
- 1创惟 GL3590 USB 3.1 Gen 2 Hub Controller运用分享
- 2Entity Framework问题:ReferentialConstraint 中的依赖属性映射由存储生成的列_依赖属性映射到由存储生成的列
- 3jenkins + docker-compose 实现一键构建部署_docker compose jenkins单个服务部署
- 41.1 操作系统的基本概念_同时共享和互斥共享 英文
- 5python学习6_python 自己收集模块如何写入到环境变量中调用函数
- 6客户端与服务器程序通信_在原有只能是客户端向服务器发送信息的基础上,实现服务器和客户端之间的相互通信
- 7解决TextView长按(复制,剪切,粘贴等)显示英文问题(系统语言为中文)_android edittext长按提示显示英文
- 8编程语言发展简史_编程语言的发展历史
- 9为何人工智能(AI)首选Python?如何转行Python人工智能?
- 10七大编程语言_程序语言
Yann Lecun: A Path Towards Autonomous Machine Intelligence(持续更新中)
赞
踩
生成式人工智能虽然在最近的时间里大放异彩,其效果也确实是大受震撼。估计当年提出人工神经网络、深度学习甚至是提出transformer的人估计也没有想到仅仅是大量的怼数据就让人们看到了通用人工智能的曙光。作为业内人士当然也是备受振奋。但是,内行看的应该是门道,不能盲从。Yann Lecun就是其中的一位站在生成式人工智能对立面的大佬。本文主要是对Yann Lecun的通用人工智能大作进行的翻译和学习。
论文链接:A Path Towards Autonomous Machine Intelligence
下面开始正文:
0 摘要
| How could machines learn as efficiently as humans and animals? How could machines learn to reason and plan? How could machines learn representations of percepts and action plans at multiple levels of abstraction, enabling them to reason, predict, and plan at multiple time horizons? This position paper proposes an architecture and training paradigms with which to construct autonomous intelligent agents. It combines concepts such as configurable predictive world model, behavior driven through intrinsic motivation, and hierarchical joint embedding architectures trained with self-supervised learning. | 机器如何像人类和动物一样高效地学习?机器如何学习推理和计划?机器如何在多个抽象层次上学习感知和行动计划的表示,使它们能够在多个时间范围内进行推理、预测和计划?本文提出了一个架构和训练范式,用它来构建自主智能代理。它结合了一些概念,如可配置的预测世界模型、通过内在动机驱动的行为以及通过自我监督学习训练的分层联合嵌入架构。 |
| Keywords: Artificial Intelligence, Machine Common Sense, Cognitive Architecture, Deep Learning, Self-Supervised Learning, Energy-Based Model, World Models, Joint Embedding Architecture, Intrinsic Motivation. | 关键词:人工智能、机器常识、认知架构、深度学习、自我监督学习、基于能量的模型、世界模型、联合嵌入架构、内在动机。 |
1. 序言
| This document is not a technical nor scholarly paper in the traditional sense, but a position paper expressing my vision for a path towards intelligent machines that learn more like animals and humans, that can reason and plan, and whose behavior is driven by intrinsic objectives, rather than by hard-wired programs, external supervision, or external rewards. Many ideas described in this paper (almost all of them) have been formulated by many authors in various contexts in various form. The present piece does not claim priority for any of them but presents a proposal for how to assemble them into a consistent whole. In particular, the piece pinpoints the challenges ahead. It also lists a number of avenues that are likely or unlikely to succeed. | 这份文件不是传统意义上的技术或学术论文,而是一份立场文件,表达了我对智能机器之路的愿景,这些机器更像动物和人类一样学习,可以推理和规划,其行为由内在目标驱动,而不是由硬连线程序、外部监督或外部奖励驱动。本文中描述的许多观点(几乎全部)都是由许多作者在不同的背景下以不同的形式提出的。目前的作品并不要求其中任何一个优先,但提出了一个建议,如何组装成一个一致的整体。这篇文章特别指出了未来的挑战。它还列出了一些可能成功或不太可能成功的途径。 |
| The text is written with as little jargon as possible, and using as little mathematical prior knowledge as possible, so as to appeal to readers with a wide variety of backgrounds including neuroscience, cognitive science, and philosophy, in addition to machine learning, robotics, and other fields of engineering. I hope that this piece will help contextualize some of the research in AI whose relevance is sometimes difficult to see. | 该文本尽可能少地使用术语,并尽可能少地使用数学先验知识,以吸引具有各种背景的读者,包括神经科学、认知科学和哲学,以及机器学习、机器人和其他工程领域。我希望这篇文章将有助于将人工智能的一些研究联系起来,这些研究的相关性有时很难看到。 |
2 Introduction
| Animals and humans exhibit learning abilities and understandings of the world that are far beyond the capabilities of current AI and machine learning (ML) systems. | 动物和人类表现出的学习能力和对世界的理解远远超出了当前人工智能和机器学习(ML)系统的能力。 |
| How is it possible for an adolescent to learn to drive a car in about 20 hours of practice and for children to learn language with what amounts to a small exposure. How is it that most humans will know how to act in many situation they have never encountered? By contrast, to be reliable, current ML systems need to be trained with very large numbers of trials so that even the rarest combination of situations will be encountered frequently during training. Still, our best ML systems are still very far from matching human reliability in real-world tasks such as driving, even after being fed with enormous amounts of supervisory data from human experts, after going through millions of reinforcement learning trials in virtual environments, and after engineers have hardwired hundreds of behaviors into them. | 一个青少年可能在大约 20 小时的练习中学会开车,而孩子可能只需要少量接触就可以学习语言。大多数人怎么会知道如何在他们从未遇到过的许多情况下采取行动?相比之下,为了可靠,当前的 ML 系统需要经过大量试验进行训练,以便在训练期间经常遇到最罕见的情况组合。尽管如此,我们最好的 ML 系统在现实世界任务(例如驾驶)中仍远未达到人类可靠性,即使在从人类专家那里获得大量监督数据之后,在虚拟环境中经历了数百万次强化学习试验之后,以及在工程师将数百种行为硬连线到其中之后 |
| The answer may lie in the ability of humans and many animals to learn world models, internal models of how the world works. There are three main challenges that AI research must address today: | 答案可能在于人类和许多动物学习世界模型的能力,即世界如何运转的内部模型。今天,人工智能研究必须解决三个主要挑战: |
| 1. How can machines learn to represent the world, learn to predict, and learn to act largely by observation? Interactions in the real world are expensive and dangerous, intelligent agents should learn as much as they can about the world without interaction (by observation) so as to minimize the number of expensive and dangerous trials necessary to learn a particular task. | 1.机器如何通过观察学会表示世界,学会预测,学会行动?真实世界中的交互是昂贵和危险的,智能代理应该尽可能多地了解没有交互的世界(通过观察),以便最小化学习特定任务所需的昂贵和危险的尝试次数。 |
| 2. How can machine reason and plan in ways that are compatible with gradient-based learning? Our best approaches to learning rely on estimating and using the gradient of a loss, which can only be performed with differentiable architectures and is difficult to reconcile with logic-based symbolic reasoning. | 2.机器如何以与基于梯度的学习兼容的方式进行推理和规划?我们最好的学习方法依赖于估计和使用损失的梯度,这只能用可微分的架构来执行,并且很难与基于逻辑的符号推理相协调。 |
| 3. How can machines learn to represent percepts and action plans in a hierarchical manner, at multiple levels of abstraction, and multiple time scales? Humans and many animals are able to conceive multilevel abstractions with which long-term predictions and long-term planning can be performed by decomposing complex actions into sequences of lower-level ones. | 3.机器如何学会以分层的方式、在多个抽象层次和多个时间尺度上表示感知和行动计划?人类和许多动物能够构思多层次的抽象概念,通过将复杂的行为分解成低层次的行为序列,可以进行长期预测和长期规划 |
| The present piece proposes an architecture for intelligent agents with possible solutions to all three challenges. The main contributions of this paper are the following: | 这篇文章提出了一个智能代理的架构,为所有这三个挑战提供了可能的解决方案。本文的主要贡献如下: |
| 1. an overall cognitive architecture in which all modules are differentiable and many of them are trainable (Section 3, Figure 2). | 1.一个整体的认知架构,其中所有的模块都是可微分的,其中许多是可训练的(第3节,图2)。 |
| 2. JEPA and Hierarchical JEPA: a non-generative architecture for predictive world models that learn a hierarchy of representations (Sections 4.4 and 4.6, Figures 12 and 15). | 2. JEPA和分层JEPA:一个用于预测世界模型的非生成性架构,该模型学习表示的层次结构(第4.4和4.6节,图12和15)。 |
| 3. a non-contrastive self-supervised learning paradigm that produces representations that are simultaneously informative and predictable (Section 4.5, Figure 13). | 3.一种非对比的自我监督学习范式,它产生的表示同时具有信息性和可预测性(第4.5节,图13)。 |
| 4. A way to use H-JEPA as the basis of predictive world models for hierarchical planning under uncertainty (section 4.7, Figure 16 and 17). | 4.一种使用H-JEPA作为不确定条件下分层规划预测世界模型基础的方法(第4.7节,图16和17)。 |
| Impatient readers may prefer to jump directly to the aforementioned sections and figures. | 不耐烦的读者可能喜欢直接跳到前面提到的章节和图表。 |
2.1 Learning World Models
| Human and non-human animals seem able to learn enormous amounts of background knowledge about how the world works through observation and through an incomprehensibly small amount of interactions in a task-independent, unsupervised way. It can be hypothesized that this accumulated knowledge may constitute the basis for what is often called common sense. Common sense can be seen as a collection of models of the world that can tell an agent what is likely, what is plausible, and what is impossible. Using suchworld models, animals can learn new skills with very few trials. They can predict the consequences of their actions, they can reason, plan, explore, and imagine new solutions to problems. Importantly, they can also avoid making dangerous mistakes when facing an unknown situation. | 人类和非人类的动物似乎能够通过观察和不可思议的少量互动,以独立于任务、不受监督的方式,学习大量关于世界如何运转的背景知识。可以假设,这种积累的知识可能构成通常所说的常识的基础。常识可以被看作是世界模型的集合,它可以告诉代理什么是可能的,什么是看似合理的,什么是不可能的。使用这样的世界模型,动物可以通过很少的尝试学习新技能。他们可以预测自己行为的后果,他们可以推理、计划、探索和想象解决问题的新方法。重要的是,他们还可以避免在面对未知情况时犯危险的错误。 |
| The idea that humans, animals, and intelligent systems use world models goes back a long time in psychology (Craik, 1943). The use of forward models that predict the next state of the world as a function of the current state and the action being considered has been standard procedure in optimal control since the 1950s (Bryson and Ho, 1969) and bears the name model-predictive control. The use of differentiable world models in reinforcement learning has long been neglected but is making a comeback (see for example (Levine, 2021)) | 人类、动物和智能系统使用世界模型的想法可以追溯到很久以前的心理学(Craik,1943)。自20世纪50年代以来(Bryson和Ho,1969年),使用前向模型预测世界的下一个状态,作为当前状态和正在考虑的行动的函数,已成为最优控制的标准程序,并被称为模型预测控制。强化学习中可微分世界模型的使用长期以来一直被忽视,但正在卷土重来(例如,见(Levine,2021)) |
| A self-driving system for cars may require thousands of trials of reinforcement learning to learn that driving too fast in a turn will result in a bad outcome, and to learn to slow down to avoid skidding. By contrast, humans can draw on their intimate knowledge of intuitive physics to predict such outcomes, and largely avoid fatal courses of action when learning a new skill. | 汽车的自动驾驶系统可能需要数千次强化学习的尝试,才能知道在转弯时开得太快会导致不好的结果,并学会减速以避免打滑。相比之下,人类可以利用他们对直觉物理学的深入了解来预测这样的结果,并在学习新技能时在很大程度上避免致命的行动过程。 |
