
- 1数据结构之单链表详解(C语言手撕)
- 2决策树剪枝python实现_决策树及其python实现
- 3Mac下编写C或C++_mac c++
- 4Android中SharedPreferences的理解_android sharepreference 创建了重复名字
- 5request.getParameter()、request.getInputStream()和request.getReader()
- 6Shell入门之二_for cls, ids in :
- 7girdview分组,统计,排序的解决方案_dev gridveiw 按字段分组后,按其他字段排序
- 8《HarmonyOS开发 – OpenHarmony开发笔记(基于小型系统)》第1章 OpenHarmony与Pegasus物联网开发套件简介_pegasus智能家居开发套件
- 9一站式在线协作开源办公软件ONLYOFFICE,协作更安全更便捷_在线office 开源
- 10临近秋招了,讲讲大家关心的问题_嵌入式秋招要刷leetcode吗
【Kubernetes系列】Kubernetes常见报错_container runtime is not running
赞
踩
目录
- 一、container runtime is not running
- 二、The Service "kubernetes-dashboard" is invalid: spec.ports[0].nodePort: Forbidden: may not be used when type is 'ClusterIP'
- 三、modprobe: FATAL: Module nf_conntrack_ipv4 not found.
- 四、raw.githubusercontent.com 无法访问
- 五、tc not found in system path
- 六、Container image "nginx:1.14.1" already present on machine
- 七、error mounting "/opt/kube/nginx/conf/nginx.conf" to rootfs at "/etc/nginx/nginx.conf": mount /opt/kube/nginx/conf/nginx.conf:/etc/nginx/nginx.conf (via /proc/self/fd/6), flags: 0x5000: not a directory: unknown
- 八、spec.ports[1].nodePort: Invalid value: 10001: provided port is not in the valid range. The range of valid ports is 30000-32767
- 九、calico报错connection is unauthorized: Unauthorized
- 十、ElasticsearchException[failed to bind service]; nested: AccessDeniedException[/usr/share/elasticsearch/data/nodes]
- 十一、Failed to pull image "192.168.0.48/shop/buyer-api:4.2.3.1": rpc error: code = Unknown desc = failed to pull and unpack image "192.168.0.48/shop/buyer-api:4.2.3.1": failed to resolve reference "192.168.0.48/shop/buyer-api:4.2.3.1": failed to do request: Head "https://192.168.0.48/v2/shop/buyer-api/manifests/4.2.3.1": dial tcp 192.168.0.48:443: i/o timeout
- 十二、命名空间无法正常删除,一直为 Terminating 状态
- 十三、provision "default/test-claim" class "managed-nfs-storage": unexpected error getting claim reference: selfLink was empty, can't make reference
- 十四、waiting for a volume to be created, either by external provisioner "fuseim.pri/ifs" or manually created by system administrator
- 十五、从 k8s.gcr.io 拉取失败
一、container runtime is not running
1.问题描述
执行过程可能会报以下错误:
[preflight] Running pre-flight checks
[WARNING FileExisting-tc]: tc not found in system path
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR CRI]: container runtime is not running: output: E0610 17:03:07.643242 25405 remote_runtime.go:925] "Status from runtime service failed" err="rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.RuntimeService"
time="2022-06-10T17:03:07+08:00" level=fatal msg="getting status of runtime: rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.RuntimeService"
, error: exit status 1
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.解决方法
执行以下命令:
rm /etc/containerd/config.toml
systemctl restart containerd
- 1
- 2
再重新执行初始化。
二、The Service “kubernetes-dashboard” is invalid: spec.ports[0].nodePort: Forbidden: may not be used when type is ‘ClusterIP’
1.问题描述
kubernetes-dashboard 报错:
The Service "kubernetes-dashboard" is invalid: spec.ports[0].nodePort: Forbidden: may not be used when type is 'ClusterIP'
- 1
2.解决方法
service中 type 没有指定时默认采用 ClusterIP,需要在配置文件中指定 type:
spec:
type: NodePort
ports:
- port: 443
targetPort: 8443
nodePort: 30001
selector:
k8s-app: kubernetes-dashboard
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
三、modprobe: FATAL: Module nf_conntrack_ipv4 not found.
