
- 1人工智能中的文本分类:技术突破与实战指导_根据帖子,提取用户特征,为ai训练数据提供分类规则
- 2C语言实现面向对象编程 | 干货_c语言对象编程
- 3Android教程2.1:Activity的详细讲解_android:value="2.1
- 4nginx负载均衡(轮询、权重、负载均衡)_nginx 轮询
- 52023年软件测试就业现状分析,到底是卷还是润?_2023年软件测试就业趋势
- 6【持续更新】汇总了一份前端领域必看面试题
- 7MobileViT模型简介_mobilevitattention
- 8cocos对接穿山甲广告运行出现两个应用任务_cocos 接入广告 2个后台
- 9每日一题 力扣2861 最大合金数
- 10网络抓包工具--wireshark_抓网口报文的软件
Redis篇之分布式锁
赞
踩
一、为什么要使用分布式锁
1.抢劵场景
(1)代码及流程图

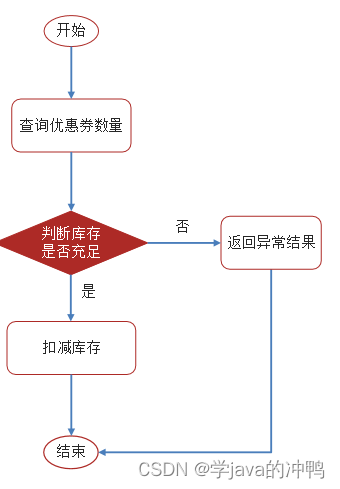
(2)抢劵执行的正常流程
就是正好线程1执行完整个操作,线程2再执行。
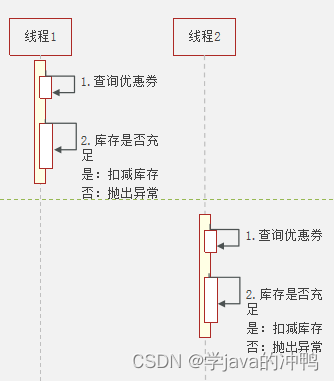
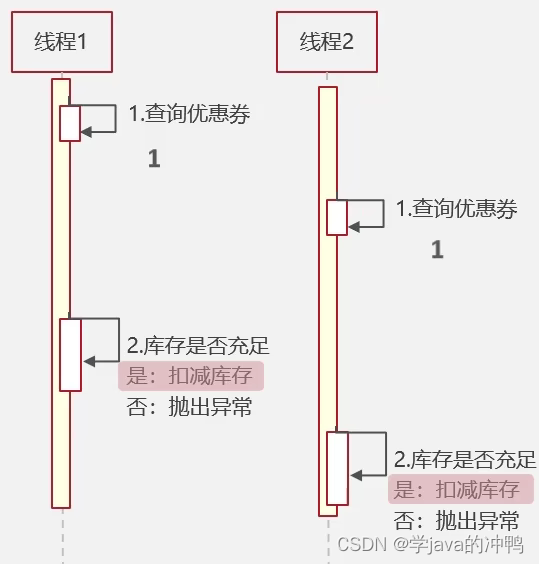
(3)抢劵执行的非正常流程
因为线程是交替进行的,所以有可能线程1查询后,线程2再查询。假如现在只有一张票,所以线程1会买到这张票,并扣除库存,现在也就是没有票了。但是线程2查询的时候,库存是有一张票的,所以也会进行库存扣除,变成-1张了。这样就出现了超卖的问题了。
(4)那怎么解决(3)的问题呢
1. 首先想到的就是普通的加锁,如下图所示:


2. 这样会不会出现问题呢?当然有可能,在实际项目中,服务器大部分都是集群部署的,因为普通加锁只能解决单个服务器的互斥,不能解决多个服务器线程的互斥,所以还是有问题。

3. 那应该怎么解决呢?就是我们提及到的使用分布式锁,这样就可以限制其他服务器也获取锁的问题,只有当一台服务器解锁,其他服务器才能拿到锁。

二、redis分布式锁
1.核心命令
Redis实现分布式锁主要利用Redis的setnx命令。setnx是SET if not exists(如果不存在,则 SET)的简写。
2.如何使用
1. 命令设置,为什么获取锁要把超时时间一起写上去呢?还有为什么一定要设置过期时间呢?第一,不分开写就是要保证数据的原子性。第二,不设置过期时间可能会导致死锁。可以看执行流程图,如果服务器宕机,会导致锁不能释放,造成死锁,所以要加过期时间兜底。

