
- 1运维笔记:inotify+rsync实现实时监控备份_centos 实时同步备份
- 2【栈】无法吃午餐的学生数量(leetcode1700)_无法吃午餐的学生数量 leetcode python
- 3Socket编程详解
- 4Ubuntu20.04下安装QtCreator 5.14.2(安装/卸载/创建快捷键/添加收藏)_ubuntu20.04 qtcreator
- 5Linux—root密码丢失重置_linux系统忘记root密码
- 6Java实现简易UDP客户端、服务器端通信程序_java 创建一个udp服务
- 7【原创】程序员必备的10大健康装备!——我们要工作更要健康!
- 8最细致讲解yolov8模型推理完整代码--(前处理,后处理)_yolov8推理
- 924个提高知识和技能极限的机器学习项目_有点难度的机器学习项目
- 1052-Android之内置应用_libcrashpad_handler_trampoline
PgSQL · 源码分析 · PG 优化器中的pathkey与索引在排序时的使用
赞
踩
概要
SQL在PostgreSQL中的处理,是类似于流水线方式的处理,先后由:
- 词法、语法解析,生成解析树后,将其交给语义解析
- 语义解析,生成查询树,将其交给Planner
- Planner根据查询树,生成执行计划,交给执行器
- 执行器执行完成后返回结果
数据库优化器在生成执行计划的时候,优化器会考虑是否需要使用索引,而使用了索引之后,则会考虑如何利用索引已经排过序的特点,来优化相关的排序,比如ORDER BY / GROUP BY等。
先来看个索引对ORDER BY起作用的例子:
- postgres=# create table t(id int, name text, value int);
- CREATE TABLE
- postgres=# create index t_value on t(value);
- CREATE INDEX
- postgres=# explain select * from
- postgres-# t order by value;
- QUERY PLAN
- ----------------------------------------------------------------------
- Index Scan using t_value on t (cost=0.15..61.55 rows=1160 width=40)
- (1 row)
-
- postgres=# explain select * from
- t order by name;
- QUERY PLAN
- ------------------------------------------------------------
- Sort (cost=80.64..83.54 rows=1160 width=40)
- Sort Key: name
- -> Seq Scan on t (cost=0.00..21.60 rows=1160 width=40)
- (3 rows)

由此可见,通过索引进行查询后,是可以直接利用已经索引的有序需不需要再次进行排序。
本文将介绍优化器如何在已有索引的基础上,优化排序的。
SQL的流水线处理
数据库以流水线的方式处理SQL请求,当一个SQL到来后:
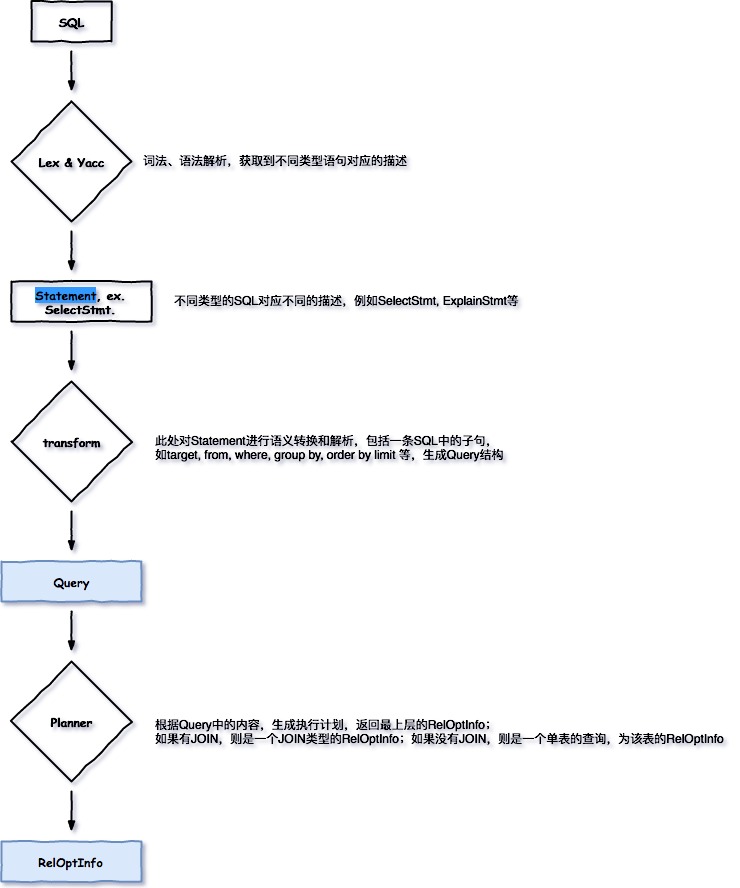
以SQL中SELECT语句的基本表达形式为例:
SELCT $targets FROM $tables_or_sub_queries WHERE $quals GROUP BY $columns ORDER BY $columns LIMIT $num OFFSET $columns;
为了表示一个SELECT的语句,语义解析之前是SelectStmt结构,其中包括targetlist、FROM 子句、WHERE子句、GROUP BY子句等。
在语义解析之后,会引入一个Query结构,该Query结构只表示当前语句中的内容,并不直接包括需要递归的子句,比如子查询(子查询用RangeTblEntry描述,存放在Query->rtable列表中)等。在Query之后,优化器根据其中的内容生成RelOptInfo,作为整个执行计划的入口。
Query 结构如下,此处我们着重关注rtable和jointree:
- 95 /*
- 96 * Query -
- 97 * Parse analysis turns all statements into a Query tree
- 98 * for further processing by the rewriter and planner.
- 99 *
- 100 * Utility statements (i.e. non-optimizable statements) have the
- 101 * utilityStmt field set, and the rest of the Query is mostly dummy.
- 102 *
- 103 * Planning converts a Query tree into a Plan tree headed by a PlannedStmt
- 104 * node --- the Query structure is not used by the executor.
- 105 */
- 106 typedef struct Query
- 107 {
- 108 NodeTag type;
- 109
- 110 CmdType commandType; /* select|insert|update|delete|utility */
- 111
- 112 QuerySource querySource; /* where did I come from? */
- 113
- 114 uint32 queryId; /* query identifier (can be set by plugins) */
- 115
- 116 bool canSetTag; /* do I set the command result tag? */
- 117
- 118 Node *utilityStmt; /* non-null if commandType == CMD_UTILITY */
- 119
- 120 int resultRelation; /* rtable index of target relation for
- 121 * INSERT/UPDATE/DELETE; 0 for SELECT */
- 122
- ...
-
-
- 133 List *cteList; /* WITH list (of CommonTableExpr's) */
- 134
- 135 List *rtable; /* list of range table entries */
- 136 FromExpr *jointree; /* table join tree (FROM and WHERE clauses) */
- 137
- 138 List *targetList; /* target list (of TargetEntry) */
- 139
-
- ...
-
- 146 List *groupClause; /* a list of SortGroupClause's */
- 147
-
- 156 List *sortClause; /* a list of SortGroupClause's */
- 157
- 158 Node *limitOffset; /* # of result tuples to skip (int8 expr) */
- 159 Node *limitCount; /* # of result tuples to return (int8 expr) */
- ...
-
- 180 int stmt_len; /* length in bytes; 0 means "rest of string" */
- 181 } Query;
在Query中,此次最关注的是由$tables_or_sub_queries解析得来的Query->rtable。Query->rtable是一个RangeTblEntry的列表,用于表示$tables_or_sub_queries中的以下几种类型:
- 表
- 子查询,表示出另外一个子句,但不包含子句中的Query,而是由RangeTblEntry中的subquery来描述其对应的Query
- JOIN,除了将JOIN相关的表添加到Query->rtable外,还会加入一个RangeTblEntry表示JOIN表达式用于后面的执行计划
- 函数
同时也会添加到相应的ParseState->p_joinlist,后转换为FromExpr作为Query->jointree。后面的执行计划生成阶段主要依赖Query->jointree和Query->rtable用于处理pathkey相关的信息。
执行计划生成
在SQL的操作中,几乎所有的操作(比如查询)最终都会落在实际的表上,那么在执行计划中表的表示就比较重要。PostgreSQL用RelOptInfo结构体来表示,如下:
-
- 518 typedef struct RelOptInfo
- 519 {
- 520 NodeTag type;
- 521
- 522 RelOptKind reloptkind;
- 523
- 524 /* all relations included in this RelOptInfo */
- 525 Relids relids; /* set of base relids (rangetable indexes) */
- 526
-
- ...
-
- 537
- 538 /* materialization information */
- 539 List *pathlist; /* Path structures */
- 540 List *ppilist; /* ParamPathInfos used in pathlist */
- 541 List *partial_pathlist; /* partial Paths */
- 542 struct Path *cheapest_startup_path;
- 543 struct Path *cheapest_total_path;
- 544 struct Path *cheapest_unique_path;
- 545 List *cheapest_parameterized_paths;
-
- ...
-
- 552 /* information about a base rel (not set for join rels!) */
- 553 Index relid;
- 554 Oid reltablespace; /* containing tablespace */
- 555 RTEKind rtekind; /* RELATION, SUBQUERY, FUNCTION, etc */
-
- ...
-
- 562 List *indexlist; /* list of IndexOptInfo */
- 563 List *statlist; /* list of StatisticExtInfo */
-
- ...
- 584 /* used by various scans and joins: */
- 585 List *baserestrictinfo; /* RestrictInfo structures (if base rel) */
- 586 QualCost baserestrictcost; /* cost of evaluating the above */
- 587 Index baserestrict_min_security; /* min security_level found in
- 588 * baserestrictinfo */
- 589 List *joininfo; /* RestrictInfo structures for join clauses
-
- ...
- 595 } RelOptInfo;
事实上,RelOptInfo是执行计划路径生成的主要数据结构,同样用于表述表、子查询、函数等。
在SQL查询中,JOIN是最为耗时,执行计划的生成首先考虑JOIN。因此,整个执行计划路径的入口即为一个JOIN类型的RelOptInfo。当只是单表的查询时,则执行计划入口为这张表的RelOptInfo。
执行计划的生成过程,就是从下往上处理到最上层的RelOptInfo->pathlist的过程,选择有成本较优先节点、删除无用节点,最后得到一个成本最优的执行计划。
在整个过程中,大约分为以下几步:
- 获取表信息
- 创建表RelOptInfo,将所有该表的扫瞄路径加入到该表的RelOptInfo->pathlist
- 创建JOIN的RelOptInfo,将所有可能的JOIN顺序和方式以Path结构体添加到RelOptInfo->pathlist
- 针对JOIN的RelOptInfo,添加GROUP BY、ORDER BY等节点
生成范围表的扫瞄节点
执行计划一开始,即首先将获取所有的表信息,并以RelOptInfo(baserel)存放在PlannerInfo结构体中的simple_rel_array中,如RelOptInfo中的indexlist用于表示这张表的索引信息,用于判断是否可以用上索引。
为每张表建立扫瞄路径,一般有顺序扫瞄和索引扫瞄两种。扫瞄路径用Path结构体来表示,并存放在该表对应的RelOptInfo->pathlist中。Path结构体如下:
- 948 typedef struct Path
- 949 {
- 950 NodeTag type;
- 951
- 952 NodeTag pathtype; /* tag identifying scan/join method */
- 953
- 954 RelOptInfo *parent; /* the relation this path can build */
- 955 PathTarget *pathtarget; /* list of Vars/Exprs, cost, width */
- 956
- 957 ParamPathInfo *param_info; /* parameterization info, or NULL if none */
- 958
- 959 bool parallel_aware; /* engage parallel-aware logic? */
- 960 bool parallel_safe; /* OK to use as part of parallel plan? */
- 961 int parallel_workers; /* desired # of workers; 0 = not parallel */
- 962
- 963 /* estimated size/costs for path (see costsize.c for more info) */
- 964 double rows; /* estimated number of result tuples */
- 965 Cost startup_cost; /* cost expended before fetching any tuples */
- 966 Cost total_cost; /* total cost (assuming all tuples fetched) */
- 967
- 968 List *pathkeys; /* sort ordering of path's output */
- 969 /* pathkeys is a List of PathKey nodes; see above */
- 970 } Path;
在添加表的扫瞄路径时,会首先添加顺序扫瞄(seqscan)到这张表的RelOptInfo->pathlist,保证表数据的获取。而后考虑indexscan扫瞄节点等其他方式。
当RelOptInfo->indexlist满足RelOptInfo->baserestrictinfo中的过滤条件,或满足RelOptInfo->joininfo等条件时,则认为index是有效的。然后根据统计信息(如过滤性等)计算成本后,建立index扫瞄节点。
在建立index扫瞄节点时,根据索引建立时的情况(排序顺序、比较操作符等),创建PathKeys的列表(可能多个字段),存放在IndexPath->Path->pathkeys中。PathKeys的结构体如下:
- 830 /*
- 831 * PathKeys
- 832 *
- 833 * The sort ordering of a path is represented by a list of PathKey nodes.
- 834 * An empty list implies no known ordering. Otherwise the first item
- 835 * represents the primary sort key, the second the first secondary sort key,
- 836 * etc. The value being sorted is represented by linking to an
- 837 * EquivalenceClass containing that value and including pk_opfamily among its
- 838 * ec_opfamilies. The EquivalenceClass tells which collation to use, too.
- 839 * This is a convenient method because it makes it trivial to detect
- 840 * equivalent and closely-related orderings. (See optimizer/README for more
- 841 * information.)
- 842 *
- 843 * Note: pk_strategy is either BTLessStrategyNumber (for ASC) or
- 844 * BTGreaterStrategyNumber (for DESC). We assume that all ordering-capable
- 845 * index types will use btree-compatible strategy numbers.