| Common sense knowledge does not just allow animals to predict future outcomes, but also to fill in missing information, whether temporally or spatially. It allows them to produce interpretations of percepts that are consistent with common sense. When faced with an ambiguous percept, common sense allows animals to dismiss interpretations that are not consistent with their internal world model, and to pay special attention as it may indicate a dangerous situation and an opportunity for learning a refined world model. | 常识不仅让动物预测未来的结果,还能填补缺失的信息,无论是时间上还是空间上的。它允许他们对感知做出与常识相一致的解释。当面对模糊的感知时,常识允许动物忽略与它们内部世界模型不一致的解释,并给予特别关注,因为这可能表明危险的情况和学习精确世界模型的机会。 |
| I submit that devising learning paradigms and architectures that would allow machines to learn world models in an unsupervised (or self-supervised) fashion, and to use those models to predict, to reason, and to plan is one of the main challenges of AI and ML today. One major technical hurdle is how to devise trainable world models that can deal with complex uncertainty in the predictions. | 我认为,设计学习范式和架构,允许机器以无监督(或自我监督)的方式学习世界模型,并使用这些模型进行预测、推理和规划,是当今人工智能和人工智能的主要挑战之一。一个主要的技术障碍是如何设计可训练的世界模型来处理预测中复杂的不确定性。 |
2.2 Humans and Animals learn Hierarchies of Models

这张图表(由 Emmanuel Dupoux 提供)表明婴儿通常在什么年龄获得关于世界如何运作的各种概念。 这与抽象概念(例如物体受重力和惯性的影响)是在不太抽象的概念(例如物体的持久性和将物体分配给广泛的类别)之上获得的想法是一致的。 这些知识大部分是通过观察获得的,几乎没有直接干预。
| Humans and non-human animals learn basic knowledge about how the world works in the first days, weeks, and months of life. Although enormous quantities of such knowledge are acquired quite quickly, the knowledge seems so basic that we take it for granted. In the first few months of life, we learn that the world is three-dimensional. We learn that every source of light, sound, and touch in the world has a distance from us. The fact that every point in a visual percept has a distance is the best way to explain how our view of the world changes from our left eye to our right eye, or when our head is being moved. Parallax motion makes depth obvious, which in turn makes the notion of object obvious, as well as the fact that objects can occlude more distant ones. Once the existence of objects is established, they can be automatically assigned to broad categories as a function of their appearance or behavior. On top of the notion of object comes the knowledge that objects do not spontaneously appear, disappear, change shape, or teleport: they move smoothly and can only be in one place at any one time. Once such concepts are acquired, it becomes easy to learn that some objects are static, some have predictable trajectories (inanimate objects), some behave in somewhat unpredictable ways (collective phenomena like water, sand, tree leaves in the wind, etc), and some seem to obey different rules (animate objects). Notions of intuitive physics such as stability, gravity, inertia, and others can emerge on top of that. The effect of animate objects on the world (including the effects of the subject’s own actions) can be used to deduce cause-and-effect relationships, on top of which linguistic and social knowledge can be acquired. | 人类和非人类动物在生命的最初几天、几周和几个月学习关于世界如何运转的基本知识。虽然大量的这类知识可以很快获得,但这些知识似乎是如此的基础,以至于我们认为它们是理所当然的。在生命的最初几个月,我们知道世界是三维的。我们知道世界上每一个光源、声音和触觉都离我们有一段距离。视觉感知中的每一点都有距离,这一事实是解释我们对世界的看法如何从左眼变为右眼,或者当我们的头移动时的最佳方式。视差运动使深度变得明显,这反过来使物体的概念变得明显,以及物体可以遮挡更远的物体的事实。一旦物体的存在被确定,它们可以根据它们的外观或行为被自动地分配到广泛的类别中。在物体的概念之上是这样一种知识,即物体不会自发地出现、消失、改变形状或传送:它们平稳地移动,并且在任何时候只能在一个地方。一旦获得了这样的概念,就很容易了解到一些物体是静态的,一些物体有可预测的轨迹(无生命的物体),一些物体的行为方式有些不可预测(集体现象,如水、沙、风中的树叶等),一些物体似乎遵守不同的规则(有生命的物体)。直观物理学的概念,如稳定性、重力、惯性和其他概念可以在此基础上出现。有生命的物体对世界的影响(包括主体自身行动的影响)可以用来推导因果关系,在此基础上可以获得语言和社会知识。 |
| Figure 1, courtesy of Emmanuel Dupoux, shows at what age infants seem to acquire basic concepts such as object permanence, basic categories, intuitive physics, etc. Concepts at higher levels of abstraction seem to develop on top of lower-level ones. | 图1,由Emmanuel Dupoux提供,显示了婴儿在几岁时似乎获得了基本概念,如物体的永久性、基本类别、直觉物理学等。抽象层次较高的概念似乎是在较低层次的概念之上发展的。 |
| Equipped with this knowledge of the world, combined with simple hard-wired behaviors and intrinsic motivations/objectives, animals can quickly learn new tasks, predict the consequences of their actions and plan ahead, foreseeing successful courses of actions and avoiding dangerous situations. | 有了这个世界的知识,结合简单的硬连线行为和内在的动机/目标,动物可以快速学习新的任务,预测它们行动的后果并提前计划,预见行动的成功过程并避免危险情况。 |
| But can a human or animal brain contain all the world models that are necessary for survival? One hypothesis in this paper is that animals and humans have only one world model engine somewhere in their prefrontal cortex. That world model engine is dynamically configurable for the task at hand. With a single, configurable world model engine, rather than a separate model for every situation, knowledge about how the world works may be shared across tasks. This may enable reasoning by analogy, by applying the model configured for one situation to another situation. | 但是,一个人或动物的大脑能包含生存所必需的所有世界模型吗?这篇论文中的一个假设是,动物和人类在其前额皮质的某个地方只有一个世界模型引擎。该世界模型引擎可针对手头的任务进行动态配置。使用单个可配置的世界模型引擎,而不是针对每种情况的单独模型,关于世界如何工作的知识可以跨任务共享。这可以通过将为一种情况配置的模型应用于另一种情况来进行类比推理。 |
| To make things concrete, I will directly dive into a description of the proposed model. | 为了使事情具体化,我将直接进入对提议的模型的描述。 |
3 自主智能模型构架

| Figure 2: A system architecture for autonomous intelligence. All modules in this model are assumed to be “differentiable”, in that a module feeding into another one (through an arrow connecting them) can get gradient estimates of the cost’s scalar output with respect to its own output. | 图2:自主智能的系统架构。该模型中的所有模块都被假定为“可微分的”,因为一个模块馈入另一个模块(通过连接它们的箭头)可以获得cost标量输出相对于其自身输出的梯度估计。 |
| The configurator module takes inputs (not represented for clarity) from all other modules and configures them to perform the task at hand. | 配置模块从所有其他模块获取输入(为清楚起见未示出),并对它们进行配置以执行手头的任务。 |
| The perception module estimates the current state of the world. | 感知模块估计世界的当前状态。 |
| The world model module predicts possible future world states as a function of imagined actions sequences proposed by the actor. | 世界模型模块根据行动者提出的想象动作序列来预测可能的未来世界状态。 |
| The cost module computes a single scalar output called “energy” that measures the level of discomfort of the agent. It is composed of two sub-modules, the intrinsic cost, which is immutable (not trainable) and computes the immediate energy of the current state (pain, pleasure, hunger, etc), and the critic, a trainable module that predicts future values of the intrinsic cost. | 成本模块计算称为“能量”的单一标量输出,该输出测量代理的不适程度。它由两个子模块组成,内在成本,它是不可变的(不可训练的)并计算当前状态(痛苦、快乐、饥饿等)的即时能量,以及评论家,一个预测内在成本未来值的可训练模块。 |
| The short-term memory module keeps track of the current and predicted world states and associated intrinsic costs. | 短期记忆模块跟踪当前和预测的世界状态以及相关的内在成本。 |
| The actor module computes proposals for action sequences. The world model and the critic compute the possible resulting outcomes.The actor can find an optimal action sequence that minimizes the estimated future cost, and output the first action in the optimal sequence. See Section 3 for details.details. | 演员模块计算动作序列的提议。世界模型和批评家计算可能的结果。行动者可以找到使估计的未来成本最小化的最优动作序列,并输出最优序列中的第一个动作。有关详细信息,请参见第3节。 |
| The proposed architecture for autonomous intelligent agents is depicted in Figure 2. | 自治智能代理的架构如图2所示。 |
| It is composed of a number of modules whose functions are described below. Some of the modules are configurable on the fly, i.e. their precise function is determined by the configurator module. The role of the configurator is executive control: given a task to be executed, it pre-configures the perception, the world model, the cost and the actor for the task at hand. The configurator modulates the parameters of the modules it feeds into. | 它由许多模块组成,其功能如下所述。一些模块是动态可配置的,即它们的精确功能由配置器模块决定。配置器的角色是执行控制:给定一个要执行的任务,它预先配置感知、世界模型、成本和手头任务的actor。配置器调节其输入的模块的参数。 |
| The configurator module takes input from all other modules and configures them for the task at hand by modulating their parameters and their attention circuits. In particular, the configurator may prime the perception, world model, and cost modules to fulfill a particular goal. | 配置器模块从所有其他模块获取输入,并通过调整它们的参数和它们的注意力回路来配置它们以用于手头的任务。特别地,配置器可以启动感知、世界模型和成本模块以实现特定目标。 |
| The perception module receives signals from sensors and estimates the current state of the world. For a given task, only a small subset of the perceived state of the world is relevant and useful. The perception module may represent the state of the world in a hierarchical fashion, with multiple levels of abstraction. The configurator primes the perception system to extract the relevant information from the percept for the task at hand. | 感知模块接收来自传感器的信号,并估计世界的当前状态。对于给定的任务,只有一小部分感知到的世界状态是相关和有用的。感知模块可以用多级抽象以分层的方式表示世界的状态。配置器启动感知系统,从感知中提取相关信息,用于手头的任务。 |
| The world model module constitutes the most complex piece of the architecture. Its role is twofold: (1) estimate missing information about the state of the world not provided by perception, (2) predict plausible future states of the world. The world model may predict natural evolutions of the world, or may predict future world states resulting from a sequence of actions proposed by the actor module. The world model may predict multiple plausible world states, parameterized by latent variables that represent the uncertainty about the world state. The world model is a kind of “simulator” of the relevant aspects of world. What aspects of the world state is relevant depends on the task at hand. The configurator configures the world model to handle the situation at hand. The predictions are performed within an abstract representation space that contains information relevant to the task at hand. Ideally, the world model would manipulate representations of the world state at multiple levels of abstraction, allowing it to predict over multiple time scales. | 世界模型模块构成了架构中最复杂的部分。它的作用是双重的:(1)估计感知没有提供的关于世界状态的缺失信息,(2)预测世界未来可能的状态。世界模型可以预测世界的自然演变,或者可以预测由行动者模块提出的一系列动作产生的未来世界状态。世界模型可以预测多个似是而非的世界状态,由代表世界状态的不确定性的潜在变量来参数化。世界模型是世界相关方面的一种“模拟器”。世界状态的哪些方面是相关的取决于手头的任务。配置器配置世界模型来处理手边的情况。预测是在包含与手头任务相关的信息的抽象表示空间内执行的。理想情况下,世界模型将在多个抽象层次上操纵世界状态的表示,允许它在多个时间尺度上进行预测。 |
