
- 1Object.defineProperty方法_object.defineproperty(obj, prop, descriptor)重写push
- 2车载Android应用开发与分析 - SystemUI 「功能」与「源码结构」分析_车载应用开发
- 3STM32系统时钟超详解_stm32的时钟
- 4Unity性能优化 - 动态图集_unity 动态图集
- 5编程习惯---(摘自)CSDN程序员_请不要尝试改动这段代码
- 6混合推荐策略_混合推荐算法
- 7解决vue-print插件打印时表格宽度无法撑满自适应_elementui表格宽度撑满
- 8python中remove函数_python remove
- 9服务器与电脑的区别?
- 10人机之间的不同交互
知识图谱构建(概念,工具,实例调研)
赞
踩
知识图谱构建(概念,工具,实例调研)
一、知识图谱的概念
知识图谱(Knowledge graph)知识图谱是一种用图模型来描述知识和建模世界万物之间的关联关系的技术方法。知识图谱由节点和边组成。节点可以是实体,如一个人、一本书等,或是抽象的概念,如人工智能、知识图谱等。边可以是实体的属性,如姓名、书名或是实体之间的关系,如朋友、配偶。知识图谱的早期理念来自Semantic Web(语义网络),其最初理想是把基于文本链接的万维网落转化为基于实体链接的语义网络。
1.知识图谱的几个关键概念
1.1 本体
领域术语集合。本体最为抽象,简单理解就是一堆概念,这堆概念集合能够描述某个具体的domain里的一切事物的共有特征,然后概念间又有一定的关系,所有构成一个具有层级特征的结构。所以在语义网里ontology和schema基本不分家。
在上面知识图谱的例子中,本体是足球领域schema
1.2 类型 type
具有相同特点或属性的实体集合的抽象,如足球球员、足球联赛、足球教练。
1.3 实体
实体就是type的实例,如足球球员--梅西,足球联赛--西甲等。
1.4 关系
实体与实体之间通过关系关联起来,如梅西是巴塞罗那的球员。
1.5 属性
实体自带信息是属性,如梅西 出生日期 1987年6月24日, 身高 1.7米等。
1.6 知识图谱
图状具有关联性的知识集合。可以由三元组(实体entity,实体关系relation,实体entity)表示。
1.7 知识库
知识库(Knowledge Base),就是一个知识数据库,包含了知识的本体和知识。Freebase是一个知识库(结构化),维基百科也可以看成一个知识库(半结构化),等等。知识图谱可以看成是由图数据库存储的知识库。
二、知识图谱的分层架构
知识图谱由数据层(data layer)和模式层(schema layer)构成。
模式层是知识图谱的概念模型和逻辑基础,对数据层进行规范约束. 多采用本体作为知识图谱的模式层,借助本体定义的规则和公理约束知识图谱的数据层。也可将知识图谱视为实例化了的本体,知识图谱的数据层是本体的实例。如果不需支持推理, 则知识图谱(大多是自底向上构建的) 可以只有数据层而没有模式层。在知识图谱的模式层,节点表示本体概念,边表示概念间的关系。
在数据层, 事实以“实体-关系-实体”或“实体-属性-属性值”的三元组存储,形成一个图状知识库. 其中,实体是知识图谱的基本元素,指具体的人名、组织机构名、地名、日期、时间等。关系是两个实体之间的语义关系,是模式层所定义关系的实例。属性是对实体的说明,是实体与属性值之间的映射关系。属性可视为实体与属性值之间的 hasValue 关系,从而也转化为以“实体-关系-实体”的三元组存储。在知识图谱的数据层,节点表示实体,边表示实体间关系或实体的属性。
三、知识图谱构建流程及应用
知识图谱的构建方法主要有两种:自底向上和自顶而下。
1.开放域知识图谱的本体构建通常用自底向上的方法,自动地从知识图谱中抽取概念、概念层次和概念之间的关系。
2.领域知识图谱多采用自顶向下的方法来构建本体。一方面,相对于开放域知识图谱,领域知识图谱涉及的概念和范围都是固定或者可控的;另一方面,对于领域知识图谱,要求其满足较高的精度。自顶向下是先为知识图谱定义好本体与数据模式,再将实体加入到知识库。该构建方式需要利用一些现有的结构化知识库作为其基础知识库。
