
- 1学生成绩等级预测数据集_学生成绩数据集
- 2使用 Jeecg-Boot Vue2 实现积木报表套打自定义纸张_比较好用的vue可调用的类似积木报表的打印
- 3IKEv1密钥交换和协商
- 4院士交锋,专家论道|NLP大模型技术与应用十大挑战,剑指AI未来_黄松芳 大模型
- 5使用libssh2建立安全的SSH连接:C++开发者的综合指南
- 6关于FPGA对 DDR4 (MT40A256M16)的读写控制 3_fpga挂在二十多片ddr4
- 7由于游戏商城的代码可能相当复杂,包括前端和后端部分,以及数据库交互等,下面我将为你提供简化版本的伪代码和示例代码片段,用几种常见的编程语言表示。_funcode代码购买
- 8远程连接工具WinSCP使用详解
- 92023年,自动化测试会取代手工测试吗?
- 10langflow agent 资料_langflow官方文档
nginx多个server_Nginx教程:概念+安装+SSL安装,通过调优Nginx来提高应用性能
赞
踩
前言
大家好!分享即关怀,我们很乐意与你分享其他的一些知识。我们准备了一个 Nginx 指南,分为三个系列。如果你已经知道一些 Nginx 知识或者想扩展你的经验和认知,这个再合适不过了。
我们将告诉你 Nginx 的运作模式、蕴含的概念,怎样通过调优 Nginx 来提高应用性能,或是如何设置它的启动和运行。
这个教程有三个部分:
- 基本概念 —— 这部分需要去了解 Nginx 的一些指令和使用场景,继承模型,以及 Nginx 如何选择 server 块,location 的顺序。
- 性能 —— 介绍改善 Nginx 速度的方法和技巧,我们会在这里谈及 gzip 压缩,缓存,buffer 和超时。
- SSL 安装 —— 如何配置服务器使用 HTTPS
创建这个系列,我们希望,一是作为参考书,可以通过快速查找到相关问题(比如 gzip 压缩,SSL 等)的解决方式,也可以直接通读全文。为了获得更好的学习效果,我们建议你在本机安装 Nginx 并且尝试进行实践。
Nginx基本概念
什么是 Nginx?
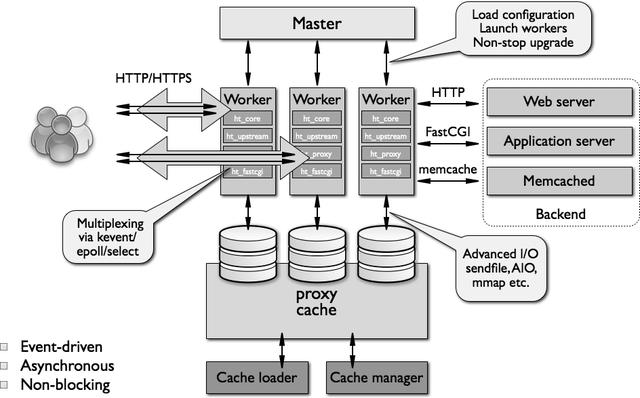
Nginx 最初是作为一个 Web 服务器创建的,用于解决 C10k 的问题。作为一个 Web 服务器,它可以以惊人的速度为您的数据服务。但 Nginx 不仅仅是一个 Web 服务器,你还可以将其用作反向代理,与较慢的上游服务器(如:Unicorn 或 Puma)轻松集成。你可以适当地分配流量(负载均衡器)、流媒体、动态调整图像大小、缓存内容等等。
基本的 nginx 体系结构由 master 进程和其 worker 进程组成。master 读取配置文件,并维护 worker 进程,而 worker 则会对请求进行实际处理。
基本命令
要启动 nginx,只需输入:
[sudo] nginx
当你的 nginx 实例运行时,你可以通过发送相应的信号来管理它:
[sudo] nginx -s signal
可用的信号:
- stop – 快速关闭
- quit – 优雅关闭 (等待 worker 线程完成处理)
- reload – 重载配置文件
- reopen – 重新打开日志文件
指令和上下文
nginx 的配置文件,默认的位置包括:
- /etc/nginx/nginx.conf,
- /usr/local/etc/nginx/nginx.conf,或
- /usr/local/nginx/conf/nginx.conf
配置文件的由下面的部分构成:
指令 – 可选项,包含名称和参数,以分号结尾
gzip on;
上下文 – 分块,你可以声明指令 – 类似于编程语言中的作用域
worker_processes 2; # 全局上下文指令
http { # http 上下文
gzip on; # http 上下文中的指令
server { # server 上下文
listen 80; # server 上下文中的指令
}
}
指令类型
在多个上下文中使用相同的指令时,必须要小心,因为继承模型不同时有着不同的指令。有三种类型的指令,每种都有自己的继承模型。
普通指令
在每个上下文仅有唯一值。而且,它只能在当前上下文中定义一次。子级上下文可以覆盖父级中的值,并且这个覆盖值只在当前的子级上下文中有效。
gzip on;
gzip off; # 非法,不能在同一个上下文中指定同一普通指令2次
server {
location /downloads {
gzip off;
}
location /assets {
# gzip is on here
}
}
数组指令
在同一上下文中添加多条指令,将添加多个值,而不是完全覆盖。在子级上下文中定义指令将覆盖给父级上下文中的值。
error_log /var/log/nginx/error.log;
error_log /var/log/nginx/error_notive.log notice;
error_log /var/log/nginx/error_debug.log debug;
server {
location /downloads {
# 下面的配置会覆盖父级上下文中的指令
error_log /var/log/nginx/error_downloads.log;
}
}
行动指令
行动是改变事情的指令。根据模块的需要,它继承的行为可能会有所不同。
例如 rewrite 指令,只要是匹配的都会执行:
server {
rewrite ^ /foobar;
location /foobar {
rewrite ^ /foo;
