
- 1Ansible+Shell+Containerd部署k8s
- 2linux kernel内存管理之/proc/meminfo下参数介绍_sunreclaim
- 3到店上门服务源码:同城生活新助手
- 4C#上位机开发(一)—— 了解上位机_怎么介绍一个上位机软件项目
- 5计算机二级考试-Python程序语言设计(部分题库)_python计算机二级
- 61541:【例 1】数列区间最大值_541:【例 1】数列区间最大值
- 7CrossOver Mac 谁说Mac不能玩游戏? 有了CrossOver,你也能在Mac上玩《幻兽帕鲁》等热门游戏_crossover 支持的游戏
- 8《工业控制系统信息安全防护指南》实施建议 (上)_江苏省工业信息安全防护实施指南
- 9ps顶级调色技术解密视频教程 终极大法_ps一级二级调色大片视频教程大全
- 10对话元境 王矛,详解元境蓝图:以全面的技术重新定义计算范式
浙大PhD张圣宇——大规模多模态因果预训练
赞
踩
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
今日视频推荐
本期AI TIME PhD直播间,我们有幸邀请到浙江大学计算机科学与技术学院博士生张圣宇,大家分享他的研究工作——大规模多模态因果预训练
嘉宾介绍

张圣宇:
浙江大学计算机科学与技术学院博士生三年级,导师为吴飞老师。研究方向为稳定学习,多模态理解,和推荐系统。在KDD,ACM MM,WWW,SIGIR等会议上发表了多篇长文论文。
个人主页:
https://shengyuzhang.github.io/
主要内容
大规模预训练旨在可轻易大量获得的无标注(或单一标注)数据上学习到与具体下游任务无关的通用表征,以迁移到只有少量标注的具体下游任务上,实现“微调即可用”(如图1)。大规模预训练可追溯到在大型数据集(例如ImageNet[2])上对AlexNet[1],VGG[4]和ResNet[3]等主干模型进行预训练,然后将知识迁移到众多下游计算机视觉任务。自此,预训练开始成为深度学习成功的标志。
最近,在自然语言处理研究领域,基于Transformer和Bert的预训练模型[5,6,7,8,9]的研究工作激增,并且在各类自然语言处理任务中都达到了最佳性能。

图1 预训练链路框架图
视觉或语言单一模态的理解对于视觉或语言任务是必不可少的,不同模态间的相互关系也同样重要,例如,如果下游的多模态模型无法将相关的视觉对象和语言单词在表征上进行联系,则预训练好的单一模态的特征在许多任务无法实现“微调即可用”的能力。因此,在大规模无标注的多模态数据上学习到有利于下游任务关联、理解和推理的特征是非常重要的研究任务[10]。

图2 超大规模跨模态数据集Conceptual Caption中存在的虚假关联问题
相比于直接在下游任务上从零开始进行训练,预训练的特征或模型在带来知识的同时也引入了预训练数据集中的偏差(Biases)[11]。预训练数据集偏差可能对域内(In-domain)数据测试有用,但可能会损害域外(Out-of-domain)数据测试[12],其原因在于虚假关联的产生[13]。例如,如图2所示,在Conceptual Caption数据集中,我们观察到在给定“Instrument”(语言词)的情况下,出现”shirt”(视觉对象)的条件概率很大,即