| A key issue is that the world model must be able to represent multiple possible predictions of the world state. The natural world is not completely predictable. This is particularly true if it contains other intelligent agents that are potentially adversarial. But it is often true even when the world only contains inanimate objects whose behavior is chaotic, or whose state is not fully observable. | 一个关键问题是,世界模型必须能够代表世界状态的多种可能的预测。自然界不是完全可以预测的。如果它包含其他具有潜在对抗性的智能代理,这一点尤其正确。但即使当世界只包含行为混乱或状态不完全可观察的无生命物体时,它也常常是正确的。 |
| There are two essential questions to answer when building the proposed architectures: (1) How to allow the world model to make multiple plausible prediction and represent uncertainty in the predictions, and (2) how to train the world model. | 当构建所提出的体系结构时,有两个基本问题需要回答:(1)如何允许世界模型做出多个似是而非的预测并在预测中表示不确定性,以及(2)如何训练世界模型。 |
| The cost module measures the level of “discomfort” of the agent, in the form of a scalar quantity called the energy. The energy is the sum of two energy terms computed by two sub-modules: the Intrinsic Cost module and the Trainable Critic module. The overall objective of the agent is to take actions so as to remain in states that minimize the average energy. | 成本模块以称为能量的标量的形式测量代理的“不适”水平。该能量是由两个子模块计算的两个能量项的总和:内在成本模块和可训练评判模块。代理的总体目标是采取行动,以便保持在最小化平均能量的状态。 |
| The Intrinsic Cost module is hard-wired (immutable, non trainable) and computes a single scalar, the intrinsic energy that measures the instantaneous “discomfort” of the agent– think pain (high intrinsic energy), pleasure (low or negative intrinsic energy), hunger, etc. The input to the module is the current state of the world, produced by the perception module, or potential future states predicted by the world model. The ultimate goal of the agent is minimize the intrinsic cost over the long run. This is where basic behavioral drives and intrinsic motivations reside. The design of the intrinsic cost module determines the nature of the agent’s behavior. Basic drives can be hard-wired in this module. This may include feeling “good” (low energy) when standing up to motivate a legged robot to walk, when influencing the state of the world to motivate agency, when interacting with humans to motivate social behavior, when perceiving joy in nearby humans to motivate empathy, when having a full energy supplies (hunger/satiety), when experiencing a new situation to motivate curiosity and exploration, when fulfilling a particular program, etc. Conversely, the energy would be high when facing a painful situation or an easily-recognizable dangerous situation (proximity to extreme heat, fire, etc), or when wielding dangerous tools. The intrinsic cost module may be modulated by the configurator, to drive different behavior at different times. | 内在成本模块是硬连线的(不可变的,不可训练的),它计算单个标量,即衡量代理即时“不适”的内在能量——思考痛苦(高内在能量)、快乐(低或负内在能量)、饥饿等。该模块的输入是由感知模块产生的世界的当前状态,或者由世界模型预测的潜在未来状态。代理的最终目标是在长期内最小化内在成本。这是基本的行为驱动和内在动机所在。内在成本模块的设计决定了代理人行为的性质。基本驱动器可以在该模块中硬连线。这可能包括当站起来激励腿式机器人行走时感觉“良好”(低能量),当影响世界的状态以激励能动性时,当与人类互动以激励社会行为时,当感知附近人类的快乐以激励同理心时,当具有充分的能量供应(饥饿/饱腹感)时,当经历新的情况以激励好奇心和探索时,当完成特定程序时,等等。相反,当面对痛苦的情况或容易识别的危险情况(接近极热、火等)时,或者当使用危险工具时,能量会很高。固有成本模块可以由配置器调整,以在不同时间驱动不同的行为。 |
| The Trainable Critic module predicts an estimate of future intrinsic energies. Like the intrinsic cost, its input is either the current state of the world or possible states predicted by the world model. For training, the critic retrieves past states and subsequent intrinsic costs stored in the associative memory module, and trains itself to predict the latter from the former. The function of the critic module can be dynamically configured by the configurator to direct the system towards a particular sub-goal, as part of a bigger task. | 可训练的评价模块预测未来内在能量的估计。像内在成本一样,它的输入要么是世界的当前状态,要么是世界模型预测的可能状态。为了进行训练,评价器检索存储在联想记忆模块中的过去状态和随后的内在成本,并训练自己从前者预测后者。作为更大任务的一部分,评价模块的功能可以由配置器动态配置,以将系统导向特定的子目标。 |
| Because both sub-modules of the cost module are differentiable, the gradient of the energy can be back-propagated through the other modules, particularly the world model, the actor and the perception, for planning, reasoning, and learning. | 因为成本模块的两个子模块都是可微分的,能量的梯度可以通过其他模块反向传播,特别是世界模型、行动者和感知,用于计划、推理和学习。 |
| The short-term memory module stores relevant information about the past, current, and future states of the world, as well as the corresponding value of the intrinsic cost. The world model accesses and updates the short-term memory while temporally predicting future (or past) states of the world, and while spatially completing missing information or correcting inconsistent information about the current world state. The world model can send queries to the short-term memory and receive retrieved values, or store new values of states. The critic module can be trained by retrieving past states and associated intrinsic costs from the memory. The architecture may be similar to that of Key-Value Memory Networks (Miller et al., 2016) This module can be seen as playing some of same roles as the hippocampus in vertebrates. | 短期记忆模块存储关于世界的过去、当前和未来状态的相关信息,以及内在成本的相应值。世界模型访问并更新短期记忆,同时在时间上预测世界的未来(或过去)状态,并且在空间上完成丢失的信息或纠正关于当前世界状态的不一致信息。世界模型可以向短期记忆发送查询并接收检索到的值,或者存储状态的新值。可以通过从存储器中检索过去的状态和相关的内在成本来训练评价模块。该架构可能类似于键值记忆网络的架构(Miller等人,2016年)。该模块可以被视为在脊椎动物中扮演与海马体相同的角色。 |
| The actor module computes proposals for sequences of actions and outputs actions to the effectors. The actor proposes a sequence of actions to the world model. The world model predicts future world state sequences from the action sequence, and feeds it to the cost. Given a goal defined by the cost (as configured by the configurator), the cost computes the estimated future energy associated with the proposed action sequence. Since the actor has access to the gradient of the estimated cost with respect to the proposed action sequence, it can compute an optimal action sequence that minimizes the estimated cost using gradientbased methods. If the action space is discrete, dynamic programming may be used to find an optimal action sequence. Once the optimization is completed, the actor outputs the first action (or a short sequence of actions) to the effectors. This process is akin tomodel-predictive control in optimal control (Bryson and Ho, 1969). | 执行器模块计算动作序列的建议,并将动作输出到效应器。执行器向世界模型提出了一系列动作。世界模型从动作序列中预测未来的世界状态序列,并将其提供给成本。给定由成本定义的目标(如配置器所配置的),成本计算与提议的动作序列相关联的估计的未来能量。由于行动者可以访问估计成本相对于提议的动作序列的梯度,因此它可以使用基于梯度的方法来计算最小化估计成本的最优动作序列。如果动作空间是离散的,动态规划可用于寻找最佳动作序列。优化完成后,执行者将第一个动作(或一个简短的动作序列)输出到效应器。这个过程类似于最优控制中的模型预测控制(Bryson和Ho,1969)。 |
| The actor may comprise two components: (1) a policy module that directly produces an action from the world state estimate produced by the perception and retrieved from the short-term memory, and (2) the action optimizer, as described above, for model-predictive control. The first mode is similar to Daniel Kahneman’s “System 1”, while the second mode is similar to “System 2” (Kahneman, 2011) | 执行器可以包括两个组件:(1)策略模块,其根据由感知产生并从短期记忆中检索的世界状态估计直接产生动作,以及(2)动作优化器,如上所述,用于模型预测控制。第一种模式类似于丹尼尔·卡内曼的“系统1”,而第二种模式类似于“系统2”(卡尼曼,2011) |
| In the following, we will use specific symbols to represent various components in architectural diagrams. An brief explanation is given in Appendix 8.3.3. | 在下文中,我们将使用特定的符号来表示架构图中的各种组件。附录8.3.3给出了简要说明。 |
3.1 Typical Perception-Action Loops
| There are two possible modes that the model can employ for a perception-action episode. The first one involves no complex reasoning, and produces an action directly from the output of the perception and a possible short-term memory access. We will call it “Mode-1”, by analogy with Kahneman’s “System 1”. The second mode involves reasoning and planning through the world model and the cost. It is akin to model-predictive control (MPC), a classical planning and reasoning paradigm in optimal control and robotics. We will call it “Mode-2” by analogy to Kahneman’s “System 2”. We use the term “reasoning” in a broad sense here to mean constraint satisfaction (or energy minimization). Many types of reasoning can be viewed as forms of energy minimization. | 有两种可能的模式,该模型可以用于感知-动作情节。第一种不涉及复杂的推理,直接从感知输出和可能的短期记忆访问中产生动作。我们将称之为“模式1”,类比卡尼曼的“系统1”。第二种模式涉及通过世界模型和成本进行推理和计划。它类似于模型预测控制(MPC),是优化控制和机器人学中的经典规划和推理范例。类比卡尼曼的“系统2”,我们称之为“模式2”。我们在这里广义地使用术语“推理”来表示约束满足(或能量最小化)。许多类型的推理可以被视为能量最小化的形式。 |
3.1.1 Mode-1: Reactive behavior(类似于强化学习)

| Figure 3: Mode-1 perception-action episode. The perception module estimates the state of the world s [ 0 ] = E n c ( x ) s[0] = Enc(x) s[0]=Enc(x). The actor directly computes an action, or a short sequence of actions, through a policy module a [ 0 ] = A ( s [ 0 ] ) a[0] = A(s[0]) a[0]=A(s[0]). | 图3:模式1感知-行动情节。感知模块估计世界的状态 s [ 0 ] = E n c ( x ) s[0] = Enc(x) s[0]=Enc(x)。参与者通过策略模块 a [ 0 ] = A ( s [ 0 ] ) a[0] = A(s[0]) a[0]=A(s[0])直接计算一个操作或一个简短的操作序列。 |
| This reactive process does not make use of the world model nor of the cost. The cost module computes the energy of the initial state f [ 0 ] = C ( s [ 0 ] ) f [0] = C(s[0]) f[0]=C(s[0]) and stores the pairs $ (s[0], f [0])$ in the short-term memory. Optionally, it may also predict the next state using the world model s [ 1 ] = P r e d ( s [ 0 ] , a [ 0 ] ) s[1] = Pred(s[0], a[0]) s[1]=Pred(s[0],a[0]), and the associated energy $f [0] = C(s[0]) $ so that the world model can be adjusted once the next observation resulting from the action taken becomes available. | 这种反应过程既不利用世界模型,也不利用成本。代价模块计算初始状态 f [ 0 ] = C ( s [ 0 ] ) f [0] = C(s[0]) f[0]=C(s[0])的能量,并将这些对 ( s [ 0 ] , f [ 0 ] ) (s[0],f [0]) (s[0],f[0])存储在短时记忆中。可选地,它还可以使用世界模型 s [ 1 ] = P r e d ( s [ 0 ] , a [ 0 ] ) s[1] = Pred(s[0],a[0]) s[1]=Pred(s[0],a[0])和相关联的能量 f [ 0 ] = C ( s [ 0 ] ) f [0] = C(s[0]) f[0]=C(s[0])来预测下一个状态,使得一旦由所采取的动作产生的下一个观察变得可用,就可以调整世界模型。 |