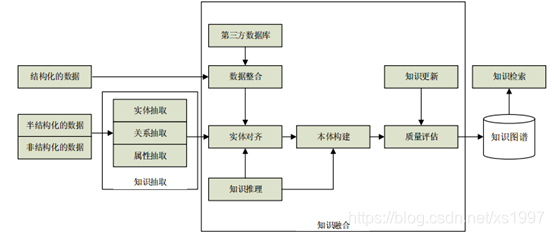
图1 知识图谱技术架构图
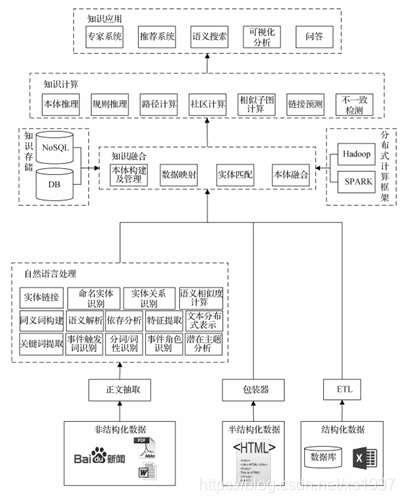
图2 知识图谱技术应用
四、知识图谱构建步骤
4.1信息抽取
信息抽取从各种类型的数据源中提取出实体、属性以及实体间的相互关系,在此基础上形成本体化的知识表达,涉及的关键技术包括实体抽取、关系抽取和属性抽取。关键问题是如何从异构数据中自动抽取信息到候选指示单元。
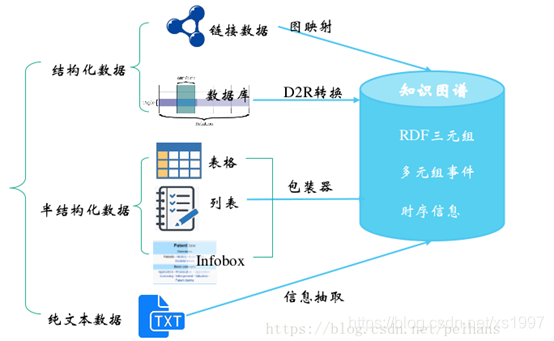
4.1.1实体抽取
实体抽取又称为命名实体识别(NER),是指从文本数据集中自动识别出命名实体,其目的就是建立知识图谱中的“节点”。 实体抽取任务有两个关键词:find & classify,找到命名实体,并进行分类。
主要应用:
(1)命名实体作为索引和超链接
(2)情感分析的准备步骤,在情感分析的文本中需要识别公司和产品,才能进一步为情感词归类
(3)关系抽取(Relation Extraction)的准备步骤
(4)QA 系统,大多数答案都是命名实体
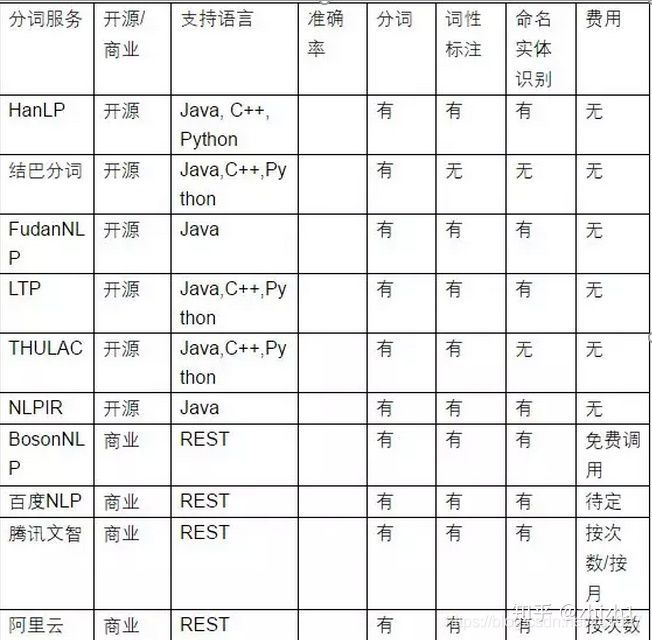
主要实现方法和工具:
(1)DeepDive-斯坦福大学开源知识抽取工具(三元组抽取):从更少的结构化数据和统计推断中提取结构化的知识而无需编写任何复杂的机器学习代码。
(2)FudanNLP: 主要是为中文自然语言处理而开发的工具包,也包含为实现这些任务的机器学习算法和数据集。可以实现中文分词,词性标注,实体名识别,句法分析,时间表达式识别,信息检索,文本分类,新闻聚类等
(3)NLPIR分词 (中科院):主要功能包括中文分词;英文分词;词性标注;命名实体识别;新词识别;关键词提取;支持用户专业词典与微博分析。NLPIR系统支持多种编码、多种操作系统、多种开发语言与平台。
(4)LTP(哈工大):语言技术平台(Language Technology Platform,LTP)提供了一系列中文自然语言处理工具,用户可以使用这些工具对于中文文本进行分词、词性标注、句法分析等等工作。
实体抽取,实体链接(两个实体同一个含义需要规整),目前最主流的算法就是CNN+LSTM+CRF进行实体识别。
4.1.2 关系抽取
文本语料经过实体抽取之后得到的是一系列离散的命名实体(节点),为了得到语义信息,还需要从相关的语料中提取出实体之间的关联关系(边),才能将多个实体或概念联系起来,形成网状的知识结构。研究关系抽取技术,就是研究如何解决从文本语料中抽取实体间的关系。根据对标注数据的依赖程度,实体关系抽取方法可分为有监督学习方法、半监督学习方法、无监督学习方法和开放式抽取方法。
(1) 有监督的实体关系抽取
有监督学习方法是最基本的实体关系抽取方法,其主要思想是在已标注的训练数据的基础上训练机器学习模型,然后对测试数据的关系类型进行识别。有监督学习方法包括有基于规则的方法、基于特征的方法和基于核函数的方法。
基于规则的方法需要根据待处理语料涉及领域的不同,通过人工或机器学习的方法总结归纳出相应的规则或模板,然后用模板匹配方法进行实体关系抽取。
基于特征向量的方法是一种简单、有效的实体关系抽取方法,其主要思想是从关系句子实例的上下文中提取有用信息( 包括词法信息、语法信息)作为特征,构造特征向量, 通过计算特征向量的相似度来训练实体关系抽取模型。该方法的关键在于寻找类间有区分度的特征,形成多维加权特征向量,然后采用合适的分类器进行分类。
基于核函数的实体关系抽取方法,包括词序列核函数方法、依存树核函数方法、最短路径依存树核函数方法、卷积树核函数方法以及它们的组合核函数方法可和基于特征的实体关系抽取方法可以相互补充。
(2)半监督的实体关系抽取
基于 Bootstrapping 的半监督实体关系抽取方法从包含关系种子的上下文中总结出实体关系序列模式,然后利用关系序列模式去发现更多的关系种子实例,形成新的关系种子集合。
基于协同学习( co-learning) 方法, 该方法利用两个条件独立的特征集来提供不同且互补的信息,从而减少标注错误。
(3)无监督的实体关系抽取