rewrite ^ /bar;
}
}
如果用户想尝试获取 /sample:
- server的rewrite将会执行,从 /sample rewrite 到 /foobar
- location /foobar 会被匹配
- location的第一个rewrite执行,从/foobar rewrite到/foo
- location的第二个rewrite执行,从/foo rewrite到/bar
return 指令提供的是不同的行为:
server {
location / {
return 200;
return 404;
}
}
在上述的情况下,立即返回200。
处理请求
在 Nginx 内部,你可以指定多个虚拟服务器,每个虚拟服务器用 server{} 上下文描述。
server {
listen *:80 default_server;
server_name netguru.co;
return 200 "Hello from netguru.co";
}
server {
listen *:80;
server_name foo.co;
return 200 "Hello from foo.co";
}
server {
listen *:81;
server_name bar.co;
return 200 "Hello from bar.co";
}
这将告诉 Nginx 如何处理到来的请求。Nginx 将会首先通过检查 listen 指令来测试哪一个虚拟主机在监听给定的 IP 端口组合。
然后,server_name 指令的值将检测 Host 头(存储着主机域名)。
Nginx 将会按照下列顺序选择虚拟主机:
- 匹配sever_name指令的IP-端口主机
- 拥有default_server标记的IP-端口主机
- 首先定义的IP-端口主机
- 如果没有匹配,拒绝连接。
例如下面的例子:
Request to foo.co:80 => "Hello from foo.co"
Request to www.foo.co:80 => "Hello from netguru.co"
Request to bar.co:80 => "Hello from netguru.co"
Request to bar.co:81 => "Hello from bar.co"
Request to foo.co:81 => "Hello from bar.co"
server_name 指令
server_name指令接受多个值。它还处理通配符匹配和正则表达式。
server_name netguru.co www.netguru.co; # exact match
server_name *.netguru.co; # wildcard matching
server_name netguru.*; # wildcard matching
server_name ~^[0-9]*.netguru.co$; # regexp matching
当有歧义时,nginx 将使用下面的命令:
- 确切的名字
- 最长的通配符名称以星号开始,例如“* .example.org”。
- 最长的通配符名称以星号结尾,例如“mail.**”
- 首先匹配正则表达式(按照配置文件中的顺序)
Nginx 会存储 3 个哈希表:确切的名字,以星号开始的通配符,和以星号结尾的通配符。如果结果不在任何表中,则将按顺序进行正则表达式测试。
值得谨记的是
server_name .netguru.co;
是一个来自下面的缩写
server_name netguru.co www.netguru.co *.netguru.co;
有一点不同,.netguru.co 存储在第二张表,这意味着它比显式声明的慢一点。
listen 指令
在很多情况下,能够找到 listen 指令,接受IP:端口值
listen 127.0.0.1:80;
listen 127.0.0.1; # by default port :80 is used
listen *:81;
listen 81; # by default all ips are used
listen [::]:80; # IPv6 addresses
listen [::1]; # IPv6 addresses
然而,还可以指定 UNIX-domain 套接字。
listen unix:/var/run/nginx.sock;
你甚至可以使用主机名
listen localhost:80;
listen netguru.co:80;
但请慎用,由于主机可能无法启动 nginx,导致无法绑定在特定的 TCP Socket。
最后,如果指令不存在,则使用 *:80。
最小化配置
有了这些知识 – 我们应该能够创建并理解运行 nginx 所需的最低配置。
# /etc/nginx/nginx.conf
events {} # events context needs to be defined to consider config valid
http {
server {
listen 80;
server_name netguru.co www.netguru.co *.netguru.co;
return 200 "Hello";
}
}
root, location, 和 try_files 指令
root 指令
root 指令设置请求的根目录,允许 nginx 将传入请求映射到文件系统。
server {
listen 80;
server_name netguru.co;
root /var/www/netguru.co;
