
- 1EHCI和OHCI,UHCI的比较和区别_ehci ohci uhci
- 2YOLOv3,YOLOv4学习_yolov3_cspdarknet_fpn
- 3自然语言处理NLP知识结构_自然语言处理功能模块结构图
- 4六何时适合使用蜻蜓优化算法?_蜻蜓优化算法应用领域
- 5【LSTM分类】基于鲸鱼算法优化空间注意力机制的卷积神经网络结合长短记忆神经网络KOA-CNN-LSTM-SAM-attention实现数据分类附matlab代码
- 6关于Clang
- 7【Phase One SDK】飞思相机SDK的环境配置及调用_phase one linux sdk
- 8小程序源码免费html5,微信小程序静态页面案例(附源码)
- 9Python数据分析,pandas对日期的处理_python记录不同年相同月份的数据
- 10分类和标注词汇(基于nltk)_nltk区分场景类名词和目标类名词
【飞桨PaddlePaddle】四天搞懂生成对抗网络(四)——CycleGAN的绝妙设计:双向循环生成的结构_shuffle=run_cfg.test_shuffle
赞
踩

“神仙姐姐”CycleGAN
在“风格迁移四部曲系列”的《风格迁移的“精神始祖”Conditional GAN》文章中,已经跟大伙一起在MNIST手写数据集上手撸了CGAN,让GAN学会了“认标签,写数字”。然后,我们将CGAN“拟合条件概率分布”的思想发扬光大,在文章《用CGAN做图像转换的鼻祖pix2pix》中,让GAN学会了“看图学画风”,并用学会的图片风格渲染新图片。到这里GAN是不是已经有了点艺术家的气质了~
但是,前面介绍的两个GAN只能算是“阿朱、阿碧”那样的小丫鬟。本项目介绍的CycleGAN才是真正的大小姐“王姑娘”。既然Pix2Pix也能干风格迁移的活儿,为什么就和CycleGAN丫鬟小姐不同命呢?打个比方,非是两个丫头不够聪明(Pix2Pix效果不够好),而是她们不认识字(适用范围窄),武功秘籍都得大侠念给她们听才能记得(得让训练集的两组图片一一对应才能训练)。王姑娘则从小接受书香门第的全面素质教育(CycleGAN经朱俊彦大神悉心改造),自家的武功秘籍还能可劲儿看(网上的图片按域特征分成两组就能喂给CycleGAN),自然识得天下武功(CycleGAN应用发扬光大)。再说,Pix2Pix效果再惊艳,也不能老蹭人家分割任务的数据集用吧。比如,下面这个将照片转变为大师画作的任务中,只要备好了一组照片和一组大师的作品作为数据集,CycleGAN就能轻松搞定:

而Pix2Pix要求“训练的两组图片要一一对应”,照片是什么内容画作也得是同一内容,结果就悲催了。总不能让大师照着照片给模型画训练集吧~
试想一下,用CycleGAN做一个游戏贴图的渲染器,把生化危机的场景贴图都换成自己学校风格的建筑,把“群众演员”的贴图换成蓝精灵...哈哈哈...
喜欢这个主意,就赶快抄起Paddle一起GAN吧~
CycleGAN的介绍
1.CycleGAN的原理
CycleGAN,即循环生成对抗网络,出自发表于 ICCV17 的论文《Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks》,和它的兄长Pix2Pix(均为朱大神作品)一样,用于图像风格迁移任务。以前的GAN都是单向生成,CycleGAN为了突破Pix2Pix对数据集图片一一对应的限制,采用了双向循环生成的结构,因此得名CycleGAN。
首先,CycleGAN也是一个GAN模型,通过判别器和生成器的对抗训练,学习数据集图片的像素概率分布来生成图片。原理已经在前面的文章《通俗理解经典GAN》中详细介绍过了。
要完成X域到Y域的图片风格迁移,就要求GAN网络既要拟合Y域图片的风格分布分布,又要保持X域图片对应的内容特征。打个比方,用草图风格的猫图片生成照片风格的猫图片时,要求生成的猫咪“即要活灵活现,又要姿势不变”。“拟合数据分布”本来就是GAN干的活儿,而“保持原图片特征”在Pix2Pix上是这么实现的(详解可参考《用CGAN做图像转换的鼻祖pix2pix》):
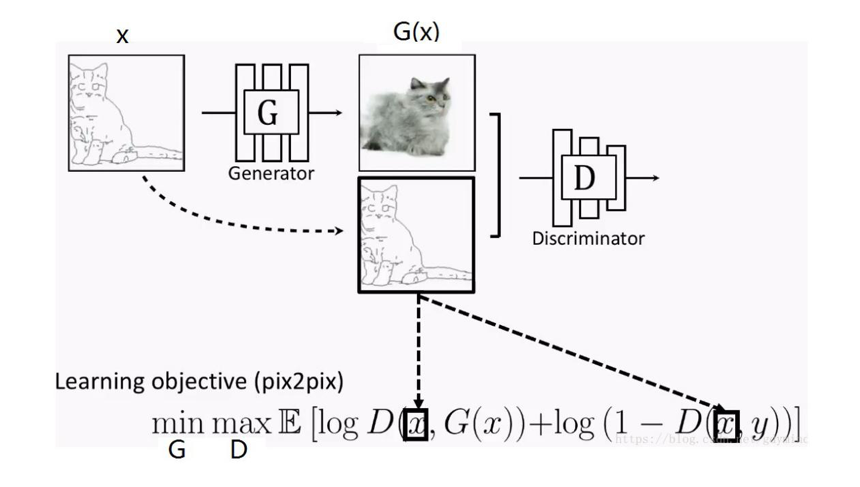
因为Pix2Pix是一个CGAN,所以,我们通过用X域图片当约束条件来限制Pix2Pix的输出Y域风格图片时保有X域图片的特征。
而送入CycleGAN的两组(X域Y域)图片没有一一对应关系,即使我们将X域图片当成限制条件输入到一个CGAN中,也起不到限制模型输出保有X域图片特征的作用。因为,送入的两组图片完全是随机配在一起,CGAN学不到任何联系。因此,CycleGAN采取了一个绝妙的设计:通过添加“循环生成”并优化一致性损失(Consistency Loss)来代替CGAN中使用的约束条件来限制生成器保有原域图片特征。这样就不需要训练集图片一一对应了。
2.CycleGAN的流程
下面,我们就来看看循环生成网络(CycleGAN)到底是怎么“循环起来”的:
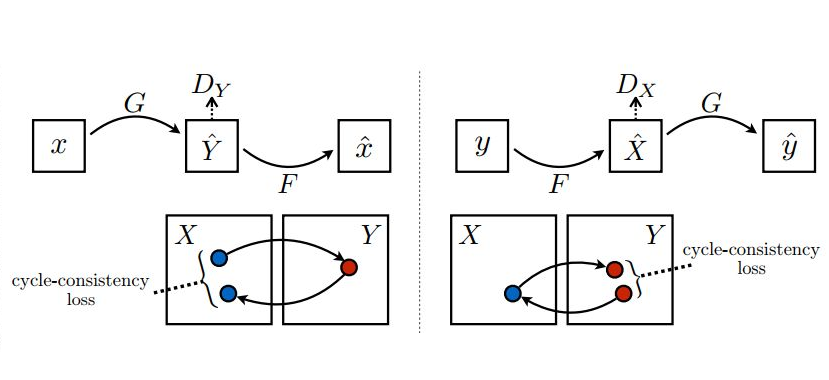
上图左半部分,将原域图片x送入(x2y方向)生成器G生成目标域图片y^,然后再将生成的目标域图片y^送入(y2x方向)生成器F反过来生成原域图片x^。生成x^的目的就是用它与输入的真图片x来算L1 Loss。我们知道Pix2Pix优化时除了使用GAN Loss(对抗损失)外,还加入了生成器输入图片和输出图片的L1 Loss来对齐生成图片与输入图片的宏观轮廓(所谓低频信息)。同样的逻辑,我们也能在CycleGAN中用L1 Loss来对齐“循环生成”的x^与输入的原图片x的内容自然,x生成的y^的轮廓也是和x对齐的了。这就达到了(原论文中的例子)“马变斑马,花纹变,姿势不变”的目的了。(我在网上看到的CycleGAN资料都没有点明这一点的,所以只好自行脑补,欢迎指正。)
在这个x->y^->x^的生成过程中,可以通过判别器Dy与生成器(x2y)G进行对抗训练。那么这个链条上的反向生成器(y2x)F怎么办?当然是加个判别器Dx与它进行对抗训练了。这样CycleGAN就有了两个方向相反的生成器,两个分别判别x域、y域图片的判别器。但要注意一个问题:就像GAN的生成器和判别器不能同时训练一样,Cyc1eGAN的两个生成器、两个判别器也只能一个一个训练,这就形成了CycleGAN训练的两条“环路”。
