
- 1Linux解压编译Tfa/bootloader_arm scmi client
- 2【AI 测试】三:数据结构理解之 树形数据结构_树形结构与ai算法
- 32024华为OD机试(C卷+D卷)最新题库(Java & Python & C++)_华为od题库c卷
- 4记一次本机使用 Java API 读取虚拟机 HDFS 文件出错:Could not obtain block…
- 5基于共识的捆绑算法(CBBA)的多智能体多任务分配问题——远程太空船交会和维修的 RPO 规划任务研究(Matlab代码实现)_cbba算法
- 6Macos多协议远程管理---Termius中文_mac termius
- 7快速排序算法的发明者霍尔_快速排序谁发明的
- 8经典机器学习算法——决策树_机器学习 决策算法
- 9【Python】Django删除数据迁移记录_python manage.py migrate 清除缓存
- 10git如何合并指定文件内容_Git 合并指定文件或文件夹
云原生Kubernetes:二进制部署K8S单Master架构(一)_kubernetes架构项目
赞
踩
目录
一、理论
1.K8S单Master架构
(1) 生产环境部署k8s常见的几种方式
- 1、kubeadm
- Kubeadm是一个K8s部署工具,提供kubeadm init和kubeadm join,用于快速部署Kubernetes集群。
- 2、二进制
- 从github下载发行版的二进制包,手动部署每个组件,组成Kubernetes集群。
- 小结:
- Kubeadm降低部署门槛,但屏蔽了很多细节,遇到问题很难排查。如果想更容易可控,推荐使用二进制包部署Kubernetes集群,虽然手动部署麻烦点,期间可以学习很多工作原理,也利于后期维护。
- 3、kubespray
- Kubespray 是 Kubernetes incubator 中的项目,目标是提供 Production Ready Kubernetes 部署方案,该项目基础是通过 Ansible Playbook
- 来定义系统与 Kubernetes 集群部署的任务。
(2)二进制安装K8S单Master架构
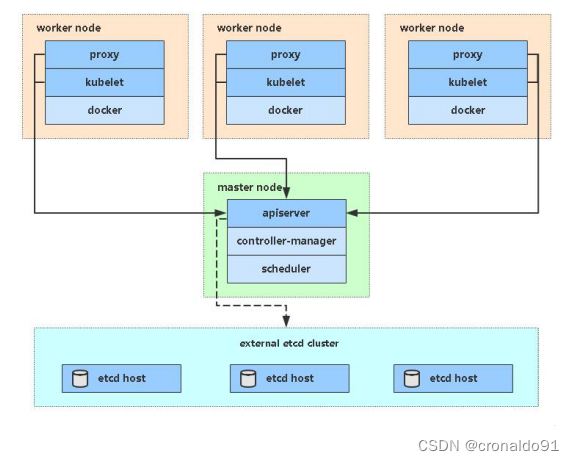
(3)TLS bootstrapping机制
TLS Bootstraping:Master apiserver启用TLS认证后,Node节点kubelet和kube-proxy要与kube-apiserver进行通信,必须使用CA签发的有效证书才可以,当Node节点很多时,这种客户端证书颁发需要大量工作,同样也会增加集群扩展复杂度。为了简化流程,Kubernetes引入了TLS bootstraping机制来自动颁发客户端证书,kubelet会以一个低权限用户自动向apiserver申请证书,kubelet的证书由apiserver动态签署。所以强烈建议在Node上使用这种方式,目前主要用于kubelet,kube-proxy还是由我们统一颁发一个证书。
TLS bootstraping 工作流程:

2. etcd 集群
(1)概念
etcd是CoreOS团队于2013年6月发起的开源项目,他的目标是构建一个高可用的分布式键值(key-value)数据库,etcd内部采用raft协议作为一致性算法,etcd是go语言编写的。
(2)特点
etcd 目的默认使用2379端口提供HTTP API服务,2380端口和peer通信(这两个端口已经被 TANA(互联网数字分配机构)官方预留给etcd)。
既etcd默认使用2379端口对外为客户端提供通讯,使用端口2380来进行服务器间内部通讯。
etcd 再生产环境中一般推荐集群方式部署。由于etcd 的leader选举机制,要求至少为3台或以上的奇数台。
主要特点如下:
- • 简单 安装配置简单,而且提供了HTTP API进行交互,使用也很简单
- • 安全: 支持SSL证书验证
- • 快速: 单实例支持每秒2k+读操作
- • 可靠: 采用raft算法实现分布式系统数据的可用性和一致性
(3)准备签发证书环境
CFSSL 是 CloudFlare 公司开源的一款 PKI/TLS 工具。 CESSL 包含一个命令行工具和一个用于签名、验证和捆绑 TLS 证书的 HTTP API 服务。使用Go语言编写。
CFSSL使用配置文件生成证书,因此自签之前,需要生成它识别的json 格式的配置文件,CFSSL 提供了方便的命令行生成配置文件。
CFSSL用来为etcd提供TLS证书,它支持签三种类型的证书:
- 1、client证书,服务端连接客户端时携带的证书,用于客户端验证服务端身份,如kube-apiserver 访问etcd;
- 2、server证书,客户端连接服务端时携带的证书,用于服务端验证客户端身份,如etcd对外提供服务:
- 3、peer证书,相互之间连接时使用的证书,如etcd节点之间进行验证和通信。
- 这里全部都使用同一套证书认证。
表1 签发证书
| cfssl | 证书签发的工具命令 |
| cfssljson | 将cfssl 生成的证书 (json格式) 变为文件承载式证书 |
| cfssl-certinfo | 验证证书的信息 |
| cfssl certinfo cert <证书名称> | 查看证书的信息 |
3.CNI
(1)概念
CNI(Container NetworkInterface)意为容器网络接口,它是一种标准的设计,为了让用户在容器创建或销毁时都能够更容易地配置容器网络。由Google和CoreOS联合定制的网络标准,是Kubernetes网络插件的基础。基于CNI标准,有如下常见的CNI网络插件产品。

(2)流行CNI插件
实际应用中流行的CNI插件:Flannel和Calico。这些插件既可以确保满足Kubernetes的网络要求,又能为Kubernetes集群管理员提供他们所需的某些特定的网络功能。
①Flannel
使用Flannel默认的VxLAN模式workernode节点信息及部署的Pod示意如下:

②Calico
使用Calico默认的VxLan模式workernode节点信息及部署的Pod示意如下:

- 1.Calico网络插件介绍:
- Calico是Kubernetes生态系统中另一种流行的网络选择。虽然Flannel被公认为是最简单的选择,但Calico以其性能、灵活性而闻名。Calico的功能更为全面,不仅提供主机和pod之间的网络连接,还涉及网络安全和管理。Calico CNI插件在CNI框架内封装了Calico的功能。
-
- 除了网络连接外,Calico还以其先进的网络功能而闻名。网络策略是其最受追捧的功能之一。此外,Calico还可以与服务网格Istio集成,以便在服务网格层和网络基础架构层中解释和实施集群内工作负载的策略。这意味着用户可以配置强大的规则,描述pod应如何发送和接受流量,提高安全性并控制网络环境。如果对你的环境而言,支持网络策略是非常重要的一点,而且你对其他性能和功能也有需求,那么Calico会是一个理想的选择。
-
- 尽管部署Calico所需的操作看起来相当简单,但它创建的网络环境同时具有简单和复杂的属性。与Flannel不同,Calico不使用overlay网络。相反,Calico配置第3层网络,该网络使用BGP路由协议在主机之间路由数据包。这意味着在主机之间移动时,不需要将数据包包装在额外的封装层中。BGP路由机制可以本地引导数据包,而无需额外在流量层中打包流量。
-
-
- 2,Calico 的几种模式:
- IPIP模式:把 IP 层封装到IP 层的一个 tunnel。作用其实基本上就相当于一个基于IP层的网桥!一般来说,普通的网桥是基于mac层的,根本不需 IP,而这个ipip 则是通过两端的路由做一个 tunnel,把两个本来不通的网络通过点对点连接起来。
-
- BGP 边界网关协议(Border Gateway Protocol, BGP):是互联网上一个核心的去中心化自治路由协议。BGP不使用传统的内部网关协议(IGP)的指标。
-
- Route Reflector 模式(RR)(路由反射):Calico维护的网络在默认是(Node-to-Node Mesh)全互联模式,Calico集群中的节点之间都会相互建立连接,用于路由交换。但是随着集群规模的扩大,mesh模式将形成一个巨大服务网格,连接数成倍增加。这时就需要使用 Route Reflector(路由器反射)模式解决这个问题。
(3)VXLAN 技术
VXLAN(Virtual eXtensible Local Area Network,虚拟扩展局域网)技术是一种大二层的虚拟网络技术,是Overlay网络中的核心技术。VXLAN技术很好地解决了现有VLAN技术无法满足大二层网络需求的问题。它备受业界关注,未来有可能成为网络虚拟化技术当中的主流技术之一。
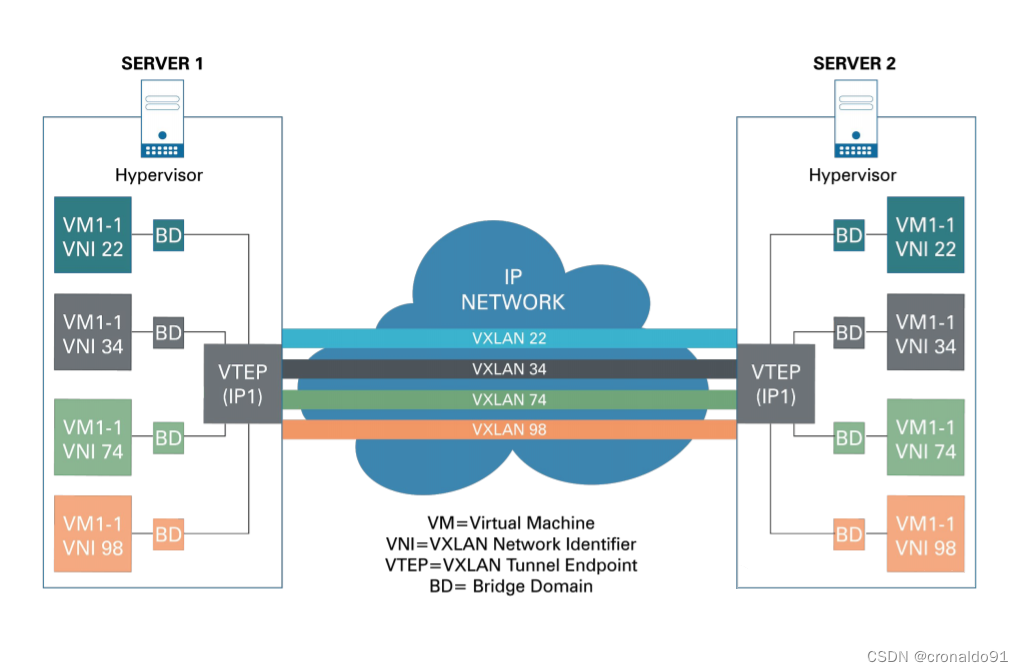
① 概念
VXLAN是一种虚拟网络技术,旨在解决大型云计算部署相关的扩展问题。它使用类似VLAN的封装技术将第2层以太网帧封装在第4层UDP数据报中。由于外层采用了UDP作为传输手段,净荷数据可以轻松地在二三层网络中传送。

② VTEP
Tunnel Endpoint (VTEP)。VXLAN使用VTEP设备对VXLAN报文进行封装与解封装,包括ARP请求报文和正常的VXLAN数据报文,VTEP将原始以太网帧通过VXLAN封装后发送至对端 VTEP设备,对端VTEP接收到 VXLAN报文后解封装然后根据原始 MAC进行转发,VTEP可以是物理交换机、物理服务器或者其他支持 VXLAN的硬件设备或软件来实现。
③场景
在数据中心,VXLAN是最常用的协议,用于创建位于物理网络之上的覆盖网络,从而能够使用由交换机、路由器、防火墙、负载均衡器等组成的虚拟网络。
 ④封装方法
④封装方法
- IP覆盖网络的以太网
-
- 整个L2帧封装在UDP中
-
- 占用50 bytes
-
- 包含24 bit VXLAN标识符(VNl tag)
-
- 24 bit ->16M逻辑网络
⑤ VXLAN数据包图

⑥ VXLAN报头
标志(8位)–对于有效的VXLAN网络ID(VNI),l标志设置为1,其余7位(标志为R)为保留字段,并设置为0。
VXLAN网络标识符(VNI)(24位)–用于标识通信VM所在的各个VXLAN覆盖网络。不同VXLAN覆盖网络中的虚拟机无法通信。