}
根据给定的请求,指定 nginx 服务器允许的内容
netguru.co:80/index.html # returns /var/www/netguru.co/index.html
netguru.co:80/foo/index.html # returns /var/www/netguru.co/foo/index.html
location 指令
location指令根据请求的 URI 来设置配置。
location [modifier] path
location /foo/ {
# ...
}
如果没有指定修饰符,则路径被视为前缀,其后可以跟随任何东西。
以上例子将匹配
/foo
/fooo
/foo123
/foo/bar/index.html
...
此外,在给定的上下文中可以使用多个 location 指令。
server {
listen 80;
server_name netguru.co;
root /var/www/netguru.co;
location / {
return 200 "root";
}
location /foo/ {
return 200 "foo";
}
}
netguru.co:80 / # => "root"
netguru.co:80 /foo # => "foo"
netguru.co:80 /foo123 # => "foo"
netguru.co:80 /bar # => "root"
Nginx 也提供了一些修饰符,可用于连接 location。这些修饰符将影响 location 模块使用的地方,因为每个修饰符都分配了优先级。
= - Exact match
^~ - Preferential match
~ && ~* - Regex match
no modifier - Prefix match
Nginx 会先检查精确匹配。如果找不到,我们会找优先级最高的。如果这个匹配依然失败,正则表达式匹配将按照出现的顺序进行测试。至少,最后一个前缀匹配将被使用。
location /match {
return 200 'Prefix match: matches everything that starting with /match';
}
location ~* /match[0-9] {
return 200 'Case insensitive regex match';
}
location ~ /MATCH[0-9] {
return 200 'Case sensitive regex match';
}
location ^~ /match0 {
return 200 'Preferential match';
}
location = /match {
return 200 'Exact match';
}
/match/ # => 'Exact match'
/match0 # => 'Preferential match'
/match1 # => 'Case insensitive regex match'
/MATCH1 # => 'Case sensitive regex match'
/match-abc # => 'Prefix match: matches everything that starting with /match'
try_files 指令
尝试不同的路径,找到一个路径就返回。
try_files $uri index.html =404;
所以对于 /foo.html 请求,它将尝试按以下顺序返回文件:
- $uri ( /foo.html )
- index.html
- 如果什么都没找到则返回 404
有趣的是,如果我们在服务器上下文中定义 try_files,然后定义匹配的所有请求的 location —— try_files 将不会执行。
这是因为在服务器上下文中定义的 try_files 是它的 pseudo-location,这是最不可能的位置。因此,定义 location/ 将比 pseudo-location 更具体。
server {
try_files $uri /index.html =404;
location / {
}
}
因此,你应该避免在 server 上下文中出现 try_files:
server {
location / {
try_files $uri /index.html =404;
}
}
tcp_nodelay, tcp_nopush 和 sendfile
tcp_nodelay
在 TCP 发展早期,工程师需要面对流量冲突和堵塞的问题,其中涌现了大批的解决方案,其中之一是由 John Nagle 提出的算法。
Nagle 的算法旨在防止通讯被大量的小包淹没。该理论不涉及全尺寸 tcp 包(最大报文长度,简称 MSS)的处理。只针对比 MSS 小的包,只有当接收方成功地将以前的包(ACK)的所有确认发送回来时,这些包才会被发送。在等待期间,发送方可以缓冲更多的数据之后再发送。
if package.size >= MSS.size
send(package)
elsif acks.all_received?
send(package)
else
# acumulate data
end
与此同时,诞生了另一个理论,延时 ACK
在 TCP 通讯中,在发送数据后,需要接收回应包(ACK)来确认数据被成功传达。
延时 ACK 旨在解决线路被大量的 ACK 包拥堵的状况。为了减少 ACK 包的数量,接收者等待需要回传的数据加上 ACK 包回传给发送方,如果没有数据需要回传,必须在至少每 2 个 MSS,或每 200 至 500 毫秒内发送 ACK(以防我们不再收到包)。
if packages.any?
send
elsif last_ack_send_more_than_2MSS_ago? || 200_ms_timer.finished?
send
else
# wait
end
正如你可能在一开始就注意到的那样 —— 这可能会导致在持久连接上的一些暂时的死锁。让我们重现它!