第一条就是刚才分析的上图左半部份的过程。在这个过程中先训练判别器Dy,再训练生成器G。判别器Dx和生成器F在上图右半部份的过程再训练。如此循环往复进行训练,生成的图片是这样的:

上图就是本项目训练的CycleGAN的部分训练输出。这是一个在selfie2anime数据集上训练的,将妹子照片转换成二次元风格图片CycleGAN。
3.CycleGAN的结构
接下来,我们再看看这两对判别器、生成器怎么摆:
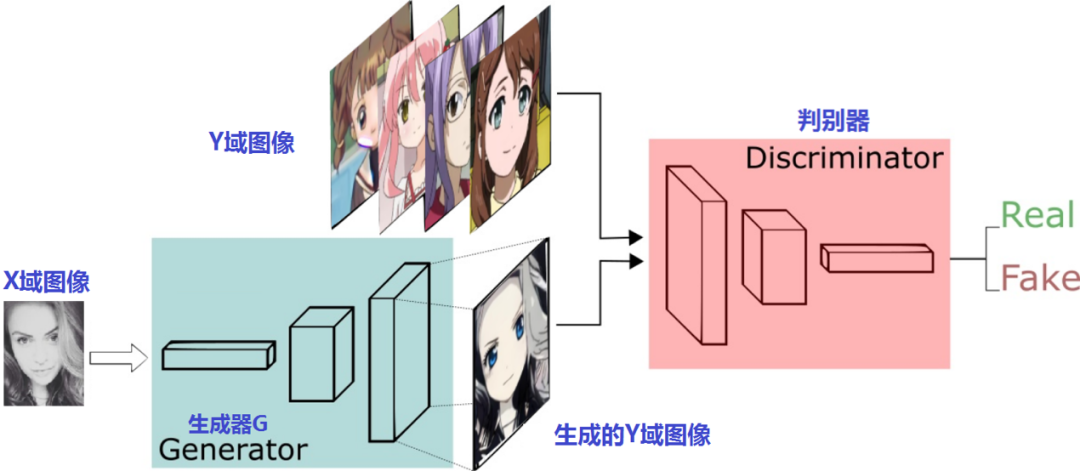
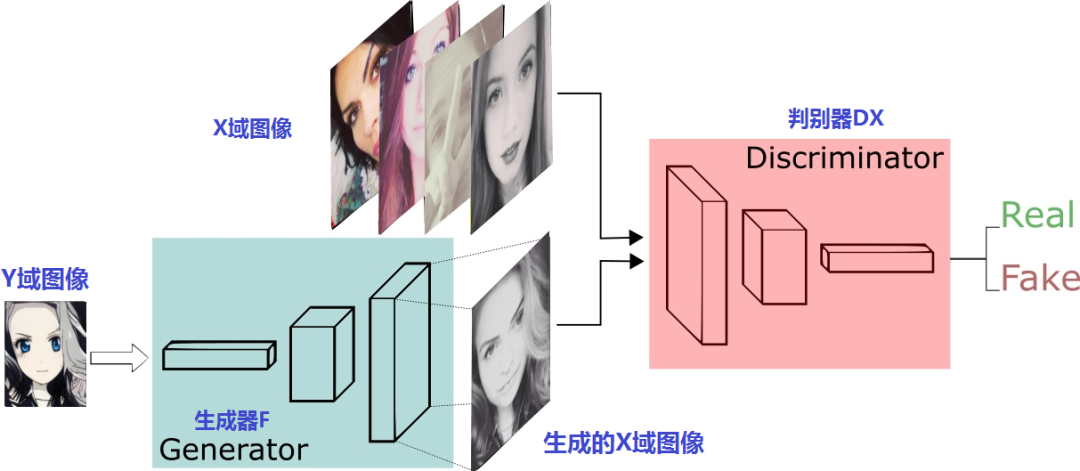
上半部份是生成器G和判别器Dy进行x2y的训练过程,下半部份是生成器F和判别器Dx进行y2x的训练过程。很像是两个风格迁移方向相反Pix2Pix模型,只是这两个GAN是普通GAN,不是Pix2Pix那样的CGAN。这一点,从生成器和判别器的输入就可以看出来,输入的只有原域图片并没有像Pix2Pix一样融合条件图片。
4.CycleGAN的loss函数
前面分析了CycleGAN的原理,我们已经知道了CycleGAN的loss由对抗损失(称为gan loss或adversarial loss)和循环一致性损失(consitency loss)组成,下面看看公式:
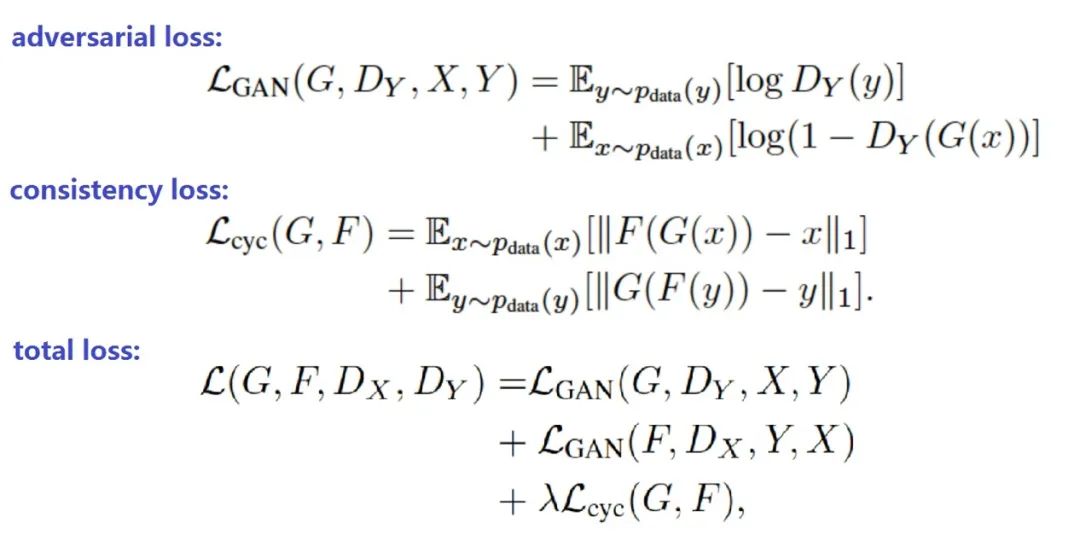
上面公式中:
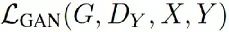 指的是x2y过程的对抗损失(adversarial loss)
指的是x2y过程的对抗损失(adversarial loss)
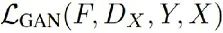 指的是y2x过程的对抗损失(adversarial loss)
指的是y2x过程的对抗损失(adversarial loss)
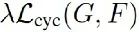 指的是生成器G和生成器F的循环一致性损失。
指的是生成器G和生成器F的循环一致性损失。
其中为循环一致性损失(consitency loss)的缩放系数,是一个超参数。
实际上,原论文的代码还加入了本体映射损失(identity loss),只是默认设置为关闭。CycleGAN正常训练时,生成器G输入x,生成y^。计算生成器G的本体映射损失(identity loss)时,生成器G输入y,生成y^,然后用y与y^的L1 loss作为G的identity loss。相应地,生成器F的identity loss则是输入的x与生成的x^的L1 loss。优化CycleGAN时,如果启用identity loss则将这两部分加到模型总loss中。与循环一致性损失(consistency loss)一样,也使用缩放系数超参控制其在总loss中所占比重。
论文中提到,CycleGAN使用identity loss的目的是在迁移的过程中保持原色调,下面是使用identity loss的对比效果:

上面图片最右边一列使用identity loss后果然纠正了生成器的色偏。
CycleGAN的实现
下面,我们就来用Paddle的动态图模式,实现这个将妹子照片转化为二次元风格的“讨喜神器”(单方精妙、小心炼制、谨慎使用~)。
1.数据集准备
将selfie2anime数据集解压到/home/aistudio/data/data50363/路径下,trainA文件夹下存储照片风格训练集图片,trainB文件夹下存储卡通风格训练集图片,testA和testB分别存储照片风格和卡通风格的测试集图片。数据集的读取器和上个文章《用CGAN做图像转换的鼻祖pix2pix》一样使用Paddle套件代码库里的脚本。与其不同的是,得益于CycleGAN的训练数据适应能力,我们无需每次送入模型一对对应的图片,只需送入两个单独的读取器从两组图片中各自shuffle后输出的任意两张图片。这样,还能通过打乱顺序增加模型的泛化能力。
此外,为了实现模型的更佳效果,还使用了明暗、对比度、饱和度、拉伸、旋转等数据增强效果。具体的使用原因我们在最后的对比分析中再详细解释。
- # 解压数据集,首次运行后注释
- # !unzip -qa -d /home/aistudio/data/data50363/ /home/aistudio/data/data50363/selfie2anime_textlist.zip
-
- import paddle.fluid as fluid
- import data_reader_epoch as data_reader
- import paddle
- import matplotlib.pylab as plt
- %matplotlib inline
- import numpy as np
-
- def show_pics(pics, heatmap=np.zeros((1, 1))):
- plt.figure(figsize=(3 * len(pics), 3), dpi=80)
- for i in range(len(pics)):
- pics[i] = (pics[i][0].transpose((1,2,0)) + 1) / 2
- plt.subplot(1, len(pics), i + 1)
- plt.imshow(pics[i])
- plt.xticks([])
- plt.yticks([])
-
- def open_pic(file_name='./data/data50363/testA/female_11846.jpg'):
- img = Image.open(file_name).resize((256, 256), Image.BILINEAR)
- img = (np.array(img).astype('float32') / 255.0 - 0.5) / 0.5
- img = img.transpose((2, 0, 1))
- img = img.reshape((-1, img.shape[0], img.shape[1], img.shape[2]))
