
- 1零基础学习Alfred(二)——常用功能和设置_aflred 设置迁移
- 2Flink 是如何保证 Exactly-once语义的?_flink 的 exactlyonce 语义怎么保证
- 3TimesNet处理UEA数据集,用在InceptionTime上
- 4第01课:中文自然语言处理的完整机器处理流程
- 5Android MediaPlayer整体架构源码分析 -【MediaCodec编解码器插件模块化注册和创建处理流程】【Part 2-B】_blocks-per-second
- 6Twin-Builder — 系统级多物理域数字孪生平台_twim builder 模块拼接
- 7python用于人工智能的例子,python人工智能有趣例子_python人工智能案例
- 8爬虫-基于python的旅游数据可视化-计算机毕业设计源码81319_python旅游数据可视化
- 9生产制造园区数字孪生3D大屏展示提升运营效益_可视化大屏实现3d效果的技术有哪些?
- 10启信宝商业大数据助力全国经济普查
人工智能翻译之间的对决:谷歌为什么败给了有道?
赞
踩
来源:CSDN
由于人工智能的飞速发展,机器翻译水平正在大幅提升,并逐渐赶超人类,这已经是不争的事实。然而,同在机器翻译这个赛道里的各位“赛手”,谷歌、有道等传统翻译产品或公司,也正在上演着一场激烈的角逐和比拼。
人工智能翻译大赛,谷歌竟然连败两场?
12月的一个早上,北京,798软件园,一场机器翻译的pk赛正在进行。活动主办方品玩,是一家“有品好玩”的科技媒体。
这场人工智能翻译大赛的规则是三局两胜,第一局考验对话翻译,第二局考验识别能力,第三局是挑战图像翻译。
而三款同台竞技的翻译软件则是:Google翻译、有道翻译官和搜狗翻译。
前两局的的赛果,有道翻译官通过稳定的发挥,以小幅优势领先,尤其是凭借着对《大话西游》的经典台词的准确翻译,让现场的观众真正领教到了人工智能翻译的实力。而真正拉开实际距离的是第三局,拍照翻译。
主持人随机选了一段BBC 气候变化的新闻作为翻译素材,标题是《How Greenland would look without its ice sheet》。

这是三家翻译软件给出的结果:
Google 翻译:如何格陵兰岛看起来没有它的冰 表。
有道翻译官:如果没有冰盖,格陵兰岛将会怎样?
搜狗翻译:没有冰的格陵兰岛会是什么样子。换行之后又翻译了一个字:表。
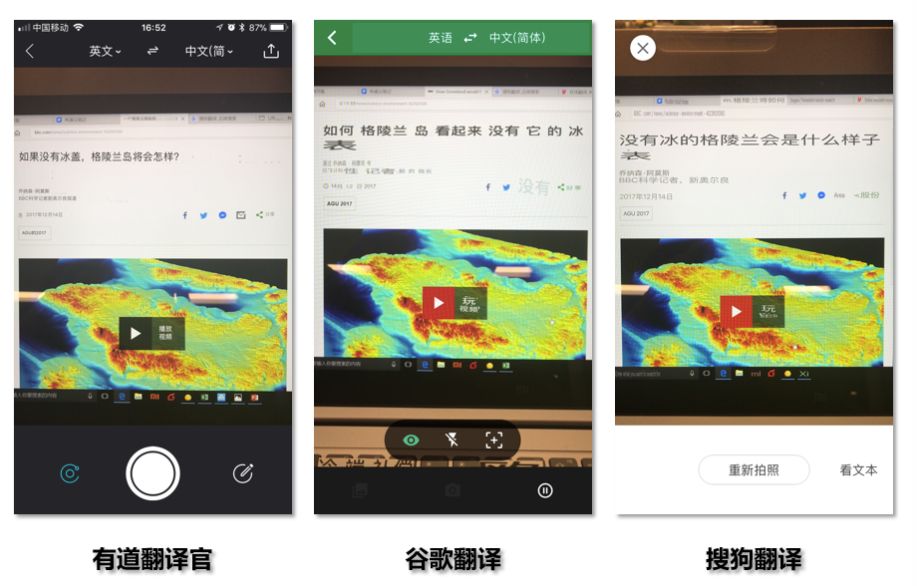
最终,有道翻译官三局两胜,拿下来这场人工智能翻译大赛。
实际上,这不是有道翻译(包括有道词典、有道翻译官、有道翻译网页版等产品)拿下的第一次胜利。早在一个月前,一场人机之间的翻译大赛中,有道翻译同样以高比分拿下第一。
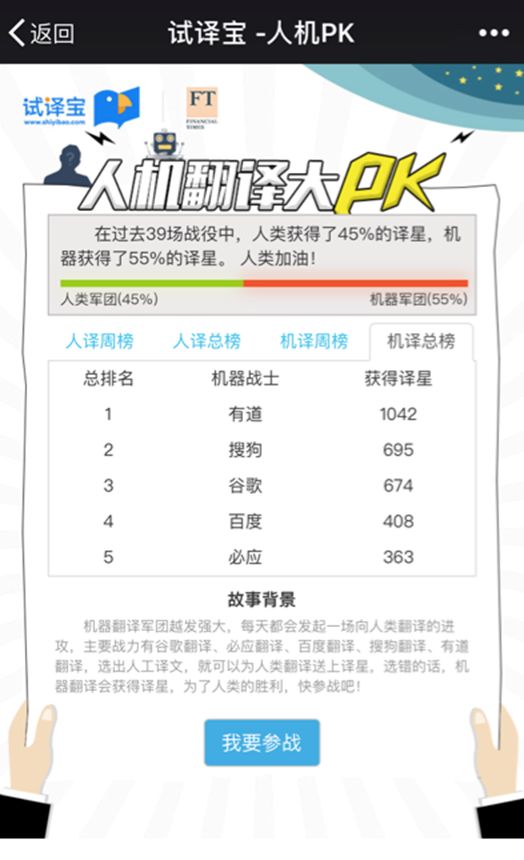
这是一场由第三方翻译评测机构“试译宝”发起了一场机器翻译人机PK赛,人类军团的翻译好手和机器军团同台竞技。
最初的翻译素材采取自《Financial Times》的报道文章,每一段翻译文本下都有对应的四句翻译结果,其中只有一句是人类翻译的,其他三句都是机器翻译的。用户需要在这四句翻译结果中,选出他们认为的最可能是人类翻译的选项,如选择正确,则人类军团得一颗译星,如翻译错误,则相应的机器军团中的选手得一课译星,也就是说获得译星越多,表明其翻译越准确。

你能看出哪个是人类翻译的结果么?
截止最新的结果,人类获得45%译星,机器获得55%译星。在机器军团贡献榜,有道获得译星最多,远高于谷歌、搜狗、百度和必应。(数据来源“试译宝”)。
不到一年的时间,人工智能给机器翻译领域带来了质的飞跃,也改变了普通大众对于机器翻译曾经“蹩脚、不准、不智能”的古板印象。
而在机器翻译领域竞逐的“赛手”也越来越多,有道、谷歌、搜狗、百度,都或早或晚的布局人工智能翻译。
可是,为什么本应该更有优势的谷歌翻译,在两场比赛中却不如有道?
中文翻译不如有道,谷歌输在哪里?
