
- 1答题PK狂欢!欢乐互动的团队多人PK答题小程序源码_网页答题pk代码大全
- 2Git笔记 | 将错误的代码Push至远程仓库/Commit至本地仓库的回退处理_git推送到本地仓库回退
- 3一种硬件加密卡方案_加密卡的设计
- 4技术 | Trias-odoo产品价值与开发进度_odoo为什么没人用
- 5非互联网人士如何转行互联网?_怎么样参加互联网
- 6跨境电商谋定重整新业态-李玉庭:数据驱动中国电商大会_阿里游忠明
- 7信道均衡-ZF迫零均衡matlab实现_设计一个三径信道,选择合适的参数模拟多径干扰,通过迫零(zf)方法实现时域均衡,画
- 8Python玩转PDF:几招搞定的高效操作方法_python pdf
- 9OpenCV的安装与配置_pip opencv
- 10python字符串驻留机制_Python驻留机制
MATLAB用改进K-Means(K-均值)聚类算法数据挖掘高校学生的期末考试成绩
赞
踩
全文链接:http://tecdat.cn/?p=30832
本文首先阐明了聚类算法的基本概念,介绍了几种比较典型的聚类算法,然后重点阐述了K-均值算法的基本思想,对K-均值算法的优缺点做了分析,回顾了对K-均值改进方法的文献,最后在Matlab中应用了改进的K-均值算法对数据进行了分析(点击文末“阅读原文”获取完整代码数据)。
常用的聚类算法
常用的聚类算法有:K-MEANS、K-MEDOIDS、BIRCH、CURE、DBSCAN、STING。
相关视频
主要聚类算法分类
| 类别 | 包括的主要算法 |
|---|---|
| 划分的方法 | K-MEANS算法(K平均)、K-MEDOIDS算法(K中心点)、CLARANS算法(基于选择的算法) |
| 层次的方法 | BIRCH算法(平衡迭代规约和聚类)、CURE算法(代表点聚类)、CHAMELEON算法(动态模型) |
| 基于密度的方法 | DBSCAN算法(基于高密度连接区域)、DENCLUE算法(密度分布函数)、OPTICS算法(对象排序识别) |
| 基于网络的方法 | STING算法(统计信息网络)、CLIQUE算法(聚类高维空间)、WAVE-CLUSTER算法(小波变换) |
| 基于模型的方法 | 统计学方法、神经网络方法 |
聚类算法的性能比较
| 聚类算法 | 适合数据类型 | 算法效率 | 发现的聚类形状 | 能否处理大数据集 | 是否受初始聚类中心影响 | 对异常数据敏感性 | 对输入数据顺序敏感性 |
|---|---|---|---|---|---|---|---|
| K-MEANS | 数值型 | 较高 | 凸形或球形 | 能 | 是 | 非常敏感 | 不敏感 |
| K-MEDOIDS | 数值型 | 一般 | 凸形或球形 | 否 | 否 | 不敏感 | 不敏感 |
| BIRCH | 数值型 | 高 | 凸形或球形 | 能 | 否 | 不敏感 | 不太敏感 |
| CURE | 数值型 | 较高 | 任意形状 | 能 | 否 | 不敏感 | 不太敏感 |
| DBSCAN | 数值型 | 一般 | 任意形状 | 能 | 是 | 敏感 | 敏感 |
| STING | 数值型 | 高 | 任意形状 | 能 | 否 | 一般 | 不敏感 |
由表可得到以下结论:1)大部分常用聚类算法只适合处理数值型数据;2)若考虑算法效率、初始聚类中心影响性和对异常数据敏感性,其中BIRCH算法、CURE算法以及STING算法能得到较好的结果;3)CURE算法、DBSCAN算法以及STING算法能发现任意形状的聚类。
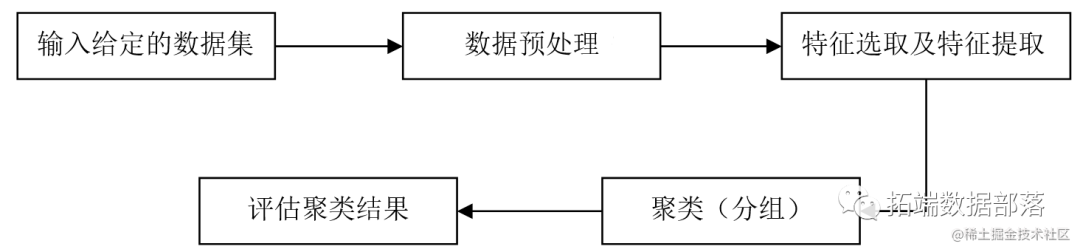
改进聚类的主要步骤
聚类的主要步骤由以下几个方面组成:
(1)数据预处理:根据聚类分析的要求,对输入数据集进行特征标准化及降维等操作。
(2)特征选择及特征提取:将由数据预处理过程得到的最初始的特征中的最有效的特征选择出来,并将选取出来的最有效特征存放于特定的向量中,然后对这些有效特征进行相应的转换,得到新的有效突出特征。
(3)聚类(分组):根据需要选择合适的相似性度量函数对数据集中的数据对象相似程度进行度量,以此进行数据对象的聚类(分组)。
(4)对聚类结果进行评估:依据特定的评价标准对聚类的结果进行有效评估,评估聚类结果的优劣,以此对聚类分析过程进行进一步的改进和完善。
聚类的主要步骤可以用图来表示。
点击标题查阅往期内容

