
- 1新书周榜:机器学习、Python、Linux成为最闪亮的星_linux设备驱动开发 刘寿永
- 2《ChatGPT原理与架构:大模型的预训练、迁移和中间件编程 》
- 3Azure系列2.1.11 —— CloudBlobContainer
- 43.15国际消费者权益日:消费者隐私威胁与保护
- 5获取docker镜像内文件_docker镜像提取文件
- 6浅谈集群和分布式的区别和联系_做了分布式部署还有必要做集群吗?
- 7MAC(适用于M1,M2芯片)下载Java8(官方 ARM64 JDK1.8)安装、配置环境,支持动态切换JDK_mac jdk1.8下载
- 8org/apache/commons/logging/LogFactory
- 9常见软件发布版本编号解释
- 10模拟电子技术------半导体_为什么 电子漂移运动是不利现象
数据导入与预处理-第6章-03数据规约
赞
踩
3 数据规约
3.1 数据规约概述(6.3.1 )
数据规约:
对于中型或小型的数据集而言,通过前面学习的预处理方式已经足以应对,但这些方式并不适合大型数据集。由于大型数据集一般存在数量庞大、属性多且冗余、结构复杂等特点,直接被应用可能会耗费大量的分析或挖掘时间,此时便需要用到数据规约。
数据规约类似数据集的压缩,它的作用主要是从原有数据集中获得一个精简的数据集,这样可以在降低数据规模的基础上,保留了原有数据集的完整特性。在使用精简的数据集进行分析或挖掘时,不仅可以提高工作效率,还可以保证分析或挖掘的结果与使用原有数据集获得的结果基本相同。
要完成数据规约这一过程,可采用多种手段,包括维度规约、数量规约和数据压缩。
3.1.1 维度规约概述
维度规约是指减少所需属性的数目。数据集中可能包含成千上万个属性,绝大部分属性与分析或挖掘目标无关,这些无关的属性可直接被删除,以缩小数据集的规模,这一操作就是维度规约。
维度规约的主要手段是属性子集选择,属性子集选择通过删除不相关或冗余的属性,从原有数据集中选出一个有代表性的样本子集,使样本子集的分布尽可能地接近所有数据集的分布。
3.1.2 数量规约概述
数量规约是指用较小规模的数据替换或估计原数据,主要包括
回归与线性对数模型
直方图
聚类
采样
数据立方体
这几种方法,其中直方图是一种流行的数据规约方法。
