
- 1python多线程和多进程的区别_python控制台和exe 线程执行不同
- 2TCP的连接与断开_tcp 连接的断开: 使用发送电子邮件来分析 tcp 连接的断开,过程会更清晰。步骤: 1.
- 3gdb堆栈被破坏时的定位方法_gdb info thread看到地址都是??这个怎么定位
- 4React-hook-form-mui(一):基本使用
- 5【华为OD真题 Python】分配土地_从前有个村庄,村民们喜欢在各种田地上插上小旗子,旗子上标识了各种不同的数字。某
- 6阿里云云安全中心支持哪些功能?费用价格是否值得买?_阿里云 安全服务 费用
- 7YOLOv7来临:论文解读附代码解析_yolov7论文
- 837、Flink 的CDC 格式:debezium部署以及mysql示例(1)-debezium的部署与示例_flink cdc --mode combined 参数 为所有表启动一个组合接收器
- 9python爬虫——用selenium爬取淘宝商品信息_selenium 淘宝搜索商品信息获取
- 10淘宝总知道你要什么?万字讲述智能内容生成实践 | 技术头条
open AI API使用经验_调用openai接口需要什么网络环境
赞
踩
open AI API
引言
OpenAI提供API接口,允许第三方开发者将GPT-3等模型集成到他们的应用程序和服务中,这种方式更具交互性和灵活性。与Chat GPT提供的聊天界面相比,OpenAI API提供了多种选项和设置,开发人员可以使用这些选项和设置来自定义模型的行为,例如模型的种类、模型的参数和任务定义等。在2023年3月1日,OpenAI开放了GPT-3.5 Turbo模型的API使用,据说这也是ChatGPT中正在使用的模型。使用API收费是每1000个tokens收费0.002美元,换算成中文大约是2分钱700个字。
概念
Tokens
传统意义上来说,GPT 模型使用的是非结构化文本,这些文本在模型中被表示为一连串的「token」标识符 ,open AI 模型将文本分解为tokens来理解和处理,也是模型计费的单位。tokens可以是单词,也可以是字符块。例如,像“pear”这样的简短而常见的单词是单个token,而单词“hamburger”被分解为“ham”,“bur”和“ger” 3个token。给定 API 请求中处理的token数量为输入和输出的总和。
API 调用中的token总数会影响:
- API 调用费用(按每个token支付)
- API 调用需要多长时间,因为写入更多token需要更多时间
- API 调用是否有效,因为总token必须低于模型的最大限制(gpt-3.5-turbo-0301 处理限制为 4096 个tokens)
prompts
提示(prompts),简单来说就是你想让模型输出你要想要的东西,首先需要给模型描述你想要的东西。提示可以是对任务的简短描述或者包含一个或多个输出示例。
Prompt 可能会包含以下几个元素
- 指令 Instruction :告诉模型你想要它执行的任务,例如:“请将上面的文字翻译成英文:”就是一个 instruction。
- 上下文 Contenxt :当前对话的上下文就是背景和语境,比如让ChatGPT 进行角色扮演,通过为 AI 分配一个角色的方式引导 AI 给出更准确的输出内容。
- 输入数据 Input Data :你想要给chatgpt处理的对象,如一段文本、一个问题,例如上文中翻译的文本内容。
- 输出指示符 Output Indicator:告诉模型你希望得到的输出类型或者格式。比如让模型给你一个列表,或者让模型给你一个由分号分隔的结果,都属于 Output Indicator。
你是一个多标签文本分类系统,请帮我完成中文多标签文本分类任务。
任务要求如下:对输入的句子进行多标签文本分类并按指定格式输出。
支持的分类类别仅限{{ labels|length }}类:{{ labels|join('、') }}。
解释及示例:{{ hint }}
输出格式要求:分类标签列表。
以下是输入句子:{{ text }}
输出:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Models
下列表格展示了Open AI API 各个模式下的可以使用的模型:
| ENDPOINT | MODEL NAME | 描述 |
|---|---|---|
| /v1/chat/completions | gpt-4, gpt-4-0314, gpt-4-32k, gpt-4-32k-0314, gpt-3.5-turbo, gpt-3.5-turbo-0301 | ChatCompletion是一个特定的终端点,主要用于模拟人类对话,例如聊天机器人、客服对话等任务。与Completion不同,ChatCompletion需要处理对话上下文,即对于同一个用户提出的多个问题或回答,需要考虑到之前的对话历史,以便提供更加连贯和准确的回复。 |
| /v1/completions | text-davinci-003, text-davinci-002, text-curie-001, text-babbage-001, text-ada-001 | completion是一个通用的终端点,主要用于生成文本,例如写作、翻译、摘要等任务。它接受一个文本提示作为输入,然后返回一段完整的文本。 |