1.问题描述
配置 ipvs 前提条件时报错:
modprobe: FATAL: Module nf_conntrack_ipv4 not found.
- 1
2.解决方法
高版本内核已经把 nf_conntrack_ipv4 替换为 nf_conntrack 了,将 nf_conntrack_ipv4 改为 nf_conntrack 即可。
四、raw.githubusercontent.com 无法访问
1.问题描述
raw.githubusercontent.com 无法访问。
2.解决方法
进入 ip 查询网站:https://www.ipaddress.com,输入 raw.githubusercontent.com 搜索真实 IP:
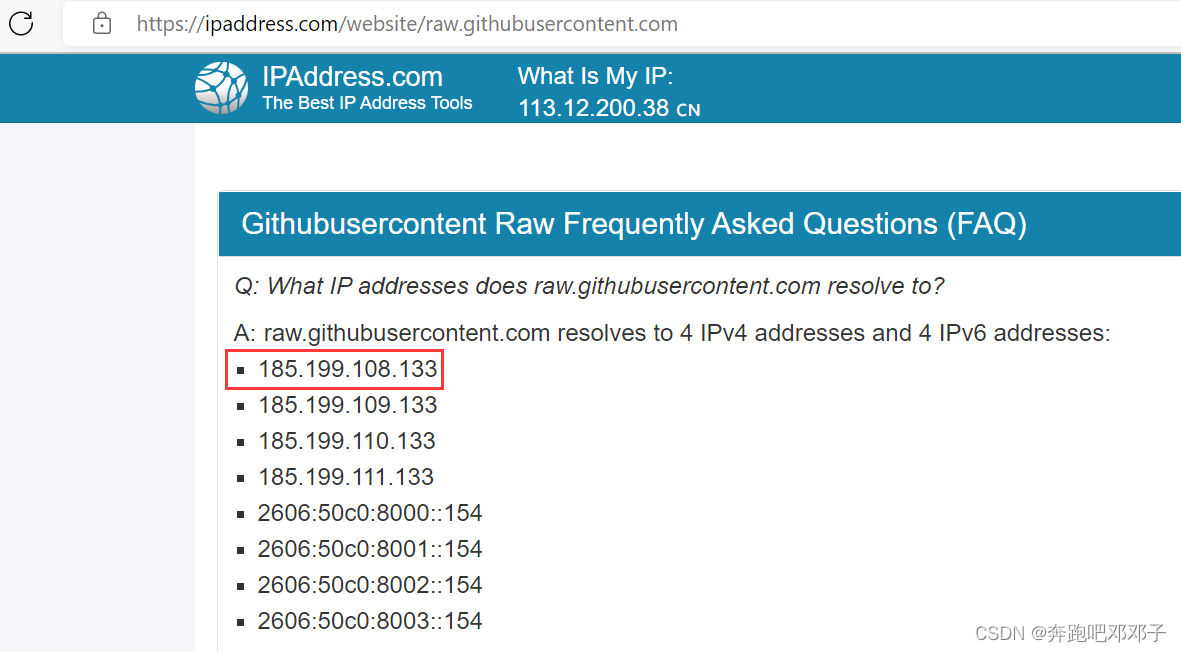
取其中一个 IP,在配置文件 /etc/hosts 加入一行:
185.199.108.133 raw.githubusercontent.com
- 1
五、tc not found in system path
1.问题描述
报错:
[preflight] Running pre-flight checks
[WARNING FileExisting-tc]: tc not found in system path
- 1
- 2
2.解决方法
下载 iproute-tc 进行安装,下载地址:
https://vault.centos.org/centos/8/BaseOS/x86_64/os/Packages/iproute-tc-5.12.0-4.el8.x86_64.rpm
安装:
rpm -ivh iproute-tc-5.12.0-4.el8.x86_64.rpm
- 1
六、Container image “nginx:1.14.1” already present on machine
1.问题描述
删除 pod 再重新创建,状态异常:
[root@master01 deployment]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deployment-7f7dcf645b-l6w5r 0/1 CrashLoopBackOff 7 (60s ago) 11m
- 1
- 2
- 3
通过 kubectl describe pod nginx-deployment-7f7dcf645b-l6w5r 查看,发现报错信息:
Container image "nginx:1.14.1" already present on machine
- 1
2.解决方法
方法1:因 Container image 已经存在,在配置文件中加入判断:
spec:
containers:
- image: nginx:1.14.1
command: [ "/bin/bash", "-c", "--" ]
args: [ "while true; do sleep 30; done;" ]
imagePullPolicy: IfNotPresent
- 1
- 2
- 3
- 4
- 5
- 6
再执行命令:
kubectl apply -f deploy.yaml
- 1
方法2:升级 image,如将 image 改为 nginx1.22.0
七、error mounting “/opt/kube/nginx/conf/nginx.conf” to rootfs at “/etc/nginx/nginx.conf”: mount /opt/kube/nginx/conf/nginx.conf:/etc/nginx/nginx.conf (via /proc/self/fd/6), flags: 0x5000: not a directory: unknown
1.问题描述
删除 pod 再重新创建,状态异常:
[root@master01 deployment]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deployment-7f7dcf645b-l6w5r 0/1 CrashLoopBackOff 7 (60s ago) 11m
- 1
- 2
- 3
通过 kubectl describe pod nginx-deployment-7f7dcf645b-l6w5r 查看,发现报错信息:
Error: failed to create containerd task: failed to create shim task: OCI runtime create failed: runc create failed: unable to start container process: error during container init: error mounting "/opt/kube/nginx/conf/nginx.conf" to rootfs at "/etc/nginx/nginx.conf": mount /opt/kube/nginx/conf/nginx.conf:/etc/nginx/nginx.conf (via /proc/self/fd/6), flags: 0x5000: not a directory: unknown
- 1
2.解决方法
不支持直接挂载文件所致,如果宿主机没有对应同名文件,会生成与文件同名的目录,造成错误。
因此,如果要挂载文件,必须宿主机也要有对应的同名文件,即事先在宿主机创建对应的同名文件。
八、spec.ports[1].nodePort: Invalid value: 10001: provided port is not in the valid range. The range of valid ports is 30000-32767
1.问题描述
部署 Nginx,指定对外端口为 10001 报错:
spec.ports[1].nodePort: Invalid value: 10001: provided port is not in the valid range. The range of valid ports is 30000-32767
- 1
2.解决方法
修改 /etc/kubernetes/manifests/kube-apiserver.yaml,在 - --service-cluster-ip-range=10.10.0.0/16 一行下增加 :
- --service-node-port-range=1-65535
- 1
修改好后如下所示:
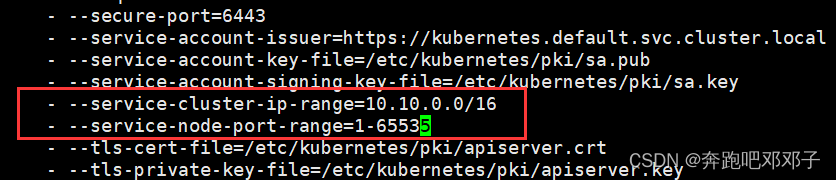
最后重启 kubectl:
systemctl daemon-reload
systemctl restart kubelet
- 1
- 2
九、calico报错connection is unauthorized: Unauthorized
1.问题描述
修改了 calico.yaml 文件后,执行 kubectl apply -f calico.yaml 报错:
connection is unauthorized: Unauthorized
- 1
将配置恢复原状执行,仍然报同样的错误!
隔几天再次出现同样的问题!查看 calico 发现状态有误:
[root@master01 kubernetes]# kubectl get pod --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-56cdb7c587-dsrgp 0/1 Error 133 6d10h
kube-system calico-node-xmvcm 0/1 CrashLoopBackOff 63 (4m27s ago) 6d10h
- 1
- 2
- 3
- 4
重新部署 calico,问题解决!
kubectl delete -f calico.yaml
kubectl apply -f calico.yaml
- 1
- 2
2.解决方法
非常奇怪的问题,最后通过 kubeadm reset ,重新初始化来解决!
后来发现是内存不足导致,腾出内存后,自动恢复正常了!
十、ElasticsearchException[failed to bind service]; nested: AccessDeniedException[/usr/share/elasticsearch/data/nodes]
1.问题描述
es 启动报错:
{"type": "server", "timestamp": "2022-06-16T04:35:45,813Z", "level": "ERROR", "component": "o.e.b.ElasticsearchUncaughtExceptionHandler", "cluster.name": "elasticsearch", "node.name": "elasticsearch-0", "message": "uncaught exception in thread [main]",
"stacktrace": ["org.elasticsearch.bootstrap.StartupException: ElasticsearchException[failed to bind service]; nested: AccessDeniedException[/usr/share/elasticsearch/data/nodes];",
"at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:170) ~[elasticsearch-7.17.3.jar:7.17.3]",
"at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:157) ~[elasticsearch-7.17.3.jar:7.17.3]",
"at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:77) ~[elasticsearch-7.17.3.jar:7.17.3]",
"at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:112) ~[elasticsearch-cli-7.17.3.jar:7.17.3]",
"at org.elasticsearch.cli.Command.main(Command.java:77) ~[elasticsearch-cli-7.17.3.jar:7.17.3]",
"at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:122) ~[elasticsearch-7.17.3.jar:7.17.3]",
"at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:80) ~[elasticsearch-7.17.3.jar:7.17.3]",
"Caused by: org.elasticsearch.ElasticsearchException: failed to bind service",
"at org.elasticsearch.node.Node.<init>(Node.java:1093) ~[elasticsearch-7.17.3.jar:7.17.3]",
"at org.elasticsearch.node.Node.<init>(Node.java:309) ~[elasticsearch-7.17.3.jar:7.17.3]",
"at org.elasticsearch.bootstrap.Bootstrap$5.<init>(Bootstrap.java:234) ~[elasticsearch-7.17.3.jar:7.17.3]",
"at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:234) ~[elasticsearch-7.17.3.jar:7.17.3]",
"at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:434) ~[elasticsearch-7.17.3.jar:7.17.3]",
"at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:166) ~[elasticsearch-7.17.3.jar:7.17.3]",
"... 6 more",
"Caused by: java.nio.file.AccessDeniedException: /usr/share/elasticsearch/data/nodes",
"at sun.nio.fs.UnixException.translateToIOException(UnixException.java:90) ~[?:?]",
"at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:106) ~[?:?]",
"at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:111) ~[?:?]",
"at sun.nio.fs.UnixFileSystemProvider.createDirectory(UnixFileSystemProvider.java:397) ~[?:?]",
"at java.nio.file.Files.createDirectory(Files.java:700) ~[?:?]",
"at java.nio.file.Files.createAndCheckIsDirectory(Files.java:807) ~[?:?]",
uncaught exception in thread [main]
"at java.nio.file.Files.createDirectories(Files.java:793) ~[?:?]",
"at org.elasticsearch.env.NodeEnvironment.lambda$new$0(NodeEnvironment.java:300) ~[elasticsearch-7.17.3.jar:7.17.3]",
"at org.elasticsearch.env.NodeEnvironment$NodeLock.<init>(NodeEnvironment.java:224) ~[elasticsearch-7.17.3.jar:7.17.3]",
"at org.elasticsearch.env.NodeEnvironment.<init>(NodeEnvironment.java:298) ~[elasticsearch-7.17.3.jar:7.17.3]",
