- 1人工智能之华为云ModelArts的深度使用体验与AI Gallery应用开发实践_华为的modelarts人工智能应用开发指南
- 2GsonFormat插件使用报错 String index out of range -1_gsonformat报错
- 3java 解析 ical_转载iCalendar 编程基础:了解和使用 iCal4j
- 4小白学Oracle基础知识(一)
- 5<CodeGeeX>基于大模型的全能AI编程助手_大模型代码助手
- 6鸿蒙系统剽窃,外媒再爆猛料!质疑华为鸿蒙系统抄袭:被指山寨谷歌安卓11系统...
- 7Base64图片页面显示_base64图片显示
- 8android 10 , android 11 预置系统应用权限开启分析_预置应用开放所有权限
- 9为什么要使用多GPU并行训练,单卡和多卡训练,bs和lr的关系_多卡训练和单卡训练效果
- 10android 调用另一个类的方法吗,无法从另一个模块调用方法:Android studio
手把手!基于领域预训练和对比学习SimCSE的语义检索(附源码)
赞
踩

之前看到有同学问,希望看一些偏实践,特别是带源码的那种,安排!今天就手把手带大家完成一个基于领域预训练和对比学习SimCSE的语义检索小系统。
所谓语义检索(也称基于向量的检索),是指检索系统不再拘泥于用户 Query 字面本身(例如BM25检索),而是能精准捕捉到用户 Query 后面的真正意图并以此来搜索,从而更准确地向用户返回最符合的结果。
最终可视化demo如下,一方面可以获取文本的向量表示;另一方面可以做文本检索,即得到输入Query的top-K相关文档!
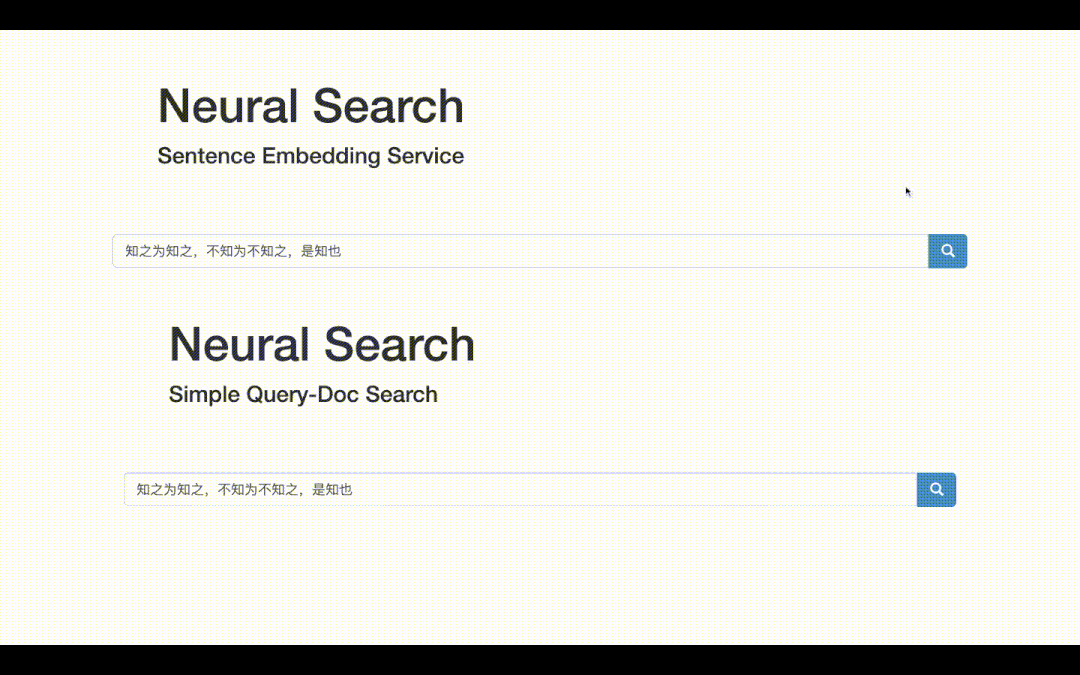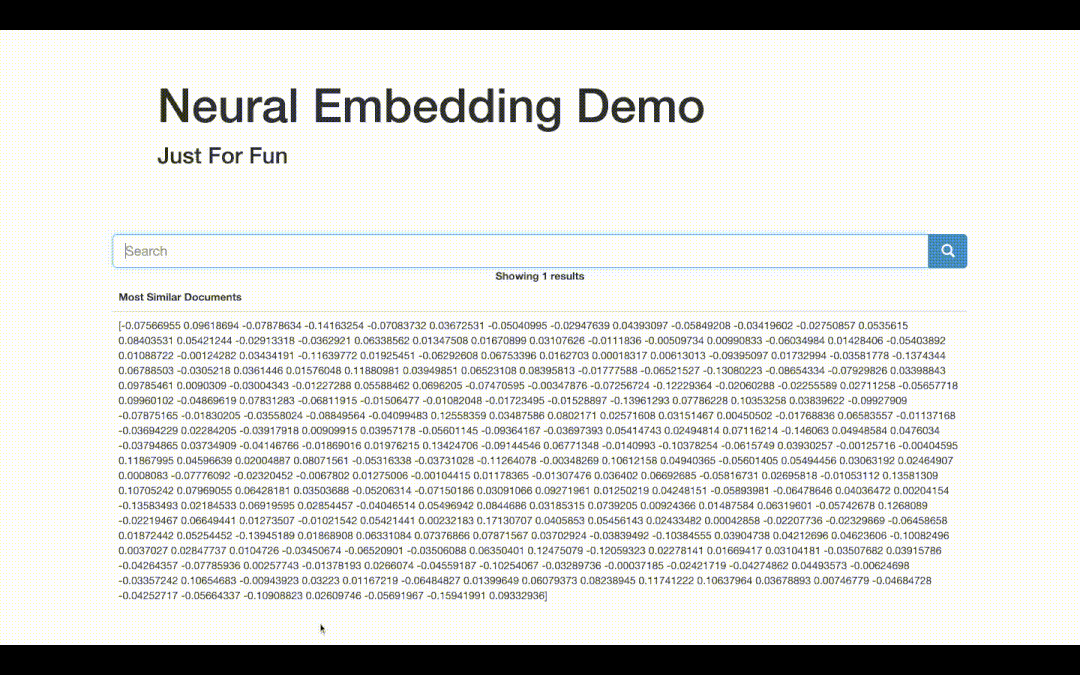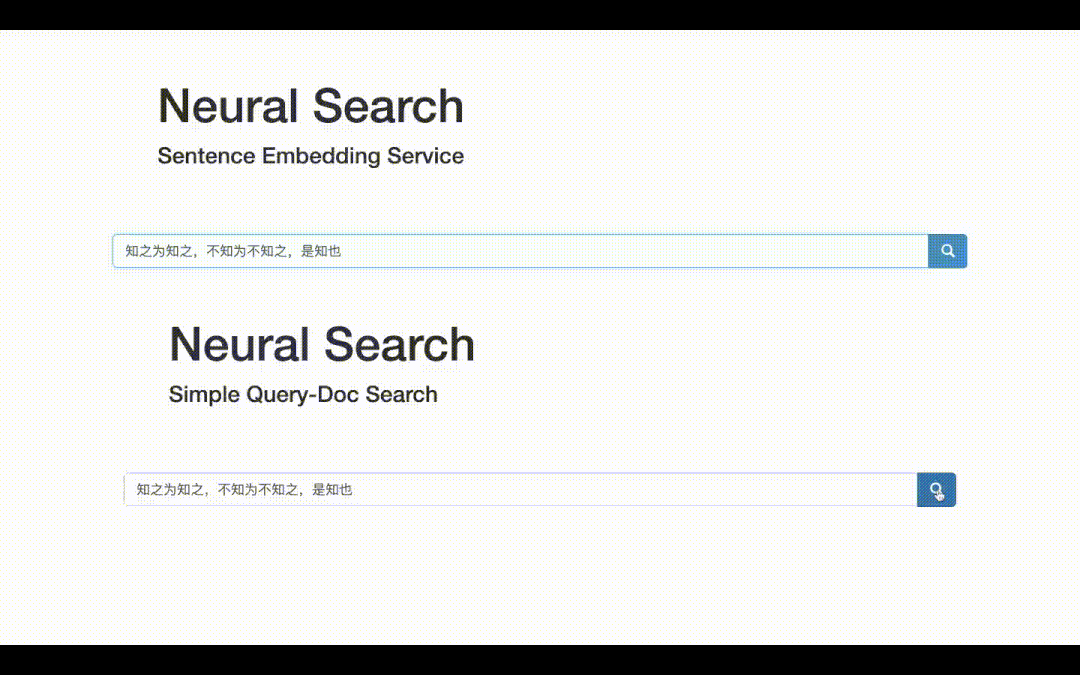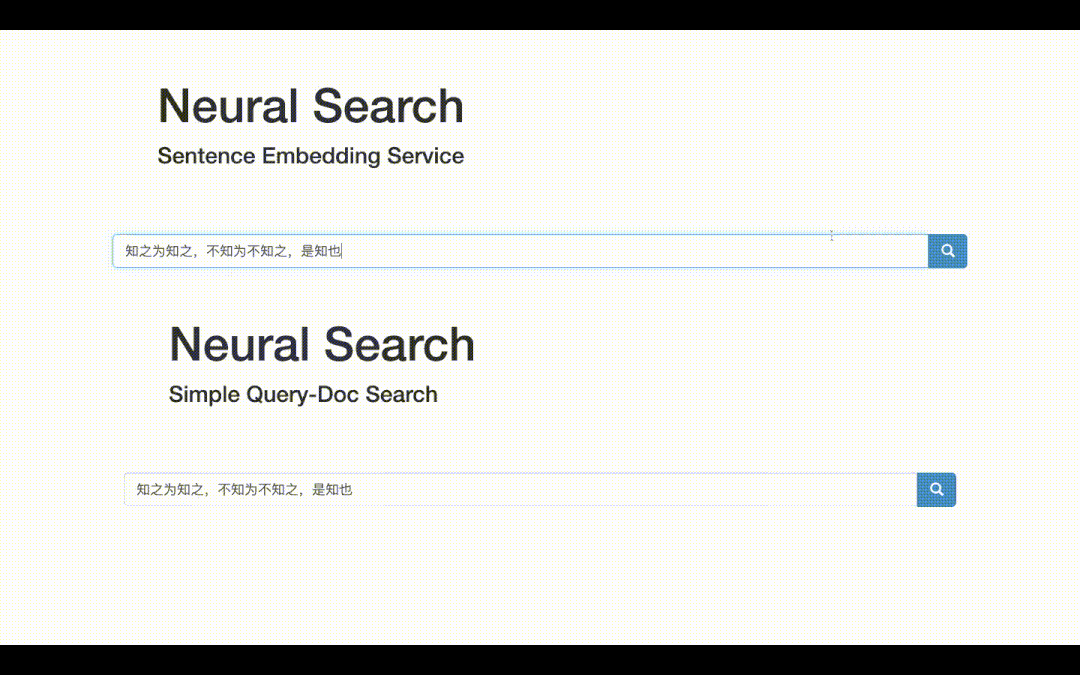
语义检索,底层技术是语义匹配,是NLP最基础常见的任务之一。之所以选题这个,从广度上看,语义匹配可以应用到QA、搜索、推荐、广告等各大方向;从技术深度上看,语义匹配需要融合各种SOTA模型、双塔和交互两种常用框架的魔改、以及样本处理的艺术和各种工程tricks。
比较有趣的是,当我在查相关资料的时候,发现百度飞桨PaddleNLP最近刚开源了类似的功能,可以的国货之光!之前使用过PaddleNLP,基本覆盖了NLP的各种应用和SOTA模型,调用起来也非常方便,强烈推荐大家试试!
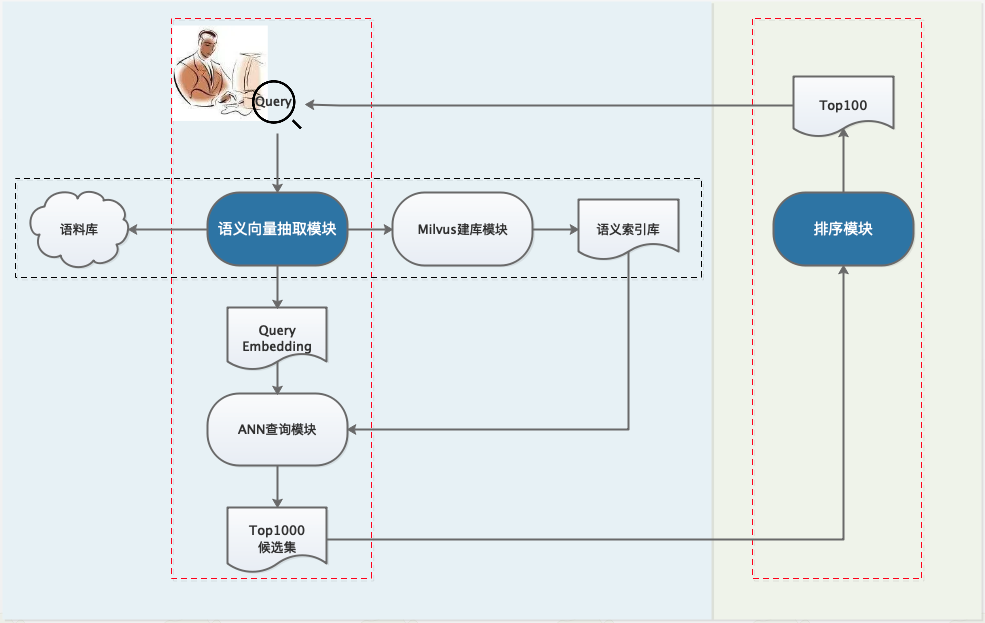
接下去我们以搜索场景为例,即输入Query返回Document集合,基于PaddleNLP提供的轮子一步步搭建语义检索系统。整体框架如下,由于计算量与资源的限制,一般工业界的搜索系统都会设计成多阶段级联结构,主要有召回、排序(粗排、精排、重排)等模块,各司其职。
step-1:利用预训练模型离线构建候选语料库
step-2:召回模块,对于在线查询Query,利用Milvus快速检索得到top1000候选集
step-3:排序模块,对于召回的top1000,再做更精细化的排序,得到top100结果返回给用户。
1、整体概览
1.1 数据
数据来源于某文献检索系统,分为有监督(少量)和无监督(大量)两种,具体示例在下文介绍
数据下载地址:https://bj.bcebos.com/v1/paddlenlp/data/literature_search_data.zip
1.2 代码
首先clone代码:
- git clone git@github.com:PaddlePaddle/PaddleNLP.git
- cd applications/neural_search
运行环境是
python3
paddlepaddle==2.2.1
paddlenlp==2.2.1
还有一些依赖包可以参考requirements.txt
2、离线建库
从上面的语义检索技术框架图中可以看出,首先我们需要一个语义模型对输入的Query/Doc文本提取向量,这里选用基于对比学习的SimCSE,核心思想是使语义相近的句子在向量空间中临近,语义不同的互相远离。关于更具体的SimCSE介绍,可以阅读我们之前的文章:
那么,如何训练才能充分利用好模型,达到更高的精度呢?对于预训练模型,一般常用的训练范式已经从『通用预训练->领域微调』的两阶段范式变成了『通用预训练->领域预训练->领域微调』三阶段范式。更多可以参看我们之前的
具体地,在这里我们的模型训练分为几步(代码和相应数据在下一节介绍):
在无监督的领域数据集上对通用ERNIE 1.0 进一步领域预训练,得到领域ERNIE
以领域ERNIE为热启,在无监督的文献数据集上对 SimCSE 做预训练
在有监督的文献数据集上结合In-Batch Negative策略微调步骤2模型,得到最终的模型,用于抽取文本向量表示,即我们所需的语义模型,用于建库和召回。
由于召回模块需要从千万量级数据中快速召回候选集合,通用的做法是借助向量搜索引擎实现高效 ANN,从而实现候选集召回。这里采用 Milvus 开源工具,关于Milvus的搭建教程可以参考官方教程
https://milvus.io/cn/docs/v1.1.1/
Milvus 是一款国产高性能检索库, 和Facebook 开源的 Faiss 功能类似,不熟悉的同学可以先阅读 亿级向量相似度检索库Faiss 原理+应用 了解下。
离线建库的代码位于PaddleNLP/applications/neural_search/recall/milvus
- |—— scripts
- |—— feature_extract.sh #提取特征向量的bash脚本
- ├── base_model.py # 语义索引模型基类
- ├── config.py # milvus配置文件
- ├── data.py # 数据处理函数
- ├── embedding_insert.py # 插入向量
- ├── embedding_recall.py # 检索topK相似结果 / ANN
- ├── inference.py # 动态图模型向量抽取脚本
- ├── feature_extract.py # 批量抽取向量脚本
- ├── milvus_insert.py # 插入向量工具类
- ├── milvus_recall.py # 向量召回工具类
- ├── README.md
- └── server_config.yml # milvus的config文件,本项目所用的配置
2.1 抽取向量
依照Milvus教程搭建完向量引擎后,就可以利用预训练语义模型提取文本向量了。运行feature_extract.py即可,注意修改需要建库的数据源路径。
运行结束会生成1000万条的文本数据,保存为corpus_embedding.npy。
2.2 插入向量
接下来,修改config.py中的Milvus ip等配置,将上一步生成的向量导入到Milvus库中。
- embeddings=np.load('corpus_embedding.npy')
- embedding_ids = [i for i in range(embeddings.shape[0])]
-
- client = VecToMilvus()
- collection_name = 'literature_search'
- partition_tag = 'partition_2'
- data_size=len(embedding_ids)
- batch_size=100000
- for i in tqdm(range(0,data_size,batch_size)):
- cur_end=i+batch_size
- if(cur_end>data_size):
- cur_end=data_size
- batch_emb=embeddings[np.arange(i,cur_end)]
- status, ids = client.insert(collection_name=collection_name, vectors=batch_emb.tolist(), ids=embedding_ids[i:i+batch_size],partition_tag=partition_tag)
抽取和插入向量两步,如果机器资源不是很"富裕"的话,可能会花费很长时间。这里建议可以先用一小部分数据进行测试功能,快速感知,等真实部署的阶段再进行全库的操作。
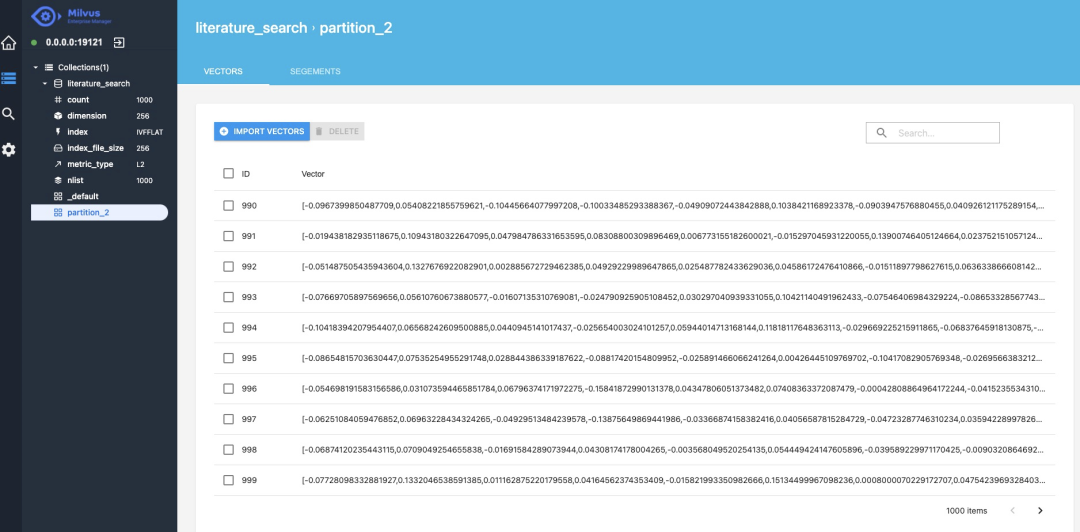
插入完成后,我们就可以通过Milvus提供的可视化工具[1]查看向量数据,分别是文档对应的ID和向量。
3、文档召回
召回阶段的目的是从海量的资源库中,快速地检索出符合Query要求的相关文档Doc。出于计算量和对线上延迟的要求,一般的召回模型都会设计成双塔形式,Doc塔离线建库,Query塔实时处理线上请求。
召回模型采用 Domain-adaptive Pretraining + SimCSE + In-batch Negatives 方案。
另外,如果只是想快速测试或部署,发现PaddleNLP也贴心地开源了训练好的模型文件,下载即可用,这里直接贴出模型链接:
领域预训练ERNIE:https://bj.bcebos.com/v1/paddlenlp/models/ernie_pretrain.zip
无监督SimCSE:https://bj.bcebos.com/v1/paddlenlp/models/simcse_model.zip
有监督In-batch Negatives:https://bj.bcebos.com/v1/paddlenlp/models/inbatch_model.zip
3.1 领域预训练
Domain-adaptive Pretraining的优势在之前文章已有具体介绍,不再赘述。直接给代码,具体功能都标注在后面。
- domain_adaptive_pretraining/
- |—— scripts
- |—— run_pretrain_static.sh # 静态图与训练bash脚本
- ├── ernie_static_to_dynamic.py # 静态图转动态图
- ├── run_pretrain_static.py # ernie1.0静态图预训练
- ├── args.py # 预训练的参数配置文件
- └── data_tools # 预训练数据处理文件目录
3.2 SimCSE无监督预训练
双塔模型,采用ERNIE 1.0热启,引入 SimCSE 策略。训练数据示例如下 代码结构如下,各个文件的功能都有备注在后面,清晰明了。
代码结构如下,各个文件的功能都有备注在后面,清晰明了。

对于训练、评估和预测分别运行scripts目录下对应的脚本即可。训练得到模型,我们一方面可以用于提取文本的语义向量表示,另一方面也可以用于计算文本对的语义相似度,只需要调整下数据输入格式即可。
3.3 有监督微调
对上一步的模型进行有监督数据微调,训练数据示例如下,每行由一对语义相似的文本对组成,tab分割,负样本来源于引入In-batch Negatives采样策略。 关于In-batch Negatives 的细节,可以参考之前的文章:
关于In-batch Negatives 的细节,可以参考之前的文章:
整体代码结构如下
训练、评估、预测的步骤和上一步无监督的类似,聪明的你肯定一看就懂了!
3.4 语义模型效果
前面说了那么多,来看看几个模型的效果到底怎么样?对于匹配或者检索模型,常用的评价指标是Recall@K,即前TOP-K个结果检索出的正确结果数与全库中所有正确结果数的比值。
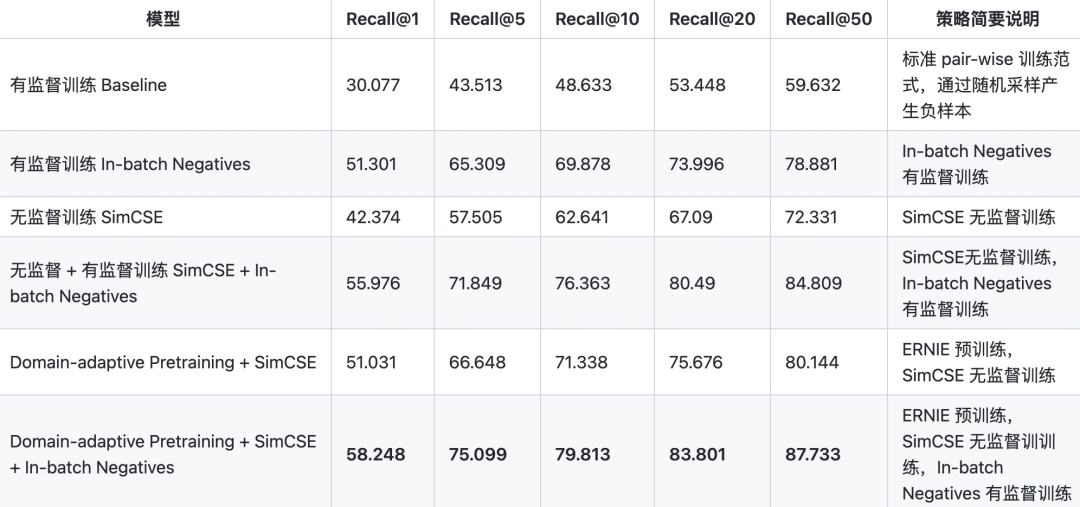
对比可以发现,首先利用ERNIE 1.0做Domain-adaptive Pretraining,然后把训练好的模型加载到SimCSE上进行无监督训练,最后利用In-batch Negatives 在有监督数据上进行训练能获得最佳的性能。
3.5 向量召回
终于到了召回,回顾一下,在这之前我们已经训练好了语义模型、搭建完了召回库,接下来只需要去库中检索即可。代码位于PaddleNLP/applications/neural_search/recall/milvus/inference.py
- def search_in_milvus(text_embedding):
- collection_name = 'literature_search' # 之前搭建好的Milvus库
- partition_tag = 'partition_2'
- client = RecallByMilvus()
- status, results = client.search(collection_name=collection_name, vectors=text_embedding.tolist(),
- partition_tag=partition_tag)
-
- corpus_file = "../../data/milvus/milvus_data.csv"
- id2corpus = gen_id2corpus(corpus_file)
- for line in results:
- for item in line:
- idx = item.id
- distance = item.distance
- text = id2corpus[idx]
- print(idx, text, distance)
以输入 国有企业引入非国有资本对创新绩效的影响——基于制造业国有上市公司的经验证据 为例,检索返回效果如下 返回结果的最后一列为相似度,Milvus默认使用的是欧式距离,如果想换成余弦相似度,可以在Milvus的配置文件中修改。
返回结果的最后一列为相似度,Milvus默认使用的是欧式距离,如果想换成余弦相似度,可以在Milvus的配置文件中修改。
4、文档排序
不同于召回,排序阶段由于面向的打分集合相对小很多,一般只有几千级别,所以可以使用更复杂的模型,这里采用 ERNIE-Gram 预训练模型,loss选用 margin_ranking_loss。
训练数据示例如下,三列,分别为(query,title,neg_title),tab分割。对于真实搜索场景,训练数据通常来源业务线上的点击日志,构造出正样本和强负样本。 代码结构如下
代码结构如下
训练运行sh scripts/train_pairwise.sh即可。
同样,PaddleNLP也开源了排序模型,https://bj.bcebos.com/v1/paddlenlp/models/ernie_gram_sort.zip
对于预测,准备数据为每行一个文本对,最终预测返回文本对的语义相似度。
- {'query': '中西方语言与文化的差异', 'title': '第二语言习得的一大障碍就是文化差异。', 'pred_prob': 0.85112214}
- {'query': '中西方语言与文化的差异', 'title': '跨文化视角下中国文化对外传播路径琐谈跨文化,中国文化,传播,翻译', 'pred_prob': 0.78629625}
- {'query': '中西方语言与文化的差异', 'title': '从中西方民族文化心理的差异看英汉翻译语言,文化,民族文化心理,思维方式,翻译', 'pred_prob': 0.91767526}
- {'query': '中西方语言与文化的差异', 'title': '中英文化差异对翻译的影响中英文化,差异,翻译的影响', 'pred_prob': 0.8601749}
- {'query': '中西方语言与文化的差异', 'title': '浅谈文化与语言习得文化,语言,文化与语言的关系,文化与语言习得意识,跨文化交际', 'pred_prob': 0.8944413}
5、总结
本文我们基于PaddleNLP提供的Neural Search功能自己快速搭建了一套语义检索系统。相对于自己从零开始,PaddleNLP非常好地提供了一套轮子。如果直接下载PaddleNLP开源训练好的模型文件,对于语义相似度任务,调用现成的脚本几分钟即可搞定;对于语义检索任务,需要将全量数据导入Milvus构建索引,除训练和建库时间外,整个流程预计30-50分钟即可完成。
在训练的间隙还研究了下,发现Github上的文档也很清晰详细啊。对于小白入门同学,做到了一键运行,不至于被繁杂的流程步骤困住而逐渐失去兴趣;对于想要深入研究的同学,PaddleNLP也开源了代码,可以进一步学习。赞!
另外我们还可以基于这些功能进行自己额外的开发,譬如开篇的动图,搭建一个更直观的语义向量生成和检索服务。Have Fun!
在跑代码过程中也遇到一些问题,非常感谢Paddle同学的耐心解答。并且得知他们最近好像会针对这个项目开一次课,免费的噢,这太香了!为感谢热心解答,这里帮忙宣传一下他们的公开课,欢迎感兴趣的同学去听呀!
12.28-12.30日,百度工程师将带来直播讲解,除语义检索系统外,还将带来问答、情感分析场景的系统方案,以及落地经验分享。可以扫码进入课程群了解详情报名

最后附上本次实践项目的代码:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/neural_search
本文参考资料
[1]
可视化工具: https://zilliz.com/products/em
- END -


百度发布PLATO-XL,全球首个百亿参数中英文对话预训练生成模型

EMNLP 2021 | 百度:多语言预训练模型ERNIE-M