无监督实体关系抽取方法无需依赖实体关系标注语料,其实现包括关系实例聚类和关系类型词选择两个过程。首先根据实体对出现的上下文将相似度高的实体对聚为一类,然后选择具有代表性的词语来标记这种关系。
(4)开放式实体关系抽取
该方法能避免针对特定关系类型人工构建语料库,可以自动完成关系类型发现和关系抽取任务。通过借助外部领域无关的实体知识库( 如 DBPedia、YAGO、OpenCyc、FreeBase 或其它领域知识库) 将高质量的实体关系实例映射到大规模文本中,根据文本对齐方法从中获得训练数据,然后使用监督学习方法来解决关系抽取问题。
4.1.3 关系抽取工具调研
1.实体间关系抽取,拿到知识图谱最小单元三元组,比较经典算法的就是Piece-Wise-CNN和 LSTM+ Attention 。
2.DeepKE:基于深度学习的开源中文关系抽取工具
3. DeepDive是斯坦福大学开发的信息抽取系统,能处理文本、表格、图表、图片等多种格式的无结构数据,从中抽取结构化的信息。系统集成了文件分析、信息提取、信息整合、概率预测等功能。Deepdive的主要应用是特定领域的信息抽取,系统构建至今,已在交通、考古、地理、医疗等多个领域的项目实践中取得了良好的效果;在开放领域的应用
Deepdive在OpenKG.CN上有一个中文的教程:中文教程
斯坦福地址:DeepDive
GitHub地址:https://github.com/HazyResearch/deepdive
支持中文的提取:支持中文的deepdive:斯坦福大学的开源知识抽取工具(三元组抽取) - 图谱 - 开放知识图谱
4.Standford NLP提供了开放信息抽取OpenIE功能用于提取三元组SPO,所以使用Standford NLP更贴合知识图谱构建任务,
5.Reverb: 开放三元组抽取http://reverb.cs.washington.edu
Reverb是华盛顿大学研发的开放三元组抽取工具,可以从英文句子中抽取形如(augument1, relation, argument2)的三元组。它不需要提前指定关系,支持全网规模的信息抽取。
6.SOFIE: 抽取链接本体及本体间关系SOFIE
SOFIE是一个自动化本体扩展系统,由max planck institute开发。它可以解析自然语言文件,从文本中抽取基于本体的事件,将它们链接到本体上,并基于逻辑推理进行消歧。
7.OLLIE:开放三元组知识抽取工具。ollie
华盛顿大学研发的知识库三元组抽取组件,OLLIE是第二代提取系统。Reverb的抽取建立在文本序列上,而OLLIE则支持基于语法依赖树的关系抽取,对于长线依赖效果更好。
4.1.3属性抽取
(1)基于规则匹配的抽取方法
基于模式匹配的抽取方法也叫基于规则的抽取方法,就是基于事先构造一系列规则来抽取文本中实体-属性的方法。这种方法首先定义相关抽取规则,如,定义相关的规范的tag标,或人工编写正则表达式,然后将这些规则与文本进行匹配,通过匹配的结果得到抽取的实体及其属性。
基于规则的抽取系统一般由两部分组成,一个是一系列关于抽取规则的集合,第二是一系列定义匹配策略的集合。
(2)基于模式匹配的实体-属性抽取方法
基于模式匹配的方法根据其定义模式的方法可以分成三种:基于手工定义的抽取、基于有监督学习的抽取和基于迭代的抽取。基于手工定义方式就是具有通过相关领域专业知识的人员进行人工的定义一系列模式。基于学习的方式就是,首先收集相关语料组成大规模的语料库,然后通过人工标准的非结构化例子训练自动获得模式,构建具有大量实体-属性的知识库。基于迭代的方法是首先定义模板元组,让后对这些模板元组进行迭代,自动产生模式,从而进行对实体-属性的抽取。
(3)基于关系分类的实体-属性抽取方法
基于关系分类的方法就是将属性抽取问题转化成关系分类问题。首先将抽取的两个实体视为一个样本,实体直接的关系视为标签,然后通过手工的方式构建样本特征,最后依据这些特征对样本进行分类,分类的结果便是实体之间的关系,也就是属性。基于关系的抽取方法通常借助机器学习的方法来进行,如支持向量机(SVM)、神经网络等,通过对大量语料库的训练来学习分类模型,从而对实体-属性进行抽取。基于关系分类的方法按照其语料库的建设方式可以分为远程监督的方法和全监督的方法。基于远程监督的方法基本由机器构建语 料库,而基于全监督的方法则由人工构建语料库。由于由人工 来构建语料库耗费大量的时间和精力,因此通常目前更热衷于 使用远程监督的方法构建语料库。