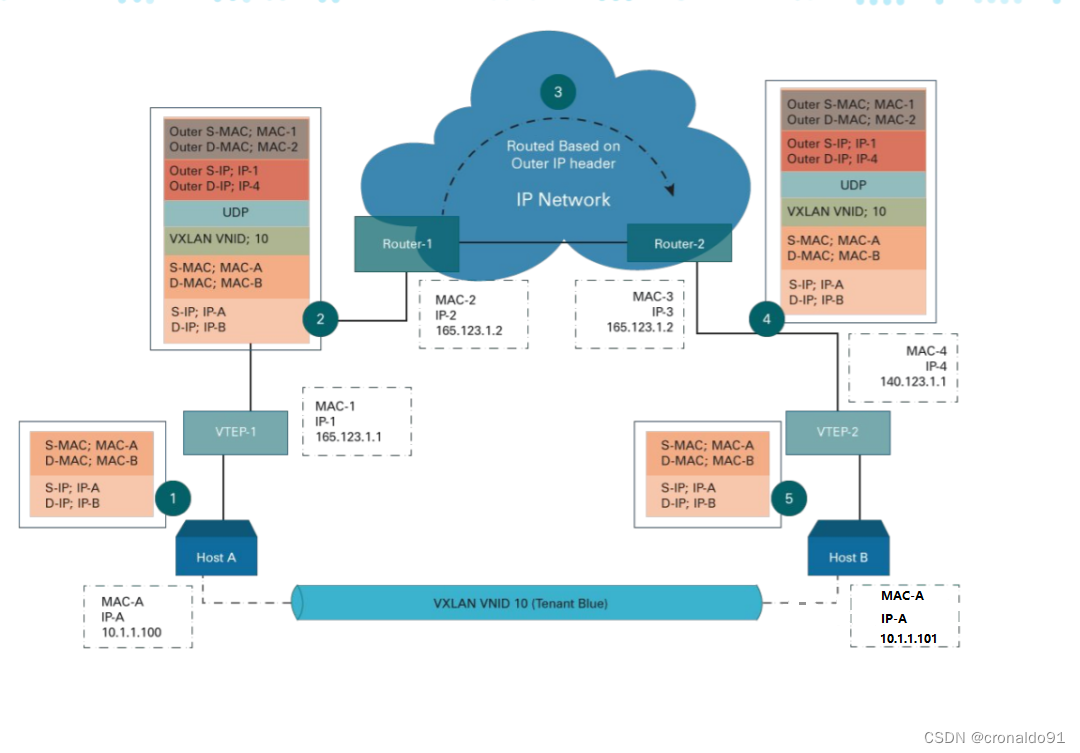
⑦ VXLAN使用完整示例
4.Flannel网络
(1)K8S中Pod网络通信
●Pod内容器与容器之间的通信
在同一个Pod内的容器(Pod内的容器是不会跨宿主机的)共享同一个网络命令空间,相当于它们在网一台机器上一样,可以用localhost地址访间彼此的端口
●同一个Node内Pod之间的通信
每个Pod 都有一个真实的全局IP地址,同一个Node 内的不同Pod之间可以直接采用对方Pod的IP 地址进行通信,Pod1 与Pod2都是通过veth连接到同一个docker0 网桥,网段相同,所以它们之间可以直接通信
●不同Node上Pod之间的通信
Pod地址与docker0 在同一网段,dockor0 网段与宿主机网卡是两个不同的网段,且不同Nodo之间的通信贝能通过宿主机的物理网卡进行
要想实现不同Node 上Pod之间的通信,就必须想办法通过主机的物理网卡IP地址进行寻址和通信。因此要满足两个条件: Pod 的IP不能冲突;将Pod的IP和所在的Node的IP关联起来,通过这个关联让不同Node上Pod之间直接通过内网IP地址通信。
Overlay Network:
叠加网络,在二层或者三层基础网络上叠加的一种虚拟网络技术模式,该网络中的主机通过虚拟链路隧道连接起来(类似于VPN)
VXLAN:
将源数据包封装到UDP中,并使用基础网络的IP/MAC作为外层报文头进行封装,然后在以太网上传输,到达目的地后由隧道端点解封装并将数据发送给目标地址
Flannel:
Flannel的功能是让集群中的不同节点主机创建的Docker容器都具有全集群唯一的虚拟IP地址
Flannel是Overlay 网络的一种,也是将TCP 源数据包封装在另一种网络 包里而进行路由转发和通信,目前己经支持UDP、VXLAN、host-GW 3种数据转发方式
(2)工作原理

数据从 node1 上的 Pod 源容器中发出后,经由所在主机的 docker0 虚拟网卡转发到flannel.1 虚拟网卡;flanneld服务监听在 flannel.1虚拟网卡的另外一端。
Flannel 通过 Etcd 服务维护了一张节点间的路由表。源主机 node01 的flanneld 服务将原本的数据内容封装到 UDP 中后根据自己的路由表通过物理网卡投递给目的节点 node02 的 flanneld 服务,数据到达以后被解包,然后直接进入目的节点的 flannel.1 虚拟网卡,之后被转发到目的主机的 docker0 虚拟网卡,最后就像本机容器通信一样由 docker0 转发到目标容器。
ETCD之Flannel 提供说明:
存储管理Flanne1可分配的IP地址段资源
监控 ETCD 中每个 Pod 的实际地址,并在内存中建立维护 Pod 节点路由表
5.K8S单Master架构环境部署
本实验所需要的软件及脚本:【免费】k8s单Master节点(软件与脚本)资源-CSDN文库
(1)关闭防火墙
- systemctl stop firewalld
- systemctl disable firewalld
(2)关闭selinux
- setenforce 0 #临时关闭
- sed -i 's/enforcing/disabled/' /etc/selinux/config #永久关闭
(3)关闭swap
- swapoff -a
- sed -ri 's/.*swap.*/#&/' /etc/fstab
(4)根据规划设置主机名
- hostnamectl set-hostname master01
- hostnamectl set-hostname node01
- hostnamectl set-hostname node02
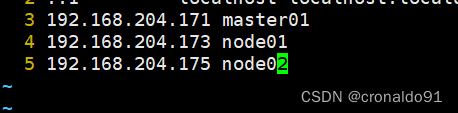
(5)在master添加hosts
- cat >> /etc/hosts << EOF
- 192.168.204.171 master01
- 192.168.204.173 node01
- 192.168.204.175 node02
- EOF
(6)将桥接的IPv4流量传递到iptables的链
- cat > /etc/sysctl.d/k8s.conf << EOF
- net.bridge.bridge-nf-call-ip6tables = 1
- net.bridge.bridge-nf-call-iptables =1
- EOF
-
- sysctl --system #重新载入一下
(7)时间同步
- yum install ntpdate -y
- ntpdate time.windows.com
6.部署 etcd 集群
(1)在 master01 节点上操作
下载证书制作工具
- wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64 -O /usr/local/bin/cfssl
- wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64 -O /usr/local/bin/cfssljson
- wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64 -O /usr/local/bin/cfssl-certinfo
- 或
- curl -L https://pkg.cfssl.org/R1.2/cfssl_linux-amd64 -o /usr/local/bin/cfssl
- curl -L https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64 -o /usr/local/bin/cfssljson
- curl -L https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64 -o /usr/local/bin/cfssl-certinfo
-
-
- chmod +x /usr/local/bin/cfssl*
也可以提前将软件包传入了opt目录中
- mv cfssl* /usr/local/bin/
-
- #查看
- ls /usr/local/bin/ |grep cfssl*
-
- chmod +x /usr/local/bin/cfssl*
-
创建k8s工作目录
- mkdir /opt/k8s
- cd /opt/k8s/
上传 etcd-cert.sh 和 etcd.sh 到 /opt/k8s/ 目录中
chmod +x etcd-cert.sh etcd.sh
创建用于生成CA证书、etcd服务器证书以及私钥的目录
- mkdir /opt/k8s/etcd-cert
- mv etcd-cert.sh etcd-cert/
- cd /opt/k8s/etcd-cert/
- ./etcd-cert.sh #生成CA证书、etcd 服务器证书以及私钥
(2)启动etcd服务
etcd二进制包地址: https://github.com/etcd-io/etcd/releases也可以上传 etcd-v3.3.10-1inux-amd64.tar.gz 到 /opt/k8s/ 目录中,解压 etcd 压缩包
- cd /opt/k8s/
- tar zxvf etcd-v3.3.10-linux-amd64.tar.gz
- ls etcd-v3.3.10-linux-amd64
创建用于存放 etcd 配置文件,命令文件,证书的目录
- mkdir -p /opt/etcd/{cfg,bin,ssl}
-
- mv /opt/k8s/etcd-v3.3.10-linux-amd64/etcd /opt/k8s/etcd-v3.3.10-linux-amd64/etcdctl /opt/etcd/bin/
- cp /opt/k8s/etcd-cert/*.pem /opt/etcd/ssl/
-
- ./etcd.sh etcd01 192.168.204.171 etcd02=https://192.168.204.173:2380,etcd03=https://192.168.204.175:2380
进入卡住状态等待其他节点加入,这里需要三台etcd服务同时启动,如果只启动其中一台后,服务会卡在那里,直到集群中所有etcd节点都已启动,可忽略这个情况
另外打开一个窗口查看etcd进程是否正常
ps -ef | grep etcd
把etcd相关证书文件和命令文件全部拷贝到另外两个
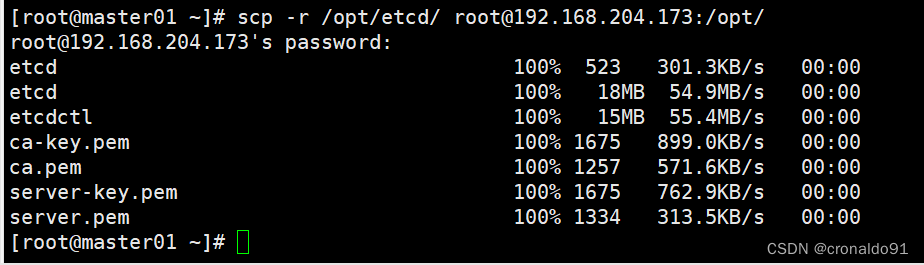
- scp -r /opt/etcd/ root@192.168.204.173:/opt/
- scp -r /opt/etcd/ root@192.168.204.175:/opt/
把etcd服务管理文件拷贝到另外两个etcd集群节点
- scp /usr/lib/systemd/system/etcd.service root@192.168.204.173:/usr/lib/systemd/system/
- scp /usr/lib/systemd/system/etcd.service root@192.168.204.175:/usr/lib/systemd/system/
-
注意修改etcd-cert.sh配置
vim etcd-cert.sh (3)在node节点修改
在node1节点修改
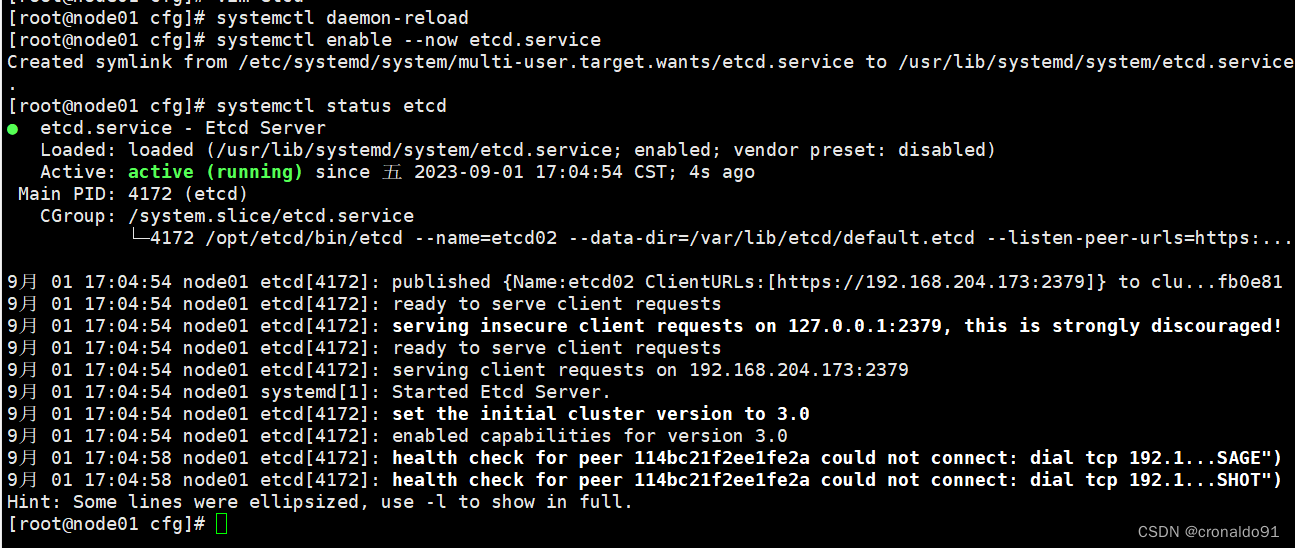
- cd /opt/etcd/cfg/
- vim etcd
- #[Member]
- ETCD_NAME="etcd02"
- ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
- ETCD_LISTEN_PEER_URLS="https://192.168.204.173:2380"
- ETCD_LISTEN_CLIENT_URLS="https://192.168.204.173:2379"
-
- #[Clustering]
- ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.204.173:2380"
- ETCD_ADVERTISE_CLIENT_URLS="https://192.168.204.173:2379"
- ETCD_INITIAL_CLUSTER="etcd01=https://192.168.204.171:2380,etcd02=https://192.168.204.173:2380,etcd03=https://192.168.204.175:2380"
- ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
- ETCD_INITIAL_CLUSTER_STATE="new"
-
- systemctl daemon-reload
- systemctl enable --now etcd.service
- systemctl status etcd
-

