
热门标签
热门文章
- 1通过PLSQL创建Database link,DBMS_Job,Procedure,实现Oracle跨库传输数据
- 2mac装双系统是启动分期磁盘报错:拷贝windows安装文件出错。_macbook装双系统报错“拷贝windows安装文件时失败”
- 3Chromium浏览器media子系统mojo说明_chrome mojo
- 4Python 缓冲区
- 5C++ 可赋参数的函数对象 004:函数对象的过滤器 005:白给的list排序_struct a { int v; a() {} a(int n) : v(n) {} bool o
- 6OpenStack 清理镜像时报错407和409的问题解决_the image cannot be deleted because it is in use t
- 7超详细Django+vue+vscode前后端分离搭建_vscode django vue
- 8oracle分页怎么查询,oracle简单查询之分页查询
- 9如何用C#操纵IIS
- 10这个牛逼的Python模块,能让你轻松模拟并记录键盘操作(附零基础学习资料)_python模拟键盘操作
当前位置: article > 正文
深度学习各子领域略览及术语列表_深度学习stemming
作者:小小林熬夜学编程 | 2024-03-22 05:27:00
赞
踩
深度学习stemming
有些内容附带了相应的超链接作为可参考资料,有些没有。很多内容可以参考我的其他博文,其中有一部分链接我也会挂到这里来。
正文
感觉不是MECE的分类,但是算了差不多就这样,建议用Ctrl+F
1. ML基础
- 有监督supervised / 无监督unsupervised / 半监督semi-supervised(弱监督) / 自监督self-supervised
有监督:有标签
无监督:没有标签
半监督:有一部分标签,对未标注的样本生成伪标签
自监督1:没有人工标注的标签,但是我们从数据本身中挖掘出标签,然后用有监督的方法来对其进行学习(如mask掉文本中的部分token) - 分类
- 多分类multi-class
- 多标签multi-label
- 极限多标签文本分类XMTC(NLP课题入门 | 极限多标签文本分类 NLP课题入门 | 极限多标签文本分类 NLP课题入门 | 极限多标签文本分类)
- 情感分析
我说这是NLP界最火(指最卷)的研究课题,应该没什么问题吧- aspect-based sentiment analysis (ABSA) 基于方面的情感分析

对这一课题的介绍和图片来源:方面情感分析-Recurrent Attention Network - 知乎
- aspect-based sentiment analysis (ABSA) 基于方面的情感分析
- 虚假新闻检测(NLP课题入门 day 4 虚假新闻检测)
- 异常检测anomaly detection
- 回归
- Generalized Linear Models (GLMs)
- Generalized Additive Models (GAMs)
- 线性回归模型
- 多重共线性
- 向前选择法forward selection
向前选择法_百度百科
- 结构化学习:输出结果是结构化的对象(序列、树、图等)
- 概率图模型
玻尔兹曼机
深度信念网络 - 排序rank
感觉推荐系统、搜索引擎、信息抽取/检索方面会用得比较多- 指标
Ranking算法评测指标之 CG、DCG、NDCG - 知乎- CG
- DCG
- NDCG
- 指标
- 特征工程 特征工程/数据预处理超全面总结(持续更新ing…)
- generative生成式 / discrimination判别式模型
可以参考这篇小红书笔记: - 支持向量机SVM
- K近邻分类KNN
- 多标签分类的模型
- 对于标签数的选择:要么直接设定一个超参(top-k),要么设定概率阈值,要么将所有标签分别作为一个二分类任务、然后设定二分类的概率阈值,要么专门做一次number learning任务(一层神经网络)
基于法条外部知识的法条推荐这篇用多种表征来进行二分类,缓解阈值选取造成的性能损失 - Label Powerset:非常直觉的……直接把多标签重新组合成多分类任务的标签集(暴力出奇迹)
- ML-KNN
数据科学实战系列之ML-KNN(一)_mlknn_明曦君的博客-CSDN博客
- 对于标签数的选择:要么直接设定一个超参(top-k),要么设定概率阈值,要么将所有标签分别作为一个二分类任务、然后设定二分类的概率阈值,要么专门做一次number learning任务(一层神经网络)
- graphical model
- 隐马尔科夫模型HMM
- 条件随机场CRF)
- 朴素贝叶斯Naive Bayesian分类器 (NBC)
- 关联规则
- 粒子优化算法PSO
- 损失函数可参考这篇:机器学习/深度学习中的常用损失函数公式、原理与代码实践(持续更新ing…)
- 留一法 / leave one out (LOO)
- 模型融合model fusion
深度学习中一般有以下几种方式:
同样的参数,不同的初始化方式。
不同的参数,通过cross-validation,选取最好的几组
同样的参数,模型训练的不同阶段,即不同迭代次数的模型
不同的模型,进行线性融合,例如RNN和传统模型
提高模型性能和鲁棒性大法:probs融合 和 投票法

- stacking:将数据分成N折,每个基模型学习其中N-1折数据
- bagging
- boosting
- GBDT
- 随机森林
- XGBoost
- LightGBM
- CatBoost
- 难例挖掘 hard-negative-mining
分析模型难以预测正确的样本,给出针对性方法。 - 聚类
- K均值K-Means
手肘法:通过SSE骤降的拐点选择K值(目测法) kmeans的手肘法_Petyon的博客-CSDN博客 - 谱聚类 A Tutorial on Spectral Clustering
- K均值K-Means
- 归一化 / 正则化
- 最大最小规范化min-max scalar
- Z Score正则化
- batch normalization
- layer normalization
- dropout(也被认为是传统的神经网络随机删减方法)
- 深度学习中的trick | 先BN后dropout:同时使用有争议
- DropConnect:就不是将层输入随机置0,而是直接随机将权重元素置0
DropConnect Explained | Papers With Code
- 数据不平衡问题imbalance
- FLOPs:注意s小写,是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。
1 MFLOPs(mega) = 10^6 FLOPs,即:100万次浮点运算
1 GFLOPs(giga) = 10^9 FLOPs,即:10亿次浮点运算
1 TFLOPs(tera) = 10^12 FLOPs,即:1万亿次浮点运算2
2. DL通用基础
- 全连接前馈神经网络FFNN / 多层感知机MLP
- 卷积神经网络CNN
- 循环神经网络RNN RNN(包括GRU和LSTM)和其他seq2seq/encoder-decoder模型
- 回声状态网络 (echo state network,ESN)
- SAE
- 孪生神经网络Siamese network3:构建2个相同的网络,计算嵌入之间的距离,使得相似输入的嵌入相似(总之是个比较类似于对比学习的思路)
如果不相似输入的嵌入仍然相似,就叫塌陷(collapse) - 置信度传播belief propagation
- 残差网络residual network (ResNet)
identity mapping: 论文阅读之identity mapping_Teague_DZ的博客-CSDN博客_identity mapping - n-gram
- token
- 池化
- 表示学习
- 误差传播
- 耦合 / 解耦
- 剪枝
- 知识蒸馏knowledge distillation
- 优化optimization
- 凸优化convex optimization
- 梯度下降
- 随机梯度下降SGD (Stochastic Gradient Descent)
- NT-ASGD Explained | Papers With Code
- 反向传播back propagation (BP)
- 学习率learning rate
- weight decay
- momentum
- Adam
- 余弦退火(cosine annealing)和热重启的随机梯度下降
- NT-ASGD
- EM(变分推断(variational inference)/variational EM)
- NeurIPS 2022上Geoffrey Hinton提出了一种超神奇的、不用反向传播的前向-前向传播的训练方式:
The Forward-Forward Algorithm: Some Preliminary Investigations
反正这个东西大意呢就是说,不用反向传播,而是直接进行两次前向传播(一次用正样本,一次用负样本),直接调整权值(具体算法我没看懂),这样的优势有很多啊,比如模型不可微、或者模型是黑盒的时候,这样就也能计算权值了……
总之我觉得可能是一些RL不够persuasive的场合下能给RL一个灭顶之灾的搞法。
然后2023年就有把这个东西用在GNN上的工作了(你们是真的快啊,别跟我讲2023年你能连综述都搞出来哈):Graph Neural Networks Go Forward-Forward - 其他不用反向传播的工作,还没看具体是咋干的所以不好分类:
(2022 ICDM) Backpropagation-free Graph Neural Networks - 蚁群优化算法Ant Colony Optimization (ACO)
- 萤火虫算法firefly algorithm
- 随机启发式无导数优化方法
- Dragon fly Optimization - GeeksforGeeks
- AutoML
- Angel-ML/angel: A Flexible and Powerful Parameter Server for large-scale machine learning
- PKU-DAIR/mindware: An efficient open-source AutoML system for automating machine learning lifecycle, including feature engineering, neural architecture search, and hyper-parameter tuning.
- PKU-DAIR/open-box: Generalized and Efficient Blackbox Optimization System [SIGKDD’21].
- 神经网络结构搜索NAS
大概来说就是不再由人工设置超参,而是直接给定一个搜索空间search space(一堆模型结构组成的空间),然后让模型自己根据模型优化结果来学它应该长成什么结构。
比较容易联想到ML中传统的网格搜索之类的。DL之所以一般不那么干就是因为那样时间久嘛(我以前做小图GNN的时候,因为跑得快,所以也上网格搜索来着,直到我后来来做了NLP……)
神经网络结构搜索(NAS)简介 - 知乎
- adaptive(加可训练的参数,比如线性转换之类的) / non-adaptive(平均值、最大值etc)
- attention(你给我解释解释,什么TMD叫TMD attention(持续更新ing…))
- transformers(Transformer/Bert)
- 小样本学习few-shot learning(N-way/shot就表示每类能看到几个训练集样本)
- 零样本学习zero-shot learning
- 数据漂移data shift
机器学习中的数据漂移问题 - 哔哩哔哩 - 关系学习relational learning(relational learning关系学习)
- 度量学习metric learning
- 对比学习contrastive learning
参考我写的另一篇博文:对比学习(持续更新ing…) - consistency learning:意思是对数据做微小扰动后,应该使其预测结果不变(呃感觉听起来跟对比学习很像啊)
【半监督】半监督方法中的Consistency learning - 知乎:只看了概念部分。实例部分咔咔一上来全是CV,看不懂! - 数据增强data augmentation
- CV中常用的:随机裁剪,图像反转,图像缩放
- NLP中常用的
- 回译
- 生成(问就是ChatGPT):近义词替换,embedding相近词替换,句子shuffle
- 文本对抗
- TextFooler(单词重要性排序,单词替换模型)4
- 数据抽样sampling
- 对抗攻击
- 对抗防御
- 推荐系统recommendation system
- 协同过滤
- 冷启动问题cold-start problem
- CTR
- uplift:一个活动做不做能带来多大的改变
two-learner: 大概来说就是通过对照试验,分别建模,这样对每一个新的用户,就能通过2估计一个活动做不做能带来多大的改变5
- 黑盒模型 / 白盒模型
- 可解释性explainbility
- attention
- 隐藏层(这个感觉CV那边会用得多一点,毕竟NLP的话……你都不连续了,谁知道你是个啥啊)
- rationale:大概就是从原文中抽取出一部分内容,作为解释原因
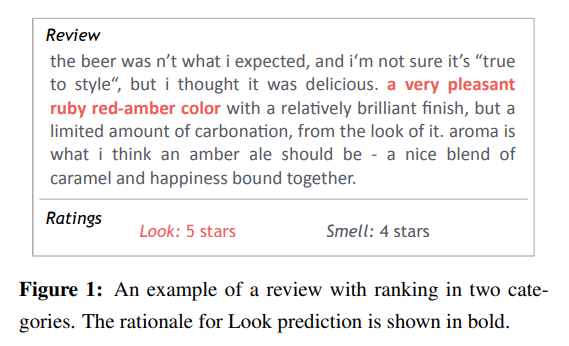
图源:Rationalizing Neural Predictions - 加一个中间任务:抽取特征(感觉上就像是把机器学习的逻辑用深度学习做一遍)
- SHAP
不再黑盒,机器学习解释利器:SHAP原理及实战 - 知乎 看这篇文章的介绍,shapley value(沙普利值) 应该是算每一个特征维度对结果的边际贡献。中间的原理巴拉巴拉的都没看。
- 鲁棒性robustness
- 贡献度分配问题(Credit Assignment Problem,CAP)6
- auto-encoder
- latent-variable predictive architectures
 7
7 - GAN
- 联邦学习federated learning
- 差分隐私differential privacy
- 多任务学习multi-task learning:就是在训练多种任务时共用一部分模型参数
多目标优化:(这部分我是真的没看懂啊,以后慢慢看吧)- 帕累托最优
一篇用MGDA实现帕累托优化的paper,博文可参考:深度学习中的trick | day 14 | 多任务学习 - borg 算法
- NSGA-II算法
- 遗传算法
- 进化算法
- metaheuristic 元启发式方法。一些随机搜索算法诸如进化算法、蚁群算法、粒子群算法这类具有启发式框架的智能算法称为元启发式算法。8
- 帕累托最优
- 强化学习reinforcement learning
Autonomous reinforcement learning on raw visual input data in a real world application
Self-critical Sequence Training for Image Captioning- sequential decision-making problems
- valuebased models
- policy-based models
- 策略梯度方法
- Q-learning
- Actor-Critic framework(策略policy函数-生成动作-环境交互,价值函数)
- asynchronous advantage actorcritic (A3C) algorithm:强化学习算法的训练方法
Asynchronous Methods for Deep Reinforcement Learning - RLHF(最近应该是因ChatGPT而比较出名)
- imitation learning
- 模型量化quantization9
- 模型加速
- 分布式训练
- 数据并行
- 模型并行
- 用cpp写代码10
- OpenNMT的加速推理引擎:
- 分布式训练
- 灾难性遗忘Catastrophic Forgetting
- 迁移学习transfer learning
Jindong Wang | Book- 差分学习率:在不同的层设置不同的学习率,可以提高神经网络的训练效果
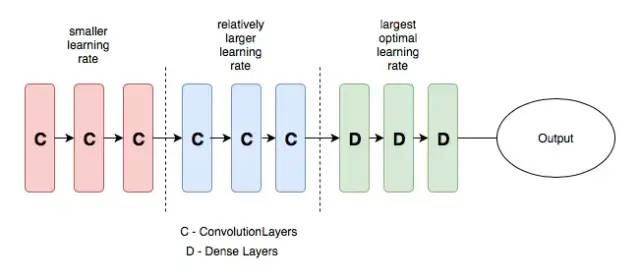 11
11
- 差分学习率:在不同的层设置不同的学习率,可以提高神经网络的训练效果
- lifelong learning / continuous learning / never ending learning / 增量学习incremental learning:学习新的任务,并保持对以前任务的预测指标
- 课程学习Curriculum Learning (CL):安排任务的学习顺序
the process of ANN training in which samples are used in a meaningful order,把数据分批丢进去学习,或者先学所有数据集,然后逐渐减少样本12 - Taskonomy:(感觉跟上一个差不多,我有点懵了)
- 2020机器学习前沿技术----LifeLong learning - 知乎
- 课程学习Curriculum Learning (CL):安排任务的学习顺序
- 主动学习active learning (AL):通过选择性的标记较少数据而训练出表现较好的模型
- 遗传编程/基因规划 Genetic Programming
- 上下文学习in-context learning (ICL):看起来意思就是用相关样本来预测目标样本。
直接这么说有点像transductive learning,但看示例似乎其实是prompt,就是给模型提供几个示例样本,然后让模型进行预测。- 上下文学习(in-context learning),检索和OOD外推 - 知乎
- A Survey for In-context Learning
- Larger language models do in-context learning differently:这篇认为只有大模型才会做in-context learning,给出错误答案后效果会下降,但如果给出与正确答案一样分布的错误答案,则不会下降太多,说明大模型能学到问题与答案之间的映射关系
In-context learning只对大模型有效! - In-Context Learning中的示例选择及效果
- i.i.d. / out-of-distribution (OOD)
- OOD detection
- 基于分类模型的方法
- 基于生成模型的方法
- Energy-based Out-of-distribution Detection
- online learning
- 领域自适应
- 元学习meta-learning
- 捷径学习shortcut learning
- 解耦学习
- 因果推理
- 反事实学习counterfactual learning
反事实解释(Counterfactual Explanation, CE) - 知乎
- 反事实学习counterfactual learning
- AI伦理问题
- AI公平性问题
这个我可能以后也会专门出个专题来写,现在先把收集到的资料整理到这里 - Ethics consideration sections in natural language processing papers
- AI公平性问题
- 多模态multi-modal
- label embedding
- label smoothing
- 几何深度学习
Geometric deep learning: going beyond Euclidean data
几何深度学习从古希腊到AlphaFold,图神经网络起源于物理与化学:这一篇感觉就是先讲了讲深度学习,然后介绍了图论、化学式、图神经网络 - symbolic AI
- Neural-Symbolic Integration13
- 反绎学习abductive learning (ABL)14
大概来说是生成伪标签,然后用逻辑推理进行修正,再重新训练分类器,反复迭代,直至分类器不再更新或标签与逻辑统一 - Human-level concept learning through probabilistic program induction
- 自动定理证明Automated Theorem Proving
就是让模型证明数学定理 - dual learning对偶学习
- 城市计算urban computing:感觉大概来说就是搞“智慧城市”
群体感知
城市计算概述(introduction to urban computing) 笔记 - 知乎 这篇讲的是这篇paper:Introduction to Urban Computing - AI+X
3. 主要用于NLP的DL基础
- OOV (out of vocabulary)
- 停用词
- 词干化stemming:将英文中所有同一个词的各种形式统一,如stopped, stopping都统一到stop
- 序列标注
常见任务:分词tokenization,短语识别,分句 / 句子边界检测,命名实体识别NER (named entity recognition),词性标注PoS Tagging,实体抽取,关系抽取relation extraction,事件检测/事件抽取,measurement extraction,指代消解coreference resolution
可参考我撰写的另一篇博文:序列标注/信息抽取任务(持续更新ing…) - TF-IDF模型
- 词袋模型BoW
- LDA
LDA原始论文:Latent Dirichlet Allocation - word2vec
- CBOW
- skip-gram
- 句子表征
- 对句子的表示可以分为composion(从词向量到句向量)和distributed(将句子当成一个unit,前后文作为context)
- 自然语言处理中句向量 - 知乎
- Sentence Embedding 现在的 sota 方法是什么? - 知乎
- 预训练语言模型pretrained language model
- 可参考我撰写的这两篇博文:预训练语言模型概述(持续更新ing…) 和 各种预训练模型的理论和调用方式大全
[CLS][SEP][BOS][EOS]
自然语言处理加BOS和EOS的作用是什么? - 知乎- 突现能力
深入理解语言模型的突现能力
137 emergent abilities of large language models — Jason Wei
On Emergent Abilities, Scaling Architectures and Large Language Models — Yi Tay - 思维链chain-of-thought (CoT):大概来说就是让LLM在生成结果前先生成文本形式的推理过程。其实我个人还是觉得这样太简单粗暴了……
Chain of Thought Prompting Elicits Reasoning in Large Language Models
Chain of Thought 开山之作论文详解_qq_42190727的博客-CSDN博客
思维链(Chain-of-Thought, CoT)的开山之作 - 知乎
- 微调finetune
- prompt / 提示学习prompt learning
- bootstraping
- 远程监督distant supervision
认为如果句子中含有一对知识库原本就存在关系的实体,那么这句话大概率表示了这一关系
关系抽取之远程监督算法(Distant Supervision)_Dr.sky_的博客-CSDN博客:这一篇我只主要看了介绍部分,终于看懂远程监督是啥意思了!
