
- 1Android Studio 连接夜神模拟器的方法_android studio连接夜神模拟器
- 2【访问网络资源出错】不允许一个用户使用一个以上用户名与服务器或共享资源的多重连接
- 3git clone报错:remote: Support for password authentication was removed on August 13, 2021._get clone remote: support for password authenticat
- 4idea使用Spring Initializer创建springboot项目的坑【保姆级教学】
- 5【大模型专区】Text2Video-Zero—零样本文本到视频生成(上)
- 6神经网络深度学习梯度下降算法优化
- 7最新chatGPT镜像网站入口
- 8BigDecimal类的加减乘除(解决double计算精度问题)_bigdecimal怎么和double相乘
- 9Zookeeper Zab 协议解析——算法整体描述(一)_解析整体描述
- 10海外版抖音怎么下载?如何快速完成下载并注册TikTok账号?
基于python的深度神经网络原理与实践_python 网络神经
赞
踩
理论基础
什么是神经网络
我们知道深度学习是机器学习的一个分支,是一种以人工神经网络为架构,对数据进行表征学习的算法。而深度神经网络又是深度学习的一个分支,它在 wikipedia 上的解释如下:
深度神经网络(Deep Neural Networks, DNN)是一种判别模型,具备至少一个隐层的神经网络,可以使用反向传播算法进行训练。权重更新可以使用下式进行随机梯度下降法求解。
首先我们可以知道,深度神经网络是一种判别模型。意思就是已知变量 x ,通过判别模型可以推算出 y。比如机器学习中常用到的案例,通过手写数字,模型推断出手写的是数字几。
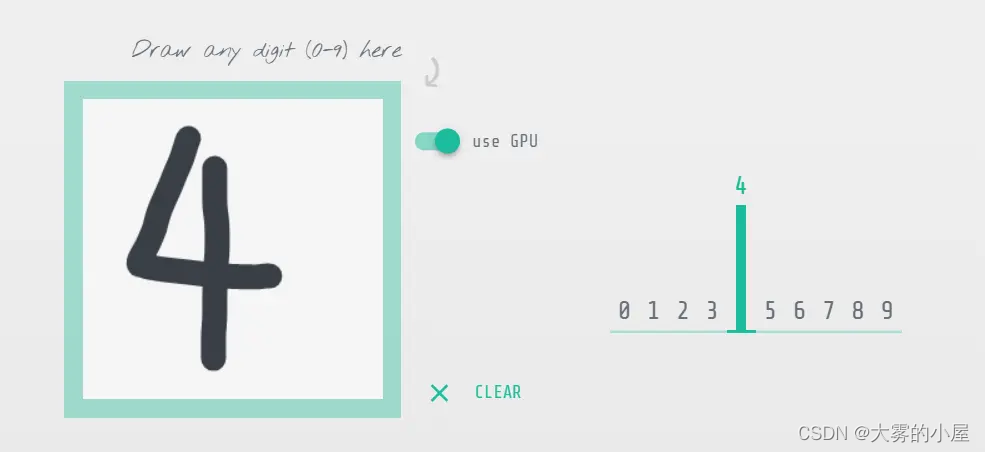
深度神经网络中的“深度”指的是一系列连续的表示层,数据模型中包含了多少层,这就被称为模型的“深度”。通过这些层我们可以对数据进行高层的抽象。如下图所示,深度神级网络由一个输入层,多个(至少一个)隐层,以及一个输出层构成,而且输入层与输出层的数量不一定是对等的。每一层都有若干个神经元,神经元之间有连接权重。
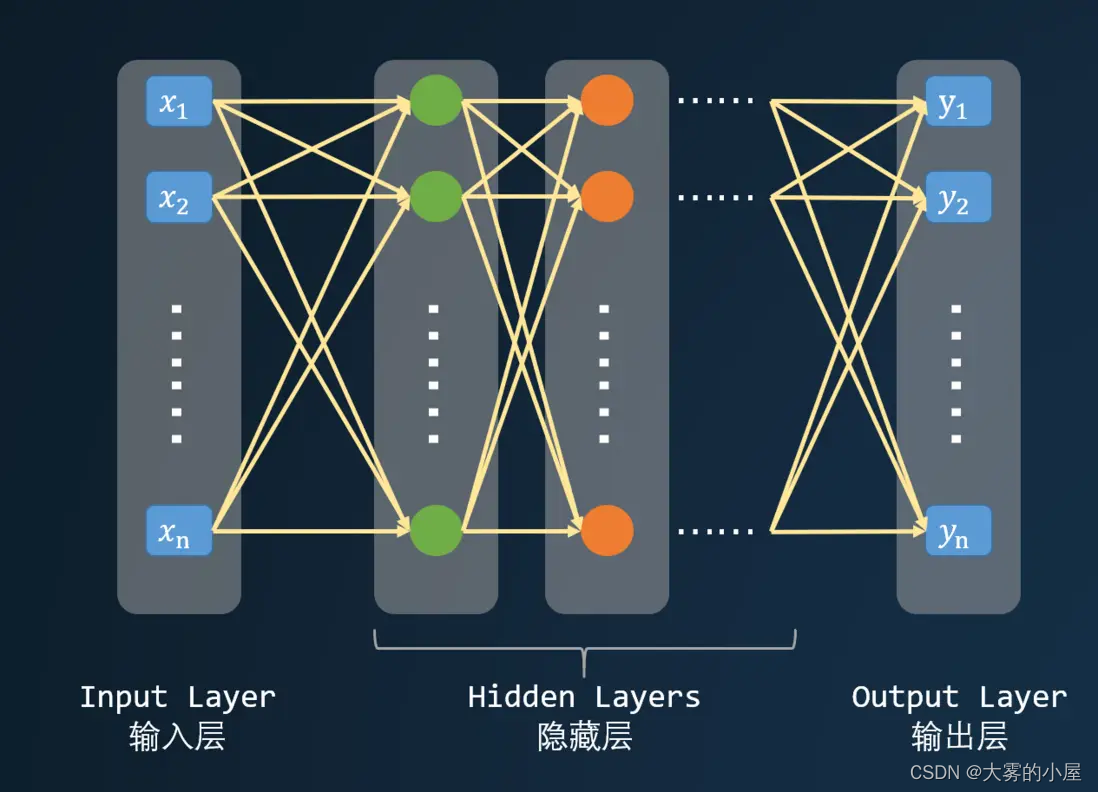
还是上面的案例,识别手写数字,手写的数字要怎么转成输入呢?既然是手写,那么肯定是一张图片,图片由多个像素点组成,这些像素点可以构成一个输入,经过多层神经网络,输出10个数字,这个10个数字就代表了数字 0 ~ 9 的概率。
神经元如何输入输出
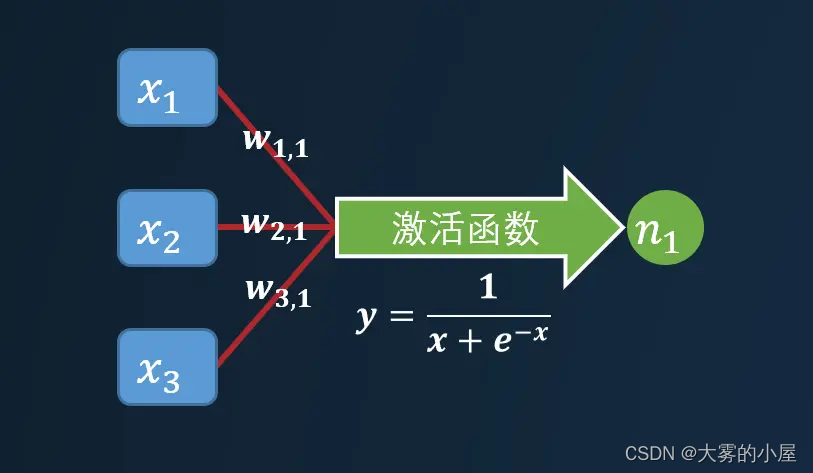
神经网络中的每个神经元都可以看成是一个简单的线性函数,下面我们构造一个简单的三层的神经网络来看看。
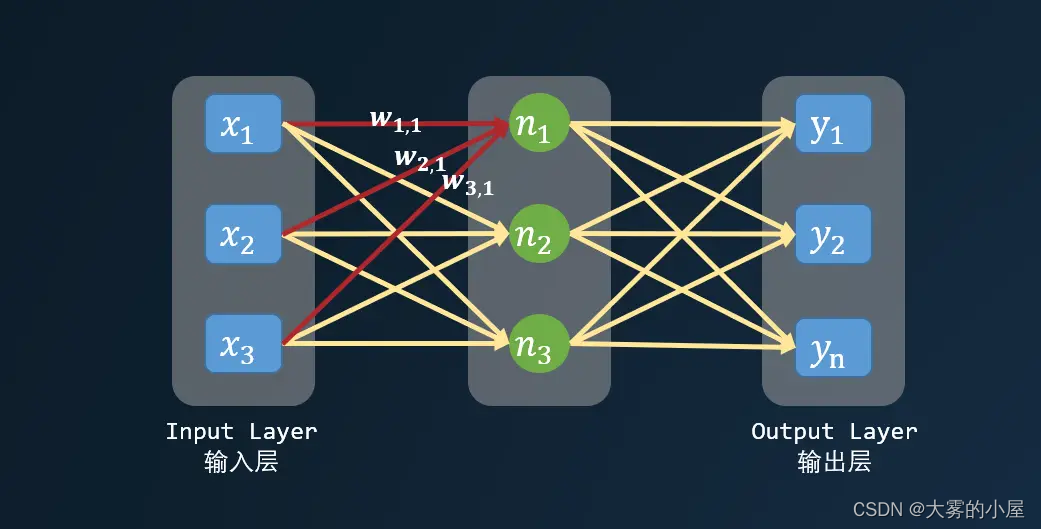
如上图所示,n1 可以表示为:
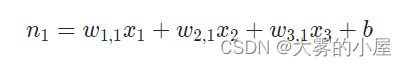
其中 w_{1,1} 表示神经元之间的权重,b 为一个常量,作为函数的偏移量。较小的权重可以弱化某个神经元对下一个神经元造成的影响,而较大的权重将放大信号。假设 w_{1,1} 为 0.1,w_{3,1} 为 0.7,那么 x3 对 n1 的影响要大于 x1。你可能会问,为什么每个神经元要与其他所有层的神经元相互连接?
这里主要由两个原因:
- 完全连接的形式相对容易的编写成计算机指令。
- 在神经网络训练的过程中会弱化实际上不需要的连接(也就是某些连接权重会慢慢趋近于 0)。
实际上通过计算得到 n1后,其实不能立马用于后面的计算,还需要经过一个激活函数(一般为 sigmod 函数)。
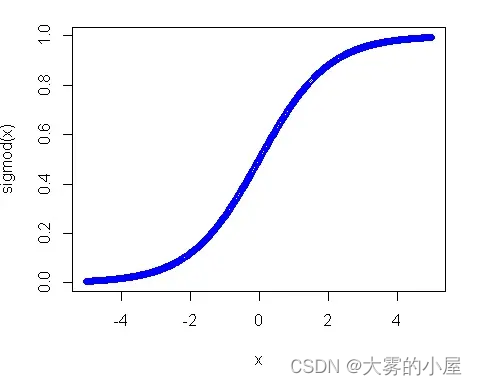
其作用主要是引入非线性因素。如果神级网络中只有上面那种线性函数,无论有多少层,结果始终是线性的。
实际案例
为了方便计算,我们构造一个只有两层的神经网络,演示一下具体的计算过程。
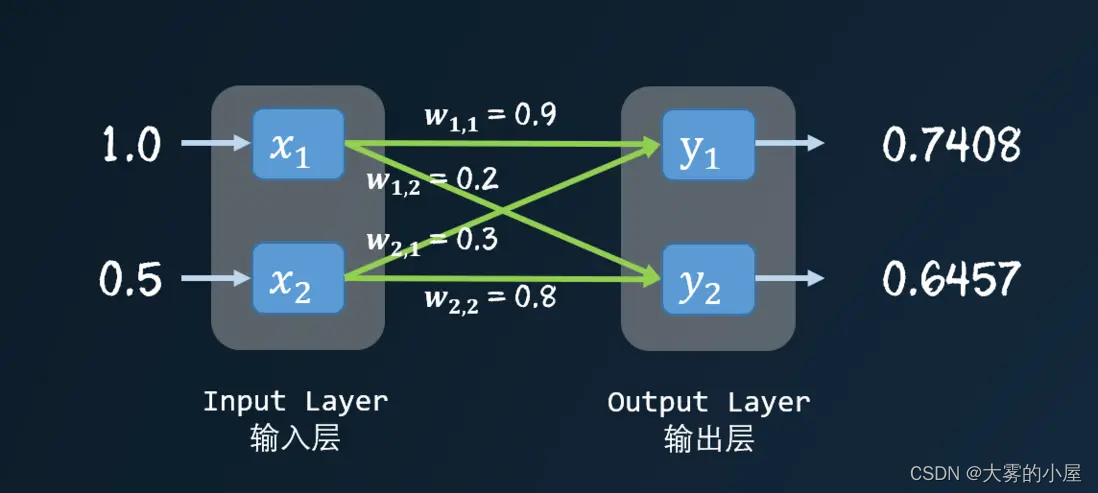
先通过线性函数求得一个 x 值,再把 x 值带入激活函数,得到 y1 的值。
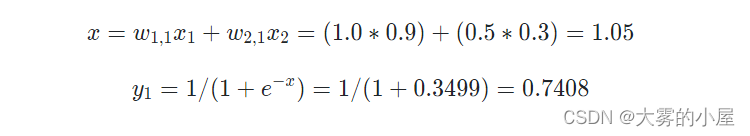
矩阵乘法
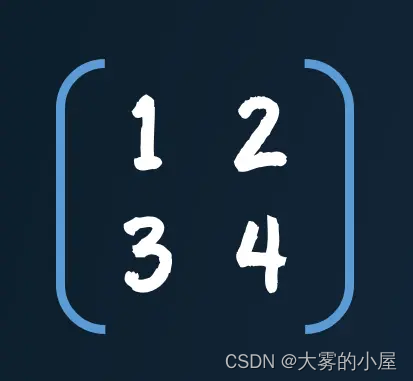
其实上面的计算过程,很容易通过矩阵乘法的方式表示。矩阵这个东西,说简单点就是一个表格,或者一个二维数组。如下图所示,就是一个典型的矩阵。
那么矩阵的乘法可以表示为:

矩阵的乘法通常被成为点乘或者内积。如果我们将矩阵内的数字换成我们神经网络的输入和权重,你会发现原来前面的计算如此简单。

获得点积后,只需要代入到激活函数,就能获得输出了。
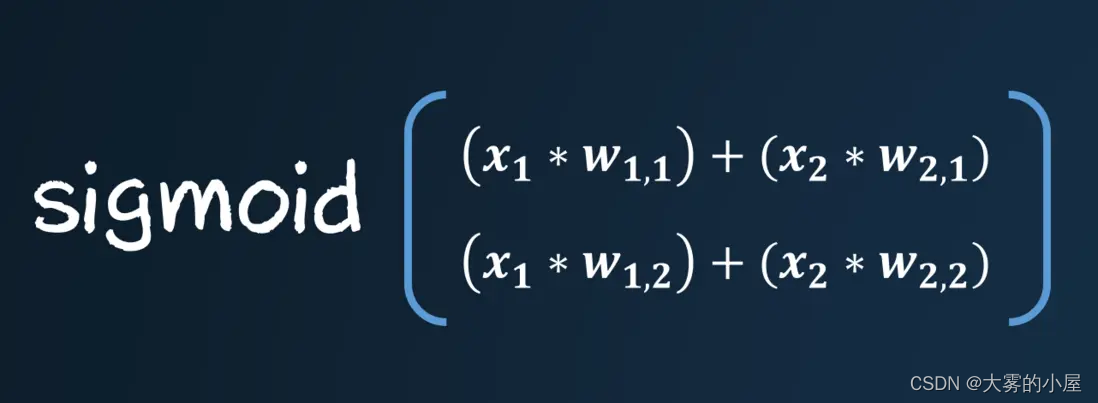
通过矩阵计算过程可以表示为:
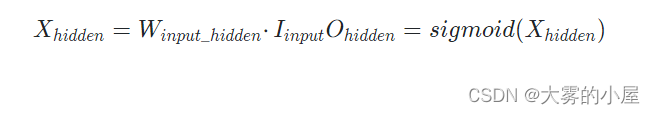
实际案例
下面通过矩阵来表示一个三层神经网络的计算过程。
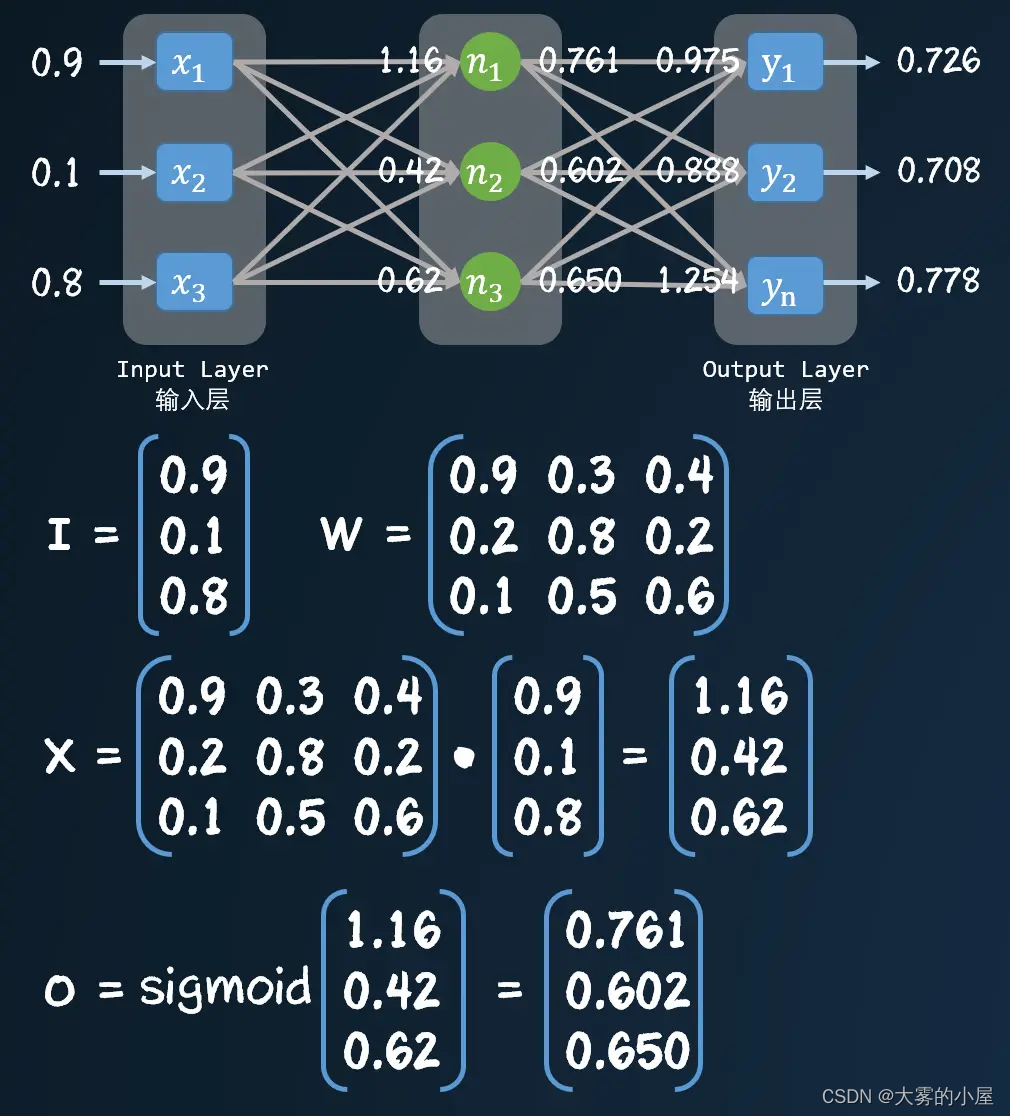
上图只给出了输入层到隐层的计算过程,感兴趣可以自己手动计算下,隐层到输出层的计算过程。隐层到输出层的权重矩阵如下:

反向传播
进过一轮神经网络计算得到输出值,通常与我们实际想要的值是不一致的,这个时候我们会得到一个误差值(误差值就是训练数据给出的正确答案与实际输出值之间的差值)。
但是这个误差是多个节点共同作用的结果,我们到底该用何种方式来更新各个连接的权重呢?这个时候我们就需要通过反向传播的方式,求出各个节点的误差值。
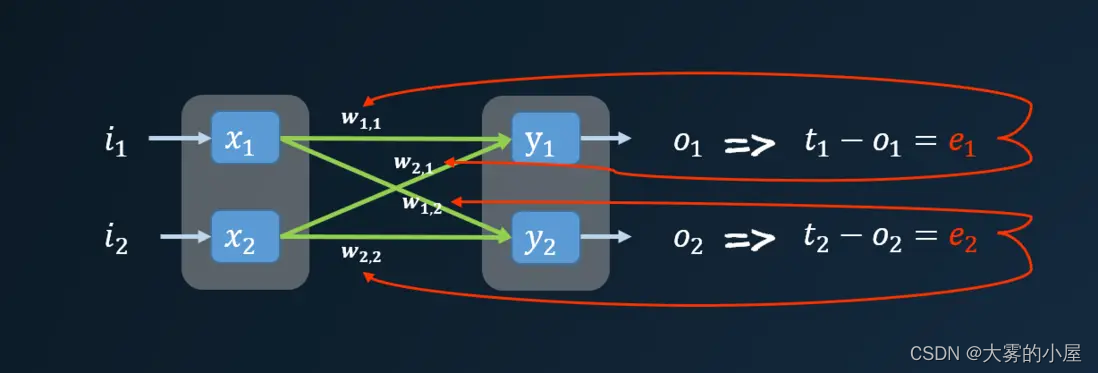
下面我们代入具体值,进行一次计算。
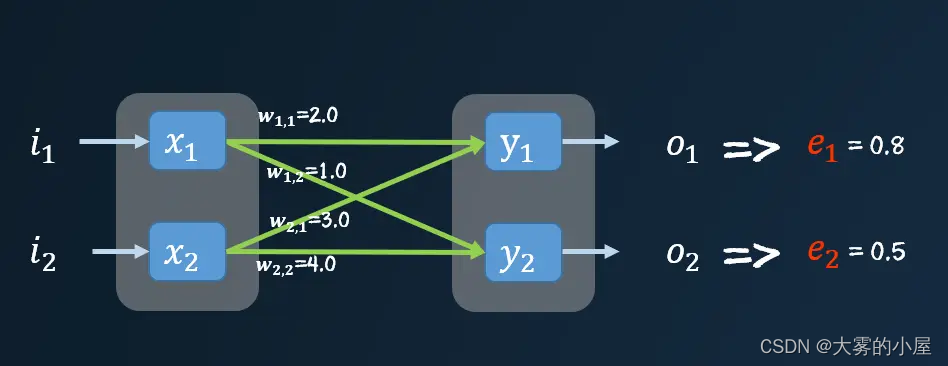
上图中可以看到 e_1 的误差值主要由 w_{1,1} 和 w_{2,1} 造成,那么其误差应当分散到两个连接上,可以按照两个连接的权重对误差 e_1 进行分割。
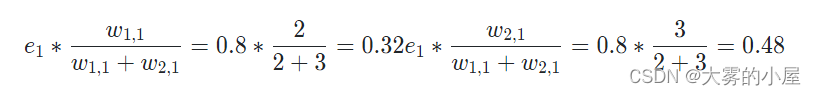
同理对误差 e_2 进行分割,然后把两个连接处的误差值相加,就能得到输出点的前馈节点的误差值。
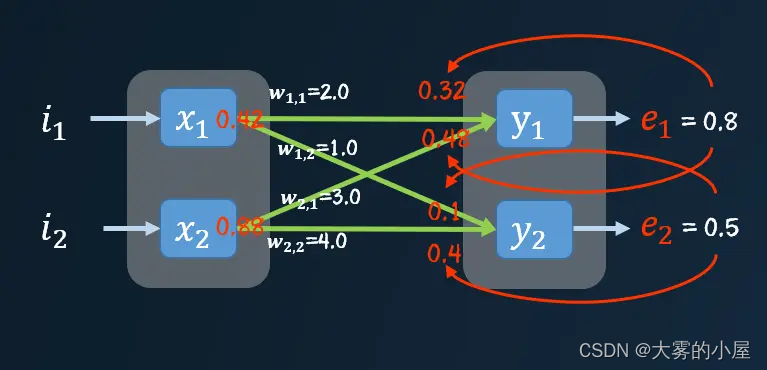
然后在按照之前的方法将这个误差传播到前面的层,直到所有节点都能得到自己的误差值,这种方式被成为反向传播。
使用矩阵乘法进行反向传播误差
上面如此繁琐的操作,我们也可以通过矩阵的方式进行简化。
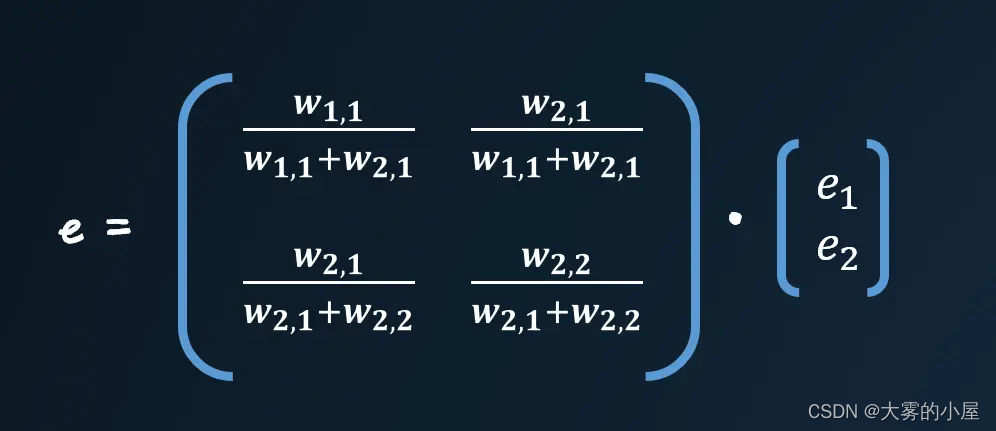
这个矩阵中还是有麻烦的分数需要处理,那么我们能不能大胆一点,将分母直接做归一化的处理。这么做我们仅仅只是改变了反馈误差的大小,其误差依旧是按照比例来计算的。


仔细观察会发现,与我们之前计算每层的输出值的矩阵点击很像,只是权重矩阵进行翻转,右上方的元素变成了左下方的元素,我们可以称其为转置矩阵,记为 w^T 。
反向传播误差的矩阵可以简单表示为:
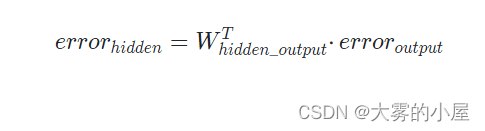
梯度下降
在每个点都得到误差后,我们该按照何种方式来更新权重呢?
这个时候就要使用到机器学习中常用的方式:梯度下降。
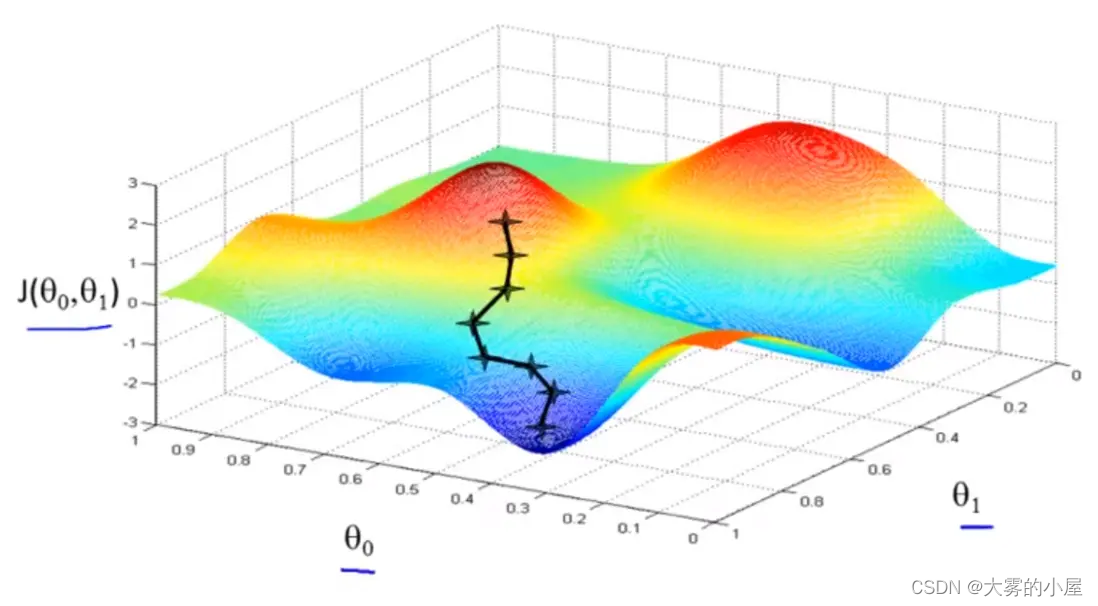
通过不停的训练,我们就能改进神经网络,其本质就是不断地改变权重的大小,减小神经网络输出的误差值。
最后就能够得到一个多层神经网络的模型,通过输入进行有效的预测。
实战
环境准备
首先需要安装 python3 ,直接去 python 官网安装,尽量安装最新版,不推荐安装 python2 。安装好 python 环境之后,然后安装 virtualenv 以及相关依赖。
# 升级 pip 到最新版本
pip3 install --upgrade pip
# 安装 virtualenv ,用于配置虚拟环境
pip3 install --user --upgrade virtualenv
- 1
- 2
- 3
- 4
- 5
正常情况下,当我们在使用 pip 进行包安装的时候,都是安装的全局包,相当于npm install -g。
假如现在有两个项目,项目 A 依赖 simplejson@2 ,项目 B 依赖 simplejson@3,这样我们在一台机器上开发显得有些手足无措。
这个时候 virtualenv 就能大展身手了,virtualenv 可以创建一个独立的 python 运行环境,也就是一个沙箱,你甚至可以在 virtualenv 创建的虚拟环境中使用与当前系统不同的 python 版本。
# 配置虚拟环境
cd ~/ml
virtualenv env
# 启动虚拟环境
# linux
source env/bin/activate
# windows
./env/Scripts/activate
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
启动后,如下
(env) λ
- 1

在虚拟环境下安装所有模块依赖。
# 安装模块和依赖
(env) λ pip3 install --upgrade jupyter matplotlib numpy scipy
- 1
- 2
- jupyter:基于网页的用于交互计算的应用程序。其可被应用于全过程计算:开发、文档编写、运行代码和展示结果。
- numpy:数组计算扩展的包,支持高维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
- scipy:基于numpy的扩展包,它增加的功能包括数值积分、最优化、统计和一些专用函数。
- matplotlib:基于numpy的扩展包,提供了丰富的数据绘图工具,主要用于绘制一些统计图形。
- scikit-learn:开源的Python机器学习库,它基于Numpy和Scipy,提供了大量用于数据挖掘和分析的工具,包括数据预处理、交叉验证、算法与可视化算法等一系列接口。
启动 jupyter
jupyter notebook
- 1
jupyter 会在8888端口起一个服务,并自动打开浏览器。
通过右上角的new,你就能创建一个项目了。创建项目后,我们很方便的在该页面上进行 python 代码的运行与输出。
准备数据
MNIST 是由美国的高中生和美国人口调查局的职员手写数字(0 ~ 9)图片。
接下来要做的事情就是让我们的程序学习这些图片的信息,能够识别出输入的图片所代表的数字含义,这听上去好像有点难度,不着急,我们一步步来。
这里准备了 MNIST 的训练数据,其中 train_100 为训练数据集,test_10 为测试数据集。
在机器学习的过程中,我们一般会将数据集切分成两个,分别为训练集合测试集,一般 80% 的数据进行训练,保留 20% 用于测试。
这里因为是 hello world 操作,我们只用 100 个数据进行训练,真实情况下,这种数据量是远远不够的。
mnist_train_100.csvmnist_test_10.csv
如果想用完整的数据进行训练,可以下载这个 csv 文件。
https://pjreddie.com/media/files/mnist_train.csv
观察数据
下载数据后,将 csv (逗号分隔值文件格式)文件放入到 datasets 文件夹,然后使用 python 进行文件的读取。
data_file = open("datasets/mnist_train_100.csv", 'r')
data_list = data_file.readlines() # readlines方法用于读取文件的所有行,并返回一个数组
data_file.close()
len(data_list) # 数组长度为100
- 1
- 2
- 3
- 4
- 5
打印第一行文本,看看数据的格式是怎么样的
print(data_list[0])
len(data_list[0].split(',')) # 使用 , 进行分割,将字符串转换为数组
- 1
- 2
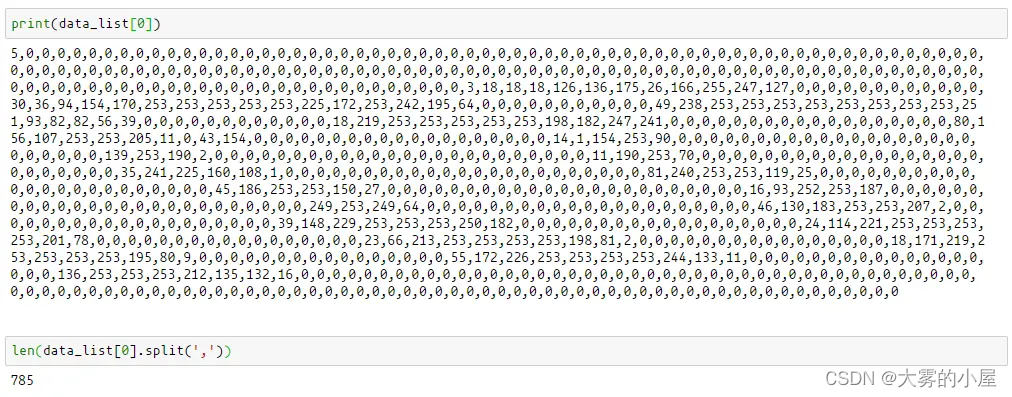
可以看到一行数据一共有 785 个数据,第一列表示这个手写数的真实值(这个值在机器学习中称为标签)。
后面的 784 个数据表示一个 28 * 28 的尺寸的像素值,流行的图像处理软件通常用8位表示一个像素,这样总共有256个灰度等级(像素值在0~255 间),每个等级代表不同的亮度。
下面我们导入 numpy 库,对数据进行处理,values[1:] 取出数组的第一位到最后并生成一个新的数组,使用 numpy.asfarray 将数组转为一个浮点类型的 ndarray。
然后每一项除以 255 在乘以 9,将每个数字转为 0 ~ 9 的个位数,使用 astype(int) 把每个数再转为 int 类型,最后 reshape((28,28) 可以把数组转为 28 * 28 的二维数组。
import numpy as np
values = data_list[3].split(',')
image_array = (np.asfarray(values[1:]) / 255 * 9).astype(int).reshape(28,28)
- 1
- 2
- 3
- 4

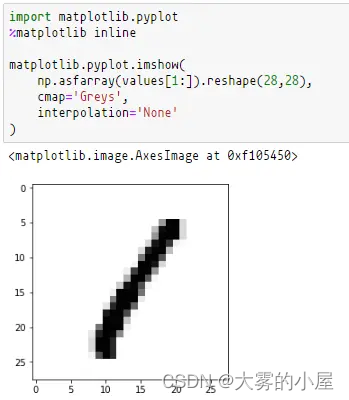
这样看不够直观,接下来使用 matplotlib ,将像素点一个个画出来。
import matplotlib.pyplot
%matplotlib inline
matplotlib.pyplot.imshow(
np.asfarray(values[1:]).reshape(28,28),
cmap='Greys',
interpolation='None'
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
搭建神经网络
我们简单勾勒出神经网络的大概样子,至少需要三个函数:
- 初始化函数——设定输入层、隐藏层、输出层节点的数量,随机生成的权重。
- 训练——学习给定的训练样本,调整权重。
- 查询——给定输入,获取预测结果。
框架代码如下:
# 引入依赖库 import numpy as np import scipy.special import matplotlib.pyplot # 神经网络类定义 class neuralNetwork: # 初始化神经网络 def __init__(): pass # 训练神经网络 def train(): pass # 查询神经网络 def query(): pass

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
初始化神经网络
接下来让我们进行第一步操作,初始化一个神经网络。
# 初始化神经网络 def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate): # 设置输入层、隐藏层、输出层节点的数量 self.inodes = inputnodes self.hnodes = hiddennodes self.onodes = outputnodes # 连接权重,随机生成输入层到隐藏层和隐藏层到输出层的权重 self.wih = np.random.rand(self.hnodes, self.inodes) - 0.5 self.who = np.random.rand(self.onodes, self.hnodes) - 0.5 # 学习率 self.lr = learningrate # 将激活函数设置为 sigmoid 函数 self.activation_function = lambda x: scipy.special.expit(x) pass
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
生成权重
生成连接权重使用 numpy 函数库,该库支持大维度数组以及矩阵的运算,通过numpy.random.rand(x, y)可以快速生成一个 x * y 的矩阵,每个数字都是一个 0 ~ 1 的随机数。因为导入库的时候使用了 import numpy as np 命令,所有代码中可以用 np 来代替 numpy。
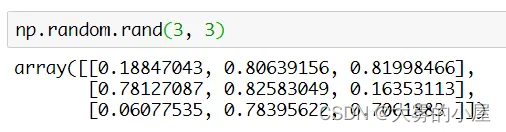
上面就是通过 numpy.random.rand 方法生成一个 3 * 3 矩阵的案例。减去0.5是为了保证生成的权重所有权重都能维持在 -0.5 ~ 0.5 之间的一个随机值。
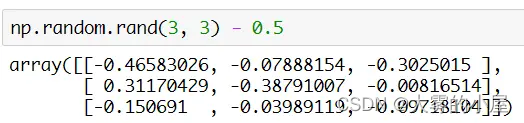
激活函数
scipy.special 模块中包含了大量的函数库,利用 scipy.special 库可以很方便快捷的构造出一个激活函数:
activation_function = lambda x: scipy.special.expit(x)
- 1
查询神经网络
# 查询神经网络 def query(self, inputs_list): # 将输入的数组转化为一个二维数组 inputs = np.array(inputs_list, ndmin=2).T # 计算输入数据与权重的点积 hidden_inputs = np.dot(self.wih, inputs) # 经过激活函数的到隐藏层数据 hidden_outputs = self.activation_function(hidden_inputs) # 计算隐藏层数据与权重的点积 final_inputs = np.dot(self.who, hidden_outputs) # 最终到达输出层的数据 final_outputs = self.activation_function(final_inputs) return final_outputs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
查询神经网络的操作很简单,只需要使用 numpy 的 dot 方法对两个矩阵求点积即可。
这里有一个知识点,就是关于 numpy 的数据类型,通过 numpy.array 方法能够将 python 中的数组转为一个 N 维数组对象 Ndarray,该方法第二个参数就是表示转化后的维度。

上图是一个普通数组 [1, 2, 3] 使用该方法转变成二维数组,返回 [[1, 2, 3]]。该方法还有个属性 T,本质是调用 numpy 的 transpose 方法,对数组进行轴对换,如下图所示。

通过转置我们就能得到一个合适的输入矩阵了。
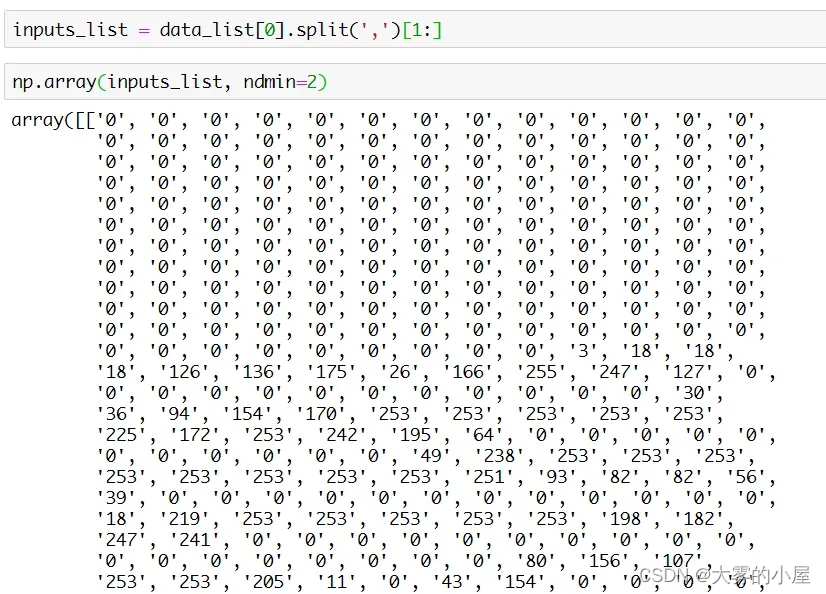
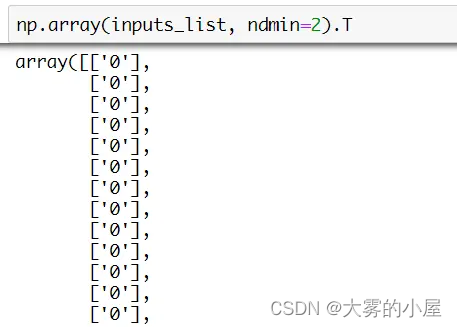
训练神经网络
# 训练神经网络 def train(self, inputs_list, targets_list): # 将输入数据与目标数据转为二维数组 inputs = np.array(inputs_list, ndmin=2).T targets = np.array(targets_list, ndmin=2).T # 通过矩阵点积和激活函数得到隐藏层的输出 hidden_inputs = np.dot(self.wih, inputs) hidden_outputs = self.activation_function(hidden_inputs) # 通过矩阵点积和激活函数得到最终输出 final_inputs = np.dot(self.who, hidden_outputs) final_outputs = self.activation_function(final_inputs) # 获取目标值与实际值的差值 output_errors = targets - final_outputs # 反向传播差值 hidden_errors = np.dot(self.who.T, output_errors) # 通过梯度下降法更新隐藏层到输出层的权重 self.who += self.lr * np.dot( (output_errors * final_outputs * (1.0 - final_outputs)), np.transpose(hidden_outputs) ) # 通过梯度下降法更新输入层到隐藏层的权重 self.wih += self.lr * np.dot( (hidden_errors * hidden_outputs * (1.0 - hidden_outputs)), np.transpose(inputs) ) pass
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
训练神经网络前半部分与查询类似,中间会将得到的差值通过求矩阵点积的方式进行反向传播,最后就是使用梯度下级的方法修正权重。
其中 self.lr 为梯度下降的学习率,这个值是限制梯度方向的速率,我们需要经常调整这个值来达到模型的最优解。
进行训练
# 设置每一层的节点数量 input_nodes = 784 hidden_nodes = 100 output_nodes = 10 # 学习率 learning_rate = 0.1 # 创建神经网络模型 n = neuralNetwork(input_nodes,hidden_nodes,output_nodes, learning_rate) # 加载训练数据 training_data_file = open("datasets/mnist_train_100.csv", 'r') training_data_list = training_data_file.readlines() training_data_file.close() # 训练神经网络 # epochs 表示训练次数 epochs = 10 for e in range(epochs): # 遍历所有数据进行训练 for record in training_data_list: # 数据通过 ',' 分割,变成一个数组 all_values = record.split(',') # 分离出图片的像素点到一个单独数组 inputs = (np.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01 # 创建目标输出值(数字 0~9 出现的概率,默认全部为 0.01) targets = np.zeros(output_nodes) + 0.01 # all_values[0] 表示手写数字的真实值,将该数字的概率设为 0.99 targets[int(all_values[0])] = 0.99 n.train(inputs, targets) pass pass # 训练完毕 print('done')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
验证训练结果
# 加载测试数据 test_data_file = open("datasets/mnist_test_10.csv", 'r') test_data_list = test_data_file.readlines() test_data_file.close() # 测试神经网络 # 记录所有的训练值,正确存 1 ,错误存 0 。 scorecard = [] # 遍历所有数据进行测试 for record in test_data_list: # 数据通过 ',' 分割,变成一个数组 all_values = record.split(',') # 第一个数字为正确答案 correct_label = int(all_values[0]) # 取出测试的输入数据 inputs = (np.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01 # 查询神经网络 outputs = n.query(inputs) # 取出概率最大的数字,表示输出 label = np.argmax(outputs) # 打印出真实值与查询值 print('act: ', label, ' pre: ', correct_label) if (label == correct_label): # 神经网络查询结果与真实值匹配,记录数组存入 1 scorecard.append(1) else: # 神经网络查询结果与真实值不匹配,记录数组存入 0 scorecard.append(0) pass pass # 计算训练的成功率 scorecard_array = np.asarray(scorecard) print("performance = ", scorecard_array.sum() / scorecard_array.size)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
完整代码下载
要查看完整代码可以访问我的资源:基于python的深度神经网络原理与实践
总结
到这里整个深度神级网络的模型原理与实践已经全部进行完毕了,虽然有些部分概念讲解并不是那么仔细,但是你还可以通过搜索其他资料了解更多。
人工智能现在确实是一个非常火热的阶段,希望感兴趣的同学们多多尝试,但是也不要一昧的追新,忘记了自己本来的优势。