(4)基于聚类的实体-属性抽取方法
基于聚类的方法就是将属性抽取问题转化成聚类问题。首先构建实体特性向量,然后基于相关方法对这些特征向量进行聚类,最后得到的聚类就是实体的属性。例如对于类别属性可以采用弱监督的聚类方法,对应产品属性可以采用无监 督的聚类方法等。
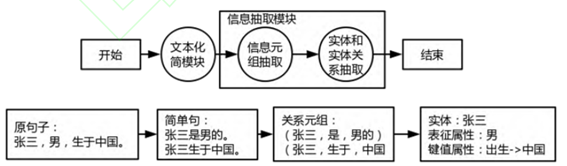
图3 基于文本化简的实体属性抽取方法
4.2知识融合
经由信息抽取之后的信息单元间的关系是扁平化的,缺乏层次性和逻辑性,同时存在大量冗余甚至错误的信息碎片。知识融合旨在解决如何将关于同一个实体或概念的多源描述信息融合起来,将多个知识库中的知识进行整合,形成一个知识库的过程,在这个过程中,主要关键技术包含指代消解、实体消歧、实体链接。
4.2.1关键问题解决方法
(1)实体统一(共指消解)
多源异构数据在集成的过程中,通常会出现一个现实世界实体对应多个表象的现象,导致这种现象发生的原因可能是:拼写错误、命名规则不同、名称变体、缩写等等。而这种现象会导致集成后的数据存在大量冗余数据、不一致数据等问题,从而降低了集成后数据的质量,进而影响了基于集成后的数据做分析挖掘的结果。分辨多个实体表象是否对应同一个实体的问题即为实体统一。
如重名现象,南京航天航空大学(南航)
1)基于两者混用的方法

2) 模式匹配
模式匹配主要是发现不同关联数据源中属性之间的映射关系,主要解决三元组中谓词之间的冲突问题;另一种解释:解决不同关联数据源对相同属性采用不同标识符的问题,从而实现异构数据源的集成

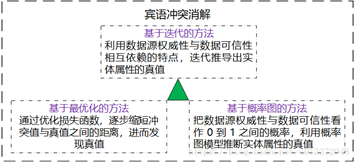
3)宾语冲突消解
宾语冲突消解是解决多源关联数据宾语不一致问题。
(2)实体消歧
实体消歧的本质在于一个词有很多可能的意思,也就是在不同的上下文中所表达的含义不太一样。如:我的手机是苹果。我喜欢吃苹果。
1)基于词典的词义消歧
基于词典的词义消歧方法研究的早期代表工作是Lesk 于1986 的工作。给定某个待消解词及其上下文,该工作的思想是计算语义词典中各个词义的定义与上下文之间的覆盖度,选择覆盖度最大的作为待消解词在其上下文下的正确词义。但由于词典中词义的定义通常比较简洁,这使得与待消解词的上下文得到的覆盖度为0,造成消歧性能不高。
2)有监督词义消歧
有监督的消歧方法使用词义标注语料来建立消歧模型,研究的重点在于特征的表示。常见的上下文特征可以归纳为三个类型:
1.词汇特征通常指待消解词上下窗口内出现的词及其词性;
2.句法特征利用待消解词在上下文中的句法关系特征,如动-宾关系、是否带主/宾语、主/宾语组块类型、主/宾语中心词等;
3.语义特征在句法关系的基础上添加了语义类信息,如主/宾语中心词的语义类,甚至还可以是语义角色标注类信息。
3)无监督和半监督词义消歧
虽然有监督的消歧方法能够取得较好的消歧性能,但需要大量的人工标注语料,费时费力。为了克服对大规模语料的需要,半监督或无监督方法仅需要少量或不需要人工标注语料。一般说来,虽然半监督或无监督方法不需要大量的人工标注数据,但依赖于一个大规模的未标注语料,以及在该语料上的句法分析结果。
(3)实体链接(Entity Linking)
实体链接(entity linking)是指对于从非结构化数据(如文本)或半结构化数据(如表格)中抽取得到的实体对象,将其链接到知识库中对应的正确实体对象的操作。其基本思想是首先根据给定的实体指称项,从知识库中选出一组候选实体对象,然后通过相似度计算将指称项链接到正确的实体对象,通过打分的方法对指称项最高的实体作为目标实体。
1.向量空间模型
基于实体指称项上下文与目标实体上下文中特征的共现信息来确定。
向量表示抽取有效的特征表示,有效地计算向量之间的相似度。
2.主题一致性模型
实体指称项的候选实体概念与指称项上下文中的其他实体概念的一致性程度
3.协同实体链接
上面只处理单个实体指称项的链接问题,忽略了单篇文档内所有实体指称项的目标实体之间的关系。对文档内所有实体指称项进行协同链接有助于提升实体链接的性能。
