
热门标签
热门文章
- 1python爬虫模拟浏览器_python爬虫利器 pyppeteer(模拟浏览器) 实战
- 2Spring SpringBoot 拦截器配置_springboot 配置拦截器
- 3HVV蓝队扫盲,关于HVV你不知道的全在这·HVV专题_hvv 防护技战术
- 4注解与反射
- 5MongoDB和MySQL性能测试及其结果分析
- 6md5.js
- 7Net6 用imagesharp 实现跨平台图片处理并存入oss_zxing imagesharp
- 8Linux CentOS7 深度学习环境 安装 CUDA Cudnn 验证安装成功 3080Ti 显卡 pytorch验证_centos验证cudnn是否安装成功
- 9论文阅读——ELECTRA
- 10ICML/ICLR‘22 推荐系统论文梳理_iclr2022录用论文
当前位置: article > 正文
python机器学习课程笔记_遍历ndarray的每一行
作者:小丑西瓜9 | 2024-06-15 11:21:48
赞
踩
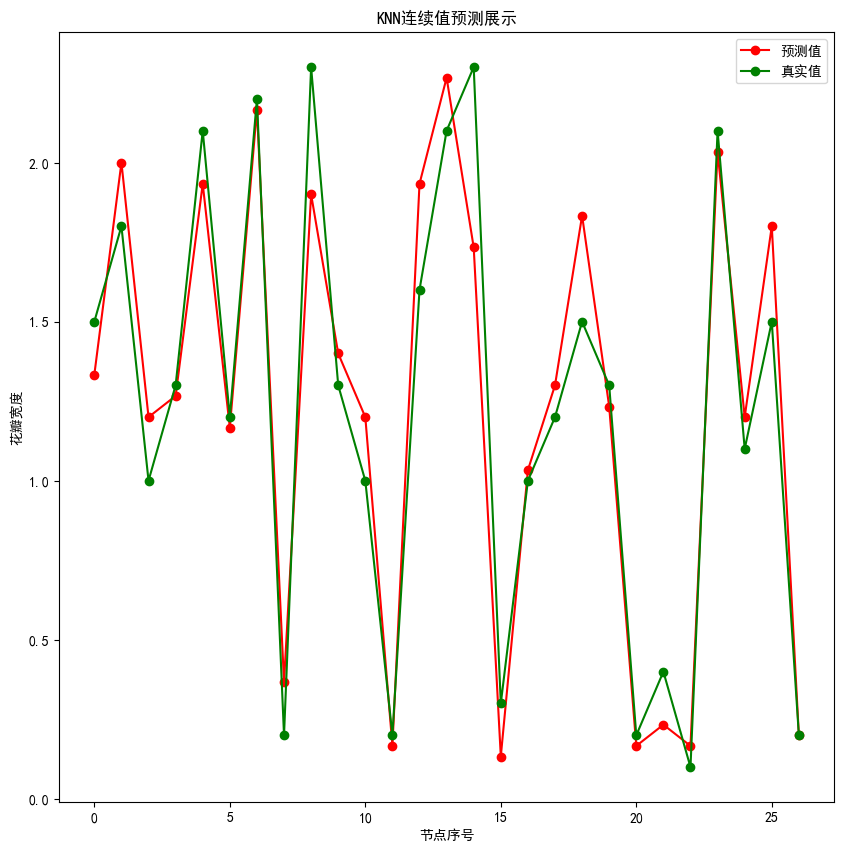
遍历ndarray的每一行
【KNN回归】
学习课程:B站【超实用】Python实现机器学习算法(全) BV1V7411P7wL
数据集:鸢尾花数据集(Iris.csv)
- import numpy as np
- import pandas as pd
- # 读取鸢尾花数据集,header参数来指定标题的行,默认为0,如果没有标题,则使用None
- data=pd.read_csv(r"C:/Users/DELL/Desktop/Iris.csv")
- # 使用花萼长度、花萼宽度、花瓣长度来预测花瓣宽度
- # 删除不需要的species列(特征),按列删除
- data.drop(["species"],axis=1,inplace=True)
- # 删除重复记录
- data.drop_duplicates(inplace=True)

- # 测试与训练
- t=data.sample(len(data),random_state=0)
- train_X=t.iloc[:120,:-1]
- train_y=t.iloc[:120,-1]
- test_X=t.iloc[120:,:-1]
- test_y=t.iloc[120:,-1]
- knn=KNN(k=3)
- knn.fit(train_X,train_y)
- result=knn.predict(test_X)
- display(result)
- display(np.mean((result-test_y)**2))
- display(test_y.values)
- # 考虑权重的结果
- result2=knn.predict2(test_X)
- display(np.mean((result2-test_y)**2))
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/722107
推荐阅读

相关标签