| A perception-action episode for Mode-1 is depicted in Figure 3. | 模式1的感知-动作情节如图3所示。 |
| The perception module, through an encoder module, extracts a representation of the state of the world s[0] = Enc(x) containing relevant information for the task at hand. A policy module, a component of the actor, produces an action as a function of the statea[0] = A(s[0]). The resulting action is sent to the effectors. | 感知模块通过编码器模块提取世界状态s[0] = Enc(x)的表示,该表示包含手头任务的相关信息。策略模块是执行元的一个组件,它根据状态a[0] = A(s[0])产生一个动作。产生的动作被发送到效应器。 |
| The function of the policy module is modulated by the configurator, which configures it for the task at hand. | 策略模块的功能由配置器来调节,配置器为手边的任务配置它。 |
| The policy module implements a purely reactive policy that does not involve deliberate planning nor prediction through the world model. Yet, its structure can be quite sophisticated. For example, in addition to the state s[0], the policy module may access the short-term memory to acquire a more complete information about previous world states. It may use the short-term memory for the associative retrieval of an action given the current state. | 政策模块执行一个纯粹的反应性政策,不涉及故意规划,也不通过世界模型进行预测。然而,它的结构可能相当复杂。例如,除了状态s[0]之外,策略模块可以访问短期存储器以获得关于先前世界状态的更完整的信息。在给定当前状态的情况下,它可以使用短时记忆来对动作进行关联检索。 |
| While the cost module is differentiable, its output f [0] = C(s[0]) is indirectly influenced by previous actions through the external world. Since the world is not differentiable, one cannot back-propagate gradients from the cost through the chain cost ← perception ←world ← action. In this mode, gradients of the cost f [0] with respect to actions can only be estimated by polling the world with multiple perturbed actions, but that is slow and potentially dangerous. This process would correspond to classical policy gradient methods in reinforcement learning. | 虽然成本模块是可微的,但它的输出f [0] = C(s[0])通过外部世界间接受到先前行动的影响。由于世界是不可微的,人们不能从成本通过链成本←感知←世界←行动反向传播梯度。在这种模式下,成本f [0]相对于动作的梯度只能通过用多个扰动动作轮询世界来估计,但是这是缓慢的并且有潜在的危险。这个过程对应于强化学习中的经典策略梯度方法。 |
| During Mode-1, the system can optionally adjust the world model. It runs the world model for one step, predicting the next state s[1], then it waits for the next percept resulting from the action taken, and uses the observed world state as a target for the predictor. | 在模式1期间,系统可以选择性地调整世界模型。它运行世界模型一步,预测下一个状态s[1],然后等待由所采取的行动产生的下一个感知,并使用观察到的世界状态作为预测器的目标。 |
| With the use of a world model, the agent can imagine courses of actions and predict their effect and outcome, lessening the need to perform an expensive and dangerous search for good actions and policies by trying multiple actions in the external world and measuring the result. | 通过使用世界模型,代理人可以想象行动的过程并预测其效果和结果,从而减少了通过在外部世界中尝试多种行动并测量结果来执行对良好行动和策略的昂贵且危险的搜索的需要。 |
3.1.2 Mode-2: reasoning and planning using the world model(类似于模型预测控制)

| Figure 4: Mode-2 perception-action episode. The perception module estimates the state of the worlds[0]. The actor proposes a sequence of actions a [ 0 ] , a [ 1 ] , . . . , a [ t ] , a [ t + 1 ] , . . . , a [ T ] a[0], a[1], . . . , a[t], a[t + 1], . . . , a[T] a[0],a[1],...,a[t],a[t+1],...,a[T]. The world model recursively predicts an estimate of the world state sequence using s [ t + 1 ] = P r e d ( s [ t ] , a [ t ] ) s[t + 1] = Pred(s[t], a[t]) s[t+1]=Pred(s[t],a[t]). The cost C ( s [ t ] ) C(s[t]) C(s[t]) computes an energy for each predicted state in the sequence, the total energy being the sum of them. Through an optimization or search procedure, the actor infers a sequence of actions that minimizes the total energy. It then sends the first action in the sequence (or the first few actions) to the effectors. This is, in effect, an instance of classical model-predictive control with recedinghorizon planning. Since the cost and the model are differentiable, gradient-based methods can be used to search for optimal action sequences as in classical optimal control. Since the total energy is additive over time, dynamic programming can also be used, particularly when the action space is small and discretized. Pairs of states (computed by the encoder or predicted by the predictor) and corresponding energies from the intrinsic cost and the trainable critic are stored in the short-term memory for subsequent training of the critic. | 图4:模式2感知-行动情节。感知模块估计世界的状态[0]。行动者提出了一系列动作 a [ 0 ] , a [ 1 ] , . . . . , a [ t ] , a [ t + 1 ] , . . . , a [ T ] a[0],a[1],....,a[t],a[t + 1],...,a[T] a[0],a[1],....,a[t],a[t+1],...,a[T]。世界模型使用 s [ t + 1 ] = P r e d ( s [ t ] , a [ t ] ) s[t + 1] = Pred(s[t],a[t]) s[t+1]=Pred(s[t],a[t])递归地预测世界状态序列的估计。cost C ( s [ t ] ) C(s[t]) C(s[t])计算序列中每个预测状态的能量,总能量是它们的总和。通过一个优化或搜索过程,行动者推断出一系列行动,使总能量最小化。然后,它将序列中的第一个动作(或前几个动作)发送给效应器。实际上,这是经典模型预测控制的一个实例。由于成本和模型是可微的,基于梯度的方法可以用来搜索最佳行动序列,如在经典的最优控制。由于总能量随着时间的推移而增加,因此也可以使用动态规划,特别是当动作空间很小且被离散化时。(由编码器计算的或由预测器预测的)状态对以及来自内在成本和可训练评价者的相应能量被存储在短期存储器中,用于评价者的后续训练。 |
| A typical perception-action episode for Mode 2 is depicted in Figure 4. | 模式2的典型感知-行动情节如图4所示。 |
| 1. perception: the perception system extract a representation of the current state of the world s[0] = P (x). The cost module computes and stores the immediate cost associated with that state. | 1.感知:感知系统提取一个世界当前状态的表示s[0] = P (x)。成本模块计算并存储与该状态相关联的即时成本。 |
| 2. action proposal: the actor proposes an initial sequence of actions to be fed to the world model for evaluation (a[0], . . . , a[t], . . . , a[T ]). | 2.行动建议:行动者建议一个初始的行动序列,以供世界模型评估(a[0],)。。。,a[t],。。。,一个[T ])。 |
| 3. simulation: the world model predicts one or several likely sequence of world state representations resulting from the proposed action sequence (s[1], . . . , s[t], . . . , s[T ]). | 3.模拟:世界模型预测一个或几个可能的世界状态表示序列,这些序列是由提议的动作序列(s[1],)产生的。。。,s[t],。。。,s[T ])。 |
| 4. evaluation: the cost module estimates a total cost from the predicted state sequence, generally as a sum over time steps F (x) = ∑T t=1 C(s[t]) | 4.评估:成本模块根据预测的状态序列估计总成本,通常是时间步长F (x) = ∑T t=1 C(s[t]) |
| 5. planning: the actor proposes a new action sequence with lower cost. This can be done through a gradient-based procedure in which gradients of the cost are back-propagated through the compute graph to the action variables. The resulting minimum-cost action sequence is denoted (ˇa[0], . . . , ˇa[T ]). Full optimization may require iterating steps 2-5. | 5.策划:演员提出一个成本更低的新动作序列。这可以通过基于梯度的程序来完成,在该程序中,成本的梯度通过计算图反向传播到行动变量。产生的最小成本动作序列表示为(a[0],。。。ˇa[T ])。完全优化可能需要重复步骤2-5。 |
| 6. acting: after converging on a low-cost action sequence, the actor sends the first action (or first few actions) in the low-cost sequence to the effectors. The entire process is repeated for the next perception-action episode. | 6.表演:在收敛到一个低成本的动作序列后,演员将低成本序列中的第一个动作(或前几个动作)发送给效果器。整个过程在下一集感知-行动中重复。 |
| 7. memory: after every action, the states and associated costs from the intrinsic cost and the critic are stored in the short-term memory. These pairs can be used later to train or adapt the critic. | 7.记忆:在每一个行动之后,来自内在成本和批评者的状态和相关成本被存储在短期记忆中。这些配对可以在以后用来训练或改编评论家。 |
| This procedure is essentially what is known as Model-Predictive Control (MPC) with receding horizon in the optimal control literature. The difference with classical optimal control is that the world model and the cost function are learned. | 这个过程本质上就是最优控制文献中所称的滚动时域模型预测控制(MPC)。与经典最优控制的区别在于世界模型和成本函数是学习的。 |
| In principle, any form of optimization strategy can be used, for step 5. While gradientbased optimization methods can be efficient when the world model and cost are wellbehaved, situations in which the action-cost mapping has discontinuities may require to use other optimization strategies, particularly if the state and/or action spaces can be discretized. These strategies include dynamic programming, combinatorial optimization, simulate annealing and other gradient-free methods, heuristic search techniques (e.g. tree search with pruning), etc. | 原则上,对于步骤5,可以使用任何形式的优化策略。虽然当世界模型和成本表现良好时,基于梯度的优化方法可能是有效的,但是动作-成本映射具有不连续性的情况可能需要使用其他优化策略,特别是如果状态和/或动作空间可以被离散化。这些策略包括动态规划、组合优化、模拟退火和其他无梯度方法、启发式搜索技术(例如带有修剪的树搜索)等。 |
| To simplify, the process was described in the deterministic case, i.e. when there is no need to handle the possibility of multiple predictions for s[t + 1] resulting from a given initial state s[t] and action a[t]. In real situations, the world is likely to be somewhat unpredictable. Multiple states may result from a single initial state and action due to the fact that the world is intrinsically stochastic (aleatoric uncertainty), or that the state representation s[t] contains incomplete information about the true world state (epistemic uncertainty), or that the world model’s prediction accuracy is imperfect due to limited training data, representational power, or computational constraints. | 为了简化,在确定性情况下描述了该过程,即,当不需要处理由给定初始状态s[t]和动作a[t]产生的s[t + 1]的多个预测的可能性时。在真实情况下,世界可能有些不可预测。由于世界本质上是随机的(任意不确定性),或者状态表示s[t]包含关于真实世界状态的不完整信息(认知不确定性),或者由于有限的训练数据、代表性能力或计算约束,世界模型的预测准确性是不完美的,因此单个初始状态和动作可能导致多个状态。 |
3.1.3 From Mode-2 to Mode-1: Learning New Skills

Figure 5: Training a reactive policy module from the result of Mode-2 reasoning. Using Mode-2 is onerous, because it mobilizes all the resources of the agent for the task at hand. It involves running the world model for multiple time steps repeatedly. This diagram depicts how to train a policy moduleA(s[t]) to approximate the action that results from Mode-2 optimization. The system first operates in Mode-2 and produces an optimal sequence of actions (ˇa[0], . . . , ˇa[T ]). Then the parameters of the policy module are adjusted to minimize a divergence D(ˇa[t]), A(s[t])) between the optimal action and the output of the policy module. This results in a policy module that performs amortized inference, and produces an approximation for a good action sequence. The policy module can then be used to produce actions reactively in Mode-1, or to initialize the action sequence prior to Mode-2 inference and thereby accelerate the optimization.