假设:
- 初始拥塞窗口等于 2。拥塞窗口是另一个 TCP 机制的一部分,称为慢启动。细节现在并不重要,只要记住它限制了一次可以发送多少个包。在第一次往返中,我们可以发送 2 个 MSS 包。在第二次发送中:4 个 MSS 包,第三次发送中:8 个MSS,依此类推。
- 4 个已缓存的等待发送的数据包:A, B, C, D
- A, B, C是 MSS 包
- D 是一个小包
场景:
- 由于是初始的拥塞窗口,发送端被允许传送两个包:A 和 B
- 接收端在成功获得这两个包之后,发送一个 ACK
- 发件端发送 C 包。然而,Nagle 却阻止它发送 D 包(包长度太小,等待 C 的ACK)
- 在接收端,延迟 ACK 使他无法发送 ACK(每隔 2 个包或每隔 200 毫秒发送一次)
- 在 200ms 之后,接收器发送 C 包的 ACK
- 发送端收到 ACK 并发送 D 包
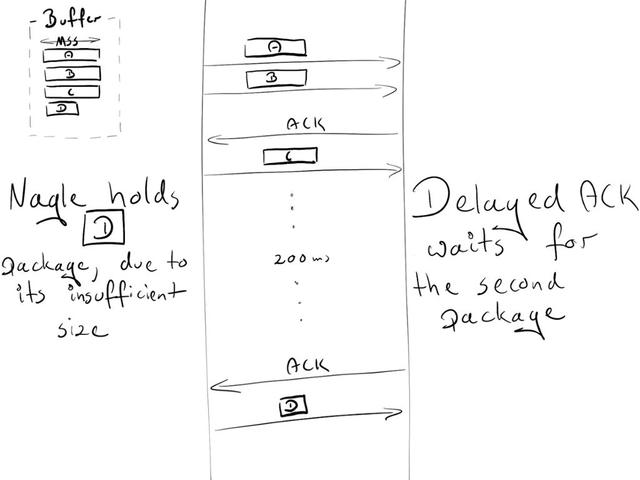
在这个数据交换过程中,由于 Nagel 和延迟 ACK 之间的死锁,引入了 200ms 的延迟。
Nagle 算法是当时真正的救世主,而且目前仍然具有极大的价值。但在大多数情况下,我们不会在我们的网站上使用它,因此可以通过添加 TCP_NODELAY 标志来安全地关闭它。
tcp_nodelay on; # sets TCP_NODELAY flag, used on keep-alive connections
享受这200ms提速吧!
sendfile
正常来说,当要发送一个文件时需要下面的步骤:
- malloc(3) – 分配一个本地缓冲区,储存对象数据。
- read(2) – 检索和复制对象到本地缓冲区。
- write(2) – 从本地缓冲区复制对象到 socket 缓冲区。
这涉及到两个上下文切换(读,写),并使相同对象的第二个副本成为不必要的。正如你所看到的,这不是最佳的方式。值得庆幸的是还有另一个系统调用,提升了发送文件(的效率),它被称为:sendfile(2)(想不到吧!居然是这名字)。这个调用在文件 cache 中检索一个对象,并传递指针(不需要复制整个对象),直接传递到 socket 描述符,Netflix 表示,使用 sendfile(2) 将网络吞吐量从 6Gbps 提高到了 30Gbps。
然而,sendfile(2) 有一些注意事项:
- 不可用于 UNIX sockets(例如:当通过你的上游服务器发送静态文件时)
- 能否执行不同的操作,取决于操作系统
在 nginx 中打开它
sendfile on;
tcp_nopush
tcp_nopush 与 tcp_nodelay 相反。不是为了尽可能快地推送数据包,它的目标是一次性优化数据的发送量。
在发送给客户端之前,它将强制等待包达到最大长度(MSS)。而且这个指令只有在 sendfile 开启时才起作用。
sendfile on;
tcp_nopush on;
看起来 tcp_nopush 和 tcp_nodelay 是互斥的。但是,如果所有 3 个指令都开启了,nginx 会:
- 确保数据包在发送给客户之前是已满的
- 对于最后一个数据包,tcp_nopush 将被删除 —— 允许 TCP 立即发送,没有 200ms 的延迟
我应该使用多少进程?