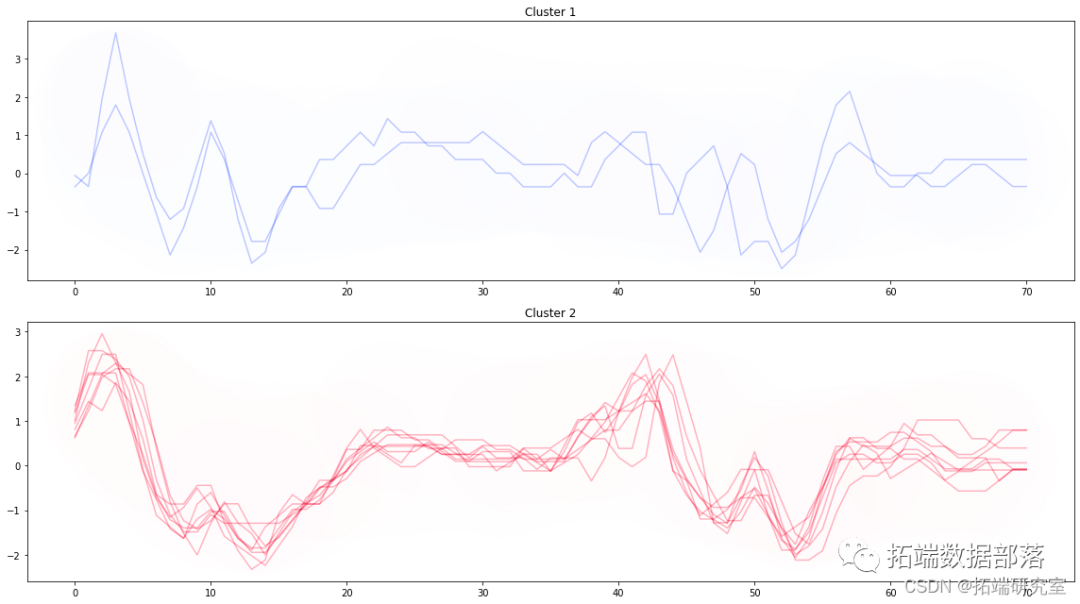
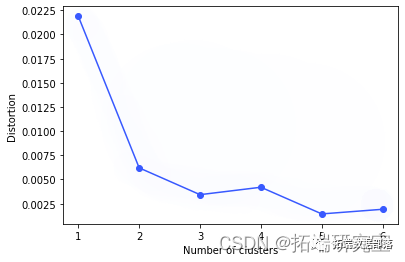
Python用KShape对时间序列进行聚类和肘方法确定最优聚类数k可视化

