- 1数据结构之单链表详解(C语言手撕)
- 2决策树剪枝python实现_决策树及其python实现
- 3Mac下编写C或C++_mac c++
- 4Android中SharedPreferences的理解_android sharepreference 创建了重复名字
- 5request.getParameter()、request.getInputStream()和request.getReader()
- 6Shell入门之二_for cls, ids in :
- 7girdview分组,统计,排序的解决方案_dev gridveiw 按字段分组后,按其他字段排序
- 8《HarmonyOS开发 – OpenHarmony开发笔记(基于小型系统)》第1章 OpenHarmony与Pegasus物联网开发套件简介_pegasus智能家居开发套件
- 9一站式在线协作开源办公软件ONLYOFFICE,协作更安全更便捷_在线office 开源
- 10临近秋招了,讲讲大家关心的问题_嵌入式秋招要刷leetcode吗
日志分析和ELK监控_elk日志监控
赞
踩
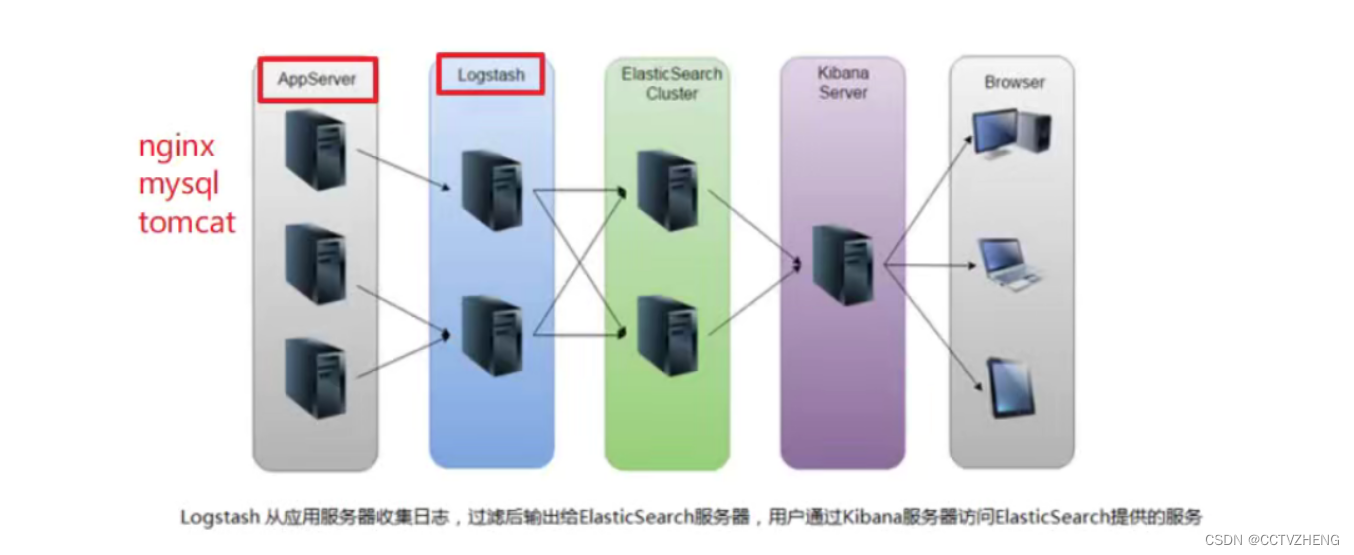
一、ELK引入

nginx的日志文件位置
二进制安装:/var/log/nginx/access.log
源码编译安装:/usr/local/nginx/logs/access.log

一般情况想要得到web服务器的PV和UV必须在日志轮转之前查看日志文件
PV (Page View)
页面访问量,即页面浏览量或点击量,用户每次刷新即被计算一次。可以统计服务一天的访问日志得到;
UV (Unique Visitor)
独立访客,统计1天内访问某站点的用户数。可以统计服务一天的访问日志并根据用户的唯一标识去重得到。响应时间(RT):响应时间是指系统对请求作出响应的时间,一般取平均响应时间。可以通过Nginx、Apache之类的Web Server得到。
二、ELK概述

三、环境准备
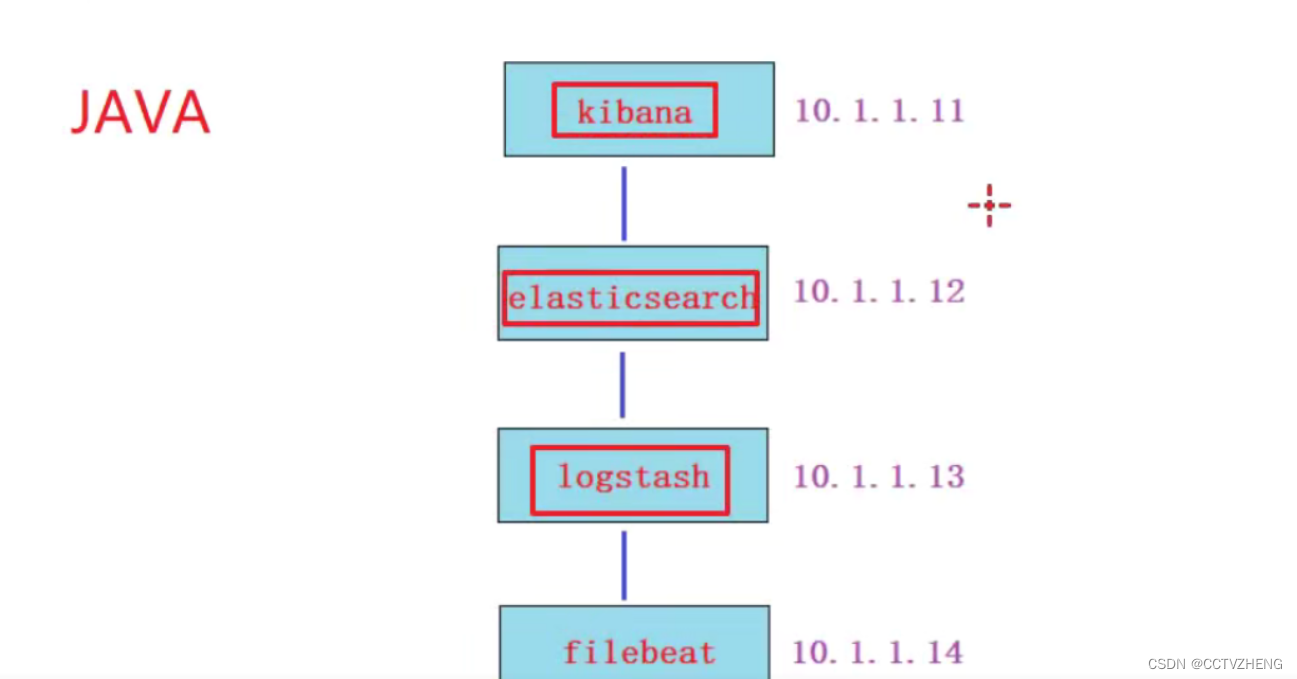

3、关闭防火墙和selinux 时间同步ntpd
四、单点elasticsearch的安装和配置
查找配置文件
 修改配置文件
修改配置文件


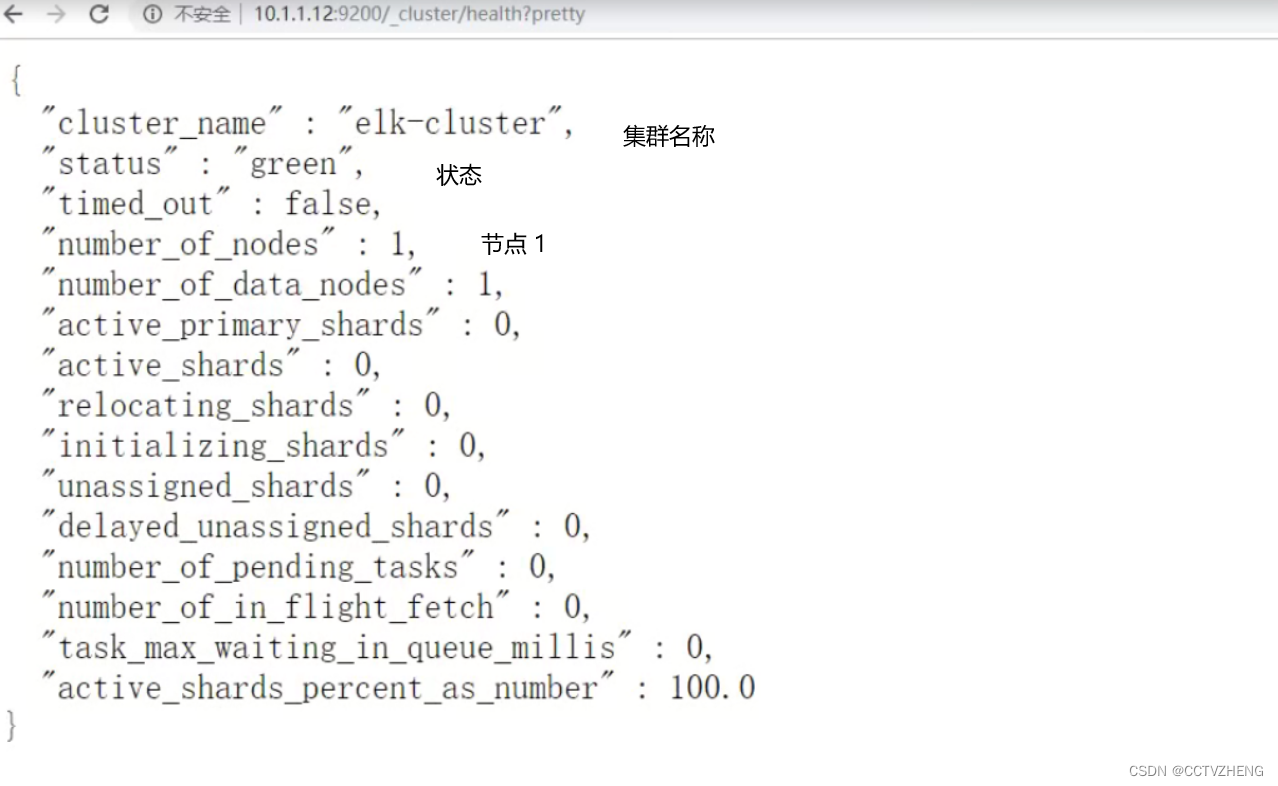
查看是服务是否启动成功
 最后用curl命令 或者 浏览器访问
最后用curl命令 或者 浏览器访问