工作进程
worker_process 指令会指定:应该运行多少个 worker。默认情况下,此值设置为 1。最安全的设置是通过传递 auto 选项来使用核心数量。
但由于 Nginx 的架构,其处理请求的速度非常快 – 我们可能一次不会使用超过 2-4 个进程(除非你正在托管 Facebook 或在 nginx 内部执行一些 CPU 密集型的任务)。
worker_process auto;
worker 连接
与 worker_process 直接绑定的指令是 worker_connections。它指定一个工作进程可以一次打开多少个连接。这个数目包括所有连接(例如与代理服务器的连接),而不仅仅是与客户端的连接。此外,值得记住的是,一个客户端可以打开多个连接,同时获取其他资源。
worker_connections 1024;
打开文件数目限制
在基于 Unix 系统中的“一切都是文件”。这意味着文档、目录、管道甚至套接字都是文件。系统对一个进程可以打开多少文件有一个限制。要查看该限制:
ulimit -Sn # soft limit
ulimit -Hn # hard limit
这个系统限制必须根据 worker_connections 进行调整。任何传入的连接都会打开至少一个文件(通常是两个连接套接字以及后端连接套接字或磁盘上的静态文件)。所以这个值等于 worker_connections*2 是安全的。幸运的是,Nginx 提供了一个配置选项来增加这个系统的值。要使用这个配置,请添加具有适当数目的 worker_rlimit_nofile 指令并重新加载 nginx。
worker_rlimit_nofile 2048;
配置
worker_process auto;
worker_rlimit_nofile 2048; # Changes the limit on the maximum number of open files (RLIMIT_NOFILE) for worker processes.
worker_connections 1024; # Sets the maximum number of simultaneous connections that can be opened by a worker process.
最大连接数
如上所述,我们可以计算一次可以处理多少个并发连接:
最大连接数 =
worker_processes * worker_connections
----------------------------------------------
(keep_alive_timeout + avg_response_time) * 2
keep_alive_timeout (后续有更多介绍) + avg_response_time 告诉我们:单个连接持续了多久。我们也除以 2,通常情况下,你将有一个客户端打开 2 个连接的情况:一个在 nginx 和客户端之间,另一个在 nginx 和上游服务器之间。
Gzip
启用 gzip 可以显著降低响应的(报文)大小,因此,客户端(网页)会显得更快些。
压缩级别
Gzip 有不同的压缩级别,1 到 9 级。递增这个级别将会减少文件的大小,但也会增加资源消耗。作为标准我们将这个数字(级别)保持在 3 – 5 级,就像上面说的那样,它将会得到较小的节省,同时也会得到更大的 CPU 使用率。
这有个通过 gzip 的不同的压缩级别压缩文件的例子,0 代表未压缩文件。
curl -I -H 'Accept-Encoding: gzip,deflate' https://netguru.co/
❯ du -sh ./*
64K ./0_gzip
16K ./1_gzip
12K ./2_gzip
12K ./3_gzip
12K ./4_gzip
12K ./5_gzip
12K ./6_gzip
12K ./7_gzip
12K ./8_gzip
12K ./9_gzip
❯ ls -al
-rw-r--r-- 1 matDobek staff 61711 3 Nov 08:46 0_gzip
-rw-r--r-- 1 matDobek staff 12331 3 Nov 08:48 1_gzip
-rw-r--r-- 1 matDobek staff 12123 3 Nov 08:48 2_gzip
-rw-r--r-- 1 matDobek staff 12003 3 Nov 08:48 3_gzip
-rw-r--r-- 1 matDobek staff 11264 3 Nov 08:49 4_gzip
-rw-r--r-- 1 matDobek staff 11111 3 Nov 08:50 5_gzip
-rw-r--r-- 1 matDobek staff 11097 3 Nov 08:50 6_gzip
-rw-r--r-- 1 matDobek staff 11080 3 Nov 08:50 7_gzip
