
- 1Sql注入截取字符串常用函数
- 2麻雀算法优化BP神经网络回归分析,麻雀算法优化BP神经网络回归预测,麻雀优化算法改进BP神经网络客流量预测
- 3虚幻引擎图文笔记:调整网格的光照贴图分辨率(Light Map Res)改善光照烘焙质量_虚幻5 lightmap 调整
- 4java root权限_有没有办法让Java应用获得root权限?
- 5chatGPT衣食住行10种场景系列教程(01)chatGPT热点事件+开发利器_openaiclientfactory.createclien
- 6Android进程间通信(三):Bundle、文件共享、Messenger_android message 携带2m文件
- 7超详细!机器学习期末考试知识点汇总,助你一臂之力,直击高分!
- 8六、confluence的使用_confluence换手机绑定登录
- 9harmonyOS鸿蒙官网教程-添加弹窗_鸿蒙弹窗提醒
- 10使用setInterval执行定时器造成的倒计时误差问题修改_setinterval 倒计时差几秒
Python多线程爬虫——数据分析项目实现详解_python如何多线程爬虫
赞
踩
前言

前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家:https://www.captainbed.cn/z
「个人网站」:雪碧的个人网站

ChatGPT体验地址

爬虫
爬虫是指一种自动化程序,能够模拟人类用户在互联网上浏览网页、抓取网页内容、提取数据等操作。爬虫通常用于搜索引擎、数据挖掘、网络分析、竞争情报、用户行为分析等领域。

