
热门标签
热门文章
- 1强制访问控制,安全模型,基于角色的访问控制模型_在强制访问控制中,从保护的角度看,安全策略可分为
- 2爬取携程酒店信息
- 3鸿蒙IDE和SDK的安装_鸿蒙 sdk下载
- 4多模态虚假新闻检测论文分享(1)MVAE: Multimodal Variational Autoencoder for Fake News Detection_mvae[模型
- 5二分查找步骤及问题总结_二分查找法mid有小数点
- 6YOLOv8最新改进系列:YOLOv8融合MobileOne模块,继续涨点、继续遥遥领先!_mobileoneblock
- 7H5软键盘兼容方案_h5模拟器安卓软键盘吗
- 8sysbench基础测试工具安装、测试、结果分析_sysbench测试结果分析
- 9vscode+platformIO下,上传littleFS文件到esp8266的步骤记录_在platformio自动上传esp8266固件
- 10可信执行环境简介:ARM 的 TrustZone
当前位置: article > 正文
自然语言处理(概念)
作者:小小林熬夜学编程 | 2024-03-31 04:08:09
赞
踩
自然语言处理(概念)
1、 RNN模型简介




1.2传统RNN模型
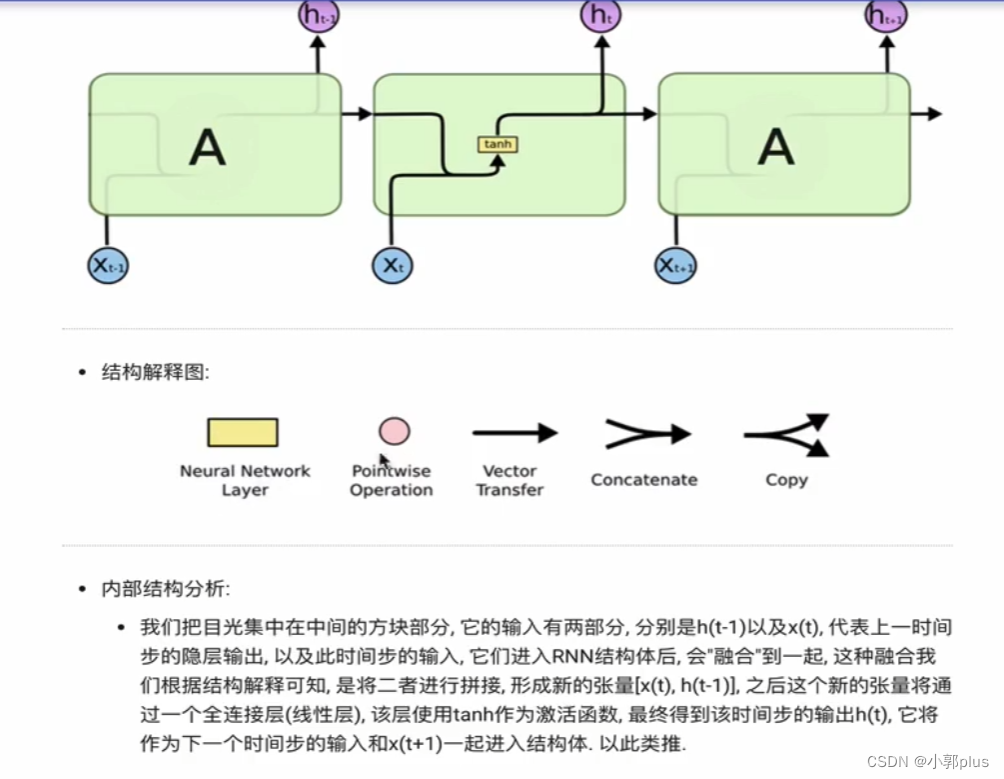
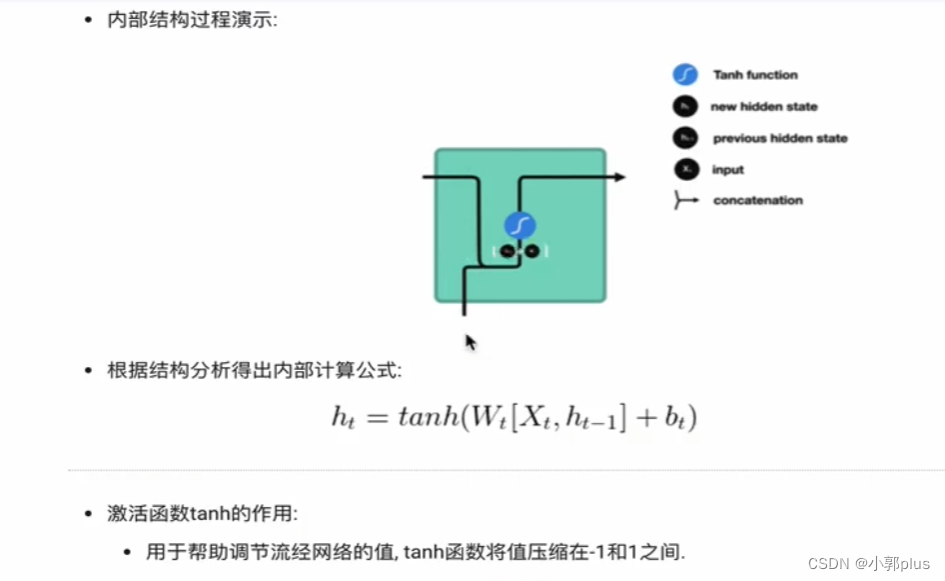