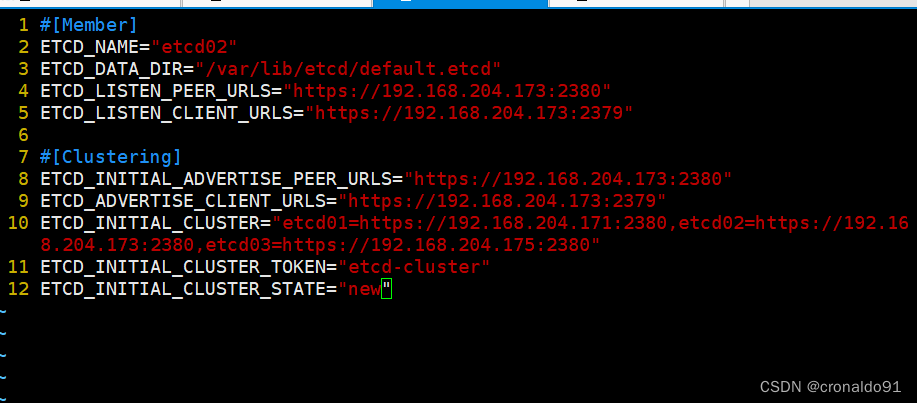
在node2节点修改
- cd /opt/etcd/cfg/
- vim etcd
- #[Member]
- ETCD_NAME="etcd03"
- ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
- ETCD_LISTEN_PEER_URLS="https://192.168.204.175:2380"
- ETCD_LISTEN_CLIENT_URLS="https://192.168.204.175:2379"
-
- #[Clustering]
- ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.204.175:2380"
- ETCD_ADVERTISE_CLIENT_URLS="https://192.168.204.175:2379"
- ETCD_INITIAL_CLUSTER="etcd01=https://192.168.204.171:2380,etcd02=https://192.168.204.173:2380,etcd03=https://192.168.204.175:2380"
- ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
- ETCD_INITIAL_CLUSTER_STATE="new"
-
- systemctl daemon-reload
- systemctl enable --now etcd.service
- systemctl status etcd
首先在master1节点上进行启动
- cd /opt/k8s/
- ./etcd.sh etcd01 192.168.204.171 etcd02=https://192.168.204.173:2380,etcd03=https://192.168.204.175:2380
接着在node1和node2节点分别进行启动
systemctl start etcd.service
(4)在 master01 节点上操作
ln -s /opt/etcd/bin/etcd* /usr/local/bin
检查etcd群集状态
- cd /opt/etcd/ssl
-
- ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://192.168.204.171:2379,https://192.168.204.173:2379,https://192.168.204.175:2379" endpoint health --write-out=table
-
- ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://192.168.204.171:2379,https://192.168.204.173:2379,https://192.168.204.175:2379" endpoint status --write-out=table
参数解释:
- --cert-file:识别HTTPS端使用sSL证书文件
- --key-file: 使用此SSL密钥文件标识HTTPS客户端
- -ca-file:使用此CA证书验证启用https的服务器的证书
- --endpoints:集群中以逗号分隔的机器地址列表
- cluster-health:检查etcd集群的运行状况
切换到etcd3版本查看集群节点状态和成员列表
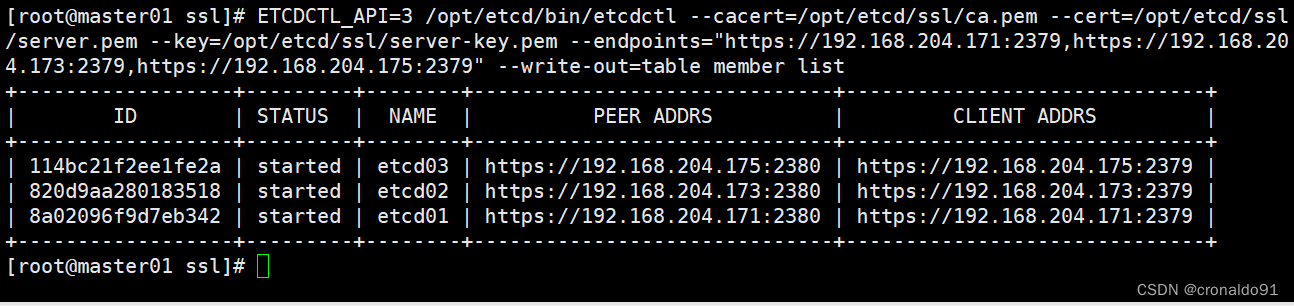
ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://192.168.204.171:2379,https://192.168.204.173:2379,https://192.168.204.175:2379" --write-out=table member list7.部署 docker 引擎
(1)所有node节点部署docker引擎
- yum install -y yum-utils device-mapper-persistent-data lvm2
- yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
- yum install -y docker-ce dqsker-ce-cli containerd.io
-
- systemctl start docker.service
- systemctl enable docker.service
8.flannel网络配置
(1)在 master01 节点上操作
添加 flannel 网路配置信息,写入分配的子网段到 etcd 中,供 flannel 使用
- cd /opt/etcd/ssl
- /opt/etcd/bin/etcdctl \
- --ca-file=ca.pem \
- --cert-file=server.pem \
- --key-file=server-key.pem \
- --endpoints="https://192.168.204.171:2379,https://192.168.204.173:2379,https://192.168.204.175:2379" \
- set /coreos.com/network/config '{"Network": "172.17.0.0/16","Backend": {"Type": "vxlan"}}'
查看写入的信息
- /opt/etcd/bin/etcdctl \
- --ca-file=ca.pem \
- --cert-file=server.pem \
- --key-file=server-key.pem \
- --endpoints="https://192.168.204.171:2379,https://192.168.204.173:2379,https://192.168.204.175:2379" \
- get /coreos.com/network/config
参数解释
- set <key> <value>
- set /coreos.com/network/config 添加一条网络配置记求,这个配置将用于flannel分配给每个docker的虛拟IP地址段
- get <key>
- got /coreos.com/network/config获取网络配置记录,后面不用再跟参数了
-
- Network:用于指定Flannel地址池
-
- Backend:用于指定数据包以什么方式转发,默认为udp模式,Backend为vxlan比起预设的udp性能相对好一些
(2)在所有node节点上操作
上传flannel.sh 和flanne1-v0.10.0-1inux-amd64.tar.gz 到/opt 目录中,解压flannel 压缩包
- cd /opt
- tar zxvf flannel-v0.10.0-linux-amd64.tar.gz
创建 kubernetes 工作目录
- mkdir -p /opt/kubernetes/{cfg,bin,ssl}
-
-
- cd /opt
- mv mk-docker-opts.sh flanneld /opt/kubernetes/bin/
启动flanneld服务,开启flanne1网络功能
- cd /opt
- chmod +x flannel.sh
- ./flannel.sh https://192.168.204.171:2379,https://192.168.204.173:2379,https://192.168.111.175:2379
flanne1启动后会生成一个docker网络相关信息配置文件/run/flannel/subnet.env,包含了docker要使用flannel通讯的相关参数
cat /run/flannel/subnet.env
- DOCKER_OPT_BIP="--bip=172.17.26.1/24"
- DOCKER_OPT_IPMASQ="--ip-masq= false"
- DOCKER_OPT_MTU="--mtu=1450"
- DOCKER_NETWORK_OPTIONS=" --bip=172.17.26.1/24 --ip-masq=false --mtu=1450"
- ------------------------------------------------
- --bip: 指定 docker 启动时的子网
- --ip-masq: 设置 ipmasq=false 关闭 snat 伪装策略
- --mtu=1450: mtu要留出50字节给外层的vxlan封包的额外开销使用
-
- Flannel启动过程解析:
- 1、从etcd中获取network的配置信息
- 2、划分subnet, 并在etcd中进行注册
- 3、将子网信息记录到/run/flannel/subnet.env中
- ------------------------------------------------
修改docker服务管理文件,配置docker连接flannel
- vim /lib/systemd/system/docker.service
- [Service]
- Type=notify
- # the default is not to use systemd for cgroups because the delegate issues stillt
- # exists and systemd currently dges not support the cgroup feature set requi red
- # for containers run by docker
- EnvironmentFile=/run/flannel/subnet.env
- #添加
- ExecStart=/usr/bin/dockerd $DOCKER_NETWORK_OPTIONS -H fd:// --containerd=/run/containerd/containerd.sock
- #修改
- ExecReload=/bin/kill -s HUP $MAINPID
- TimeoutSec=0
- RestartSec=2
- Restart=always
重启docker服务
- systemctl daemon-reload
- systemctl restart docker
查看flannel网络
ifconfig测试能否ping通对方docker0网卡
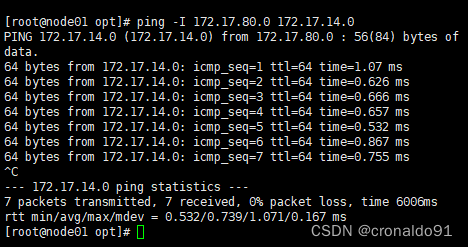
ping -I 172.17.80.0 172.17.14.0
如果部署的k8s中途暂停了,导致flannel(或Docker)网络不通,可以配置ipv4转发功能解决
- cat >> /etc/sysctl.conf << EOF
- net.ipv4.ip_forward=1
- EOF
二、实验
1.二进制部署K8S单Master架构
(1)环境
表2 K8S环境
| 主机 | IP | 软件 | 硬件 |
| k8s集群master01 | 192.168.204.171 | kube-apiserver kube-controller-manager kube-scheduler etcd | 4核4G |
| k8s集群node1 | 192.168.204.173 | kubelet kube-proxy docker flannel | 4核4G |
| k8s集群node2 | 192.168.204.175 | kubelet kube-proxy docker flannel | 4核4G |
2. 环境部署
(1)关闭防火墙
(2)关闭selinux


