
- 1Tuxera NTFS2022Mac如何安装以及怎么激活NTFS?_tuxera ntfs激活版 csdn
- 2Linux安装Anaconda和虚拟环境配置_env.yaml文件 linux 使用
- 3简单实现gcc/g++更换版本_gcc版本切换
- 4华为云IOT Android应用开发详细教程_android iot 文档
- 5Substance Designer(基础一)Blend节点的混合模式(未完)_节点类型 混合
- 6在Win11电脑上安装安装APP详细过程_安装amazon出现错误,请稍后重试
- 7素描令牌:一个中层的学习轮廓和目标检测的表征Sketch Tokens: A Learned Mid-level Representation for Contour and Object Detec
- 8华为的鸿蒙系统是安卓吗,华为鸿蒙,一个本属于2025年的产品
- 9源自国家电网,可用于新能源发电预测的高质量数据集_发电预测数据集如何划分
- 10adb 常用命令_pm compile -m speed
利用ffmpeg对两个音频文件进行混音处理
赞
踩
前言
最近,拿到了一个语音识别程序,想测试一下它识别的准确性。原本程序有一段自己的测试音频,准确性还可以,但是,自己想增加一下测试素材的复杂性。想到了在原本的测试音频中引入干扰数据(噪点),再看一下语音识别程序的健壮性。
正文
1、素材介绍
原本程序自带的音频测试素材是一段时长 24 秒的 wav 文件,其中包含了关键词 Yes 和 No,两个关键词出现的具体时间点如下:
yes @1100ms
no @5500ms
yes @9100ms
no @13600ms
yes @17100ms
no @21600ms
想引入的噪点数据是前段时间在抖音上比较火的背景音乐——《野花与栀子花》,具体内容这里就省略了。
2、混音处理
最基础的 ffmpeg 混音命令如下:
ffmpeg -i test.wav -i flowers.mp3 -b:a 16k -ac 2 -ar 48000 -filter_complex "amix=inputs=2" mixed_audio.wav
简单介绍一下上述参数:
-b:a 16,音频码率为16kbps
-ac 2,音频声道数为2
-ar 48000,音频采样率为48kHz
-filter_complex "amix=inputs=2" ,音频过滤器
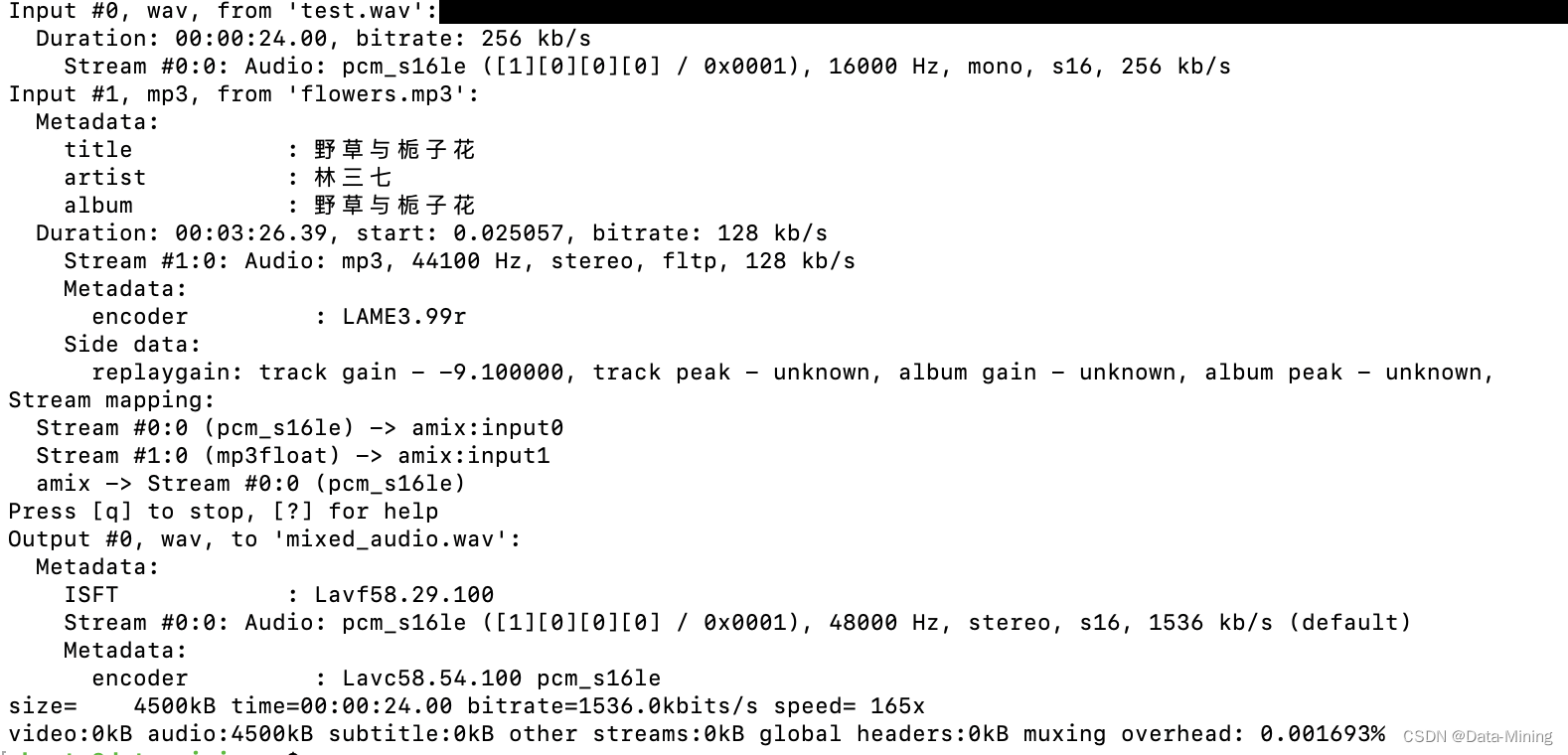
执行结果如下:

生成的混音文件 mixed_audio.mp3 包含了两个输入音频文件的内容,只是叠加到了一起。不过细心的网友会发现,这个输出音频文件的时长是以最长的输入音频文件长度为准的,也就是音乐《野花与栀子花》的时长,3分26秒。
如何让它以最短时长的音频文件长度为准呢,可以增加参数 duration=shortest,具体命令如下:
ffmpeg -i test.wav -i flowers.mp3 -b:a 16k -ac 2 -ar 48000 -filter_complex "amix=inputs=2:duration=shortest" mixed_audio.wav
执行结果如下:
3、测试
最后使用新生成的音频素材进行测试,准确率确实受到了影响,但是整体影响不大。