2、LSTM模型

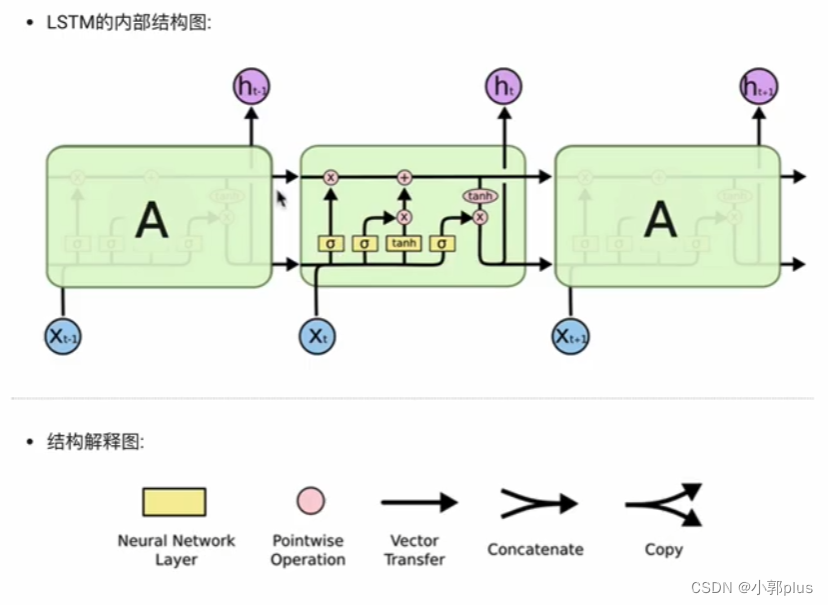

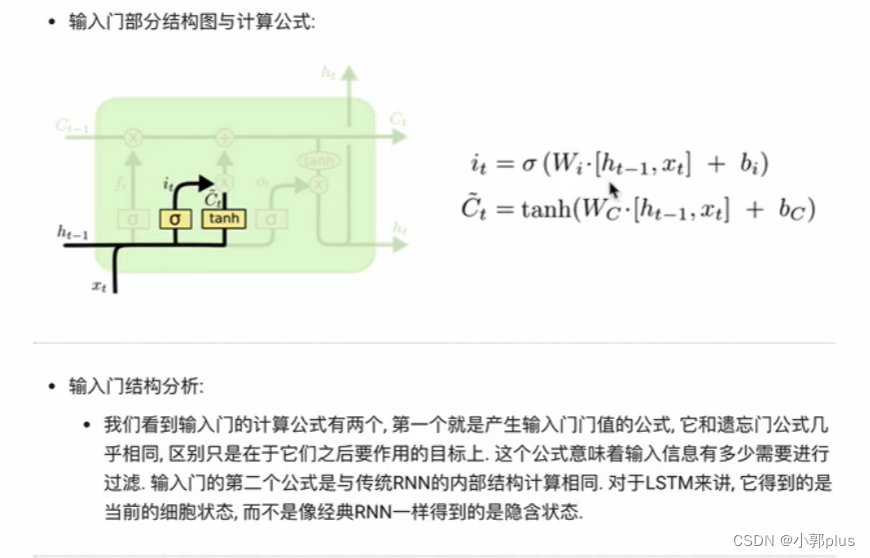
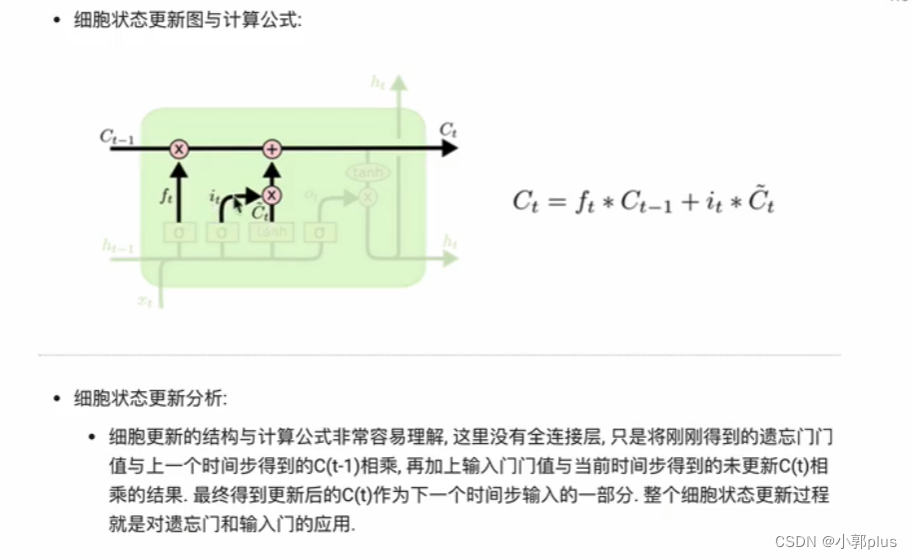
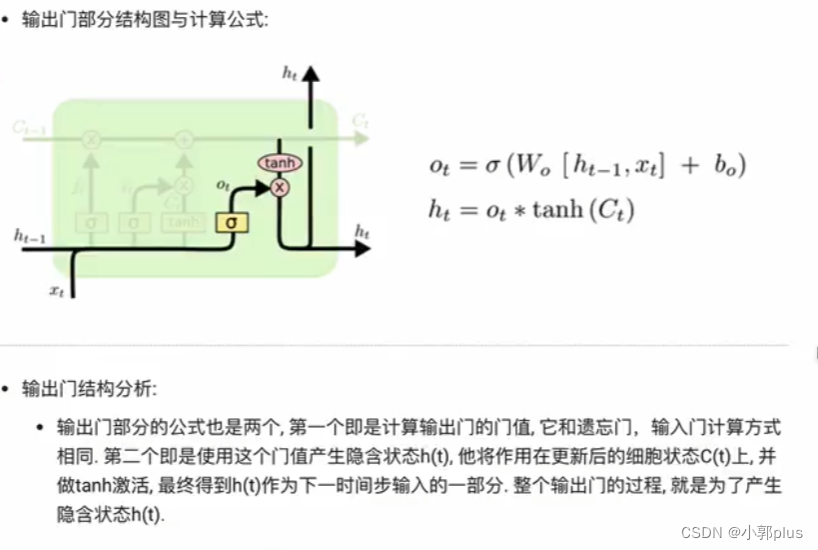
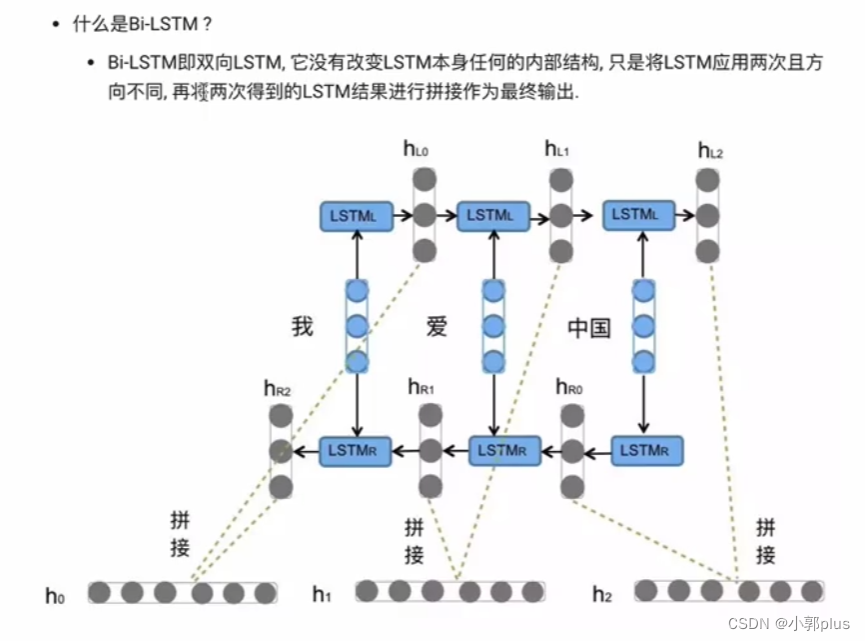