但是这两者之间没有因果关系。没有因果关联的两个事物在数据集中却被频繁观测到,这看似很奇怪,但在因果理论中可以被有效形式化。如图3所示,我们观测到两个事务X和Y具有很强的关联性(有很多相关的数据都含有<X, Y>数据对),是否就可以判断X到Y具有因果效应,从而让模型放心大胆的学习这种效应呢?答案是否定的,从因果的角度,我们观测到X和Y频繁出现,可能是由于X和Y有共同的共因Z。换句话说,有观测到Z的时候,我们通常也会观测到X(Z→X),和Y(Z→Y),而仅观测到X的时候(没有Z),却很少出现Y(X!→Y),即Z构成了X和Y之间的混淆因子。
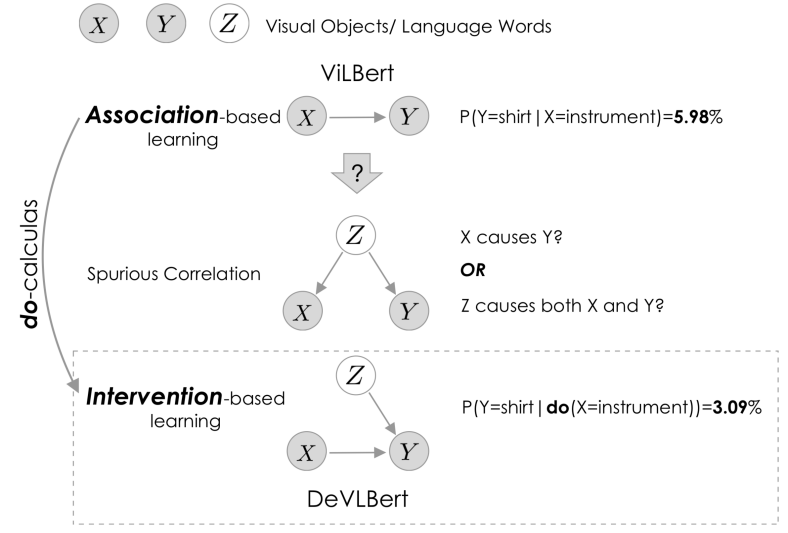
图3 没有因果效应的关联原因在于混淆因子Z
我们可能无法责怪预训练数据集本身,因为我们不能保证数据收集的过程是绝对公平的。通过扩充预训练数据可以通过防止数据样本分布稀缺从而缓解此类问题[11],但是这种策略在数据收集和计算方面都是昂贵的。
在本次研究中,我们将从因果推理研究中汲取灵感,并借鉴后门调整(也称为协变量调整或统计调整)[14]的思想缓解预训练中的偏差问题。通过后门调节(去混杂),可以将
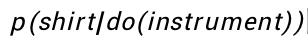
降低到3.10%(更多的案例请参见图3)。后门调整的实质是在评估给定条件(instrument)的效果时,控制条件(instrument)不受其他潜在混杂因素(Confounder)的影响。通过这种方式,我们旨在减轻数据中可能存在的虚假相关,并提出基于干预的预训练,学习可以很好地迁移到具有未知数据分布的下游任务的通用无偏差的视觉语言表示形式,实现基于大规模多模态因果预训练的泛内容理解。

图2 干预前(红色)后(蓝色)视觉物体和语言单词之间的条件概率
因果和预训练的结合主要需要解决以下几个问题:
1)明确是什么样的模型结构和预训练目标产生了上述的虚假关联。
2)哪些因素是导致虚假关联的潜在混淆因子,它们是否是可观测到的,是否可以隐式表征从而建模。
3)如何在模态内部进行干预消除模态内混淆。
4)如何在模态间进行干预消除模态间混淆。
本文拟针对大规模多模态预训练中存在的数据偏差问题,利用因果理论分析Bert预训练的目标函数,并建模可能导致数据偏差的因素。在Bert结构基础上提出多个可能的基于干预的去偏差条件预测模块,以替代或增强MLM目标。通过多个下游任务实验测试多个模块的泛化能力,可视化因果干预带来的可解释作用。
目前大规模多模态预训练的常用模型框架是Bert(Bidirectional Encoder Representation Transformer)。以自然语言预训练为例,Bert的MLM(Masked Language Modeling)预训练任务会随机遮掩一个语言单词Y,其他的某一个(或所有)语言单词表示为X,Bert建模了P(Y/X)。从因果的分析视角,在该条件预测中可能会有混淆因子Z同时影响X和Y,如果在预测X对Y的影响时不控制Z的影响,则可能会得出关于X和Y之间的一些错误结论,因为部分或全部影响可能来自X。
根据贝叶斯公式,可以得到:
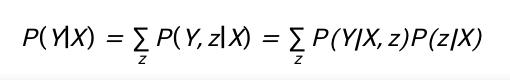
我们的目标是在评估X对Y的影响时利用do算子(do-calculus)消除任何对受干预变量X的影响,可以得到:

该式和上式的区别在于消除了在评估X对Y影响时z和X之间的影响。然而由于需要对每一个z都需要单独讨论,对每一个z都单独建立一个模型是不可行的,因此我们利用Normalized Weighted Geometric Mean方法,当模型最后预测结果为softmax分类时,可以近似得到:

到了这一步,建模P(Y|do(X))只需要合适的选取潜在的混淆因子z,并使用Bert有效建模
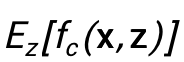
对于混淆因子的选取和去混淆,我们考虑如下三种方式:
1) 视觉去混淆
我们将每种视觉物体视作潜在的混淆因子,比如猫和衬衫。为了得到每种混淆因子的表征,我们首先使用预训练得到的物体检测器抽取每张图片中的物体表征,然后将同物体类别在不同图的表征进行平均得到该物体类别的表征。这样,我们构成了视觉混淆因子字典。
2) 语言去混淆
在自然语言中,直觉上可以将每一个词视作潜在的混淆因子,但是这样会造成混淆因子字典数目较大,影响训练效率。因此,我们提炼自然语言中的名词作为潜在的混淆因子,名词具有和视觉物体类似的含义,可以与视觉混淆因子保持语义上的接近。为了得到每种混淆因子的表征,和视觉做法类似,我们使用预训练的Bert得到相同名词在不同文本中的上下文表征,然后将这些表征进行平均得到该名词的表征。这样,我们构成了自然语言混淆因子字典。
3) 跨模态去混淆
在扩模态预训练中,建模视觉/文本特征时也会用到文本/视觉的信息作为上下文,因此,视觉-文本跨模态之间也会产生混淆,我们在建模视觉/文本特征时也会考虑文本/视觉的混淆因子字典,进行跨模态去混淆。
为了有效建模该式中的

并和Bert结构结合,本研究提出了四种结构和方法,如图3所示。
1) 模型A
我们首先探索如何通过干预来增强掩码语言模型(MLM),这是因为1)MLM是最常用的预训练代理任务之一。2)MLM仅基于似然估计,这可能会引入虚假关联。我们以自然语言预训练为例进行说明。Wt对于一个被屏蔽的单词Wt,由于Wt不包含来自单词本身(单词本身被掩盖)的信息,因此可以最终表示Wt视为Xt。但是,要在单个推理中找到包含单词Wt信息的Yt并不容易。我们选择进行另外一次推断(在该推断中没有任何词被掩盖)。因此在第二次推断中,单词
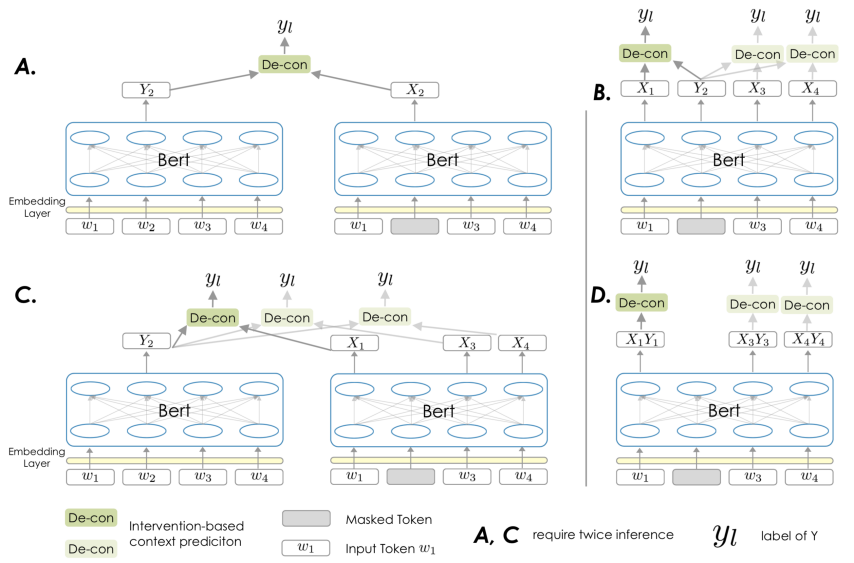
图3 四种基于干预的Bert风格因果预训练模型结构示意图
Wt的最终表示可以视为y。在图3的A子图描绘了该实现。
2) 模型B
图3B所示为增强MLM的另外一种实现。在MLM的框架下,Bert搜集上下文中与被掩盖的Wt相关的信息并进行汇总,以预测Wt的标签。从这个角度来看,被掩盖的单词Wt的最终表示可以看作是Yt,而每一个未被掩盖的单词的最终表示可以被看作x。这种设计比模型A更为高效,因为不需要额外的推理过程。
3) 模型C
模型C是模型A的一个变种,其将每一个未被掩盖的单词的最终表示看作x和模型A不同的是,模型C并没有影响MLM目标,而是在MLM之上增加了新的训练目标。
4) 模型D
模型D将每一个未被掩盖的单词视作和其对应的x和y的融合特征,它不需要像模型A和模型C一样的二次推断过程,同时和C一样不影响MLM目标,因此是一种非侵入式的设计。
我们在超大规模多模态数据集Conceptual Caption数据集上进行了因果预训练,并在多个与Conceptual Caption数据分布不同的数据集上进行了下游任务的训练和测试,这样可以更好的评估我们的方法是否能在数据分布迁移中实现更好的性能。我们在图片检索,零样本图片建模和视觉问答三个下游任务上进行了测试,对比了SCAN和BUTD两个特定领域的SOTA模型,和只使用下游任务数据的VisualBert、只使用和下游任务数据无关数据的ViLBERT(Out-of-domain Pretraining),和同时使用下游任务数据和领域无关数据的InterBert。
表1 多预训练模型对比模型在多下游任务上的对比