Distant supervision for relation extraction without labeled data:远程监督界的开山之作 - cross-view training:感觉意思差不多是说,在有监督的训练方法之外,新增了其他挖空方式(cross-view)来进行训练
- 信息检索information retrieval (IR)15
- 召回-重排rerank
- 文本匹配
- 句子相似度
- 算法:BM25
- NLP基础知识 | 常见任务类型 | 信息检索
- 向量检索/向量相似性计算方法(持续更新ing…)
- ad-hoc检索:集合中的文档相对稳定,query变化很大
routing检索:query要求相对稳定,被查询的文档(数据库)不断变化
ad hoc检索 & routing检索_ad hoc 检索_Mr.DC30的博客-CSDN博客
- 搜索引擎
Sponsored Search付费搜索 - 关键词提取(常用的Python3关键词提取方法)
- 主题分类/抽取
- 文本生成natural language generation (NLG)
- 文本摘要text summarization(可以直接参考我写的博文:文本摘要(text summarization)任务:研究范式,重要模型,评估指标(持续更新ing…))
- 机器翻译machine translation
- paraphrase generation / rephrasing:生成输入文本的同义文本(相当于转述)
- PPT生成
- 问答QA
QA相关我之前写过一个回答,列过一些paper,可供参考:https://www.zhihu.com/question/536413640/answer/2533262058 - 问题生成question generation
- Multiple Choice Question Generation (MCQG)
- 文本风格转换text style transfer(是NLG任务,但不像一般NLG任务是源域与目标域样本一比一匹配的,而是那种(比划)就是一堆对应一堆的那种)
- 文本纠错text correction
- 创新度novelty
- encoder-decoder架构
- seq2seq任务
- BLEU指标
- 自然语言理解NLU / 自然语言推理Natural Language Inferencing (NLI)
一文看懂自然语言理解-NLU(基本概念+实际应用+3种实现方式)
NLU调研 - 给荔枝打气- 蕴含识别entailment / recognizing textual entailment (RTE)
矛盾 (contradiction)、无关 (neutral) 和蕴含 (entailment)- SAN:多步推理(RNN+记忆机制)
用于自然语言推理的随机答案网络 - 知乎 Stochastic Answer Networks for Natural Language Inference
- SAN:多步推理(RNN+记忆机制)
- 意图识别/检测(NLP课题入门 | day 14 | 意图分类)
在搜索场景下的应用可参考这篇博文:R&S[25] | 搜索中的意图识别 - 槽填充slot filling(NLP基础知识 | 常见任务类型 | 槽填充 NLP课题入门 | day 15 | 槽填充)

开放域/域外意图检测 - Text-to-SQL
- 蕴含识别entailment / recognizing textual entailment (RTE)
- Spoken Language Understanding (SLU)
- 阅读理解Machine Reading Comprehension (MRC)
- 讽刺检测sarcasm detection(NLP课题入门 | day 9 | 讽刺检测)
- 抄袭检测plagiarism detection
A Review of Machine Learning based Plagiarism Detection Approaches - 跨语言cross-language
- emotional recogniton
- semantic relatedness (SR)
根据上下文或语义相似性量化两个unit(词汇/句子/概念)之间的关系16

比如这个例子中,第一对句子比第二对句子相关性更高 - decontectualization:大致来说就是把文中的一句话单拎出来进行修改,补全该句所需的上下文,表示原句意。说来复杂总之可以参考:为什么每次有人大声通电话时,我就很烦躁…_51CTO博客_有人大声说话就烦躁
- language detection
- 这篇工作上次更新代码已是5年前,上次回复issue已是2020年,所以感觉不太维护了:saffsd/langid.py: Stand-alone language identification system
- 语义标记semantic markup:标注语义/内容相关的信息,举个栗子就像这样:

(图源Semantic mark-up of Italian legal texts through NLP-based techniques)
参考资料: - 论点挖掘argument mining
论点挖掘小技巧-CSDN博客 - 语义表示
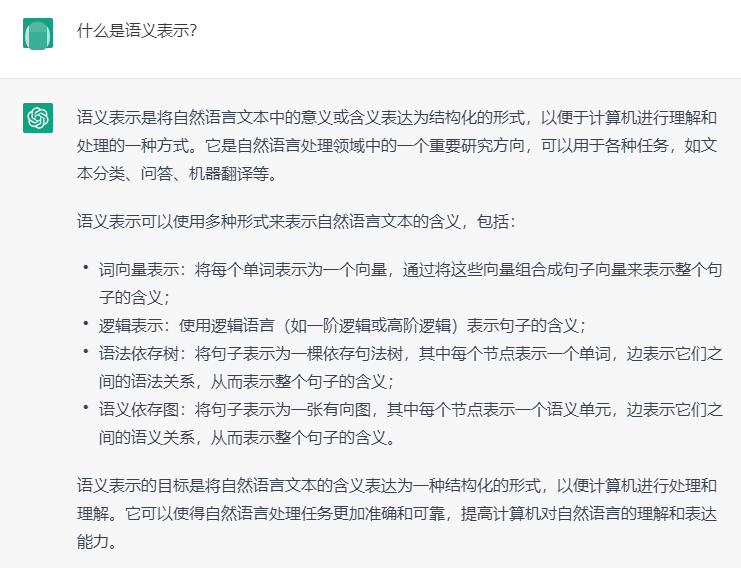
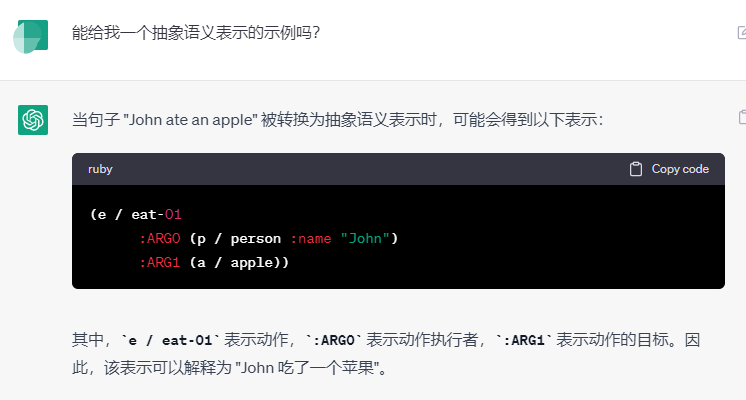
- 抽象语义表示Abstract Meaning Representation (AMR):使用单根有向无环图,来表示一个句子的语义结构,其中词抽象为概念节点(Node),词之间的语义关系抽象为带有语义角色标签的有向弧(Arc)

GoThereGit/Chinese-AMR: Chinese AMR Corpus
- 抽象语义表示Abstract Meaning Representation (AMR):使用单根有向无环图,来表示一个句子的语义结构,其中词抽象为概念节点(Node),词之间的语义关系抽象为带有语义角色标签的有向弧(Arc)
- 框架语义学frame semantics

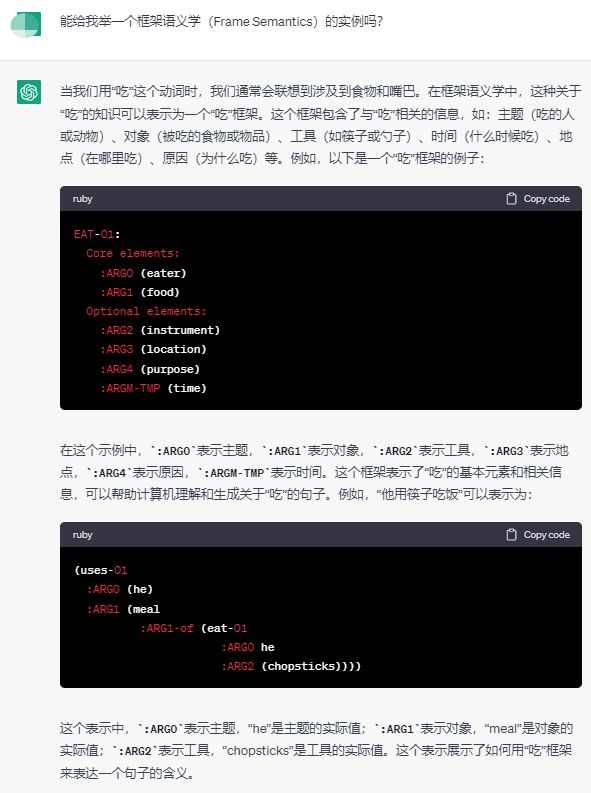
- 框架语义解析(Frame Semantic Parsing,FSP)是自然语言处理领域中的一项重要任务,其目标是从句中提取框架语义结构,实现对句子中涉及到的事件或情境的深层理解
- 空间语义理解

- 潜在语义索引latent semantic indexing (LSI)

- claim verification:根据文档(document)验证声明(claim)的准确性,进行supported(支持),refuted(驳斥),NEI(信息不足)三分类17
- 词汇替换任务(lexical substitution)是自然语言处理(NLP)领域的一个任务,其目标是在给定的语境中不改变句子含义的情况下,用替代词替换句子中的目标词。
词汇替换任务在许多 NLP 应用中都有重要作用,例如:
词汇简化:将复杂的词汇替换为简单的词汇,以提高文本的可读性和理解度。例如,将“automobile”替换为“car”。
词义消歧:在多义词的语境中,选择合适的词义。例如,在“The dog chased the cat”中,将“chase”的词义解释为“追逐”。
摘要生成:将长文本摘要为短文本,其中可能需要替换一些词汇。例如,将“The dog is a loyal animal”替换为“Dogs are loyal animals”。
词汇替换任务通常分为两类:
基于规则的词汇替换:使用人工定义的规则来替换目标词。例如,可以使用同义词表来替换词汇。
基于机器学习的词汇替换:使用机器学习模型来学习替换目标词的策略。例如,可以使用神经网络来学习替换目标词的语义相似度。
基于规则的词汇替换方法简单易行,但其效果通常不如基于机器学习的方法。基于机器学习的方法可以学习到更复杂的替换策略,但其训练成本通常较高。
以下是一些词汇替换任务的例子:
将“The dog chased the cat”中的“dog”替换为“puppy”。
将“The man is driving a car”中的“car”替换为“automobile”。
将“The meeting will be held at 9:00 AM”中的“AM”替换为“in the morning”。 - 程序语言处理PLP (programming language processing)
- program representation
- algorithm detection
- LegalAI:准备专门写一篇,等等吧
- 语言学上的一些概念
- 计算语言学CL (Computational Linguistics)
- 齐夫定律 - 维基百科,自由的百科全书:在自然语言的语料库里,一个单词出现的频率与它在频率表里的排名成反比
- 同指关系referentiality:指称同一对象的不同词之间的意义关系。指称同一对象的这些词可能同义,也可能异义。例如“老虎”“於菟”“百兽之王”都可指称虎。18
- surface form:词语本身的表现形式19
- 量子自然语言处理QNLP (Quantum Natural Language Processing)
量子+AI:自然语言处理 - 腾讯云开发者社区-腾讯云
GitHub - ICHEC/QNLP: ICHEC Quantum natural language processing (QNLP) toolkit
4. GNN和图论
- transductive learning / inductive learning