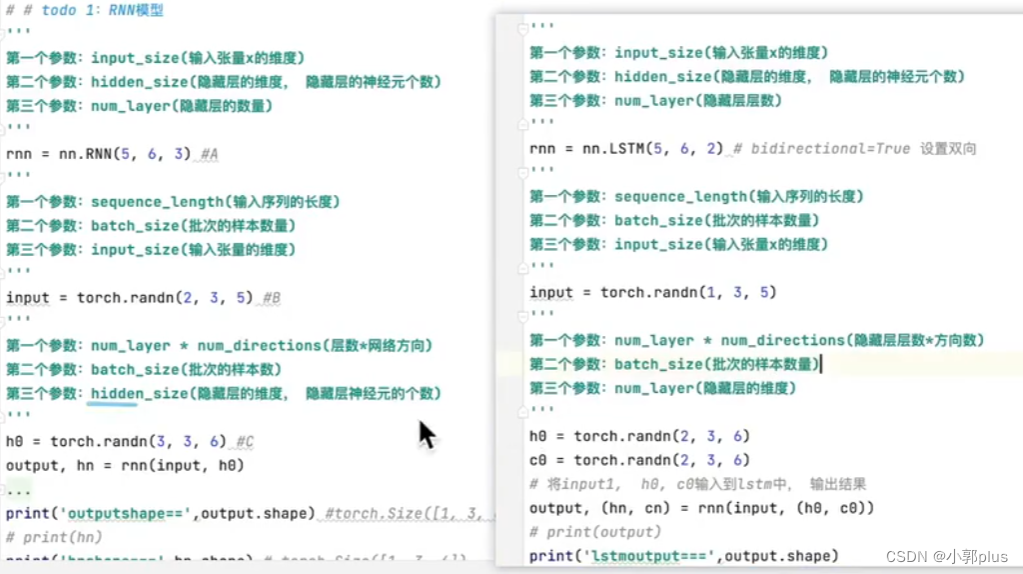
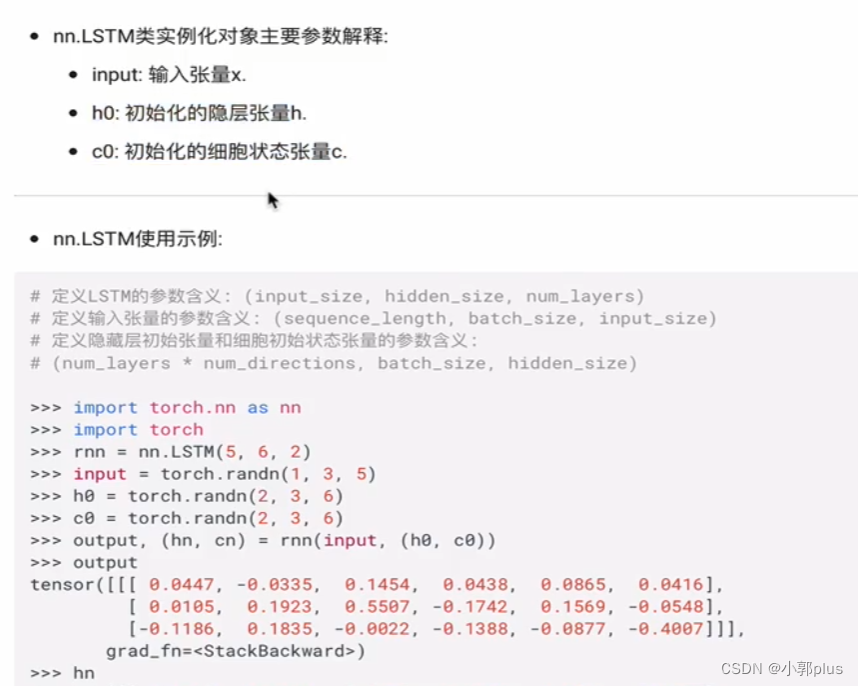
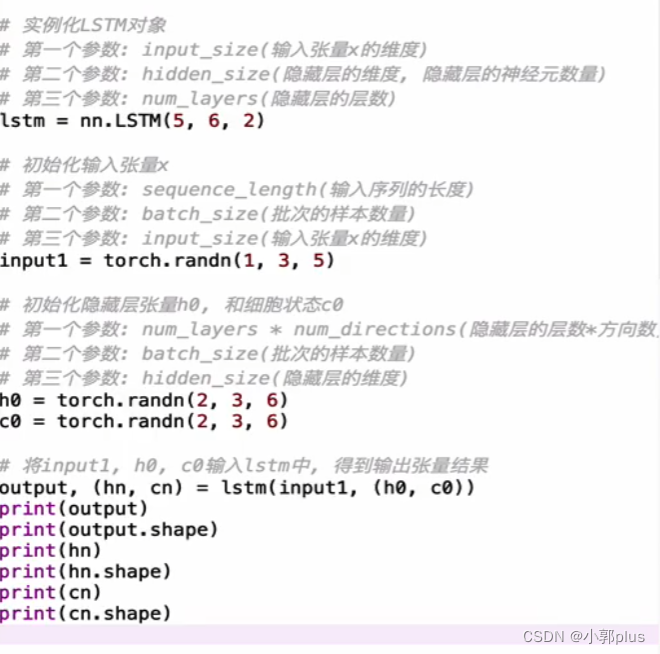




