
- 1企业DevOps:实施过程中需要关注的各项要点_devops 心得体会
- 2机器学习经典开源数据集盘点
- 3Kafka数据清理指南
- 4The injection point has the following annotations: - @org.springframework.beans.factory.annotation.
- 5" href="/w/Gausst松鼠会/article/detail/235323" target="_blank">Scss 基本使用 ( @extend、 @mixin、@import、@if、@for、@while、@each )_当前位置: article > 正文
java学习记录_java学习项目记录
作者:小小林熬夜学编程 | 2024-03-18 08:12:56赞
踩
java学习项目记录前言
- Java系列课之基础入门:钟洪发老师
- JAVA零基础入门笔记
JAVA学习指导

00.关于Java学习的一个开场白

01.常用dos命令和ava环境软件下载
在开始学习java之前,我们必须掌握一些常用的dos命令:
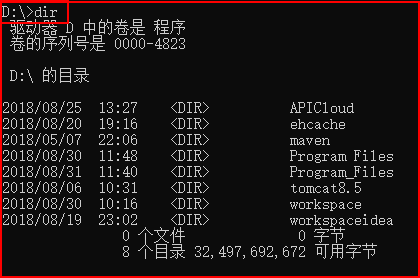
一、dir:查看计算机目录里有文件或子目录
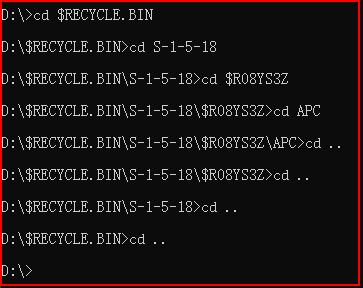
二、cd:目录切换
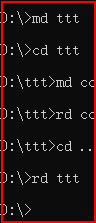
三、md和rd:md,创建目录;rd,删除目录
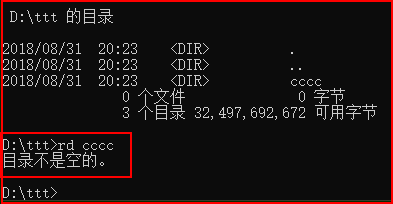
注意目录不是空的删除不了:
四、cls:清屏
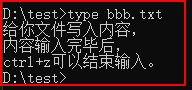
五、copy创建一个文件(txt文件,给文件写入内容)

六、del+文件名删除文件:
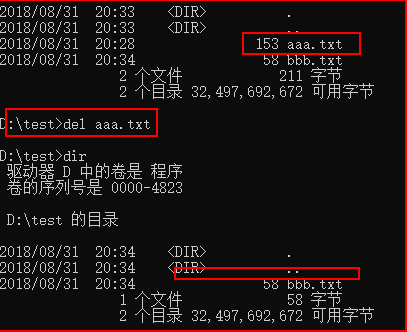
七、type显示一个文本文件的内容
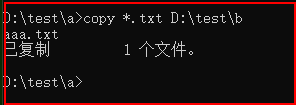
八、copy把文件复制到另一个目录
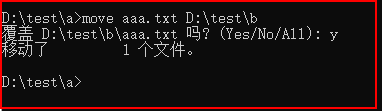
九、move:把文件移动到另一个目录
十、ren:把旧文件名改新名字
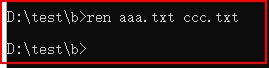
Java的开发环境下载:在百度上搜索JDK,进入官网下载!
02.Jdk安装与环境变量配置

03. 第一个ava程序 Helloworld案例与 javadoc
用记事本写第一个java程序HelloWorld
- 第一步:写java源代码程序:HelloWorld.java
- 第二步:编译java源代码程序,生成HelloWorld.class文件,字节码文件
- 第三步:运行程序.
public class HelloWorld{ public static void main(String[] args){ System.out.println("Hello World!"); } }- 1
- 2
- 3
- 4
- 5
注释:给程序员看的,帮助程序员理解和记忆的说明文字,计算机会视而不见
- 文档注释:
/** */- 1
- 2
- 单行注释:
//- 1
- 多行注释:
/* */- 1
- 2
javadoc命令:将文档注释的内容生成帮助文档
javadoc *.java,通常和通配符联合使用04.学习Java使用的开发工具及配置

EditPlus的简单配置,竟然秒杀vscode

05.标识符变量与数据类型
一:认识Java标识符
问:标识符是神马?
答:标识符就是用于给 Java 程序中变量、类、方法等命名的符号。
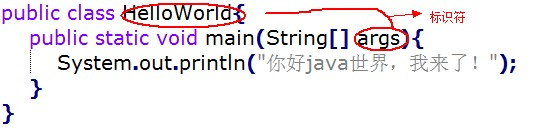
记住:使用标识符时,需要遵守几条规则:
-
标识符可以由字母、数字、下划线(_)、美元符($)组成,但不能包含 @、%、空格等其它特殊字符,不能以数字开头。譬如:123name 就是不合法滴
-
标识符不能是 Java 关键字和保留字( Java 预留的关键字,以后的升级版本中有可能作为关键字),但可以包含关键字和保留字。如:不可以使用 void 作为标识符,但是 Myvoid 可以
-
标识符是严格区分大小写的。 所以涅,一定要分清楚 love 和 LOVE 是两个不同的标识符哦!
-
标识符的命名最好能反映出其作用,做到见名知意。
二:变量是什么(看两个例子)
① 简单的说,我们可以把
变量看作是个盒子,根据盒子的不同用途,比如将钥匙放钥匙的盒子、手机放手机的盒子、饮料放饮料的盒子,我们会把盒子分为不同的类型,变量也是如此所以每个变量都有变量类型,一般情况下每种盒子只能放指定的东西,但有的时候我们也需要在手机盒子里放钥匙,所有盒子的用途是可以转换的,那么变量的类型也可以一定程度上转换!

在 Java 中,我们通过三个元素描述变量:变量类型、变量名以及变量值(就是放在盒子里的东西)。
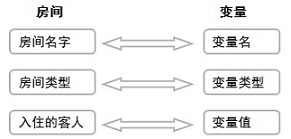
② 如果我们把变量比作是酒店的房间,要存储的数据就好比要住宿的客人,我们可以根据客人的要求安排其入住“标准间”或者是“总统套房”(变量的类型),并且可以根据房间名字(变量名)快速查找到入住客人(变量里的数据,变量值)的信息。同理,在 Java 程序中,我们也可以根据所需要保存的数据的格式,将其保存在指定类型的变量空间中,并且通过变量名快速定位!
例如,我们定义了一个变量 love ,用来保存一个字符串 “like java” , 在程序中只要找到了 love 这个变量,就能找到存储在里面的 ”like java”!当然,我们也可以把 love 里面的值更换成新的字符串 “i love java” !
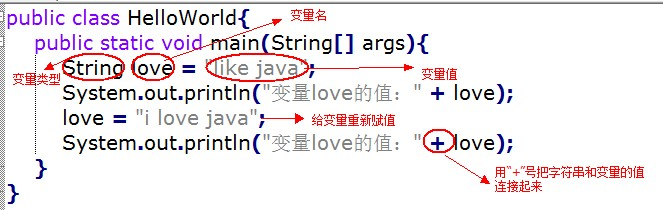
运行结果:
变量love的值:like java
变量love的值:i love java注意: Java 中的标点符号是英文的。譬如语句结束的分号,是英文符号的分号,千万不能写成中文!
变量的本质:其实是内存里的一部分空间,创建变量的时候,意味着向操作系统申请一部分内存的空间,声明不同类型的变量本质上就上说申请的内存空间大小不一样;(
扩展一下计算机程序的执行和硬件自己的关系)三:如何命名Java变量(变量名也是标识符的一种,所以它的命名规则和上面一模一样)
以下变量的命名都是符合规范的:

但请看下面的代码,你懂得哈:

优秀工程师的习惯:
1、变量名由多单词组成时,第一个单词的首字母小写,其后单词的首字母大写,俗称骆驼式命名法(也称驼峰命名法),如 myAge2、变量命名时,尽量简短且能清楚的表达变量的作用,做到见名知意。如:定义变量名 stuName 保存“学生姓名”信息
PS: Java 变量名的长度没有限制,但 Java 语言是区分大小写的,所以 price 和 Price 是两个完全不同的变量哦!四:Java中变量的使用规则
1、Java 中的变量需要先声明后使用
2、变量使用时,可以声明变量的同时进行初始化,也可以先声明后赋值
3、变量中每次只能赋一个值,但可以修改多次
4、main 方法中定义的变量必须先赋值,然后才能输出
5、虽然语法中没有提示错误,但在实际开发中,变量名不建议使用中文,容易产生安全隐患,譬如后期跨平台操作时出现乱码等等五:Java中的数据类型
通常情况下,为了方便物品的存储,我们会规定每个盒子可以存放的物品种类,就好比在“放臭袜子的盒子”里我们是不会放“面包”的!同理,变量的存储也讲究“分门别类”!
Java 语言是一种强类型语言。通俗点说就是,在 Java 中存储的数据都是有类型的,而且必须在编译时就确定其类型。 Java 中有两类数据类型:
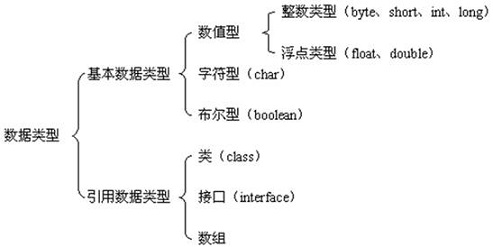
在 Java 的领域里,数据类型有基本数据类型和引用数据类型之分:基本数据类型变量存的是数据本身,而引用类型变量存的是保存数据的空间地址。说白了,基本数据类型变量里存储的是直接放在抽屉里的东西,而引用数据类型变量里存储的是这个抽屉的钥匙,钥匙和另外放东西的抽屉一一对应。
常用的基本数据类型有:

Java中的char为什么占两个字节?能表示所有的字符吗?:jvm中使用utf-16编码你可能已经注意到了:

注:关于 float 型和 double 型的区别,以及 char 型和 String 型的不同:
1.
①.float是单精度浮点数,内存分配4个字节,占32位,有效小数位6-7位
double是双精度浮点数,内存分配8个字节,占64位,有效小数位15位
②.java中默认声明的小数是double类型的,如double d=4.0
如果声明: float x = 4.0则会报错,需要如下写法:float x = 4.0f或者float x = (float)4.0
其中4.0f后面的f只是为了区别double,并不代表任何数字上的意义
③.对编程人员而言,double 和 float 的区别是double精度高,但double消耗内存是float的两倍,
且double的运算速度较float稍慢。
2.
①.char表示字符,定义时用单引号,只能存储一个字符,如char c=‘x’;
而String表示字符串,定义时用双引号,可以存储一个或多个字符,如String name=“tom”;
②.char是基本数据类型,而String 是一个类,具有面向对象的特征,可以调用方法,如name.length()获取字符串的长度。
String 是一种常见的引用数据类型,用来表示字符串。在程序开发中,很多操作都要使用字符串来完成,例如系统中的用户名、密码、电子邮箱等。练习:对每种类型的数据定义一次变量,然后赋值,然后在控制台中输入它的值
06. 进制与转换
为什么要使用进制数
数据在计算机中的表示,最终以二进制的形式存在 , 就是各种 <黑客帝国>电影中那些 0101010… 的数字 ;
我们操作计算机 , 实际 就是 使用 程序 和 软件 在 计算机上 各种读写数据,
如果我们直接操作二进制的话 , 面对这么长的数进行思考或操作,没有人会喜欢。
用16进制或8进制可以解决这个问题。
因为,进制越大,数的表达长度也就越短。
之所以 使用 16或8进制,而不其它的,诸如9或20进制 .
是因为2、8、16,分别是2的1次方、3次方、4次方。这一点使得三种进制之间可以非常直接地互相转换 ;
8进制或16进制 既 缩短了二进制数,还能 保持了二进制数的表达特点。转换还方便 。进制的介绍
- 10进制
先说 我们最 熟悉的 10进制 , 就是 用 0~9 的数表示 , 逢 10 进 1 . - 16进制
如果是 16 进制 , 它就是 由 0-9,A-F组成, 与10进制的对应关系是:0-9 对应 0-9;A-F对应10-15;
字母不区分大小写。 - 2进制 和 8进制
2进制 由 0-1组成,10
8进制 由 0-7组成 10

二进制与十进制之间的转换
十进制转二进制
方法为:十进制数除2取余法,即十进制数除2,余数为权位上的数,得到的商值继续除2,依此步骤继续向下运算直到商为0为止。
(具体用法如下图)
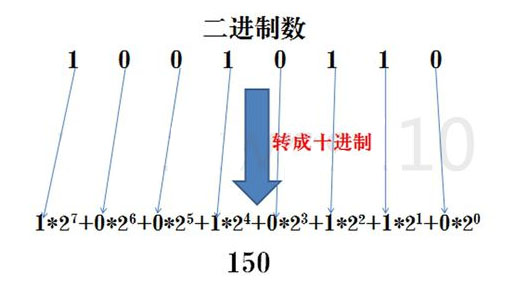
二进制转十进制
方法为:把二进制数按权展开、相加即得十进制数。
(具体用法如下图)
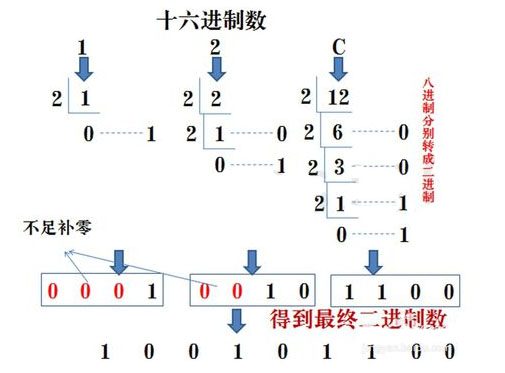
二进制与十六进制之间的转换
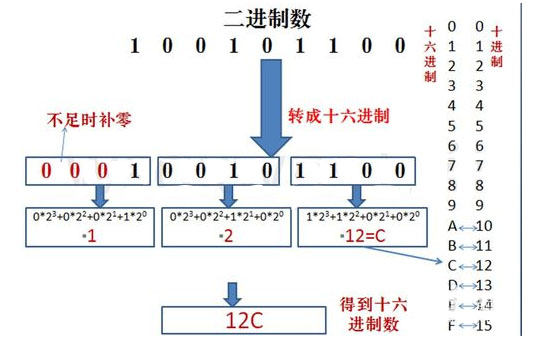
二进制转十六进制
方法为:十六进制是取四合一。注意事项,4位二进制转成十六进制是从右到左开始转换,不足时补0。
(具体用法如下图)
注意:java中的十六进制的数表示方法为:0x或0X的开头,比如0x12C67
十六进制转二进制
方法为:十六进制数通过除2取余法,得到二进制数,对每个十六进制为4个二进制,不足时在最左边补零。
(具体用法如下图)
补码:
一个正数的补码和它的原码的形式是相同的。
负数的补码形式:将该数值的绝对值的二进制形式,按位取反然后再加1。为什么使用补码的形式来将数据存放在计算机底层:
使用补码,就可以把减法运算转换为加法,也就是说在计算机底层本质上没有减法是硬件实现,都是加法, 降低硬件的设计难度,易于实现!分析一下为什么用补码:
假设字长为8bits 要完成,1-1 =0
( 1 ) - ( 1 )
= ( 1 ) + ( -1 )
= (00000001)+ (10000001) -----------------原码计算
= (10000010)= ( -2 )
( 1 ) - ( 2 )
= ( 1 ) + ( -2 )
= (00000001)+ (10000010) -----------------原码计算
= (10000011)= ( -3 )
显然结果不正确.
因为在两个正数的加法运算中是没有问题的,
于是就发现问题出现在带符号位的负数身上,
对除符号位外的其余各位逐位取反就产生了反码.反码的取值空间和原码相同且一一对应.下面是反码的减法运算:
(1)+(-1)
= (00000001)+ (11111110)----反码计算
= (11111111)
= ( 10000000 )
=(-0)有问题
按上面同样的方法计算1-2=-1
1+(-2)
= (00000001)+ (11111101)----反码计算
= (11111110)
= ( 10000001 ) = (-1)正确
问题出现在(+0)和(-0)上,在人们的计算概念中零是没有正负之分的.于是就引入了补码概念.负数的补码
负数的补码就是对反码加1,而正数不变,正数的原码反码补码是一样的.
下面是补码的运算:
( 1 )- ( 1 )= ( 1 )+ ( -1 )
=(00000001)补+ (11111111)补((11111110)+1)(反码加1)
= (00000000)补= ( 0 )正确
( 1 )- ( 2)= ( 1 )+ ( -2 )
= (00000001)补+ (11111110)补
= (11111111)补= ( -1 ) 正确
(-1) = (10000001)原码=(11111110 )反码 =((11111110 )+ 1)补码设计目的
所以补码的设计目的是:
⑴使符号位能与有效值部分一起参加运算,从而简化运算规则.
⑵使减法运算转换为加法运算,进一步简化计算机中运算器的线路设计,所有这些转换都是在计算机的最底层进行的,而在我们使用的汇编、C、java等其他高级语言中使用的都是原码。练习题:
1、十进制算术表达式:3512+764+4*8+5的运算结果,用二进制表示为( ).
A. 10111100101 B.11111100101 C. 11110100101 D.11111101101 111111001012、与二进制数101.01011等值的十六进制数为( )
A)A.B B)5.51 C)A.51 D)5.583、十进制数2004等值于八进制数( )。
A. 3077 B. 3724 C. 2766 D. 4002 E. 37554、(2004)10 + (32)16的结果是( )。
A. (2036)10 B16 C. (4006)10 D. (100000000110)2 E. (2036)165、十进制数2006等值于十六制数为( )
A、7D6 B、6D7 C、3726 D、6273 E、71366、十进制数2003等值于二进制数( )。
A)11111010011 B)10000011 C)110000111 D)010000011l E)11110100117、运算式(2008)10-(3723)8的结果是( )。
A、 (-1715)10 B、(5)10 C、 (-5)16 D、 (111)2 E、 (3263)807. 基本数据类型

在Java程序中,不同的基本类型的值经常需要进行相互转换。
Java语言所提供的7种数值类型之间可以相互转换,有两种类型转换方式:自动类型转换和强制类型转换。自动类型转换
Java所有的数值型变量可以相互转换,如果系统支持把某种基本类型的值直接赋给另一种基本类型的变量,则这种方式被称为自动类型转换。
当把一个表数范围小的数值或变量直接赋给另一个表数范围大的变量时,系统将可以进行自动类型转换,否则就需要强制转换。
就如同有两瓶水,当把小瓶里的水倒入大瓶中时不会有任何问题。
Java支持自动类型转换的类型如下所示,左边的数值类型可以自动类型转换成箭头右边的数值类型。
1),byte->short->int->long->float->double
2),char->int->long->float->double
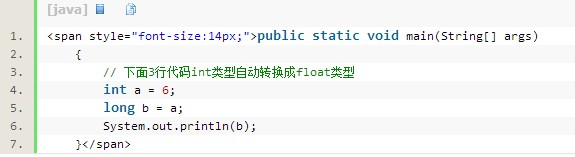
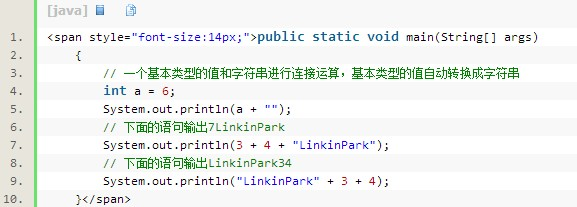
在实际应用中除开基本数据类型之间的转换,还有一个引用类型String(字符串类型),它和基本数据类型之间也是需要经常的相互转换:
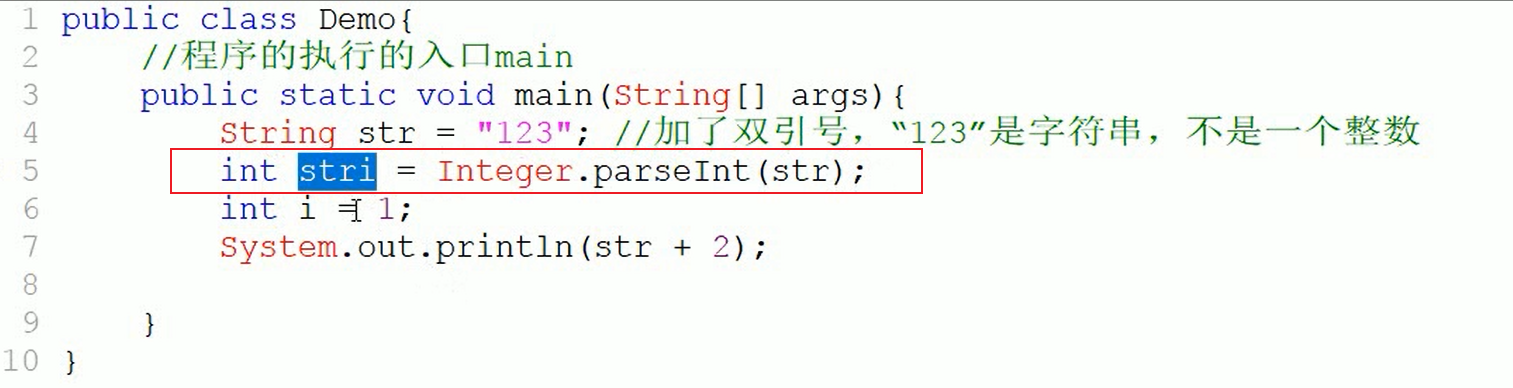
强制类型转换
如果希望上面自动转换中,箭头右边的类型转换成左边的类型,则必须进行强制类型转换。
强制类型转换的语法格式:(targetType)value,强制类型转换的运算符是圆括号()。
当进行强制类型转换时,类似于把一个大瓶子里面的水倒入一个小瓶子,如果大瓶子里面的水不多还好,如果大瓶子里面的水很多,将会引起溢出,从而造成数据丢失。
这种类型也称为缩小转换。
注意:当试图强制把表数范围大的类型转换为表示范围小的类型时,必须格外小心,因为非常容易引起信息丢失。

表达式类型的自动提升
当一个算数表达式包含多个基本类型的值时,整个算术表达式的数据类型将发生自动提升。
Java定义了如下的自动提升规则:
1),所有的byte类型,short类型和char类型将被提升到int类型。
2),整个算术表达式的数据类型自动提升到表达式中最高等级操作数同样的类型。

08.关键字与转义字符
java中的关键字
java中的关键字又称作保留字,是指Java语言中自带的用于标示数据类型名或者程序构造名的标示符。
java中关键字很多,不需要强制记忆,因为在编译程序是如果你用了关键字做标识符编译器会提醒你出错。
java中的关键字列举如下:abstract ; boolean ; break ; byte ; case ; catch ; char ; class ; continue ; default ; do ; double ; else ; extend ; false ; final ; finally ; float ; for ; if ; implement ; import ; instanceof ; int ; interface ; long ; native ; new ; null ; package ; private ; protected ; public ; return ; short ; static ; synchronized ; super ; this ; throw ; throws ; transient ; true ; try ; void ; volatile ; while ;
注意一点:我们自己中程序中取的名字,不管是类名,文件们,变量名,还是其他,不能和关键字一模一样(拼写,大小写一样)
转义字符:用来表示特殊的符号或特殊意义
\b:表示后退一个字符
\t:表示一个制表位
\n:表示换到下一行
\r: 回车
\":表示双引号
\':表示单引号
\\:表示反斜杠字符\09.算术赋值比较运算符
一、算术运算符
算术运算符主要用于进行基本的算术运算,如加法、减法、乘法、除法等。
Java 中常用的算术运算符: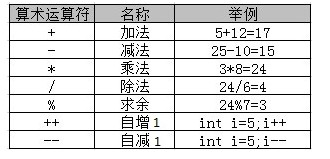
其中,++ 和 – 既可以出现在操作数的左边,也可以出现在右边,但结果是不同滴例:


一定要注意哦!自增和自减运算符只能用于操作变量,不能直接用于操作数值或常量!例如 5++ 、 8-- 等写法都是错误滴!
二、赋值运算符
赋值运算符是指为变量或常量指定数值的符号。如可以使用 “=” 将右边的表达式结果赋给左边的操作数。
Java 支持的常用赋值运算符,如下表所示:
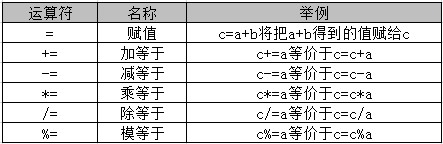
举例:
三、比较运算符
比较运算符用于判断两个数据的大小,例如:大于、等于、不等于。比较的结果是一个布尔值( true 或 false )。
Java 中常用的比较运算符如下表所示:
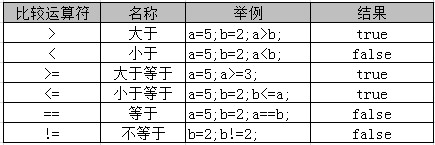
注意哦:
1、 > 、 < 、 >= 、 <= 只支持左右两边操作数是数值类型
2、 == 、 != 两边的操作数既可以是数值类型,也可以是引用类型
知识扩展: java中equals和==的区别
1、值类型是存储在内存中的堆栈(简称栈),而引用类型的变量在栈中仅仅是存储引用类型变量的地址,而其本身则存储在堆中。
2、==操作比较的是两个变量的值是否相等,对于引用型变量表示的是两个变量在堆中存储的地址是否相同,即
栈中的内容是否相同。3、
equals操作表示的两个变量是否是对同一个对象的引用,即堆中的内容是否相同。4、==比较的是2个对象的地址,而equals比较的是2个对象的内容,显然,当equals为true时,==不一定为true。
10.逻辑运算符与示例
逻辑运算符
逻辑运算符主要用于进行逻辑运算。Java 中常用的逻辑运算符如下表所示:

注意短路运算符,它可以节约运算资源.我们可以从“投票选举”的角度理解逻辑运算符:
1、 与:要求所有人都投票同意,才能通过某议题
2、 或:只要求一个人投票同意就可以通过某议题
3、 非:某人原本投票同意,通过非运算符,可以使其投票无效
4、 异或:有且只能有一个人投票同意,才可以通过某议题
当使用逻辑运算符时,我们会遇到一种很有趣的
“短路”现象。譬如:( one > two ) && ( one < three ) 中,如果能确定左边 one > two 运行结果为 false , 则系统就认为已经没有必要执行右侧的 one < three 啦。
同理,在( one > two ) || ( one < three ) 中,如果能确定左边表达式的运行结果为 true , 则系统也同样会认为已经没有必要再进行右侧的 one < three 的执行啦!
11.位运算符与变量交换
我们知道,位运算在计算中有着广泛的应用。在计算机的各种编程语言中位运算也是一种必不可少的运算,尤其是在计算机的底层实现代码中。
下面我们就来介绍一下位运算。
1.左移运算<< 左移右移都是移动二进制数
0000-0000 0000-0000 0000-0000 0000-1100 =12 向左移动一位变为(右边缺几位就补几个0)
0000-0000 0000-0000 0000-0000 0001 1000 =24 再向左移一位
0000-0000 0000-0000 0000-0000 0011 0000 =48
由此,我们可以得到,其实m向左移n位后,m=m*2^n;即每向左移一位,该数就会增到一倍。2.右移运算>> 右移运算和左移运算类似,但是也有一个区别。
0000-0000 0000-0000 0000-0000 0000-1100 =12 向右移一位
0000-0000 0000-0000 0000-0000 0000-0110 =6再向右移一位
0000-0000 0000-0000 0000-0000 0000-0011 =3再向右移动一位
0000-0000 0000-0000 0000-0000 0000-0001 =1我们也可以得到一个规律,每向右移动一位,该数就会减小一倍(按计算机的整数规律减小)
>>向右移动的过程中,左边是补0还是1,是根据原来的数的最高位来确定的,原来数的最高位是1,则补1,否则补0
无符号右移运算>>>向右移动的过程中,不管原来数的最高位是1还是0,都补0,所以我们应该根据需要来选择,右移是用>>>还是>>.3.&与运算
与运算同样都是对二进制位来说的。比如10&7=2(省略了前面的二进制位)
1010
&0111
----------------
00104.|或运算 与与运算类似(略)
5.~运算也都差不多
6.
^异或运算,我们主要看一下异或运算 12^7=111100
^0111
--------------------------
1011异或运算就是两个数不相同则为1,相同则为0。
7.我们讲一下在计算机中是怎样将二进制转化为16进制的
0000-0000 0000-0000 0000-0000 0010-1011
我们都知道,只要将每四位一取,然后对每一项算出它的16进制,然后再合起来就是2进制的16进制的表现形式
上面的数据十六进制形式应该是 2 11(B) = 2B
那计算机是怎样算的呢?这儿就是用&运算来完成的,和那个数$运算呢? 我十六进制数的最大元数 15(F)
首先,将上数进行下面的与运算
0000-0000 0000-0000 0000-0000 0010-1011
&0000-0000 0000-0000 0000-0000 0000-1111
-------------------------------------------------------------
0000-0000 0000-0000 0000-0000 0000-1011这样,我们就把上面的数据的最后四位二进制位取出来了,然后进行计算就得到16进制的值
如果我们要把倒数的第二个四位二进制位取出来,那又该怎么取呢?
我们只需要把该书向右移四位,然后再取就ok了。非常简单吧,这也是位运算在计算机中的应用之一。
8.接下来我们讲一下,用位运算怎么交换两个数
最普通的方法:int temp=a,a=b,b=temp,最简单最常用的,不多说。
稍微高级一点的:
a=a+b
b=a-b
a=a-b再高级一点的位运算:
a=a^b
b=a^b
a=a^b
这是为什么?因为异或运算有一个特点,如下10^8=2
1010
^1000
----------
0010
但是10^8^8=??? =10
0010
^1000
--------
1010
也就是说,n^m^m=n,神奇吧,慢慢领会就会了。12.三目运算符与优先级
条件运算符
条件运算符(
? :)也称为 “三元运算符”。
语法形式:布尔表达式 ? 表达式1 :表达式2
运算过程:
如果布尔表达式的值为 true ,则返回 表达式1 的值,否则返回 表达式2 的值String mark =(score>=60)?“及格”:“不及格”;
System.out.println(“考试成绩如何:”+mark);在说一下优先级的问题:
在一个表达式中可能包含多个有不同运算符连接起来的、具有不同数据类型的数据对象;由于表达式有多种运算,不同的运算顺序可能得出不同结果甚至出现错误运算错误,因为当表达式中含多种运算时,必须按一定顺序进行结合,才能保证运算的合理性和结果的正确性、唯一性。基本的优先级需要记住:
单目乘除为关系,逻辑三目后赋值。
单目:单目运算符+ –(负数) ++ – 等
乘除:算数单目运算符* / % + -
为:位移单目运算符<< >>
关系:关系单目运算符> < >= <= == !=
逻辑:逻辑单目运算符&& || & | ^
三目:三目单目运算符A > B ? X : Y
后:无意义,仅仅为了凑字数
赋值:赋值=在实际应用中,很多时候,不确定运算顺序的时候,用小括号,改变运算顺序,和数学中的一样,就不多说了
13.If分支语句
JAVA 的分支语句 if-else 和 switch 。
分支语句的作用是可以让程序根据不同的情况、不同条件进行不同操作,
从而让程序更灵活。if语句使用布尔表达式或布尔值作为分支条件来进行分支控制,
其中if语句有如下三种形式:第一种形式:
if ( logic expression ){
statements…
}
第二种形式:
if (logic expression){
statements…
}else{
statements…
}
第三种形式:
if (logic expression){
statements…
}else if(logic expression){ …//可以有零个或多个else if语句
statements…
}else{ //最后的else语句也可以省略
statement
}在上面if语句的三种形式中,放在if之后的括号里的只能是一个逻辑表达式,
即这个表达式的返回值只能是true或false.第二种情形和第三种情形是相通的,如果第三种形式中else if代码块不出现,
则变成了第二种形式。上面的条件语句中,if(logic expression)、else if(logic expression)
以及else后花括号括起来多行代码被称为代码块,一个代码块通常被当成一个整体来执行(除非运行过程中遇到return、break、continue等关键字,或者遇到了异常),因此这个代码块也被称为条件执行体。
int age = 30;
if (age > 20){
//只有当age > 20时,下面花括号括起来的语句块才会执行
//花括号括起来的语句是一个整体,要么一起执行,要么一起不会执行
System.out.println(“年龄已经大于20岁了”);
System.out.println(“20岁以上的人应该学会承担责任…”);
}因此,如果if(logic expression)、else if(logic expression)
和else后的语句块只有一行语句时,则可以省略花括号,
因为单行语句本身就是一个整体,无须花括号来把它们定义成一个整体。通常,我们建议不要省略if、else、else if后执行块的花括号,
即使条件执行体只有一行代码,因为保留花括号会有更好的可读性,
而且保留花括号会减少发生错误的可能最后我们用一个判断分数的案例, 类结束if的讲解!
14. Switch分支语句
switch语句 , java的另一种分支结构语句:
switch (支持的判断类型变量) { case "值1": 语句1; break; case "值2": 语句2; break; .... default: 语句; break; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
①能用于switch判断的类型有:byte、short、int、char(JDK1.6),还有枚举类型,但是在JDK1.7后添加了对String类型的判断,switch的判断类型支持:整数,字符,字符串
②case语句中少写了break,编译不会报错,但是会一直执行之后所有case条件下的语句而不再判断,直到default语句
③若果没有符合条件的case就执行default下的代码块,default并不是必须的,也可以不写
④每一个case语句后的值, 具有排他性, 在switch代码块中, 必须是唯一, 不能喝其他case语句后的值相同!写一个Demo看验证一下:
public class SwitchDemo { public static void main(String[] args) { stringTest(); breakTest(); defautTest(); } /* * switch用于判断String类型 * 输出:It's OK! */ private static void stringTest() { String string = new String("hello"); switch (string) { case "hello": System.out.println("It's OK!"); break; default: System.out.println("ERROR!"); break; } } /* * case语句中少写了break,编译不会报错 * 但是会一直执行之后所有case条件下的语句,并不再进行判断,直到default语句 * 下面的代码输出: case two * case three */ private static void breakTest() { char ch = 'A'; switch (ch) { case 'B': System.out.println("case one"); case 'A': System.out.println("case two"); case 'C': System.out.println("case three"); default: break; } } /* * default不是必须的,也可以不写 * 输出:case two */ private static void defautTest() { char ch = 'A'; switch (ch) { case 'B': System.out.println("case one"); break; case 'A': System.out.println("case two"); break; case 'C': System.out.println("case three"); break; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
15. While与 dowhilef循环
那么在讲解循环之前呢我们先来了解一下什么是循环
生活中的例子
车子的轮胎他就是一直在循环
马拉松跑到也是在循环,因为运动员不停的一圈一圈在跑这也是一个循环那么我们为什么要学习循环呢?
下面看一个小问题 张三为了表明自己要勤奋学习Java的决心,他决定在程序中写一百遍“好好学习,天天向上!”打印出来,一般的做法…
System.out.print(“好好学习天天向上”);要写好久而且非常麻烦;如如果我们写一万遍怎么办?
那么有没有更简单的方法实现这个复杂的问题呢,今天学习的循环就可以很轻松的解决这个问题:
while循环:
while(循环条件){
循环操作
}注意:但是使用这个循环一定要注意,如果条件永远成立的话那就就会死循环,如果出现这个情况就需要终止程序
死循环这个问题,基本上所有刚接触这个知识点的人都遇到过这个问题,我们上面的案例控制循环条件的是 i 因为,每执行一循环 i的值就会加1等到i的值大于100的时候,那么循环结构不成立,所以就不会再次执行循环操作
while循环的特点是先判断 在执行 如果判断结构返回的是错误 那么不会执行
do…while循环:
有这样的一个场景:让张三先上机编写完成程序,然后老师检查是否合格。如果不合格,则继续编写,直到合格为止。
如果使用 while循环,那么也只能先判断,合不合格,没办法让张三先做一遍,所以这里只能使用do…while结构的循环:
do{
循环操作
}while(循环条件);do while循环是不管条件成不成立都先执行一次
总结一下两者区别:
①语法不同
②执行次序不同,一个是先判断在执行,另一个是先执行后在判断要不要继续
③初始条件不满足执行条件的时候,while是一次都不会执行, do…while是至少会执行一次的.16.for循环
Java里的for循环里有两种,普通
for循环和for each循环,后者是java后来加上去的,原本是没有的。今天先看普通for循环的格式是这样的:
for(初始化条件(一般为数据的初始化); 判断条件(一般与前面初始化的数据有关); 条件改变(一般改变那个数据)){ 执行的操作 }- 1
- 2
- 3
如果执行的操作只有一条语句,花括号可以省略掉,但是建议初学者不要这么做,容易把自己弄糊涂。
那么,上面这个for循环是怎么执行的呢? 我们来写个小程序,来说明一下这个问题:
for(int i = 0; i < 10; i ++){ System.out.println("Hello Baby!"); }- 1
- 2
- 3
i是一个整型数据,在for循环的最最开始,它被定义并初始化为0,然后判断它是否小于10,如果小于10,那么执行
这个例子也许没什么实际的意义,那么我们这里来看看有点儿实际意义的。 著名的数学家高斯,在10岁那年,用较短的时间,轻松的算出了1+2+3+…+100 = 5050, 使得他的老师彪特奈尔异常激动,意识到自己发现了一个天才。我们现在知道,当年高斯的算法是第一个数加上最后一个数是101,第二个数加上倒数第二个也是101,一共有50对这样的加法,最后得到5050,那么如果我们用java的for循环来做呢? 我们在此用两种方法,一种是1+2+…+100,另一种就是模拟高斯的做法,程序代码如下:

以上便是普通的for循环,一般来说,for循环经常控制某些操作的执行次数,所以,多数情况下,会对整形数据进行初始化和自加操作。但这不是绝对的,for循环可以很灵活的,比如下面的例子:
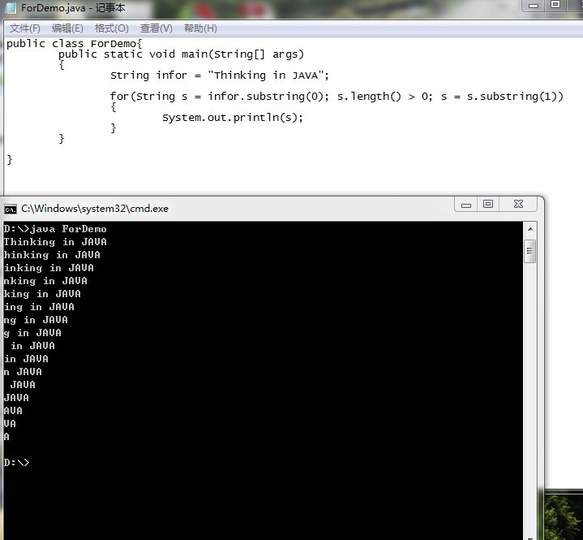
这个例子打印出Thinking in JAVA,但是每次都少打一个字母,这有些像"我顿时凌乱了, 顿时凌乱了,时凌乱了,凌乱了,乱了,了”, 对吧,这个小程序用到了String的基本操作,我们还没有涉及到。不过这没关系,我只是说,普通for循环的格式是死板的,但是使用for循环的人是灵活的。
17.多重循环示例与小结
多重循环定义,如果循环语句的循环体中又出现循环语句,就构成多重循环结构。一般常用的有二重循环和三重循环。
/** * 多重循环的经典案例 * * */ public class MultipleCycleDemo { public static void main(String[] args) { RightTriangle();//打印直角三角形 Triangle();//打印等腰三角形 Factorial();//求阶乘和 Multiplication();//打印九九乘法表 } // 使用多重循环打印直角三角形 public static void RightTriangle() { // 外层控制行数 for (int i = 0; i < 5; i++) { // 控制每行的空格数 for (int j = i; j < 4; j++) { System.out.print(" "); } // 控制每行的*的个数 for (int j = 0; j <= i; j++) { System.out.print("*"); } System.out.println();// 输出换行 } } //用多重循环语句:打印等腰三角形 public static void Triangle(){ //控制行数 for(int i = 0;i<5;i++){ //控制每行的空格数 for(int j=i;j<4;j++){ System.out.print(" "); } // 控制每行的*的个数 for(int j = 0;j<=i*2;j++){ System.out.print("*"); } System.out.println(); } } // 用多重循环语句:阶乘求和1!+2!+……+10! public static void Factorial() { int sum = 0; // 定义一个变量接收结果 // 控制十个数的阶乘 for (int i = 1; i <= 10; i++) { // 外层循环控制循环次数 int s = 1; // 定义一个变量来接收每个数的阶乘 for (int j = 1; j <= i; j++) { // 内层循环实现每个数字的阶乘 s *= j; } System.out.println(i + "的阶乘是 " + s); sum += s; } System.out.println("10的阶乘和是: " + sum); } // 用多重循环语句:打印九九乘法表 public static void Multiplication() { int result; // 控制行数 for (int i = 1; i <= 9; i++) { //控制列数 for (int j = 1; j <= i; j++) { result = i * j; System.out.print(j + "X" + i + "=" + result + "\t"); } System.out.println(); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
18.循环语句中的break,continue,return
Java提供了continue和break来控制循环结构,除此之外,return可以结束整个方法,也可以间接的实现结束循环。
一.使用break结束循环
1.作用:在某种条件出现时强行终止循环,用于完全结束一个循环,跳出循环体。
for(int i=0;i<10;i++){ if(i==2){ //不会再执行i=3.... 直接跳出循环 break; } System.out.println("hello!, i=" + i); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.break不仅可以结束所在的循环,还可以直接结束其外层循环,需要在break后面紧跟一个标签,这个标签用于表示一个外层循环,标签是一个后面紧跟着 :标识符。标签只有放在循环语句之前才有用!
outer: for(int i=0;i<5;i++){ System.out.println("i:"+i); for(int j=0;j<3;j++){ if(j==1){ //跳出outer标签所标识的循环 break outer; } System.out.println("--------j:"+j); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
二.使用continue忽略本次循环剩下语句
1.作用:忽略本单次循环的后面的语句,不会结束整个循环
for(int i=0;i<10;i++){ if(i==2){ //i等于2时,不会执行下方的语句,但是会继续i=3循环 continue; } System.out.println("hello!, i=" + i); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
三.使用return结束方法
1.return并不是专门用于循环结构控制的关键字,而是用来结束一个方法,当一个方法执行到return语句时,这个方法将被结束,方法内部的循环自然也随之结束。与break,continue不同的是,return不管处于多少层循环之内直接结束整个方法。
19.方法的定义与参数
* 1:什么叫方法?
- 方法其实就是一个{},给该{}起名字,好通过名字去反复执行{}中的内容
—>方法的本质:可反复调用的独立的代码块,代码块就是一{}
* 2:如何定义呢? (暂时把static关键字带上:面向对象的时候讲)
- main()方法为例,来总结一下定义方法的语法结构:
- public static void main(String[] args){ }对应方法的定义的格式,即语法结构:
- 权限修饰符 静态修饰符 返回值类型 方法名(形式参数:(数据类型 变量名)){
如果返回值类型不是void:必须有 return 返回具体的结果;
void关键字:表示没有返回值; }
进一步总结方法的通用格式:[修饰符1 修饰符2 …] ,返回值类型 方法名 (形式参数列表) { Java语句;…}
- 详细解释:
- 权限修饰符:public:公共的,公开的 (面向对象在详细的讲)
- 静态修饰符:static(面向对象在详细的讲)
- 返回值类型:暂时使用基本数据类型(int类型,float…) 以后还可以引用类型(面向对象部分)
- 方法名:注意起名的规则, 标识符的规则一样, 最好做到见名知意, 超级超级建议不用拼音和中文
- 形式参数写法 : 数据类型(基本数据类型) 变量名
- return:带回一个结果
- 比如例子:求两个数据之和
方法调用: 方法名(), 这是没有参数的, 方法名(实参) , 这是有参数的.
*有具体返回值类型的方法调用:- 1)单独调用:没有任何意义,只是调用了,没有具体的结果出现!没有输出语句
- 2)输出调用:没有错,但是不能针对具体结果进行下一步操作!
- 3)赋值调用:推荐使用赋值调用
通过上面的例子,具体说明一下参数传递的过程!
*写方法的注意事项:
*两个明确:
- 1)明确返回值类型 :int类型
- 2)明确参数个数以及参数类型:int类型,2个参数
20.方法的重载

21.数组的定义与赋值方法
一、首先理解一下Java数组是什么? 它是一种数据的容器。对这种数据容器,首先我们应该掌握一些基础的知识点:
① 种容器是有一个限制规定: 在一个数组中保存的所有元素的数据类型都必须是同种类型的! 比如一个整数类型的数组【11,34,21,55】
② 数组都有一个共同的属性:数组长度,在java程序中用length这个关键字来获取数组的长度值。
③ 数组中可以有很多个元素,这些元素是有排序位置的:
这个位置序号,我们叫索引,而且这个索引是从0开始的,最后一个是arr.length-1。已上面的数值为例,有四个元素,所有长度为4:
元素11的索引就是:0
元素34的索引就是:1
元素21的索引就是:2
元素55的索引就是:3 = 长度 - 1二、数组的定义及赋值方式:
① 第一种定义方式, 定义的同时给赋了初始值, 也是第一种赋值方式:
int[] arr = {1,2,3,4,5,6,7,8,9,10}; 其实这是一种连写,本质是是两个步骤:
第一步: int[] arr; //定义或叫声明一个 整数类型的数组变量 arr
第二步:arr = {1,2,3,4,5,6,7,8,9,10}; // 给整数类型的数组变量 arr 赋值, 注意可以这样理解,但是没这种赋值的语法② 第二种定义方式, 和第一种本质一样,只是写法不一样:
int[] arr = new int[]{20,30,40}; // 可以理解第一种写法是这种写法的简化,省略new int[]关键字
③ 第三种定义方式, 定义就只是定义, 没给赋初始值:
int[] arr = new int[3]; // 定义数组变量的时候没赋值,必须要指定数组的长度
定义好数组变量后, 可以这样给单个单个数组元素赋值, 这是第三种赋值方式:
arr[0] = 11;
arr[1] = 12;
arr[2] = 13;给数组元素赋值,除了可以直接用字面量常数外,也是可以赋值另一个变量的。
int a = 10;
int b = 20 ;
// 这样是可以的,因为a和b都是int类型——
arr[0] = a;
arr[1] = b;22.数组取值、数组遍历和相关内存分析
取出数组中的数据、数组遍历和定义数组的过程中内存的变化:
一、取值: 取出数组元素的值是通过数组的变量名+索引值的方式取出,语法: 变量名[索引值]
二、数组的遍历:
1、for循环
for(int i = 0 ; i < arr.length; i++){ System.out.println(arr[i]); }- 1
- 2
- 3
2、foreach循环
for(int i:arr){ System.out.println(i); }- 1
- 2
- 3
三、Arrays工具类
// 因为Arrays工具类已经封装了对数组的元素的打印——
System.out.println(Arrays.toString(arr));四、内存分析:
因为Java数组的类型是引用类型数据,因此定义它要使用Java的关字:new,当然对于数组有简写的方式省略了new关键字
为什么可以简化呢? 因为 JVM 它先识别 int[] 是一个数组 , 然后自动的调用执行new关键字的操作,所以简写的本质上仍然使用了new关键字,下面重点分析数组变量在定义的时候内存中是怎么对应着保存数据的:
int[] arr = new int[3]
arr[0] = 11
arr[1] = 12
arr[2] = 13数组的定义中当执行到new关键字的时候, JVM它调用了数值元素类型对应的构造器的方法来实例化,这个实例化的内部其实是做三件事:
①、开辟内存空间,根据数组的类型,和数组元素的个数想操作系统申请对应的内存空间
②、调用构造器并初始化,堆内存的大小
③、将生成的地址返回,将堆内存中分配得到的地址保存到栈内存对应分配得到的单元空间里

注意上面的赋值方式,必须在定义数据变量的时候才能使用!切记!

如果,将地址返X回,那么这个值就是一个十六进制数据!我们可以输出一下看看!
首先理解一下Java数组是什么? 它是一种数据的容器。
但这种容器是有规定,不同数据类型的容器,会存储不同的数据。也就是说在一个数组中, 它里面保存的所有元素的数据类型都必须是同种类型的!注意:数组的元素是怎么确定位置的呢? 是通过索引,而且这个索引是从0开始的,最后一个是arr.lenght-1。
比如一个整数类型的数组,int[] arr = {11,34,21,55};
元素11的索引就是:0
元素34的索引就是:1
…数组的定义及赋值方式:
①、第一种方式:int[] arr = {1,2,3,4,5,6,7,8,9,10};
②、第二种方式:int[] arr = new int[]{20,30,40};
③、第三种方式:int[] arr = new int[3];
arr[0] = 11;
arr[1] = 12;
arr[2] = 13;
这是Java的一维数组,可以保存单个与之对应的变量。
int a = 10;
int b = 20 ;
// 这样是可以的,因为a和b都是int类型——
int arr = {a,b};
其实第四种赋值方式,可以变为数组拷贝就可以完成赋值功能!!!
数组的遍历分两种:
一、for循环或foreach循环
for(int i = 0 ; i < arr.length; i++){
System.out.println(arr[i]);
}
for(int i:arr){
System.out.println(i);
}二、Arrays工具类
// 因为Arrays工具类已经封装了对数组的元素的打印——
System.out.println(Arrays.toString(arr));内存分析:
因为Java数组是一个引用类型数据类型,因此它需要使用到Java的关键字:new
但为什么它还可以定义:int[] arr = {};
// 这种方式,因为它已经隐式地帮我们调用了构造器,JVM是这样的,它是方法的多态性的,也就是说它先识别int[]是一个数组,根据JVM编译规则的语法推断,赋值的过程必须是要求对象来处理,所以它调用了它的构造器来实例化,这样做就是构造器的创建会做三件事:
①、开辟内存空间
②、调用构造器并初始化
③、将生成的地址返回【这就是类的实例化过程】——
栈内存 堆内存
arr = {1,2,3,4};如果,将地址返回,那么这个值就是一个hashCode和十六进制数据!
23.打印字母三角形
public class Demo{ //程序入口 public static void main(String[] args){ //定义字符型的数组 char[] arr = {'A','B','C','D','E'}; for(int i=0;i<arr.length;i++){ //控制三角形的层数 for(int j=i;j<arr.length;j++){ //打印空格 System.out.print(" "); } for(int k=0;k<=i*2;k++){ System.out.print(arr[i]); } System.out.println(); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
24.二维数组
二维数组
数组的数组—二维数组的本质也是一维数组,只不过是这个一维数组里的每一个元素是又是一个一维数组
第一种定义格式
数据类型[][] 数组名 = new 数据类型[包含的一维数组的个数][每个一维数组的长度];
int[][] arr = new int[3][5];
—定义了一个整型的二维数组,其中包含3个一维数组,每个一维数组可以存储5个整数赋值和取值:
arr[0]—下标为0的位置上的一维数组
arr[1][3]—如果要获取具体的元素需要两个下标注意知识点:定义一个一维数组,没有赋初始值的定义方式,必须指定这个数组的长度,但是到了二维数组,里边的元素数组的长度我们在定义的时候可以不明确指定是可以的:
int[][] arr = new int[3][]; ----表示一个包含了三个整型的一维数组的二维数组,里边的充当元素的数值长度是可变的

第二种定义格式:当然也可以在定义二维数组的同时赋予初始值:
数据类型[][] 数组名 = {{元素},{元素1, 元素2},……};
int[][] arr = {{2,5},{1},{3,2,4},{1,7,5,9}};二维数组的遍历
二维数组的长度:数组名.length —每个一维数组:数组名[下标].length
二维数组的遍历—两重for循环for(int i = 0; i < arr.length; i++){ //遍历二维数组,遍历出来的每一个元素是一个一维数组 for(int j = 0; j < arr[i].length; j++){ //遍历对应位置上的一维数组 System.out.println(arr[i][j]); } }- 1
- 2
- 3
- 4
- 5
25.最大最小值算法

26.冒泡排序
在开发中,对一组数据进行有序地排列是经常需要做的事情,所以掌握几种甚至更多的排序算法是绝对有必要的:
问题:设有一数组,其大小为10个元素(int arr[10])数组内的数据是无序。现在要求我们通过编程将这个无序的数组变成一个从小到大排序的数组(从下标为0开始)
冒泡排序
冒泡排序是比较相邻两数的大小来完成排序的。
以升序排序为例,每趟排序完成之后,比较边界中的最大值就沉入底部,比较边界就向前移动一个位置。所以,第二趟排序开始时,比较边界是[0,n-2]。对于长度为n的序列,最多需要n趟完成排序,所以冒泡排序就由两层循环构成,最外层循环用于控制排序的趟数,最内层循环用于比较相邻数字的大小并在本趟排序完成时更新比较边界。
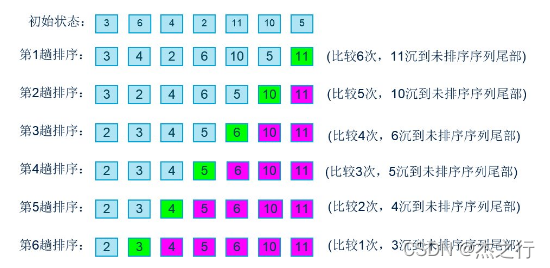
具体代码如下:
public static void bubbleSort(int[] arr){ int temp=0,len=arr.length; int compareRange=len-1;//冒泡排序中,参与比较的数字的边界。 //冒泡排序主要是比较相邻两个数字的大小,以升序排列为例,如果前侧数字大于后侧数字,就进行交换,一直到比较边界。 for (int i = 0; i <len ; i++) {//n个数使用冒泡排序,最多需要n趟完成排序。最外层循环用于控制排序趟数 for (int j = 1; j <=compareRange ; j++) { if(arr[j-1]>arr[j]){ temp=arr[j-1]; arr[j-1]=arr[j]; arr[j]=temp; } } compareRange--;//每进行一趟排序,序列中最大数字就沉到底部,比较边界就向前移动一个位置。 } System.out.println("排序后数组"+Arrays.toString(arr)); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
在排序后期可能数组已经有序了而算法却还在一趟趟的比较数组元素大小,可以引入一个标记,如果在一趟排序中,数组元素没有发生过交换说明数组已经有序,跳出循环即可。优化后的代码如下:
public static void bubbleSort2(int[] arr){ int temp=0,len=arr.length; int compareRange=len-1;//冒泡排序中,参与比较的数字的边界。 boolean flag=true;//标记排序时候已经提前完成 int compareCounter=0; //冒泡排序主要是比较相邻两个数字的大小,以升序排列为例,如果前侧数字大于后侧数字,就进行交换,一直到比较边界。 while(flag) { flag=false; for (int j = 1; j <=compareRange ; j++) { if(arr[j-1]>arr[j]){ temp=arr[j-1]; arr[j-1]=arr[j]; arr[j]=temp; flag=true; } } compareCounter++; compareRange--;//每进行一趟排序,序列中最大数字就沉到底部,比较边界就向前移动一个位置。 } System.out.println("优化后排序次数:"+(compareCounter-1)); System.out.println("排序后数组"+Arrays.toString(arr)); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
还可以利用这种标记的方法还可以检测数组是否有序,遍历一个数组比较其大小,对于满足要求的元素进行交换,如果不会发生交换则数组就是有序的,否则是无序的。
两种方法的排序结果如下所示:

27.选择排序算法
算法描述:对于给定的一组记录,经过第一轮比较后得到最小的记录,然后将该记录与第一个记录的位置进行交换;
接着对不包括第一个记录以外的其他记录进行第二轮比较,得到最小的记录并与第二个记录进行位置交换;重复该过程,直到进行比较的记录只有一个时为止。
下面实现从小到大的排序:public class SelectionSort { public static void selectionSort(int[] a) { int n = a.length; for (int i = 0; i < n; i++) { int k = i; // 找出最小值的下标 for (int j = i + 1; j < n; j++) { k = a[k] < a[j] ? k : j; } // 将真正最小值和假设的最小值交换 if (k > i) { int tmp = a[i]; a[i] = a[k]; a[k] = tmp; } } } public static void main(String[] args) { int[] b = { 49, 38, 65, 97, 76, 13, 27, 50 }; selectionSort(b); for (int i : b) System.out.print(i + " "); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
28.双色球案例
双色球需求:红球选六个,蓝球选一个
红球6个:1–33
篮球1个:1–16
红球数组:1,2,3, …… 33 用随机数(Random)
篮球数组:1,2,3, …… 16 random(16)+1
中奖数组:6个红一个蓝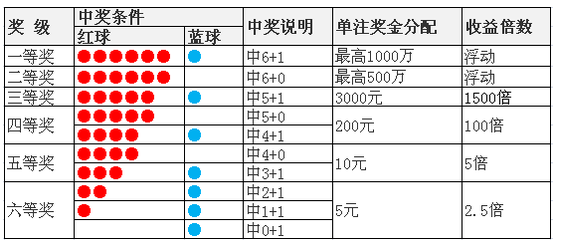
29.包的概念和 Eclipse开发工具基本使用
Eclipse开发工具基本使用
1、下载地址:
eclipse:https://www.eclipse.org/downloads/download.php?file=/oomph/epp/2018-09/R/eclipse-inst-win64.exe
sts: http://spring.io/tools3(1)包的概念:
包(package)是Java提供的一种区别类的名字空间的机制,是类的组织方式,
是一组相关类和接口的集合,它提供了访问权限和命名的管理机制。
Java中提供的包主要有以下3种用途:- 将功能相近的类放在同一个包中,可以方便查找与使用。
- 由于在不同包中可以存在同名类,所以使用包在一定程度上可以避免命名冲突。
- 在Java中,某次访问权限是以包为单位的。
(2)定义包
package myblog; //它必须在第一行(它之前除了注释和空白什么都不能有)
注意:
(1)定义了包之后,这个包内的所有类的全名就是:包名.类名
(2)如果不加package语句,则指定为缺省包或无名包。
(3)包对应着文件系统的目录层次。
(4)在package语句中,用“.”来指明包(目录)的层次。
(5)因为我们自定义的包要对应文件系统中的一个目录名,在这个目录名下面存放的是一个类,我们需要建立相应的文件夹,作为包。但是有一个问题,如果我们有成千上万的类是不是我们要手动建立成千上万的包呢?这样繁琐的事情我们还是交给java编译器吧,也就是我们eclipse在编译的时候会自动生成包对应的系统目录。
(6)多包(多层次)大包与小包还有类的层次结构:大包.小包.类名(3)import语句
(1)引入包中的类(如果我们只想引入某个包中的类)
import java.io.File;
(2)引入整个包
import java.io.*;
①这样虽然方便,但是当我们导入包中所有的类时,java编译器就会用额外的内存来存储包中类和方法的名字,
以便跟踪这个包中所有的元素,这在我们的pc机上没有太大的性能差异。然而当我们在手持设备上,
一般的手持设备内存都比较小,这种方式就不太好了,更适合第一种方式想引用哪个类就具体引用哪个
②当我们通过网络远程加载一个类时,如果它导入了一包中所有的类,
那么在加载的时候就会把所有的类和方法加载到本地来,这就会造成java程序执行时间上的延迟。
所以只有当我们需要导入这个包中很多类的时候,再用这种方式。
(3)在同一包中的类可以互相引用,无需import语句注意:java.lang包是自动引入的,不需要我们显式的加import引入。因此我们可以直接引用System、String
2、新建java工程,新建工程就要说到包的概念
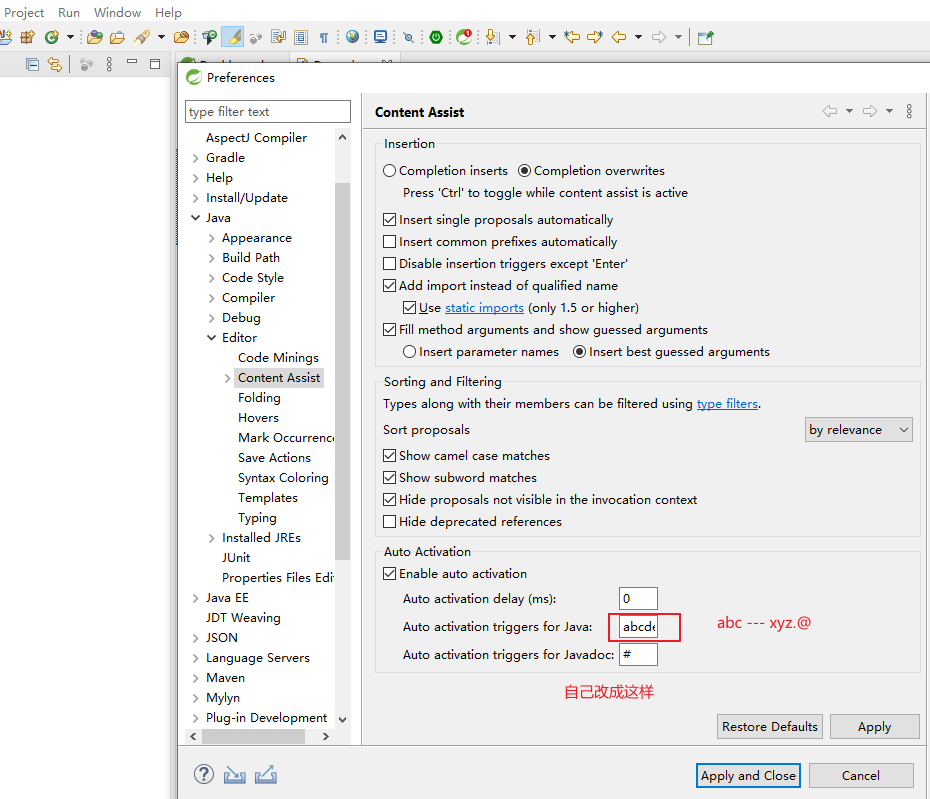
3、运行工程中的类的main方法,Debug跟踪程序的执行过程
30.面向对象的理解
1、什么是面向对象( Object Oriented Programming,简称OOP)
面向对象是一种解决问题的思想,是一种看问题的角度。
其实编程就是把现实世界的语言,翻译成计算机能看懂的语言来执行的过程。
无论是面向对象,还面向过程(C语言),其实就是翻译的方式不同而已。与面向对象相对应的是面向过程的思想,它是做法就是先明确实现什么功能,
然后针对这个功能考虑我第一步做什么,第二步做什么…写出来的代码:

面向对象相的思想,我先把冰箱这个这个类抽象出来,
然后定义这个类的每个实际个体都可以做的动作(方法)抽象出来:

可以反复地重复地使用这个类:

这样做的好处就是减少了我们的代码量,让代码的复用性更强了!!
2、面向对象的有三个特征,
封装、继承、多态,我们在今后的学习中会慢慢讲,大家先记住就可以了3、总之,面向对象在写程序中,首先考虑的是整体,然后在分析这个整体里的具体!
4、做面向对象与面向过程的比较:
(1)面向过程:程序的重心集中在谓语上
(2)面向对象:程序的重心集中在名词上
如:我把大象关冰箱总共分几步在面向过程的main函数里: 在面向对象的main函数里: 把冰箱门打开的函数 vs 冰箱、大象两个对象 把大象放进去的函数 vs 冰箱有开门、存放(搁置)东西的功能,关门的功能, 把冰箱门关上的函数- 1
- 2
- 3
- 4
面向过程的核心的动作,面向对象的核心是冰箱,传一参数大象
面向对象的最大贡献:可扩展、可重用(相同的功能的代码只写一编,可以重复使用)
程序是对象间的相互调用
不管面向对象语言有什么好处和缺点,你现在在学习java,他是一种纯面向对象的语言,大家就要
学会用面向对象的方法来解决问题31.类和对象
1、学习java语言,我们首先就得提到两个非常重要的概念,就是类和对象。
要知道什么是类,什么是对象,他俩有什么关系。
面向对象的编程,其实更具体一点的应该说是面向类的编程。(1) 所谓类就就是一个模板,我们把具有相似特征的东西抽象成为类。
具有这些特征的真实个体就是对象。
比如刚才我们声明的Icebox就是一个冰箱类,至于家里用的具体的某个冰箱,就是这个Icebox类的实例。

(2) 再比如说,图片上有各种各样的灯,他们为什么都叫灯,
因为它们都有灯丝,灯罩和灯座(这些抽象成类的属性,其实就是特征),
他们都有开、关、变亮、变暗的功能(抽象成类的方法,就是动作行为)。
我们把灯抽象出来定义成为类,家里使用的每个灯
都是灯类的一个对象,可以通过其属性值的不同分辨是哪种类。注意:正确的方法和正确的属性应该出现在正确的类中
2、类的定义
在实际编程过程中,我们应该把具有一类特征的事物抽象成一个类,每个具体的事物就是一个类的对象。
那么在java中怎么用代码来描述一个类?
(1)定义一个类

修饰符一般为public,也可以没有修饰符。
注意类名的命名规范。类名一般大写首字母
类的成员:成员变量(属性) 成员函数(方法)- 1
- 2
通过“
.”调用属性和方法类的完全声明形式,先看一个眼熟,后面会具体的讲解:
[public] [abstract | final ] class 类名称 [extends 父类名称] [implements 接口名称列表] { 成员变量声明及初始化; 方法声明及方法体; }- 1
- 2
- 3
- 4
- 5
格式说明
类的访问说明符:级别 修饰符 同包 不同包 公开 public Ok Ok 默认 Ok No- 1
- 2
- 3
类的其它修饰符:
(1)final(表明这个类是一个最终的类,不能由这个类派生出其他的子类比如我们熟知的String类)
这个类不能被继承(先记住)
(2)abstract(表示这是一个抽象类)(先记住)成员变量(类的属性)声明格式
[public | protected | private] [static][ final ] 变量数据类型 变量名1[=变量初值], 变量名2[=变量初值], … ;- 1
格式说明
static指明这是一个静态成员变量(后面会仔细讲)
final指明变量的值不能被修改(后面会仔细讲)
变量的访问修饰符:级别 修饰符 同类 同包 子类 不同包 公开 public Ok Ok Ok Ok 受保护 protected OK Ok Ok No 私有 private ok no no no 完整的类的方法声明格式,也是眼熟一下,具体的东西,慢慢道来:
[public|protected|private] [static] [final] [abstract] [native] [synchronized] 返回类型 方法名([参数列表]) [throws exceptionList] { 方法体; }- 1
- 2
- 3
- 4
- 5
格式说明
static指明方法是一个类方法
final指明方法是一个终结方法
abstract指明方法是一个抽象方法
native用来集成java代码和其它语言的代码
synchronized用来控制多个并发线程对共享数据的访问方法的访问修饰符:
级别 修饰符 同类 同包 子类 不同包 公开 public Ok Ok Ok Ok 受保护 protected OK Ok Ok No 私有 private ok no no no 
练习 Person.java
定义一个Person类,Person类具有名字、年龄及性别和身高等属性,
并具有一个getInfo( )方法可以打印出Person类的属性, sayHello()方法和大家说“Hello everybody!”练习 Point.java
定义一个点类Point,包含两个成员变量x、y分别表示x和y的坐标,
一个movePoint(int dx,int dy)方法实现点的位置的移动。练习 MyDate.java
定义一个日期MyDate,包含三个成员变量year 、month、day分别表示年、月、日,
以及每个属性对应的get和set方法(如,year有getYear( )方法用来获得日期的年份,
还有setYear(int y)方法用来修改或设置日期的年份),最后还有printDate()方法,
调用该方法可以把日期按照“yyyy-mm-dd”的形式输出。练习 西游记游戏软件中的游戏人物的类定义出来
孙悟空:孙悟空的武器是金箍棒,战斗力五颗星,耐力五颗星
唐 僧:唐僧没有武器,战斗力为零,耐力五颗星
猪八戒:猪八戒的武器是耙子,战斗力四颗星,耐力两颗星
沙 僧:沙僧的武器是月牙铲 ,战斗力三颗星,耐力四颗星3、对象的定义
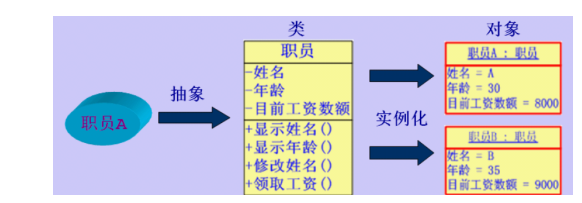
- 类和对象的关系
类(class) — 是对某一类事物的描述
对象(object) — 是实际存在的某类事物的个体,也称为实例(instance)
类是创建对象的模板,对象是类的实例。
对象的创建语法格式
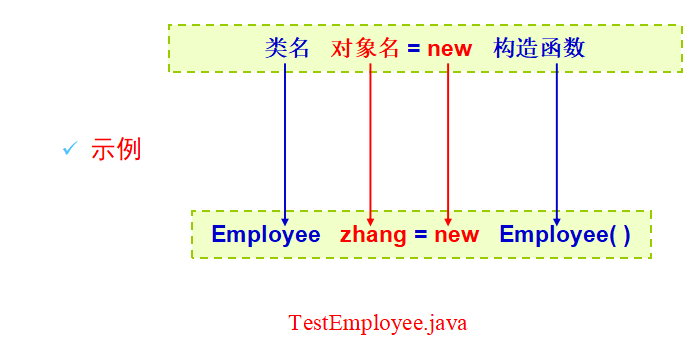
注意:构造函数是面向过程中的叫法,在面向对象里我们将构造方法,其实是一个概念,它名称必须是类名!
练习 TestPerson.java
在TestPerson类里写一个main方法,在main( )方法中:
创建一个Person类的对象
这个对象的名字叫张三,年龄28,性别男
在控制台中打印这个实例的信息
并调用这个对象的sayHello( )方法,向大家问好练习 TestPoint.java
在TestPoint类里写一个main方法,在main( )方法中:
创建一个Point类的对象
这个点的坐标是(3,2)
将这个点移动到坐标为(5,6)的位置
并把移动后的点的坐标按“(x,y)”形式打印在控制台上练习 TestDate.java
在TestDate类里写一个main方法,在main( )方法中:
创建一个MyDate类的对象
通过setXXX方法将该日期对象的时间设置为“2018年10月8日”
在控制台上打印该对象的月份
把该日期对象按“2018-10-8”的格式输出匿名对象
创建完对象,在调用该对象的方法时,也可以不定义对象的句柄,
而直接调用这个对象的方法。这样的对象叫匿名对象:

使用场景:如果对一个对象只需要进行一次方法调用
32. 构造方法
1、构造方法(构造函数/构造器,Constructor)
我在创建类的实例的时候,要用到new关键字,后面再加一个函数,这个函数就叫做构造函数。
构造函数是一种特殊的函数,我们可以通过调用构造函数来创建一个对象或类的实例(这是构造方法的基本能力)。
(1)那么什么样的函数才能做构造函数来创建一个对象,或者说如果要你在定义类的时候写一个构造函数
你该怎么写呢?我们来看一下构造函数的写法。具有与类相同的名称 不含返回值类型 不能在方法中用return语句返回一个值 一般访问权限为public- 1
- 2
- 3
- 4
(2)不含返回值的含义不是返回值类型void,而是void都不能写,这是语法是规则不要问为什么。
(3)我们按照上面所说的语法规则,来定义一个Person类的构造函数。
。。。
(4) 我们已经声明好这个构造函数了,那么我们在构造函数体里应该写些什么呢?
我们说一般可以通过构造函数来完成对成员变量的初始化。
对于事物一些与生俱来的特征,我们就可以放在构造函数中对它进行定义。
比如说,对于一个Person类,只要它生下来age(年龄)和sex就已经定下来了。那我们在创
建一个Person对象的同时,就可以。。。2、默认的构造方法
在Java中,每个类都至少要有一个构造方法,如果程序员没有在类里定义构造方法,系统会自动为这个类产生一个默认的构造方法。
注意:一旦编程者为该类定义了构造方法(自己显示地写出了构造方法),系统就不再提供默认的构造方法
原则(现在必须记住的一个原则):一旦我们自己显示地写出了有参数的构造方法,一定一定要在显示地写出无参数的空构造!!!!!!!!!!因为以后我们要学习的很多框架(真正的企业级的项目开发,都是要用框架来进行开发,这些框架一般情况下都会调用类里的空构造!)

3、前面讲过方法的重载,构造方法也是可以重载的,并且构造方法是可以有多个的,举例:
33.对象创建的内存模型
1、我们在第8次课就介绍了java的变量分两大类:基本数据类型变量和引用类型的变量,
(1)其中基本数据类型有四类八种:boolean byte char short int long double float
(2)那什么是引用类型的变量呢?引用类型变量
除了8种基本数据类型的变量,其他变量都是引用类型变量
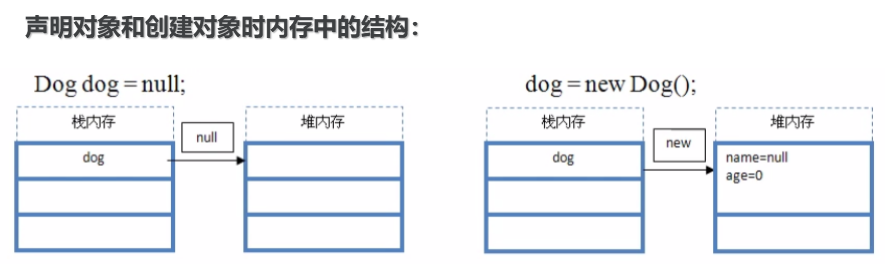
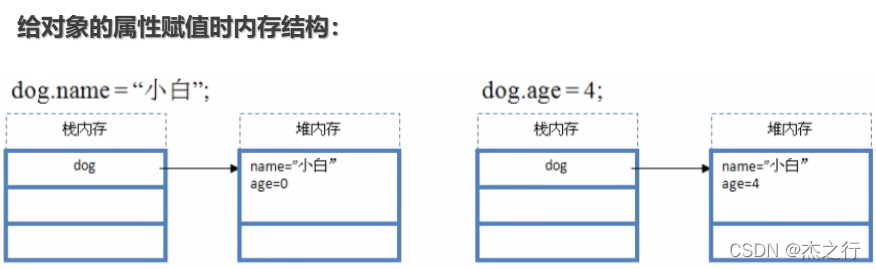

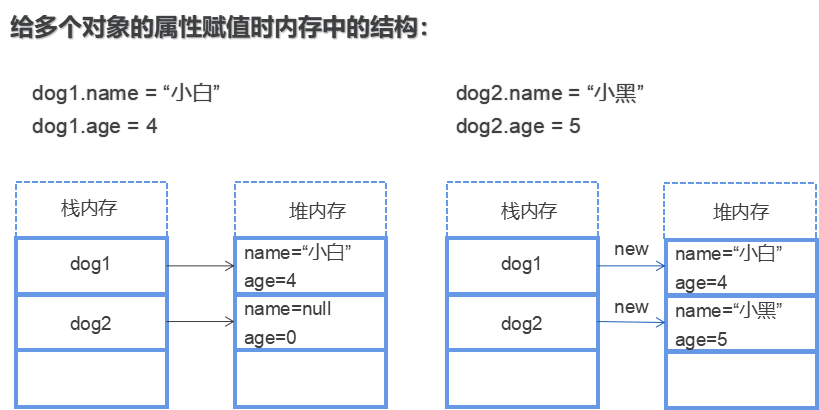
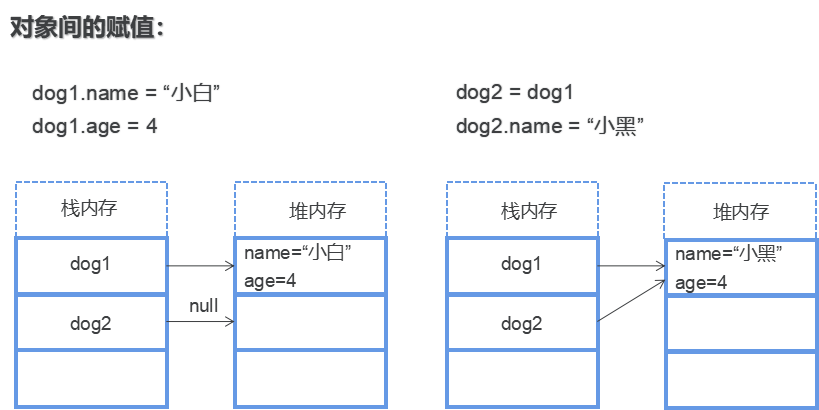
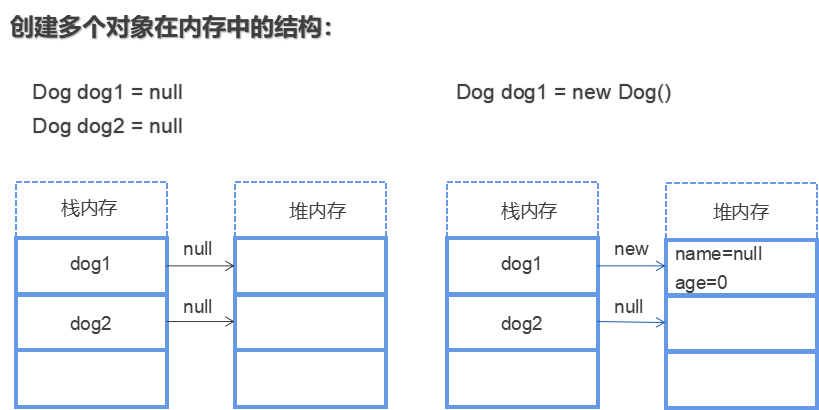
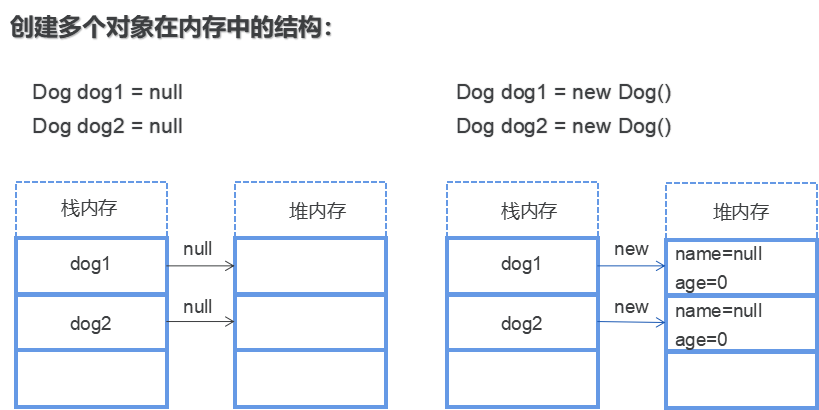
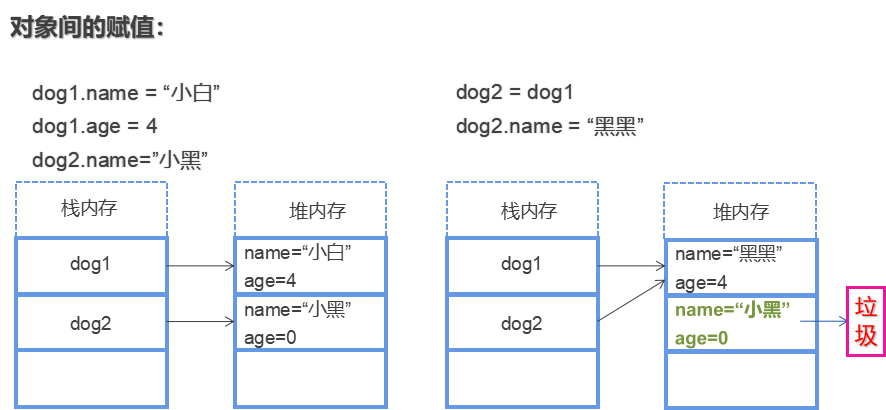
所谓的引用就是持有堆内存中对应对象所在的位置的内存地址!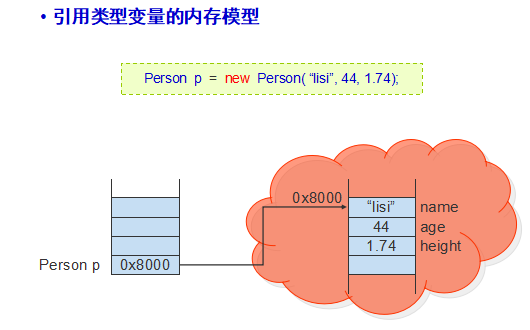
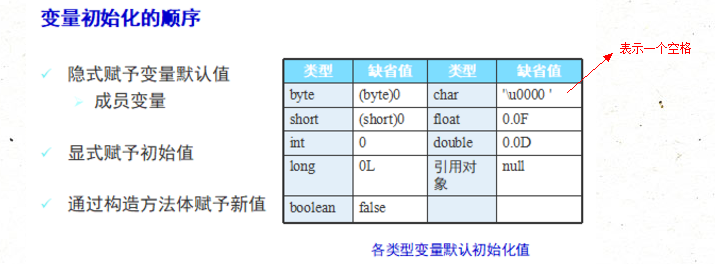
34.变量的作用域和变量初始化顺序
好到目前为止我们才算把java中所有的变量类型讲个七七八八。
接下来我们来看看不同的变量,他们的生存周期也就是作用范围都是怎样的。- 所谓变量的作用域就是说你声明的某个变量在内存中待的时间的长短,直白一点就是你定义的变量,
在代码的那些范围里能够取到这个变量的值,
而变量的类型是指变量在内存中占的地方大小 - 变量的作用域是通过变量声明的位置来判断的
根据变量的作用域的不同将变量分为全局变量和局部变量
全局变量
类体中声明的成员变量为全局变量
全局变量在类的整个生命周期中都有效局部变量
方法体中声明的变量,方法中的参数,或代码块中声明的变量,都是局部变量
局部变量只在方法调用的过程中有效,方法调用结束后失效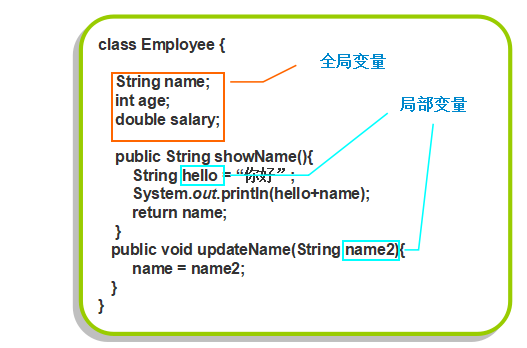

35. 调用方法时的参数传值
前面我们对方法的参数传值有过简单介绍,但那是只方法参数传值中的第一种,值传递,
但是方法参数传递除了值传递还有引用传递,下面我就彻底地分析一下参数传递中的知识:1、当方法被调用时,如果方法有参数,参数必须要实例化,即
参数变量必须有具体的值。

2、
基本数据类型参数的传值——值
这种数据传递方式被称为是值传递,方法接收参数的值,但不能改变这些参数的值。3、
引用类型参数的传值——地址
引用传值方式:Java的引用类型数据包括对象、数组和接口,当方法中参数是引用类型时,
引用数据类型传递给方法的是数据在内存中的地址,是引用,可以改变原来参数的值。分析例子:
class People { String face; void setFace(String s) { face = s; } } class C { void f(int x, double y, People p) { x = x + 1; y = y + 1; p.setFace("笑脸"); System.out.println("参数x和y的值分别是:" + x + "," + y); System.out.println("参数对象p的face是:" + p.face); } } public class MainDemo { public static void main(String args[]) { int m = 100; double n = 100.88; People zhang = new People(); zhang.setFace("很严肃的样子"); C a = new C(); a.f(m, n, zhang); System.out.println("main方法中m和n的值仍然分别是:" + m + "," + n); System.out.println("main方法中对象zhang的face是:" + zhang.face); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
36.对象数组
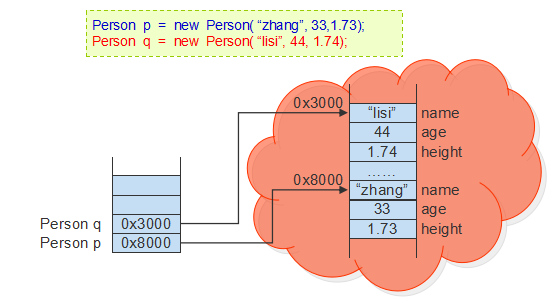
在Java中不但可以声明由基本数据类型的数据组成的数组,还可以声明由对象组成的数组;
声明对象数组的方式如:

注意:对象数组==引用数组,它的内存结构很多初学者都会搞错:
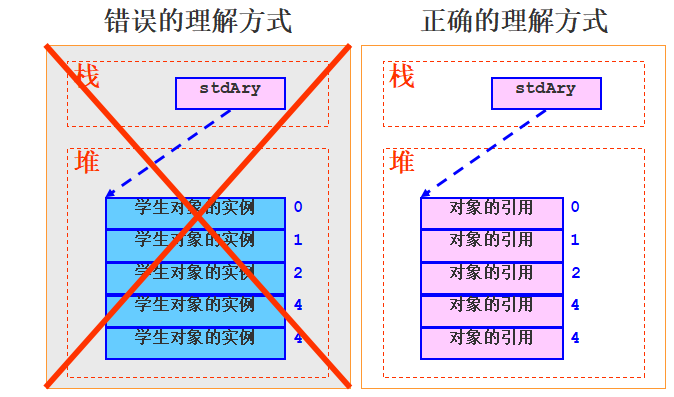
放到数组的元素其实是对象在堆内存中的内存地址,我们常常叫做这个对象的引用:
真正的内存结构应该是:
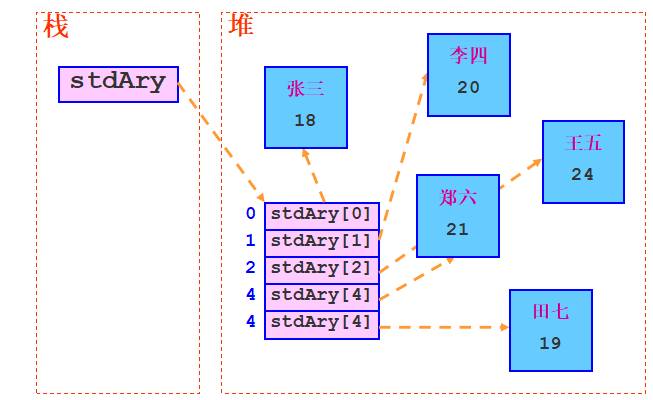
最后写一下这个例子:

37. this关键字
一:概述
this代表它所在函数所属对象的引用。
简单说:哪个对象在调用this所在的函数,this就代表哪个对象。二、this关键字主要有三个应用:
(1)this调用本类中的属性,也就是类中的成员变量;
Public Class Student { String name; //定义一个成员变量name private void SetName(String name) { //定义一个参数(局部变量)name this.name=name; //将局部变量的值传递给成员变量 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
(2)this调用本类中的其他方法;
(3)this调用本类中的其他构造方法,调用时要放在构造方法的首行。
public class Student { //定义一个类,类的名字为student。 public Student() { //定义一个方法,名字与类相同故为构造方法 this(“Hello!”); } public Student(String name) { //定义一个带形式参数的构造方法 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
38.static关键字
一.static关键字的用途
在《Java编程思想》P86页有这样一段话:
“static方法就是没有this的方法。在static方法内部不能调用非静态方法,反过来是可以的。而且可以在没有创建任何对象的前提下,仅仅通过类本身来调用static方法。这实际上正是static方法的主要用途。”
这段话虽然只是说明了static方法的特殊之处,但是可以看出static关键字的基本作用,简而言之,一句话来描述就是:
方便在没有创建对象的情况下来进行调用(方法/变量)。
很显然,被static关键字修饰的方法或者变量不需要依赖于对象来进行访问,只要类被加载了,就可以通过类名去进行访问。
static可以用来修饰类的成员方法、类的成员变量,另外可以编写static代码块来优化程序性能。1)static方法
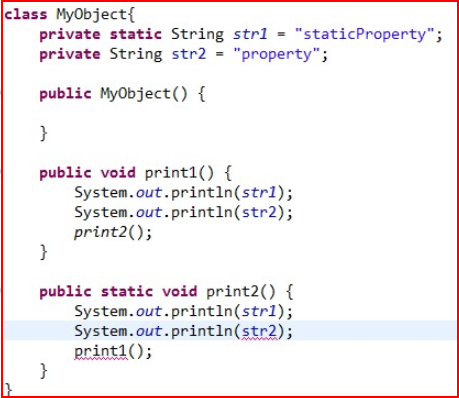
static方法一般称作静态方法,由于静态方法不依赖于任何对象就可以进行访问,因此对于静态方法来说,是没有this的,因为它不依附于任何对象,既然都没有对象,就谈不上this了。并且由于这个特性,在静态方法中不能访问类的非静态成员变量和非静态成员方法,因为非静态成员方法/变量都是必须依赖具体的对象才能够被调用。
但是要注意的是,虽然在静态方法中不能访问非静态成员方法和非静态成员变量,但是在非静态成员方法中是可以访问静态成员方法/变量的。举个简单的例子:
2)static变量
static变量也称作静态变量,静态变量和非静态变量的区别是:静态变量被所有的对象所共享,在内存中只有一个副本,它当且仅当在类初次加载时会被初始化。而非静态变量是对象所拥有的,在创建对象的时候被初始化,存在多个副本,各个对象拥有的副本互不影响。
static成员变量的初始化顺序按照定义的顺序进行初始化。3)static代码块
static关键字还有一个比较关键的作用就是用来形成静态代码块以优化程序性能。static块可以置于类中的任何地方,类中可以有多个static块。在类初次被加载的时候,会按照static块的顺序来执行每个static块,并且只会执行一次。
为什么说static块可以用来优化程序性能,是因为它的特性:只会在类加载的时候执行一次。下面看个例子:class Person{ private Date birthDate; public Person(Date birthDate) { this.birthDate = birthDate; } boolean isBornBoomer() { Date startDate = Date.valueOf("1946-1-1"); Date endDate = Date.valueOf("1964-12-31"); return birthDate.compareTo(startDate)>=0 && birthDate.compareTo(endDate) < 0; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
isBornBoomer是用来这个人是否是1946-1964年出生的,而每次isBornBoomer被调用的时候,都会生成startDate和birthDate两个对象,造成了空间浪费,如果改成这样效率会更好:
class Person{ private Date birthDate; private static Date startDate,endDate; static{ startDate = Date.valueOf("1946-1-1"); endDate = Date.valueOf("1964-12-31"); } public Person(Date birthDate) { this.birthDate = birthDate; } boolean isBornBoomer() { return birthDate.compareTo(startDate)>=0 && birthDate.compareTo(endDate) < 0; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
因此,很多时候会将一些只需要进行一次的初始化操作都放在static代码块中进行。
二.static关键字的误区
1.static关键字会改变类中成员的访问权限吗?
Java中的static关键字不会影响到变量或者方法的作用域。在Java中能够影响到访问权限的只有private、public、protected(包括包访问权限)这几个关键字。看下面的例子就明白了:

2.能通过this访问静态成员变量吗?
虽然对于静态方法来说没有this,那么在非静态方法中能够通过this访问静态成员变量吗?先看下面的一个例子,这段代码输出的结果是什么?
public class Main { static int value = 33; public static void main(String[] args) throws Exception{ new Main().printValue(); } private void printValue(){ int value = 3; System.out.println(this.value); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
这里面主要考察队this和static的理解。this代表什么?this代表当前对象,那么通过new Main()来调用printValue的话,当前对象就是通过new Main()生成的对象。而static变量是被对象所享有的,因此在printValue中的this.value的值毫无疑问是33。在printValue方法内部的value是局部变量,根本不可能与this关联,所以输出结果是33。在这里永远要记住一点:静态成员变量虽然独立于对象,但是不代表不可以通过对象去访问,所有的静态方法和静态变量都可以通过对象访问(只要访问权限足够)。
3.static能作用于局部变量么?
在Java中切记:static是不允许用来修饰局部变量。不要问为什么,这是Java语法的规定。
《Java编程思想》电子书分享链接:https://pan.baidu.com/s/1mwOTFTFYvdTFbjCmFOPB4Q
提取码:ynx339. java封装
Java 封装
在前面的课程中,我们其实已经接触到了封装,只不过我没有显示地提出封装这个概念:
前面在讲类的定义的时候,我们列举的例子中,我说通常情况下,我们的类里的属性都会用private访问修饰符
修饰,然后在为每一个属性创建一个对set/get方法来实现对属性的取值和赋值操作!
其实这就是Java编程中最最常见的一种封装!什么是封装?
简而言之封装就是:把该隐藏起来的藏起来,该暴露的暴露出来,说的正是一点的就是指将对象的信息隐藏在
对象的内部,不允许外部的程序直接访问对象的内部信息,而是通过该类所提供的方法来实现对内部信息的操作和访问。为什么要封装?
面向对象的编程语言的本质核心思想就是对客观世界的模拟,在客观世界里,客观对象的状态信息都是隐藏在内部的,
好比前面我说的,对象好比我们的家,对象里的属性好比我们家里的东西,显然我们家里的东西,是不允许别人随便
的拿和放的!这是客观事实,所有对客观世界的模拟的Java程序里的对象,也要封装!怎么实现Java封装
- 修改属性的可见性来限制对属性的访问(一般限制为private),例如:
public class Person { private String name; private int age; }- 1
- 2
- 3
- 4
这段代码中,将 name 和 age 属性设置为私有的,只能本类才能访问,其他类都访问不了,如此就对信息进行了隐藏。
- 对每个值属性提供对外的公共方法访问,也就是创建一对赋取值方法,用于对私有属性的访问,例如:
public class Person{ private String name; private int age; public int getAge(){ return age; } public String getName(){ return name; } public void setAge(int age){ this.age = age; } public void setName(String name){ this.name = name; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
采用 this 关键字是为了解决实例变量(private String name)和局部变量(setName(String name)中的name变量)之间发生的同名的冲突。
以上实例中public方法是外部类访问该类成员变量的入口。
通常情况下,这些方法被称为getter和setter方法。
因此,任何要访问类中私有成员变量的类都要通过这些getter和setter方法。
通过如下的例子说明EncapTest类的变量怎样被访问:
RunPerson.java 文件代码:public class RunPerson{ public static void main(String args[]){ Person p= new Person(); p.setName("James"); p.setAge(20); System.out.print("Name : " + p.getName()+ " Age : "+ p.getAge()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
以上代码编译运行结果如下:
Name : James Age : 20封装的优点
- 良好的封装能够减少耦合。
- 类内部的结构可以自由修改。
- 可以对成员变量进行更精确的控制。(代码举例说明)
- 隐藏信息,实现细节。
40.类的继承
继承(inheritance)是面向对象编程的核心机制之一,没有使用继承的程序设计,就不能成为面向对象的程序设计。
1、什么是继承:
在软件开发中,通过继承机制,可以利用已有的数据类型来定义新的数据类型。所定义的新的数据类型不仅拥有新定义的成员,而且还同时拥有旧的成员。说白了,就是定义一个类,让它成为某个类(一般叫父类)的子类,那么它就会继承这个做父类的类里的部分属性和方法,因此,类的继承性使所建立的软件具有开放性、可扩充性,这是信息组织与分类的行之有效的方法,通过类的继承关系,使公共的特性能够共享,简化了对象、类的创建工作量,增加了代码的可重用性,复用性。
2、java 中继承使用关键字extends ,语法如下:
[类修饰符] class 子类名 extends 父类名{ 语句; }- 1
- 2
- 3
代码的示例:
//Person public class Person{ String name; int age; void eat(String s){ System.out.println(s); } void sleep(String s){ System.out.println(s); } } //Teacher public class Teacher extends Person{ int salary; String school; void teach(String s){ System.out.println(s); } public static void main(String[] args){ Teacher t = new Teacher(); //实例化Teacher 类对象t t.name = "张三"; System.out.println("教师"+t.name); t.eat("吃"); //使用从父类继承来的成员方法eat() t.sleep("睡"); //使用从父类继承来的成员方法sleep() t.teach("上课"); //使用在Teacher类中定义的teach()方法 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
有关类的继承上需要我们注意的知识点:
1、在java中,java.lang.Object 类是所有java类的最高层父类,是唯一一个没有父类的类:
如果在类的声明中未使用extends 关键字指明其父类,则默认父类为Object 类。java中的类的继承关系形成了以Object 类为树根的树状层次结构。例:public class Text{ ......; }- 1
- 2
- 3
等价于
public class Text extends Object{ ......; }- 1
- 2
- 3
2、如果两个类存在继承关系,则子类会自动继承父类的部分方法和变量,在子类中可以调用父类的方法和变量。在java中,只允许单继承,也就是说 一个类最多只能显示地继承于一个父类。但是一个类却可以被多个类继承,也就是说一个类可以拥有多个子类。
(1) 子类继承父类的成员变量
当子类继承了某个类之后,便可以使用父类中的成员变量,但是并不是完全继承父类的所有成员变量。具体的原则如下:
1)能够继承父类的public和protected成员变量;不能够继承父类的private成员变量;
2)对于子类可以继承的父类成员变量,如果在子类中出现了同名称的成员变量,则会发生隐藏现象,即子类的成员变量会屏蔽掉父类的同名成员变量。如果要在子类中访问父类中同名成员变量,需要使用super关键字来进行引用。(2) 子类继承父类的方法
同样地,子类也并不是完全继承父类的所有方法。
1)能够继承父类的public和protected成员方法;不能够继承父类的private成员方法;
2)对于子类可以继承的父类成员方法,如果在子类中出现了同名称且同参数的成员方法(又叫子类重写父类的方法),则称为覆盖,即子类的成员方法会覆盖掉父类的同名成员方法。如果要在子类中访问父类中同名成员方法,需要使用super关键字来进行引用。注意:隐藏和覆盖是不同的。隐藏是针对成员变量和静态方法的,而覆盖是针对普通方法的。

3、子类是不能够继承父类的构造器,但是要注意的是,如果父类的构造器都是带有参数的,则必须在子类的构造器中显示地通过super关键字调用父类的构造器并配以适当的参数列表。如果父类有无参构造器,则在子类的构造器中用super关键字调用父类构造器不是必须的,如果没有使用super关键字,系统会自动调用父类的无参构造器。做个例子就清楚了:
4.super关键字
super主要有两种用法:
1)super.成员变量/super.成员方法;
2)super(parameter1,parameter2…)
第一种用法主要用来在子类中调用父类的同名成员变量或者方法;
第二种主要用在子类的构造器中显示地调用父类的构造器,
要注意的是,如果是用在子类构造器中,则必须是子类构造器的第一个语句。41. 多态性
面向对象编程有三大特性:封装、继承、多态。有的资料上对面向对象的编程说成4个基本特征:抽象,封装、继承、多态。
封装隐藏了类的内部实现机制,可以在不影响使用的情况下改变类的内部结构,同时也保护了数据。对外界而已它的内部细节是隐藏的,暴露给外界的只是它的访问方法。
继承是为了重用父类代码。两个类若存在通常"D is a B"(D被包含在B内)的关系就可以使用继承。同时继承也为实现多态做了铺垫。那么什么是多态呢?多态的实现机制又是什么?
1、什么是多态
说多态前我们首先要知道Java的引用类型变量有两种更细类型:一个是编译时类型,一个是运行时类型。
编译时类型由声明这个变量的时候决定的,比如 String a=“你好”;
运行时类型则是由实际赋值给这个变量的对象来决定的。Integer b=1; String a = b;
如果编译时类型和运行时类型不一致的时候,就可能出现所谓的多态! 子类类型的对象赋值给父类类型的引用变量!比如一个酒神,对酒情有独钟。某日回家发现桌上有几个杯子里面都装了白酒,从外面看我们是不可能知道这是些什么酒,只有喝了之后才能够猜出来是何种酒。酒神一喝,这是剑南春、再喝这是五粮液、再喝这是酒鬼酒….在这里我们可以描述成如下:
酒 a = 剑南春 // 这个时候就发生了java里边说的:多态
酒 b = 五粮液
酒 c = 酒鬼酒
说一句话:剑南春是白酒, 白酒做成父类,剑南春白酒的子类,java语言!
上面的例子中酒是一个类, 剑南春也是一个类, 酒类包含了剑南春这个子类,我们把子类的对象赋值给父类类型的引用变量叫做子类的向上转型。用代码来表示:
public class Wine { public void fun1(){ System.out.println("Wine 的Fun....."); fun2(); } public void fun2(){ System.out.println("Wine 的Fun2..."); } } public class JNC extends Wine{ /** * @desc 子类重载父类方法 * 父类中不存在该方法,向上转型后,父类是不能引用该方法的 * @param a * @return void */ public void fun1(String a){ System.out.println("JNC 的 Fun1..."); fun2(); } /** * 子类重写父类方法 * 指向子类的父类引用调用fun2时,必定是调用该方法 */ public void fun2(){ System.out.println("JNC 的Fun2..."); } } public class Test { public static void main(String[] args) { Win a1 = new Win(); //声明的变量和赋值的对象同种类型,不存在多态 Wine a = new JNC(); //声明的变量和赋值的对象不同类型,这就存在多态了 a.fun1(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
从程序的运行结果中我们发现,a.fun1()首先是运行父类Wine中的fun1().然后再运行子类JNC中的fun2()。
分析:在这个程序中子类JNC重载了父类Wine的方法fun1(),重写fun2(),而且重载后的fun1(String a)与 fun1()不是同一个方法,父类中没有含参数的fun1方法,向上转型后会丢失子类里的特有方法,所以用JNC这个类的对象的Wine类型引用是不能引用有参数的fun1(String a)方法。而子类JNC重写了fun2() ,那么指向JNC的Wine引用会优先调用JNC中fun2()方法。所以对于多态我们可以总结如下:
指向子类的父类引用由于向上转型了,它只能访问父类中拥有的方法和属性,而对于子类中存在而父类中不存在的方法,该引用是不能使用的,尽管是重载该方法。若子类重写了父类中的某些方法,在调用该些方法的时候,必定是使用子类中定义的这些方法,他们优先级高于父类中的方法。2、多态的实现机制
基于继承(包括我们后面要讲的接口,对接口的实现我们也可以理解为一种特殊的继承)的多态实现机制主要表现在父类和继承该父类的一个或多个子类对某些方法的重写,多个子类对同一方法的重写可以表现出不同的行为。多态:多种形态,就是多态性!(用代码是说明一下!)
有关多态的经典例子:
public class A { public String show(D obj) { return ("A and D"); } public String show(A obj) { return ("A and A"); } } public class B extends A{ public String show(B obj){ return ("B and B"); } public String show(A obj){ return ("B and A"); } } public class C extends B{ } public class D extends B{ } public class Test { public static void main(String[] args) { A a1 = new A(); A a2 = new B(); B b = new B(); C c = new C(); D d = new D(); System.out.println("1--" + a1.show(b)); System.out.println("2--" + a1.show(c)); System.out.println("3--" + a1.show(d)); System.out.println("4--" + a2.show(b)); System.out.println("5--" + a2.show(c)); System.out.println("6--" + a2.show(d)); System.out.println("7--" + b.show(b)); System.out.println("8--" + b.show(c)); System.out.println("9--" + b.show(d)); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
运行结果:
1--A and A 2--A and A 3--A and D 4--B and A 5--B and A 6--A and D 7--B and B 8--B and B 9--A and D- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在这里看结果1、2、3还好理解,从4开始就开始糊涂了,对于4来说为什么输出不是“B and B”呢?
其实在继承链中对象方法的调用存在优先级:this.show(O)、super.show(O)、this.show((super)O)、super.show((super)O)。
首先我们分析5,a2.show©,a2是A类型的引用变量,所以this就代表了A,a2.show©,它在A类中找发现没有找到,于是到A的超类中找(super),由于A没有超类(Object除外),所以跳到第三级,也就是this.show((super)O),C的超类有B、A,所以(super)O为B、A,this同样是A,这里在A中找到了show(A obj),同时由于a2是B类的一个引用且B类重写了show(A obj),因此最终会调用子类B类的show(A obj)方法,结果也就是B and A。
当超类对象引用变量引用子类对象时,被引用对象的类型决定了调用谁的成员方法,但是这个被调用的方法必须是在超类中定义过的,在看一个例子说明:a2.show(b);
这里a2是引用变量,为A类型,它引用的是B对象,因此按照上面那句话的意思是说由B来决定调用谁的方法,所以a2.show(b)应该要调用B中的show(B obj),产生的结果应该是“B and B”,但是为什么会与前面的运行结果产生差异呢?这里我们忽略了后面那句话“但是这儿被调用的方法必须是在超类中定义过的”,那么show(B obj)在A类中存在吗?根本就不存在!所以这句话在这里不适用?那么难道是这句话错误了?非也!其实这句话还隐含这这句话:它仍然要按照继承链中调用方法的优先级来确认。所以它才会在A类中找到show(A obj),同时由于B重写了该方法所以才会调用B类中的方法,否则就会调用A类中的方法。
42. 引用变量的类型强制转换和 instanceof运算符
1.什么时候需要用到强制类型转换(引用数据类型)
当把子类对象赋给父类引用变量时,这个父类引用变量只能调用父类拥有的方法,
不能调用子类特有的方法,即使它实际引用的是子类对象。
如果需要让这个父类引用变量调用它子类的特有的方法,就必须把它强制转换成子类类型。2.引用类型之间要强制转换成功需要有什么条件
把父类实例转换成子类类型,则这个对象必须实际上是子类实例才行,否则将在运行时引发ClassCastException。
3.让程序更健壮的写法:
在强制转换前使用instanceof运算符判断是否可以成功转换。
示例如下:class Base { private int value; public void say() { System.out.println("Base class"); } } class Sub extends Base { public void say() { System.out.println("Sub class"); } //子类的特有方法 public void read() { System.out.println("Are you sleeping?"); } } public class Test { public static void main(String[] args) { Base base=new Sub(); base.say();//多态,会调用子类的方法 if(base instanceof Sub)//先判断能否转换成功 { ((Sub)base).read();//强转过后才可以调用read方法 } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
java 中的instanceof 运算符是用来在运行时指出对象是否是特定类的一个实例。instanceof通过返回一个布尔值来指出,这个对象是否是这个特定类或者是它的子类的一个实例。
用法:
result = object instanceof class
参数:
Result:布尔类型。
Object:必选项。任意对象表达式。
Class:必选项。任意已定义的对象类。
说明:
如果 object 是 class 的一个实例,则 instanceof 运算符返回 true。如果 object 不是指定类的一个实例,或者 object 是 null,则返回 false。
但是instanceof在Java的编译状态和运行状态是有区别的:
在编译状态中,class可以是object对象的父类,自身类,子类。在这三种情况下Java编译时不会报错。
在运行转态中,class可以是object对象的父类,自身类,不能是子类。在前两种情况下result的结果为true,最后一种为false。但是class为子类时编译不会报错。运行结果为false。public class People{ private int a=0; public void eat() { System.out.println("======"+a); } } 子类xiaoming: public class xiaoming extends People { private String name; @Override public void eat() { System.out.println("+++++++++"); } } 主函数 public static void main(String[] args) { People p=new People(); xiaoming x=new xiaoming(); System.out.println(p instanceof Person); System.out.println(p instanceof xiaoming);//结果是false System.out.println(x instanceof Person); System.out.println(x instanceof xiaoming ); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
43. 继承和组合
继承
继承是面向对象的三大特征之一,也是
实现软件复用的重要手段,Java的继承具有单继承的特点,每个类只有一个直接父类,可以有多个间接父类。继承是一种"is-a"的关系。
优点:
代码复用
子类可重写父类的方法
创建子类对象时,无需创建父类的对象,子类自动拥有父类的成员变量和方法。
子类在父类的基础上可根据自己的业务需求扩展,新增属性和方法
缺点:
破坏封装
封装:通过公有化方法访问私有化属性,使得数据不容易被任意窜改,常用private修饰属性;
继承:通过子类继承父类从而获得父类的属性和方法,正常情况下,用protected修饰属性,专门用于给子类继承的,权限一般在本包下和子类里;
继承破坏了封装:是因为属性的访问修饰符被修改,使得属性在本包和子类里可以任意修改属性的数据,数据的安全性从而得不到保障。
如下例子中父类Fruit中有成员变量weight。Apple继承了Fruit之后,Apple可直接操作Fruit类的成员变量,因此破坏了封装性!public class Fruit { //成员变量 // private double weight;为了让子类继承,改为了: protected double weight; public void info(){ System.out.println("我是一个水果!重" + weight + "g!"); } } /** * 继承--子类 */ public class Apple extends Fruit { public static void main(String[] args){ Apple a = new Apple(); a.weight = 10; a.info(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
支持扩展,但往往以增加复杂度为代价
不支持动态继承,在运行时,子类无法选择不同的父类
紧耦合
当子类继承了父类,需要修改父类接口名称时,修改了接口名称,子类都会报错,如果是同一个人维护,可能还可以修改,如果由多个人修改,后果不敢想象呀!组合
什么是组合? 组合在代码中如何体现呢?如下:
public class Animal { public void breath(){ System.out.println("呼吸中..."); } } /** * 组合 */ public class Bird { //将Animal作为Bird的成员变量 private Animal a; public Bird(Animal a){ this.a = a; } public void breath(){ a.breath(); } public void fly(){ System.out.println("我在飞.."); } public static void main(String[] args){ Animal animal = new Animal(); Bird b = new Bird(animal); b.breath(); b.fly(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
优点
不破坏封装,松耦合
具有可扩展性
支持动态组合
缺点
整体类不能自动获得和局部类同样的接口组合对比继承
继承结构,子类可以获得父类内部实现细节,破坏封装。组合结构:整体不能看到部分的内部实现细节,不会破坏封装
继承模式是单继承,不支持动态继承,组合模式可以支持动态组合
继承结构中,子类可以回溯父类,直到Object类,这样就可以根据业务实现多态(向上转型和向下转型) ,组合中不可以实现多态
在开发过程中,如果复用的部分不会改变,为了安全性和封装的本质,应该使用组合,当我们不仅需要复用,而且还可能要重写或扩展,则应该使用继承如何选择?
两个类之间,明显的存在整体和部分的关系,则应该使用组合来实现复用,当我们需要对已有类做一番改造,从而得到新的符合需求的类,则应该使用继承
当需要被复用的类一定不会改变时,应该使用组合,否则,应该使用继承44.初始化块
45. 包装类
46. tostring.方法、==和 equals方法
47. 单例模式
48. finale关键字
49.抽象类
50. 接口
51.内部类(上)
52.内部类(下)
53.枚举类型
54. JAR文件
55. 控制台程序实现与用户互动的方法
56. 系统相关的类之 System类
57.系统相关的类之 Runtime类
58. Object类
59.常用接口之 comparable和 Comparator
60. Objects类
61. String、StringBuilder和StringBuffer
62. Math类
63. BigDecimal类
64. 日期时间类
65. 正则表达式
66.国际化
67. 集合
68. 泛型
69. 注解
70. 异常类
后记:eclipse设置自动提示的一个小技巧
本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/小小林熬夜学编程/article/detail/261604推荐阅读相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