4.基于神经网络的实体消歧方法
4.2.2知识融合常见的流程和步骤
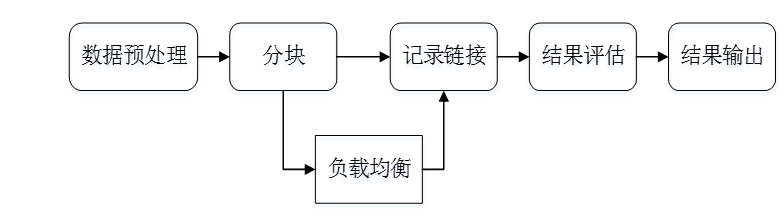
1.数据预处理
数据预处理阶段,原始数据的质量会直接影响到最终链接的结果,不同的数据集对同一实体的描述方式往往是不相同的,对这些数据进行归一化是提高后续链接精确度的重要步骤。常用的数据预处理有:
语法正规化:
语法匹配:如联系电话的表示方法
综合属性:如家庭地址的表达方式
数据正规化:
移除空格、《》、“”、-等符号
输入错误类的拓扑错误
用正式名字替换昵称和缩写等
2.记录连接
假设两个实体的记录x 和y, x和y在第i个属性上的值是<script type = "math/tex" id="MathJax-Element-8">x_i, y_i</script>, 那么通过如下两步进行记录连接:
属性相似度: 综合单个属性相似度得到属性相似度向量:
实体相似度: 根据属性相似度向量得到一个实体的相似度。
2.1属性相似度的计算
属性相似度的计算有多种方法,常用的有编辑距离、集合相似度计算、基于向量的相似度计算等。
(1)编辑距离: Levenstein、 Wagner and Fisher、 Edit Distance with Afine Gaps
(2)集合相似度计算: Jaccard系数, Dice
(3)基于向量的相似度计算: Cosine相似度、TFIDF相似度
2.2实体相似度的计算
实体关系发现框架Limes
教程网址:http://openkg1.oss-cn-beijing.aliyuncs.com/d9780259-7e4f-456f-88fa-8274a3def82b/tutorial-limes.pdf
2.2.1聚合:
(1)加权平均:对相似度得分向量的各个分量进行加权求和,得到最终的实体相似度
(2)手动制定规则:给每一个相似度向量的分量设置一个阈值,若超过该阈值则将两实体相连
(3)分类器:采用无监督/半监督训练生成训练集合分类
2.2.2聚类:
(1)层次聚类:通过计算不同类别数据点之间的相似度对在不同的层次的数据进行划分,最终形成树状的聚类结构。
(2)相关性聚类:使用最小的代价找到一个聚类方案。
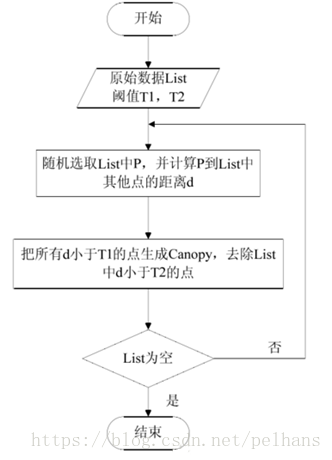
(3)Canopy + K-means:不需提前指定K值进行聚类
2.2.3知识表示学习:(嵌入式表示)
将知识图谱中的实体和关系都映射低维空间向量,直接用数学表达式来计算各个实体之间相似度。这类方法不依赖任何的文本信息,获取到的都是数据的深度特征。
(1)分块
分块 (Blocking)是从给定的知识库中的所有实体对中,选出潜在匹配的记录对作为候选项,并将候选项的大小尽可能的缩小。常用的分块方法有基于Hash函数的分块、邻近分块等。常见的Hash函数有:字符串的前n个字,n-grams,结合多个简单的hash函数等。邻近分块算法包含Canopy聚类、排序邻居算法、Red-Blue Set Cover等。
负载均衡 (Load Balance)来保证所有块中的实体数目相当,从而保证分块对性能的提升程度。最简单的方法是多次Map-Reduce操作。
4.2.3 知识融合实现工具
(1)本体对齐工具-Falcon-AO
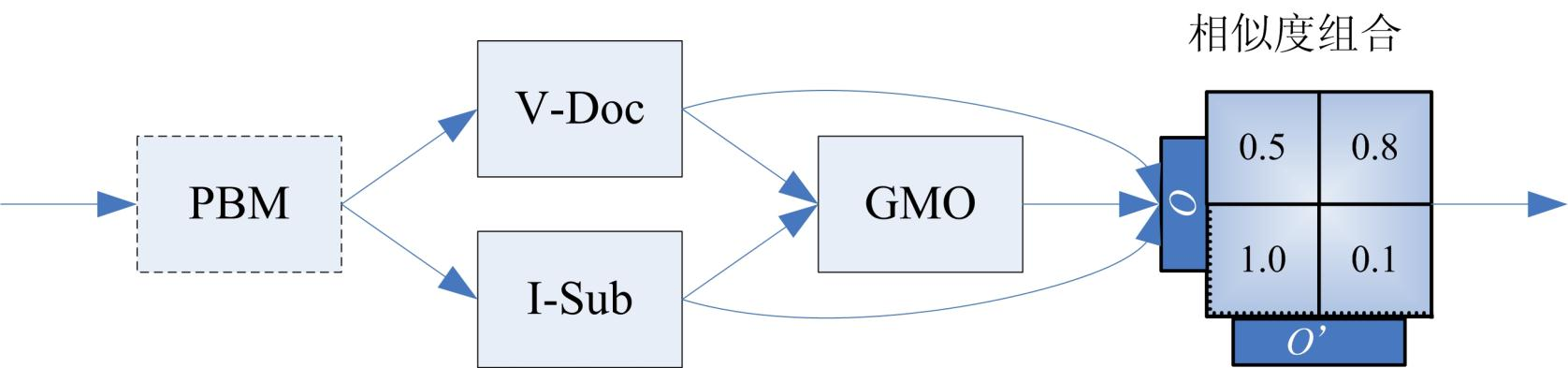
Falcon-AO是一个自动的本体匹配系统,已经成为RDF(S)和OWL所表达的Web本体相匹配的一种实用和流行的选择。编程语言为Java。匹配算法库包含V-Doc、I-sub、GMO、PBM四个算法。其中V-Doc即基于虚拟文档的语言学匹配,它是将实体及其周围的实体、名词、文本等信息作一个集合形成虚拟文档的形式。可以用TD-IDF等算法进行操作。I-Sub是基于编辑距离的字符串匹配。I-Sub和V-Doc都是基于字符串或文本级别的处理。更进一步的就有了GMO,它是对RDF本体的图结构上做的匹配。PBM则基于分而治之的思想做。首先经由PBM进行分而治之,后进入到V-Doc和 I-Sub ,GMO接收两者的输出做进一步处理,GMO的输出连同V-Doc和I-Sub的输出经由最终的贪心算法进行选取。
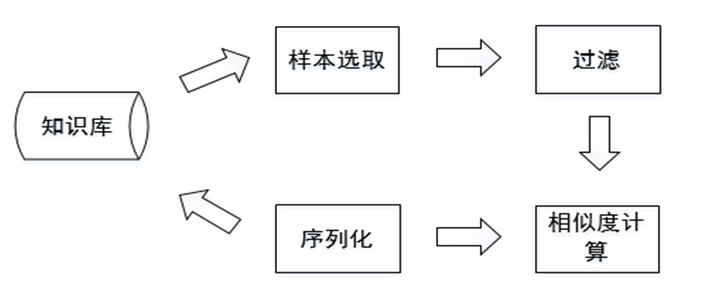
(2)Limes 实体匹配
Limes是一个基于度量空间的实体匹配发现框架,适合于大规模数据链接,编程语言是Java。其整体框架如下图所示:
(3)Sematch(开源2017)
用于知识图谱的语义相似性的开发、评价和应用的集成框架。 Sematch支持对概念、词和实体的语义相似度的计算,并给出得分。 Sematch专注于基于特定知识的语义相似度量,它依赖于分类( 比如 ) 中的结构化知识。 深度、路径长度 ) 和统计信息内容( 语料库与语义图谱) 。----基于wordNet。
(4)基于Neo4j 图数据库的知识图谱的实体对齐(目前最常用)
计算相关性的基本步骤分为三步:
1.链接neo4j数据库,并且读取出里面的数据
2.对齐算法运算
3.拿到运算结果设定一个阀值,来判断大于阀值的就是相关。
基于Neo4j 图数据库的知识图谱的关联对齐-最小编辑距离-jacard算法
(5)使用jieba完成实体统一
jieba是优秀的中文分词第三方库,中文文本需要通过分词获得单个的词语,jieba是优秀的中文分词第三方库,需要额外安装,jieba库提供三种分词模式,最简单只需掌握一个函数
(6)TF-IDF
Term Frequency-inverse Document Frequency是一种针对关键词的统计分析方法,用于评估一个词对一个文件集或者一个语料库的重要程度。一个词的重要程度跟它在文章中出现的次数成正比,跟它在语料库出现的次数成反比。这种计算方式能有效避免常用词对关键词的影响,提高了关键词与文章之间的相关性。
(7)基于Silk的知识融合
Silk是一个集成异构数据源的开源框架。编程语言为Python。提供了专门的 Silk-LSL 语言来进行具体处理。提供了图形化用户界面Silk Workbench,用户可以很方便的进行记录链接。
Silk 的整体框架如下图所示:

(8)使用Dedupe包实现实体匹配
dedupe是一个python 包,在知识融合领域有着重要作用!主要就是用来实体匹配。dedupe是一个用于fuzzy matching, record deduplication 和 entity-resolution的python库。它基于active learing的方法,只需用户标注它在计算过程选择的少量数据,即可有效地训练出复合的blocking方法和record间相似性的计算方法,并通过聚类完成匹配。dedupe支持多种灵活的数据类型和自定义类型。
dedupe 论文:http://www.cs.utexas.edu/~ml/papers/marlin-dissertation-06.pdf
dedupe 源码:https://github.com/dedupeio/dedupe
dedupe demo: https://github.com/dedupeio/dedupe-examples
dedupe 中文网站:dedupe: 知识链接python库 - 工具 - 开放知识图谱
dedupe 官方网站:Dedupe 2.0.17 — dedupe 2.0.17 documentation
dedupe API说明:Library Documentation — dedupe 2.0.17 documentation
4.3知识加工(Knowledge Processing)
海量数据在经信息抽取、知识融合之后得到一系列基本的事实表达,但这并不等同于知识,要想获得结构化,网络化的知识体系,还需要经过质量评估之后(部分需要人工参与甄别),才能将合格的部分纳入知识体系中以确保知识库的质量,这就是知识加工的过程。知识加工主要包括3方面内容:本体构建、知识推理和质量评估。
4.3.1 相关概念
本体:定义了组成领域的词汇表的基本术语及其关系,以及结合这些术语和关系来定义词汇表外延的规则。
领域:一个本体描述的是一个特定的领域。
术语:指给定领域中的重要概念。
基本术语之间的关系:包括类的层次结构,包括并列关系、上下位关系等等。
词汇表外延的规则:包括属性、值约束、不相交描述。
4.3.2本体构建
本体构建过程包含三个阶段:实体并列关系相似度计算>实体上下位关系抽取>本体的生成.
比如对下面这个例子,当知识图谱刚得到“阿里巴巴”、“腾讯”、“手机”这三个实体的时候,可能会认为它们三个之间并没有什么差别,但当它去计算三个实体之间的相似度后,就会发现,阿里巴巴和腾讯之间可能更相似,和手机差别更大一些。
这就是第一步的作用,但这样下来,知识图谱实际上还是没有一个上下层的概念,它还是不知道,阿里巴巴和手机,根本就不隶属于一个类型,无法比较。因此我们在实体上下位关系抽取这一步,就需要去完成这样的工作,从而生成第三步的本体。
当三步结束后,这个知识图谱可能就会明白,“阿里巴巴和腾讯,其实都是公司这样一个实体下的细分实体。它们和手机并不是一类。”
4.3.3知识推理(Knowledge Inference)
完成了本体构建这一步之后,一个知识图谱的雏形便已经搭建好了。但可能在这个时候,知识图谱之间大多数关系都是残缺的,缺失值非常严重,可以使用知识推理技术,去完成进一步的知识发现。知识推理就是指从知识库中已有的实体关系数据出发,经过计算机推理,建立实体间的新关联,从而扩展和丰富知识网络。
知识推理工具调研:知识推理工具
(1)单调推理机https://hub.docker.com/r/zb1840/montony_inference/
单调推理机 montony-inference是一个基于perl语言的内存计算框架的单调语义推理软件。输入为两部分。1事实抽取出三元组。2自定义的一套规则语法的三元组。输出为推理后得出的事实三元组,使用排列组合算法产生新事实加入内存再次迭代计算,一直到没有新的事实产生输出。
(2)RacerPro : OWL推理器和推理服务器RacerPro
RacerPro是语义网的OWL推理器和推理服务器。 RACER代表Renamed ABox和Concept Expression Reasoner。 RacerPro是软件的商业名称。
(3)Jena:建立链接数据的java框架Jena
Jena用来构建语义Web和关联数据的免费开源的Java框架。它为RDF,RDFS和OWL,SPARQL,GRDDL提供了一个编程环境,并且包括基于规则的推理引擎。
(4)RDFox: 牛津大学的知识库推理工具RDFox
RDFox是一个高度可扩展的内存RDF三元组存储,支持共享内存并行OWL 2 RL推理。 它是用C ++编写的跨平台软件,带有一个Java包装器,允许与任何基于Java的解决方案(包括OWL API)轻松集成。
(5)Virtuoso: 老牌的知识库查询存储推理技术平台Virtuoso
Virtuoso是一个可扩展的跨平台服务器,将关系,图形和文档数据管理与Web应用程序服务器和Web服务平台功能相结合。Virtouso也是一个OWL推理者。Virtuoso直接提供RDB2RDF(以前称为SQL2RDF)通过Sponger及其墨盒,它还可以从GRDDL,RDFa,微格式和更多输入提供RDF。
(6)GraphDB:语义数据查询推理引擎GraphDB Downloads and Resources
GraphDB(前OWLIM)是最可扩展的语义库。 它包括三元组存储,推理引擎和SPARQL查询引擎。它被封装为Sesame RDF数据库的存储和推理层(SAIL)。GraphDB使用TRREE引擎执行RDFS,OWL DLP,OWL Horst推理和OWL 2 RL。 最支持的表达式语言是OWL 2 RL,包含RDFS。 GraphDB提供可配置的推理支持和性能。
(7)Hermit: OWL推理机HermiT Reasoner: Home
HermiT是使用OWL编写的本体论的推理者。给定一个OWL文件,HermiT可以确定本体是否一致,识别类之间的包含关系等等。HermiT是第一个公开可用的OWL推理器,基于一种新颖的“超高级”演算,提供比任何以前已知的算法更有效的推理。以前需要几分钟或几小时进行分类的本体通常可以通过HermiT分类为秒,并且HermiT是能够对一些本体进行分类的第一推理器,这些本体以前被证明对于任何可用系统来说太复杂。
(8)FaCT++: OWL DL推理器 OWL : FaCT++
FaCT++是一个在C ++中实现的OWL DL推理器。它是一个基于tableaux的表达式描述逻辑(DL)的推理器。 它涵盖OWL和OWL 2(不支持关键约束和一些数据类型)基于DL的本体语言。 它可以用作独立的DIG推理器,或作为基于OWL API的应用程序的后端推理器。 现在它被用作ProtégéOWL编辑器中的默认推理器之一。
4.3.4 更新与维护
在知识图谱更新过程中,根据知识表达的方法可以发现一些新出现的实体,属性以及关系。在构建的一般步骤包括关系属性的抽取,实体关系的抽取以及实体关系的推理过程中,需要把海量的实体、属性、关系转化为机器能够读懂的知识表示方法(XML/OWL)。知识图谱的更新包含数据模式层更新和数据层更新,又可以按照层次进行划分定义为实体属性的更新和推理过程的更新。在知识图谱更新过程中,根据知识表达的方法可以发现一些新出现的实体、属性