我们以爬取某个用户的博文列表并存储到文件中实现多线程爬虫为例,带大家体验爬虫的魅力
获取cookie
首先我们在爬取网站的时候首先获取cookie
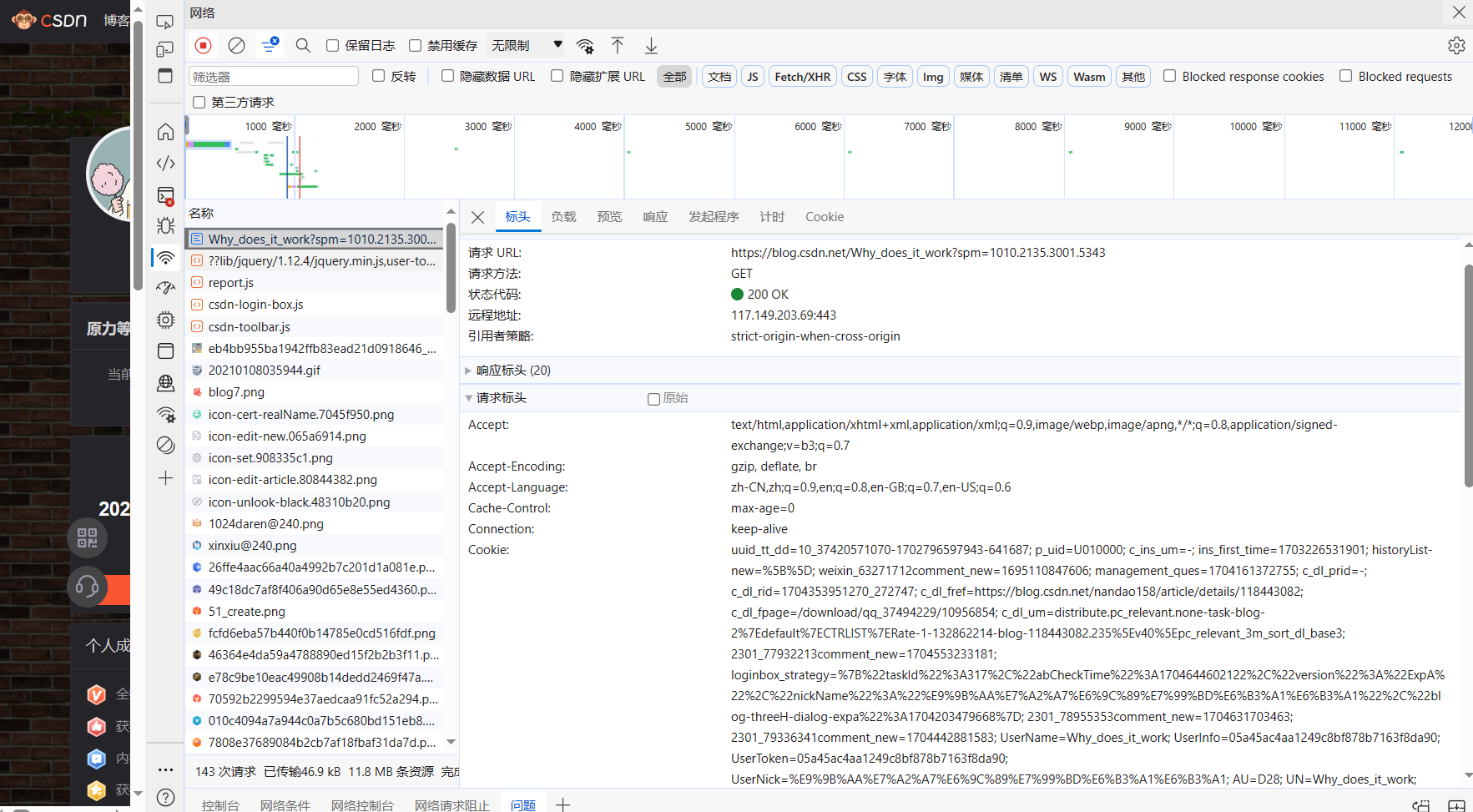
拿我的博客主页为例,用F12打开控制台,点击网络,找到cookie
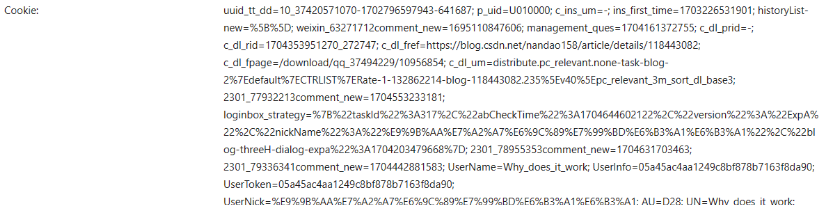
创建一个cookie文件,复制进去
然后从给定的cookie_path文件中读取cookie信息,并将其存储在一个字典中。函数返回这个字典。
具体如下
def get_headers(cookie_path:str):
cookies = {}
with open(cookie_path, "r", encoding="utf-8") as f:
cookie_list = f.readlines()
for line in cookie_list:
cookie = line.split(":")
cookies[cookie[0]] = str(cookie[1]).strip()
return cookies
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
网站爬取与启动
CSDN爬虫
class CSDN(object):
def init(self, username, folder_name, cookie_path):
# self.headers = {
# "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36"
# }
self.headers = get_headers(cookie_path)
self.s = requests.Session()
self.username = username
self.TaskQueue = TaskQueue()
self.folder_name = folder_name
self.url_num = 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
headers: 这是一个字典,用于存储请求头信息。s: 这是一个会话对象,用于保持与CSDN网站的连接。username: 这是一个字符串,表示CSDN用户的用户名。TaskQueue: 这是一个任务队列对象,用于管理待访问的URL。folder_name: 这是一个字符串,表示保存爬取结果的文件夹名称。_name: 这是一个整数,表示当前保存的文件夹编号。_num: 这是一个整数,表示当前爬取的页面编号。
爬虫启动
def start(self):
num = 0
articles = [None]
while len(articles) > 0:
num += 1
url = u'https://blog.csdn.net/' + self.username + '/article/list/' + str(num)
response = self.s.get(url=url, headers=self.headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
articles = soup.find_all('div', attrs={"class":"article-item-box csdn-tracking-statistics"})
for article in articles:
article_title = article.a.text.strip().replace(' ',':')
article_href = article.a['href']
with ensure_memory(sys.getsizeof(self.TaskQueue.UnVisitedList)):
self.TaskQueue.InsertUnVisitedList([article_title, article_href])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 初始化一个变量
num,用于表示当前访问的文章页码。- 初始化一个列表
articles,用于存储待处理的文章信息。- 使用一个
while循环,当articles列表中的文章数量大于0时,执行循环体。- 更新
num变量,表示当前访问的文章页码。- 构造一个URL,该URL包含当前用户名、文章列表和页码。
- 使用
requests库发送请求,并获取响应。- 使用
BeautifulSoup库解析HTML内容,并提取相关的文章信息。- 遍历提取到的文章列表,提取文章标题和链接。
- 将文章标题和链接插入到任务队列
TaskQueue的未访问列表中。
将爬取内容存到文件中
- 打印爬取开始的信息。
- 计算并获取存储博文列表的文件路径。
- 使用
open函数以写入模式打开文件,并设置文件编码为utf-8。 - 写入文件头,包括用户名和博文列表。
- 遍历任务队列
TaskQueue中的未访问列表,将每篇文章的标题和链接写入文件。 - 在每篇文章标题和链接之间添加一个空行,以提高可读性。
- 更新一个变量
_num,用于表示当前已写入的文章序号。
代码如下
def write_readme(self):
print("+"*100)
print("[++] 开始爬取 {} 的博文 ......".format(self.username))
print("+"*100)
reademe_path = result_file(self.username,file_name="README.md",folder_name=self.folder_name)
with open(reademe_path,'w', encoding='utf-8') as reademe_file:
readme_head = "# " + self.username + " 的博文\n"
reademe_file.write(readme_head)
for [article_title,article_href] in self.TaskQueue.UnVisitedList[::-1]:
text = str(self.url_num) + '. [' + article_title + ']('+ article_href +')\n'
reademe_file.write(text)
self.url_num += 1
self.url_num = 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
列表文件生成之后,我们要对每一个链接进行处理
def get_all_articles(self): try: while True: [article_title,article_href] = self.TaskQueue.PopUnVisitedList() try: file_name = re.sub(r'[\/::*?"<>|]','-', article_title) + ".md" artical_path = result_file(folder_username=self.username, file_name=file_name, folder_name=self.folder_name) md_head = "# " + article_title + "\n" md = md_head + self.get_md(article_href) print("[++++] 正在处理URL:{}".format(article_href)) with open(artical_path, "w", encoding="utf-8") as artical_file: artical_file.write(md) except Exception: print("[----] 处理URL异常:{}".format(article_href)) self.url_num += 1 except Exception: pass