2. 执行流程:
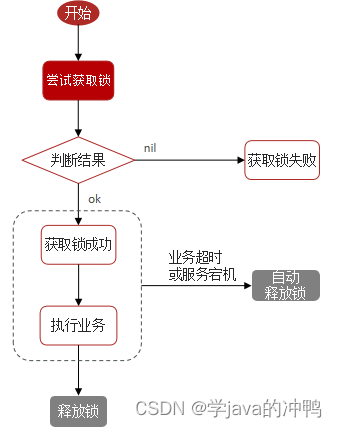
3.如何控制锁的有效时长呢
1.根据业务执行时间预估。这种方法往往不能保证原子性,一般不使用。
2.给锁续期。就是根据执行业务的时长进行锁时长的增加。那自己还需要开一个线程专门来监控,实现起来也比较麻烦,所以会使用redission实现的分布式锁。
三、redission实现的分布式锁
1.redission实现分布式锁的流程
(1)流程图
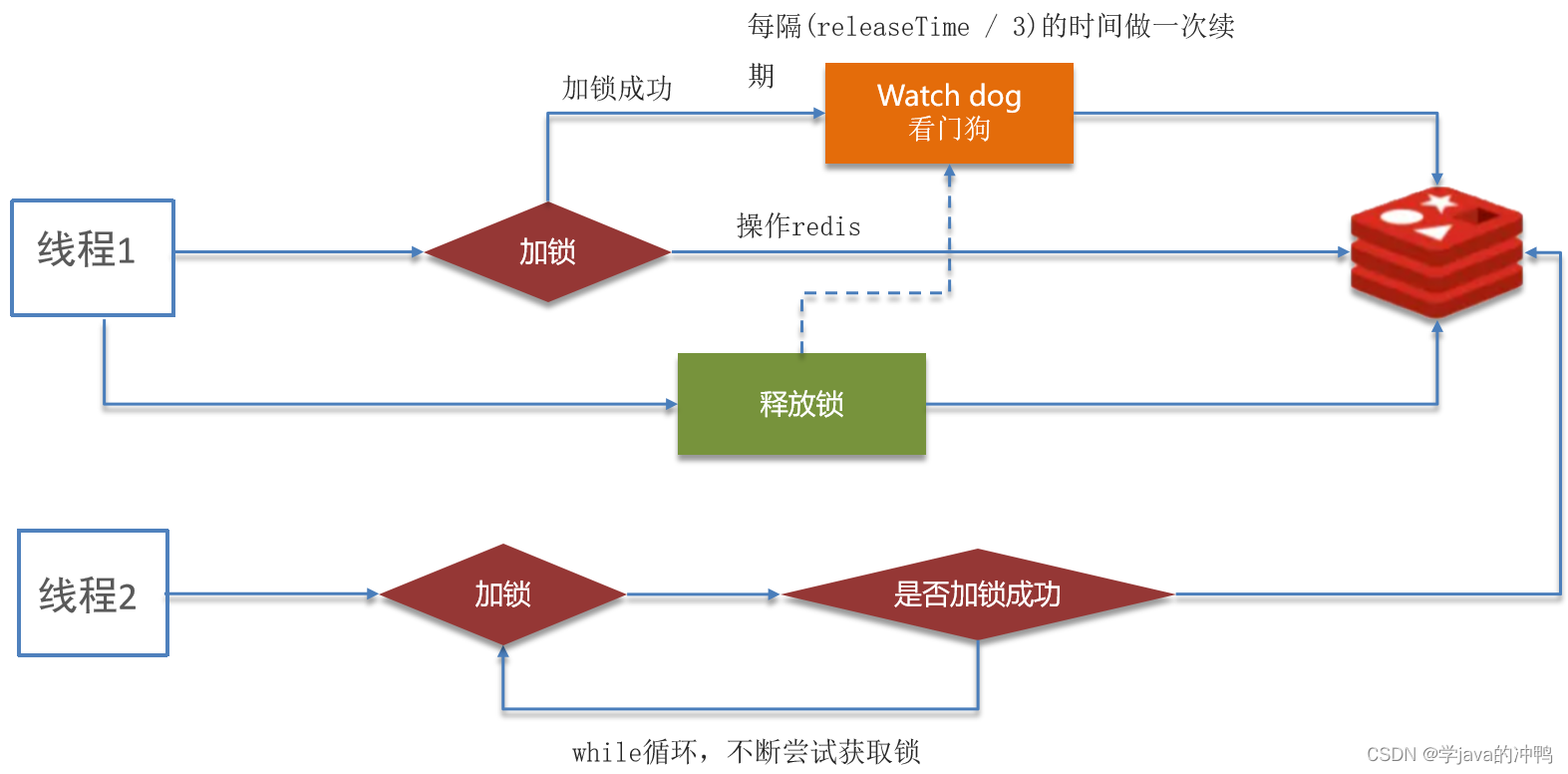
(2)解释流程图的步骤
首先,线程1获取锁成功后,采用 watch-dog来检查和更新锁状态,每隔(过期时间/3)的时间续期一次,然后操作redis,手动释放锁后,会通知watch-dog不用监听锁了。
如果线程2也需要加锁,但是没有获取到锁,则会while循环去尝试获取锁,循环的次数也不是无限的,而是到达一定阈值就停止。也不用担心因为循环而导致获取锁失败,因为在高并发的情况下,业务时长不会太长,所以会在这种情况下可以增加分布式锁的使用性能。这也是分布式锁的一个特性:等待机制。
(3)具体代码
- public void redisLock() throws InterruptedException{
- //获取重入锁,执行锁的名字(自定义)
- RLock lock = redissionClient.getLock("nameLock");
- try {
- //尝试获取锁,参数分别是:锁的最大等待时间,锁自动释放时间,时间单位
- boolean isLock = lock.tryLock(10,30,TimeUnit.SECONDS);
- //判断是否获取锁成功
- if(isLock){
- //业务代码
- }
- }finally {
- //释放锁
- lock.unlock();
- }
- }
关键点:加锁、设置过期时间等操作都是基于lua脚本完成的,目的是保证数据的原子性。
2.redission分布式锁的可重入
(1)例子代码
- public void add1() {
- RLock lock = redissonClient.getLock("nameLock");
- boolean isLock = lock.tryLock();
- //执行业务
- add2();
- // 释放锁
- lock.unlock();
- }
-
- public void add2() {
- RLock lock = redissonClient.getLock("nameLock");
- boolean isLock = lock.tryLock();
- //执行业务
- // 释放锁
- lock.unlock();
- }

