
- 1uniapp(vue3) H5页面连接打印机并打印_在uni-app(vue2)中h5调起浏览器自动打印
- 23.neo4j源码解读-neo4j配置apoc插件详细全流程(desktop 和社区版本)_neo4j源码解析
- 3Mysql高级语句(进阶查询语句、数据库函数、连接查询)_mysql数据库连接查询
- 4java第十版第九章答案_Java语言程序设计(基础篇)原书第十一版 梁勇 第9章 课后题答案...
- 5基础15·OS库下的python第三方库安装(OS库(操作系统交互),异常处理)_cmd安装os库
- 6Android 之Activity_获得用户焦点 是啥意思
- 7MySQL 用户管理操作_通过mysql实现用户管理
- 8MySQL表的增删改查(基础)_增啥改查四个英文
- 9怎样实现两台redis服务器的数据迁移_低版本redis 怎么保留数据迁移到高版本
- 10Qt+OpenCV识别物体的形状_qt opencv识别图像
Kafka生产者消息发送流程原理及源码分析
赞
踩
Kafka是一个分布式流处理平台,它能够以极高的吞吐量处理数据。在Kafka中,生产者负责将消息发送到Kafka集群,而消费者则负责从Kafka集群中读取消息。本文将探讨Kafka生产者消息发送流程的细节,包括消息的序列化、分区分配、记录提交等关键步骤。
先看一个生产者发送消息的代码样例
- public class MyProducer1 {
- public static void main(String[] args) throws ExecutionException, InterruptedException {
-
- Map<String, Object> configs = new HashMap<>();
- // 指定初始连接用到的broker地址
- configs.put("bootstrap.servers", "node164:9092");
- // 指定key的序列化类
- configs.put("key.serializer", IntegerSerializer.class);
- // 指定value的序列化类
- configs.put("value.serializer", StringSerializer.class);
- //borker集群消息持久化控制
- configs.put("acks", "all");
- //重试次数
- configs.put("reties", "3");
- KafkaProducer<Integer, String> producer = new KafkaProducer<Integer, String>(configs);
-
- // 用于设置用户自定义的消息头字段
- List<Header> headers = new ArrayList<>();
- headers.add(new RecordHeader("biz.name", "producer.demo".getBytes()));
-
- ProducerRecord<Integer, String> record = new ProducerRecord<Integer, String>(
- "test_topic",
- 0,
- 0,
- "hello world 0",
- headers
- );
-
- // 消息异步确认
- producer.send(record, new Callback() {
- @Override
- public void onCompletion(RecordMetadata metadata, Exception exception) {
- if (exception == null) {
- System.out.println("消息的主题:" + metadata.topic());
- System.out.println("消息的分区号:" + metadata.partition());
- System.out.println("消息的偏移量:" + metadata.offset());
- } else {
- System.out.println("异常消息:" + exception.getMessage());
- }
- }
- });
-
- // 关闭生产者
- producer.close();
- }
- }

通过跟踪producer.send源码可知生产者发送消息的大体流程如下图,RecordAccumulator的消息发送到brokers实际上由Sender线程处理,下图暂时忽略,先看producer主线程处理的一些细节。
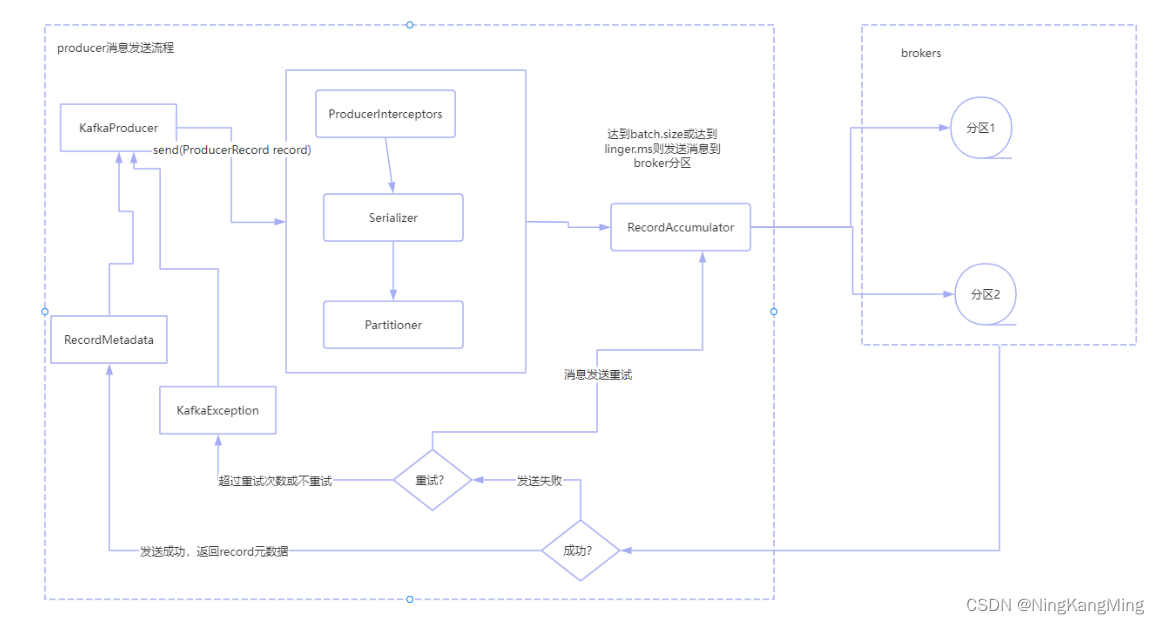
- KafkaProducer构造函数根据客户端参数初始化拦截器、序列化器、分区器,创建Sender守护线程。
- 调用send函数发送消息时,其内部使用异步消息发送,消息经过拦截器、序列化器、分区器后缓存到缓冲区。
- 批次发送的条件为:缓冲区数据⼤⼩达到batch.size或者linger.ms达到上限。
- 缓冲区消息发送到指定分区,落盘到broker。如果发送失败,客户端将根据设置的重试参数进行重试,如果超过了重试次数,抛出异常。
- 发送成功,返回RecordMetadata元数据到客户端。如果是同步调用将阻塞等待元数据返回,如果是异步调用将通过Callback接口进行回调返回元数据
生产者拦截器
KafkaProducer调用send方法后,如果有设置拦截器,会先经过拦截器,默认是不会经过任何拦截器的,除非客户端配置了拦截器(interceptor.classes参数),send函数如下