3、GRU模型
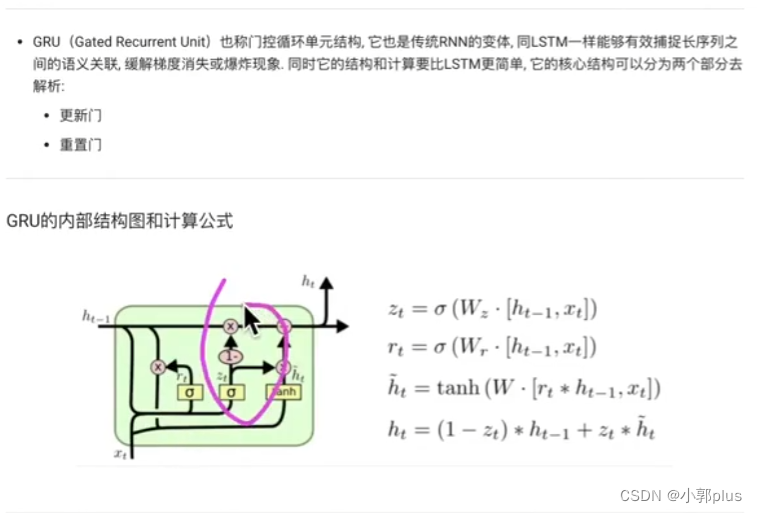




5、注意力机制





6、人名分类器

7 、BERT
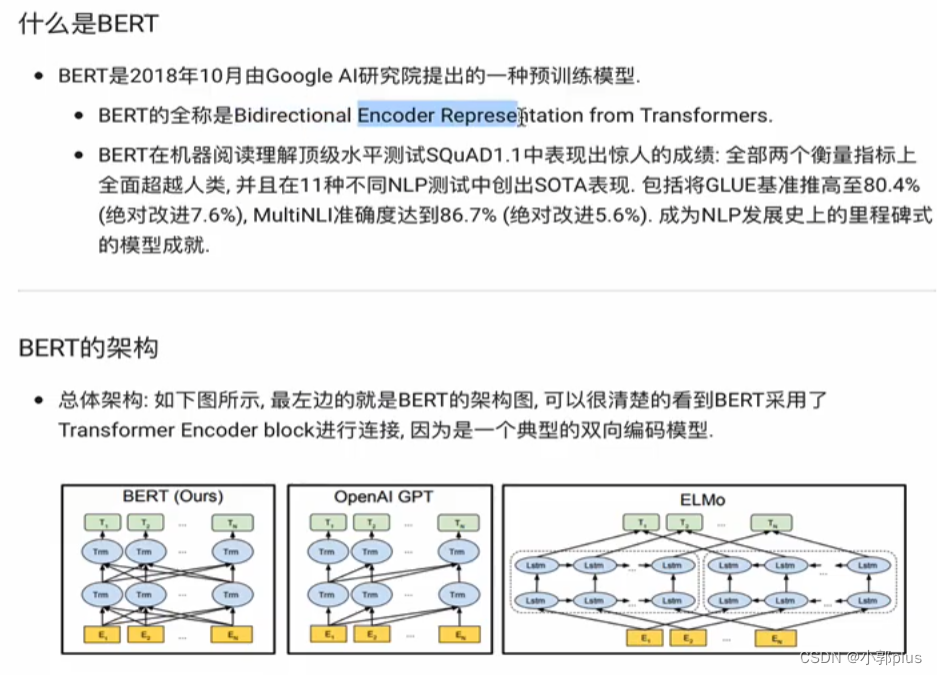
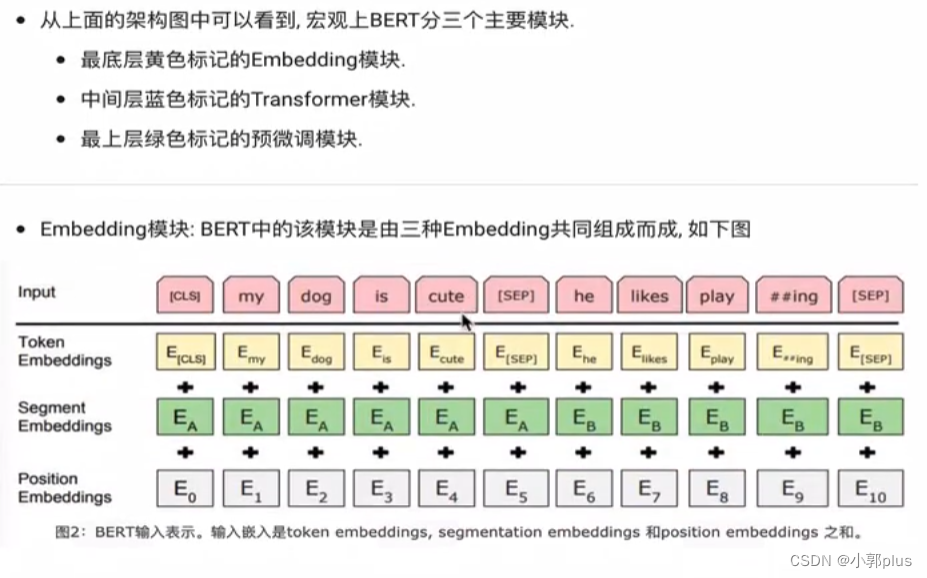


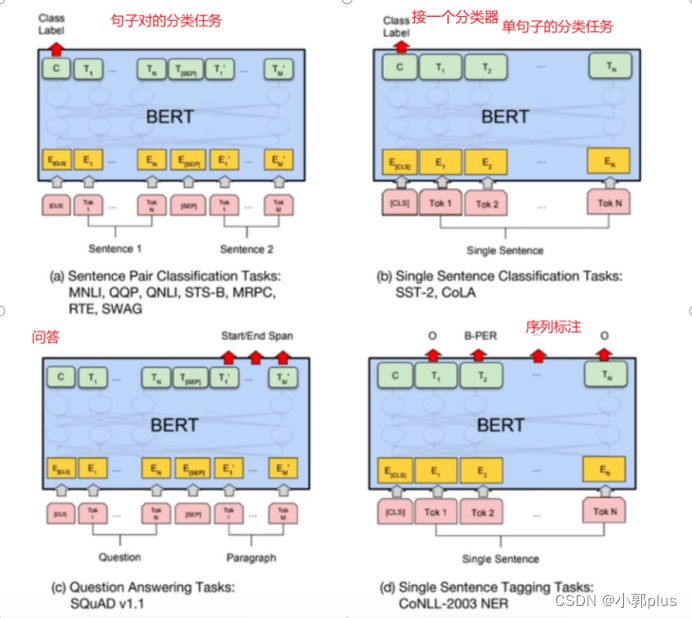





8、Transformer 的结构是什么样子的? 各个子模块有什么作用?
8.1 Encoder模块

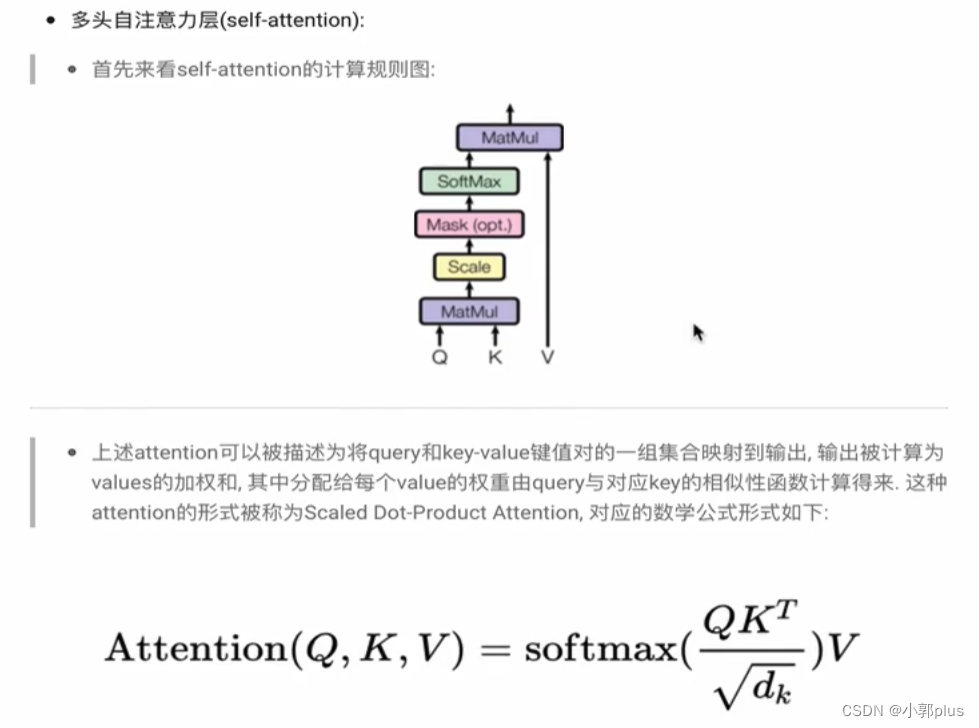
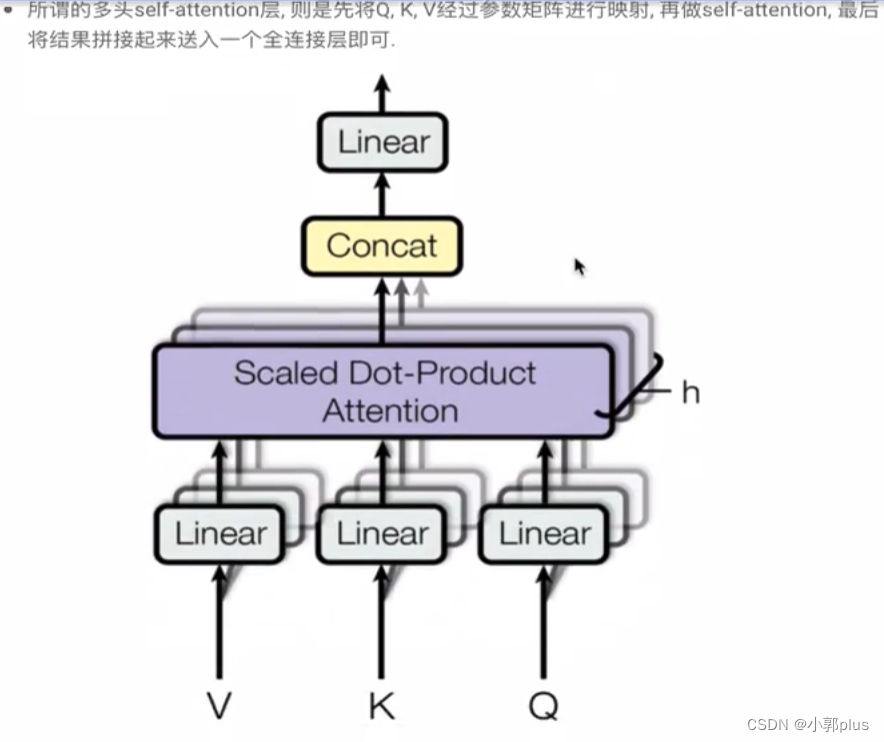