-rw-r--r-- 1 matDobek staff 11071 3 Nov 08:51 8_gzip
-rw-r--r-- 1 matDobek staff 11005 3 Nov 08:51 9_gzip
gzip_http_version 1.1;
这条指令告诉 nginx 仅在 HTTP 1.1 以上的版本才能使用 gzip。我们在这里不涉及 HTTP 1.0,至于 HTTP 1.0 版本,它是不可能既使用 keep-alive 和 gzip 的。因此你必须做出决定:使用 HTTP 1.0 的客户端要么错过 gzip,要么错过 keep-alive。
配置
gzip on; # enable gzip
gzip_http_version 1.1; # turn on gzip for http 1.1 and above
gzip_disable "msie6"; # IE 6 had issues with gzip
gzip_comp_level 5; # inc compresion level, and CPU usage
gzip_min_length 100; # minimal weight to gzip file
gzip_proxied any; # enable gzip for proxied requests (e.g. CDN)
gzip_buffers 16 8k; # compression buffers (if we exceed this value, disk will be used instead of RAM)
gzip_vary on; # add header Vary Accept-Encoding (more on that in Caching section)
# define files which should be compressed
gzip_types text/plain;
gzip_types text/css;
gzip_types application/javascript;
gzip_types application/json;
gzip_types application/vnd.ms-fontobject;
gzip_types application/x-font-ttf;
gzip_types font/opentype;
gzip_types image/svg+xml;
gzip_types image/x-icon;
缓存
缓存是另一回事,它能提升用户的请求速度。
管理缓存可以仅由 2 个 header 控制:
- 在 HTTP/1.1 中用 Cache-Control 管理缓存
- Pragma 对于 HTTP/1.0 客户端的向后兼容性
缓存本身可以分为两类:公共缓存和私有缓存。公共缓存是被多个用户共同使用的。专用缓存专用于单个用户。我们可以很容易地区分,应该使用哪种缓存:
add_header Cache-Control public;
add_header Pragma public;
对于标准资源,我们想保存1个月:
location ~* .(jpg|jpeg|png|gif|ico|css|js)$ {
expires 1M;
add_header Cache-Control public;
add_header Pragma public;
}
上面的配置似乎足够了。然而,使用公共缓存时有一个注意事项。
让我们看看如果将我们的资源存储在公共缓存(如 CDN)中,URI 将是唯一的标识符。在这种情况下,我们认为 gzip 是开启的。
有2个浏览器:
- 旧的,不支持 gzip
- 新的,支持 gzip
旧的浏览器给 CDN 发送了一个 netguru.co/style 请求。但是 CDN 也没有这个资源,它将会给我们的服务器发送请求,并且返回未经压缩的响应。CDN 在哈希里存储文件(为以后使用):
{
...
netguru.co/styles.css => FILE("/sites/netguru/style.css")
...
}
然后将其返回给客户端。
现在,新的浏览器发送相同的请求到 CDN,请求 netguru.co/style.css,获取 gzip 打包的资源。由于 CDN 仅通过 URI 标识资源,它将为新浏览器返回一样的未压缩资源。新的浏览器将尝试提取未打包的文件,但是将获得无用的东西。
如果我们能够告诉公共缓存是怎样进行 URI 和编码的资源识别,我们就可以避免这个问题。
{
...
(netguru.co/styles.css, gzip) => FILE("/sites/netguru/style.css.gzip")
(netguru.co/styles.css, text/css) => FILE("/sites/netguru/style.css")
...