左右滑动查看更多
01
02

03
04

改进聚类分析中的数据类型及聚类准则函数
聚类算法的数据结构:数据矩阵、相异度矩阵。
相异度矩阵:相异度矩阵用来存储的是实体之间的差异性,n个实体的相异度矩阵表示为 n×n维的矩阵,用d(A,B)来表示实体A与实体B的相异性,一般来讲,是一种量化的表示方式,则含有n个实体的集合X={x1,x2,…,xn}的相异度矩阵表示如下:
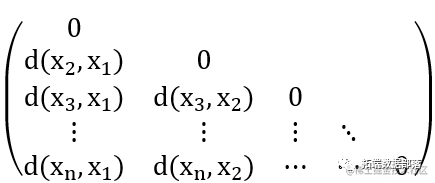
d(i,j)表示对象i和j之间的相异性的量化表示,通常它是一个非负的数值,当对象i和j 越相似或接近,其值越接近0;两个对象越不同,其值越大。并且有d(i,j)=d(j,i),d(i,i)=0。目前最常用的的相似性度量函数为欧式距离。
在MATLAB中应用K-MEANS算法
数据的预处理
本研究的数据是某高校学生的期末考试成绩,成绩表包括以下字段:x1为“电子商务”科目成绩,x2为“C语言概论”科目基础知识。其中,数据已经经过标准化和中心化的预处理:
(1)补充缺失值。对退学、转学、休学、缺考造成的数据缺失采用平均值法,以该科目的平均分数填充。
(2)规范化数据。运用最小-最大规范化方法对数据进行规范化处理,将数据映射到[0,1]区间,计算公式如下:
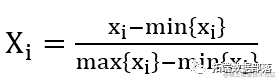
过程及结果分析
(1)读取数据
选择MATLAB的Data.mat,通过ImpoMatlabt Files,将所有数据读入。
- load('data1.mat')
- k = 6;
- figure;
- %数据标准化
- data = zeros(size(data1));
- [data(:,1) me(1) va(1)] = dataNormalization(data1(:,1))
(2)K-Means 模型设置
1)NumbeRs of clusteR:制定生成的聚类数目,这里设置为3.
2)定义了分割数据集,选择训练数据集作为建模数据集,并利用测试数据集对模型进行评价。
- [idx c] = kmeansOfMy(data,k);
- c = dataRecovery(c,me,va);
- %画出各个区域中的散点
- count = 0;
- for i = 1 : k
- if i == 1
- plot(data1(idx == i,1),data1(idx == 1,2),'r*');
- elseif i == 2
- plot(data1(idx == i,1),data1(idx == i,2),'g*');
- elseif i == 3
(3)执行和输出
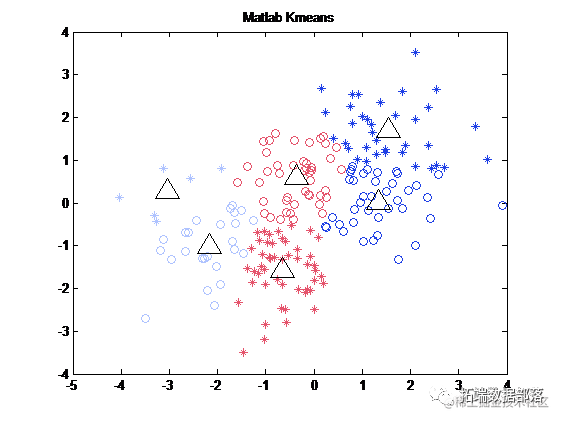
设置完成后,选中Execute 按钮,即可得到改进聚类执行并观察到结果。
- %kOfVertex = randKOfVertex(k);
- kOfVertex = electedInitialCentroid(k);
- for i = 1 : size(data,1)
- index(i) = minOfDistans(i,kOfVertex);
可以以图表的形式来显示模型的统计信息以及各个属性在各簇中的分布信息,结果如下图所示。
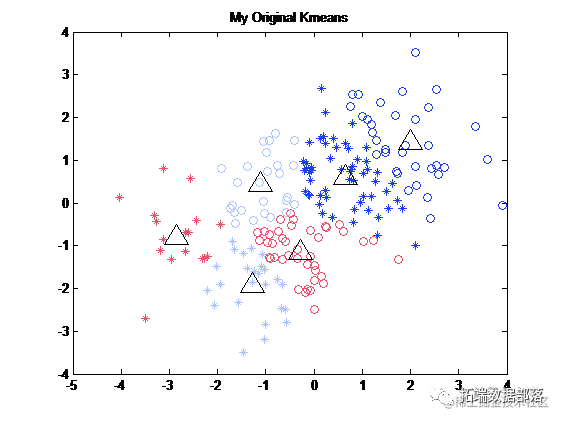
(4)聚类结果
结果表明:簇1中的学生都是考试成绩中等的,簇2中的学生考试成绩较高,簇2中的学生考试成绩较差,可见,大部分学生的期末考试成绩处于中等水平;各变量在各簇中的显著程度均较大,表明学生对各科目的学习分化程度较高,差异显著。
参考文献
[1] 贺玲, 吴玲达, 蔡益朝. 数据挖掘中的聚类算法综述[J]. 计算机应用研究, 2007(1).
[2] 蒋帅. K-均值聚类算法研究[D]. 陕西师范大学, 2010.
[3] 周涓, 熊忠阳, 张玉芳, 等. 基于最大最小距离法的多中心聚类算法[J]. 计算机应用, 2006, 26(6).
[4] A.K.Jain, MATLAB.C.Dubes. AlgoMatlabithms foMatlab ClusteMatlabing Data [J]. PMatlabentice-Hall Advanced MATLABefeMatlabence SeMatlabies, 1988(1).