可以看到,我们的因果预训练模型DeVLBert相对于特定领域SOTA模型,和ViLBERT、VisualBert都取得了显著的提升。相对于同时使用下游任务数据集的InterBert,我们在图片检索任务上取得了接近的性能,并在视觉问答任务上取得了提升。这些结果验证了我们模型的有效性。
为了从人的视角直观展示因果预训练的优势,我们可视化了DeVLBert(每个案例的左侧)和 ViLBERT(右侧)中最后一个跨模态注意力层的注意力权重最大的视觉物体(红、绿框)和文本单词对(以及对应的注意权重)。我们从下游任务的测试/验证集中采样案例,考虑图像检索(上半部分)和 视觉问答(下半部分)两个下游任务。

可以看到,以第三行第一个案例为例,VilBert容易受文本“clouds”和视觉物体“Sky”虚假关联影响,关注到错误视觉区域,并给出了错误的回答。相对应的,DeVLBert通过减弱虚假关联, 关注到正确的视觉物体区域 “clouds”,给出正解。同时,以第三行第4个案例为例,VilBert受文本“sitting”和视觉物 体“table”虚假关联影响,关注到 错误视觉区域。相反,DeVLBert通过减弱虚假关联,注意到 更少共现 但正确的区域 “cutting board”,给出统计意义上更少出现的正解
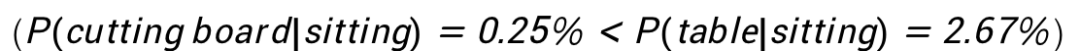
参考文献:
[1] Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. 2012. “ImageNet Classification with Deep Convolutional Neural Networks.” In Advances in Neural Information Processing Systems, Lake Tahoe, Nevada, United States.
[2] Deng, Jia, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Fei-Fei Li. 2009. “ImageNet: A Large-Scale Hierarchical Image Database.” In IEEE Computer Society Conference on Computer Vision and Pattern Recognition.
[3] He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. “Deep Residual Learning for Image Recognition.” In IEEE Conference on Computer Vision and Pattern Recognition.
[4] Simonyan, Karen, and Andrew Zisserman. 2015. “Very Deep Convolutional Networks for Large-Scale Image Recognition.” In 3rd International Conference on Learning Representations.
[5] Conneau, Alexis, and Guillaume Lample. 2019. “Cross-Lingual Language Model Pretraining.” In Advances in Neural Information Processing Systems.
[6] Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. “BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding.” In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies.
[7] Dong, Li, Nan Yang, Wenhui Wang, Furu Wei, Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming Zhou, and Hsiao-Wuen Hon. 2019. “Unified Language Model Pre-Training for Natural Language Understanding and Generation.” In Advances in Neural Information Processing Systems.
[8] Liu, Yinhan, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. “RoBERTa: A Robustly Optimized BERT Pretraining Approach.” CoRR abs/1907.11692.
[9] Song, Kaitao, Xu Tan, Tao Qin, Jianfeng Lu, and Tie-Yan Liu. 2019. “MASS: Masked Sequence to Sequence Pre-Training for Language Generation.” In Proceedings of the 36th International Conference on Machine Learning.
[10] Lu, Jiasen, Dhruv Batra, Devi Parikh, and Stefan Lee. 2019. “ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks.” In Advances in Neural Information Processing Systems.
[11] Yang, Xu, Hanwang Zhang, and Jianfei Cai. 2020. “Deconfounded Image Captioning: A Causal Retrospect.” CoRR abs/2003.03923.
[12] Kuang, Kun, Peng Cui, Susan Athey, Ruoxuan Xiong, and Bo Li. 2018. “Stable Prediction across Unknown Environments.” In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining.
[13] Pearl, Judea, Madelyn Glymour, and Nicholas P Jewell. 2016. Causal Inference in Statistics: A Primer. John Wiley & Sons.
[14] Shanmugam, Ram. 2001. “Causality: Models, Reasoning, and Inference : Judea Pearl; Cambridge University Press, Cambridge, UK, 2000, Pp 384, ISBN 0-521-77362-8.” Neurocomputing 41 (1–4): 189–90.
相关资料
论文标题:
DeVLBert: Learning Deconfounded Visio-Linguistic Representations
论文链接:
https://dl.acm.org/doi/10.1145/3394171.3413518
PPT下载:
公众号后台回复“浙大2”获取下载链接
AI TIME欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你!
请将简历等信息发至yun.he@aminer.cn!
微信联系:AITIME_HY
AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注

(点击“阅读原文”观看回放)