- return img
-
- class CFG:
- def __init__(self):
- self.batch_size = 1
- self.image_size = 256
- self.crop_size = 244
- self.crop_type = 'Random'
- self.use_gpu = True
- self.shuffle = True
- self.dataset = '/home/aistudio/data/data50363/'
- self.model_net = 'CycleGAN'
- self.data_dir = './data'
- self.run_test = True
-
- cfg = CFG()
-
- reader = data_reader.data_reader(cfg)
- A_reader, B_reader, a_reader_test, b_reader_test, batch_num, a_id2name, b_id2name = reader.make_data()
-
- data_a = next(A_reader())
- data_b = next(B_reader())
-
- data_a = data_a[0]
- data_b = data_b[0]
-
- show_pics([data_a, data_b])


上面的代码打印了reader输出的两张图片,左边的是A组照片风格的图片,右边的是B组卡通风格的图片。训练集的读取器会执行shuffle,所以每次执行输出的图片会不同,也不会有固定的匹配关系。
2.辅助函数
下面的代码保存训练过程中打印的图片,帮助我们观察模型的训练情况。训练时保存的图片存在./output/pics/文件夹下,测试时保存的图片存在./output/pics_test/文件夹下,文件名为训练的迭代次数。保存图片的频率随轮数降低,因为训练前期输出的图片变化较大。
- from PIL import Image
- def save_pics(pics, file_name='tmp', save_path='./output/pics/'):
- for i in range(len(pics)):
- pics[i] = pics[i][0]
- pic = np.concatenate(tuple(pics), axis=2)
- pic = pic.transpose((1,2,0))
- pic = (pic + 1) / 2
- pic = np.clip(pic * 256, 0, 255)
- img = Image.fromarray(pic.astype('uint8')).convert('RGB')
- img.save(save_path+file_name+'.jpg')
-
- # save_pics([data_a, data_b])
3.判别器和生成器
CycleGAN有两个结构一样的判别器和两个结构一样的生成器,所以我们只需要定义一个判别器和一个生成器,后面train过程使用时实例化成不同对象就可以了。
CycleGAN和上个Pix2Pix项目一样,使用的PatchGAN判别器和ResNet的残差块儿组成的生成器。
由于CycleGAN的判别器和生成器使用的是普通GAN,而非像Pix2Pix一样的CGAN。它的判别器和生成器输入的图片数据的维度不同,不需要拼接用作“限制条件”的图片。
- import paddle.fluid as fluid
- from paddle.fluid.dygraph import Conv2D, Linear, Dropout, BatchNorm, Pool2D, Conv2DTranspose, InstanceNorm, SpectralNorm
- import numpy as np
-
- class Disc(fluid.dygraph.Layer):
- def __init__(self):
- super(Disc, self).__init__()
-
- # self.conv1 = Conv2D(6, 64, 4, stride=2, padding=1, bias_attr=True, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
- self.conv1 = Conv2D(3, 64, 4, stride=2, padding=1, bias_attr=True, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
- self.in1 = InstanceNorm(64)
- self.conv2 = Conv2D(64, 128, 4, stride=2, padding=1, bias_attr=False, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
- self.in2 = InstanceNorm(128)
- self.conv3 = Conv2D(128, 256, 4, stride=2, padding=1, bias_attr=False, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
- self.in3 = InstanceNorm(256)
- self.conv4 = Conv2D(256, 512, 4, padding=1, bias_attr=False, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
- self.in4 = InstanceNorm(512)
- self.conv5 = Conv2D(512, 1, 4, padding=1, bias_attr=True, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
-
- def forward(self, x):