直推 / 归纳(这两个词的翻译真的很诡异)
如何理解 inductive learning 与 transductive learning? - 知乎 - 图的表示:
定义一(图)
定义二(图的邻接矩阵) - 图的属性:
定义三(结点的度,degree)
定义四(邻接结点,neighbors)
定义五(行走,walk)
定理六(行走的个数)
定义七(路径,path)
定义八(子图,subgraph)
定义九(连通分量,connected component)
定义十(连通图,connected graph)
定义十一(最短路径,shortest path)
定义十二(直径,diameter)
定义十三(拉普拉斯矩阵,Laplacian Matrix)
定义十四(对称归一化的拉普拉斯矩阵,Symmetric normalized Laplacian) - 节点分类
- 典型任务
- 生物医药领域:药物发现drug discovery,蛋白质结构预测protein structure prediction20
- 典型任务
- 链路预测(图学习中的链路预测任务(持续更新ing…))
- 图分类
- 图着色graph coloring
- clique是一个点集,在一个无向图中,这个点集中任意两个不同的点之间都是相连的。maximal clique是一个clique,这个clique不可以再加入任何一个新的结点构成新的clique
- graph summarization
A Survey on Graph Neural Networks for Graph Summarization - 子图学习
- subgraph neural networks / subgraph mining(NLP课题入门 | day 20)
- 对于同质图节点表征模型,我专门另外写了一个博文,可作参考:各种同质图神经网络模型的理论和节点表征学习任务的集合包rgb_experiment
- 图扩散卷积graph diffusion convolution (GDC)(仅适用于同配图):怎么说呢,感觉就是用PPR之类的扩散方法重新构建出了一个新图
Diffusion improves graph learning
gasteigerjo/gdc: Graph Diffusion Convolution, as proposed in “Diffusion Improves Graph Learning” (NeurIPS 2019)
原博文:Graph Diffusion Convolution - MSRM Blog
中文翻译:图扩散卷积:Graph_Diffusion_Convolution_jialonghao的博客-CSDN博客_图扩散 - 二分图bipartite graph
(2023 Social Network Analysis and Mining) A survey on bipartite graphs embedding - 异质图神经网络HGNN(异质图神经网络(持续更新ing…))
- metapath
- meta-graph
- metapath-based neighborhood
- meta-path neighbor graph / metapath-based graph
- network schema
- metapath及其相关概念(持续更新ing…)
- 动态图神经网络
- 概念:图信息会根据时间进行改变(改变节点特征→比如修改论文内容,改变边→比如增加好友关系)
动态网络(dynamic network)和时态网络(temporal network)有区别吗? - 知乎:感觉结论是没有区别 - 工具包
- 概念:图信息会根据时间进行改变(改变节点特征→比如修改论文内容,改变边→比如增加好友关系)
- multiplex network:大概就是说,同样的节点,但是有多种不同的组边方式(只有1种节点,但是有多种边的异质图)
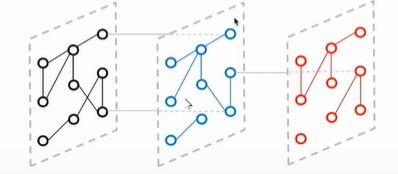
(图源:Graph Representation Learning 笔记 Ch1&Ch2(未读))
Representation learning for attributed multiplex heterogeneous network - hyperbolic
- graph un-learning:理念是从模型中去掉已学习的部分训练集(想要保护隐私,所以要删除指定用户数据,这种scenario)
(2023 ICLR) GNNDelete: A General Strategy for Unlearning in Graph Neural Networks
