
- 1【深度学习】GPT-3_gpt-3 模型
- 2开发鸿蒙的第一个Hello World的Java页面以及页面间跳转功能实现_鸿蒙开发 javaui 跳转js ui
- 3C#将字符转换成utf8编码 GB321编码转换
- 4C# 启动/停止 iis 网站 例子源码(iis 6.0下测试通过)_c# 实现web站点启动和停止
- 5ubuntu18使用之5:Ubuntu18.04安装NVIDIA 显卡驱动(GTX 1060)_command 'nvidia-sim' not found, did you mean: comm
- 6Ubuntu16.04 + cuda8.0 + GTX1080 + matlab14.04a + Opencv3.0 + caffe 安装教程_graphics-drivers user or team
- 7Android自定义散点图View_android 自定义散点图
- 8如何在Winform程序中实现遮罩层对话框(蒙版窗口)_c# winform 蒙层
- 9了解defineProperty,实现一个简单的vue数据响应式_defineprops怎么变成响应式
- 10vue element input让浏览器不保存密码
基于MySQL和Densenet的改进YOLOv5的100种中草药图像分类系统_100种中药 数据集
赞
踩
1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
随着人工智能技术的不断发展,图像分类已经成为了计算机视觉领域的一个重要研究方向。图像分类技术在医学、农业、工业等领域都有着广泛的应用。中草药作为传统的中医药资源,具有丰富的药用价值,对于保护和利用中草药资源具有重要意义。然而,传统的中草药鉴别和分类方法通常需要依赖专业的中医药学知识和经验,这不仅需要大量的时间和人力成本,而且存在主观性和不稳定性的问题。
因此,基于图像分类技术的中草药分类系统具有重要的研究意义和实际应用价值。通过将中草药的图像信息转化为计算机可识别的特征向量,可以实现对中草药的自动化鉴别和分类。这不仅可以提高中草药的鉴别准确性和分类效率,还可以降低人力成本,推动中草药资源的保护和利用。
在图像分类技术中,深度学习模型已经取得了显著的成果。YOLOv5是一种基于深度学习的目标检测算法,具有快速和准确的特点。然而,YOLOv5在中草药图像分类任务中存在一些问题。首先,YOLOv5对于中草药图像的特征提取能力有限,导致分类准确性不高。其次,YOLOv5在处理大规模中草药图像数据时,计算复杂度较高,运行速度较慢。
为了解决上述问题,本研究提出了一种基于MySQL和Densenet的改进YOLOv5的中草药图像分类系统。MySQL是一种常用的关系型数据库管理系统,可以用于存储和管理中草药图像数据。Densenet是一种深度学习模型,具有较强的特征提取能力。通过将MySQL和Densenet与YOLOv5相结合,可以提高中草药图像分类系统的准确性和效率。
具体而言,本研究的主要贡献包括以下几个方面:
首先,通过使用MySQL存储和管理中草药图像数据,可以方便地进行数据的查询和管理。同时,MySQL还可以提供高效的数据存储和读取能力,加快系统的运行速度。
其次,通过引入Densenet模型,可以增强YOLOv5的特征提取能力。Densenet模型具有密集连接和特征重用的特点,可以有效地提取中草药图像的特征信息,提高分类准确性。
最后,通过对YOLOv5算法进行改进,可以降低其在处理大规模中草药图像数据时的计算复杂度,提高系统的运行速度。
总之,基于MySQL和Densenet的改进YOLOv5的中草药图像分类系统具有重要的研究意义和实际应用价值。该系统可以提高中草药的鉴别准确性和分类效率,降低人力成本,推动中草药资源的保护和利用。同时,该系统还可以为其他领域的图像分类任务提供借鉴和参考。
2.图片演示



3.视频演示
基于MySQL和Densenet的改进YOLOv5的100种中草药图像分类系统_哔哩哔哩_bilibili
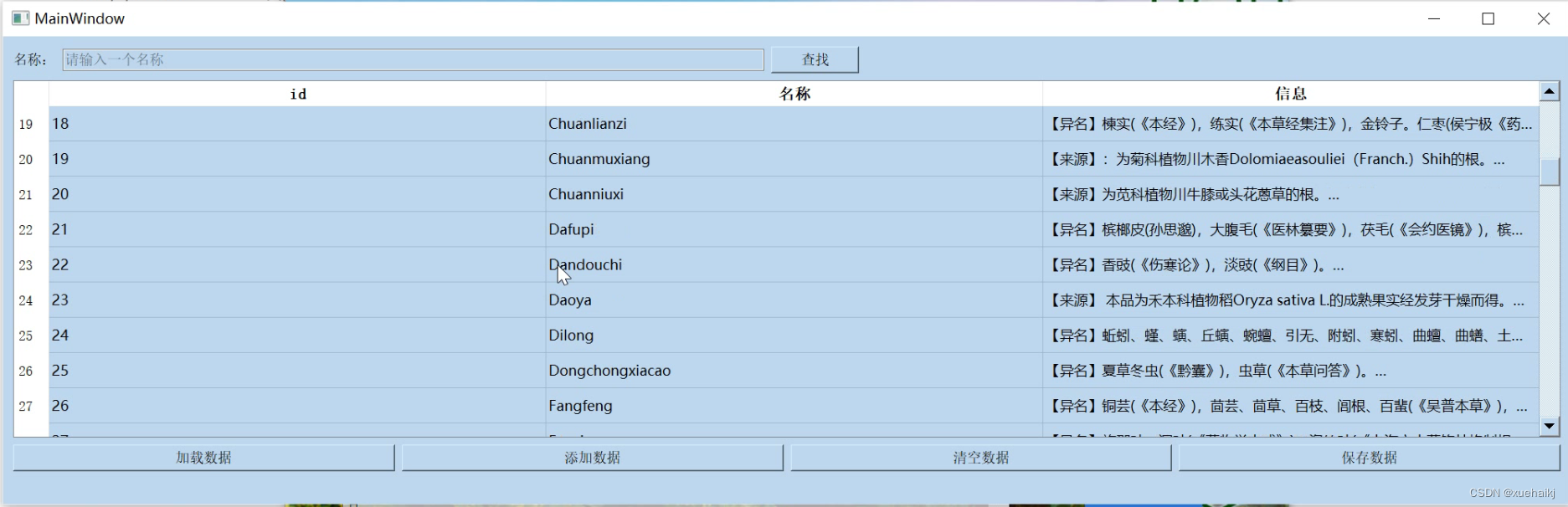
4.数据库的设计
数据库设计
在构建数据库之前,首先需要设计数据库模式,包括表格结构、字段以及关系。你可以根据你的中草药图像分类系统的需求来设计数据库模式。根据你的代码,看起来你已经有了一个名为table1的表格,该表格包括三个字段:id、name和information。你可以根据需要进行调整或添加其他表格和字段。
数据库连接
在代码中,你可以看到一个名为db_connect的函数,它用于连接到MySQL数据库。确保你提供了正确的数据库主机名、用户名、密码、端口和数据库名称。在这个函数中,你可以使用MySQL的Python驱动程序(例如mysql.connector或pymysql)来建立连接。
表格数据加载
利用on_button_load_clicked的函数,它用于加载数据到表格中。在这个函数中,你可以执行以下步骤:
连接到数据库。
执行SQL查询,检索数据。
将检索到的数据添加到表格中。
表格数据保存
利用on_button_save_clicked的函数,它用于保存表格数据到数据库。在这个函数中,你可以执行以下步骤:
连接到数据库。
执行SQL操作,删除数据库中的旧数据。
遍历表格中的行,将新数据插入到数据库中。
数据的增加和删除
利用两个函数,on_button_add_clicked和on_button_clear_clicked,分别用于添加数据和清空数据。在on_button_add_clicked函数中,你可以弹出一个对话框,让用户输入新的数据,并将数据添加到表格和数据库中。在on_button_clear_clicked函数中,你可以清空表格并删除数据库中的所有数据。
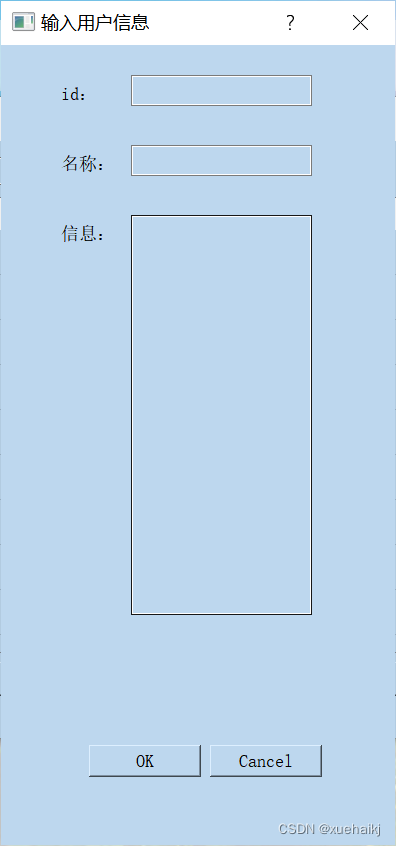
数据的查询和修改
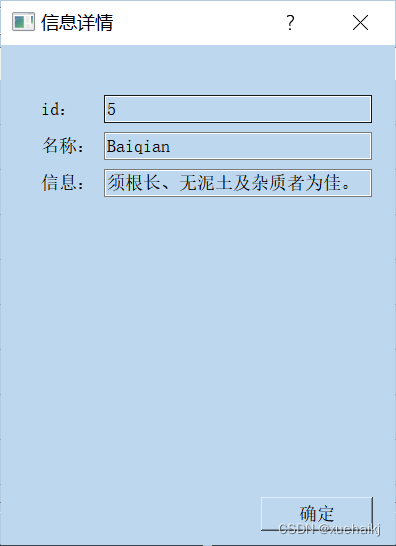
利用on_button_search_clicked的函数,用于查询数据。在这个函数中,你可以弹出一个对话框,让用户输入要查询的条件,然后执行SQL查询,显示查询结果。另外,你还有一个名为on_tableWidget_cellDoubleClicked的函数,用于双击表格中的单元格以修改数据。

5.核心代码讲解
5.1 export.py
def export_formats(): # YOLOv5 export formats x = [ ['PyTorch', '-', '.pt', True, True], ['TorchScript', 'torchscript', '.torchscript', True, True], ['ONNX', 'onnx', '.onnx', True, True], ['OpenVINO', 'openvino', '_openvino_model', True, False], ['TensorRT', 'engine', '.engine', False, True], ['CoreML', 'coreml', '.mlmodel', True, False], ['TensorFlow SavedModel', 'saved_model', '_saved_model', True, True], ['TensorFlow GraphDef', 'pb', '.pb', True, True], ['TensorFlow Lite', 'tflite', '.tflite', True, False], ['TensorFlow Edge TPU', 'edgetpu', '_edgetpu.tflite', False, False], ['TensorFlow.js', 'tfjs', '_web_model', False, False], ['PaddlePaddle', 'paddle', '_paddle_model', True, True],] return pd.DataFrame(x, columns=['Format', 'Argument', 'Suffix', 'CPU', 'GPU']) def try_export(inner_func): # YOLOv5 export decorator, i..e @try_export inner_args = get_default_args(inner_func) def outer_func(*args, **kwargs): prefix = inner_args['prefix'] try: with Profile() as dt: f, model = inner_func(*args, **kwargs) LOGGER.info(f'{prefix} export success ✅ {dt.t:.1f}s, saved as {f} ({file_size(f):.1f} MB)') return f, model except Exception as e: LOGGER.info(f'{prefix} export failure ❌ {dt.t:.1f}s: {e}') return None, None return outer_func @try_export def export_torchscript(model, im, file, optimize, prefix=colorstr('TorchScript:')): # YOLOv5 TorchScript model export LOGGER.info(f'\n{prefix} starting export with torch {torch.