(1)数据模式层更新
数据模式层是教育知识图谱体系中最为重要的一个层次,是数据的整理与实体关系储存的管理层面。在数据模式层,以语义网的形式存储着大量实体、实体的一般属性。在知识图谱的更新过程中,掌握着更新层次的主体推理算法。如果更新时间小于上一次数据库同步的时间,便可以利用算法对实体进行更新,对实体属性进行增加修改操作。如果推理算法可扩展性强,还可以对实体间关系进行预测补全。
现阶段在数据模式层的更新过程中,一般采用两种方式进行更新操作。一为整体数据替换的方式,在数据集成存储中整体下载成规模的结构性数据并进行符合当前知识图谱本体规则的重塑。第二种方式是借助网络众包的形式进行碎片化知识整理。
(2)数据层更新
知识图谱的数据更新方式与传统数据库的数据更新有所不同。传统模式的数据更新只关注于数据的本身操作,更在乎于数据的更新时间或有无脏读等模式化操作。并没有考虑整体的结构。知识图谱的更新与维护当中,须要寻找待更新实体以及持续补充实体间的关联,采用良好的实体显示模型,可以判断两个实体间的关联,这叫做知识图谱的补全。
在不同角度解决复杂关系模型的问题上,可选取较为简单准确的Trans E推理模型加以改进,得出更新过程中需要改进的最大实体数,作为关联更新算法的数据源加以利用。确定更新算法,采用知识表示模型对知识图谱中实体进行增加,修改操作。确定实体间关系后,谨慎处理实体间删除操作。增加时间戳并且限定更新空间,估算更新频率,改进更新关联算法。使得知识图谱在最短的时间效率内更新最大化实体,考虑更新频率的优化问题,单位时间内减少更新次数。
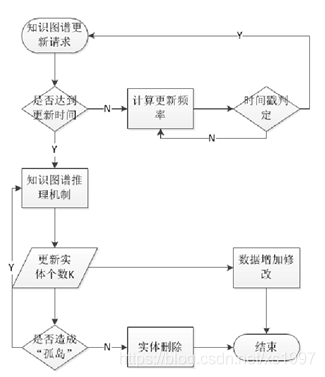
知识图片更新流程
五、知识图谱分析工具及开源项目代码
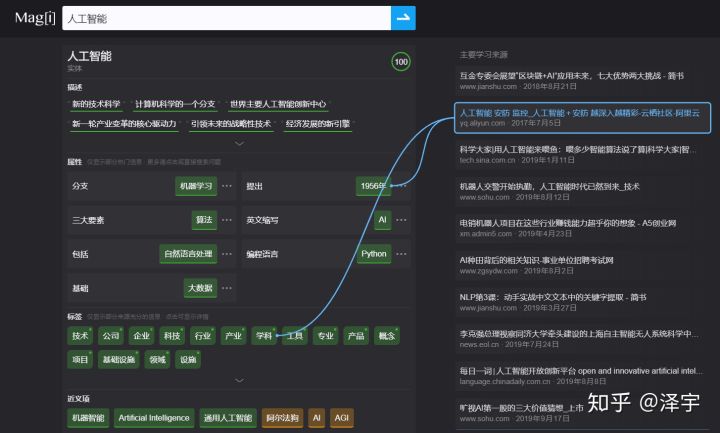
(1)知识图谱搜索引擎Magi
Magi 是由Peak Labs研发的基于机器学习的信息抽取和检索系统,它能将任何领域的自然语言文本中的知识提取成结构化的数据,通过终身学习持续聚合和纠错,进而为人类用户和其他人工智能提供可解析、可检索、可溯源的知识体系。
(2)中文知识图谱资源库
OpenKG包含16类的知识图谱,同时包括56个知识图谱相关工具,此外经常发布知识图谱论文解读。
- OpenKG开放资源共享平台: http://OpenKG.CN
- 中文开放知识图谱Schema:http://cnSchema.org
- 中文开放知识图谱众包平台:Openbase
(3)Github上的一些优秀的知识图谱项目
1.利用网络上公开的数据构建一个小型的证券知识图谱/知识库
https://github.com/lemonhu/stock-knowledge-graph
2. 医疗保险领域知识图谱
https://github.com/AdiaLoveTrance/MedicalInsuranceKG
3. 农业知识图谱(AgriKG):主要功能包括命名实体识别,实体查询,关系查询,农业知识分类,农业知识问答
https://github.com/qq547276542/Agriculture_KnowledgeGraph
1.命名实体识别
2.实体查询
3. 关系查询,搜索与某一实体相关的实体以及他们之间的关系:
4.知识问答
4. 漫威英雄的知识图谱
https://github.com/YZHANG1270/Marvel_KnowledgeGraph
5. 基于知识图谱的《红楼梦》人物关系可视化及问答系统
https://github.com/chizhu/KGQA_HLM
6. 小型金融知识图谱构建流程
https://github.com/jm199504/Financial-Knowledge-Graphs
7. 中式菜谱知识图谱可视化(CookBook-KG)
https://github.com/ngl567/CookBook-KG
8. 从无到有构建一个电影知识图谱,并基于该KG,开发一个简易的KBQA程序
https://github.com/SimmerChan/KG-demo-for-movie
9. 上市公司高管图谱
https://github.com/Shuang0420/knowledge_graph_demo
10. 红楼梦人物关系图谱
https://github.com/chizhu/KGQA_HLM
11. 通用领域知识图谱
https://github.com/Pelhans/Z_knowledge_graph
12. 免费1.5亿实体通用领域知识图谱

