
- 1破解Visio时office失效,激活失败_visio产品激活失败怎么办
- 2机房系统安装服务器,云机房服务器系统安装
- 3优先队列详解(转载)
- 4Llama 2免费托管及API提供_llama-cpp-python
- 5StreamReader和StreamWriter 的使用_go streamreader存文件
- 6YOLOv8改进 | 检测头篇 | 独创RFAHead检测头超分辨率重构检测头(适用Pose、分割、目标检测)_yolov8超分
- 7新手必看|AdSet聚合广告SDK入驻流程_广告sdk接入平台
- 8Pytorch nn.Embedding
- 9使用HBuilder X开发Vue3+node+element-plus_hbuilder vue3
- 10机器学习之优化算法总结_模型不同的样本使用不同的优化函数
dom型xss ---(waf绕过)_dom类xss如何判断
赞
踩
目录
1. 漏洞源码
- <!DOCTYPE html>
- <html lang="en">
-
- <head>
- <meta charset="UTF-8">
- <meta http-equiv="X-UA-Compatible" content="IE=edge">
- <meta name="viewport" content="width=device-width, initial-scale=1.0">
- <title>Document</title>
- </head>
- <body>
- </body>
- <script>
- const data = decodeURIComponent(location.hash.substr(1));;
- const root = document.createElement('div');
- root.innerHTML = data;
-
- // 这里模拟了XSS过滤的过程,方法是移除所有属性,sanitizer
- for (let el of root.querySelectorAll('*')) {
- let attrs = [];
- for (let attr of el.attributes) {
- attrs.push(attr.name);
- }
- for (let name of attrs) {
- el.removeAttribute(name);
- }
- }
- document.body.appendChild(root);
-
- </script>
- </html>

2. 进行绕过
2.1 使用老方法进行绕过
payload:
<img x src='x' xx onerror='alert(1)'>使用此payload的原因具体看上一篇文章—《dom型xss》
注入结果:
注入失败原因:
这里可以看到payload中的元素全部被删除,是因为这里定义了一个名为attrs的数组专门用来删除注入语句里的元素,语句中的元素首先会逐个进入“attrs”数组,然后会在数组中被逐个删除,这样就保证了注入语句中的元素不会出现偶数元素被保留的情况。
2.2 分析注入方式
方式一、 在过滤语句之前就执行payload,然后payload才进入过滤语句被过滤,此时已经没有实际意义。
方式二、 使过滤语句不能过滤payload中的弹窗语句。
2.3 使用svg进行绕过(方式一)
2.3.1 了解什么是dom树,以及dom树的构建。
2.3.2.1 dom树的概念:
DOM 是文档对象化模型(Document Object Model)的简称。DOM Tree 是指通过 DOM 将 HTML 页面进行解析,并生成的 HTML tree 树状结构和对应访问方法。借助DOM Tree,我们能直接而且简易的操作HTML页面上的每个标记内容
DOM技术被Internet Explorer 5.0及以上版本的浏览器所支持,它采取一种非常直观且一致的方式将HTML文档进行模型化处理,并借此提供访问、导航和操作页面的简易编程接口。通过DOM技术,我们不仅能够访问和更新页面的内容及结构,而且还能操纵文档的风格样式。DOM由W3C组织所倡导,这样,大多数浏览器都将最终支持这项技术。
2.3.2.2 dom树的构建:
我们知道JS是通过DOM接口来操作文档的,而HTML文档也是用DOM树来表示。所以在浏览器的渲染过程中,我们是最关注的就是DOM树是如何构建的。
首先在解析一份文档时,先由标记生成器做词法分析,将读入的字符转化为不同类型的Token,然后将Token传递给树构造器处理;接着标识识别器继续接收字符转换为Token,如此循环。实际上对于很多其他语言,词法分析全部完成后才会进行语法分析(树构造器完成的内容),但由于HTML的特殊性,树构造器工作的时候有可能会修改文档的内容,因此这个过程需要循环处理。
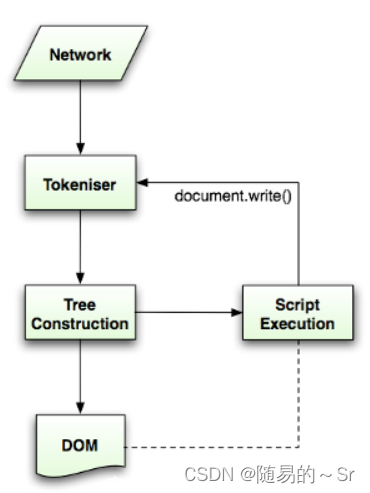
在树构建过程中,遇到不同的Token有不同的处理方式。具体的判断是在HTMLTreeBuilder::ProcessToken(AtomicHTMLToken*token)中进行的。AtomicHTMLToken是代表Token的数据结构,包含了确定Token类型的字段,确定Token名字的字段等等。Token类型共有7种,kStartTag代表开标签,kEndTag代表闭标签,kCharacter代表标签内的文本。所以一个<script>alert(1)</script>会被解析成3个不同种类的Token,分别是kStarTag、kCharacter和kRendTag。在处理Token的过程中,还有一个InsertionMode的概念,用于判断和辅助处理一些异常情况。
在处理Token的时候,还会用到HTMLElementStack,一个栈的结构。当解析器遇到开标签时,会创建相应元素并附加到其父节点,然后将Token和元素构成的Item压入该栈。遇到一个闭标签的时候,就会一直弹出站直到遇到对应元素构成的item为止,这也是一个处理文档异常的办法。比如<div><p>1</div>会被浏览器正确识别达成<div><p>1</p></div>正是借助了栈的能力。
而当处理script的闭合标签是,除了弹出相应item,还会暂停当前的DOM树构建,进入JS的执行环境。换句话说,在文档中的script标签会阻塞DOM的构造。JS环境里对DOM操作又会导致回流,为DOM树构造造成额外影响。
当html中存在js语句时会优先处理js语句然后再继续生成dom树。
2.3.3 分析img方法失败的原因
我们通过断点进行调试:
将过滤的代码注释以后,注入payload并打断点调试一下
payload:
<img src=1 onerror=alert(1)>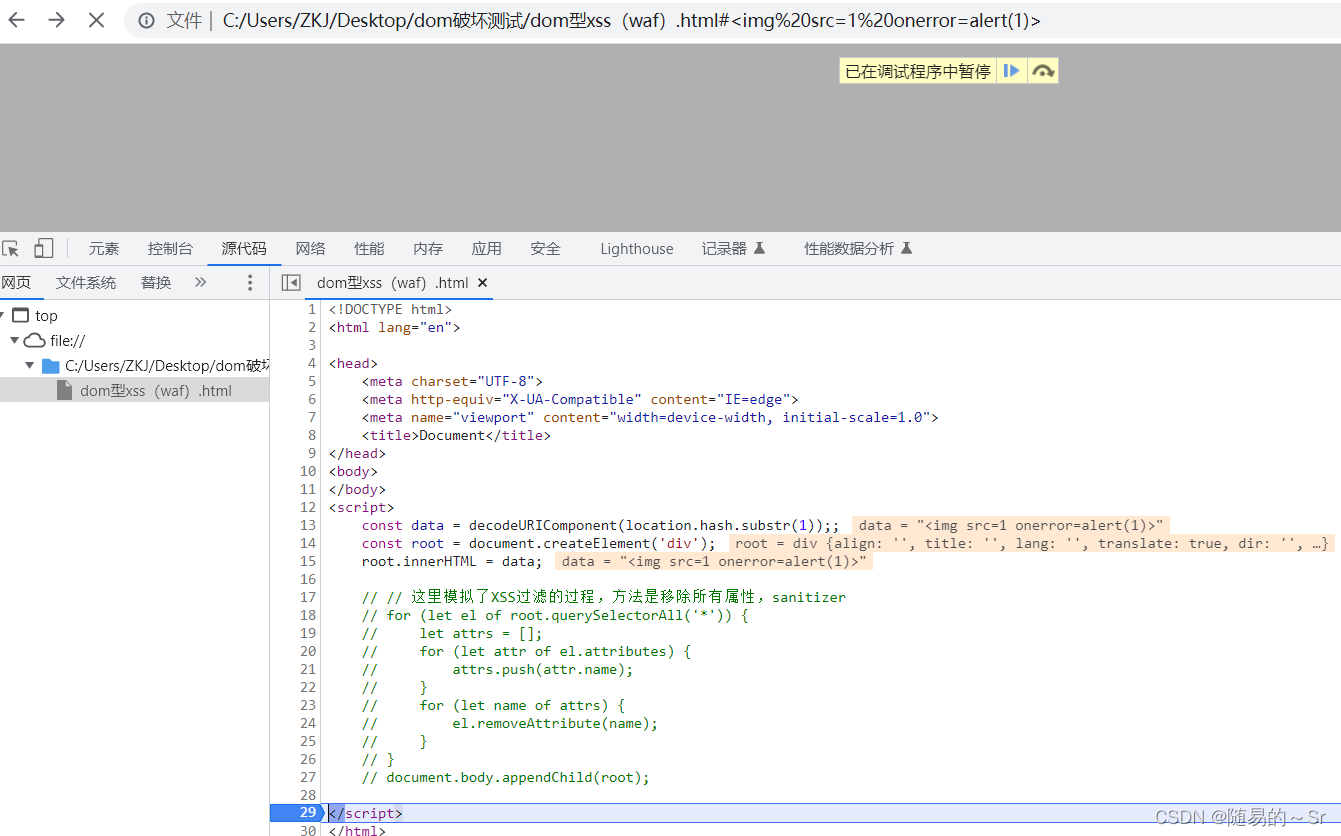
可以发现即使代码已经执行到最后一步,但在没有退出JS环境以前依然还没有弹窗。

此时再点击单步调试就会来到我们的代码的执行环境了。此外,这里还有一个细节就是appendChild被注释并不影响代码的执行,证明即使img元素没有被添加到DOM树也不影响相关资源的加载和事件的触发。
那么很明显,alert(1)是在页面上script标签中的代码全部执行完毕以后才被调用的。这里涉及到浏览器渲染的另外一部分内容: 在DOM树构建完成以后,就会触发DOMContentLoaded事件,接着加载脚本、图片等外部文件,全部加载完成之后触发load事件。
同时,上文已经提到了,页面的JS执行是会阻塞DOM树构建的。所以总的来说,在script标签内的JS执行完毕以后,DOM树才会构建完成,接着才会加载图片,然后发现加载内容出错才会触发error事件。
可以在页面上添加以下代码来测试这一点。
- window.addEventListener("DOMContentLoaded", (event) => {
- console.log('DOMContentLoaded')
- });
- window.addEventListener("load", (event) => {
- console.log('load')
- });
测试注入语句
<img src=1 onerror=console.log("img")> //通过<img>标签打印出img
那么失败的原因也就跟明显了,由于JS阻塞DOM树,一直到JS语句执行结束后,才可以引入img,此时img的属性已经被sanitizer清除了,自然也不可能执行事件代码了。
总结下整个执行流程就是:
最先执行的js ---> for循环用来删除我们标签属性的 ---> js把dom树阻塞住了,js先执行(img所有的属性先删除了)---> js执行结束 ---> 恢复DOM树的加载 ---> DOMCONTENTloaded ---> 执行img(此时img已经没有任何属性了)
总结失败原因:
img和其他payload的失败原因在于sanitizer执行的时间早于事件代码的执行时间,sanitizer将恶意代码清除了。
2.3.4 使用svg劫持innerhtml
poyload:
<svg><svg onload=alert(1)>执行结果:

弹窗成功,但查询后发现<svg>标签中并没有弹窗语句。这是怎么回事呢?
2.3.5 分析双svg标签成功原因
想法:怀疑如方式一中所提到的svg弹窗语句在未进入过滤语句之前就执行了payload,然后payload才进入过滤语句被过滤。
继续使用断点调试的方法检测双svg标签,不过这一次我们将断点打到过滤语句之前进行调试。

神奇的事情发生了,直接弹出了窗口,点击确定以后,调试器才会走到下一行代码。而且,经检查这个地方如果只有一个<svg onload=alert(1)>,那么结果将同img一样,直到script标签结束以后才能执行相关的代码,这样的代码放到挑战里也将失败(测试单个svg时要注意,不能像img一样注释掉appendChild那一行)。那为什么多了一个svg套嵌就可以提前执行呢?带着这个疑问,我们来看一下浏览器是怎么处理的。
触发流程
上文提到一个叫HTMLElementStack的结构用来帮助构建DOM树,它有多个出栈函数。其中,除了Pop All以外,大部分出栈函数最终会调用到PopCommon函数。这两个函数代码如下:
- void HTMLElementStack::PopAll() {
- root_node_ = nullptr;
- head_element_ = nullptr;
- body_element_ = nullptr;
- stack_depth_ = 0;
- while (top_) {
- Node& node = *TopNode();
- auto* element = DynamicTo<Element>(node);
- if (element) {
- element->FinishParsingChildren();
- if (auto* select = DynamicTo<HTMLSelectElement>(node))
- select->SetBlocksFormSubmission(true);
- }
- top_ = top_->ReleaseNext();
- }
- }
-
- void HTMLElementStack::PopCommon() {
- DCHECK(!TopStackItem()->HasTagName(html_names::kHTMLTag));
- DCHECK(!TopStackItem()->HasTagName(html_names::kHeadTag) || !head_element_);
- DCHECK(!TopStackItem()->HasTagName(html_names::kBodyTag) || !body_element_);
- Top()->FinishParsingChildren();
- top_ = top_->ReleaseNext();
-
- stack_depth_--;
- }
当我们没有正确闭合标签的时候,如<svg><svg>,就可能调用到PopAll来清理;而正确闭合的标签就可能调用到其他出栈函数并调用到PopCommon。这两个函数有一个共同点,都会调用栈中元素的FinishParsingChildren函数。这个函数用于处理子节点解析完毕以后的工作。因此,我们可以查看svg标签对应的元素类的这个函数。
- void SVGSVGElement::FinishParsingChildren() {
- SVGGraphicsElement::FinishParsingChildren();
-
- // The outermost SVGSVGElement SVGLoad event is fired through
- // LocalDOMWindow::dispatchWindowLoadEvent.
- // IsOutermostSVGSVGElement 是否是最外层的svg,如果是直接return
- if (IsOutermostSVGSVGElement())
- return;
-
- // finishParsingChildren() is called when the close tag is reached for an
- // element (e.g. </svg>) we send SVGLoad events here if we can, otherwise
- // they'll be sent when any required loads finish
- SendSVGLoadEventIfPossible();
- }
这里有一个非常明显的判断IsOutermostSVGSVGElement,如果是最外层的svg则直接返回。注释也告诉我们了,最外层svg的load事件由LocalDOMWindow::dispatchWindowLoadEvent触发;而其他svg的load事件则在达到结束标记的时候触发。所以我们跟进SendSVGLoadEventIfPossible进一步查看。
- bool SVGElement::SendSVGLoadEventIfPossible() {
- if (!HaveLoadedRequiredResources())
- return false;
- if ((IsStructurallyExternal() || IsA<SVGSVGElement>(*this)) &&
- HasLoadListener(this))
- DispatchEvent(*Event::Create(event_type_names::kLoad));
- return true;
- }
- #先决条件 在于svg不能最外层 onload 必须保证不是最外层。
这个函数是继承自父类SVGElement的,可以看到代码中的DispatchEvent(*Event::Create(event_type_names::kLoad));确实触发了load事件,而前面的判断只要满足是svg元素以及对load事件编写了相关代码即可,也就是说在这里执行了我们写的οnlοad=alert(1)的代码。
总结:
如果只有一个<svg>即只有外层的<svg>load事件会直接返回不会执行,如果为双层<svg>且load事件在内层,load事件会直接执行。所以这就是这里需要使用双<svg>的原因,load事件在没有进入过滤语句时就直接执行,之后才被删除。
实验
我们将过滤的代码注释,并添加相关代码来验证这个事件的触发时间。
- window.addEventListener("DOMContentLoaded", (event) => {
- console.log('DOMContentLoaded')
- });
- window.addEventListener("load", (event) => {
- console.log('load')
- });
测试的代码
<svg onload=console.log("svg0")><svg onload=console.log("svg1")><svg onload=console.log("svg2")>实验结果:
这里通过打印顺序可知,最内层的svg先触发,然后是第二层的svg,之后dom树构建完成,最后外层的svg触发。
套嵌的svg之所以成功,是因为当页面为root.innerHtml赋值的时候浏览器进入DOM树构建过程;在这个过程中会触发非最外层svg标签的load事件,最终成功执行代码。所以,sanitizer执行的时间点在这之后,无法影响我们的payload。
注意一点:

这是用火狐浏览器进行的弹窗测试,弹窗失败。这里可以看到不仅弹窗语句被过滤,就连<div>标签中也没有创建<svg>标签。
断点调试结果:

可以看到data中接收到了双层的<svg>注入语句,但是在火狐浏览器中内层<svg>的弹窗语句没有被直接执行,而是进入到过滤语句中被直接过滤,这是浏览器之间的差异。
2.4 使用details标签延迟响应绕过(方式一)
payload:
<details open ontoggle=alert(1)>执行结果:
测试失败,这个payload有时可行,有时不行。所以,这里也值得探讨一下。
2.4.1 事件触发流程
首先触发代码的点是在DispatchPendingEvent函数里
- void HTMLDetailsElement::DispatchPendingEvent(
- const AttributeModificationReason reason) {
- if (reason == AttributeModificationReason::kByParser)
- GetDocument().SetToggleDuringParsing(true);
- DispatchEvent(*Event::Create(event_type_names::kToggle));
- if (reason == AttributeModificationReason::kByParser)
- GetDocument().SetToggleDuringParsing(false);
- }
而这个函数是在ParseAttribute被调用的
- void HTMLDetailsElement::ParseAttribute(
- const AttributeModificationParams& params) {
- if (params.name == html_names::kOpenAttr) {
- bool old_value = is_open_;
- is_open_ = !params.new_value.IsNull();
- if (is_open_ == old_value)
- return;
-
- // Dispatch toggle event asynchronously.异步调度事件
- pending_event_ = PostCancellableTask(
- *GetDocument().GetTaskRunner(TaskType::kDOMManipulation), FROM_HERE,
- WTF::Bind(&HTMLDetailsElement::DispatchPendingEvent,
- WrapPersistent(this), params.reason));
-
- ....
-
- return;
- }
- HTMLElement::ParseAttribute(params);
- }
ParseAttribute正是在解析文档处理标签属性的时候被调用的。注释也写到了,分发toggle事件的操作是异步的。可以看到下面的代码是通过PostCancellableTask来进行回调触发的,并且传递了一个TaskRunner。
- TaskHandle PostCancellableTask(base::SequencedTaskRunner& task_runner,
- const base::Location& location,
- base::OnceClosure task) {
- DCHECK(task_runner.RunsTasksInCurrentSequence());
- scoped_refptr<TaskHandle::Runner> runner =
- base::AdoptRef(new TaskHandle::Runner(std::move(task)));
- task_runner.PostTask(location,
- WTF::Bind(&TaskHandle::Runner::Run, runner->AsWeakPtr(),
- TaskHandle(runner)));
- return TaskHandle(runner);
- }
跟进PostCancellableTask的代码则会发现,回调函数(被封装成task)正是通过传递的TaskRunner去派遣执行。
清楚调用流程以后,就可以思考,为什么无法触发这个事件呢?最大的可能性,就是在任务交给TaskRunner以后又被取消了。因为是异步调用,而且PostCancellableTask这个函数名也暗示了这一点。
2.4.2 实验验证
可以做一个实验来验证,修改一部分源码,将sanitizer部分延时执行
- <!DOCTYPE html>
- <html lang="en">
-
- <head>
- <meta charset="UTF-8">
- <meta http-equiv="X-UA-Compatible" content="IE=edge">
- <meta name="viewport" content="width=device-width, initial-scale=1.0">
- <title>Document</title>
- </head>
- <body>
- </body>
- <script>
- const data = decodeURIComponent(location.hash.substr(1));;
- const root = document.createElement('div');
- root.innerHTML = data;
-
- // 这里模拟了XSS过滤的过程,方法是移除所有属性,sanitizer
- setTimeout( () => {
- for (let el of root.querySelectorAll('*')) {
- let attrs = [];
- for (let attr of el.attributes) {
- attrs.push(attr.name);
- }
- for (let name of attrs) {
- el.removeAttribute(name);
- }
- }
- document.body.appendChild(root)
- } , 2000) //这里通过setTimeout函数将运行代码做了2秒的延迟
-
- </script>
- </html>
payload:
<details open ontoggle=alert(1)>重新执行结果:

火狐结果:

弹窗成功,但依旧没有弹窗语句。
分析:
因为details标签的toggle事件是异步触发的,由于改变后的源码中延迟了2秒,导致弹窗语句的进程执行完毕之后才被过滤函数过滤掉,这就是为什么弹窗成功却不存在弹窗语句的原因。未改变前的源码没有延迟,所以无法进行异步执行,而被直接过滤掉。
2.4.3 再次更改源码进行details标签测试
更改后的源码:
- <!DOCTYPE html>
- <html lang="en">
-
- <head>
- <meta charset="UTF-8">
- <meta http-equiv="X-UA-Compatible" content="IE=edge">
- <meta name="viewport" content="width=device-width, initial-scale=1.0">
- <title>Document</title>
- </head>
- <body>
- </body>
- <script>
- const data = decodeURIComponent(location.hash.substr(1));;
- const root = document.createElement('div');
- root.innerHTML = data;
-
- let details = root.querySelector("details")
- root.removeChild(details) //这里增加了一个移除details标签的操作
-
- for (let el of root.querySelectorAll('*')) {
- let attrs = [];
- for (let attr of el.attributes) {
- attrs.push(attr.name);
- }
- for (let name of attrs) {
- el.removeAttribute(name);
- }
- }
-
- </script>
- </html>
payload:
<details open ontoggle=alert(1)>执行结果:


弹窗成功,但这里的源码中不存在弹窗语句,同时没有创建的<div>标签,表明此时的details标签不存在,那么是如何进行弹窗的?
分析:
details标签被移除表明其是黑名单的一员,这也是我一开始无法理解为何这个payload能成功执行的原因。但现在我们理清楚调用流程以后,可以有一个大胆的猜测:正是因为details在黑名单里,所以被移除以后其属性没有被直接修改,所以事件依然在队列中没有被取消。
所以我们可以得到结论,details标签的toggle事件是异步触发的,并且直接对details标签的移除不会清除原先通过属性设置的异步任务 ,弹窗可正常执行。
注意:

这里的火狐浏览器弹窗失败。
2.5 DOM clobbering 绕过(方法二)
2.5.1 DOM clobbering(dom破坏)
对于安全来说DOM clobbering主要是用来进行DOM型的XSS攻击,其可以篡改JS函数原本的属性恶意插入一些XSS代码到页面的JS中去,它的特征就是利用了元素配置id或name属性后可以使用包括document、window、自己名称的形式进行访问。其可以对document的属性进行恶意的替换。从而影响dom树的结构造成破坏。也是这一特性让它有了DOM COLBBERING这个名号。
想要了解具体的DOM clobbering(dom破坏)知识点请查看本人之前的博客 “DOM clobbering(dom破坏)”:DOM clobbering(DOM破坏)
这里不再赘述我们继续看漏洞
payload:
<form tabindex=1 onfocus="alert(1);this.removeAttribute('onfocus');" autofocus=true> <img id=attributes><img id=attributes></form> 执行结果:

弹窗成功,且源码中存在弹窗语句。
分析:
payload分析:
- <form tabindex=1 onfocus="alert(1);this.removeAttribute('onfocus');" autofocus=true>
- // 这里是注入的弹窗语句,通过创建了一个form表单,焦点索引为1,聚焦时执行JS代码并删除聚焦,开启自动聚焦
- <img id=attributes><img id=attributes></form>
- // 这里就是主要进行dom破坏的部分,通过建立<img>标签其中的id=attributes就是使用<img>标签对过滤语句中的attributes属性进行劫持,替换掉下面过滤代码中的el.attribute属性为img
payload主要是通过dom破坏替换掉下面过滤代码中的el.attribute属性为img,使过滤时只能对替换后的img进行过滤,无法过滤form表单中的弹窗语句。
那么这里为什么要进行两次dom过滤呢?
2.5.2 只进行一次dom破坏查看注入情况
只进行一次dom破坏的payload:
<form tabindex=1 onfocus="alert(1);this.removeAttribute('onfocus');" autofocus=true> <img id=attributes></form>执行结果:
可以看到浏览器此时弹出了报错信息,说el.attributes不是一个可迭代对象,为什么会报错呢?因为只有可迭代对象才能进入for循环,此时的img只替换了一个el.attributes不能被迭代,所以会弹出说el.attributes不是一个可迭代对象,所以说这里至少需要两个<img>标签的dom破坏,才会出现迭代对象,才能进入for循环被过滤掉。
2.5.3 总结:
两个img的id设置为attributes就是为了形成一个可迭代对象,替换掉下面过滤代码中的el.attribute属性,让它只能删除img标签。而使得我们的form标签逃逸出过滤器。
2.5.4 注意一点
又是我们的火狐浏览器立大功
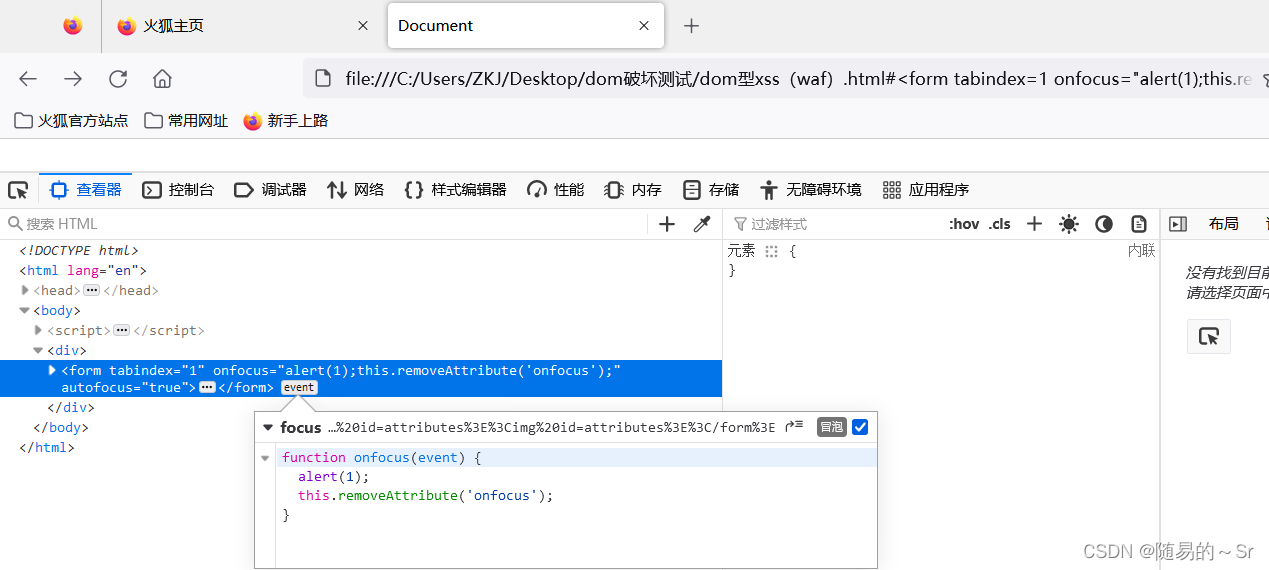
火狐浏览器弹窗失败,我们查看直接注入后的源码发现,form表单中的弹窗语句被火狐的事件监听器中的对焦功能模块监听,导致注入语句被划分开无法形成完整的注入语句,从而导致弹窗失败。(此为个人分析如有问题请指正)
我们在进行打断点的方式进行注入: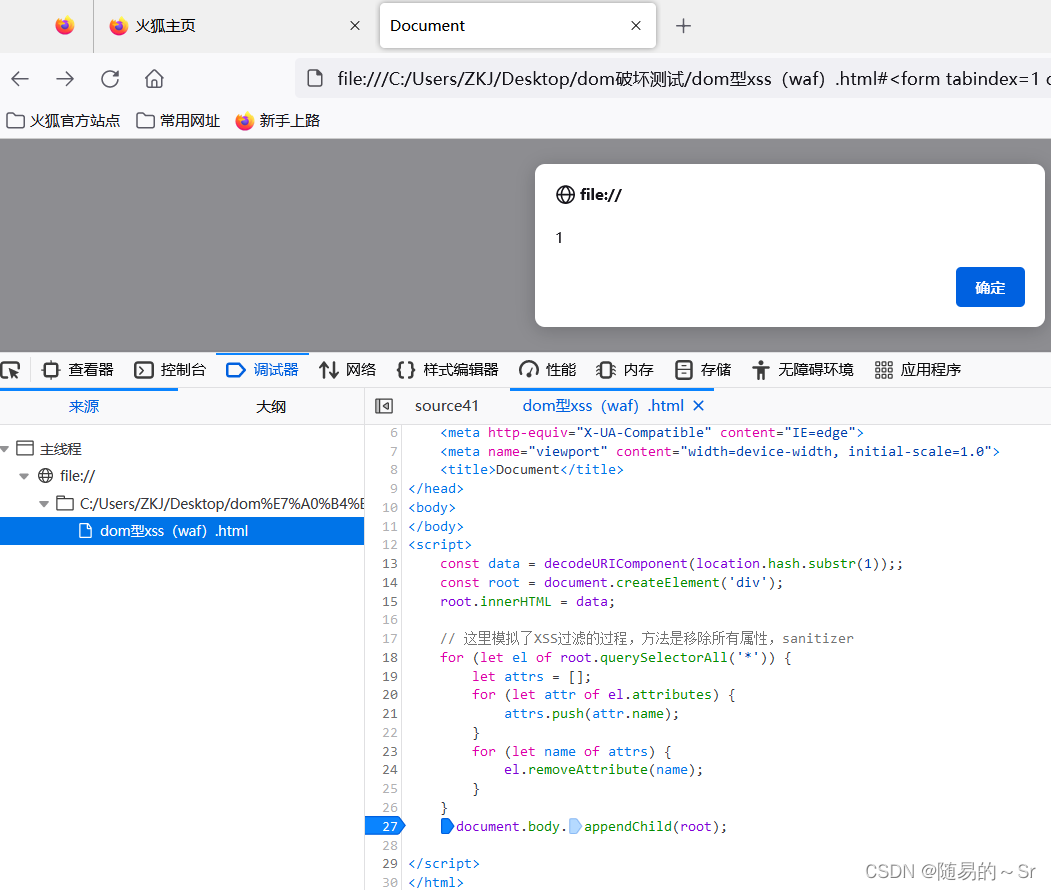
成功形成了弹窗
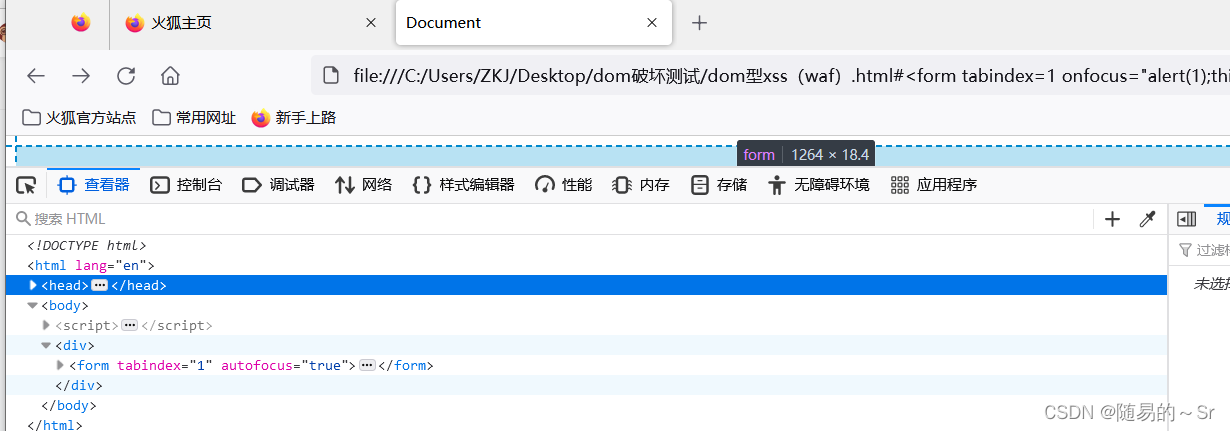
而且注入的弹窗代码完整不存在事件监听器,也可能是事件监听器中的代码被重新进行了拼接,形成了完整的弹窗注入语句。
3. 漏洞总结
对于DOM XSS,我们是通过操作DOM来引入代码,但由于浏览器的限制,我们无法像这样root.innerHTML = "<script>..</script>" 直接执行插入的代码,因此,一般需要通过事件触发。通过上面的例子,可以发现依据事件触发的时机能进一步区分DOM XSS:
1. 立即型,操作DOM时触发。嵌套的svg可以实现
2. 异步型,操作DOM后,异步触发。details可以实现
3. 滞后型,操作DOM后,由其他代码触发。img等常见payload可以实现
从危害来看,明显是1>2>3,特别是1,可以直接无视后续的过滤操作。但是随着浏览器的版本更新。svg的处理流程似乎也有所变化。比如火狐就不支持svg这样的写法进行绕过。同时我们也拥有dom破坏这样的方法,但也要注意是否会被浏览器的事件监听器监听破坏。

