidu.com/s/169Fgb6vhfsx10O2xEomY1Q 提取码: r4zv
将下载的数据包解压至%python_lib%/site-packages/pyhanlp/static文件夹。我这里提供的是1.7.5版本,同样支持1.7.7版本的pyhanlp。
默认会自动下载相关的jar包。
-
测试代码
from pyhanlp import HanLP print(HanLP.parseDependency("HanLP是一系列模型与算法组成的自然语言处理工具包,目标是普及自然语言处理在生产环境中的应用"))- 1
- 2
1 HanLP HanLP ws nx _ 2 主谓关系 _ _ 2 是 是 v v _ 0 核心关系 _ _ 3 一系列 一系列 n n _ 4 定中关系 _ _ 4 模型 模型 n n _ 7 主谓关系 _ _ 5 与 与 p p _ 7 状中结构 _ _ 6 算法 算法 n n _ 5 介宾关系 _ _ 7 组成 组成 v v _ 10 定中关系 _ _ 8 的 的 u u _ 7 右附加关系 _ _ 9 自然语言处理 自然语言处理 nz nz _ 10 定中关系 _ _ 10 工具包 工具包 n n _ 2 动宾关系 _ _ 11 , , wp w _ 2 标点符号 _ _ 12 目标 目标 n n _ 13 主谓关系 _ _ 13 是 是 v v _ 2 并列关系 _ _ 14 普及 普及 v v _ 13 动宾关系 _ _ 15 自然语言处理 自然语言处理 nz nz _ 19 主谓关系 _ _ 16 在 在 p p _ 19 状中结构 _ _ 17 生产环境 生产环境 n n _ 16 介宾关系 _ _ 18 中的 中的 v v _ 19 状中结构 _ _ 19 应用 应用 v vn _ 14 动宾关系 _ _- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
3.3.2 hanlp2.0
-
安装
pip install hanlp- 1
hanlp2.0是基于tensorflow2.1训练的网络模型,线上提供了很多训练好的预训练模型,问题在于基本上不可能自动下载成功,需要手动下载模型并存放到相应的位置。
-
查看已经提供的模型
import hanlp for k,v in hanlp.pretrained.ALL.items(): print(k, v)- 1
- 2
- 3
-
测试代码
tokenizer = hanlp.load('CTB6_CONVSEG') tagger = hanlp.load('CTB5_POS_RNN') syntactic_parser = hanlp.load('CTB7_BIAFFINE_DEP_ZH') pipeline = hanlp.pipeline() \ .append(hanlp.utils.rules.split_sentence, output_key='sentences') \ .append(tokenizer, output_key='tokens') \ .append(tagger, output_key='part_of_speech_tags') \ .append(syntactic_parser, input_key=('tokens', 'part_of_speech_tags'), output_key='syntactic_dependencies', conll=False) text = 'HanLP是一系列模型与算法组成的自然语言处理工具包,目标是普及自然语言处理在生产环境中的应用' doc = pipeline(text) tokens = doc.tokens[0] pos = doc.part_of_speech_tags[0] dependencies = doc.syntactic_dependencies[0] for i in range(len(tokens)): print(i, tokens[i], pos[i], dependencies[i][0], dependencies[i][1])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
0 HanLP NN 2 top 1 是 VC 0 root 2 一系列 NN 6 nn 3 模型 NN 6 conj 4 与 CC 6 cc 5 算法 NN 7 nsubj 6 组成 VV 10 rcmod 7 的 DEC 7 cpm 8 自然 NN 10 nn 9 语言 NN 11 nsubj 10 处理 VV 2 ccomp 11 工具包 PU 11 punct 12 , PU 2 punct 13 目标 NN 15 top 14 是 VC 2 conj 15 普及 VV 15 ccomp 16 自然 NN 18 nn 17 语言 NN 16 dobj 18 处理 VV 16 conj 19 在 P 25 assmod 20 生产 NN 22 nn 21 环境 NN 23 lobj 22 中 LC 20 plmod 23 的 DEG 20 assm 24 应用 NN 19 dobj- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
4. 数据集
-
Penn Treebank
Penn Treebank是一个项目的名称,项目目的是对语料进行标注,标注内容包括词性标注以及句法分析。
-
SemEval-2016 Task 9
中文语义依存图数据:http://ir.hit.edu.cn/2461.html
下载地址:https://github.com/HIT-SCIR/SemEval-2016
-
evsam05
链接: https://pan.baidu.com/s/1cFQBNcd-HnuTPUlGT7h9wg 提取码: tjdx
-
CoNLL任务
- http://universaldependencies.org/conll18/
- http://ufal.mff.cuni.cz/conll2009-st/
- https://www.clips.uantwerpen.be/conll2008/
- https://www.clips.uantwerpen.be/conll2007/
5. 可视化工具
-
conllu.js
-
DependencyViewer.exe
参考:

