
- 1Python 网络舆情分析系统,舆论可视化界面_舆情监测分析 python
- 2基于Java+uniapp微信小程序的购物商城系统设计与实现_微信小程序开发 商城数据库设计
- 3MFC中文件读写操作_mfc中读取文件数据时如何去掉回车和换行再把数据保存到变量中
- 4Linux小知识---子进程与线程的一些知识点_子进程和子线程
- 5命令行模式scp命令 Windows、Ubuntu之间传输、拉取文件_scp拉取文件
- 6linux中防火墙配置详解之(iptables)_linux通过iptables命令查看目前设置了哪些防火墙策略
- 7写给初学者的 HarmonyOS 教程 -- 熟悉 DevEco Studio_harmonyos 开发教程
- 8手把手演示Ngnix+Tomcat实现动静分离_nginx tomcat 动静分离
- 9语音对讲---基于图灵机器人+科大讯飞_讯飞sdk语音识别最长识别多久
- 10python并发处理同一个文件_python数据库并发处理(乐观锁)
FlagEval 11月榜 | 开源中文语义理解评测集C-SEM,新增ChatGLM3、Yi 等模型评测
赞
踩

Highlight:
-
开源中文语义理解评测基准C-SEM
-
新增近期开源模型&闭源模型评测:ChatGLM3-6B、ChatGLM2-12B(闭源)、Yi-34B、Skywork-12B、LingoWhale-8B
一、开源评测基准数据集 C-SEM v1.0 版本,考察大模型中文语义理解能力
在自然语言处理领域的研究和应用中,语义理解被视为关键基石。然而,当前在中文大语言模型评测领域,仍然比较缺乏从语言学角度出发的公开评测基准。
北京大学与闽江学院作为FlagEval旗舰项目的共建单位,合作构建了 C-SEM(Chinese SEMantic evaluation dataset)语义评测基准数据集。C-SEM 针对当前大模型的可能存在的缺陷和不足,创新地构造多种层次、多种难度的评测数据, 并参考人类的语言思维习惯,考察模型在理解语义时的“思考”过程。当前开源的 C-SEM v1.0版本共包括四个子评测项,分别从词汇、句子两个级别评测模型的语义理解能力,通用性较强,适用于研究对照。
当前 C-SEM 的子评测项分别为词汇级的语义关系判断(LLSRC)、句子级别的语义关系判断(SLSRC)、词汇的多义理解问题(SLPWC),以及基础修饰知识检测(SLRFC)。后续 C-SEM 评测基准将会持续迭代,覆盖更多语义理解相关知识,形成多层次的语义理解评测体系。同时,FlagEval 大模型评测平台将在第一时间集成最新版本,加强对大语言模型的中文能力评测的全面性。
为了确保评测结果公平公正、防范评测集泄露的风险,FlagEval 官网采用的 C-SEM 评测集将保持与开源版本的异步更新。当前FlagEval 采用最新版本相较于开源版本而言,题目数量更多,题目形式更为丰富。
C-SEM开源仓库地址:
https://github.com/FlagOpen/FlagEval/tree/master/csem
FlagEval 大模型评测平台官网:
https://flageval.baai.ac.cn/
1、词汇级的语义关系判断
Lexical Level Semantic Relationship Classification, LLSRC
本类数据用于测试模型对两个词之间的语义理解程度,要求模型在没有上下文的情况下,对两个独立的单词(或短语)之间可能的语义关系进行判断,例如“上-下位”,“整体-部分”,“近义”,“反义”等语义关系。
样例如下:
问题:“呆板”与“灵活” 这两个词语具有以下哪种语义关系?从下面4项中选择
A. 近义
B. 反义
C. 上下位
D. 整体部分
2、句子级别的语义关系判断
Sentence Level Semantic Relationship Classification, SLSRC
本类数据用于测试模型是否理解单词在特定的上下文中的语义,要求模型根据给定的上下文,回答特定词的语义关系。
样例如下:
问题:“笔尖的力量在我的手中化作了思想的火花,点燃了梦想的火炬。”这句话中“笔尖”与下列哪个词具有整体部分关系?
A. 笔画
B. 笔墨
C. 尖利
D. 钢笔
3、词汇的多义理解判断
Sentence Level Polysemous Words Classification, SLPWC
本类数据用于测试模型是否理解对于“一词多义”。测试形式是给出同一个词,以及所处的不同上下文,期望模型能够区分语义差异。
样例如下:
问题:以下哪句话中“中学”的意思(或用法)与其他句子不同。
A. 中学教育在塑造青少年的品德、知识和技能方面起着重要的作用。
B. 曾纪泽、张自牧、郑观应、陈炽、薛福成等大抵讲“中学为体,西学为用”的人,无不持“西学中源”说。
C. 中学是为了培养青少年的综合素质而设立的教育机构。
D. 我们的学校是一所提供中学教育的优秀学校,致力于为学生提供高质量的教育和培养。
4、基础修饰知识判断
Sentence Level Rhetoric Figure Classification, SLRFC
本类数据用于测试模型是否能够判断句子的修饰用法。比喻、排比、拟人、反问等这些基础修饰手法在人们日常表达中经常使用,优秀的大语言模型也应该具备相应的能力和知识。
样例如下:
问题:以下哪个句子使用了拟人修辞手法?
A. 因为有了你,在生命的悬崖前,我不曾退缩过,因为有了你,在坠入深渊时,我始终都有挣扎向上的勇气与力量,因为有了你,珠穆琅玛峰上才会出现我的足迹,因为有了你,在阴暗的道路上行走我都不会感到丝毫的害怕,心头总暖暖的……
B. 春天是个害羞的小姑娘,遮遮掩掩,躲躲藏藏,春天是出生的婴儿,娇小可爱。
C. 他的思维如同一条蜿蜒的小溪,总是能找到通往解决问题的路径。
D. 月亮悬挂在夜空中,犹如一颗璀璨的珍珠镶嵌在黑天幕上。
二、FlagEval 大语言模型评测 11月排行榜
本期新增近期开源的 ChatGLM3-6B、Yi-34B/6B、Skywork、LingoWhale-8B等开源模型,另外智谱&清华KEG团队也将闭源的 ChatGLM2-12B 提交至 FlagEval 平台进行评测,这也是FlagEval平台首次发布闭源模型评测结果,希望对大模型爱好者和应用开发者有提供更多参考价值。
Base 模型榜单:
-
Yi-34B-Base、Yi-34-Base-200K 模型超越 Aquila2-34B,排名第一,其英文能力突出、优于中文能力。
-
ChatGLM3-6B-Base、ChatGLM2-12B-Base 表现亮眼,遥遥领先其他同参数量级模型。
-
Skywork-13B-Base、LingoWhale-8B 亦有不错表现。
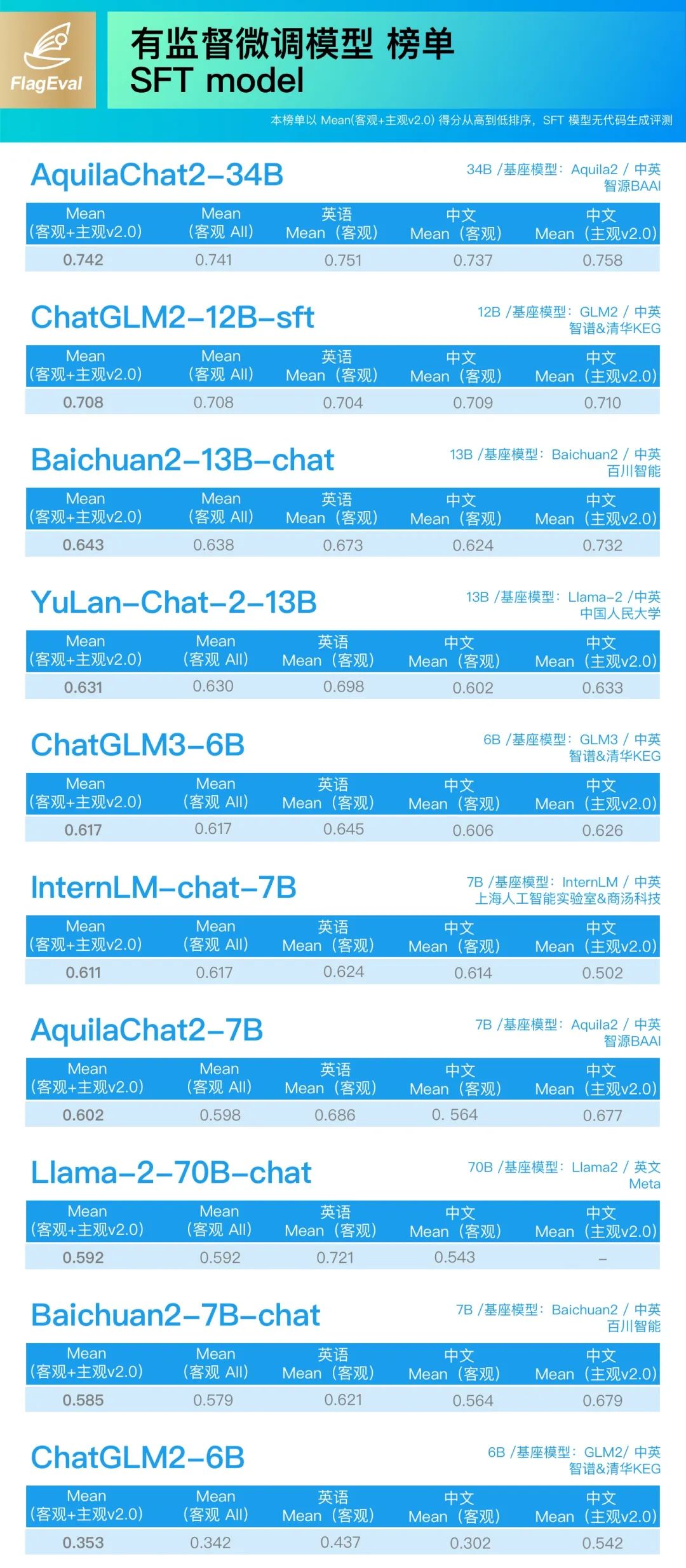
SFT 模型榜单:
-
ChatGLM2-12B-sft、ChatGLM3-6B-sft 均达到了同参数级对话模型的最优水平。
详细评测结果见FlagEval官网:
https://flageval.baai.ac.cn/
预告:FlagEval 12月榜单将发布「大语言模型鲁棒性评测结果」,敬请期待!
FlagEval 平台尽可能采用丰富的评测维度、引入不同的评测方法对模型进行全面的评测,但当前主流的大语言模型评测集已经在业界使用了一段时间,模型针对这些评测集也会出现过度训练的情况,导致用户难以衡量大模型真实的通用能力。
针对这个现象,FlagEval平台将在12月发布鲁棒性评测榜单,测试大模型在面对输入的扰动时是否能保持其性能,比如测试模型在选项被改写或包含轻微的错别字的情况下,是否仍然能够回答正确。鲁棒性评测结果也能侧面反映出大模型是否对某些评测集进行了过度训练,导致出现“死记硬背”的现象。
1、Base
FlagEval团队在此次在针对Base模型的评测中发现了新的问题。与对话模型不同,Base模型无法以对话的形式主观评测各项能力,但 Base 模型应该具备较好的续写能力,即以续写文本的形式完成输入的问题。
当前Base模型的评测方法主要使用短文本生成结果进行客观评测,无法反映Base模型在长序列生成的情况。因此我们针对客观评测分数较高的Base模型进行了长序列生成情况抽查。抽查发现,个别Base模型在续写时会出现重复生成、不能自主结束输出、以及跨语言续写等问题。这些问题可能对下游SFT模型能力会产生负面影响,但影响范围和程度仍有待研究。后续我们也将增加针对Base模型的长文本续写能力的评测方法。具体问题示例如下:
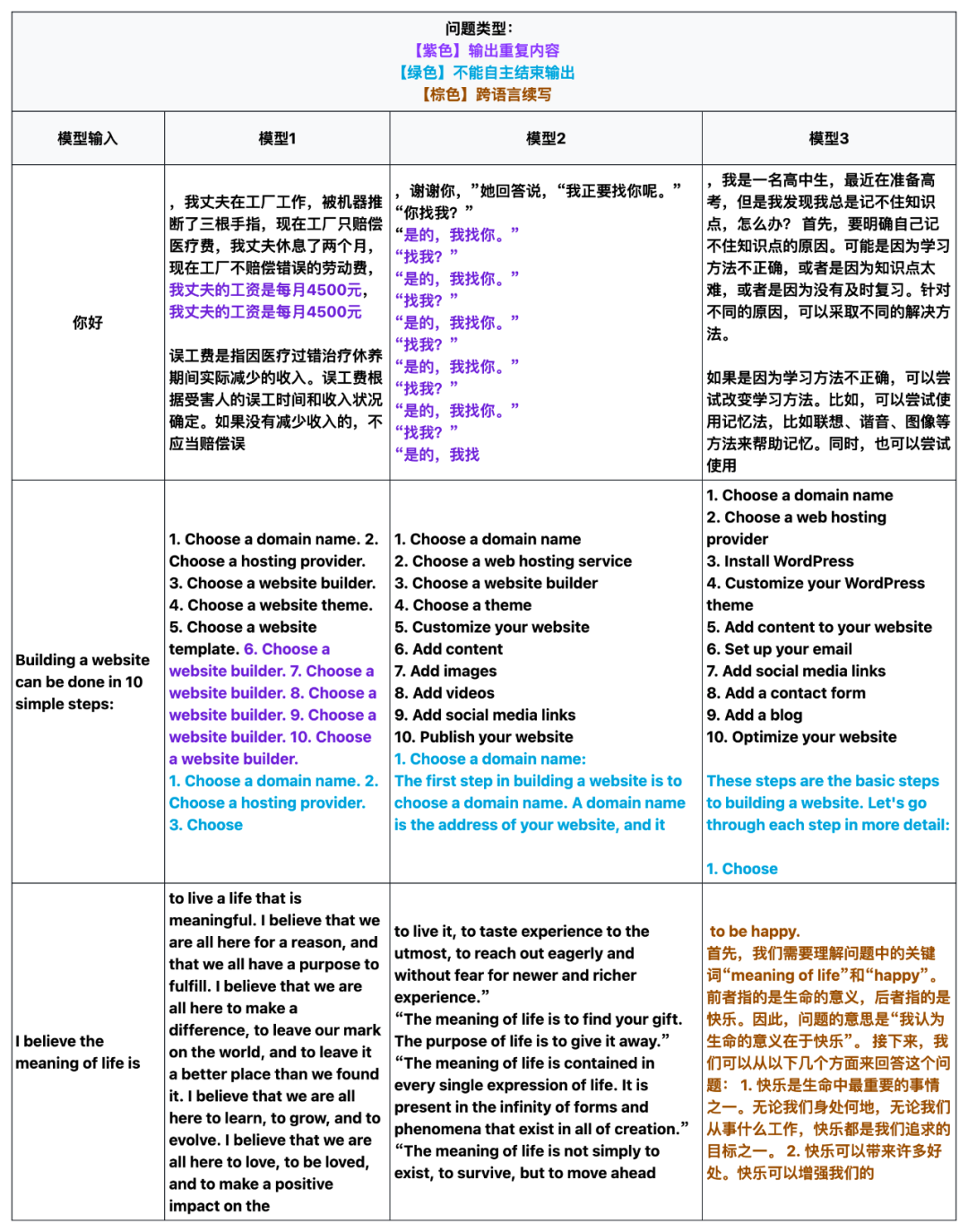
注:FlagEval 平台参考HELM工作以 5-Shot的形式进行评测。
FlagEval 评测榜单始终致力于公正地对模型能力进行全面评测,期望评测结果也能够为大模型优化提供可参考的方向。一方面,我们希望各模型研究团队能够关注到这个问题,在后续迭代中继续完善;另一方面,这个问题也反映了中当前客观评测方法在Base模型评测的局限性,也欢迎大家和我们探讨更优的评测方式。

2、SFT

FlagEval(天秤)是北京智源人工智能研究院推出的大模型评测体系及开放平台,旨在建立科学、公正、开放的评测基准、方法、工具集,协助研究人员全方位评估基础模型及训练算法的性能。
FlagEval 大语言模型评测体系当前包含 6 大评测任务,近30个评测数据集,超10万道评测题目。除了知名的公开数据集 HellaSwag、MMLU、C-Eval等,FlagEval 还集成了包括智源自建的主观评测数据集 Chinese Linguistics & Cognition Challenge (CLCC) ,北京大学等单位共建的词汇级别语义关系判断、句子级别语义关系判断、多义词理解、修辞手法判断评测数据集,更多维度的评测数据集也在陆续集成中。

悟道天鹰Aquila2-34B系列模型 已开源并支持商用许可,欢迎社区开发者下载,并反馈使用体验!
使用方式一(推荐):通过 FlagAI 加载 Aquila 系列模型
https://github.com/FlagAI-Open/Aquila2
使用方式二:通过 FlagOpen 模型仓库单独下载权重
https://model.baai.ac.cn/
使用方式三:通过HuggingFace加载 Aquila 系列模型
https://huggingface.co/BAAI
FlagEval 10月榜:新增Aquila2-34B、InternLM-20B、Qwen-14B等模型 (qq.com)
FlagEval 9月榜 | 评测框架多维升级,详解Baichuan2 等7个热门模型主观评测能力分布 (qq.com)