本文中分析的数据分享到会员群,扫描下面二维码即可加群!


点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《MATLAB数据挖掘用改进的K-Means(K-均值)聚类算法分析高校学生的期末考试成绩数据》。
点击标题查阅往期内容
R语言主成分PCA、因子分析、聚类对地区经济研究分析重庆市经济指标
数据分享|R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
R语言逻辑回归logistic模型分析泰坦尼克titanic数据集预测生还情况
R语言用lme4多层次(混合效应)广义线性模型(GLM),逻辑回归分析教育留级调查数据
R语言随机森林RandomForest、逻辑回归Logisitc预测心脏病数据和可视化分析
R语言基于Bagging分类的逻辑回归(Logistic Regression)、决策树、森林分析心脏病患者
R语言逻辑回归(Logistic回归)模型分类预测病人冠心病风险
R语言用局部加权回归(Lowess)对logistic逻辑回归诊断和残差分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
R语言用线性模型进行臭氧预测:加权泊松回归,普通最小二乘,加权负二项式模型,多重插补缺失值
R语言Bootstrap的岭回归和自适应LASSO回归可视化
R语言多元时间序列滚动预测:ARIMA、回归、ARIMAX模型分析
R语言用lme4多层次(混合效应)广义线性模型(GLM),逻辑回归分析教育留级调查数据
R语言混合效应逻辑回归(mixed effects logistic)模型分析肺癌数据
R语言建立和可视化混合效应模型mixed effect model
R语言用Rshiny探索lme4广义线性混合模型(GLMM)和线性混合模型(LMM)
R语言如何解决线性混合模型中畸形拟合(Singular fit)的问题
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
R语言用WinBUGS 软件对学术能力测验(SAT)建立分层模型
使用SAS,Stata,HLM,R,SPSS和Mplus的分层线性模型HLM
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
SPSS中的多层(等级)线性模型Multilevel linear models研究整容手术数据
R语言高维数据的主成分pca、 t-SNE算法降维与可视化分析案例报告
R语言惩罚logistic逻辑回归(LASSO,岭回归)高维变量选择的分类模型案例
R语言使用Metropolis- Hasting抽样算法进行逻辑回归
R语言自适应LASSO 多项式回归、二元逻辑回归和岭回归应用分析
R语言基于树的方法:决策树,随机森林,Bagging,增强树
python在Scikit-learn中用决策树和随机森林预测NBA获胜者
R语言惩罚logistic逻辑回归(LASSO,岭回归)高维变量选择的分类模型案例
R语言用标准最小二乘OLS,广义相加模型GAM ,样条函数进行逻辑回归LOGISTIC分

![]()