(2)如何实现呢
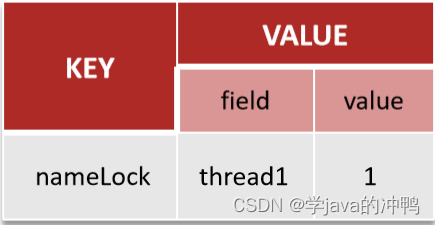
利用hash结构记录线程id和重入次数。其中key就是锁的名字,field就是线程的唯一标识,value就是重入的次数。根据上面代码,add1方法先获取锁后,value的值就是1。然后调用add2方法,add2方法也获取该锁,所以value的值就变成2。然后add2解锁,value就减一变成1。回到add1方法中,释放锁,value再减一,最后value就变成了0。最后当value为0时,就可以删除锁。
关键点:必须是在同一个线程才能重入。
3.redission分布式锁的主从一致性
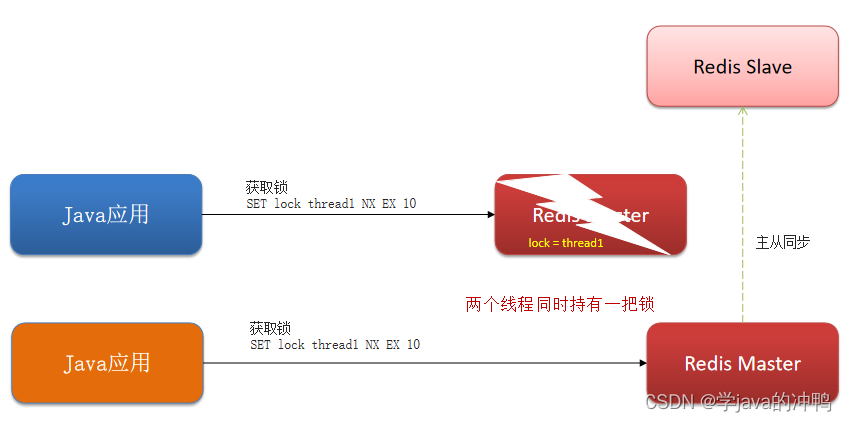
(1)非正常情况
1. 当主节点宕机。