图5:根据模式2推理的结果训练一个反应策略模块。使用模式2很麻烦,因为它调动了代理的所有资源来完成手头的任务。它包括重复运行多个时间步长的世界模型。此图描述了如何训练策略模块A(s[t])来近似模式2优化产生的动作。系统首先在模式2下运行,并产生一个最佳的动作序列(ˇa[0],。。。ˇa[T ])。然后,调整策略模块的参数,以最小化最佳动作和策略模块的输出之间的偏差D(ˇa[t]),A(s[t])。这导致策略模块执行分期推断,并产生良好动作序列的近似。然后,可以使用策略模块在模式1中反应性地产生动作,或者在模式2推理之前初始化动作序列,从而加速优化。
| Using Mode-2 is onerous. The agent only possesses one world model “engine”. It is configurable by the configurator for the task at hand, but it can only be used for a single task at a time. Hence, similarly to humans, the agent can only focus on one complex task at a time. | 使用模式2很麻烦。代理只拥有一个世界模型“引擎”。它可由配置器为手头的任务进行配置,但一次只能用于单个任务。因此,与人类类似,智能体一次只能专注于一项复杂的任务。 |
| Mode-1 is considerably less onerous, since it only requires a single pass through a policy module. The agent may possess multiple policy modules working simultaneously, each specialized for a particular set of tasks. | 模式1要简单得多,因为它只需要一次通过策略模块。代理可以拥有多个同时工作的策略模块,每个策略模块专门用于一组特定的任务。 |
| The process described in Figure 5 shows how a policy module A ( s [ t ] ) A(s[t]) A(s[t]) can be trained to produce approximations of the optimal actions resulting from Mode-2 reasoning. The system is run on Mode-2, producing an optimal action sequence ( ˇ a [ 0 ] , . . . , ˇ a [ t ] , . . . , ˇ a [ T ] ) (ˇa[0], . . . , ˇa[t], . . . , ˇa[T ]) (ˇa[0],...,ˇa[t],...,ˇa[T]). Then, the parameters of the policy module A ( s [ t ] ) A(s[t]) A(s[t]) are updated to minimize a divergence measure between its output and the optimal action at that time D ( ˇ a [ t ] , A ( s [ t ] ) ) D(ˇa[t], A(s[t])) D(ˇa[t],A(s[t])). Once properly trained, the policy module can be used to directly produce an action in Mode-1 $ ̃a[0] = A(s[0]) $. It can also be used to recursively compute an initial action sequence proposal before Mode-2 optimization: | 图5中描述的过程显示了如何训练策略模块 A ( s [ t ] ) A(s[t]) A(s[t])来产生模式2推理产生的最佳动作的近似。系统以模式2运行,产生最佳动作序列 ( ˇ a [ 0 ] ,。。。ˇ a [ t ] ,。。。ˇ a [ T ] ) (ˇa[0],。。。ˇa[t],。。。ˇa[T ]) (ˇa[0],。。。ˇa[t],。。。ˇa[T])。然后,更新策略模块 A ( s [ t ] ) A(s[t]) A(s[t])的参数,以最小化其输出和当时的最优动作 D ( ˇ a [ t ] , A ( s [ t ] ) D(ˇa[t],A(s[t]) D(ˇa[t],A(s[t])之间的偏差度量。一旦经过适当的训练,策略模块可以用于直接产生模式-1 $ ̃a[0] = A(s[0]) $中的动作。它还可用于在模式2优化之前递归计算初始动作序列建议: |
| The policy module can be seen as performing a form of amortized inference. This process allows the agent to use the full power of its world model and reasoning capabilities to acquire new skills that are then “compiled” into a reactive policy module that no longer requires careful planning. | 策略模块可以被视为执行某种形式的分期推断。这个过程允许代理使用其世界模型和推理能力的全部能力来获得新的技能,然后这些技能被“编译”到不再需要仔细规划的反应策略模块中。 |
3.1.4 Reasoning as Energy Minimization
| The process of elaborating a suitable action sequence in Mode-2 can be seen as a form of reasoning. This form of reasoning is based on simulation using the world model, and optimization of the energy with respect to action sequences. More generally, the “actions” can be seen as latent variables representing abstract transformations from one state to the next. This type of planning though simulation and optimization may constitute the kind of reasoning that is most frequent in natural intelligence. | 在模式2中精心设计一个合适的动作序列的过程可以被看作是一种推理形式。这种形式的推理基于使用世界模型的模拟,以及相对于动作序列的能量优化。更一般地说,“动作”可以被视为表示从一个状态到下一个状态的抽象转换的潜在变量。这种通过模拟和优化的规划可能构成自然智能中最常见的推理类型。 |
| Many classical forms of reasoning in AI can actually be formulated as optimization problems (or constraint satisfaction problems). It is certainly the case for the kind of probabilistic inference performed with factor graphs and probabilistic graphical models. The proposed architecture is, in fact, a factor graph in which the cost modules are log factors. But the kind of reasoning that the proposed architecture enables goes beyond traditional logical and probabilistic reasoning. It allows reasoning by simulation and by analogy. | 人工智能中的许多经典推理形式实际上可以表述为优化问题(或约束满足问题)。对于用因子图和概率图模型进行的概率推理来说,当然是这种情况。所提出的架构实际上是一个因子图,其中成本模块是对数因素。但是所提出的体系结构所支持的推理类型超出了传统的逻辑和概率推理。它允许通过模拟和类比进行推理。 |
3.2 The Cost Module as the Driver of Behavior
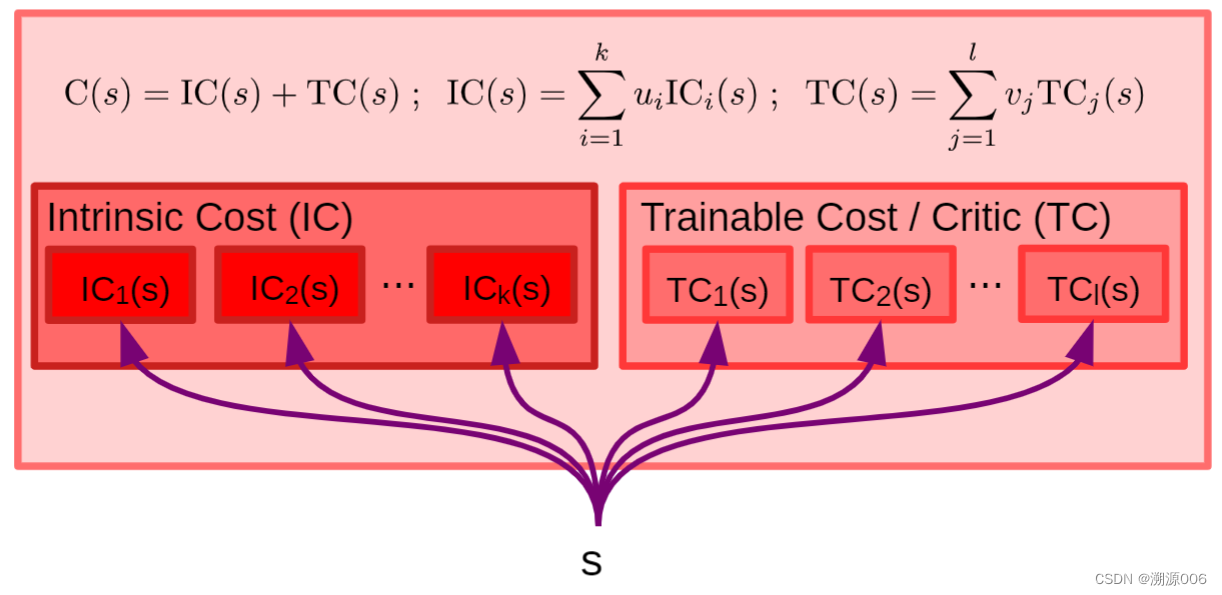
Figure 6: Architecture of the cost module. The cost module comprises the intrinsic cost module which is immutable
I
C
i
(
s
)
IC_i(s)
ICi(s) (left) and the critic or Trainable Cost
T
C
j
(
s
)
TC_j (s)
TCj(s) (right), which is trainable. Both IC and TC are composed of multiple submodules whose output energies are linearly combined. Each submodule imparts a particular behavioral drive in the agent. The weights in the linear combination,
u
i
u_i
ui and
v
j
v_j
vj , are determined by the configurator module and allow the agent to focus on different subgoals at different times.