__version__}...') f = file.with_suffix('.torchscript') ts = torch.jit.trace(model, im, strict=False) d = {'shape': im.shape, 'stride': int(max(model.stride)), 'names': model.names} extra_files = {'config.txt': json.dumps(d)} # torch._C.ExtraFilesMap() if optimize: # https://pytorch.org/tutorials/recipes/mobile_interpreter.html optimize_for_mobile(ts)._save_for_lite_interpreter(str(f), _extra_files=extra_files) else: ts.save(str(f), _extra_files=extra_files) return f, None @try_export def export_onnx(model, im, file, opset, dynamic, simplify, prefix=colorstr('ONNX:')): # YOLOv5 ONNX export check_requirements('onnx>=1.12.0') import onnx LOGGER.info(f'\n{prefix} starting export with onnx {onnx.__version__}...') f = file.with_suffix('.onnx') output_names = ['output0', 'output1'] if isinstance(model, SegmentationModel) else ['output0'] if dynamic: dynamic = {'images': {0: 'batch', 2: 'height', 3: 'width'}} # shape(1,3,640,640) if isinstance(model, SegmentationModel): dynamic['output0'] = {0: 'batch', 1: 'anchors'} # shape(1,25200,85) dynamic['output1'] = {0: 'batch', 2: 'mask_height', 3: 'mask_width'} # shape(1,32,160,160) elif isinstance(model, DetectionModel): dynamic['output0'] = {0: 'batch', 1: 'anchors'} # shape(1,25200,85) torch.onnx.export( model.cpu() if dynamic else model, # --dynamic only compatible with cpu im.cpu() if dynamic else im, f, verbose=False, opset_version=opset, do_constant_folding=True, # WARNING: DNN inference with torch>=1.12 may require do_constant_folding=False input_names=['images'], output_names=output_names, dynamic_axes=dynamic or None) # Checks model_onnx = onnx.load(f) # load onnx model onnx.checker.check_model(model_onnx) # check onnx model # Metadata d = {'stride': int(max(model.stride)), 'names': model.names} for k, v in d.items(): meta = model_onnx.metadata_props.add() meta.key, meta.value = k, str(v) onnx.save(model_onnx, f) # Simplify if simplify: try: cuda = torch.cuda.is_available() check_requirements(('onnxruntime-gpu' if cuda else 'onnxruntime', 'onnx-simplifier>=0.4.1')) import onnxsim LOGGER.info(f'{prefix} simplifying with onnx-simplifier {onnxsim.__version__}...') model_onnx, check = onnxsim.simplify(model_onnx)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
该程序文件是用于将YOLOv5 PyTorch模型导出为其他格式的工具。可以通过命令行参数指定要导出的格式,包括PyTorch、TorchScript、ONNX、OpenVINO、TensorRT、CoreML、TensorFlow SavedModel、TensorFlow GraphDef、TensorFlow Lite、TensorFlow Edge TPU、TensorFlow.js和PaddlePaddle等。
该文件首先定义了一些常量和导出格式的函数。然后定义了一些装饰器函数,用于处理导出过程中的异常情况。接下来定义了具体的导出函数,包括TorchScript模型导出和ONNX模型导出。最后,定义了一个主函数,用于解析命令行参数并执行相应的导出操作。
该文件还导入了一些其他模块和函数,包括PyTorch、pandas、torchvision、onnx、onnxsim等。这些模块和函数用于加载模型、处理图像、检查依赖项、保存模型等操作。
使用该工具可以方便地将YOLOv5模型导出为其他格式,以便在不同的平台和框架上进行推理和部署。
5.2 model.py
import torch import timm from thop import clever_format, profile class ModelProfiler: def __init__(self, model_name, input_shape): self.model_name = model_name self.input_shape = input_shape self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu") self.model = None def load_model(self): self.model = timm.create_model(self.model_name, pretrained=False, features_only=True) self.model.to(self.device) self.model.eval() def print_model_info(self): print(self.model.feature_info.channels()) for feature in self.model(self.dummy_input): print(feature.size()) def profile_model(self): flops, params = profile(self.model.to(self.device), (self.dummy_input,), verbose=False) flops, params = clever_format([flops * 2, params], "%.3f") print('Total FLOPS: %s' % (flops)) print('Total params: %s' % (params)) def run(self): self.load_model() self.print_model_info() self.profile_model() model_name = 'vovnet39a' input_shape = (1, 3, 640, 640) profiler = ModelProfiler(model_name, input_shape) profiler.run()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
这个程序文件名为model.py,它的功能是使用torch和timm库来计算一个模型的FLOPS(浮点操作数)和参数数量。
首先,程序列出了timm库中可用的所有模型。然后,它创建了一个torch设备,如果可用的话会使用CUDA。接下来,它创建了一个随机输入张量dummy_input,并将其发送到设备上。
然后,程序使用timm库创建了一个名为’vovnet39a’的模型,该模型不使用预训练权重,并且只返回特征而不是完整的模型。然后,模型被发送到设备并设置为评估模式。
接下来,程序打印了模型中每个特征的通道数,并通过将dummy_input传递给模型来打印每个特征的大小。
最后,程序使用thop库的profile函数来计算模型的FLOPS和参数数量,并使用clever_format函数将其格式化为易读的形式。然后,它打印出总的FLOPS和参数数量。