"at org.elasticsearch.node.Node.<init>(Node.java:429) ~[elasticsearch-7.17.3.jar:7.17.3]",
"at org.elasticsearch.node.Node.<init>(Node.java:309) ~[elasticsearch-7.17.3.jar:7.17.3]",
"at org.elasticsearch.bootstrap.Bootstrap$5.<init>(Bootstrap.java:234) ~[elasticsearch-7.17.3.jar:7.17.3]",
"at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:234) ~[elasticsearch-7.17.3.jar:7.17.3]",
"at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:434) ~[elasticsearch-7.17.3.jar:7.17.3]",
"at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:166) ~[elasticsearch-7.17.3.jar:7.17.3]",
"... 6 more"] }
ElasticsearchException[failed to bind service]; nested: AccessDeniedException[/usr/share/elasticsearch/data/nodes];
Likely root cause: java.nio.file.AccessDeniedException: /usr/share/elasticsearch/data/nodes
at java.base/sun.nio.fs.UnixException.translateToIOException(UnixException.java:90)
at java.base/sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:106)
at java.base/sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:111)
at java.base/sun.nio.fs.UnixFileSystemProvider.createDirectory(UnixFileSystemProvider.java:397)
at java.base/java.nio.file.Files.createDirectory(Files.java:700)
at java.base/java.nio.file.Files.createAndCheckIsDirectory(Files.java:807)
at java.base/java.nio.file.Files.createDirectories(Files.java:793)
at org.elasticsearch.env.NodeEnvironment.lambda$new$0(NodeEnvironment.java:300)
at org.elasticsearch.env.NodeEnvironment$NodeLock.<init>(NodeEnvironment.java:224)
at org.elasticsearch.env.NodeEnvironment.<init>(NodeEnvironment.java:298)
at org.elasticsearch.node.Node.<init>(Node.java:429)
at org.elasticsearch.node.Node.<init>(Node.java:309)
at org.elasticsearch.bootstrap.Bootstrap$5.<init>(Bootstrap.java:234)
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:234)
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:434)
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:166)
at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:157)
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:77)
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:112)
at org.elasticsearch.cli.Command.main(Command.java:77)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:122)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:80)
For complete error details, refer to the log at /usr/share/elasticsearch/logs/elasticsearch.log
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
2.解决方法
es 没有操作挂载目录权限所致,授权即可:
chmod -R 777 /home/developer/docker/kubernetes/data/middleware/elasticsearch/data
- 1
十一、Failed to pull image “192.168.0.48/shop/buyer-api:4.2.3.1”: rpc error: code = Unknown desc = failed to pull and unpack image “192.168.0.48/shop/buyer-api:4.2.3.1”: failed to resolve reference “192.168.0.48/shop/buyer-api:4.2.3.1”: failed to do request: Head “https://192.168.0.48/v2/shop/buyer-api/manifests/4.2.3.1”: dial tcp 192.168.0.48:443: i/o timeout
1.问题描述
k8s pull harbor 镜像报错:
Failed to pull image "192.168.0.48/shop/buyer-api:4.2.3.1": rpc error: code = Unknown desc = failed to pull and unpack image "192.168.0.48/shop/buyer-api:4.2.3.1": failed to resolve reference "192.168.0.48/shop/buyer-api:4.2.3.1": failed to do request: Head "https://192.168.0.48/v2/shop/buyer-api/manifests/4.2.3.1": dial tcp 192.168.0.48:443: i/o timeout
- 1
2.解决方法
网络问题,写错 IP 地址,无法访问到对应 IP 的服务!!!
改为正确的 IP 即可!!!