直方图是一种流行的数据规约方法,它会将给定属性的数据分布划分为不相交的子集或桶(给定属性的一个连续区间)。
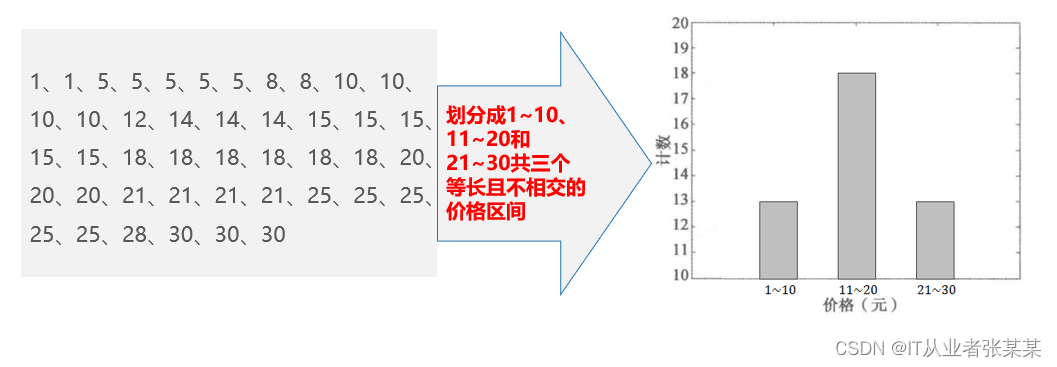
采样也是一种常用的数据规约手段,它通过选取随机样本以实现用小数据代表大数据,主要包括简单随机采样、聚类采样、分层采样等几种方法。
简单随机采样:简单随机采样又分为无放回简单随机抽样和有放回简单随机抽样,都是从原有数据集中的若干个元组中抽取部分样本。
聚类采样:聚类采样会先将原有数据集划分成若干个不相交的类,再从这些类的数据中抽取部分样本数据。
分层采样:分层采样会将原有数据集划分为若干个不相交的层,再从每层中随机收取部分样本数据。
3.1.3 数据压缩
数据压缩是利用编码或转换将原有数据集压缩为一个较小规模的数据集。
无损压缩:若原有数据集能够从压缩后的数据集中重构,且不损失任何信息,则该数据压缩是无损压缩。
有损压缩:若原有数据集只能够从压缩后的数据集中近似重构,则该数据压缩是有损压缩。
在进行数据挖掘时,数据压缩通常采用两种有损压缩方法,分别是小波转换和主成分分析,这两种方法都会把原有数据变换或投影到较小的空间。
pandas中提供了一些实现数据规约的操作,包括重塑分层索引(6.3.2小节)和降采样(6.3.3小节),其中重塑分层索引是一种基于维度规约手段的操作,降采样是一种基于数量规约手段的操作,这些操作都会在后面的小节展开介绍。
3.2 重塑分层索引(6.3.2 )
3.2.1 重塑分层索引介绍
重塑分层索引是pandas中简单的维度规约操作,该操作主要会将DataFrame类对象的列索引转换为行索引,生成一个具有分层索引的结果对象。
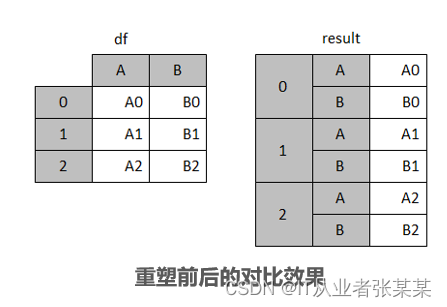
df起初是一个只有单层索引的二维数据,其经过重塑分层索引操作之后,生成一个有两层行索引结构的result对象。
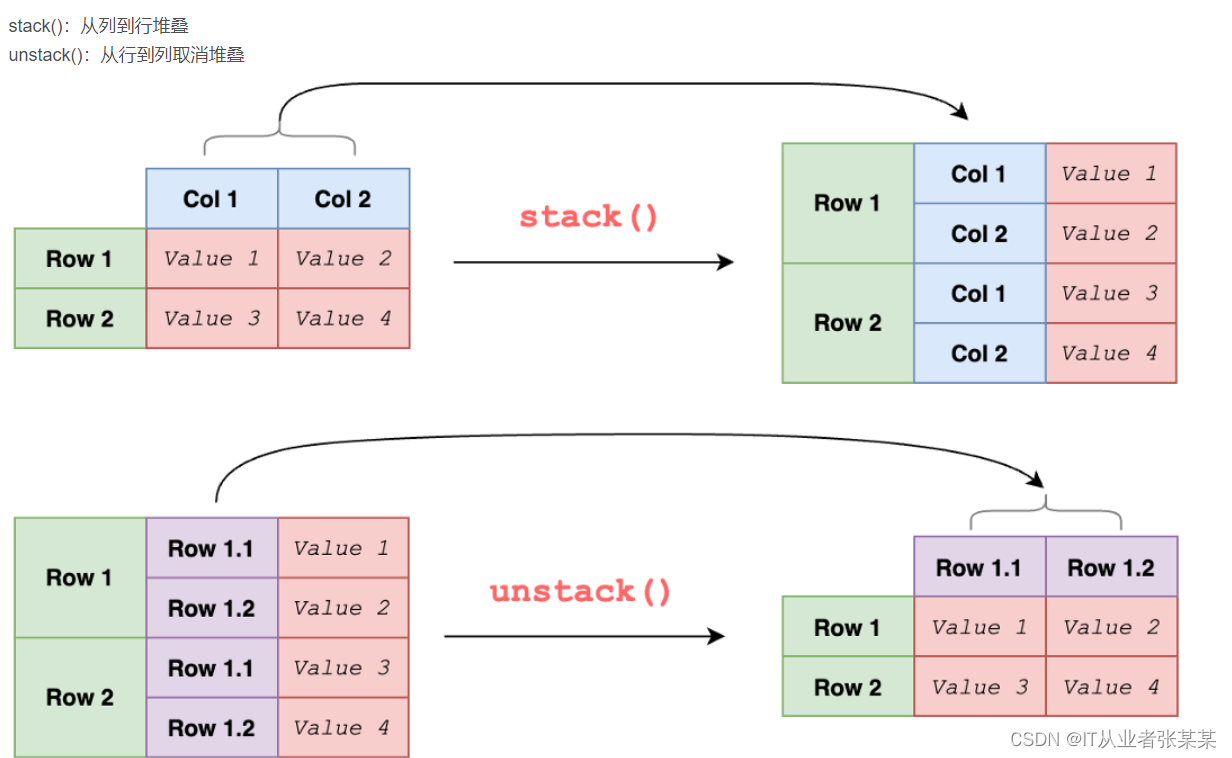
3.2.2 stack和unstack用法
pandas中可以使用stack()方法实现重塑分层索引操作。
stack(level=- 1, dropna=True)
- 1
level:表示索引的级别,默认为-1,即操作内层索引,若设为0,则会操作外层索引。
dropna:表示是否删除结果对象中存在缺失值的一行数据,默认为True。
同时还有一个stack的逆操作,unstack。两者的操作如下:
案例操作:
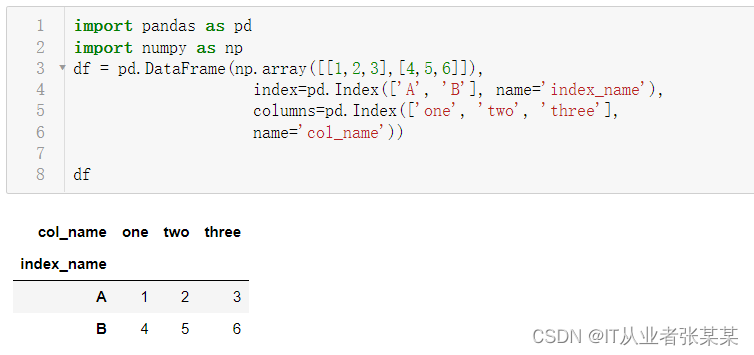
初始化数据
import pandas as pd
import numpy as np
df = pd.DataFrame(np.array([[1,2,3],[4,5,6]]),
index=pd.Index(['A', 'B'], name='index_name'),
columns=pd.Index(['one', 'two', 'three'],
name='col_name'))
df
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
输出为:
使用stack列转行
# 重塑df,使之具有两层行索引
# 原来的列数据one, two, three就到了行上来了,形成多层索引。
# 注意这里:stack()操作后返回的对象是Series类型
result = df.stack()
result
- 1
- 2
- 3
- 4
- 5
输出为:

使用unstack行转列
result.unstack()
- 1
输出为:
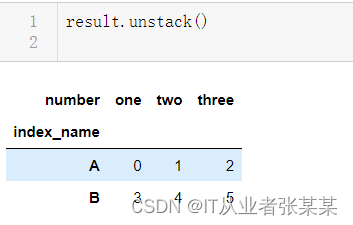
执行unstack时也可以指定层次
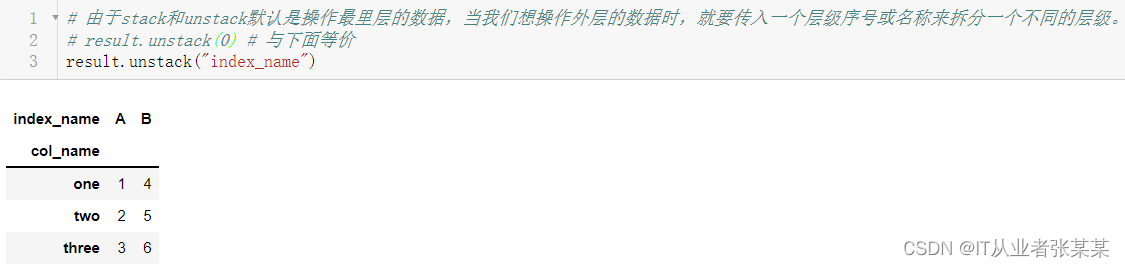
# 由于stack和unstack默认是操作最里层的数据,当我们想操作外层的数据时,就要传入一个层级序号或名称来拆分一个不同的层级。
# result.unstack(0) # 与result.unstack("index_name")等价
result.unstack("index_name")
- 1
- 2
- 3
输出为:
3.3 降采样(6.3.3 )
3.3.1 降采样介绍
降采样是一种简单的数据规约操作,它主要是将高频率采集数据规约到低频率采集数据,比如,从每日采集一次数据降低到每月采集一次数据,会增大采样的时间粒度,且在一定程度上减少了数据量。