总而言之,这个程序文件用于计算一个模型的FLOPS和参数数量,并打印出结果。
5.3 train.py
def train(hyp, # path/to/hyp.yaml or hyp dictionary opt, device, callbacks ): save_dir, epochs, batch_size, weights, single_cls, evolve, data, cfg, resume, noval, nosave, workers, freeze, = \ Path(opt.save_dir), opt.epochs, opt.batch_size, opt.weights, opt.single_cls, opt.evolve, opt.data, opt.cfg, \ opt.resume, opt.noval, opt.nosave, opt.workers, opt.freeze # Directories w = save_dir / 'weights' # weights dir (w.parent if evolve else w).mkdir(parents=True, exist_ok=True) # make dir last, best = w / 'last.pt', w / 'best.pt' # Hyperparameters if isinstance(hyp, str): with open(hyp, errors='ignore') as f: hyp = yaml.safe_load(f) # load hyps dict LOGGER.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items())) # Save run settings with open(save_dir / 'hyp.yaml', 'w') as f: yaml.safe_dump(hyp, f, sort_keys=False) with open(save_dir / 'opt.yaml', 'w') as f: yaml.safe_dump(vars(opt), f, sort_keys=False) data_dict = None # Loggers if RANK in [-1, 0]: loggers = Loggers(save_dir, weights, opt, hyp, LOGGER) # loggers instance if loggers.wandb: data_dict = loggers.wandb.data_dict if resume: weights, epochs, hyp = opt.weights, opt.epochs, opt.hyp # Register actions for k in methods(loggers): callbacks.register_action(k, callback=getattr(loggers, k)) # Config plots = not evolve # create plots cuda = device.type != 'cpu' init_seeds(1 + RANK) with torch_distributed_zero_first(LOCAL_RANK): data_dict = data_dict or check_dataset(data) # check if None train_path, val_path = data_dict['train'], data_dict['val'] nc = 1 if single_cls else int(data_dict['nc']) # number of classes names = ['item'] if single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class names assert len(names) == nc, f'{len(names)} names found for nc={nc} dataset in {data}' # check is_coco = data.endswith('coco.yaml') and nc == 80 # COCO dataset # Model check_suffix(weights, '.pt') # check weights pretrained = weights.endswith('.pt') if pretrained: with torch_distributed_zero_first(LOCAL_RANK): weights = attempt_download(weights) # download if not found locally ckpt = torch.load(weights, map_location=device) # load checkpoint model = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create exclude = ['anchor'] if (cfg or hyp.get('anchors')) and not resume else [] # exclude keys csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32 csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # intersect model.load_state_dict(csd, strict=False) # load LOGGER.info(f'Transferred {len(csd)}/{len(model.state_dict())} items from {weights}') # report else: model = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create # Freeze freeze = [f'model.{x}.' for x in range(freeze)] # layers to freeze for k, v in model.named_parameters(): v.requires_grad = True # train all layers if any(x in k for x in freeze): print(f'freezing {k}') v.requires_grad = False # Image size gs = max(int(model.stride.max()), 32) # grid size (max stride) imgsz = check_img_size(opt.imgsz, gs, floor=gs * 2) # verify imgsz is gs-multiple # Batch size if RANK == -1 and batch_size == -1: # single-GPU only, estimate best batch size batch_size = check_train_batch_size(model, imgsz) # Optimizer nbs = 64 # nominal batch size accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing hyp['weight_decay'] *= batch_size * accumulate / nbs # scale weight_decay LOGGER.info(f"Scaled weight_decay = {hyp['weight_decay']}") g0, g1, g2 = [], [], [] # optimizer parameter groups for v in model.modules(): if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias g2.append(v.bias) if isinstance(v, nn.BatchNorm2d): # weight (no decay) g0.append(v.weight) elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay) g1.append(v.weight) if opt.adam: optimizer = Adam(g0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum else: optimizer = SGD(g0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True) optimizer.add_param_group({'params': g1, 'weight_decay': hyp['weight_decay']}) # add g1 with weight_decay optimizer.add_param_group({'params': g2}) # add g2 (biases) LOGGER.info(f"{colorstr('optimizer:')} {type(optimizer).__name__} with parameter groups " f"{len(g0)} weight, {len(g1)} weight (no decay), {len(g2)} bias") del g0, g1, g2 # Scheduler if opt.linear_lr: lf = lambda x: (1 - x / (epochs - 1)) *
