
- 1基于区块链的不动产登记电子证照应用服务系统设计方案---3.总体设计_基于区块链的可信电子证照方案设计
- 2Qt Design Studio使用场景
- 3Qt Quick QML 与 C++ 交互系列之二
- 4自然语言处理在智能客服中的实践与优化
- 5元学习Meta-Learning_元学习的情景训练
- 6一切皆是映射:AI的去中心化:区块链技术的融合
- 7macOS系统安装pycharm社区版本_pycharm社区版本下载mac
- 8火车票预售系统(JavaGUI)_网上购票系统java+gui界面
- 9快速查询的秘籍 —— B+索引的建立_索引 b+ 页中查询
- 10骨架算法(skeleton)的实现_skeleton3d函数图示
幻方发布全球最强开源MoE模型DeepSeek-V2:超低成本,性能媲美GPT4_幻方研发的模型
赞
踩
前言
继今年1月份开源国内首个MoE模型后,幻方人工智能公司最新推出了第二代MoE模型——DeepSeek-V2。这款新模型不仅参数更多、性能更强,训练成本更低的特点,令其在业界引起广泛关注。
DeepSeek-V2采用了创新的模型架构和训练方法,在多项综合评测中均表现出色,有些指标甚至媲美或超越目前最强的GPT-4模型。同时,它的推理效率和部署成本也大幅优于同类大模型,可谓是性能与成本的完美结合。
-
Huggingface模型下载:https://huggingface.co/deepseek-ai/DeepSeek-V2-Chat
-
AI快站模型免费加速下载:https://aifasthub.com/models/deepseek-ai
技术特点