十二、命名空间无法正常删除,一直为 Terminating 状态
1.问题描述
执行删除命名空间命令后,查询状态一直为 Terminating:
kubectl get ns
NAME STATUS AGE
default Active 8d
kube-node-lease Active 8d
kube-public Active 8d
kube-system Active 8d
kubernetes-dashboard Active 21h
kubesphere-system Terminating 14m
kuboard Active 20h
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2.解决方法
(1)导出命名空间到 json
kubectl get ns kubesphere-system -o json > ks.json
- 1
(2)编辑 json,去掉 “finalizers” 一节:
将:
{
"apiVersion": "v1",
"kind": "Namespace",
"metadata": {
"annotations": {
"kubectl.kubernetes.io/last-applied-configuration": "{\"apiVersion\":\"v1\",\"kind\":\"Namespace\",\"metadata\":{\"annotations\":{},\"name\":\"kubesphere-system\"}}\n"
},
"creationTimestamp": "2022-06-24T00:39:36Z",
"deletionTimestamp": "2022-06-24T00:50:27Z",
"labels": {
"kubernetes.io/metadata.name": "kubesphere-system"
},
"name": "kubesphere-system",
"resourceVersion": "929511",
"uid": "93a55125-ff17-4c0a-8e5d-55c71b14ca98"
},
"spec": {
"finalizers": [
"kubernetes"
]
},
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
改为:
{
"apiVersion": "v1",
"kind": "Namespace",
"metadata": {
"annotations": {
"kubectl.kubernetes.io/last-applied-configuration": "{\"apiVersion\":\"v1\",\"kind\":\"Namespace\",\"metadata\":{\"annotations\":{},\"name\":\"kubesphere-system\"}}\n"
},
"creationTimestamp": "2022-06-24T00:39:36Z",
"deletionTimestamp": "2022-06-24T00:50:27Z",
"labels": {
"kubernetes.io/metadata.name": "kubesphere-system"
},
"name": "kubesphere-system",
"resourceVersion": "929511",
"uid": "93a55125-ff17-4c0a-8e5d-55c71b14ca98"
},
"spec": {
},
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
(3)启动代理
在一个单独的命令窗口启动代理:
kubectl proxy
Starting to serve on 127.0.0.1:8001
- 1
- 2
(4)执行命令
执行以下命令后删除成功:
curl -k -H "Content-Type: application/json" -X PUT --data-binary @ks.json http://127.0.0.1:8001/api/v1/namespaces/kubesphere-system/finalize
- 1
十三、provision “default/test-claim” class “managed-nfs-storage”: unexpected error getting claim reference: selfLink was empty, can’t make reference
1.问题描述
K8s 上部署 nfs pvc 时报错:
kubectl logs -f nfs-client-provisioner-666fb6b5fb-8x72v
- 1
provision "default/test-claim" class "managed-nfs-storage": unexpected error getting claim reference: selfLink was empty, can't make reference
- 1
2.解决方法
Kubernetes 1.20及以后版本禁用了 selfLink 所致。
修改 /etc/kubernetes/manifests/kube-apiserver.yaml,添加 - --feature-gates=RemoveSelfLink=false 后重新部署:
spec:
containers:
- command:
- kube-apiserver
- --feature-gates=RemoveSelfLink=false
- 1
- 2
- 3
- 4
- 5
十四、waiting for a volume to be created, either by external provisioner “fuseim.pri/ifs” or manually created by system administrator
1.问题描述
K8s 上部署 nfs pvc 时报错:
kubectl describe pvc test-claim
- 1
waiting for a volume to be created, either by external provisioner "fuseim.pri/ifs" or manually created by system administrator
- 1
2.解决方法
Kubernetes 1.20及以后版本禁用了 selfLink 所致。
修改 /etc/kubernetes/manifests/kube-apiserver.yaml,添加 - --feature-gates=RemoveSelfLink=false 后重新部署:
spec:
containers:
- command:
- kube-apiserver
- --feature-gates=RemoveSelfLink=false
- 1
- 2
- 3
- 4
- 5
十五、从 k8s.gcr.io 拉取失败
改为从 国内连接拉取:
url=registry.cn-hangzhou.aliyuncs.com/google_containers
version=v1.23.8
images=(`kubeadm config images list --kubernetes-version=$version|awk -F '/' '{print $2}'`)
for imagename in ${images[@]} ; do
echo $imagename
docker pull $url/$imagename
docker tag $url/$imagename k8s.gcr.io/$imagename
docker rmi -f $url/$imagename
done
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