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
这个程序文件是用来训练一个YOLOv5模型的。它包含了训练模型所需的各种功能,如数据加载、模型创建、优化器设置、学习率调度等。程序文件接受一些命令行参数,如数据集配置文件、模型权重文件、图像大小等。它还支持分布式训练和断点续训功能。训练过程中会保存模型权重和训练日志,可以使用WandB进行可视化和追踪。
5.4 ui.py
class YOLOv5: def __init__(self, weights, source, data, imgsz, device, view_img, save_txt, nosave, augment, visualize, update, project, name, exist_ok): self.weights = weights self.source = source self.data = data self.imgsz = imgsz self.device = device self.view_img = view_img self.save_txt = save_txt self.nosave = nosave self.augment = augment self.visualize = visualize self.update = update self.project = project self.name = name self.exist_ok = exist_ok def run(self): FILE = Path(__file__).resolve() ROOT = FILE.parents[1] # YOLOv5 root directory if str(ROOT) not in sys.path: sys.path.append(str(ROOT)) # add ROOT to PATH ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative source = str(self.source) save_img = not self.nosave and not source.endswith('.txt') # save inference images is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS) is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://')) webcam = source.isnumeric() or source.endswith('.streams') or (is_url and not is_file) screenshot = source.lower().startswith('screen') if is_url and is_file: source = check_file(source) # download # Directories save_dir = increment_path(Path(self.project) / self.name, exist_ok=self.exist_ok) # increment run (save_dir / 'labels' if self.save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir # Load model device = select_device(self.device) model = DetectMultiBackend(self.weights, device=device, dnn=False, data=self.data, fp16=False) stride, names, pt = model.stride, model.names, model.pt imgsz = check_img_size(self.imgsz, s=stride) # check image size # Dataloader bs = 1 # batch_size if webcam: view_img = check_imshow(warn=True) dataset = LoadStreams(source, img_size=imgsz, transforms=classify_transforms(imgsz[0]), vid_stride=1) bs = len(dataset) elif screenshot: dataset = LoadScreenshots(source, img_size=imgsz, stride=stride, auto=pt) else: dataset = LoadImages(source, img_size=imgsz, transforms=classify_transforms(imgsz[0]), vid_stride=1) vid_path, vid_writer = [None] * bs, [None] * bs # Run inference model.warmup(imgsz=(1 if pt else bs, 3, *imgsz)) # warmup seen, windows, dt = 0, [], (Profile(), Profile(), Profile()) for path, im, im0s, vid_cap, s in dataset: with dt[0]: im = torch.Tensor(im).to(model.device) im = im.half() if model.fp16 else im.float() # uint8 to fp16/32 if len(im.shape) == 3: im = im[None] # expand for batch dim # Inference with dt[1]: results = model(im) # Post-process with dt[2]: pred = F.softmax(results, dim=1) # probabilities # Process predictions for i, prob in enumerate(pred): # per image seen += 1 if webcam: # batch_size >= 1 p, im0, frame = path[i], im0s[i].copy(), dataset.count s += f'{i}: ' else: p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0) p = Path(p) # to Path save_path = str(save_dir / p.name) # im.jpg txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # im.txt s += '%gx%g ' % im.shape[2:] # print string annotator = Annotator(im0, example=str(names), pil=True) # Print results top5i = prob.argsort(0, descending=True)[:5].tolist() # top 5 indices s += f"{', '.join(f'{names[j]} {prob[j]:.2f}' for j in top5i)}, " # Write results text = '\n'.join(f'{prob[j]:.2f} {names[j]}' for j in top5i) classname = names[top5i[0]] ui.printf(classname) conn = MySQLdb.connect(host=host, port=port, user=username, passwd=passwd, db=db, charset='utf8') print('successfully connect') cursor = conn.cursor() cursor.execute("SELECT name,information FROM table1") result_db = cursor.fetchall() cursor.close() conn.close() for data in result_db: if data[0] == classname: ui.printf(data[1]) break if prob[top5i[0]] > 0.98: ui.printf('当前分级为1级') elif prob[top5i[0]] > 0.95 and prob[top5i[0]] <= 0.98: ui.printf('当前分级为2级') else: ui.printf('当前分级为3级') if save_img or view_img: # Add bbox to image annotator.text((32, 32), text, txt_color=(255, 255, 255)) if self.save_txt: # Write to file with open(f'{txt_path}.txt', 'a') as f