- x = self.conv1(x)
- x = self.in1(x)
- x = fluid.layers.leaky_relu(x, alpha=0.2)
-
- x = self.conv2(x)
- x = self.in2(x)
- x = fluid.layers.leaky_relu(x, alpha=0.2)
-
- x = self.conv3(x)
- x = self.in3(x)
- x = fluid.layers.leaky_relu(x, alpha=0.2)
-
- x = self.conv4(x)
- x = self.in4(x)
- x = fluid.layers.leaky_relu(x, alpha=0.2)
-
- x = self.conv5(x)
-
- return x
-
- # 定义生成器使用的残差块
- class Residual(fluid.dygraph.Layer):
- def __init__(self, input_output_dim, use_bias):
- super(Residual, self).__init__()
- name_scope = self.full_name()
-
- self.conv1 = Conv2D(input_output_dim, input_output_dim, 3, bias_attr=use_bias, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
- self.bn1 = BatchNorm(input_output_dim)
- self.conv2 = Conv2D(input_output_dim, input_output_dim, 3, bias_attr=use_bias, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
- self.bn2 = BatchNorm(input_output_dim)
-
- def forward(self, x_input):
- x = fluid.layers.pad2d(x_input, [1, 1, 1, 1], mode='reflect')
- x = self.conv1(x)
- x = self.bn1(x)
- x = fluid.layers.relu(x)
-
- x = fluid.layers.pad2d(x, [1, 1, 1, 1], mode='reflect')
- x = self.conv2(x)
- x = self.bn2(x)
-
- return x + x_input
-
- # 定义ResNet版的生成器
- class Gen(fluid.dygraph.Layer):
- def __init__(self, base_dim=64, residual_num=7):
- super(Gen, self).__init__()
-
- self.residual_num = residual_num
-
- self.conv1 = Conv2D(3, base_dim, 7, bias_attr=False, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
- self.bn1 = BatchNorm(base_dim)
- self.conv2 = Conv2D(base_dim, base_dim * 2, 3, padding=1, stride=2, bias_attr=False, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
- self.bn2 = BatchNorm(base_dim * 2)
- self.conv3 = Conv2D(base_dim * 2, base_dim * 4, 3, padding=1, stride=2, bias_attr=False, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
- self.bn3 = BatchNorm(base_dim * 4)
-
- self.residual_list = []
- for i in range(residual_num):
- layer = self.add_sublayer('res_'+str(i), Residual(base_dim * 4, False))
- self.residual_list.append(layer)
-
- self.convTrans1 = Conv2DTranspose(base_dim * 4, base_dim * 2, 3, stride=2, padding=1, bias_attr=False, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
- self.bn4 = BatchNorm(base_dim * 2)
- self.convTrans2 = Conv2DTranspose(base_dim * 2, base_dim, 3, stride=2, padding=1, bias_attr=False, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
- self.bn5 = BatchNorm(base_dim)
- self.conv4 = Conv2D(base_dim, 3, 7, bias_attr=True, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
-
- def forward(self, x):
- x = fluid.layers.pad2d(x, [3, 3, 3, 3], mode='reflect')
- x = self.conv1(x)
- x = self.bn1(x)
- x = fluid.layers.relu(x)
-
- x = self.conv2(x)