五、elasticsearch集群的安装和配置
scp上传安装包到另外的 节点

打开network监听 和http端口
unicast 单播 点对点 multicast 组播 boardcast 广播
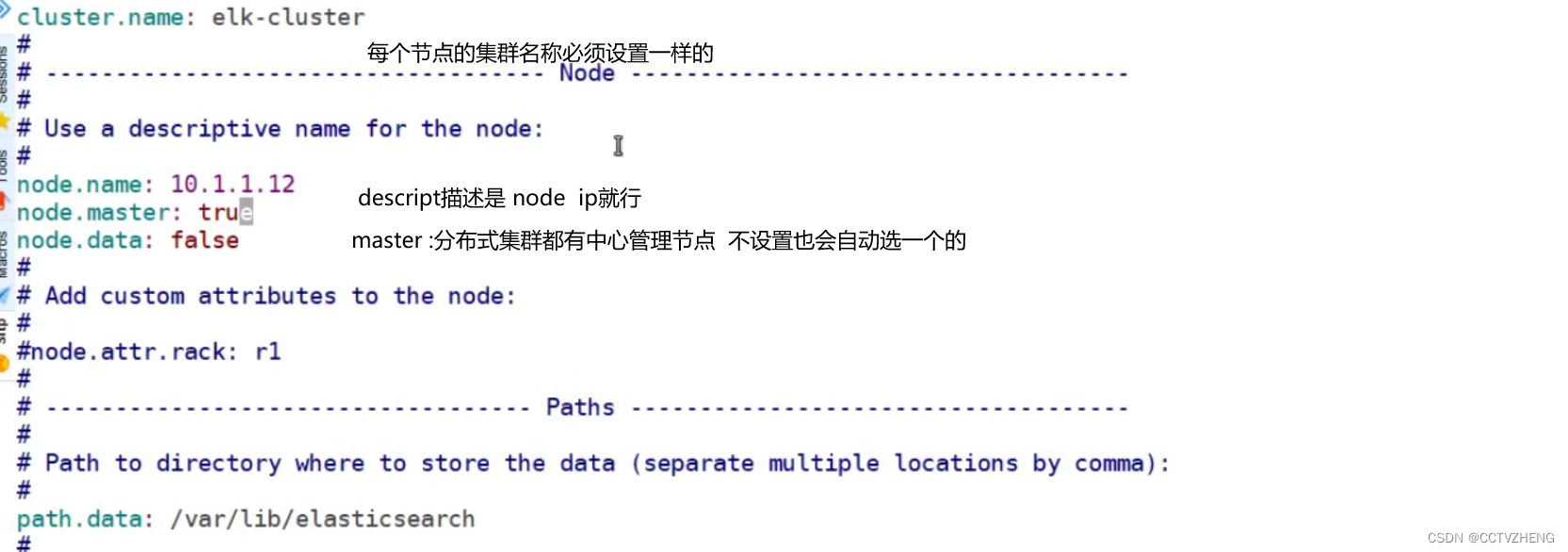
 这里每个节点都必须配置单播,并且把ip都写进配置文件用逗号隔开
这里每个节点都必须配置单播,并且把ip都写进配置文件用逗号隔开
node.master:true 就是中心管理节点 其他节点可以配置成false

systemctl enable elasticsearch
集群高可用的中心节点解决方法都差不多,都能防止脑裂
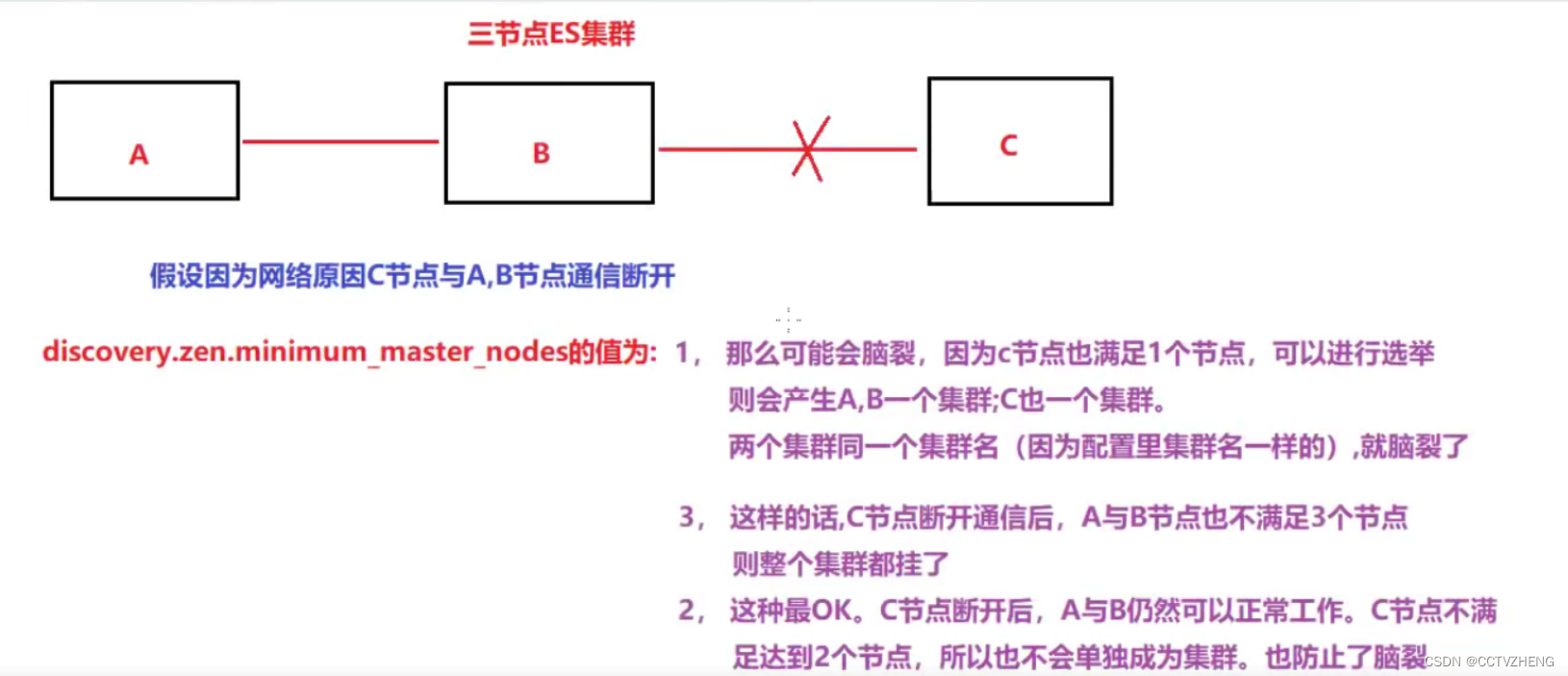

timeout是超时就踢出去,保证集群的高可用

elasticsearch中 一行日志就是document 一个日志文件就是index

和ceph分布式存储类似镜像备份实现高可用
API格式
增加和删除index


elasticsearch-head
 官网地址:https:/github.com/mobz/elasticsearch-head
官网地址:https:/github.com/mobz/elasticsearch-head
node.js下载页面: https://nodejs.org/en/download/


注意创建软链接必须把目录写对 要不然会报错


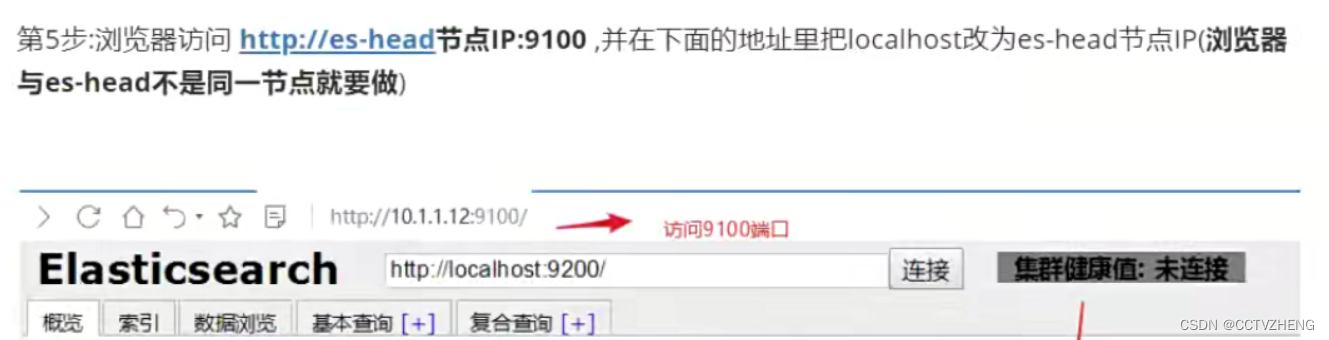
连接的ip必须都配置了下面的两个参数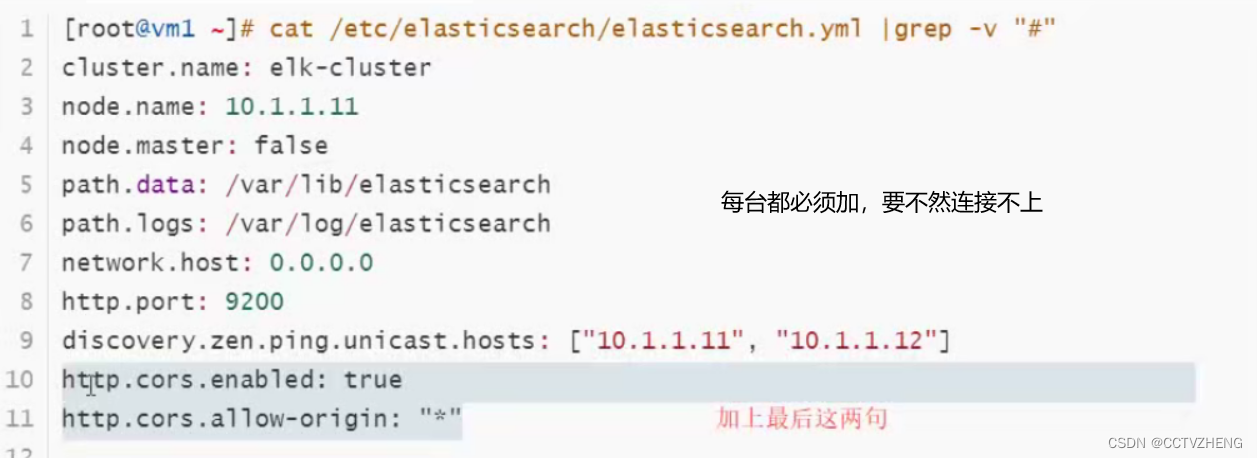
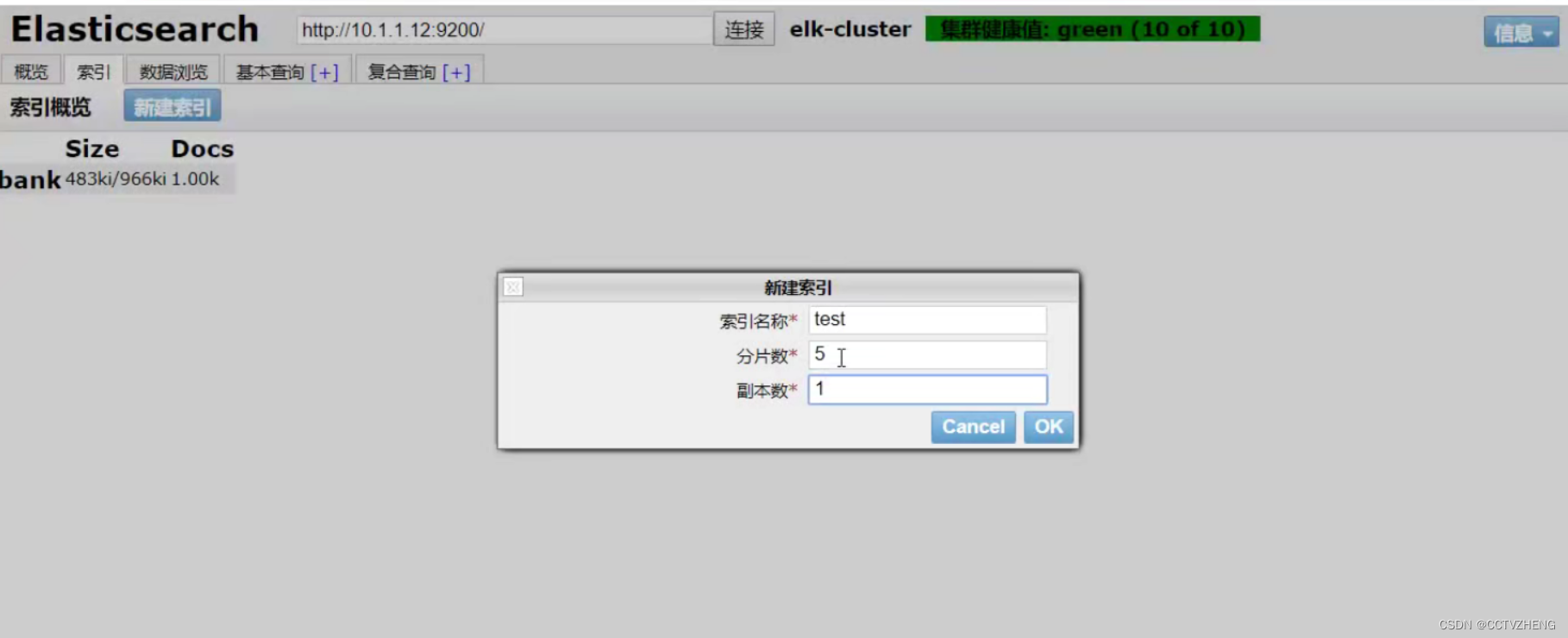
六、logstash
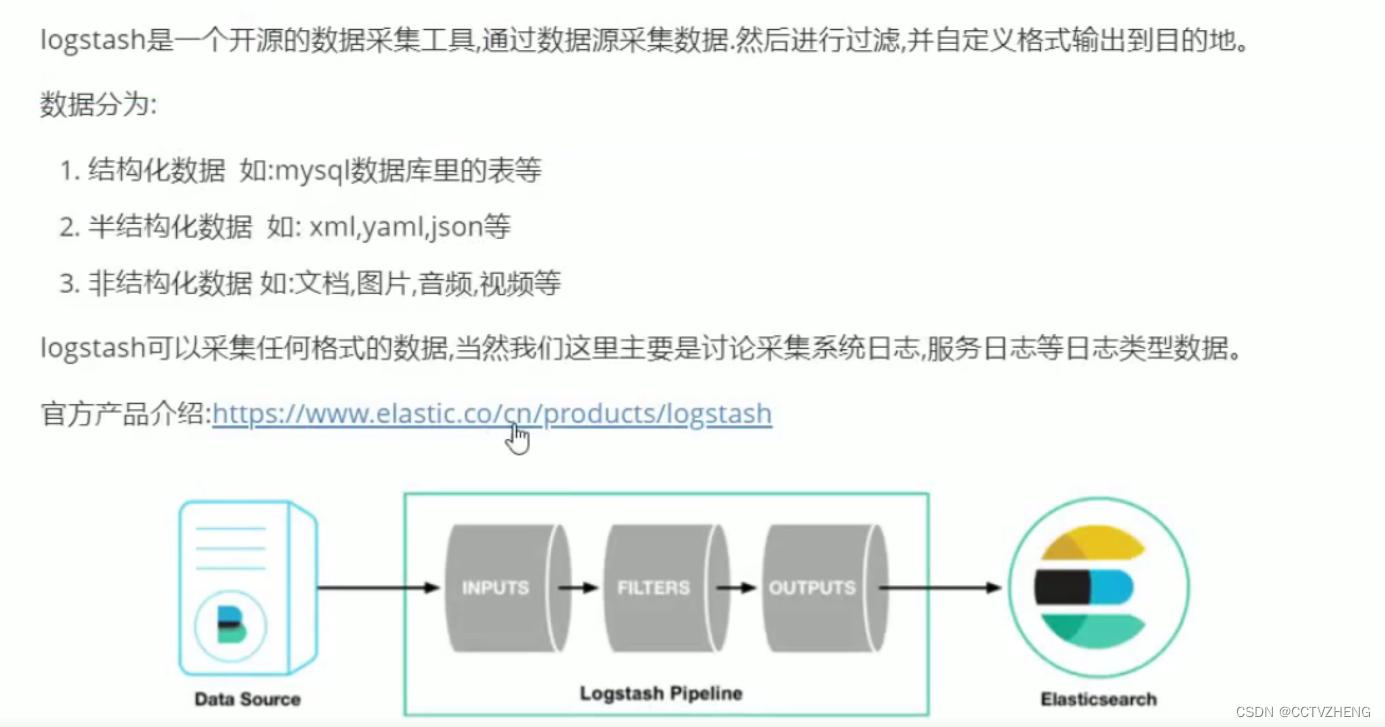
input插件:用于导入日志源(配置必须)
https://www.elastic.co/guide/en/logstash/current/input-plugins.html
filter插件:用于过滤(不是配置必须的)
https://www.elastic.co/guide/en/logstash/current/filter-plugins.html
output插件:用于导出(配置必须)
https://www.elastic.co/guide/en/logstash/current/output-plugins.html
6.1、logstash的安装和启动验证
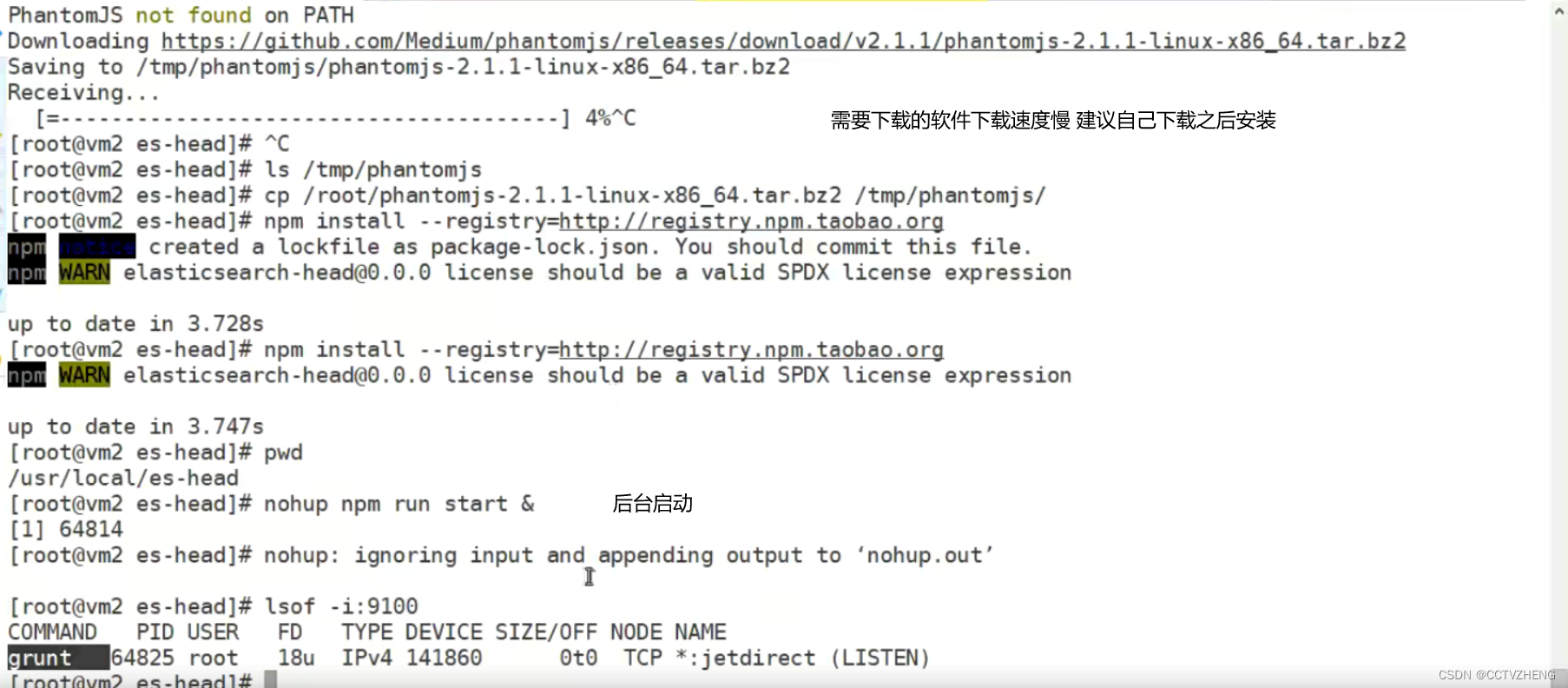
网络很慢,建议去阿里云镜像站里面找,但是这个软件没有
最好提前官网下载好
Releases · elastic/logstash (github.com)![]() https://github.com/elastic/logstash/releases
https://github.com/elastic/logstash/releases
最小化安装可能没有jdk


stden 标准输入法 指键盘输入的内容
通过标准输入和标准输出测试启动
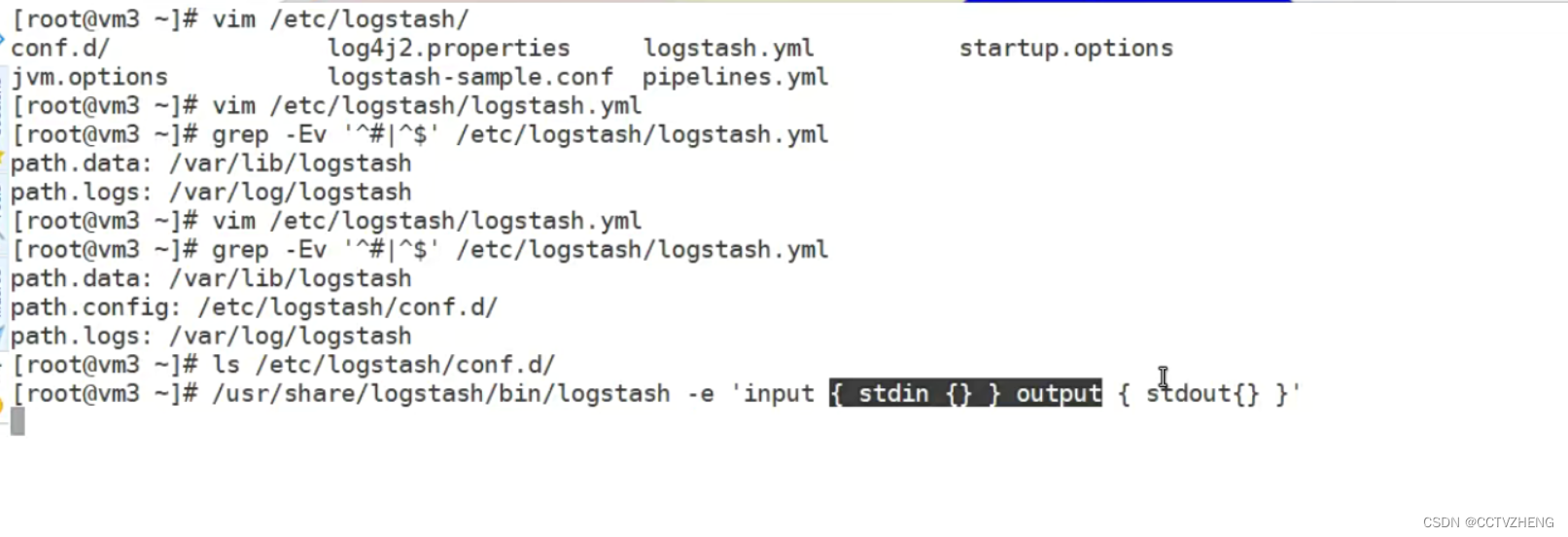
要等一会儿之后才能启动
启动成功之后可以键盘输入测试 message

第二种测试方法
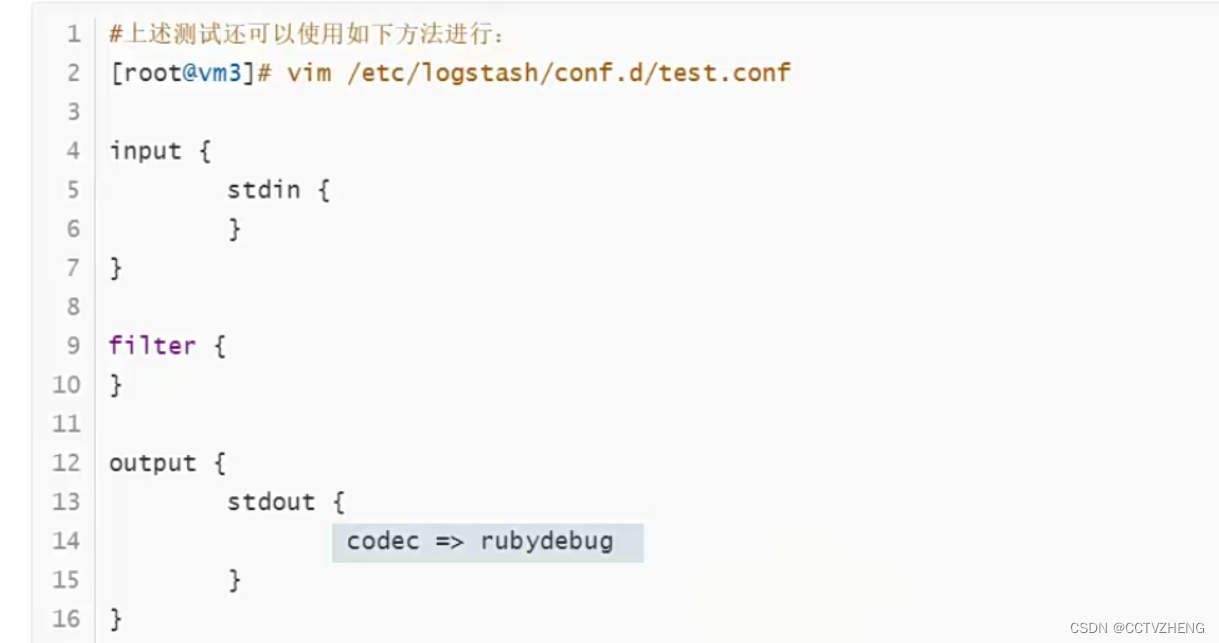

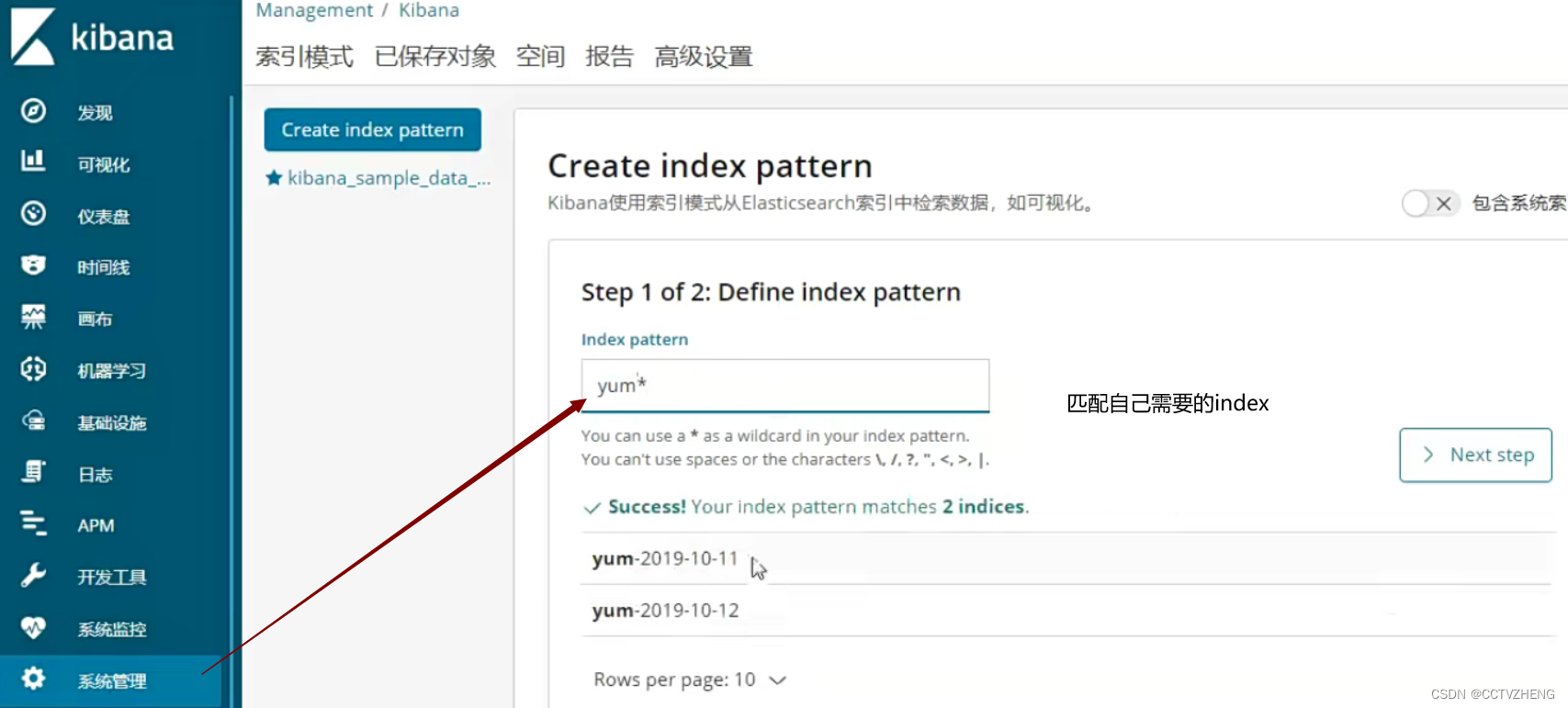
多日志采集配置
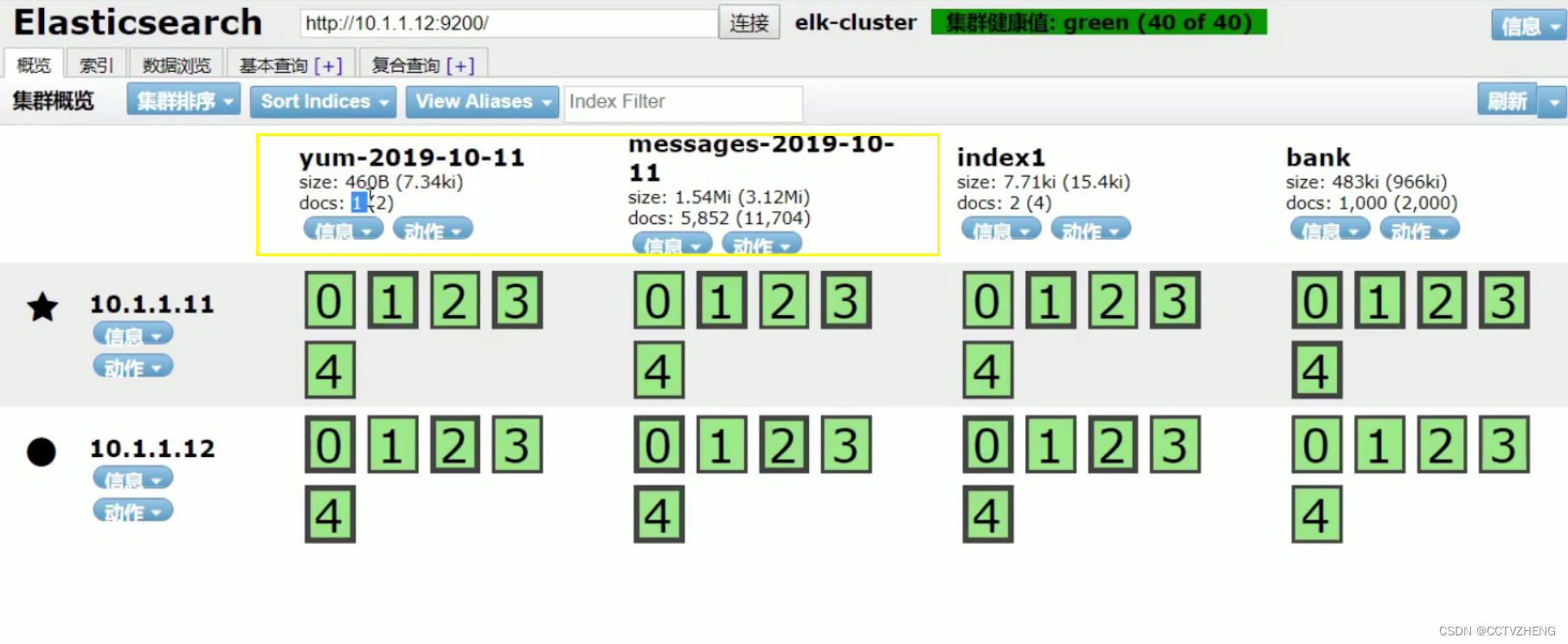
采集的两个日志文件分别对应两个索引
启动之后如果yum日志是空的 或者刚好日志轮转就不会采集到数据
采集的日志配置都编写在里面
七、kibana介绍
Kiban是一个开源的可视化平台,可以为ElasticSearch集群的管理提供友好的Web界面,帮助汇总,分析和搜索重要的日志数据。
文档路径: https://www.elastic.colguide/en/kibana/current/setup.html
可以根据官方文档安装和配置kibana