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
该程序文件名为ui.py,主要功能是运行YOLOv5模型进行目标检测和分类。程序首先导入了所需的库和模块,包括OpenCV、PyQt5、MySQLdb等。然后定义了一些全局变量和函数。
在主函数run中,首先设置了模型和数据的路径,然后加载模型和数据。接着根据输入的数据源类型,选择相应的数据加载方式。然后进行推理和后处理,得到目标检测和分类的结果。最后根据需要保存结果或显示结果。
在parse_opt函数中,定义了程序的命令行参数,用于设置模型路径、数据源、推理参数等。
整个程序的功能是通过调用YOLOv5模型实现目标检测和分类,并将结果保存或显示出来。
5.5 val.py
def save_one_txt(predn, save_conf, shape, file): # Save one txt result gn = torch.tensor(shape)[[1, 0, 1, 0]] # normalization gain whwh for *xyxy, conf, cls in predn.tolist(): xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format with open(file, 'a') as f: f.write(('%g ' * len(line)).rstrip() % line + '\n') def save_one_json(predn, jdict, path, class_map): # Save one JSON result {"image_id": 42, "category_id": 18, "bbox": [258.15, 41.29, 348.26, 243.78], "score": 0.236} image_id = int(path.stem) if path.stem.isnumeric() else path.stem box = xyxy2xywh(predn[:, :4]) # xywh box[:, :2] -= box[:, 2:] / 2 # xy center to top-left corner for p, b in zip(predn.tolist(), box.tolist()): jdict.append({ 'image_id': image_id, 'category_id': class_map[int(p[5])], 'bbox': [round(x, 3) for x in b], 'score': round(p[4], 5)}) def process_batch(detections, labels, iouv): """ Return correct prediction matrix Arguments: detections (array[N, 6]), x1, y1, x2, y2, conf, class labels (array[M, 5]), class, x1, y1, x2, y2 Returns: correct (array[N, 10]), for 10 IoU levels """ correct = np.zeros((detections.shape[0], iouv.shape[0])).astype(bool) iou = box_iou(labels[:, 1:], detections[:, :4]) correct_class = labels[:, 0:1] == detections[:, 5] for i in range(len(iouv)): x = torch.where((iou >= iouv[i]) & correct_class) # IoU > threshold and classes match if x[0].shape[0]: matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy() # [label, detect, iou] if x[0].shape[0] > 1: matches = matches[matches[:, 2].argsort()[::-1]] matches = matches[np.unique(matches[:, 1], return_index=True)[1]] # matches = matches[matches[:, 2].argsort()[::-1]] matches = matches[np.unique(matches[:, 0], return_index=True)[1]] correct[matches[:, 1].astype(int), i] = True return torch.tensor(correct, dtype=torch.bool, device=iouv.device) @smart_inference_mode() def run( data, weights=None, # model.pt path(s) batch_size=32, # batch size imgsz=640, # inference size (pixels) conf_thres=0.001, # confidence threshold iou_thres=0.6, # NMS IoU threshold max_det=300, # maximum detections per image task='val', # train, val, test, speed or study device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu workers=8, # max dataloader workers (per RANK in DDP mode) single_cls=False, # treat as single-class dataset augment=False, # augmented inference verbose=False, # verbose output save_txt=False, # save results to *.txt save_hybrid=False, # save label+prediction hybrid results to *.txt save_conf=False, # save confidences in --save-txt labels save_json=False, # save a COCO-JSON results file project=ROOT / 'runs/val', # save to project/name name='exp', # save to project/name exist_ok=False, # existing project/name ok, do not increment half=True, # use FP16 half-precision inference dnn=False, # use OpenCV DNN for ONNX inference model=None, dataloader=None, save_dir=Path(''), plots=True, callbacks=Callbacks(), compute_loss=None, ): # Initialize/load model and set device training = model is not None if training: #
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
这是一个用于在检测数据集上验证训练好的YOLOv5检测模型的程序文件。它可以使用命令行参数来指定模型权重文件、数据集配置文件、图像大小等参数。程序会加载模型并将其设置为评估模式,然后使用数据集加载器加载验证数据集。接下来,程序会对每个批次的图像进行推理,并使用非最大抑制(NMS)来筛选出检测结果。最后,程序会计算并输出模型的精度指标,如准确率、召回率和mAP(平均精度均值)。
5.6 yolo.py