- x = self.bn2(x)
- x = fluid.layers.relu(x)
-
- x = self.conv3(x)
- x = self.bn3(x)
- x = fluid.layers.relu(x)
-
- for res_layer in self.residual_list:
- x = res_layer(x)
-
- x = self.convTrans1(x)
- x = self.bn4(x)
- x = fluid.layers.relu(x)
- x = fluid.layers.pad2d(x, [0, 1, 0, 1], mode='constant', pad_value=0.0)
-
- x = self.convTrans2(x)
- x = self.bn5(x)
- x = fluid.layers.relu(x)
- x = fluid.layers.pad2d(x, [0, 1, 0, 1], mode='constant', pad_value=0.0)
-
- x = fluid.layers.pad2d(x, [3, 3, 3, 3], mode='reflect')
- x = self.conv4(x)
- x = fluid.layers.tanh(x)
-
- return x
4.训练过程
下面代码中的ImagePool类是用来缓存图片的队列的对象。使用这个队列是CycleGAN论文中用的一个trick。通过使用缓存在队列里的生成器输出的图片来训练判别器,可以保持判别器的稳定性。缓存队列的容量是50,也即随机使用前50次迭代成的图片训练判别器。
train()函数执行训练和验证。代码的各个部分已经注释,而且和上个Pix2Pix项目大致相同。先训练判别器DA、DB,再训练生成器GA、GB。对抗损失和Pix2Pix一样使用最小二乘损失。
需要关注一下的是“循环一致性损失”的权重cycle_weight设为30,“本体损失”的权重identity_weight设为10,都是作为train()函数的默认参数值进行设定的。这个权重是经过一些试验选取的。
- import paddle.fluid as fluid
- import time
- from PIL import Image, ImageEnhance
-
- class ImagePool(object):
- def __init__(self, pool_size=50):
- self.pool = []
- self.count = 0
- self.pool_size = pool_size
-
- def pool_image(self, image):
- image = image.numpy()
- rtn = ''
- if self.count < self.pool_size:
- self.pool.append(image)
- self.count += 1
- rtn = image
- else:
- p = np.random.rand()
- if p > 0.5:
- random_id = np.random.randint(0, self.pool_size - 1)
- temp = self.pool[random_id]
- self.pool[random_id] = image
- rtn = temp
- else:
- rtn = image
- return fluid.dygraph.to_variable(rtn)
-
- def train(epoch_num=99999, adv_weight=1, cycle_weight=30, identity_weight=10, \
- use_gpu=True, load_model=False, model_path='./model/', model_path_bkp='./model_bkp/', \
- print_interval=1, max_step=50, model_bkp_interval=5000):
- place = fluid.CUDAPlace(0) if use_gpu == True else fluid.CPUPlace()
- with fluid.dygraph.guard(place):
- # model
- g_a = Gen()
- g_b = Gen()
- d_a = Disc()
- d_b = Disc()
-
- # data
- reader_a, reader_b, _, _, _, _, _ = reader.make_data()
-
- # optimizer
- g_a_optimizer = fluid.optimizer.Adam(learning_rate=0.0002, beta1=0.5, beta2=0.999, parameter_list=g_a.parameters())
- g_b_optimizer = fluid.optimizer.Adam(learning_rate=0.0002, beta1=0.5, beta2=0.999, parameter_list=g_b.parameters())
- d_a_optimizer = fluid.optimizer.Adam(learning_rate=0.0002, beta1=0.5, beta2=0.999, parameter_list=d_a.parameters())
- d_b_optimizer = fluid.optimizer.Adam(learning_rate=0.0002, beta1=0.5, beta2=0.999, parameter_list=d_b.parameters())
-
- # image pool
- fa_pool, fb_pool = ImagePool(), ImagePool()
-
- total_step_num = np.array([0])
-
- if load_model == True:
- ga_para, ga_opt = fluid.load_dygraph(model_path+'gen_b2a')