| /v1/edits | text-davinci-edit-001, code-davinci-edit-001 | 用户可以将原始文本提交给 API,以获取建议的修改和改进。API 将返回一组编辑建议,这些建议包括替换、删除、插入和重新排列原始文本, |
| /v1/audio/transcriptions | whisper-1 | 提供音频文件,返回语音的转录文本,价格为每分钟 0.006 美元 |
| /v1/audio/translations | whisper-1 | 提供音频文件,返回另一种语言的转录文本 |
| /v1/fine-tunes | davinci, curie, babbage, ada | 提供训练数据,设定参数如学习速率、微调轮数、批量大小,对已有的GPT模型进行微调 |
| /v1/embeddings | text-embedding-ada-002, text-search-ada-doc-001 | 提供sentence/paragraph-level embedding。可以将一个或多个文本输入作为请求,并获得与每个文本对应的向量嵌入作为响应。如文本分类、语义搜索、文本相似性计算等。向量嵌入可以被认为是文本在高维空间中的表示,通过计算向量之间的距离或相似度来判断文本之间的关系 |
| /v1/moderations | text-moderation-stable, text-moderation-latest | 可以将一个或多个文本输入作为请求,并获得每个文本对应的审核结果作为响应。审核结果包括两个部分:是否通过审核和原因。如果文本通过了审核,则结果中的“toxicity”值为0,否则值为1,并且会返回一些相关的信息,例如违规词汇、句子结构、情感分析等。 |
#查看模型权限
import os
import openai
openai.organization = "YOUR_ORG_ID" #使用自己的ID
openai.api_key = os.getenv("OPENAI_API_KEY") #使用账号下创建的key
openai.Model.list()
- 1
- 2
- 3
- 4
- 5
- 6
使用流程
1.登录open AI 账号获得API keys
生成自己的api_key: https://platform.openai.com/account/api-keys
初始赠送5美金使用额度,额度用完之后需要自行购买,具体的收费价格和模型相关。
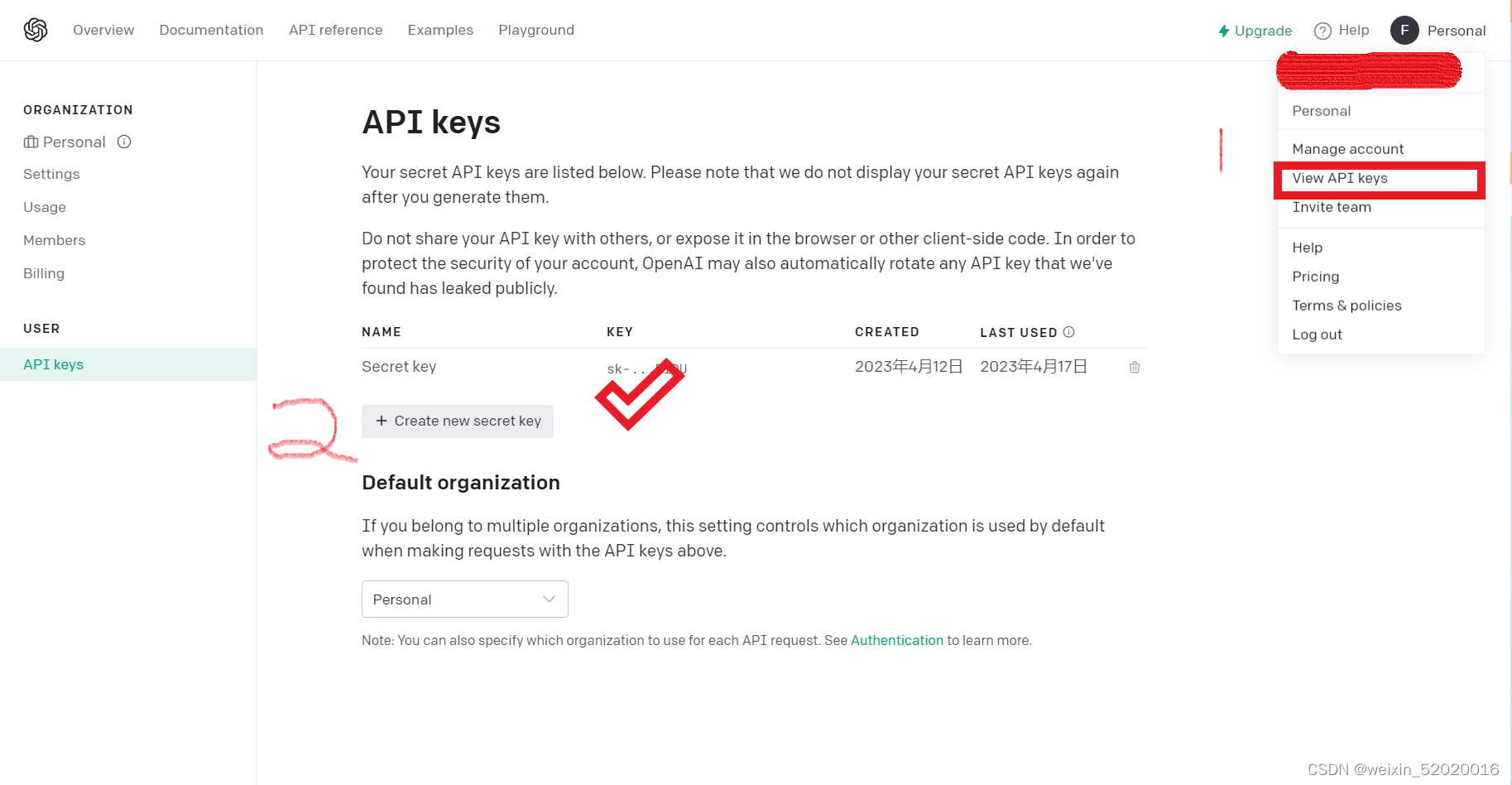
2.接入环境
安装官方的Python库,调用API时需要准备科学上网环境或配置代理
pip install openai
- 1
3.API用例
(1)Completion
import os import openai openai.api_key = os.getenv("OPENAI_API_KEY") # or openai.api_key = "YOUR OPENAI_API_KEY" prompt = """ Decide whether a comment on CSDN sentiment is positive, neutral, or negative. comment: I want to learn the openai more! Sentiment: """ response = openai.Completion.create( model="text-davinci-003", prompt=prompt, max_tokens=1024, temperature=0, top_p=0.1 ) print(response)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
temperature: 介于 0 和 2 之间。较高的值(如 0.8)将使输出更加随机,而较低的值(如 0.2)将使其更加集中和确定。
top_p:作用效果类似temperature,,其中模型考虑具有top_p概率的tokens。所以 0.1 意味着只考虑包含前 10% 概率的tokens
max_tokens: 生成的最大tokens数量, 加上prompt的tokens后,不能超过模型最大限制。
输出结果:
{ "choices": [ { "finish_reason": "stop", "index": 0, "logprobs": null, "text": "Positive" } ], "created": 1681656672, "id": "cmpl-75y0ePNfI8aT41A03W3WpYYwfvcuD", "model": "text-davinci-003", "object": "text_completion", "usage": { "completion_tokens": 2, "prompt_tokens": 36, "total_tokens": 38 } } Process finished with exit code 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
(2)ChatCompletion
content = '''
you are my assistant, Could we talk a little bit about
the schedule today, what will we do in the afternoon ?
'''
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": content}],