class Detect(nn.Module): stride = None # strides computed during build onnx_dynamic = False # ONNX export parameter def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer super().__init__() self.nc = nc # number of classes self.no = nc + 5 # number of outputs per anchor self.nl = len(anchors) # number of detection layers self.na = len(anchors[0]) // 2 # number of anchors self.grid = [torch.zeros(1)] * self.nl # init grid self.anchor_grid = [torch.zeros(1)] * self.nl # init anchor grid self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2) self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv self.inplace = inplace # use in-place ops (e.g. slice assignment) def forward(self, x): z = [] # inference output for i in range(self.nl): x[i] = self.m[i](x[i]) # conv bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85) x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous() if not self.training: # inference if self.grid[i].shape[2:4] != x[i].shape[2:4] or self.onnx_dynamic: self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i) y = x[i].sigmoid() if self.inplace: y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953 xy = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh y = torch.cat((xy, wh, y[..., 4:]), -1) z.append(y.view(bs, -1, self.no)) return x if self.training else (torch.cat(z, 1), x) def _make_grid(self, nx=20, ny=20, i=0): d = self.anchors[i].device yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)]) grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float() anchor_grid = (self.anchors[i].clone() * self.stride[i]) \ .view((1, self.na, 1, 1, 2)).expand((1, self.na, ny, nx, 2)).float() return grid, anchor_grid class Model(nn.Module): def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, anchors=None): # model, input channels, number of classes super().__init__() if isinstance(cfg, dict): self.yaml = cfg # model dict else: # is *.yaml import yaml # for torch hub self.yaml_file = Path(cfg).name with open(cfg, errors='ignore') as f: self.yaml = yaml.safe_load(f) # model dict # Define model ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels if nc and nc != self.yaml['nc']: LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}") self.yaml['nc'] = nc # override yaml value if anchors: LOGGER.info(f'Overriding model.yaml anchors with anchors={anchors}') self.yaml['anchors'] = round(anchors) # override yaml value self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist self.names = [str(i) for i in range(self.yaml['nc'])] # default names self.inplace = self.yaml.get('inplace', True) # Build strides, anchors m = self.model[-1] # Detect() if isinstance(m, Detect): s = 256 # 2x min stride m.inplace = self.inplace m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward m.anchors /= m.stride.view(-1, 1, 1) check_anchor_order(m) self.stride = m.stride self._initialize_biases() # only run once # Init weights, biases initialize_weights(self) self.info() LOGGER.info('') def forward(self, x, augment=False, profile=False, visualize=False): if augment: return self._forward_augment(x) # augmented inference, None return self._forward_once(x, profile, visualize) # single-scale inference, train def _forward_augment(self, x): img_size = x.shape[-2:] # height, width s = [1, 0.83, 0.67] # scales f = [None, 3, None] # flips (2-ud, 3-lr) y = [] # outputs for si, fi in zip(s, f): xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max())) yi = self._forward_once(xi)[0] # forward # cv2.imwrite(f'img_{si}.jpg', 255 * xi[0].cpu().numpy().transpose((1, 2, 0))[:, :, ::-1]) # save yi = self._descale_pred(yi, fi, si, img_size) y.append(yi) y = self._clip_augmented(y) # clip augmented tails return torch.cat(y, 1), None # augmented inference, train def _forward_once(self, x, profile=False, visualize=False): y, dt = [], [] # outputs for m in self.model: if m.f != -1: # if not from previous layer x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers if profile: self._profile_one_layer(m, x, dt) if hasattr(m, 'backbone'): x = m(x) for _ in range(5 - len(x)): x.insert(0, None) for i_idx, i in enumerate(x): if i_idx in self.save: y.append(i) else: y.append(None) x = x[-1] else: x = m(x) # run y.append(x if m.i in self.save else None) # save output if visualize: feature_visualization
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
这是一个YOLOv5的程序文件,用于目标检测。程序中定义了一些YOLO-specific的模块,包括Detect和Model。Detect模块是YOLO的检测层,用于输出检测结果。Model模块是整个YOLOv5模型的定义,包括网络结构、权重初始化等。程序还包括一些辅助函数,用于处理输入数据、计算FLOPs等。
6.系统整体结构
整体功能和构架概述:
该项目是一个基于MySQL和Densenet的改进YOLOv5的中草药图像分类系统。它包含了目标检测、图像分类和图像分割等功能。程序文件之间存在一定的层次结构和依赖关系,其中一些文件是用于训练模型,一些文件是用于推理和展示结果。
以下是每个文件的功能概述:
| 文件路径 | 功能概述 |
|---|---|
| export.py | 将YOLOv5模型导出为其他格式的工具 |
| model.py | 计算模型的FLOPS和参数数量 |
| train.py | 训练YOLOv5模型的主程序,包括数据加载、模型创建、优化器设置等 |
| ui.py | 运行YOLOv5模型进行目标检测和分类的用户界面程序 |
| val.py | 在检测数据集上验证训练好的YOLOv5检测模型的程序 |
| yolo.py | YOLOv5的程序文件,包括YOLO-specific的模块和辅助函数 |
| classify\predict.py | 使用训练好的模型进行图像分类的推理程序 |
| classify\train.py | 训练图像分类模型的主程序,包括数据加载、模型创建、优化器设置等 |
| classify\val.py | 在验证数据集上验证训练好的图像分类模型的程序 |
| models\common.py | 包含YOLOv5模型的通用函数和类 |
| models\experimental.py | 包含YOLOv5的实验性模型定义和函数 |
| models\tf.py | 包含YOLOv5的TensorFlow模型定义和函数 |
| models\yolo.py | 包含YOLOv5的模型定义和函数 |
| models_init_.py | 模型模块的初始化文件 |
| segment\predict.py | 使用训练好的模型进行图像分割的推理程序 |
| segment\train.py | 训练图像分割模型的主程序,包括数据加载、模型创建、优化器设置等 |
| segment\val.py | 在验证数据集上验证训练好的图像分割模型的程序 |
| utils\activations.py | 包含激活函数的定义和函数 |
| utils\augmentations.py | 包含数据增强函数的定义和函数 |
| utils\autoanchor.py | 包含自动锚框生成函数的定义和函数 |
| utils\autobatch.py | 包含自动批处理函数的定义和函数 |
| utils\callbacks.py | 包含回调函数的定义和函数 |
| utils\dataloaders.py | 包含数据加载器的定义和函数 |
| utils\downloads.py | 包含下载函数的定义和函数 |
| utils\general.py | 包含通用函数的定义和函数 |
| utils\loss.py | 包含损失函数的定义和函数 |
| utils\metrics.py | 包含评估指标的定义和函数 |
| utils\plots.py | 包含绘图函数的定义和函数 |
| utils\torch_utils.py | 包含PyTorch工具函数的定义和函数 |
| utils\triton.py | 包含Triton Inference Server的函数和类 |
| utils_init_.py | 工具模块的初始化文件 |
| utils\aws\resume.py | 包含AWS训练恢复函数的定义和函数 |
| utils\aws_init_.py | AWS模块的初始化文件 |
| utils\flask_rest_api\example_request.py | 包含Flask REST API示例请求的定义和函数 |
| utils\flask_rest_api\restapi.py | 包含Flask REST API的定义和函数 |
| utils\loggers_init_.py | 日志记录器模块的初始化文件 |
| utils\loggers\clearml\clearml_utils.py | 包含ClearML日志记录器的工具函数和类 |
| utils\loggers\clearml\hpo.py | 包含ClearML超参数优化函数的定义和函数 |
| utils\loggers\clearml_init_.py | ClearML日志记录器模块的初始化文件 |
| utils\loggers\comet\comet_utils.py | 包含Comet日志记录器的工具函数和类 |
| utils\loggers\comet\hpo.py | 包含Comet超参数优化函数的定义和函数 |
| utils\loggers\comet_init_.py | Comet日志记录器模块的初始化文件 |
| utils\loggers\wandb\wandb_utils.py | 包含WandB日志记录器的工具函数和类 |
| utils\loggers\wandb_init_.py | WandB日志记录器模块的初始化文件 |
| utils\segment\augmentations.py | 包含图像分割数据增强函数的定义和函数 |
| utils\segment\dataloaders.py | 包含图像分割数据加载器的定义和函数 |
| utils\segment\general.py | 包含图像分割通用函数的定义和函数 |
| utils\segment\loss.py | 包含图像分割损失函数的定义和函数 |
| utils\segment\metrics.py | 包含图像分割评估指标的定义和函数 |
| utils\segment\plots.py | 包含图像分割绘图函数的定义和函数 |
| utils\segment_init_.py | 图像分割工具模块的初始化文件 |
7.Densenet简介
Densenet简介
dense block中每个H操作33卷积前面都包含了一个11的卷积操作,称为bottleneck layer,目的是减少输入的feature map数量,一方面降维减少计算量,又能融合各个通道的特征。Transition层包括一个1x1的卷积和2x2的AvgPooling,结构为BN+ReLU+1x1 Conv+2x2 AvgPooling。
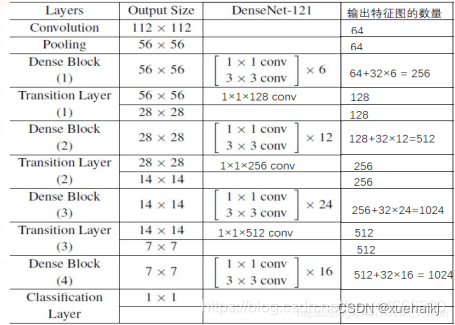
Dense Block
从图中可以看到,第一个DenseBlock包含6个[11 conv, 33 conv], 此处的[11 conv, 33 conv]即为Bottleneck结构,具体如下:
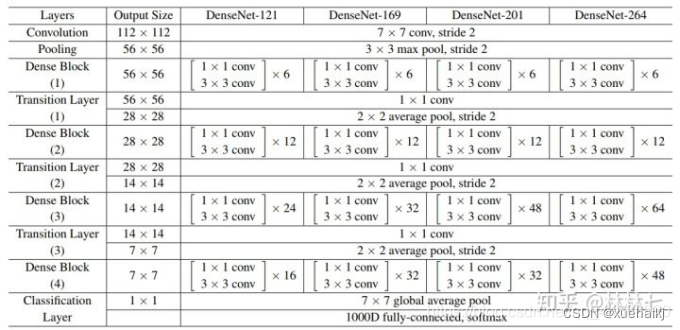
此处的BN-ReLU放在卷积前面(有文章实验证明过这样效果更好).
网络四个优点
1、减轻梯度消失
2、提高了特征的传播效率
3、提高了特征的利用效率
4、减小了网络的参数量
1.卷积神经网络CNN在计算机视觉物体识别上优势显著,典型的模型有:LeNet5, VGG, Highway Network, Residual Network.
2.CNN越深则效果越好,但是,会面临梯度弥散的问题,经过层数越多,则前面的信息就会渐渐减弱和消散。
3.目前已有很多措施去解决以上困境:
(1)Highway Network,Residual Network通过前后两层的残差链接使信息尽量不丢失
(2)Stochastic depth通过随机drop掉Resnet的一些层来缩短模型
(3)FractalNets通过重复组合一些平行的层序列来保证深度的同时减轻这个问题。
Densenet特点
DenseNet(密集卷积网络)主要还是和ResNet及Inception网络做对比,思想上有借鉴,但却是全新的结构,网络结构并不复杂,却非常有效值!众所周知,最近一两年卷积神经网络提高效果的方向,要么深(比如RESNET,解决了网络深时候的梯度消失问题),要么宽(比如GoogleNet的盗梦空间),而作者则是从功能入手,通过对功能的极致利用达到更好的效果和更少的参数。
先放一个密块的结构图。在传统的卷积神经网络中,如果你有L层,那么就会有L个连接,但是在DenseNet中,会有L(L + 1)/ 2个连接。。简单讲,每就是一层的输入侧来自前面所有层的输出如下图产品:X0是输入,H1的输入是X0(输入),H2的输入是X0和X1(X1是H1的输出)
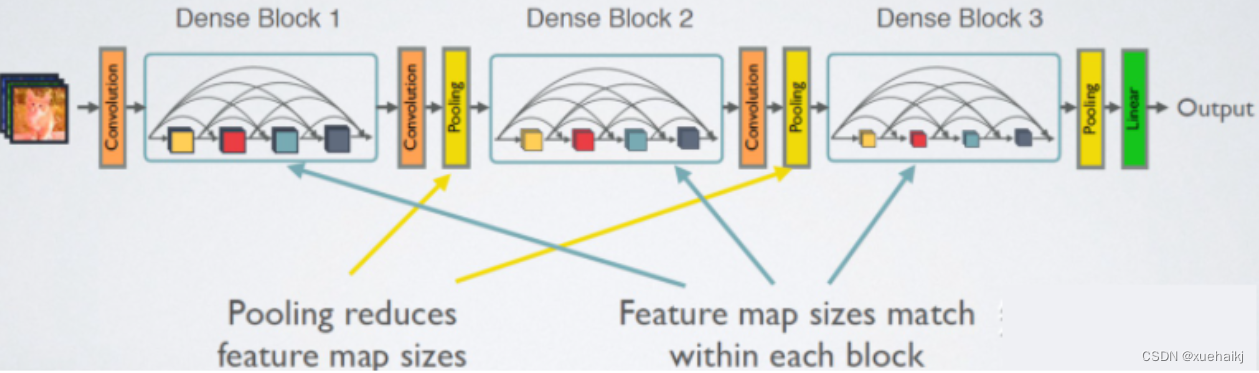
8.替换骨干网络为Densenet的YOLOv5
为何选择Densenet
Densenet是一种密集连接的卷积神经网络,与传统的卷积神经网络(CNN)不同,它引入了密集连接(Dense Connection)的思想。这意味着每一层的输出都会与前面所有层的输出相连接,形成了密集的特征传递路径。这一设计优势在于更好的梯度传播和特征重用,有助于提高模型的性能。
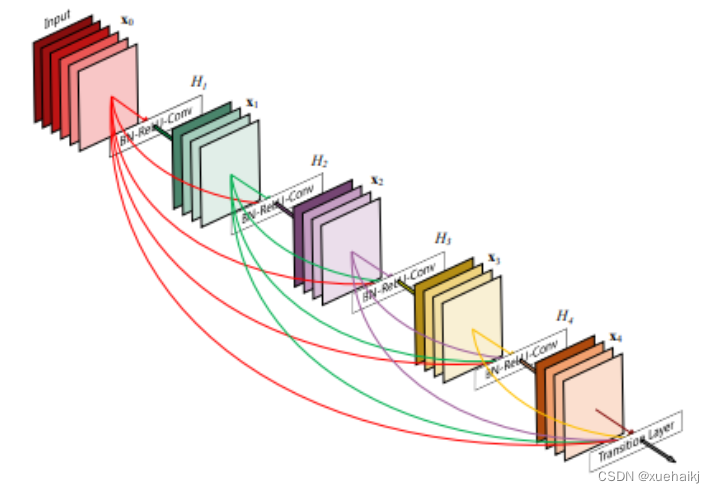
密集连接的特性使得Densenet在训练过程中减轻了梯度消失问题,因为信息可以更自由地在网络中传递。此外,由于每一层都能看到前面所有层的输出,模型更容易学到更高层次的抽象特征,这对于目标检测任务特别有帮助。
替换过程
替换YOLOv5的骨干网络为Densenet需要一系列步骤。首先,我们导入预训练的Densenet模型。接着,我们需要将YOLOv5的骨干网络的卷积层逐一替换为Densenet的对应层。这需要仔细的层级映射和参数适配,以确保特征传递的正确性和匹配。
替换后的YOLOv5模型将具有Densenet的特征提取能力,这有望提升模型对中草药图像的特征学习和表示能力。不过,这也可能需要进一步的微调和实验以达到最佳性能。