图6:成本模块的架构。成本模块包括固有成本模块,它是不可变的
I
C
i
(
s
)
IC_i(s)
ICi(s)(左)和the critic或可训练成本
T
C
j
(
s
)
TC_j (s)
TCj(s)(右),它是可训练的。IC和TC都由多个子模块组成,每个子模块的输出能量是线性组合的。每个子模块在代理中赋予特定的行为驱动。线性组合中的权重
u
i
u_i
ui和
v
j
v_j
vj由配置器模块确定,并允许代理在不同时间关注不同的子目标。
| The overall architecture of the cost module is shown in Figure 6. It is composed of the intrinsic cost module which is immutable ICi(s) and the critic or Trainable Cost TCj (s), which is trainable. Both IC and TC are composed of multiple submodules whose output energies are linearly combined | 成本模块的整体架构如图6所示。它由不可变的 I C i ( s ) IC_i(s) ICi(s)和可训练的临界或可训练成本 T C j ( s ) TC_j (s) TCj(s)组成。IC和TC都由多个输出能量线性组合的子模块组成 |
| C ( s ) = I C ( s ) + T C ( s ) (1) C(s) = IC(s) + TC(s) \tag{1} C(s)=IC(s)+TC(s)(1) | |
| I C ( s ) = ∑ i = 1 k u i I C i ( s ) (2) IC(s) = \sum_{i=1}^k u_iIC_i(s) \tag{2} IC(s)=i=1∑kuiICi(s)(2) | |
| T C ( s ) = ∑ j = 1 l v i T C j ( s ) (3) TC(s) =\sum_{j=1}^l v_iTC_j(s) \tag{3} TC(s)=j=1∑lviTCj(s)(3) | |
| Each submodule imparts a particular behavioral drive to the agent. The weights in the linear combination, ui and vj , are modulated by the configurator module and allow the agent to focus on different subgoals at different times. | 每个子模块向代理赋予特定的行为驱动。线性组合中的权重 u i u_i ui和 v j v_j vj由配置器模块调整,并允许代理在不同时间关注不同的子目标。 |
| The intrinsic cost module (IC) is where the basic behavioral nature of the agent is defined. It is where basic behaviors can be indirectly specified. | 内在成本模块(ic)是定义代理的基本行为性质的地方。这是可以间接指定基本行为的地方。 |
| For a robot, these terms would include obvious proprioceptive measurements corresponding to “pain”, “hunger”, and “instinctive fears”, measuring such things as external force overloads, dangerous electrical, chemical, or thermal environments, excessive power consumption, low levels of energy reserves in the power source, etc. | 对于机器人,这些术语将包括对应于“疼痛”、“饥饿”和“本能恐惧”的明显的本体感受度量,度量诸如外力过载、危险的电、化学或热环境、过度的功率消耗、电源中低水平的能量储备等。 |
| They may also include basic drives to help the agent learn basic skills or accomplish its missions. For example, a legged robot may comprise an intrinsic cost to drive it to stand up and walk. This may also include social drives such as seeking the company of humans, finding interactions with humans and praises from them rewarding, and finding their pain unpleasant (akin to empathy in social animals). Other intrinsic behavioral drives, such as curiosity, or taking actions that have an observable impact, may be included to maximize the diversity of situations with which the world model is trained (Gottlieb et al., 2013) | 它们还可能包括帮助代理学习基本技能或完成其任务的基本驱动力。例如,腿式机器人可以包括驱动其站立和行走的内在成本。这也可能包括社会驱动力,如寻求人类的陪伴,发现与人类的互动和他们的赞美是有益的,发现他们的痛苦是不愉快的(类似于社会性动物的移情)。其他内在行为驱动,如好奇心,或采取具有可观察影响的行动,可以被包括在内,以最大化世界模型被训练的情况的多样性(Gottlieb等人,2013年) |
| The IC can be seen as playing a role similar to that of the amygdala in the mammalian brain and similar structures in other vertebrates. | IC的作用可以被看作类似于哺乳动物大脑中的杏仁核和其他脊椎动物中的类似结构。 |
| To prevent a kind of behavioral collapse or an uncontrolled drift towards bad behaviors, the IC must be immutable and not subject to learning (nor to external modifications). | 为了防止某种行为崩溃或不受控制地向不良行为发展,IC必须是不可变的,不能被学习(也不能被外部修改)。 |
| The role of the critic (TC) is twofold: (1) to anticipate long-term outcomes with minimal use of the onerous world model, and (2) to allow the configurator to make the agent focus on accomplishing subgoals with a learned cost. | critic (TC)的角色是双重的:(1)以最少的使用繁重的世界模型来预测长期的结果,以及(2)允许配置者让代理人专注于用学习到的成本来完成子目标。 |
| In general, the behavioral nature of an AI agent can be specified in four ways: | 一般来说,人工智能主体的行为本质可以用四种方式来描述: |
| 1. by explicitly programming a specific behavior activated when specific conditions are met | 1.通过显式编程在满足特定条件时激活特定行为 |
| 2. by defining an objective function in such a way that the desired behavior is executed by the agent as a result of finding action sequences that minimize the objective. | 2。通过以这样的方式定义一个目标函数,即作为找到最小化目标的动作序列的结果,期望的行为由代理执行。 |
| 3. by training the agent to behave a certain way through direct supervision. The agent observes the actions of an expert teacher, and trains a Mode-1 policy module to reproduce it. | 3.通过直接监督训练代理人的行为方式。代理观察专家教师的行为,并训练模式1策略模块来再现它。 |
| 4. by training the agent through imitation learning. The agent observes expert teachers, and infers an objective function that their behavior appears to be optimizing when they act. This produces a critic submodule for Mode-2 behavior. This process is sometimes called inverse reinforcement learning. | 4.通过模仿学习来训练智能体。代理观察专家教师,并推断一个目标函数,当他们行动时,他们的行为似乎是优化的。这产生了模式2行为的批判子模块。这个过程有时被称为逆向强化学习。 |
| The second method is considerably simpler to engineer than the first one, because it merely requires to design an objective, and not design a complete behavior. The second method is also more robust: a preordained behavior may be invalidated by unexpected conditions or a changing environment. With an objective, the agent may adapt its behavior to satisfy the objective despite unexpected conditions and changes in the environment. The second method exploits the learning and inference abilities of the agent to minimize the amount of priors hard-wired by the designer that are likely to be brittle. | 第二种方法比第一种方法简单得多,因为它只需要设计一个目标,而不需要设计一个完整的行为。第二种方法也更健壮:一个预先注定的行为可能会被意想不到的情况或变化的环境所否定。有了目标,尽管环境中有意外的条件和变化,代理可以调整它的行为以满足目标。第二种方法利用代理的学习和推理能力来最小化由设计者硬连线的可能不可靠的先验的数量。 |
3.3 Training the Critic
| An essential question is how to train the critic. The principal role of the critic is to predict future values of the intrinsic energy. To do so, it uses the short-term memory module. This module is an associative memory in which the intrinsic cost module stores triplets (time, state, intrinsic energy): (τ, sτ , IC(sτ )). The stored states and corresponding intrinsic energies may correspond to a perceived state or to a state imagined by the world model during a Mode-2 episode. The memory may retrieve a state sτ given a time τ , and may retrieve an energy IC(sτ ) given a time τ or a state sτ . With a suitable memory architecture, the retrieval may involve interpolations of keys and retrieved values. The process is shown in Figure 7 | 一个基本问题是如何培养批评家。批评家的主要作用是预测内在能量的未来值。为此,它使用短期记忆模块。这个模块是一个联想记忆,内在成本模块存储三元组(时间,状态,内在能量):(τ,sτ,IC(sτ))。所存储的状态和相应的内在能量可以对应于感知状态或模式2发作期间由世界模型想象的状态。给定时间τ,存储器可以检索状态sτ,并且给定时间τ或状态sτ,可以检索能量IC(sτ)。利用合适的存储器架构,检索可以包括关键字和检索值的插值。这个过程如图7所示 |
| The critic can be trained to predict future intrinsic energy values by retrieving a past state vector s τ s_τ sτ together with an intrinsic energy at a later time I C ( s τ + δ ) IC(s_{τ +δ} ) IC(sτ+δ). The parameters of the critic can then be optimized to minimize a prediction loss, for example ∣ ∣ I C ( s τ + δ ) − T C ( s τ ) ∣ ∣ 2 ||IC(s_{τ +δ} ) −T C(s_τ )||^2 ∣∣IC(sτ+δ)−TC(sτ)∣∣2. This is a simple scenario. More complex schemes can be devised to predict expectations of discounted future energies, or distributions thereof. Note that the state vectors may contain information about the actions taken or imagined by the actor. | 可以训练评论家通过检索过去的状态向量 s τ s_τ sτ以及稍后时间 I C ( s τ + δ ) IC(s_{τ +δ} ) IC(sτ+δ)的内在能量来预测未来的内在能量值。然后可以优化critic的参数,使预测损耗最小,例如 ∣ ∣ I C ( s τ + δ ) − T C ( s τ ) ∣ ∣ 2 ||IC(s_{τ +δ} ) −T C(s_τ )||^2 ∣∣IC(sτ+δ)−TC(sτ)∣∣2。这是一个简单的场景。可以设计更复杂的方案来预测未来能量折扣的期望值或其分布。请注意,状态向量可能包含有关行动者采取或想象的行动的信息。 |
| At a general level, this is similar to critic training methods used in such reinforcement learning approaches as A2C. | 总的来说,这类似于A2C等强化学习方法中使用的批评训练方法。 |
| The short-term memory can be implemented as the memory module in a key-value memory network ??: a query vector is compared to a number of key vectors, producing a vector of scores. The scores are normalized and used as coefficients to output a linear combination of the stored values. It can be seen as a “soft” associative memory capable of interpolation. One advantage of it is that, with a proper allocation scheme of new key/value slots, it is capable of one-shot learning, yet can interpolate between keys and is end-to-end differentiable. | 短时记忆可以实现为键值记忆网络中的记忆模块??将查询向量与多个关键向量进行比较,产生得分向量。分数被归一化并用作系数,以输出存储值的线性组合。它可以被看作是一个能够插值的“软”联想记忆。它的一个优点是,通过新的键/值槽的适当分配方案,它能够一次性学习,还可以在键之间进行插值,并且是端到端可区分的。 |
4 Designing and Training the World Model
| Arguably, designing architectures and training paradigms for the world model constitute the main obstacles towards real progress in AI over the next decades. One of the main contributions of the present proposal is precisely a hierarchical architecture and a training procedure for world models that can represent multiple outcomes in their predictions. | 可以说,为世界模型设计架构和训练范式构成了未来几十年人工智能真正进步的主要障碍。本建议的一个主要贡献就是为世界模型提供了一个层次结构和一个训练程序,这些世界模型可以在它们的预测中表示多种结果 |
| Training the world model is a prototypical example of Self-Supervised Learning (SSL), whose basic idea is pattern completion. The prediction of future inputs (or temporarily unobserved inputs) is a special case of pattern completion. In this work, the primary purpose of the world model is seen as predicting future representations of the state of the world. | 训练世界模型是自监督学习(SSL)的一个典型例子,其基本思想是模式补全。未来输入(或暂时未观察到的输入)的预测是模式补全的特殊情况。在这项工作中,世界模型的主要目的是预测世界状态的未来表现。 |
| There are three main issues to address. First, quite evidently, the quality of the world model will greatly depend on the diversity of state sequences, or triplets of (state, action, resulting state) it is able to observe while training. Second, because the world is not entirely predictable, there may be multiple plausible world state representations that follow a given world state representation and an action from the agent. The world model must be able to meaningfully represent this possibly-infinite collection of plausible predictions. Third, the world model must be able to make predictions at different time scales and different levels of abstraction. | 有三个主要问题需要解决。首先,很明显,世界模型的质量将在很大程度上取决于它在训练时能够观察到的状态序列或三元组(状态、动作、结果状态)的多样性。第二,因为世界不是完全可预测的,所以在给定的世界状态表示和代理的动作之后,可能有多个似乎合理的世界状态表示。世界模型必须能够有意义地代表这个可能无限的似是而非的预测集合。第三,世界模型必须能够在不同的时间尺度和不同的抽象层次上做出预测。 |
| The first issue touches on one of the main questions surrounding learning for sequential decision processes: the diversity of the “training set” depends on the actions taken. The issue is discussed in Section 4.10 below. | 第一个问题触及了围绕顺序决策过程学习的一个主要问题:“训练集”的多样性取决于所采取的行动。这个问题将在下面的第4.10节中讨论。 |
| The second issue is even more dire: the world is not entirely predictable. Hence, the world model should be able to represent multiple plausible outcomes from a given state and (optionally) an action. This may constitute one of the most difficult challenges to which the present proposal brings a solution. This issue is discussed in Section 4.8 below. | 第二个问题更加可怕:这个世界并不完全可以预测。因此,世界模型应该能够代表来自给定状态和(可选的)一个动作的多种可能的结果。这可能是本提案解决的最困难的挑战之一。这个问题将在下面的第4.8节中讨论。 |
| The third issue relates to the problem of long-term prediction and planning. Humans plan complex goals at an abstract level and use high-level descriptions of the world states and actions to make predictions. High-level goals are then decomposed into sequences of more elementary sequences of subgoals, using shorter-term prediction from the world model to produce lower-level actions. This decomposition process is repeated all the way down to millisecond-by-millisecond muscle control, informed by local conditions. The question of how world models could represent action plans at multiple time scales and multiple levels of abstraction is discussed in Section 4.6 | 第三个问题涉及长期预测和规划问题。人类在抽象的层次上规划复杂的目标,并使用对世界状态和行动的高级描述来进行预测。然后,高级目标被分解为更基本的子目标序列,使用世界模型中的短期预测来产生低级行动。这种分解过程一直重复到由局部条件决定的毫秒级肌肉控制。世界模型如何在多个时间尺度和多个抽象层次上表示行动计划的问题将在第4.6节中讨论 |
4.1 Self-Supervised Learning
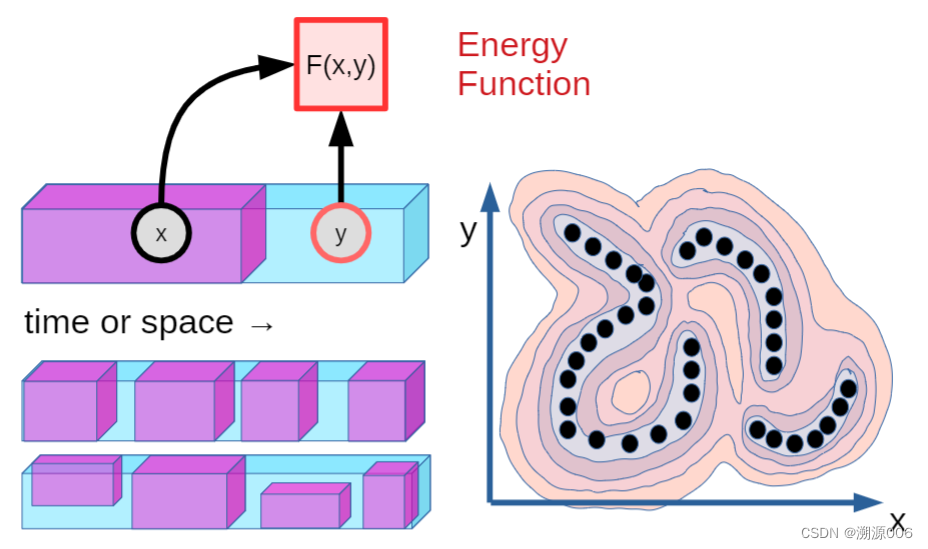
Figure 8: Self-Supervised Learning (SSL) and Energy-Based Models (EBM). SSL is a learning paradigm in which a learning system is trained to “fill in the blanks”, or more precisely to capture the dependencies between observed parts of the input and possibly unobserved parts of the input. Part of the input signal is observed and denoted x (in pink), and part of the input signal is either observed or unobserved and denoted y (in blue). In a temporal prediction scenario, x represents past and present observations, and y represent future observations. In a general pattern completion scenario, various parts of the input may be observed or unobserved at various times. The learning system is trained to capture the dependencies between x and y through a scalar-valued energy function F (x, y)that takes low values when x and y are consistent or compatible, and higher values if x and y are inconsistent or incompatible. In a video prediction scenario, the system would produce a low energy value if a video clip y is a plausible continuation of the video clip x. This energy-based model (EBM) formulation enables the system to represent multi-modal dependencies in which multiple values of y(perhaps an infinite set) may be compatible with a given x. In the right panel, an energy landscape is represented in which dark discs represent data points, and closed lines represents contours (level sets) of the energy function.