(3)关闭swap

(4)根据规划设置主机名



(5)在master添加hosts



(6)将桥接的IPv4流量传递到iptables的链





(7)时间同步
安装软件



同步时间



3.部署 etcd 集群
(1)在 master01 节点上操作
可提前将软件包传入了opt目录中
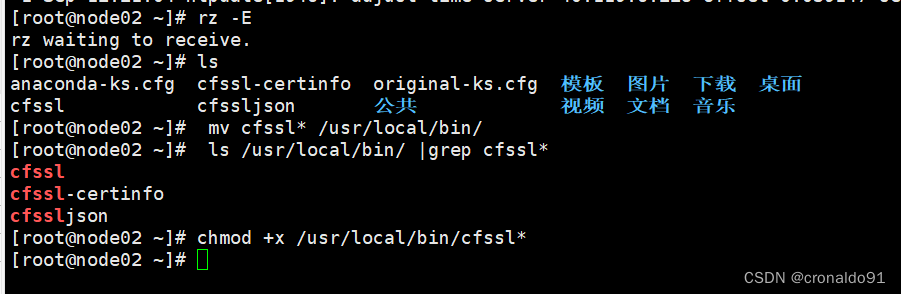
创建k8s工作目录

上传 etcd-cert.sh 和 etcd.sh 到 /opt/k8s/ 目录中

创建用于生成CA证书、etcd服务器证书以及私钥的目录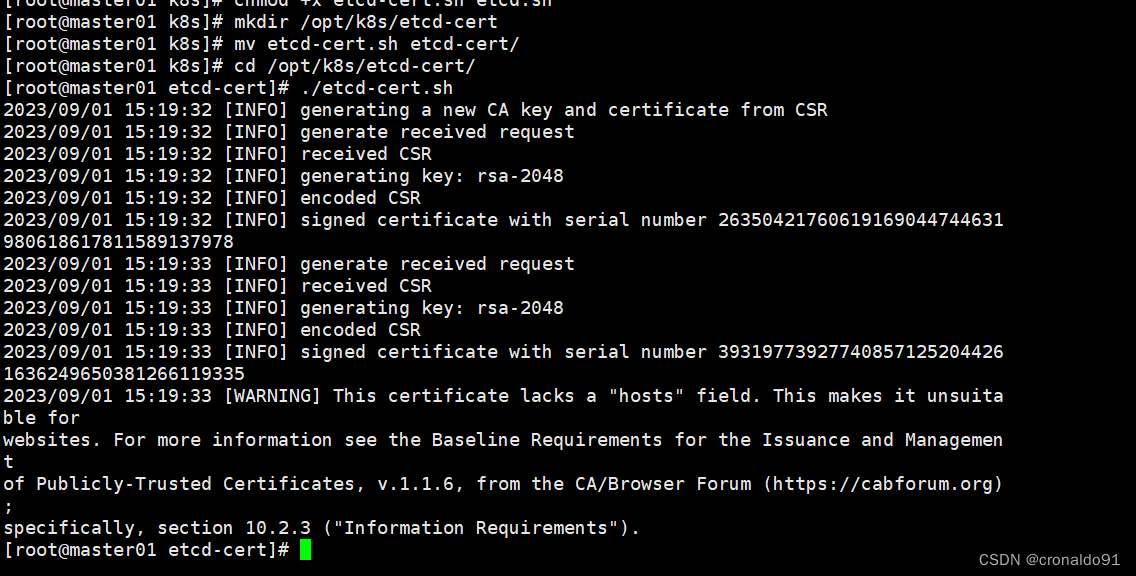
查看
(2)启动etcd服务
上传 etcd-v3.3.10-1inux-amd64.tar.gz 到 /opt/k8s/ 目录中,解压 etcd 压缩包


创建用于存放 etcd 配置文件,命令文件,证书的目录

指定服务器IP和端口启动,会卡在这这时需要再打开一个终端

进入卡住状态等待其他节点加入,这里需要三台etcd服务同时启动,如果只启动其中一台后,服务会卡在那里,直到集群中所有etcd节点都已启动,可忽略这个情况
另外打开一个窗口查看etcd进程是否正常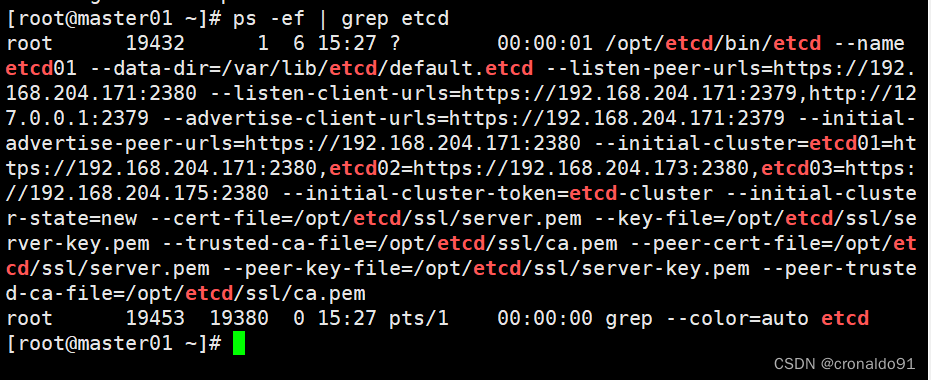
把etcd相关证书文件和命令文件全部拷贝到另外两个
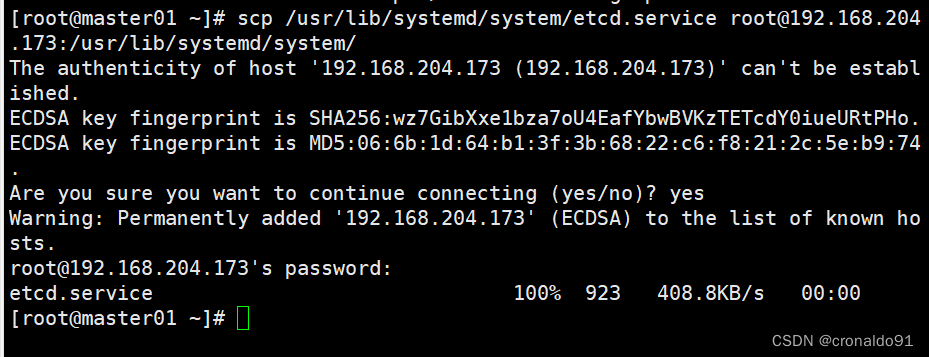

把etcd服务管理文件拷贝到另外两个etcd集群节点

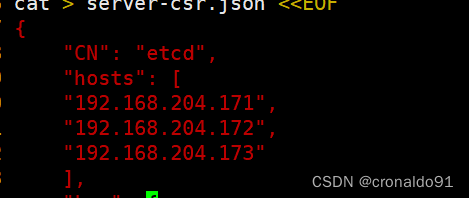
注意修改etcd-cert.sh配置

(3)在node节点修改
在node1节点修改

启动成功
在node2节点修改
启动成功

首先在master1节点上进行启动

接着在node1和node2节点分别进行启动


(4)在 master01 节点上操作

检查etcd群集状态

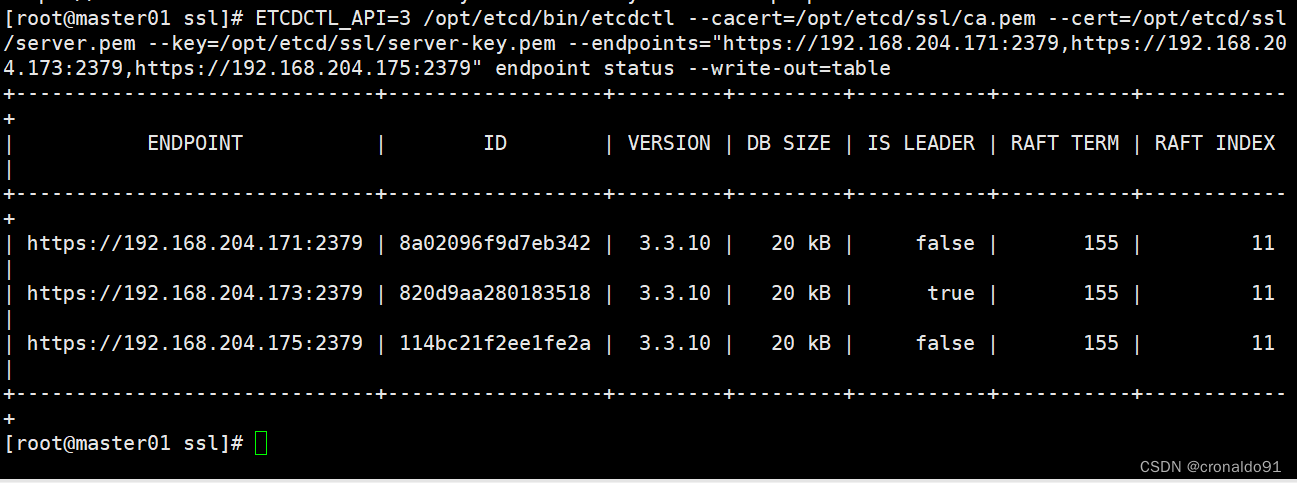
切换到etcd3版本查看集群节点状态和成员列表
4.部署 docker 引擎
(1) 所有node节点部署docker引擎
![]()