- 846 */
- 847 typedef struct PathKey
- 848 {
- 849 NodeTag type;
- 850
- 851 EquivalenceClass *pk_eclass; /* the value that is ordered */
- 852 Oid pk_opfamily; /* btree opfamily defining the ordering */
- 853 int pk_strategy; /* sort direction (ASC or DESC) */
- 854 bool pk_nulls_first; /* do NULLs come before normal values? */
- 855 } PathKey;
- 856
事实上,PathKeys可以用于所有已排过序的RelOptInfo中,用于表示这个表、函数、子查询、JOIN等是有序的,作为上层判断选择Path的依据之一。
在建立除seqscan之外的其他节点时,会与pathlist中已有的每个节点根据启动成本和总体成本做对比(相差在一定比值,默认1%),则分为四种情况:
-
新建节点和已有节点,其中一方启动成本和总成本都更优,且其pathkeys也更优,那么删除另外一个
-
新建节点和所有已有节点的启动成本和总成本两方面的对比不一致(如总成本高但启动成本较低,或反过来),且新建节点总成本较低,则会全部保留并添加到RelOptInfo->pathlist中。
-
新节点和已有节点,其中一方启动成和总成本都更优,但其pathkeys不够,则两者都保留,由上层Path节点来判断
-
当新建节点和已有节点成本相同时,则对比两者的pathkeys,选择保留更优pathkeys的节点
此时,即完成一张表所有的Path的生成,保存在该表的RelOptInfo->pathlist中,并从中选择一条成本最低的Path,作为RelOptInfo->cheapest_total_path。索引扫瞄节点的pathkeys将会被上层路径在与排序相关节点中用到,如ORDER BY、GROUP BY、MERGE JOIN等。
生成JOIN节点
JOIN节点生成的算法较为复杂,简单来说,会针对所有参与JOIN的表,动态规划不同的顺序和JOIN方式,然后生成不同的Path加到这个JOIN的RelOptInfo->pathlist中。
最终执行计划的生成
在完成JOIN的各个路径判断后,针对各路径选择成本最低的Path(表的JOIN顺序和JOIN方式)作为最优路径,并依据这个路径上的pathkeys处理ORDER BY、GROUP BY等其他子句的计划,从而完成最终的执行计划。
在前面的介绍中,每张表的RelOptInfo->pathlist中的indexscan的Path都带有pathkeys信息,即表明这个节点执行完之后的结果是按pathkeys来排序的。那么在以下几个地方则可以用到该特性:
-
MERGE JOIN
在建立JOIN节点时,会有多种JOIN方式可以选择,如NESTLOOP、MERGE JOIN等。当建立了MERGE JOIN节点之后,一般是需要对两张表进行排序。但当某张表的扫瞄节点返回的是有序的,且该顺序与查询所需完全一致,则会去除这个排序节点,从而在成本上占据优势。
-
ORDER BY
当最终的RelOptInfo节点建立完成后,会拿表RelOptInfo->pathlist中成本最低的Path,与带有pathkeys的Path做成本上的对比,选择成本更低的路径。如果最终是pathkeys的路径,那么该RelOptInfo的pathkeys会保留。
若该SQL语句中带ORDER BY,则可以判断该RelOptInfo的pathkeys是否对ORDER BY(字段和排列顺序一致),则不必再建立ORDER BY节点。如果pathkeys没有帮助,则会建立排序节点
-
GROUP BY
GROUP BY有多种方式。如果RelOptInfo中的pathkeys与在解析阶段产生的GROUP BY的pathkeys一致,则从成本上对RelOptInfo结果集的pathkeys对该GROUP BY是否有效,从而可以考虑选用SORT加AGG的方式。这种方式,因为pathkeys的存在,则不必再建SORT 节点。然后再对比与其他方式的成本,择优采用。
-
子查询
如果JOIN中包含子查询,那么则在JOIN的RelOptInfo->pathlist中添加一个subquery类型的Path,并把子查询中的排序的结果指定为pathkeys放在该Path中。从而上层节点,可以用上面同样的方法,选用该RelOptInfo中最优的Path,并根据pathkeys决定是否需要排序。
总结
通过以上表述,可以说明一条SQL语句的执行计划入口是一个RelOptInfo结构,其中成员pathlist则标示所有不同的查找路径,在这些路径中最终会落在表的RelOptInfo->pathlist中最优的Path中。如果该Path带有pathkeys,那么上层在处理ORT相关的操作时,可以根据pathkeys是否对排序有效而决定是否需要排序节点,从而选择成本更低的路径。

