
- 1php路由目录,自学PHP的第22天—ThinkPHP中的路由、ThinkPHP目录结构
- 2Android异常整理——《App研发录—架构设计,Crash分析和竞品技_at android.app.alertdialog.resolvedialogtheme(aler
- 3使用pypinyin将中文转换成不带声调的拼音_npm pinyin 不带声调
- 4word2vec的参数选择及原理简介_word2vec参数
- 5python语言--pip配置清华源_pip tsinghua
- 6基于深度学习的木材表面缺陷检测系统(网页版+YOLOv8/v7/v6/v5代码+训练数据集)
- 7轻松读懂人脸情感分类实现【含图形界面GUI】Python_表情情感分类 python实例
- 8ArcEngine教程(三)——图层的基本操作_arcengine 加载图层
- 9python短文本相似度计算_预训练Bert句向量_flask_python bert-base-chinese 文本相似度
- 10Bag of Tricks for Image Classification with Convolutional Neural Networks
Bert 结构详解_bert的结构组成
赞
踩
Bert 结构详解
1 Bert 模型结构

图1,我们导入bert 14 分类model,并且打印出模型结构。
https://blog.csdn.net/frank_zhaojianbo/article/details/107547338?spm=1001.2014.3001.5501

图2
图 2 是BertForSequenceClassification 模型的结构,可以看出 bert Model 有两大部分组成,embeddings 和 encoder。上面我们已经介绍过了transformer,Bert的结构就是 transformer encoder 的结构。 下面我们分别介绍embeddings 和 encoder。
2 bert embedding 层

图3
由图3 可以看出, word_embeddings 转换器 输入维度是 21128 ,输出维度是 768,21128就是bert字典的大小。 由于max_length 取了512,positional_embeddings 转换器的输入维度是512,它要给每个字加上位置信息。Bert 中token type 只有0 和1,因此,token_type_embeddings 转换器输入为2维。最后 我们把word embedding,positional embedding 和 token_type_embedding 进行向量相加,把最后结果进行 layer Normalization。
3 bert encoder

图4
如图4 bert encoder 主要分为两部分,自注意力和前馈神经网络。
3.1 bert attention
3.1.1什么是查询向量、键向量和值向量向量?


图5


图6


图7

3.1.2通过矩阵运算实现自注意力机制

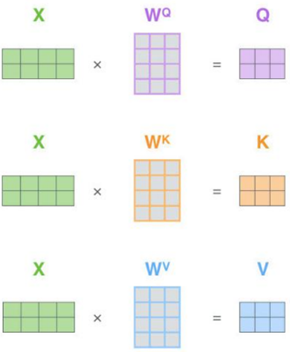
图8


图9
3.1.3 多头注意力
Bert base 使用的是 12 heads attention,multi head attention扩展了模型专注于不同位置的能力。

图10
使用 multi head attention,我们为每个头保持独立的查询、键、值权重矩阵。我们使用X乘以WQ/WK/WV 矩阵来产生查询、键、值权值矩阵。

图11
图 11 与上面自注意力机制计算相同,只需要进行12次不同的权重矩阵运算,我们就可以的到12个不同的Z矩阵。

图12
最后把 12个矩阵拼接成一个矩阵
3.1.4 bert多头注意力

图13
图13 我们再对照一下BertSelfAttention结构。Linear(in_features=768, out_features=768, bias=True) 其实就是query_weight ,key_weight, value_weight 矩阵。Bert base 使用的是 12 heads attention,其query,key,value是64维度。12*64 = 768,这正好和 in_features, out_features 和 embedding size维度想对应。

图14
图14 经过attentions 后Z矩阵和input embeddings 求和归一。
3.2 前馈神经网络

图15
图15 我们把图14 的结果输入到前馈神经网络中,将其结果和输入求和归一。其输出的结果作为下一个bert layer 的输入。
 图16
图16
图16 大家可以对照bert encoder 和 代码看一下。
4 任务层

图17
图17 这个模型是bert 14 分类任务,因此最后 连接了一个 Linear 层,输入768 维度,输出14维度。