图8:自我监督学习(SSL)和基于能量的模型(EBM)。SSL是一种学习范式,其中学习系统被训练为“填空”,或者更准确地说,捕捉输入的观察部分和输入的可能未观察部分之间的依赖关系。输入信号的一部分被观察到并表示为x(粉红色),输入信号的一部分被观察到或未被观察到并表示为y(蓝色)。在时间预测场景中,x表示过去和现在的观测值,y表示未来的观测值。在一般的模式完成场景中,输入的各个部分可能在不同的时间被观察到或未被观察到。学习系统被训练成通过标量值能量函数F (x,y)来捕捉x和y之间的依赖性,当x和y一致或兼容时,该标量值能量函数F(x,y)取低值,而如果x和y不一致或不兼容,则取较高值。在视频预测场景中,如果视频剪辑y是视频剪辑x的似是而非的延续,则系统将产生低能量值。这种基于能量的模型(EBM)公式使系统能够表示多模态依赖性,其中y的多个值(可能是无穷集合)可以与给定的x兼容。在右侧面板中,表示了能量景观,其中黑色圆盘表示数据点,而闭合线表示能量函数的轮廓(水平集)。
| Self-Supervised Learning (SSL) is a paradigm in which a learning system is trained to capture the mutual dependencies between its inputs. Concretely, this often comes down to training a system to tell us if various parts of its input are consistent with each other. | 自我监督学习(SSL)是一种范式,其中学习系统被训练来捕捉其输入之间的相互依赖性。具体来说,这通常归结为训练一个系统来告诉我们其输入的各个部分是否彼此一致。 |
| For example, in a video prediction scenario, the system is given two video clips, and must tell us to what degree the second video clip is a plausible continuation of the first one. In a pattern completion scenario, the system is given part of an input (image, text, audio signal) together with a proposal for the rest of the input, and tells us whether the proposal is a plausible completion of the first part. In the following, we will denote the observed part of the input by x and the possibly-unobserved part by y. | 例如,在视频预测场景中,系统被给予两个视频剪辑,并且必须告诉我们第二个视频剪辑在多大程度上是第一个视频剪辑的合理延续。在模式完成场景中,系统被给予输入的一部分(图像、文本、音频信号)以及对输入的其余部分的建议,并告诉我们该建议是否是第一部分的合理完成。在下文中,我们将用x表示输入的观察部分,用y表示可能未观察到的部分。 |
| Importantly, we do not impose that the model be able to predict y from x. The reason is that there may be an infinite number of y that are compatible with a given x. In a video prediction setting, there is an infinite number of video clips that are plausible continuations of a given clip. It may be difficult, or intractable, to explicitly represent the set of plausible predictions. But it seems less inconvenient to merely ask the system to tell us if a proposedy is compatible with a given x. | 重要的是,我们不强制要求模型能够从x预测y。原因是可能有无限数量的y与给定的x兼容。在视频预测设置中,有无限数量的视频剪辑是给定剪辑的合理延续。显式地表示一组似是而非的预测可能是困难的,或者是棘手的。但是仅仅要求系统告诉我们一个被提议的y是否与一个给定的x兼容,似乎不那么不方便。 |
| A general formulation can be done with the framework of Energy-Based Models (EBM). The system is a scalar-valued function F (x, y) that produces low energy values when x andy are compatible and higher values when they are not. The concept is depicted in Figure 8. Data points are black dots. The energy function produces low energy values around the data points, and higher energies away from the regions of high data density, as symbolized by the contour lines of the energy landscape. The EBM implicit function formulation enables the system to represent multi-modal dependencies in which multiple values of y are compatible with a given x. The set of y compatible with a given x may be a single point, multiple discrete points, a manifold, or a collection of points and manifolds. | 一个通用的公式可以用基于能量的模型(EBM)的框架来完成。该系统是一个标量值函数F (x,y ),当x和y相容时产生低能量值,当它们不相容时产生较高的值。这个概念如图8所示。数据点是黑点。能量函数在数据点周围产生低能量值,在远离高数据密度的区域产生较高能量,如能量景观的等高线所象征的。EBM隐函数公式使系统能够表示多模态依赖性,其中y的多个值与给定的x兼容。与给定的x兼容的y的集合可以是单点、多个离散点、流形或点和流形的集合。 |
| To enable Mode-2 planning, a predictive world model should be trained to capture the dependencies between past and future percepts. It should be able to predict representations of the future from representations of the past and present. The general learning principle is as follows: given two inputs x and y, learn two functions that compute representations s x = g x ( x ) s_x = g_x(x) sx=gx(x) and s y = g y ( y ) s_y = g_y(y) sy=gy(y) such that (1) sx and sy are maximally informative about x andy and (2) sy can easily be predicted from s x s_x sx. This principle ensures a trade-off between making the evolution of the world predictable in the representation space, and capturing as much information as possible about the world state in the representation. | 为了实现模式2规划,应该训练预测世界模型来捕捉过去和未来感知之间的依赖性。它应该能够从过去和现在的表象中预测未来的表象。一般的学习原理如下:给定两个输入x和y,学习计算表达式 s x = g x ( x ) s_x = g_x(x) sx=gx(x)和 s y = g y ( y ) s_y = g_y(y) sy=gy(y)的两个函数,使得(1) s x s_x sx和 s y s_y sy最大限度地提供关于x和y的信息,以及(2) s y s_y sy以容易地从 s x s_x sx预测。这一原则确保了在使世界的演变在表示空间中可预测和在表示中捕获尽可能多的关于世界状态的信息之间的平衡。 |
| What concepts could such an SSL system learn by being trained on video? Our hypothesis is that a hierarchy of abstract concepts about how the world works could be acquired. | 这样的SSL系统通过视频训练可以学到什么概念?我们的假设是,可以获得关于世界如何运转的抽象概念的层次结构。 |
| Learning a representation of a small image region such that it is predictable from neighboring regions surrounding it in space and time would cause the system to extract local edges and contours in images, and to detect moving contours in videos. Learning a representation of images such that the representation of a scene from one viewpoint is predictable from the representation of the same scene from a slightly different viewpoint would cause the system to implicitly represent a depth map. A depth map is the simplest way to explain how a view of a scene changes when the camera moves slightly. Once the notion of depth has been learned, it would become simple for the system to identify occlusion edges, as well as the collective motion of regions belonging to a rigid object. An implicit representation of 3D objects may spontaneously emerge. Once the notion of object emerges in the representation, concepts like object permanence may become easy to learn: objects that disappear behind others due to parallax motion will invariably reappear. The distinction between inanimate and animate object would follow: inanimate object are those whose trajectories are easily predictable. Intuitive physics concepts such as stability, gravity, momentum, may follow by training the system to perform longer-term predictions at the object representation level. One may imagine that through predictions at increasingly abstract levels of representation and increasingly long time scales, more and more complex concepts about how the world works may be acquired in a hierarchical fashion. | 学习小图像区域的表示,使得它可以从在空间和时间上围绕它的相邻区域中预测,这将使系统提取图像中的局部边缘和轮廓,并检测视频中的移动轮廓。学习图像的表示,使得来自一个视点的场景的表示可以从来自稍微不同的视点的相同场景的表示中预测出来,这将使得系统隐式地表示深度图。深度图是解释相机轻微移动时场景视图如何变化的最简单方式。一旦学习了深度的概念,系统识别遮挡边缘以及属于刚性对象的区域的集体运动将变得简单。3D对象的隐式表示可能会自发出现。一旦对象的概念出现在表现中,像对象持久性这样的概念可能变得容易学习:由于视差运动而消失在其他对象后面的对象将总是重新出现。无生命物体和有生命的物体之间的区别如下:无生命的物体是那些轨迹容易预测的物体。直观的物理概念,例如稳定性、重力、动量,可以通过训练系统在对象表示级别执行长期预测来跟随。人们可以想象,通过在越来越抽象的表现层次和越来越长的时间尺度上的预测,越来越多的关于世界如何运转的复杂概念可能会以一种分层的方式被获得。 |
| The idea that abstract concepts can be learned through prediction is an old one, formulated in various way by many authors in cognitive science, neuroscience, and AI over several decades. The question is how to do it, precisely. | 抽象概念可以通过预测来学习的想法是一个古老的想法,由认知科学、神经科学和人工智能的许多作者在几十年里以不同的方式制定。准确地说,问题是如何去做。 |
4.2 Handling Uncertainty with Latent Variables
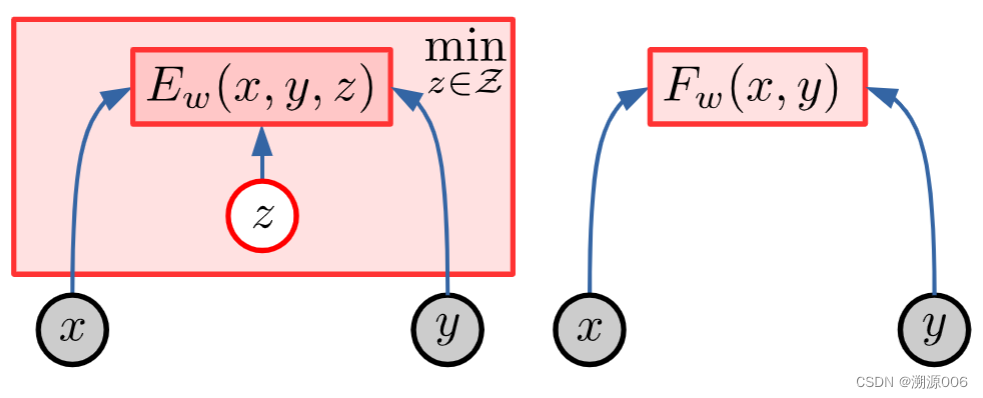
Figure 9: Latent-Variable Energy-Based Model (LVEBM). To evaluate the degree of compatibility between x and y, an EBM may need the help of a latent variablez. The latent variable can be seen as parameterizing the set of possible relationships between an xand a set of compatible y. Latent variables represent information about y that cannot be extracted from x. For example, if x is a view of an object, and y another view of the same object, z may parameterize the camera displacement between the two views. Inference consists in finding the latent that minimizes the energy
ˇ
z
=
a
r
g
m
i
n
z
∈
Z
E
w
(
x
,
y
,
z
)
ˇz = argmin_{z∈Z} E_w(x, y, z)
ˇz=argminz∈ZEw(x,y,z). The resulting energy
F
w
(
x
,
y
)
=
E
w
(
x
,
y
,
ˇ
z
)
F_w(x, y) = E_w(x, y, ˇz)
Fw(x,y)=Ew(x,y,ˇz)only depends on x and y. In the dual view example, inference finds the camera motion that best explains how x could be transformed into y.