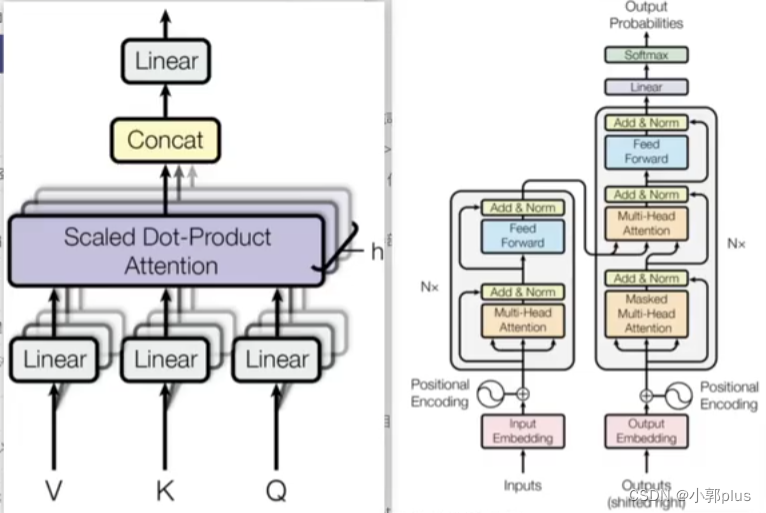
8.2 Decoder模块







8.3 Transformer 结构中的Decoder端具体输入是什么? 在训练阶段和预测阶段一致吗?



8.4 Transformer中一直强调的self-attention是什莫?为什么能发挥如此大的作用?计算的时候如果不使用三元组(Q,K,V),而仅仅使用(Q,V)或者(K,V)或者(V)行不行、




8.5 Transformer 为什莫需要进行Multi-Head Attention? Multi-head Attention 的计算过程是什莫?



8.6 Transformer 相比于RNN/LSTM有什莫优势?为什莫?


8.7 为什么说Transformer可以替代seq2seq?