- gb_para, gb_opt = fluid.load_dygraph(model_path+'gen_a2b')
- da_para, da_opt = fluid.load_dygraph(model_path+'dis_ga')
- db_para, db_opt = fluid.load_dygraph(model_path+'dis_gb')
- g_a.load_dict(ga_para)
- g_a_optimizer.set_dict(ga_opt)
- g_b.load_dict(gb_para)
- g_b_optimizer.set_dict(gb_opt)
- d_a.load_dict(da_para)
- d_a_optimizer.set_dict(da_opt)
- d_b.load_dict(db_para)
- d_b_optimizer.set_dict(db_opt)
-
- total_step_num = np.load('./model/total_step_num.npy')
-
- step = total_step_num[0]
- print('Start time :', time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), 'start step:', step + 1)
- for epoch in range(epoch_num):
- for data_a, data_b in zip(reader_a(), reader_b()):
- step += 1
-
- # data
- data_a, data_b = np.array(data_a[0]), np.array(data_b[0])
- # data_a[0] = prepare_a(data_a[0]) # A augment
- img_ra = fluid.dygraph.to_variable(data_a)
- img_rb = fluid.dygraph.to_variable(data_b)
-
- # train DA
- d_loss_ra = fluid.layers.reduce_mean((d_a(img_ra.detach()) - 1) ** 2)
- d_loss_fa = fluid.layers.reduce_mean(d_a(fa_pool.pool_image(g_a(img_rb.detach()))) ** 2)
- da_loss = (d_loss_ra + d_loss_fa) * 0.5
- da_loss.backward()
- d_a_optimizer.minimize(da_loss)
- d_a.clear_gradients()
-
- # train DB
- d_loss_rb = fluid.layers.reduce_mean((d_b(img_rb.detach()) - 1) ** 2)
- d_loss_fb = fluid.layers.reduce_mean(d_b(fb_pool.pool_image(g_b(img_ra.detach()))) ** 2)
- db_loss = (d_loss_rb + d_loss_fb) * 0.5
- db_loss.backward()
- d_b_optimizer.minimize(db_loss)
- d_b.clear_gradients()
-
- # train GA
- ga_gan_loss = fluid.layers.reduce_mean((d_a(g_a(img_rb.detach())) - 1) ** 2)
- ga_cyc_loss = fluid.layers.reduce_mean(fluid.layers.abs(img_rb.detach() - g_b(g_a(img_rb.detach()))))
- ga_ide_loss = fluid.layers.reduce_mean(fluid.layers.abs(img_ra.detach() - g_a(img_ra.detach())))
- ga_loss = ga_gan_loss * adv_weight + ga_cyc_loss * cycle_weight + ga_ide_loss * identity_weight
-
- ga_loss.backward()
- g_a_optimizer.minimize(ga_loss)
- g_a.clear_gradients()
-
- # train GB
- gb_gan_loss = fluid.layers.reduce_mean((d_b(g_b(img_ra.detach())) - 1) ** 2)
- gb_cyc_loss = fluid.layers.reduce_mean(fluid.layers.abs(img_ra.detach() - g_a(g_b(img_ra.detach()))))
- gb_ide_loss = fluid.layers.reduce_mean(fluid.layers.abs(img_rb.detach() - g_b(img_rb.detach())))
- gb_loss = gb_gan_loss * adv_weight + gb_cyc_loss * cycle_weight + gb_ide_loss * identity_weight
-
- gb_loss.backward()
- g_b_optimizer.minimize(gb_loss)
- g_b.clear_gradients()
-
- # save pictures
- if step in range(1, 101):
- pic_save_interval = 1
- elif step in range(101, 1001):
- pic_save_interval = 10
- elif step in range(1001, 10001):
- pic_save_interval = 100
- else:
- pic_save_interval = 500
- if step % pic_save_interval == 0:
- save_pics([img_ra.numpy(), g_b(img_ra).numpy(), g_a(g_b(img_ra)).numpy(), g_b(img_rb).numpy(), \
- img_rb.numpy(), g_a(img_rb).numpy(), g_b(g_a(img_rb)).numpy(), g_a(img_ra).numpy()], \
- str(step))
- test_pic = open_pic()
- test_pic_pp = fluid.dygraph.to_variable(test_pic)
- save_pics([test_pic, g_b(test_pic_pp).numpy()], str(step), save_path='./output/pics_test/')
-
- # print losses & pictures
- if step % print_interval == 0:
- print([step], \
- 'DA:', da_loss.numpy(), \
- 'DB:', db_loss.numpy(), \
- 'GA:', ga_loss.numpy(), \
- 'GB:', gb_loss.numpy(), \
- time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
- show_pics([img_ra.numpy(), g_b(img_ra).numpy(), g_a(g_b(img_ra)).numpy(), g_b(img_rb).numpy()])
- show_pics([img_rb.numpy(), g_a(img_rb).numpy(), g_b(g_a(img_rb)).numpy(), g_a(img_ra).numpy()])
-
- # save models regularly
- if step % model_bkp_interval == 0:
- fluid.save_dygraph(g_a.state_dict(), model_path_bkp+'gen_b2a')
- fluid.save_dygraph(g_a_optimizer.state_dict(), model_path_bkp+'gen_b2a')
- fluid.save_dygraph(g_b.state_dict(), model_path_bkp+'gen_a2b')
- fluid.save_dygraph(g_b_optimizer.state_dict(), model_path_bkp+'gen_a2b')
- fluid.save_dygraph(d_a.state_dict(), model_path_bkp+'dis_ga')
- fluid.save_dygraph(d_a_optimizer.state_dict(), model_path_bkp+'dis_ga')
- fluid.save_dygraph(d_b.state_dict(), model_path_bkp+'dis_gb')
- fluid.save_dygraph(d_b_optimizer.state_dict(), model_path_bkp+'dis_gb')
- np.save(model_path_bkp+'total_step_num', np.array([step]))
-
- # end train
- if step >= max_step + total_step_num[0]:
- fluid.save_dygraph(g_a.state_dict(), model_path+'gen_b2a')
- fluid.save_dygraph(g_a_optimizer.state_dict(), model_path+'gen_b2a')
- fluid.save_dygraph(g_b.state_dict(), model_path+'gen_a2b')
- fluid.save_dygraph(g_b_optimizer.state_dict(), model_path+'gen_a2b')
- fluid.save_dygraph(d_a.state_dict(), model_path+'dis_ga')
- fluid.save_dygraph(d_a_optimizer.state_dict(), model_path+'dis_ga')
- fluid.save_dygraph(d_b.state_dict(), model_path+'dis_gb')
- fluid.save_dygraph(d_b_optimizer.state_dict(), model_path+'dis_gb')
- np.save(model_path+'total_step_num', np.array([step]))
- print('End time :', time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), 'End Step:', step)
- return
-
- # 重新训练
- # train(print_interval=1, max_step=1, model_bkp_interval = 2000)
-
-
- # 继续训练
- train(load_model=True, print_interval=1, max_step=3, model_bkp_interval = 2000)
Start time : 2020-11-11 21:22:00 start step: 200107
[200107] DA: [0.05124042] DB: [0.04026642] GA: [4.1400466] GB: [3.8985167] 2020-11-11 21:22:01
[200108] DA: [0.01048683] DB: [0.01179506] GA: [9.123032] GB: [4.7860665] 2020-11-11 21:22:01