DeepSeek-V2的核心技术亮点包括:
创新的模型架构
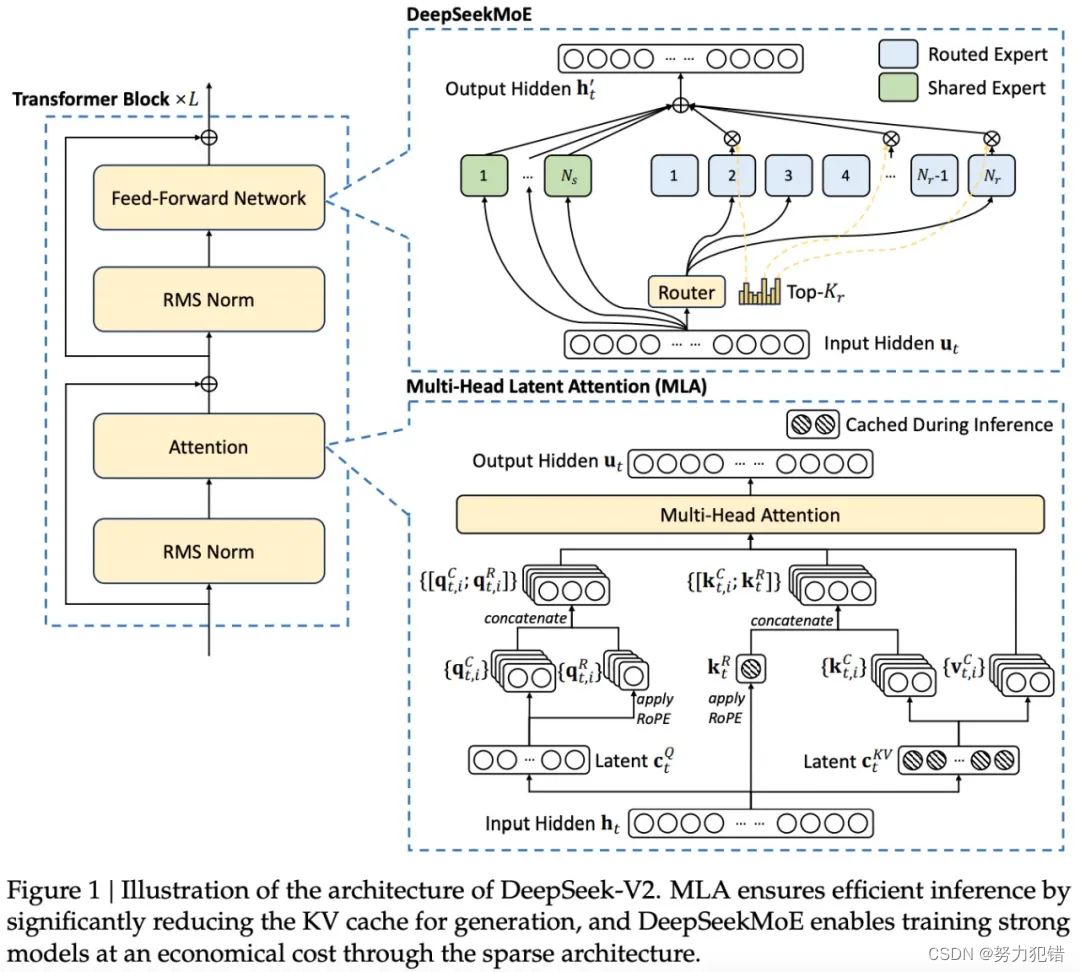
DeepSeek-V2没有沿用主流的"Dense结构"或"Sparse结构",而是提出了全新的MLA(Multi-head Latent Attention)注意力机制和DeepSeekMoE前馈网络。这些创新的架构设计大幅降低了计算量和显存占用,确保了高效推理。
高效的训练方法
DeepSeek-V2采用了多项训练优化技术,包括:
-
使用高质量、多样化的8.1万亿token预训练语料
-
针对不同任务(如数学、编程、对话等)进行监督微调和强化学习
-
利用HAI-LLM框架进行高效并行训练,充分利用GPU算力
这些方法确保了DeepSeek-V2在训练成本上大幅优于同类模型。
优异的推理性能
DeepSeek-V2支持128K的超长上下文,且在GPU上的推理吞吐量高达每秒10万tokens输入、5万tokens输出。这要归功于其创新的架构设计以及针对推理优化的内核实现。
性能表现
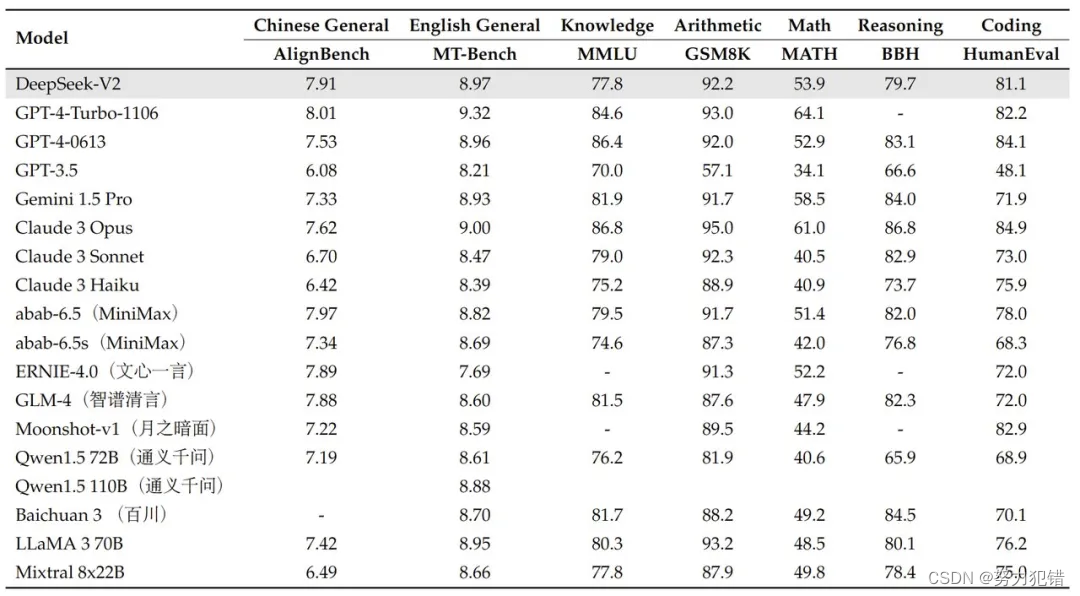
DeepSeek-V2在各类基准测试中均取得了出色的成绩:
-
综合能力
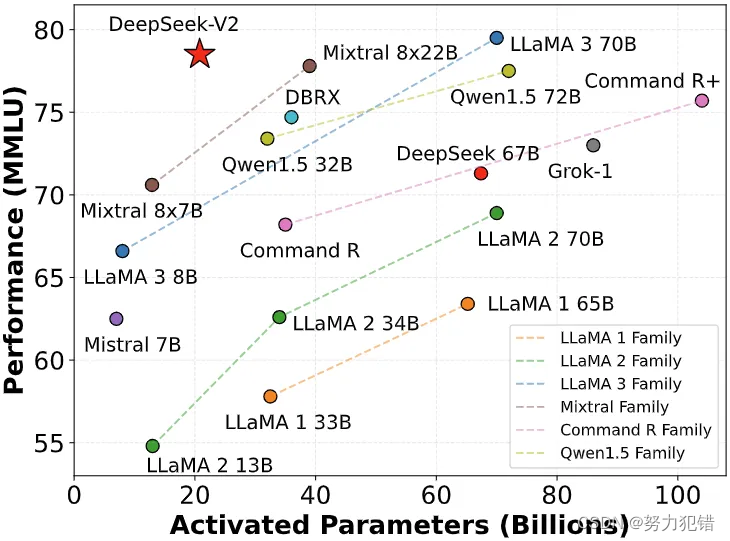
在中文综合能力评测AlignBench中,DeepSeek-V2超越了所有开源模型,与GPT-4-Turbo等行业巨头处于同等水平。在英文综合评测MT-Bench中,它也与最强的LLaMA3-70B同处第一梯队,超越了Mixtral 8x22B等其他MoE模型。
-