temperature=0.3,
max_tokens=1048,
top_p=1.0,
)
text = response.choices[0].message["content"]
print(text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
输出结果:
Of course! Can you please provide me with some more information about your schedule today? What activities do you have planned for the morning? This will help me better understand what we can do in the afternoon.
- 1
(3)Images
OpenAI API在给定原始图像或提示的情况下创建扩展或生成的图像。
response = openai.Image.create(
prompt="A super cute girl sitting in a basket of flowers, pop mart style, chibi",
n=1,
size="1024x1024"
)
image_url = response['data'][0]['url']
print(image_url)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
生成的图片:

(4)Edit
edit mode如果给出提示和指令,模型将返回经过编辑的版本
mycode = '''
while(!dead) {
code();
}
'''
response = openai.Edit.create(
model="code-davinci-edit-001",
input=mycode,
instruction="Fix the code mistakes and optimize it"
)
print(response)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
输出结果:
{ "choices": [ { "index": 0, "text": "while(!dead) \n code();\n" } ], "created": 1681659196, "object": "edit", "usage": { "completion_tokens": 41, "prompt_tokens": 35, "total_tokens": 76 } } Process finished with exit code 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
常用模型说明:
| LATEST MODEL | DESCRIPTION | MAX TOKENS | TRAINING DATA |
|---|---|---|---|
| gpt-3.5-turbo | Most capable GPT-3.5 model and optimized for chat at 1/10th the cost of text-davinci-003. Will be updated with our latest model iteration. | 4,096 tokens | Up to Sep 2021 |
| gpt-3.5-turbo-0301 | Snapshot of gpt-3.5-turbo from March 1st 2023. Unlike gpt-3.5-turbo, this model will not receive updates, and will only be supported for a three month period ending on June 1st 2023. | 4,096 tokens | Up to Sep 2021 |
| text-davinci-003 | Can do any language task with better quality, longer output, and consistent instruction-following than the curie, babbage, or ada models. Also supports [inserting] completions within text. | 4,097 tokens | Up to Jun 2021 |
| text-davinci-002 | Similar capabilities to text-davinci-003 but trained with supervised fine-tuning instead of reinforcement learning | 4,097 tokens | Up to Jun 2021 |
| code-davinci-002 | Optimized for code-completion tasks | 8,001 tokens | Up to Jun 2021 |
参考
https://platform.openai.com/docs
https://www.dataapplab.com/a-simple-guide-to-openai-api-with-python/