图9:基于潜在变量能量的模型(LVEBM)。为了评估x和y之间的相容程度,EBM可能需要潜在变量z的帮助。潜在变量可以被视为参数化xan和一组兼容的y之间的一组可能的关系。潜在变量表示不能从x提取的关于y的信息。例如,如果x是一个对象的视图,而y是同一对象的另一个视图,则z可以参数化两个视图之间的相机位移。推断在于找到使能量最小化的潜在值
ˇ
z
=
a
r
g
m
i
n
z
∈
Z
E
w
(
x
,
y
,
z
)
ˇz = argmin_{z∈Z} E_w(x, y, z)
ˇz=argminz∈ZEw(x,y,z)。产生的能量
F
w
(
x
,
y
)
=
E
w
(
x
,
y
,
ˇ
z
)
F_w(x, y) = E_w(x, y, ˇz)
Fw(x,y)=Ew(x,y,ˇz)仅取决于x和y。在双视图示例中,推理找到了最能解释x如何转换为y的相机运动。
| As was pointed out above, one of the main issues is enabling the model to represent multiple predictions. This may require the use of a latent variable. A latent variable is an input variable whose value is not observed but inferred. A latent variable can be seen as parameterizing the set of possible relationships between an x and a set of compatible y. Latent variables are used to represent information about y that cannot be extracted fromx. | 如上所述,主要问题之一是使模型能够表示多种预测。这可能需要使用潜在变量。潜在变量是一个输入变量,其值不是观察到的,而是推断出来的。潜在变量可以被视为参数化x和一组相容的y之间的一组可能的关系。潜在变量用于表示不能从x中提取的关于y的信息。 |
| Imagine a scenario in which x is a photo of a scene, and y a photo of the same scene from a slightly different viewpoint. To tell whether x and y are indeed views from the same scene, one may need to infer the displacement of the camera between the two views. Similarly, if x is a picture of a car coming to a fork in the road, and y is a picture of the same car a few seconds later on one of the branches of the fork, the compatibility betweenx and y depends on a binary latent variable that can be inferred: did the car turn left or right. | 想象一个场景,其中x是一个场景的照片,y是从稍微不同的视点拍摄的同一场景的照片。要判断x和y是否确实是同一场景的视图,可能需要推断两个视图之间的摄像机位移。类似地,如果x是一辆汽车来到道路岔口的照片,y是同一辆汽车几秒钟后在岔口的一个分支上的照片,那么x和y之间的兼容性取决于一个可以推断的二元潜在变量:汽车左转还是右转。 |
| In a temporal prediction scenario, the latent variable represents what cannot be predicted about y (the future) solely from x and from past observations (the past). It should contain all information that would be useful for the prediction, but is not observable, or not knowable. I may not know whether the driver in front of me will turn left or right, accelerate or brake, but I can represent those options by a latent variable. | 在时间预测场景中,潜在变量表示仅从x和过去的观察值(过去)无法预测y(未来)的情况。它应该包含对预测有用的所有信息,但这些信息是不可观察的或不可知的。我可能不知道我前面的司机会左转还是右转,会加速还是刹车,但我可以用一个潜变量来表示那些选项。 |
| A latent-variable EBM (LVEBM) is a parameterized energy function that depends on x , y x, y x,y, and z : E w ( x , y , z ) z: E_w(x, y, z) z:Ew(x,y,z). When presented with a pair ( x , y ) (x, y) (x,y) the inference procedure of the EBM finds a value of the latent variable z that minimizes the energy | 潜变量EBM (LVEBM)是一个参数化的能量函数,它取决于 x , y x, y x,y, and z : E w ( x , y , z ) z: E_w(x, y, z) z:Ew(x,y,z)。当呈现一对 ( x , y ) (x,y) (x,y)时,EBM的推理过程找到最小化能量的潜在变量z的值 |
| z = a r g m i n z ∈ Z E w ( x , y , z ) (4) z = argmin_{z∈Z}E_w(x, y, z) \tag{4} z=argminz∈ZEw(x,y,z)(4) | |
| This latent-variable inference by minimization allows us to eliminate z from the energy function: | 这种通过最小化的潜在变量推断允许我们从能量函数中消除z: |
| F w ( x , y ) = m i n z ∈ Z E w ( x , y , z ) = E w ( x , y , ˇ z ) (5) F_w(x, y) = min_{z∈Z }E_w(x, y, z) = E_w(x, y, ˇz) \tag{5} Fw(x,y)=minz∈ZEw(x,y,z)=Ew(x,y,ˇz)(5) | |
| Technically, F w ( x , y ) F_w(x, y) Fw(x,y) should be called a zero-temperature free energy, but we will continue to call it the energy. | 从技术上讲, F w ( x , y ) F_w(x,y) Fw(x,y)应该叫做零温自由能,但我们将继续称它为能量。 |
4.3 Training Energy-Based Models
| Before we discuss EBM training, it is important to note that the definition of EBM does not make any reference to probabilistic modeling. Although many EBMs can easily be turned into probabilistic models, e.g. through a Gibbs distribution, this is not at all a necessity. Hence the energy function is viewed as the fundamental object and is not assumed to implicitly represent the unnormalized logarithm of a probability distribution. | 在我们讨论EBM训练之前,有一点很重要,那就是EBM的定义并没有提到概率建模。虽然许多EBM可以很容易地转换成概率模型,例如通过吉布斯分布,但这根本不是必需的。因此,能量函数被视为基本对象,并且不被假定为隐含地表示概率分布的非标准化对数。 |
| Training an EBM consists in constructing an architecture (e.g. a deep neural network) to compute the energy function F w ( x , y ) F_w(x, y) Fw(x,y) parameterized with a parameter vector w. The training process must seek a w vector that gives the right shape to the energy function. For a given x from the training set, a well-trained F w ( x , y ) F_w(x, y) Fw(x,y) will produce lower energies for values of y that are associated with x in the training set, and higher energies to other values of y. | 训练EBM包括构建一个体系结构(例如深度神经网络)来计算用参数向量w参数化的能量函数 F w ( x , y ) F_w(x,y) Fw(x,y)。训练过程必须寻找一个w向量,该向量给出能量函数的正确形状。对于来自训练集的给定x,训练良好的 F w ( x , y ) F_w(x,y) Fw(x,y)将为与训练集中的x相关联的y值产生较低的能量,并为y的其他值产生较高的能量 |
| Given a training sample (x, y), training an EBM comes down to devising a suitable loss functional L(x, y, Fw(x, y)), which can be expressed directly as a function of the parameter vector L(x, y, w), and such that minimizing this loss will make the energy of the training sample Fw(x, y) lower than the energies Fw(x, ˆy) of any ˆy different from y. | 给定训练样本(x,y),训练EBM归结为设计合适的损失泛函L(x,y,Fw(x,y)),其可以直接表示为参数向量L(x,y,w)的函数,并且使得最小化该损失将使得训练样本Fw(x,y)的能量低于不同于y的任何y的能量Fw(x,y) |
| Making the energy of the training sample low is easy: it is sufficient for the loss to be an increasing function of the energy, and for the energy to have a lower bound. | 使训练样本的能量变低是容易的:损失是能量的增函数,并且能量具有下限就足够了。 |
| The difficult question is how to ensure that the energies of ˆy different from y are higher than the energy of y. Without a specific provision to ensure that Fw(x, y′) > Fw(x, y) whenever ˆy 6 = y the energy landscape may suffer a collapse: given an x the energy landscape could become “flat”, giving essentially the same energy to all values of y. | 困难的问题是如何确保与y不同的y的能量高于y的能量。如果没有具体的规定来确保Fw(x,y’)> Fw(x,y),那么每当y ^ 6 = y时,能源格局可能会崩溃:给定x,能源格局可能会变得“平坦”,给y的所有值提供本质上相同的能量。 |
| What EBM architectures are susceptible to collapse? Whether an EBM may be susceptible to collapse depends on its architecture. Figure 10 shows a number of standard architectures and indicates whether they can be subject to collapse. | 哪些EBM架构容易崩溃?EBM是否容易崩溃取决于它的架构。图10显示了许多标准架构,并指出它们是否会崩溃。 |
4.4 Joint Embedding Predictive Architecture (JEPA)
4.5 Training a JEPA
4.5.1 VICReg
4.5.2 Biasing a JEPA towards learning “useful” representations
4.6 Hierarchical JEPA (H-JEPA)
4.7 Hierarchical Planning
4.8 Handling uncertainty
4.8.1 World Model Architecture
4.9 Keeping track of the state of the world
4.10 Data Streams
5 Designing and Training the Actor
6 Designing the Configurator
7 Related Work
7.1 Trained World Models, Model-Predictive Control, Hierarchical PLanning
7.2 Energy-Based Models and Joint-Embedding Architectures
7.3 Human and animal cognition
8 Discussion, Limitations, Broader Relevance
8.1 What is missing from the Proposed Model?
8.2 Broader Relevance of the Proposed Approach
8.2.1 Could this Architecture be the Basis of a Model of Animal Intelligence?
8.2.2 Could this be a Path towards Machine Common Sense?
8.3 Is it all about scaling? Is reward really enough?
8.3.1 Scaling is not enough
8.3.2 Reward is not enough
8.3.3 Do We Need Symbols for Reasoning?
Acknowledgments
参考:
【1】Yann Lecun: A Path Towards Autonomous Machine Intelligence 自主机器学习和AGI