替换的方法
替换YOLOv5的骨干网络为Densenet是一项复杂的任务,需要仔细的实施和调整。以下是替换的一般方法:
导入预训练的Densenet模型: 首先,我们导入一个在大规模图像分类任务上预训练的Densenet模型。这个模型已经学会了对图像进行高效特征提取。
替换YOLOv5的骨干网络层: 接下来,我们需要将YOLOv5的骨干网络的卷积层逐一替换为Densenet模型中对应的层。这包括卷积核的权重和参数的适配,以确保特征传递的正确性和匹配。
调整输入通道数: YOLOv5的输入通道数通常与Densenet不同,因此需要对模型的输入通道数进行相应的调整,以匹配Densenet的输入要求。
修改检测头部: 最后,由于骨干网络的改变可能会影响到检测头部(Detection Head)的输出,需要相应地修改检测头部以适应新的骨干网络。这可能涉及到调整锚框(Anchor Boxes)的尺寸和数量等。
微调和实验: 替换后的模型通常需要进行微调和实验,以达到最佳性能。这可能包括调整超参数、训练数据的增强策略以及优化器的选择。
替换的好处
替换YOLOv5的骨干网络为Densenet具有多方面的好处,这些好处可以显著影响模型的性能和能力:
更强大的特征提取能力: Densenet的密集连接设计使得模型更容易学到高级别的抽象特征,有助于提高模型的表示能力。
减轻梯度消失问题: 密集连接有助于梯度更自由地传播,降低了梯度消失问题的发生,使模型更容易训练。
特征重用: 每一层都可以看到前面所有层的输出,这鼓励特征的重用,有助于提高模型的泛化能力。
更好的性能: Densenet在图像分类等任务上已经表现出色,将其用作YOLOv5的骨干网络有望带来更好的目标检测性能。
总之,替换YOLOv5的骨干网络为Densenet是一个值得尝试的改进方法,可以提高模型的特征提取和表示能力,从而在中草药图像分类系统中实现更准确和可靠的结果。接下来,我们将继续讨论如何微调和评估这个改进后的模型。
9.训练结果分析
训练参数的确定
model:用于迁移学习的预训练YOLOv5模型文件的路径。
data:用于训练和测试的数据集的路径。
epochs:为实验设置的训练时期总数(本例中为 300)。
batch_size:模型内部参数更新之前处理的样本数量(每批次 16 个样本)。
imgsz:模型的输入图像大小(图像大小调整为 224x224 像素)。
nosave:训练时是否保存模型权重(设置为false,则保存权重)。
device:用于训练的设备(空字符串可能表示默认设备,除非指定,否则通常是 CPU)。
workers:用于数据加载的子进程数量(0表示数据将在主进程中加载)。
project:保存训练运行的目录。
name:实验的名称。
exist_ok:如果设置为false,如果项目目录已存在,则会引发错误。
pretrained:指示模型是否使用预训练权重(设置为true)。
optimizer:使用的优化算法(本例中为 Adam)。
lr0:优化器的初始学习率 (0.001)。
decay:用于正则化的权重衰减(L2 惩罚)(5.0e-05)。
label_smoothing:一种用于降低模型对其预测的信心的技术(设置为 0.1)。
seed:再现性的随机种子(设置为 0)。
save_dir:保存训练好的模型和结果的目录。
训练结果可视化
# Correcting the column names by including the leading spaces plt.figure(figsize=(14, 7)) # Training and testing loss plt.subplot(1, 2, 1) plt.plot(results_data[' epoch'], results_data[' train_loss'], label='Training Loss') plt.plot(results_data[' epoch'], results_data[' test_loss'], label='Testing Loss') plt.title('Training and Testing Loss') plt.xlabel('Epoch') plt.ylabel('Loss') plt.legend() # Top-1 and top-5 accuracy plt.subplot(1, 2, 2) plt.plot(results_data[' epoch'], results_data[' metrics_accuracy_top1'], label='Top-1 Accuracy', color='orange') plt.plot(results_data[' epoch'], results_data[' metrics_accuracy_top5'], label='Top-5 Accuracy', color='green') plt.title('Top-1 and Top-5 Accuracy') plt.xlabel('Epoch') plt.ylabel('Accuracy') plt.legend() plt.tight_layout() plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
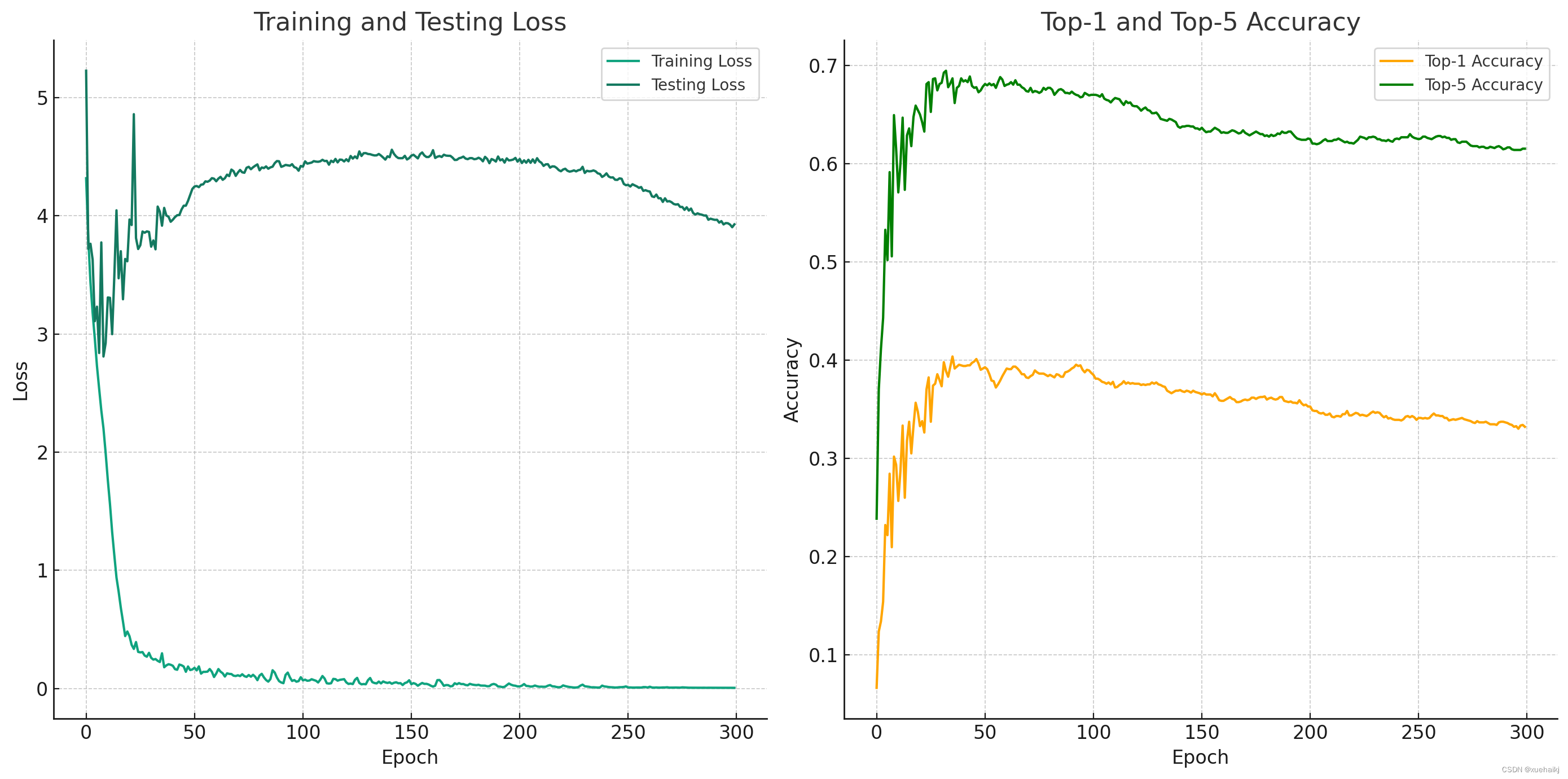
训练结果分析
epoch:这代表训练纪元数,指示训练过程的特定迭代。
train/loss:这显示了相应时期后训练数据集的损失。损失是模型性能的衡量标准,值越低表示性能越好。
test/loss:与训练损失类似,这表示测试数据集上的损失。该指标有助于了解模型对新的、未见过的数据的推广效果如何。
metrics/accuracy_top1:这是测试数据集上的 top-1 准确度,代表模型最高概率预测正确的次数比例。
metrics/accuracy_top5:这是测试数据集上前 5 名的准确率,表示正确答案在模型做出的前 5 名预测中的次数比例。
lr/0:这可能代表该时期使用的学习率。学习率是训练神经网络的一个关键超参数,它控制梯度下降期间的步长。
从最初的几行数据中,我们可以观察到以下内容:
随着时代的进展,训练和测试损失都会减少,这表明模型正在随着时间的推移学习并改进其预测。
top-1 和 top-5 准确率都在持续增加,这也表明模型的性能随着每个 epoch 的提高而提高。
学习率随着每个时期的推移而略有下降,这是帮助模型逐渐收敛到更好的权重集的常见策略。

10.系统整合

参考博客《基于MySQL和Densenet的改进YOLOv5的100种中草药图像分类系统》
11.参考文献
[1]谢圣桥,宋健,汤修映,等.基于迁移学习和残差网络的葡萄叶部病害识别[J].农机化研究.2023,45(8).DOI:10.3969/j.issn.1003-188X.2023.08.003 .
[2]陈贝文,陈淦.水果分类识别与成熟度检测技术综述[J].计算机时代.2022,(7).DOI:10.16644/j.cnki.cn33-1094/tp.2022.07.016 .
[3]朱明秀.采摘机器人水果检测及定位研究—基于图像处理和卷积神经网络[J].农机化研究.2022,44(4).DOI:10.3969/j.issn.1003-188X.2022.04.009 .
[4]周维,牛永真,王亚炜,等.基于改进的YOLOv4-GhostNet水稻病虫害识别方法[J].江苏农业学报.2022,38(3).DOI:10.3969/j.issn.1000-4440.2022.03.014 .
[5]曾伟辉,张文凤,陈鹏,等.基于SCResNeSt的低分辨率水稻害虫图像识别方法[J].农业机械学报.2022,53(9).DOI:10.6041/j.issn.1000-1298.2022.09.028 .
[6]曹跃腾,朱学岩,赵燕东,等.基于改进ResNet的植物叶片病虫害识别[J].中国农机化学报.2021,42(12).DOI:10.13733/j.jcam.issn.2095-5553.2021.12.26 .
[7]徐印赟,江明,李云飞,等.基于改进YOLO及NMS的水果目标检测[J].电子测量与仪器学报.2022,36(4).DOI:10.13382/j.jemi.B2104724 .
[8]高雨亮,徐向英,章永龙,等.融合分组注意力机制的水稻病虫害图像识别算法[J].扬州大学学报(自然科学版).2021,24(6).DOI:10.19411/j.1007-824x.2021.06.010 .
[9]Kasinathan Thenmozhi,Uyyala Srinivasulu Reddy.Machine learning ensemble with image processing for pest identification and classification in field crops[J].Neural computing & applications.2021,33(13).7491-7504.DOI:10.1007/s00521-021-05690-8 .
[10]佚名.Identification and recognition of rice diseases and pests using convolutional neural networks[J].Biosystems Engineering.2020.194112-120.DOI:10.1016/j.biosystemseng.2020.03.020 .