}
这正是 Vary Accept-Encoding: 完成的。它告诉公共缓存,可以通过 URI 和 Accept-Encoding header 区分资源。
所以我们的最终配置如下:
location ~* .(jpg|jpeg|png|gif|ico|css|js)$ {
expires 1M;
add_header Cache-Control public;
add_header Pragma public;
add_header Vary Accept-Encoding;
}
超时
client_body_timeout 和 client_header_timeout 定义了 nginx 在抛出 408(请求超时)错误之前应该等待客户端传输主体或头信息的时间。
send_timeout 设置向客户端发送响应的超时时间。超时仅在两次连续的写入操作之间被设置,而不是用于整个响应的传输过程。如果客户端在给定时间内没有收到任何内容,则连接将被关闭。
设置这些值时要小心,因为等待时间过长会使你容易受到攻击者的攻击,并且等待时间太短的话会切断与速度较慢的客户端的连接。
# Configure timeouts
client_body_timeout 12;
client_header_timeout 12;
send_timeout 10;
Buffers
client_body_buffer_size
设置读取客户端请求正文的缓冲区大小。如果请求主体大于缓冲区,则整个主体或仅其部分被写入临时文件。对 client_body_buffer_size 而言,设置 16k 大小在大多数情况下是足够的。
这是又一个可以产生巨大影响的设置,必须谨慎使用。太小了,则 nginx 会不断地使用 I/O 把剩余的部分写入文件。太大了,则当攻击者可以打开所有连接但你无法在系统上分配足够缓冲来处理这些连接时,你可能容易受到 DOS 攻击。
client_header_buffer_size 和 large_client_header_buffers
如果 header 不能跟 client_header_buffer_size 匹配上,就会使用 large_client_header_buffers。如果请求也不适合 large_client_header_buffers,将给客户端返回一个错误提示。对于大多数的请求来说,1KB 的缓存是足够的。但是,如果一个包含大量记录的请求,1KB 是不够的。
如果请求行的长度超限,将给客户端返回一个 414(请求的 URI 太长)错误提示。如果请求的 header 长度超限,将抛出一个 400(错误请求)的错误代码
client_max_body_size
设置客户端请求主体的最大允许范围,在请求头字段中指定“内容长度”。如果您希望允许用户上传文件,调整此配置以满足您的需要。
配置
client_body_buffer_size 16K;
client_header_buffer_size 1k;
large_client_header_buffers 2 1k;
client_max_body_size 8m;
Keep-Alive
HTTP 所依赖的 TCP 协议需要执行三次握手来启动连接。这意味着在服务器可发送数据(例如图像)之前,需要在客户机和服务器之间进行三次完整的往返。
假设你从 Warsaw 请求的 /image.jpg,并连接到在柏林最近的服务器:
Open connection
TCP Handshake:
Warsaw ->------------------ synchronize packet (SYN) ----------------->- Berlin
Warsaw -
Warsaw ->------------------- acknowledgement (ACK) ------------------->- Berlin
Data transfer:
Warsaw ->---------------------- /image.jpg --------------------------->- Berlin
Warsaw -
Close connection
对于另一次请求,你将不得不再次执行整个初始化。如果你在短时间内发送多次请求,这可能会快速累积起来。这样的话 keep-alive 使用起来就方便了。在成功响应之后,它保持连接空闲给定的时间段(例如 10 秒)。如果在这段时间内有另一个请求,现有的连接将被重用,空闲时间将被刷新。
Nginx 提供了几个指令来调整 keepalive 设置。这些可以分为两类:
在客户端和 nginx 之间 keep-alive
keepalive_disable msie6; # disable selected browsers.
# The number of requests a client can make over a single keepalive connection. The default is 100, but a much higher value can be especially useful for testing with a load‑generation tool, which generally sends a large number of requests from a single client.
keepalive_requests 100000;
# How long an idle keepalive connection remains open.
keepalive_timeout 60;
在 nginx 和上游服务器之间 keep-alive
upstream backend {
# The number of idle keepalive connections to an upstream server that remain open for each worker process
keepalive 16;
}
server {
location /http/ {
proxy_pass http://http_backend;
proxy_http_version 1.1;
proxy_set_header Connection "";
}
}
SSL 和 TLS
SSL(Socket Secure Layer 缩写)是一种通过 HTTP 提供安全连接的协议。