- @Override
- public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
- // intercept the record, which can be potentially modified; this method does not throw exceptions
- ProducerRecord<K, V> interceptedRecord = this.interceptors == null ? record : this.interceptors.onSend(record);
- return doSend(interceptedRecord, callback);
- }
可见,拦截器列表会被首先执行,而拦截器的初始化则是在KafkaProducer的 构造函数中,部分源码如下
- List<ProducerInterceptor<K, V>> interceptorList = (List) (new ProducerConfig(userProvidedConfigs, false)).getConfiguredInstances(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,
- ProducerInterceptor.class);
- this.interceptors = interceptorList.isEmpty() ? null : new ProducerInterceptors<>(interceptorList);
可见,拦截器是通过客户端配置的ProducerConfig.INTERCEPTOR_CLASSES_CONFIG来初始化的,拦截器必须实现ProducerInterceptor接口。
- public interface ProducerInterceptor<K, V> extends Configurable {
-
- public ProducerRecord<K, V> onSend(ProducerRecord<K, V> record);
-
-
- public void onAcknowledgement(RecordMetadata metadata, Exception exception);
-
-
- public void close();
- }
拦截器接口共有三个接口,第一个onSend接口把ProducerRecord直接传了进来,我们可以在实现接口时,对原消息进行统一处理,比如添加一些业务相关的头部信息等。onAcknowledgement接口则可以在确认消息发送成功后做一些操作,最后close接口则可以在拦截器关闭时清理一些资源。
如需要自定义拦截器则直接实现ProducerInterceptor接口,实现相关方法,在客户端进行配置即可,客户端配置示例:
- // 如果有多个拦截器,则设置为多个拦截器类的全限定类名,中间用逗号隔开
- configs.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, "com.xxx.CustomInterceptorOne,com.xxx.CustomInterceptorTwo");
生产者序列化器
拦截器处理完后,将进入到doSend方法,在发送消息前,首先会根据客户端配置的序列化器对key和value进行序列化。
序列化接口如下:
- public interface Serializer<T> extends Closeable {
-
- /**
- * Configure this class.
- * @param configs configs in key/value pairs
- * @param isKey whether is for key or value
- */
- void configure(Map<String, ?> configs, boolean isKey);
-
- /**
- * Convert {@code data} into a byte array.
- *
- * @param topic topic associated with data
- * @param data typed data
- * @return serialized bytes
- */
- byte[] serialize(String topic, T data);
-
- /**
- * Close this serializer.
- *
- * This method must be idempotent as it may be called multiple times.
- */
- @Override
- void close();
- }
在Kafka中,消息可以是任何类型的数据,如字符串、JSON、二进制数据等。为了将这些数据存储到Kafka集群中,Kafka需要对它们进行序列化。Kafka提供了多种序列化器,如StringSerializer、JsonSerializer等。生产者可以根据自己的需求选择合适的序列化器来序列化消息。如果默认提供的序列化器仍未满足需求,实现上面的Serializer接口,然后在客户端配置自己的序列化器即可。通过接口可以看出,序列化器最终将key和value序列化成字节数组。
doSend方法使用序列化器的部分源码:
- byte[] serializedKey;
- try {
- serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
- } catch