2. 其中一个从节点会代替主节点。

3. 如果这时线程2也来获取锁,因为线程1获取锁后,主节点宕机了,所以线程2会访问新的主节点,获取锁成功。这样会出现,两个线程获取同一把锁,就有问题了。
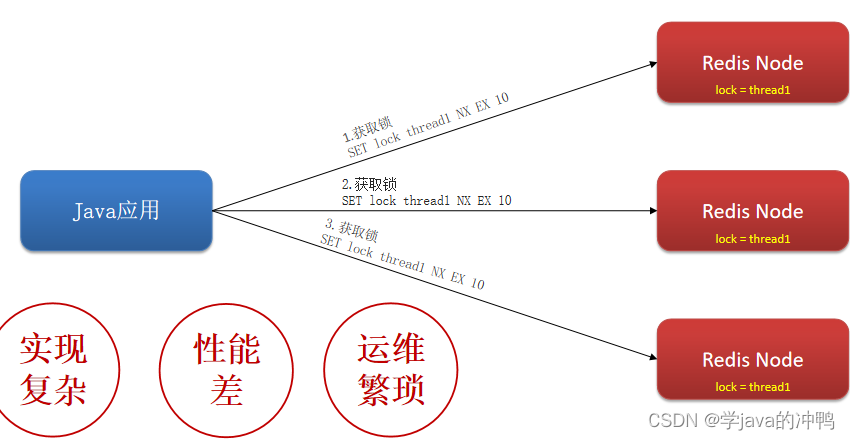
(2)如何解决(1)的问题
RedLock(红锁):不能只在一个redis实例上创建锁,应该是在多个redis实例上创建锁(n / 2 + 1),避免在一个redis实例上加锁。由于缺点太多了。实际中并不会大量使用redission的红锁。
redis:AP思想。
zookeeper:CP思想。
所以,实际中就是 使用zookeeper来解决主从一致性。
四、面试的时候怎么说
面试官:Redis分布式锁如何实现 ?
候选人:嗯,在redis中提供了一个命令setnx(SET if not exists)
由于redis的单线程的,用了命令之后,只能有一个客户端对某一个key设置值,在没有过期或删除key的时候是其他客户端是不能设置这个key的
面试官:好的,那你如何控制Redis实现分布式锁有效时长呢?
候选人:嗯,的确,redis的setnx指令不好控制这个问题,我们当时采用的redis的一个框架redisson实现的。
在redisson中需要手动加锁,并且可以控制锁的失效时间和等待时间,当锁住的一个业务还没有执行完成的时候,在redisson中引入了一个看门狗机制,就是说每隔一段时间就检查当前业务是否还持有锁,如果持有就增加加锁的持有时间,当业务执行完成之后需要使用释放锁就可以了
还有一个好处就是,在高并发下,一个业务有可能会执行很快,先客户1持有锁的时候,客户2来了以后并不会马上拒绝,它会自旋不断尝试获取锁,如果客户1释放之后,客户2就可以马上持有锁,性能也得到了提升。
面试官:好的,redisson实现的分布式锁是可重入的吗?
候选人:嗯,是可以重入的。这样做是为了避免死锁的产生。这个重入其实在内部就是判断是否是当前线程持有的锁,如果是当前线程持有的锁就会计数,如果释放锁就会在计算上减一。在存储数据的时候采用的hash结构,大key可以按照自己的业务进行定制,其中小key是当前线程的唯一标识,value是当前线程重入的次数
面试官:redisson实现的分布式锁能解决主从一致性的问题吗
候选人:这个是不能的,比如,当线程1加锁成功后,master节点数据会异步复制到slave节点,此时当前持有Redis锁的master节点宕机,slave节点被提升为新的master节点,假如现在来了一个线程2,再次加锁,会在新的master节点上加锁成功,这个时候就会出现两个节点同时持有一把锁的问题。
我们可以利用redisson提供的红锁来解决这个问题,它的主要作用是,不能只在一个redis实例上创建锁,应该是在多个redis实例上创建锁,并且要求在大多数redis节点上都成功创建锁,红锁中要求是redis的节点数量要过半。这样就能避免线程1加锁成功后master节点宕机导致线程2成功加锁到新的master节点上的问题了。
但是,如果使用了红锁,因为需要同时在多个节点上都添加锁,性能就变的很低了,并且运维维护成本也非常高,所以,我们一般在项目中也不会直接使用红锁,并且官方也暂时废弃了这个红锁。
面试官:好的,如果业务非要保证数据的强一致性,这个该怎么解决呢?
候选人:嗯~,redis本身就是支持高可用的,做到强一致性,就非常影响性能,所以,如果有强一致性要求高的业务,建议使用zookeeper实现的分布式锁,它是可以保证强一致性的。