SSL 1.0 由 Netscape 开发,但由于严重的安全漏洞从未公开发布过。SSL 2.0 于 1995 年发布,它存在一些问题,导致了最终的 SSL 3.0 在 1996 年发布。
TLS(Transport Layer Security 缩写)的第一个版本是作为 SSL 3.0 的升级版而编写的。之后 TLS 1.1 和 1.2 出来了。现在,就在不久之后,TLS 1.3 即将推出(这确实值得期待),并且已经被一些浏览器所支持。
从技术上讲,SSL 和 TLS 是不同的(因为每个协议都描述了协议的不同版本),但其中使用的许多名称是可以互换的。
基本 SSL/TLS 配置
为了处理 HTTPS 流量,你需要具有 SSL/TLS 证书。你可以通过使用 Let’s encrypt 以生成免费的证书。
当你拥有证书之后,你可以通过以下的方式轻易切换至 HTTPS:
- 开始监听端口 443(当你输入 https://sample.co 时浏览器将使用的默认端口)
- 提供证书及其密钥
server {
listen 443 ssl default_server;
listen [::]:443 ssl default_server;
ssl_certificate /etc/nginx/ssl/netguru.crt;
ssl_certificate_key /etc/nginx/ssl/netguru.key;
}
我们也想通过调整配置实现:
- 仅使用 TLS 协议。由于众所周知的漏洞,所有的 SSL 版本都将不再使用
- 使用预定义的安全的服务器密码(类似于协议的情况 – 那些日子只有少数密码被认为是安全的)
请牢记,上述设置总是在变化的。时不时重新更新是个好主意。
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_ciphers EECDH+CHACHA20:EECDH+AES128:RSA+AES128:EECDH+AES256:RSA+AES256:!MD5;
ssl_prefer_server_ciphers on;
server {
listen 443 ssl default_server;
listen [::]:443 ssl default_server;
ssl_certificate /etc/nginx/ssl/netguru.crt;
ssl_certificate_key /etc/nginx/ssl/netguru.key;
}
TLS 会话恢复
使用 HTTPS,在 TCP 之上需要增加 TLS 握手。这大大增加了此前实际数据传输的时间。假设你从华沙请求 /image.jpg,并接入到柏林最近的服务器:

为了在 TLS 握手期间节省一个 roundtrip 时间,以及生成新密钥的计算开销,我们可以重用在第一个请求期间生成的会话参数。客户端和服务器可以将会话参数存储在会话 ID 密钥的后面。在接下来的 TLS 握手过程中,客户端可以发送会话 ID,如果服务器在缓存中仍然有正确的条目,那么会重用前一个会话所生成的参数。
server {
ssl_session_cache shared:SSL:10m;
ssl_session_timeout 1h;
}
OCSP Stapling
SSL 证书可以随时撤销。浏览器为了知道给定的证书是否不再有效,需要通过在线证书状态协议 (Online Certificate Status Protocol ,OCSP) 执行额外的查询。无需用户执行指定的 OCSP 查询,我们可以在服务器上执行此操作,缓存其结果,并在 TLS 握手期间为客户端提供 OCSP 响应。它被称为OCSP stapling。
server {
ssl_stapling on;
ssl_stapling_verify on; # verify OCSP response
ssl_trusted_certificate /etc/nginx/ssl/lemonfrog.pem; # tell nginx location of all intermediate certificates
resolver 8.8.8.8 8.8.4.4 valid=86400s; # resolution of the OCSP responder hostname
resolver_timeout 5s;
}
Security headers
有一些标头确实值得调整以提供更高的安全性。有关更多关于标头及其详细信息,你绝对应该查看OWASP 项目之安全标头。
HTTP Strict-Transport-Security
或简称 HSTS,强制用户代理在向源发送请求时使用 HTTPS。
add_header Strict-Transport-Security "max-age=31536000; includeSubdomains; preload";
X-Frame-Options
表示浏览器是否需要在一帧、一个 iframe 或一个对象标签中渲染页面。
add_header X-Frame-Options DENY;
X-Content-Type-Options
此选项将阻止浏览器在判断文件类型时嗅探文件。文件将会按照 Content-Type 头中声明的格式转译。
add_header X-Content-Type-Options nosniff;
Server tokens
另一个很好的做法是在 HTTP 响应头字段中隐藏有关 Web 服务器的信息:
Server : nginx/1.13.2
实现此功能可以通过禁用 server_tokens 指令:
server_tokens off;
附录 :: Let’s Encrypt
安装
最新的安装包可以在这里找到。
为了测试使用暂存环境,不排除速率限制。
生成新证书
certbot certonly --webroot --webroot-path /var/www/netguru/current/public/
-d foo.netguru.co
-d bar.netguru.co
确保能够正确更新。
certbot renew --dry-run
确保你在 crontab 添加了自动更新。运行 crontab -e,同时添加下边一行代码
3 * * * /usr/bin/certbot renew --quiet --renew-hook "/usr/sbin/nginx -s reload"
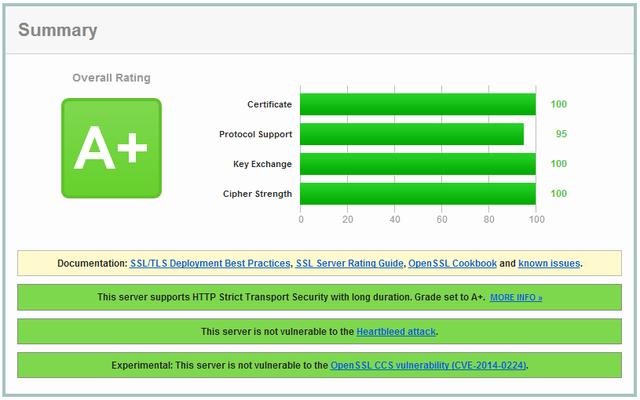
检查 SSL 是否能够通过 ssllabs 正常运行。