降采样常见于时间序列类型的数据。假设现有一组按日统计的包含开盘价、收盘价等信息的股票数据(非真实数据),该组数据的采集频率由每天采集一次变为每7天采集一次。
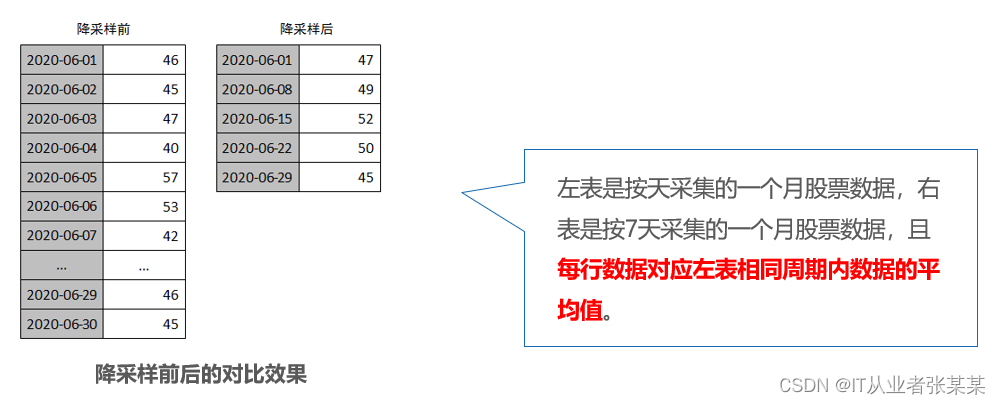
左表是按天采集的一个月股票数据,右表是按7天采集的一个月股票数据,且每行数据对应左表相同周期内数据的平均值。
3.3.2 降采样resample用法
pandas中可以使用resample()方法实现降采样操作。resample方法,是针对时间序列的频率转换和重采样的简便方法。对象必须具有类似日期时间的索引(DatetimeIndex、PeriodIndex或TimedeltaIndex),或者调用方必须将类似日期时间的系列/索引的标签传递给on/level关键字参数。
resample(rule, axis=0, closed=None, label=None, convention='start',
kind=None, loffset=None, base=None, on=None, level=None,
origin='start_day', offset=None)
- 1
- 2
- 3
rule:表示降采样的频率。
axis:表示沿哪个轴完成降采样操作,可以取值为0/‘index’或1/‘columns’,默认值为0。
closed:表示各时间段的哪一端是闭合的,可取值为’right’、'left’或None。
label:表示降采样时设置的聚合结果的标签。
limit:表示允许前向或后向填充的最大时期数。
更多操作可以参考官网
创建9个间隔1分钟的时间戳Series
import numpy as np
import pandas as pd
# 创建9个间隔1分钟的时间戳Series。
index = pd.date_range('1/1/2000', periods=9, freq='T')
series = pd.Series(range(9), index=index)
series
- 1
- 2
- 3
- 4
- 5
- 6
输出为:

按照时间间隔3分钟下采样:
# 按照时间间隔3分钟下采样
series.resample('3T').sum()
- 1
- 2
输出为:


