
热门标签
热门文章
- 1小程序 getphonenumber_小程序入门,看这一篇就够了!
- 2android 与地图互动,高德、百度和腾讯三家比拼,哪个 Android 车机地图 App 更好用?...
- 3there is no source code available for the current location的解决方法_there is no source code for the current location
- 4【区块链】区块链技术:起源、发展、重点技术、应用场景与未来演进
- 5bianliang
- 6A Dual Weighting Label Assignment Scheme for Object Detection
- 7快速理清Paxos、Zab、Raft协议_zab paxos
- 8ThreadLocal源码分析---ThreadLocalMap中的Entry_threadlocal entry
- 9【无人机编队】基于二阶一致性实现无领导多无人机协同编队控制附matlab仿真_无人机集群协同控制仿真
- 10宇芯基于全志平台 成功移植arm ubuntu 桌面系统!!_全志ubuntu18.04旋转
当前位置: article > 正文
python 排序与自定义排序:列表、字典、dataframe_python列表自定义排序
作者:小小林熬夜学编程 | 2024-03-18 09:09:46
赞
踩
python列表自定义排序
一、列表 list --> sort()
1.1 升序、降序 reverse
list_ = ['Facebook', 'Google','Wechat', 'Baidu', 'Taobao','Jingdong']
print("原始列表:",list_,"\n")
# 默认排序(升序)
list_.sort()
print("默认排序:",list_)
# 降序,使用参数 reverse=True
list_.sort(reverse=True)
print(" 降序:",list_)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

1.2 自定义排序(使用参数key)
# 1.按照字符串长度排序(降序) # 排序参考: # Facebook --> len(Facebook) = 8 # Google --> len(Google) = 6 # Wechat --> len(Wechat) = 6 # Baidu --> len(Baidu) = 5 # Taobao --> len(Taobao) = 6 # Jingdong --> len(Jingdong) = 8 list_.sort(reverse=True,key=lambda x:len(x)) print("按照字符串长度排序(降序):",list_) # 2.按照第二个字母排序(升序) # 排序参考: # Facebook --> a # Google --> o # Wechat --> e # Baidu --> a # Taobao --> a # Jingdong --> i list_.sort(key=lambda x:x[1]) print("按照第二个字母排序(升序):",list_) # 3.不排序,但要使用sort函数(为了更直观地介绍参数key的用法) # 排序参考: # Facebook --> 1 # Google --> 1 # Wechat --> 1 # Baidu --> 1 # Taobao --> 1 # Jingdong --> 1 list_ = ['Facebook', 'Google','Wechat', 'Baidu', 'Taobao','Jingdong'] list_.sort(key=lambda x:1) # 此时匿名函数lambda返回一个常量,排序则根据该常量进行判断 print(" 不排序,但要使用sort函数:",list_) # 4.指定顺序:['Taobao','Jingdong','Baidu','Wechat','Facebook', 'Google'] MySortList = ['Taobao','Jingdong','Baidu','Wechat','Facebook', 'Google'] MySortDict = dict([[i,MySortList.index(i)] for i in MySortList]) list_.sort(key=lambda x:MySortDict[x]) print(" 指定顺序:",list_)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39

二、字典 dict --> sorted
- sorted() 同样可以作用于列表,且两者参数类似
- list.sort() == sorted(list)
- 同样,sort()可以适用于字典
dict_ = { '斗罗大陆': '小舞', '斗破苍穹': "云韵", '狐妖小红娘': '涂山雅雅', '天行九歌': '焰灵姬', } print(" 原始字典:",dict_,'\n') print("直接排序(默认按key值):",sorted(dict_)) print(" 按values排序:",sorted(dict_.values())) print(" 按键值对排序:",sorted(dict_.items())) ################################## 自定义排序(使用参数key) ################################## # 按 values 长度排序 # 排序参考: # 斗罗大陆 --> len(小舞) = 2 # 斗破苍穹 --> len(云韵) = 2 # 狐妖小红娘 --> len(涂山雅雅) = 4 # 天行九歌 --> len(焰灵姬) = 3 print(" 按 values 长度排序:",sorted(dict_.items(),key=lambda x:len(x[1])))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20

三、Dataframe 排序
- 创建一个dataframe
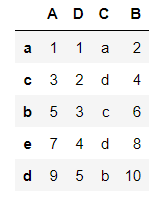
import pandas as pd
df = pd.DataFrame(
{
"A":[1,3,5,7,9],
"D":[1,2,3,4,5],
"C":['a','d','c','d','b'],
"B":[2,4,6,8,10]
},
index=list("acbed")
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3.1 索引排序 sort_index()
- 参数解析
sort_index(
axis = 0, # 0按照行名;1按照列名
level = None, # 默认None,否则按照给定的level顺序排列
ascending = True, # 默认True升序;False降序
inplace = False, # 默认False,否则排序之后的数据直接替换原来的dataframe
kind = 'quicksort', # 排序方法,{'quicksort','mergesort','heapsort'},默认'quicksort'。(似乎不用太关心)
na_position = 'last', # 缺失值默认排在最后{'first','last'}
sort_remaining = True, # ************
by = None # 按照某一列或几列数据进行排序,这里by参数不建议使用
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 针对 index 排序(行)
df.sort_index(
axis = 0, # 默认 index
ascending = True, # 升序
)
- 1
- 2
- 3
- 4

- 针对 columns 排序(列)
df.sort_index(
axis = 1, # 1代表针对columns
ascending = True, # 升序
)
- 1
- 2
- 3
- 4

3.2 值排序 sort_values()
- 参数解析
sort_values(
by = [columns], # 参考排序的列
axis = 0, # 0按照行名;1按照列名
ascending = True, # 布尔型,True则升序,如果by=['列名1','列名2'],则该参数可以是[True, False],即第一字段升序,第二个降序。
inplace = False, # 默认False,否则排序之后的数据直接替换原来的dataframe
kind = 'quicksort', # 排序方法,{'quicksort','mergesort','heapsort'},默认'quicksort'。(似乎不用太关心)
na_position = 'last' # 缺失值的位置{'first','last'}
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 针对C列进行升序的基础上再对D列进行降序
- 即在C列有相同值的情况下,D列进行降序
df.sort_values(by=['C','D'],ascending=[True,False])
- 1

3.3 dataframe 自定义排序
- 加载库 CategoricalDtype
from pandas.api.types import CategoricalDtype
- 1
3.3.1 单变量自定义排序
- 针对C列
c_sort = CategoricalDtype(
['a','d','c'], # 列表以外的值都会变为 NaN
ordered=True # [布尔值]如果为false,则将类别视为无序。
)
df['C'] = df['C'].astype(c_sort)
df.sort_values(by=['C'])
- 1
- 2
- 3
- 4
- 5
- 6

3.3.2 多变量自定义排序
- 针对B、C列
cat_B = CategoricalDtype(
[8,4], # 列表以外的值都会变为 NaN
ordered=True # [布尔值]如果为false,则将类别视为无序。
)
cat_C = CategoricalDtype(
['a','d','c'], # 列表以外的值都会变为 NaN
ordered=True # [布尔值]如果为false,则将类别视为无序。
)
df['B'] = df['B'].astype(cat_B)
df['C'] = df['C'].astype(cat_C)
df.sort_values(by=['C','B'])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小小林熬夜学编程/article/detail/261929
推荐阅读
相关标签