8.8 self-attention公式中的归一化有什莫作用?为什么要添加scaled

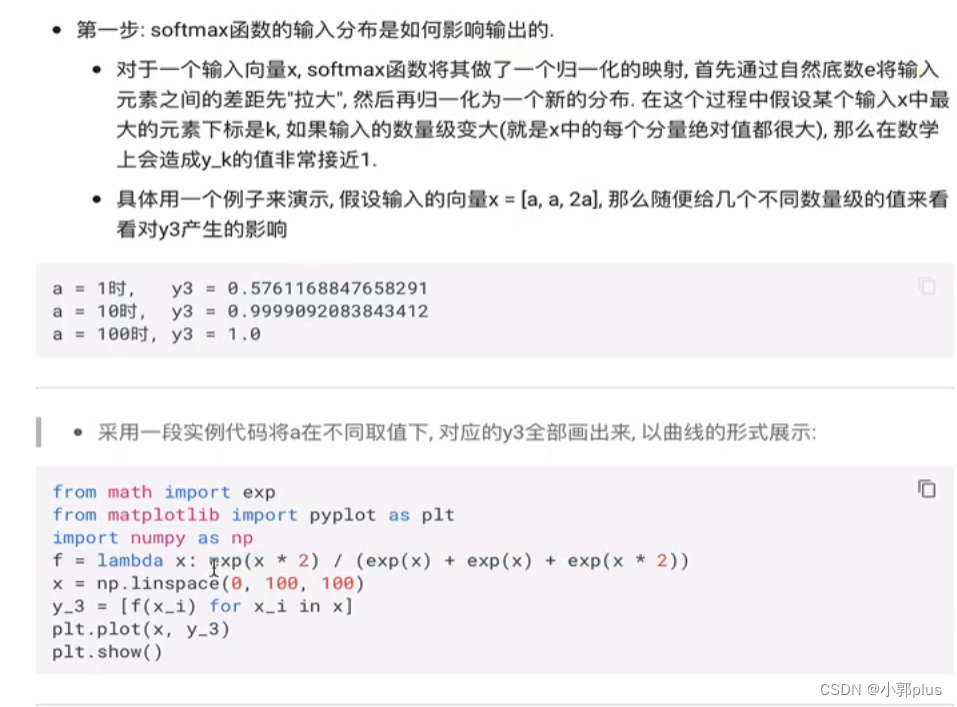
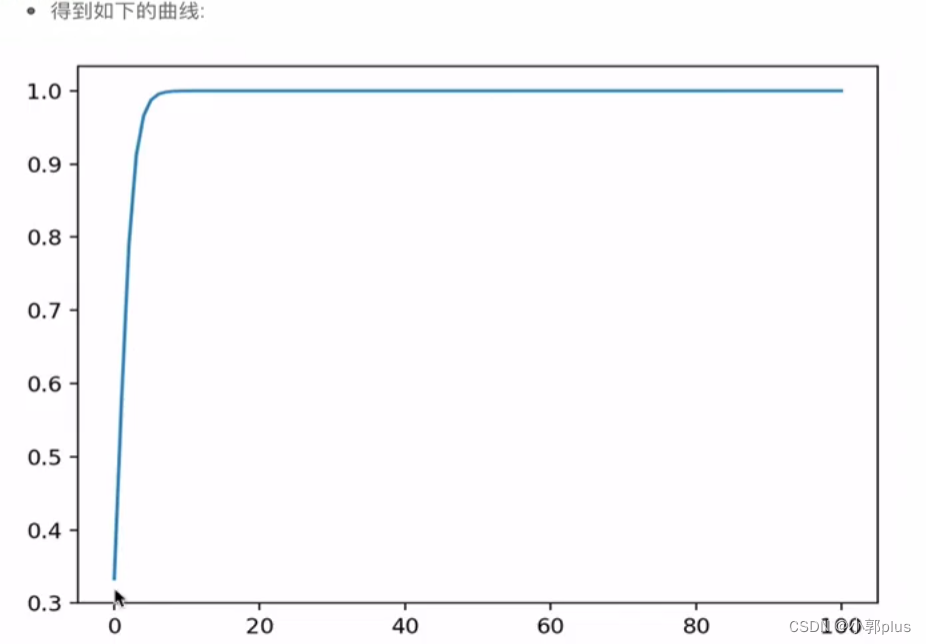








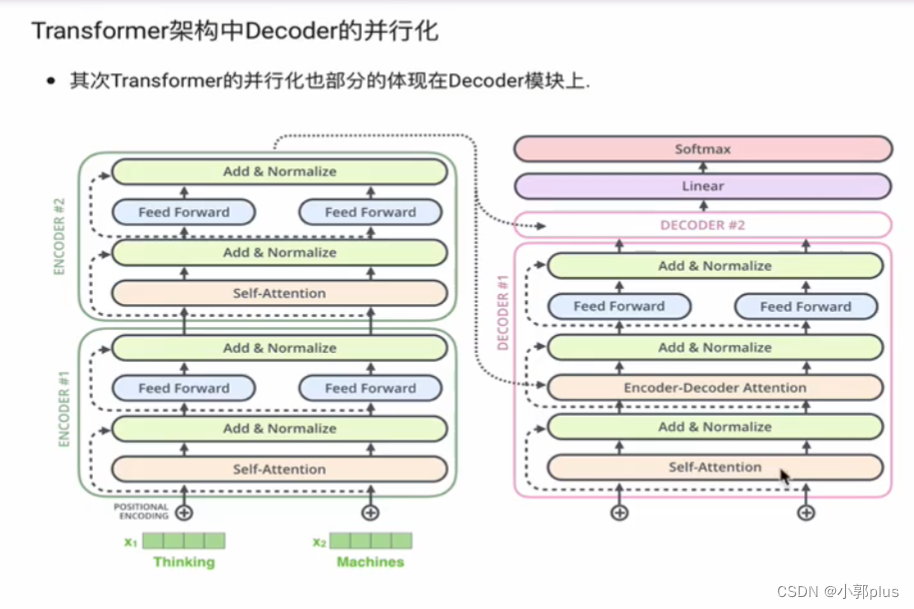
8.8 Transformer 架构的并行化如何进行的?具体体现在在哪?



8.10 BERT 模型的优点和缺点


8.11 BRET 的MLM任务中为什么采用了80%,10%,10%的策略?


8.11 长文本预测任务如果想用BERT来实现,如何构造训练样本?



声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小小林熬夜学编程/article/detail/343051
推荐阅读
相关标签