[200109] DA: [0.00659171] DB: [0.01218848] GA: [12.422014] GB: [13.788451] 2020-11-11 21:22:02
End time : 2020-11-11 21:22:07 End Step: 200109






5.预测过程
使用训练好的模型在测试集图片上运行测试,评估训练效果。
- import paddle.fluid as fluid
-
- def infer(max_step=10, use_gpu=True, load_model=True, model_path='./model/'):
- place = fluid.CUDAPlace(0) if use_gpu == True else fluid.CPUPlace()
- with fluid.dygraph.guard(place):
- # model
- g_b = Gen()
-
- # data
- reader_a, reader_b, a_reader_test, _, _, _, _ = reader.make_data()
-
- if load_model == True:
- gb_para, gb_opt = fluid.load_dygraph(model_path+'gen_a2b')
- g_b.load_dict(gb_para)
- step = 0
- for data_a in a_reader_test():
- step += 1
- data_a = np.array(data_a[0])
- img_ra = fluid.dygraph.to_variable(data_a)
- img_b = g_b(img_ra).numpy() * .9
- show_pics([data_a, img_b])
- print('(', step, '/', max_step, ')')
- if step >= max_step:
- return
-
- # infer(max_step=10, use_gpu=False)
- infer(max_step=10)
- ( 1 / 10 )
- ( 2 / 10 )
- ( 3 / 10 )
- ( 4 / 10 )
- ( 5 / 10 )
- ( 6 / 10 )
- ( 7 / 10 )
- ( 8 / 10 )
- ( 9 / 10 )
- ( 10 / 10 )










总结
上面运行的效果看上去还不错吧~实际上,第一次训练CycleGAN时我用的原论文中“马变斑马”数据集上用的参数。训练一二百万轮后有些“极端”的画风是这样的:



我的天啊!怎么妹子变成了格格巫~
上面的图片每次迭代输出一行,左一是A域图片,左二是A2B图片,左三是A2B2A的图片,左四是用B2B(用GB生成器)的图片,右边的四张则是B域迁移的A域的相应图片。这些训练图片我已经存到了./output/pics_w10文件夹下。欢迎同学观摩各种妖魔鬼怪~(由于版本文件数的限制图片没有复制到新版本中,但模型已经保存到了./model_cycleweight10文件夹下,大家可以用这个存模型自己生成下)
在./output/pics_test_w10文件夹下则存储了每次迭代时用同一张测试集图片测试的结果:


效果似乎还凑合,但仔细观察会发现,生成的二次元妹子的左边嘴角总有一道斜线不知哪里来的。原图那个位置既没有线条,也没有明显的明暗变化。我尝试分析原因(虽然咱管这叫炼丹,但还是总忍不住要分析分析~)...后来在一些图片上找到了线索。比如上面训练集图片的第三行的左二A2B图片看上去,生成的二次元效果还行,但再看左三A2B2A图片就会发现:经过CycleGAN的循环生成,妹子的嘴巴这是肿么了~
我推测,这是GAN网络对两图图片进行迁移时五官定位错误造成的。第三行训练集照片上妹子的嘴实际上对应生成了二次元图片的下巴,从照片上妹子的脸部的比例和生成的二次元脸部长宽比例就能看得出来。这可能是训练集照片人脸五官的分布比例和卡通五官分布没有正确对应造成的。从测试集生成的妹子二次元图片上左嘴角边的斜线也能印证:测试照片上妹子脸比较长,穿越成二次元时发生了五官定位错误,左嘴角又生成了一个下巴(狐狸)~
为了解决这个问题,我使用了,拉伸、旋转等图像增强方法,使模型迁移风格时五官能正确对应。并且,我还将循环一致性损失在loss中的权重cycle_weight从10调整为30,使风格迁移的过程中更多保持一些原有特征,防止生成妖魔鬼怪~。调整后的模型就是我们项目中训练的版本,我们看下测试集那张妹子照片还有没有“双下巴”~



安全上垒!二次元妹子成功瘦身,减掉了“双下巴”。
除了这种数据增强的小trick外,后来的大佬们对GycleGAN的应用也做了很多改进。比如,为了用GTA游戏场景生成街景图片,用于扩展训练集,论文CYCADA提出了自己的Semantic Consistency Loss,取得了很好的效果。论文UGATIT则提出了使用“热图引导注意力机制”和“AdaLIN归一化”方法增强了CycleGAN头像风格迁移任务的效果。
现在有了PaddleGAN这个“神器”,GAN的活再也不用自己干~
附上炼丹套件地址:
https://github.com/PaddlePaddle/PaddleGAN/blob/master/docs/zh_CN/tutorials/pix2pix_cyclegan.md
学习官方大佬优雅的代码风格也是能给自己涨点的啊~
如在使用过程中有问题,可加入飞桨官方QQ群进行交流:1108045677。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
·飞桨PaddleGAN项目地址(欢迎Star)·
GitHub:
https://github.com/PaddlePaddle/PaddleGAN
Gitee:
https://Gitee.com/PaddlePaddle/PaddleGAN
·飞桨官网地址·
https://www.paddlepaddle.org.cn/