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 从任务队列
TaskQueue中弹出未访问的文章链接和标题。- 尝试获取一个文件名,该文件名由文章标题生成,以避免文件名中的特殊字符。
- 计算并获取存储文章的文件路径。
- 创建一个Markdown文件头,包括文章标题。
- 获取文章内容,并将其添加到Markdown文件头。
- 将处理后的Markdown内容写入文件。
- 打印正在处理的URL。
- 更新一个变量
_num,用于表示已处理的文章数量。
多线程爬虫
实现多线程爬虫,以提高爬取速度。在循环中,会不断地创建新的线程来处理任务队列中的任务,直到任务队列为空。这样可以充分利用计算机的多核性能,提高爬取效率。
def muti_spider(self, thread_num):
while self.TaskQueue.getUnVisitedListLength() > 0:
thread_list = []
for i in range(thread_num):
th = threading.Thread(target=self.get_all_articles)
thread_list.append(th)
for th in thread_list:
th.start()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
我们在多线程爬虫的时候,要保证系统有足够的内存空间。通过使用contextlib库的contextmanager装饰器,可以轻松地实现上下文管理,确保内存分配和释放的正确性。
lock = threading.Lock()
total_mem= 1024 * 1024 * 500 #500MB spare memory
@contextlib.contextmanager
def ensure_memory(size):
global total_mem
while 1:
with lock:
if total_mem > size:
total_mem-= size
break
time.sleep(5)
yield
with lock:
total_mem += size
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
在__enter__方法中,使用with lock语句模拟加锁,确保在执行内存分配操作时,不会发生竞争条件。然后判断当前系统的总内存是否大于所需分配的内存空间,如果大于,则减少总内存,并跳出循环。
选择要爬取的用户
def spider_user(username: str, cookie_path:str, thread_num: int = 10, folder_name: str = "articles"):
if not os.path.exists(folder_name):
os.makedirs(folder_name)
csdn = CSDN(username, folder_name, cookie_path)
csdn.start()
th1 = threading.Thread(target=csdn.write_readme)
th1.start()
th2 = threading.Thread(target=csdn.muti_spider, args=(thread_num,))
th2.start()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 检查文件夹
folder_name是否存在,如果不存在,则创建该文件夹。 - 创建一个CSDN对象
csdn,用于模拟用户登录和爬取文章。 - 创建一个线程
th1,目标为_readme。 - 创建一个线程
th2,目标为_spider,并传入参数(thread_num,),用于指定线程数量。
这个函数的目的是爬取指定用户的CSDN博客文章,并将文章保存到文件夹folder_name中。通过创建线程,可以实现多线程爬虫,提高爬取速度。
线程池
线程池存储爬虫代理 IP 的数据库或集合。在网络爬虫中,由于目标网站可能会针对同一 IP 地址的访问频率进行限制,因此需要使用池来存储多个代理 IP 地址,以实现 IP 地址的轮换和代理。池可以提高爬虫的稳定性和效率,避免因为 IP 地址被封禁而导致的爬虫失效。
爬虫和池是爬虫领域中不可或缺的概念,池能够提高爬虫的稳定性和效率,同时帮助爬虫更好地适应目标的反爬虫策略。