5.flannel网络配置
(1)在 master01 节点上操作
添加 flannel 网路配置信息,写入分配的子网段到 etcd 中,供 flannel 使用

查看写入的信息

(2)在所有node节点上操作
上传flannel.sh 和flanne1-v0.10.0-1inux-amd64.tar.gz 到/opt 目录中,解压flannel 压缩包

创建 kubernetes 工作目录

启动flanneld服务,开启flanne1网络功能

flanne1启动后会生成一个docker网络相关信息配置文件/run/flannel/subnet.env,包含了docker要使用flannel通讯的相关参数

修改docker服务管理文件,配置docker连接flannel




重启docker服务


查看flannel网络
node1节点为flannel的 172.17.80.0

node1节点为flannel的172.17.14.0
测试能否ping通对方docker0网卡
配置ipv4转发功能



三、问题
1.etcd 报错
(1)报错
日志显示
error “remote error: tls: bad certificate“, ServerName ““)(2)原因分析
etcd证书请求文件中未增加hosts参数
(3)解决方法
etcd证书请求文件中增加hosts参数将etcd节点加入后重新生成证书文件


2.安装etcd问题
(1)报错
etcd:Job for etcd.service failed because a timeout was exceeded. See "systemctl status etcd.service"(2)原因分析
系统支持及配置文件
(3)解决方法
解决方案1:
在etcd.conf配置文件中的其他节点信息必须使用: " http:" 而不能使用“ https: ”。解决方案2:
- 更新etcd系统默认配置
- 当前使用的是etcd v3版本,系统默认的是v2,通过下面命令修改配置。
-
- # vim /etc/profile
-
- 在文件末尾追加:
-
- export ETCDCTL_API=3
-
- 让更改生效:
-
- # source /etc/profile
3.系统断电后,某个etcd节点无法启动
(1) 报错
publish error: etcdserver: request timed out
(2)原因分析
坏掉的 etcd 节点并没有启动
(3)解决方法
检查日志发现并没有特别明显的错误,根据经验来讲,etcd 节点坏掉一个其实对集群没有大的影响,这时集群已经可以正常使用了,但是这个坏掉的 etcd 节点并没有启动
- #进入 etcd 的数据存储目录进行备份 备份原有数据:
- cd /var/lib/etcd/default.etcd/member/
- cp * /data/bak/
- #删除这个目录下的所有数据文件
- rm -rf /var/lib/etcd/default.etcd/member/*
- #停止另外两台 etcd 节点,因为 etcd 节点启动时需要所有节点一起启动,启动成功后即可使用。
- systemctl stop etcd
- systemctl restart etcd
4. 如何永久关闭swap
(1)解决方法
sed -ri 's/.*swap.*/#&/' /etc/fstab
sed命令选项与参数:
- -n : 使用静默模式,在一般的sed的用法中,所有来自stdin(标准输出)的数据一般都会被列出到屏幕上。
- 但如果加上-n参数后,则只要经过sed特殊处理的那行才会被列出来。
- -e : 直接在命令行模式上进行sed的操作编辑
- -f : 直接将sed的操作写在一个文件内,-f filename则可以执行filename内的sed操作
- -r : 使用扩展正则表达式的语法
- -i : 直接修改文件内容,而不是输出到屏幕上
- command说明:[n1][,n2] action
- n1,n2 : 一般代表【选择进行操作(action)的行数】,举例:如果我的操作是需要在
- 5行到20行之间进行的,则【5,20[action]】。
- action的参数:
- 单行模式空间
- a : 新增。a的后面接字符,而这些字符会在新增到下一行
- i : 插入。i的后面接字符,而这些字符会在新增到上一行
- c : 替换。c的后面接字符,这些字符替换n1到n2的行
- d : 删除。因为是删除,所以d后面通常不接任何东西
- p : 打印。将匹配的数据打印出来。通常p会与选项-n一起使用
- s : 替换。将文件原内容替换为新内容。举例:s/lod/new/g
- n : 读取匹配的数据的下一行,覆盖模型空间的前一行(也就是被匹配的行),结果交给下一个参数处理
- 多行模式空间
- N : 读取匹配的数据的下一行追加到模式空间,同时将两行看做一行,但是两行之间依然含有\n换行符
- P : 打印。打印模式空间开端至\n(换行)之间的内容,并追加到默认输出之前。
- D : 如果模式空间包含换行符,则删除模式空间开端至\n(换行)之间的内容, 并不会读取新的输入行,
- 而使用合成的模式空间重新启动循环。如果模式空间不包含换行符,则会像发出d命令那样启动正常的新循环
-
- 替换标记
- g 表示行内全面替换。
- p 表示打印行。
- w 表示把行写入一个文件。
- x 表示互换模板块中的文本和缓冲区中的文本。
- y 表示把一个字符翻译为另外的字符(但是不用于正则表达式)
- \\1 子串匹配标记
- & 已匹配字符串标记
-
- 其它
- ! 表示后面的命令对所有没有被选定的行发生作用。
- = 打印当前行号码。
- # 把注释扩展到下一个换行符以前。
四、总结
Kubeadm降低部署门槛,但屏蔽了很多细节,遇到问题很难排查。如果想更容易可控,推荐使用二进制包部署Kubernetes集群,虽然手动部署麻烦点,期间可以学习很多工作原理,也利于后期维护。
etcd就是etcd服务的启动命令,后面可跟各种启动参数;etcdctl主要为etcd服务提供了命令行操作。etcd端口如下:
默认使用2379端口对外为客户端提供通讯,使用端口2380来进行服务器间内部通讯。实际应用中流行的CNI插件:Flannel和Calico,其对比如下:
Flannel启动过程解析:
- 1、从etcd中获取network的配置信息
-
- 2、划分subnet, 并在etcd中进行注册
-
- 3、将子网信息记录到/run/flannel/subnet.env中