专项能力
DeepSeek-V2在数学、编程、知识等多个领域的专项基准测试中表现突出,均位列前列。在LiveCodeBench实时编程挑战基准上,它的成绩更是超越多数其他模型。
-
成本优势
即便在如此出色的性能下,DeepSeek-V2的训练成本和部署成本却大幅低于同类大模型。其API定价仅为GPT-4-Turbo的近百分之一,每百万tokens仅需1元人民币,可谓性价比极高。

应用前景
得益于卓越的综合性能、专项能力和极低的使用成本,DeepSeek-V2必将在各类AI应用中发挥重要作用:
-
智能对话: DeepSeek-V2的对话生成能力强劲,可应用于虚拟助手、客服机器人等场景。
-
内容创作: 模型出色的写作、数学和编程能力,可助力报告、文章、代码等内容的生成。
-
教育辅助: 在数学、编程等领域的强大功能,可为学生提供智能辅导和练习。
-
专业服务: DeepSeek-V2在知识推理、问题求解等方面的能力,可为各行各业的专业人士提供帮助。
总结
幻方开源的DeepSeek-V2模型,凭借全新的架构设计和先进的训练方法,在综合性能、专项能力和成本效率等方面均达到了行业领先水平。与目前最强的GPT-4相媲美,却只需极低的使用成本,这无疑为各类AI应用注入了强大动力。未来DeepSeek-V2必将在智能对话、内容创作、教育辅助等领域大显身手,为人工智能发展添砖加瓦。
模型下载
Huggingface模型下载
https://huggingface.co/deepseek-ai/DeepSeek-V2-Chat
AI快站模型免费加速下载
https://aifasthub.com/models/deepseek-ai