(2023 NDSS) Unlearnable Graph: Protecting Graphs from Unauthorized Exploitation:这篇更进一步,直接让模型原本的整个图都不能学了 - 图结构学习graph structure learning (GSL):学习节点表示的同时,学习更合适的图结构
论文笔记:A Survey on Graph Structure Learning: Progress and Opportunities - 知乎 - GNN+NLP
- GNN以文本作为特征
- 直接解耦或端到端训练BERT+GNN
- (2022 ICLR) Node Feature Extraction by Self-Supervised Multi-scale Neighborhood Prediction:GIANT模型
首先用预测图结构(预测一个节点的邻居,在图上是链路预测任务,但用extreme多标签分类的范式进行学习)的自监督学习任务来构建文本表征模型,然后再对文本进行表征,然后再用GNN进行表征。
文本表征模型用的是XR-Transformers,将节点邻居的跳数视作文本分类的层级 - (2022 KAIS) Embedding text-rich graph neural networks with sequence and topical semantic structures
联合训练图表征和文本表征(利用文本中的图结构) - (2023 ICLR) Learning on Large-scale Text-attributed Graphs via Variational Inference
用EM算法分别更新LLM和GNN - (2023) SimTeG: A Frustratingly Simple Approach Improves Textual Graph Learning
直接在下游任务上对LLM做PEFT,用last hidden state做节点表征,然后用GNN学习下游任务。
- GNN Transformer
(2022 NeurIPS) Recipe for a General, Powerful, Scalable Graph Transformer
GraphGPS包:rampasek/GraphGPS: Recipe for a General, Powerful, Scalable Graph Transformer
(2023) Attending to Graph Transformers
- GNN以文本作为特征
- AutoGraph:这个我主要是听过一位北大博士给我们实验室讲的talk。我自己不是做这个的,所以只在此简单罗列。对slides或者相关专业人士有需求的可以联系我,我再去帮你找人。
补充知识点:GNN算子可以分为propagate(P)和transform(T)
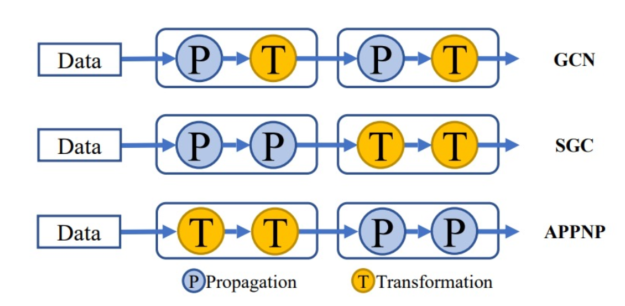
- G-NAS:PT的pipeline(模式和深度)是固定的
GraphNAS Graph Neural Architecture Search
Auto-GNN: Neural Architecture Search of Graph Neural Networks - Model Degradation Hinders Deep Graph Neural Networks:这篇paper考虑了以前工作太浅导致对全图信息的表现力不足,GNN很难做深是个经典问题了,本文这里给出的解释是拉普拉斯平滑(slides这里还有一些相关论文列表,JKNet,SGC,APPNP,DAGNN等,其他略,可以看下面一条的deep GNN工作集锦),主要探讨了P和T两种算子的深度分别对GNN产生的影响
- DFG-NAS: Deep Graph Neural Architecture Search:design space考虑不同的PT顺序、组合和数量,加入门机制、skip connection等
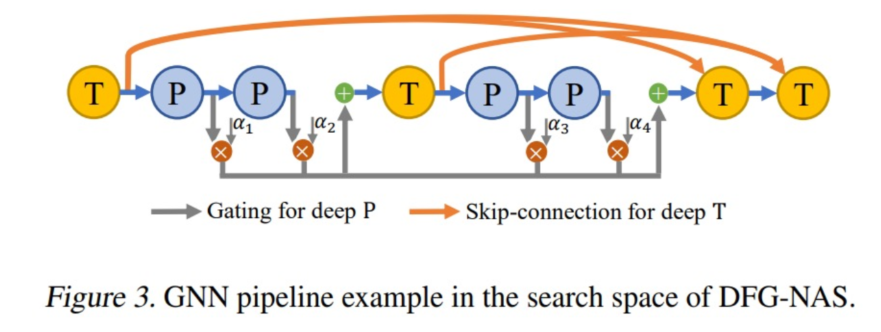
(架构的选择与图的稀疏程度、大小等有关) - PaSca: a Graph Neural Architecture Search System under the Scalable Paradigm:这篇主要考虑信息通讯代价的问题,提升GNN的scalability
PKU-DAIR/SGL: A scalable graph learning toolkit for extremely large graph datasets. (WWW’22, 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小小林熬夜学编程/article/detail/285578
- G-NAS:PT的pipeline(模式和深度)是固定的
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