下载rpm软件包可以把wget去掉,直接在网页下载
7.1、kibana部署
第1步:在kibana服务器(我这里是VM1)上安装kibana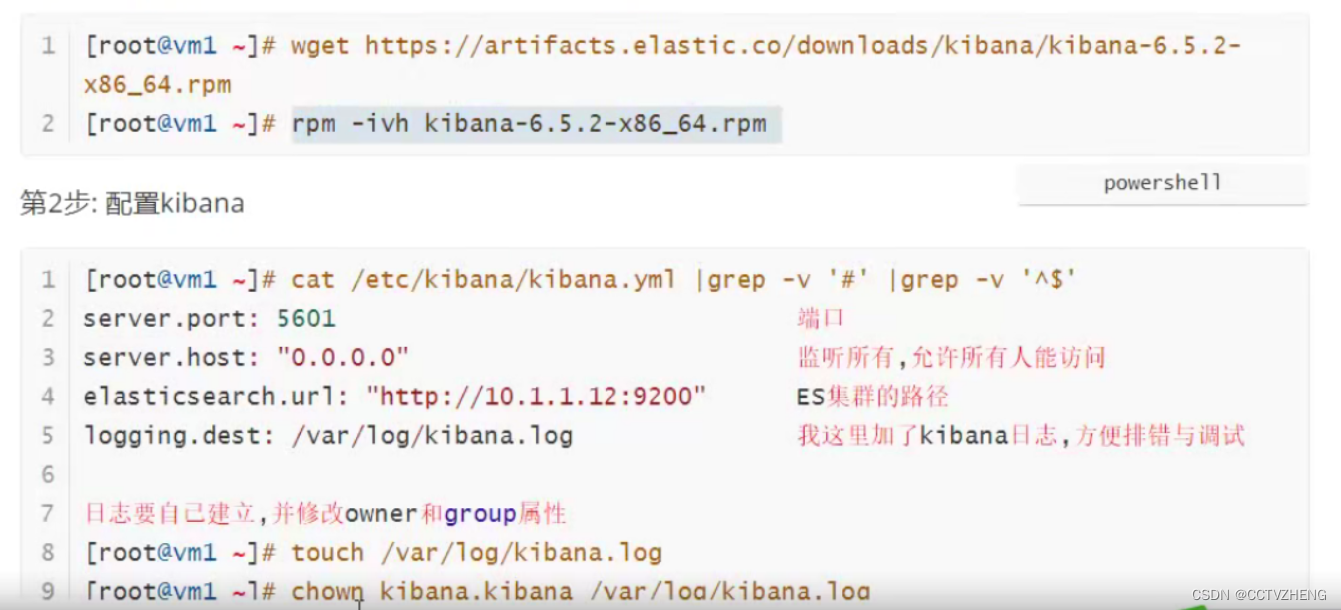
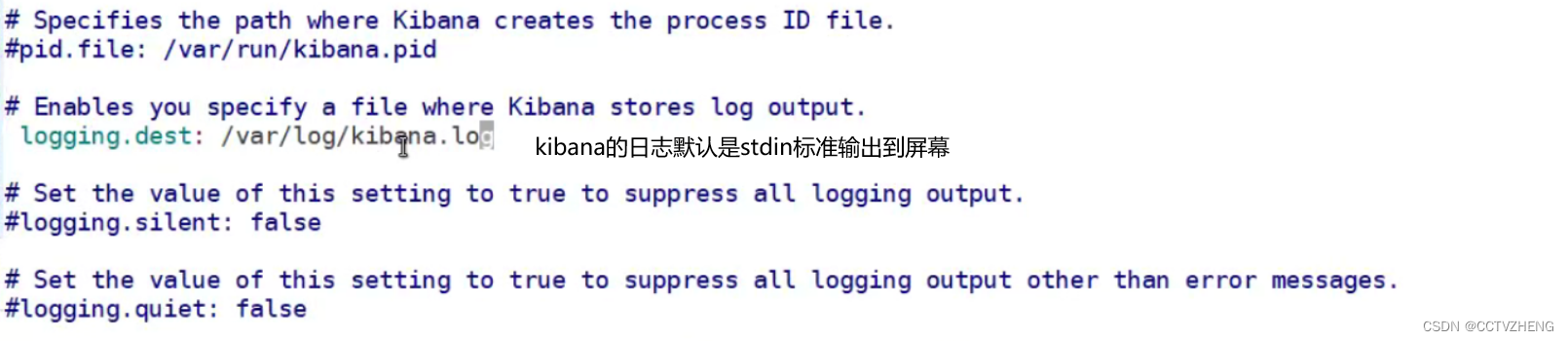
写错了 标准输出是stdout
重启kibana服务设置开机自启 然后浏览器访问就可以使用了
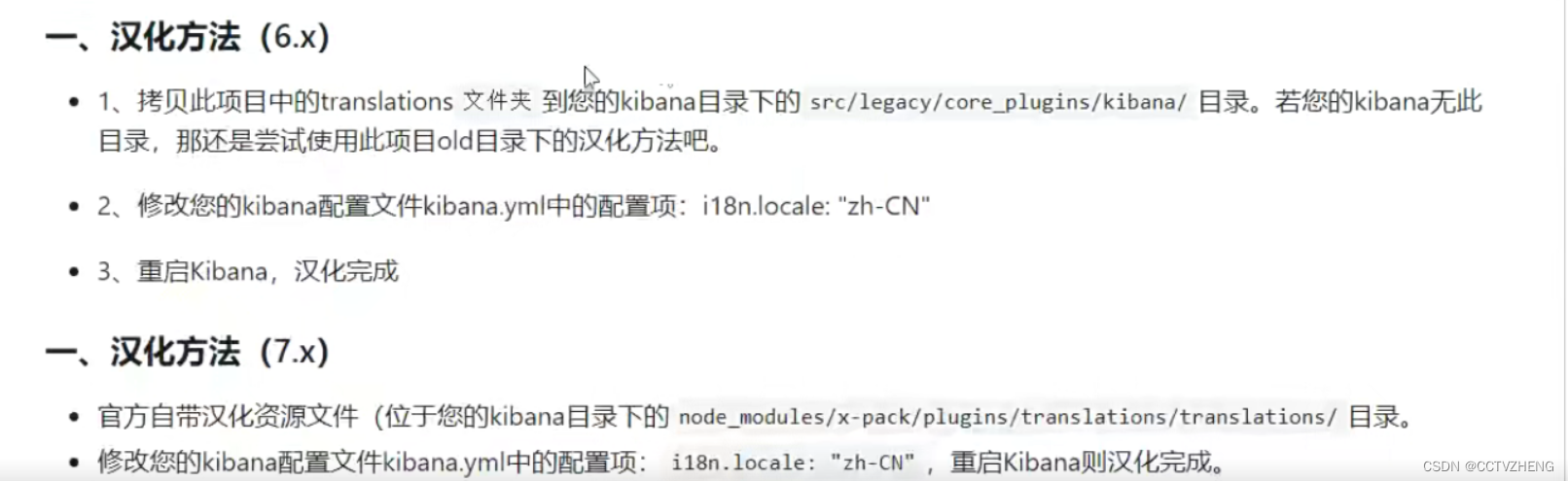
7.2、kibana 汉化
https://github.com/anbai-inc/Kibana Hanization/
这个github的资源已经没有了 希望大哥大姐可以给我一个新的

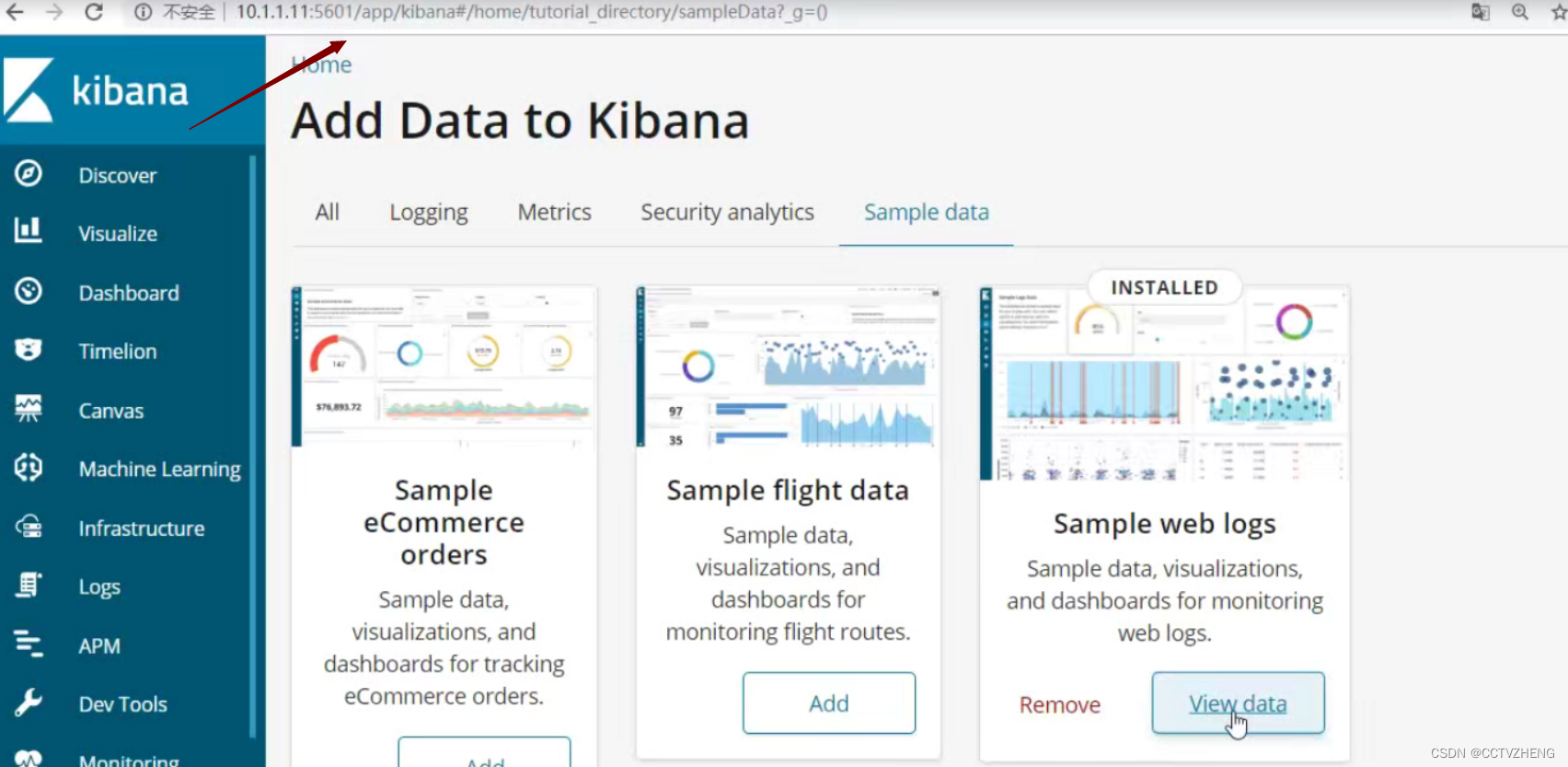
汉化成功之后再刷新访问web 注意:只有安装了kibana的服务器才能访问

点击发现,可以过滤日志产生的时间
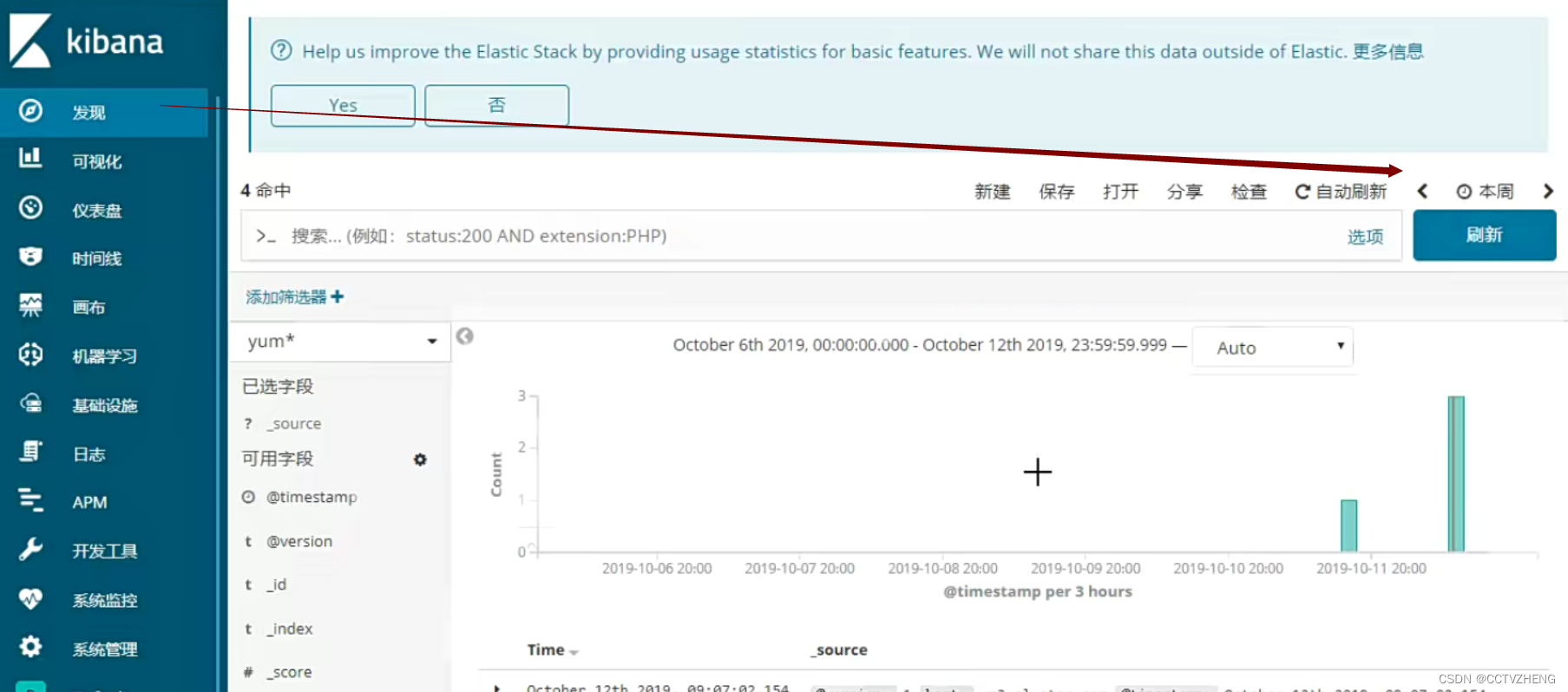
还可以通过筛选器来 精确筛选日志的信息,想看什么信息就看什么
 可视化操作可以把日志信息画图显示
可视化操作可以把日志信息画图显示

仪表盘其实就是聚合图形,把所有的可视化图聚合在一起
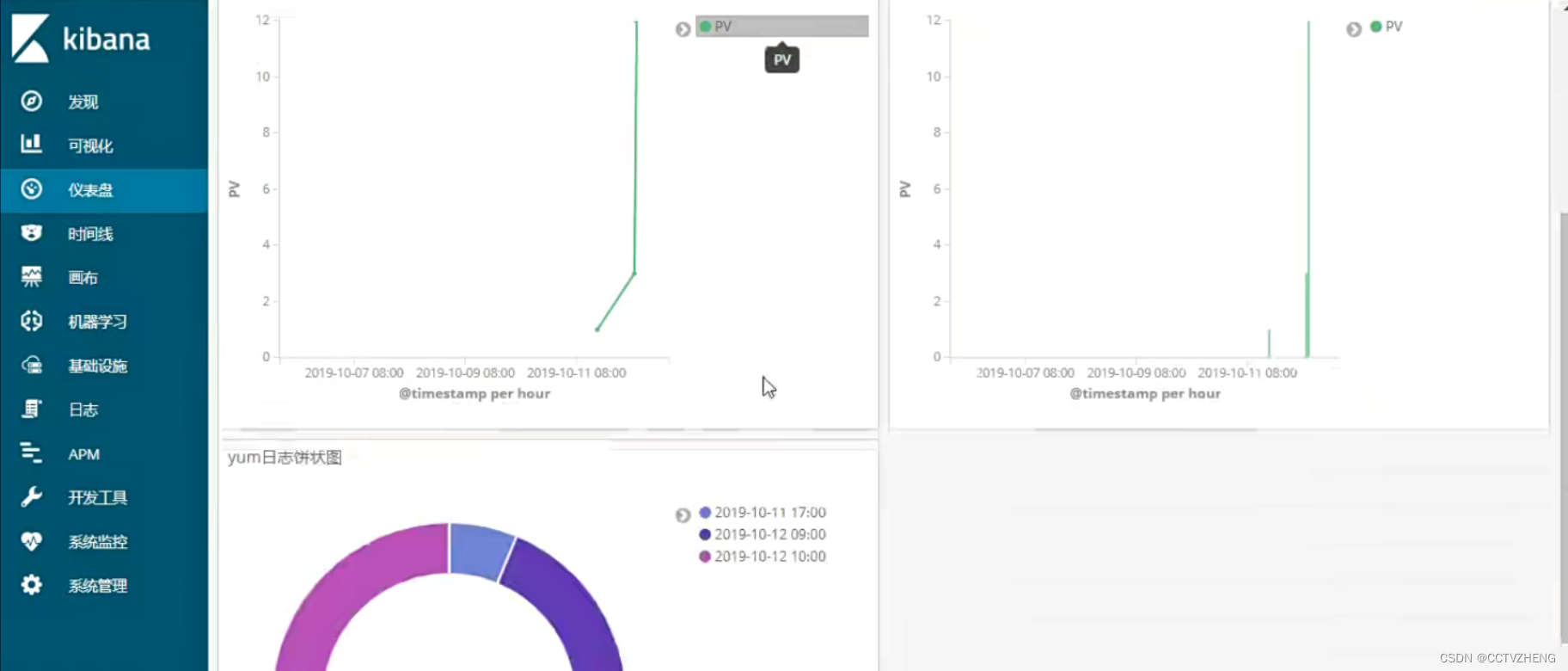
八、filebeat
注意:下载的是下x86_64rpm

 如果使用EFK架构的话,日志没有通过logstash过滤
如果使用EFK架构的话,日志没有通过logstash过滤

8.1、filebeat采集日志发送给es集群
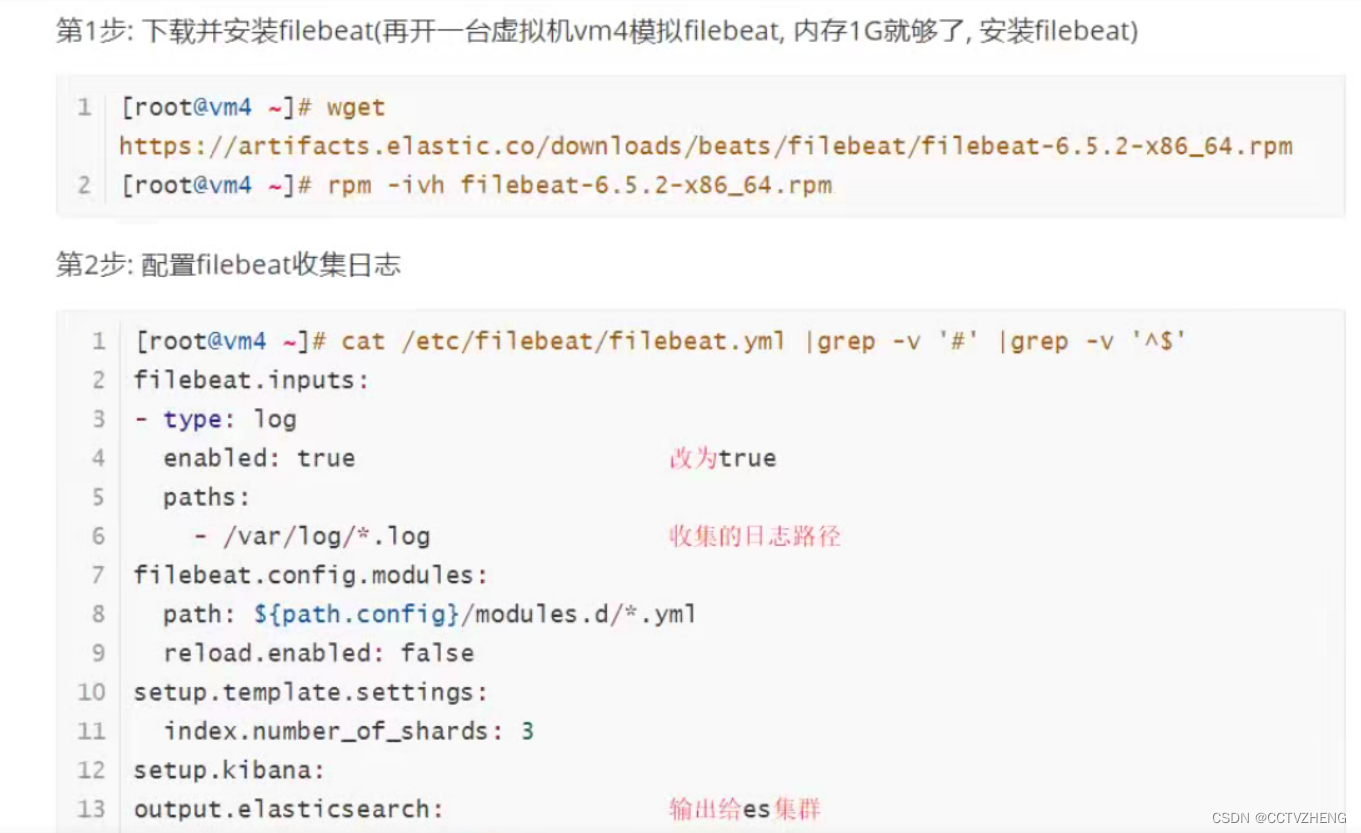
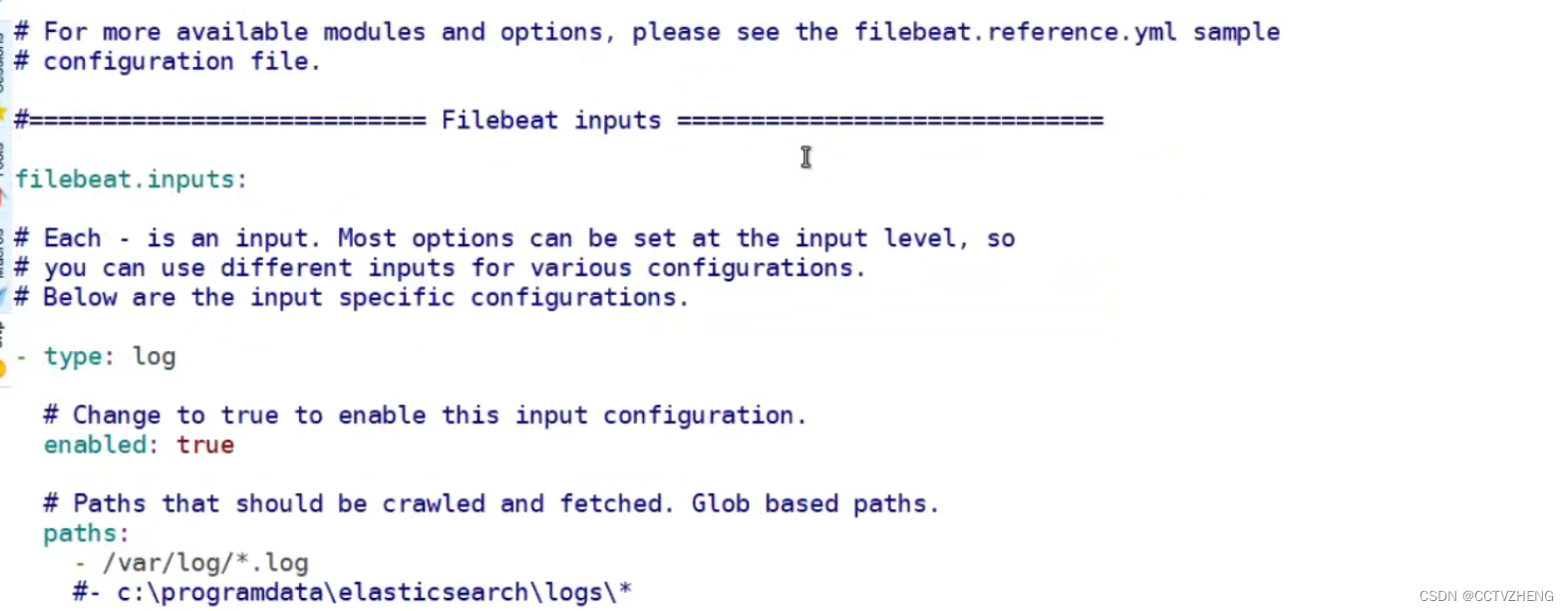
yaml格式特别严格
这配置是为了把采集到的 日志发送给es集群
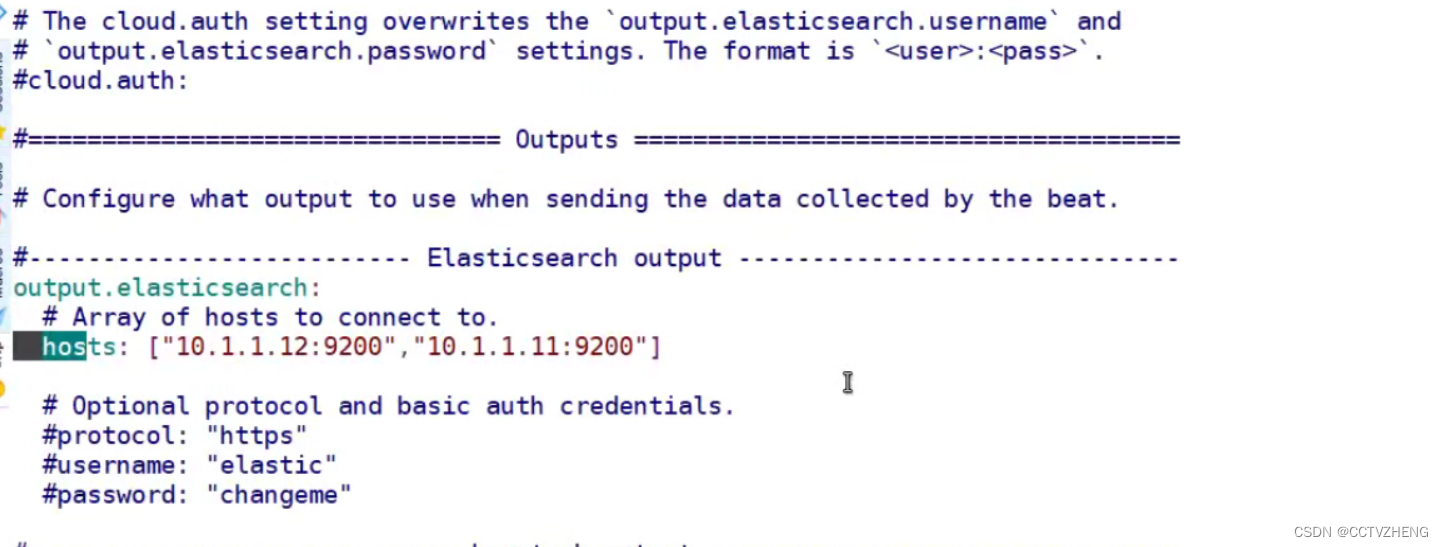
开启filebeat服务之后如果不取消kibana的筛选就会看不到日志

8.2、filebeat采集的日志输出到logstash
这里必须要把filebeat的配置文件output.elasticsearch改成output.logstash
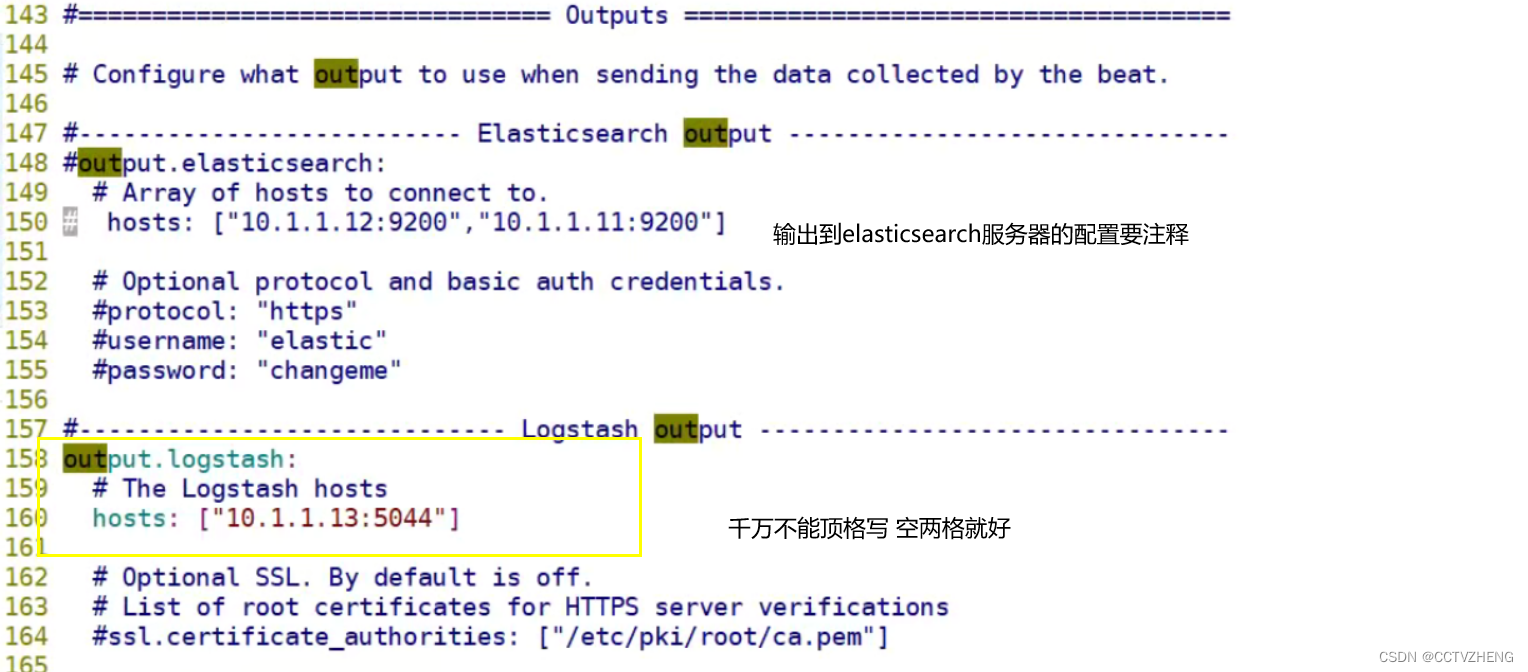
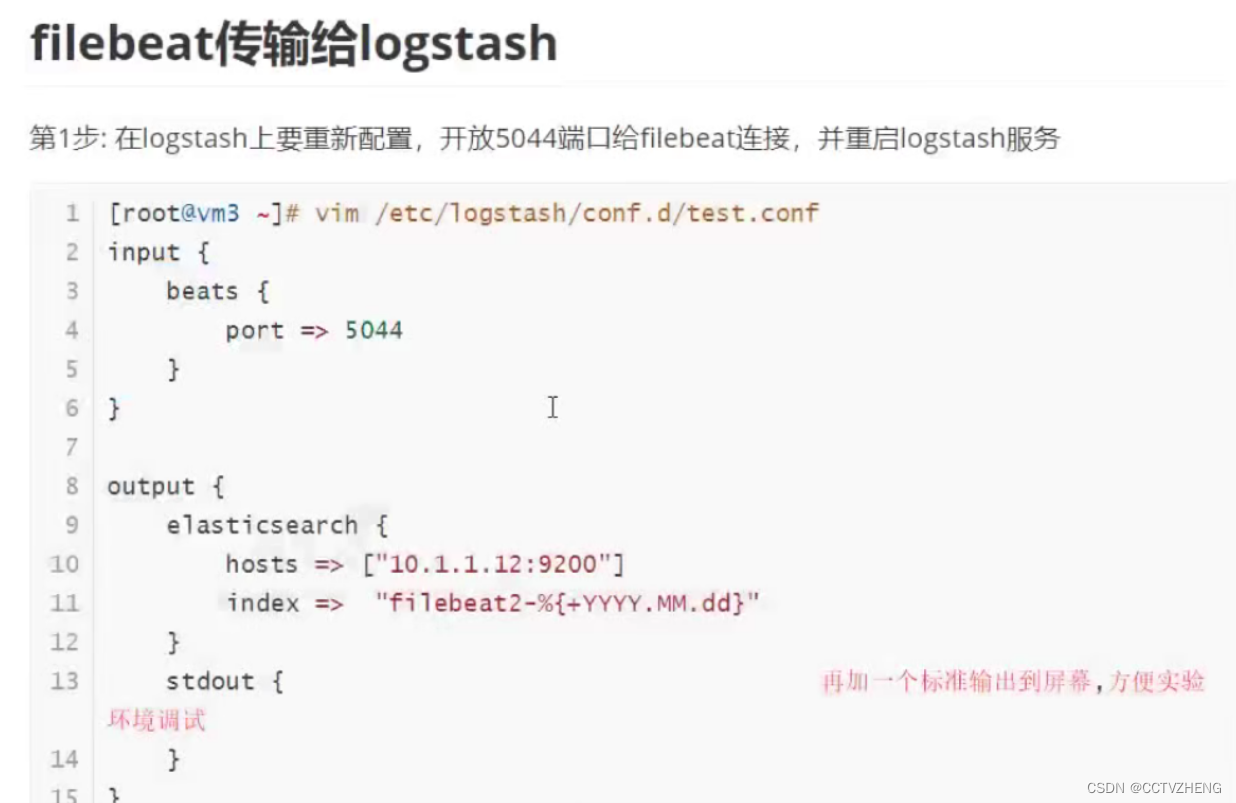
在logstash服务器上配置端口5044接收filebeat的日志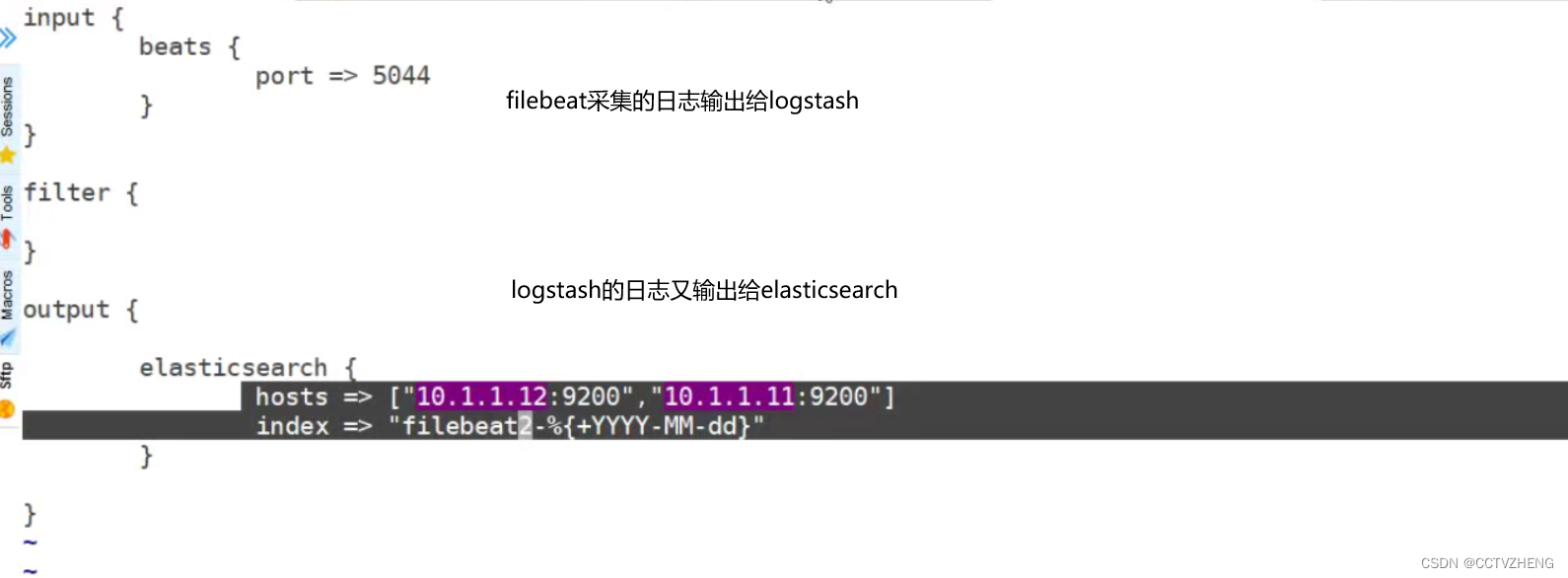
后台开启logstash服务,开启服务的命令不需要记忆
 &
&
收集nginx日志
yum install epel-release -y
一般用yum源安装的软件 日志文件都在/var/log/软件名称
 在filebeat.yml文件里面配置filebeat output nginx的访问日志路径或者error.log日志
在filebeat.yml文件里面配置filebeat output nginx的访问日志路径或者error.log日志
把nginx的access.log配置好
可能会出现的问题
filebeat可以配置通过关键字采集日志

logstash插件
tcp

把本地的信息传输变成网络的

json

把日志信息过滤成 key -value 方便单独统计UV
就是把message里面的信息过滤成content里面的key-value
如果把target => "content" 去掉 就直接过滤成key-value

kv
分隔带有字符字段的信息
·自动解析为key=value。
·也可以任意字符串分割数据。
. field_split一串字符,指定分隔符分析键值对
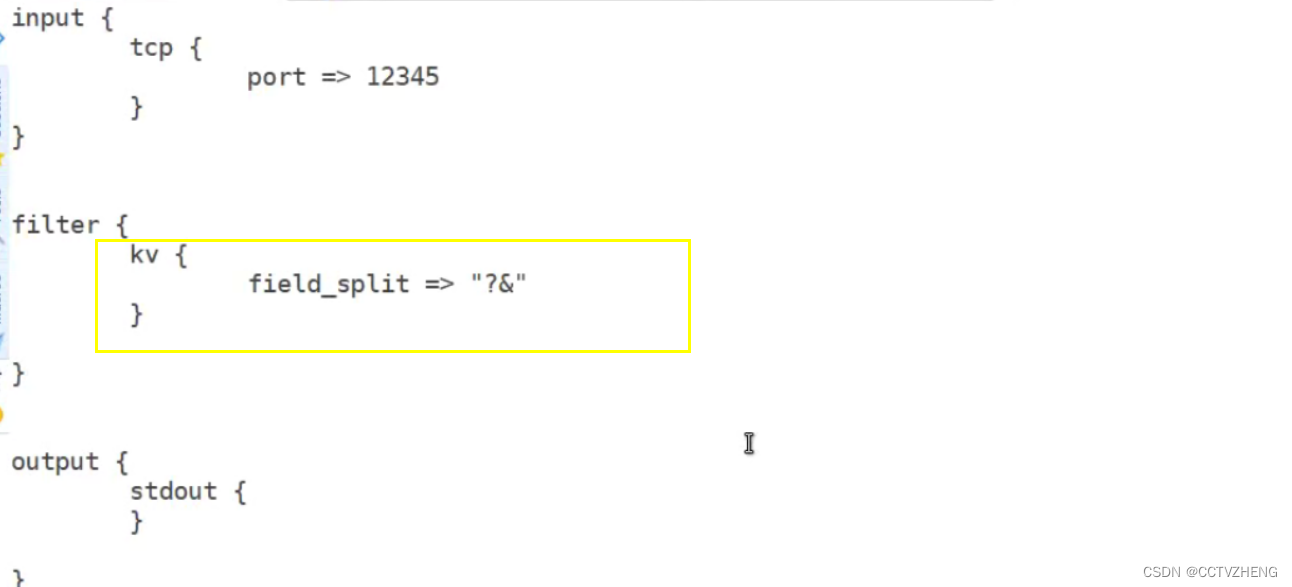
和json类似,只不过json是处理key-value的值 kv是处理字符分隔的信息

grok
grok是将非结构化数据解析为结构化
·这个工具非常适于系统日志,mysql日志,其他Web服务器日志以及通常人类无法编写任何日志的格式。
·默认情况下,Logstash附带约120个模式。也可以添加自己的模式(patterns_dir)·模式后面对应正则表达式
·查看模式地址: https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns
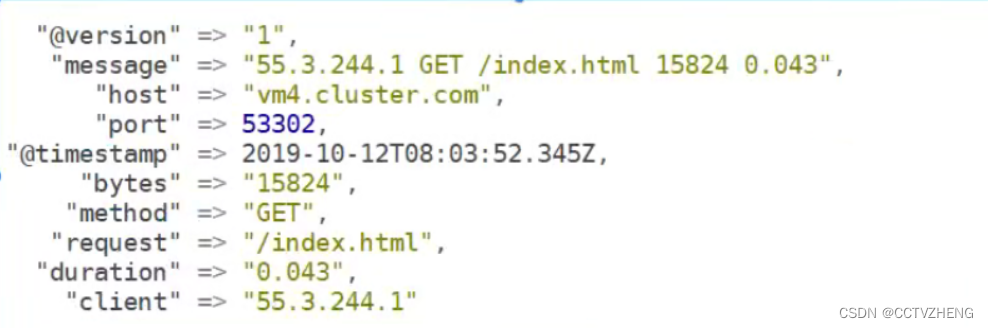
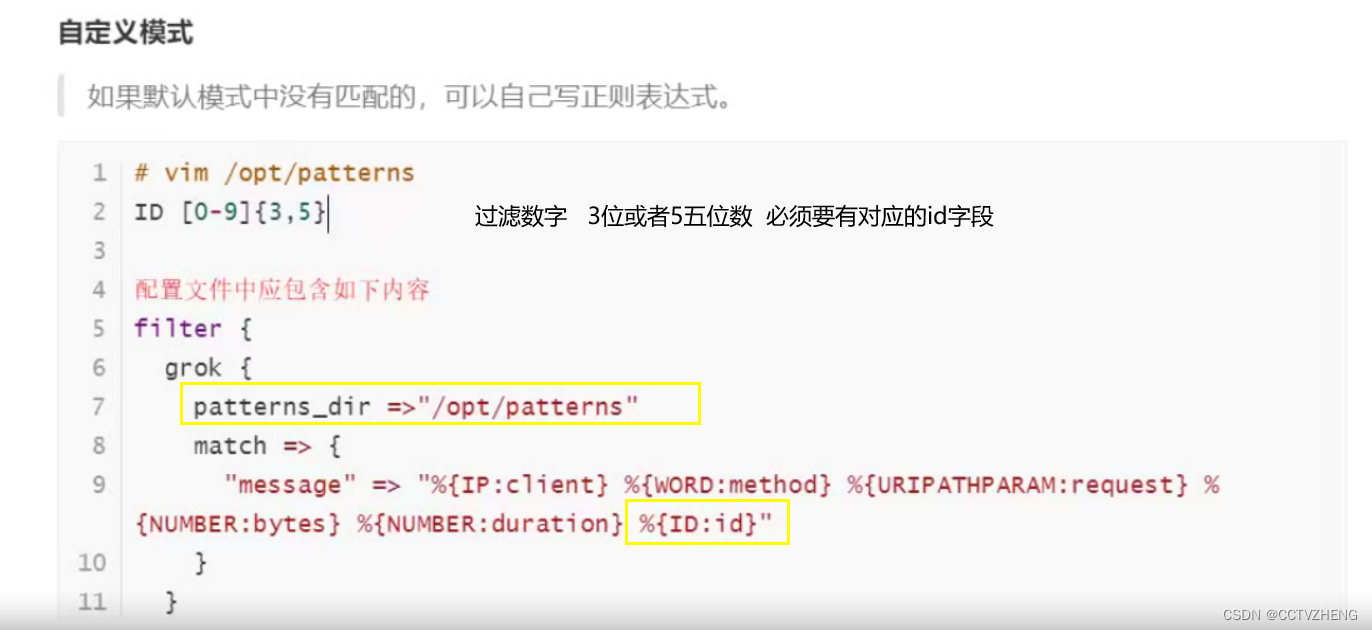
字段和过滤的message的类容是按顺序一 一 对应的
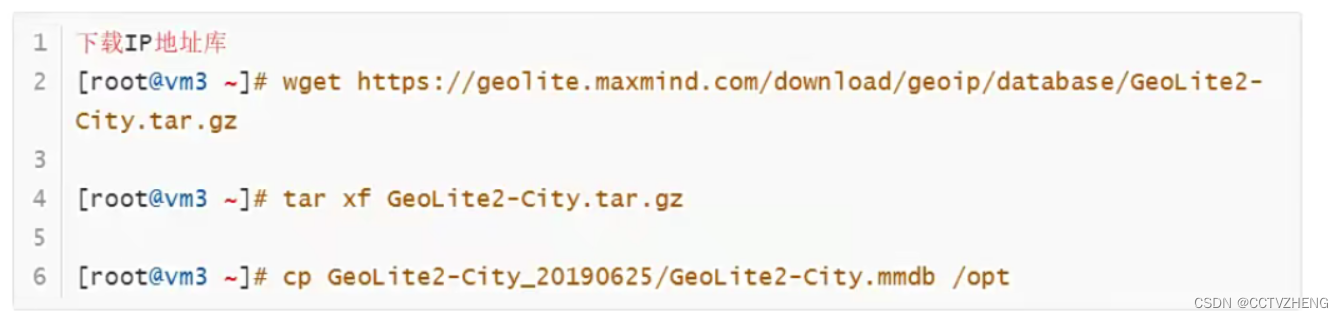
geoip
开源lP地址库
自己找