实际上,由于学术界近两年在人工智能方面的突破,给了各家翻译公司提供了大量的理论基础和支撑,各家使用的神经网络翻译模型其实大同小异,但在模型具体的训练上,各家是有差别的。
这其中的原因很多,包括语料的不同、对于句子的“单元处理”以及不同领域内的适配能力。
机器翻译的语料:你吃什么就像什么
数据对于人工智能来说至关重要,一个人工智能系统通常有非常强大的自我学习能力,而它学习的原始素材就是来自于大量的数据,对于神经网络翻译模型而言,这些数据就是语料。
语料有多重要?我们来做一个比喻。
假如把神经网络翻译比作人脑,它可能相当于一个三岁儿童,这个儿童正在咿呀学语,但是学习速度惊人。
小明和小刚是两个年龄三岁左右的儿童,他们大脑构造相同,把他们放置在两个不同的语料环境中学习语言。小明在A语料环境中,在这个语料环境中,“Apple”被翻译成“苹果”,并且长时间不断如此重复。一段时间后,当小明看到“Apple”这个词后,脱口而出就知道是“苹果”。小刚在 B语料环境中,“Apple”被翻译成“蛇果”,偶尔也会翻译成“苹果”,但只有少数一两次。一段时间后,当小刚看到“Apple”这个词后,他会说成是 “蛇果”。
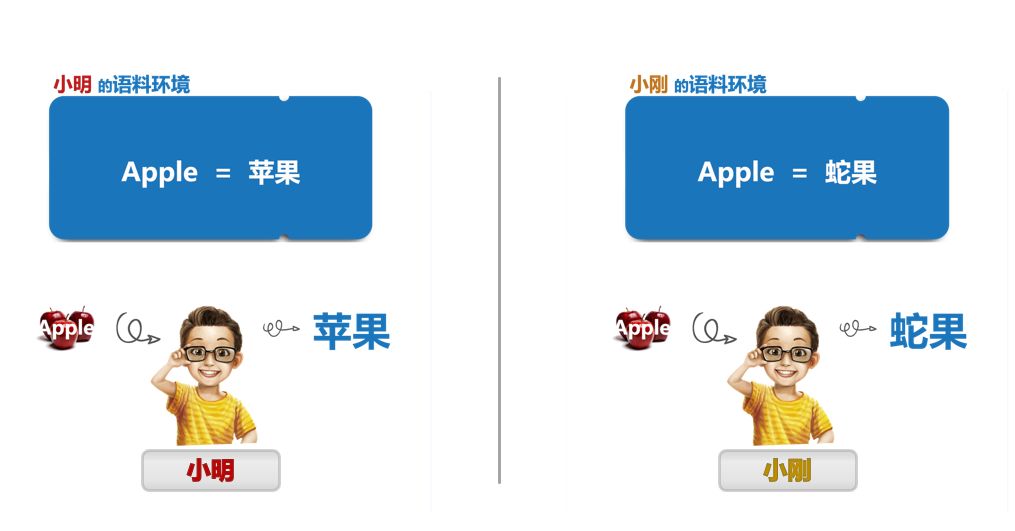
这就是语料对于神经网络模型的重大影响。当模型在大量的数据中进行自我学习时,平行语料中的某一方语料本该有的“词义”缺失或者不准确(比如“Apple”对应的语料中没有“苹果”这个意思,或者很少出现),则模型在翻译的时候,很难或者根本无法翻译出准确的结果。(因为它根本不知道可以翻译成“苹果”)。
如果你对上面的内容大概有所了解,我们再看一段BBC上的新闻:
Universal Music Group's executive vice president of digital strategy, Michael Nash said: "Together, Facebook and UMG are creating a dynamic new model for collaboration between music companies and social platforms to advance the interests of recording artists and songwriters while enhancing the social experience of music for their fans."(摘自BBC 2017.12.21)
谷歌的结果是:
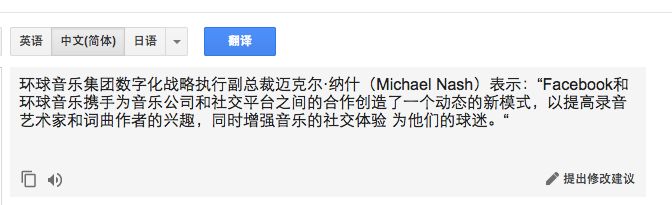
有道的结果是:
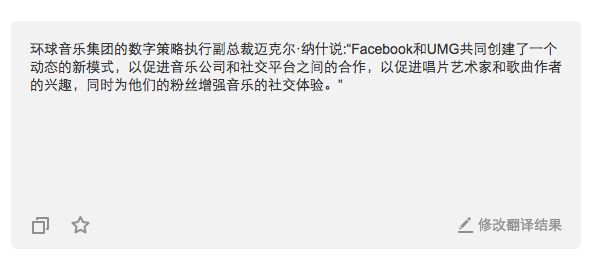
在有道和谷歌的翻译中,有两个地方有明显出入:
“recording artists”谷歌翻译成“录音艺术家”,有道是“唱片艺术家”;“for their fans” 谷歌翻译成“为他们的球迷”,有道是“为他们的粉丝”
通过结果可以看出,在谷歌的平行语料中,“recording ”被翻译成“录音”,而在有道的语料中“recording ”或许既有“录音”的意思,也有“唱片”的意思,但由于和上下文的结合,有道更能理解此处应该翻译为“唱片”更准确。
所以最终的结果就是,有道翻译更懂中文。
在翻译中,有两个基本的维度是必须考核的:忠实度和流利度。我们常说的“信达雅”中,“信”和“雅”都是属于忠实度的层面,“达”则是流利度的层面。而语料准确与丰富与否,不仅仅影响着忠实度,还影响着句子的流利度。
还是上文的句子,“for their fans在原文中放在了句末。在翻译结果里,有道把“为他们的粉丝”往前提,而谷歌“为他们的球迷”则依然放在了句末。
在英语语法中,介词短语如果不是表示强调的情况下,的确一般放在句末。但是在中文的表达里,则会提前。
这种关于语序的调整,神经网络翻译模型也会通过大量的数据进行学习、理解。也就是说,有道翻译的神经网络模型在其训练的语料中,已经大量存在把介词短语往前提的情况,所以当再次遇到这类句子翻译的时候,它就明白应该把“for their fans”往前提。
句子就像蛋糕 怎么“切”决定翻译是否通顺
除了语料的问题,在翻译中还一个常见的问题,也就是如何对句子进行“断句”,专业术语叫做“处理单元”。
我们在初中学古文的时候,老师常会让我们在翻译之前,先把句子进行断句,分成多个部分然后再进行翻译。
神经网络翻译模型也是一样,再对一个句子进行翻译之前,它首先会对这个句子进行“断句”,而“断句”的准确性,会直接影响到后面的翻译结果。
再来看一个例子,如何翻译”小美美美地睡了一觉“呢?
正常人的翻译步骤是“小美-Xiaomei ,美美地-good/nice,睡了一觉-had a sleep”,组合调序得出的翻译结果是”Xiaomei had a good sleep.”
那机器翻译地结果呢?
谷歌翻译:“little America beautiful sleep”
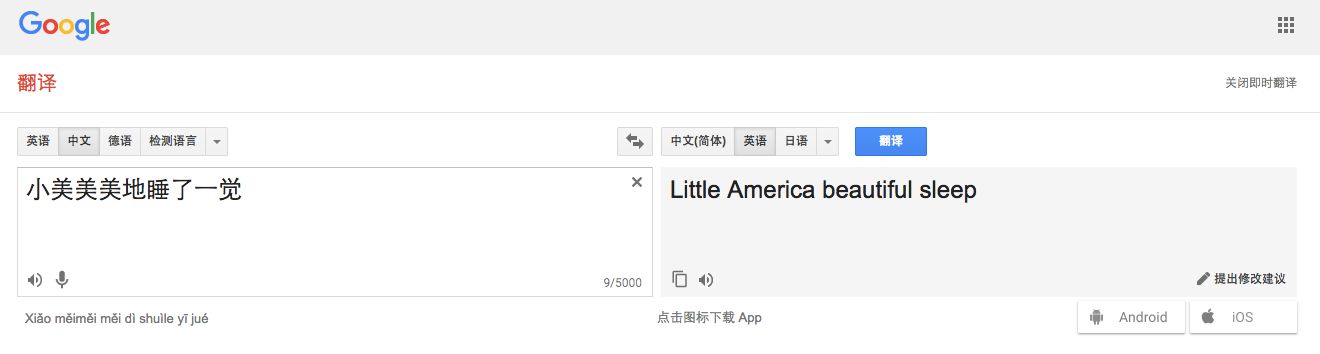
有道翻译:“little beauty had a good sleep”
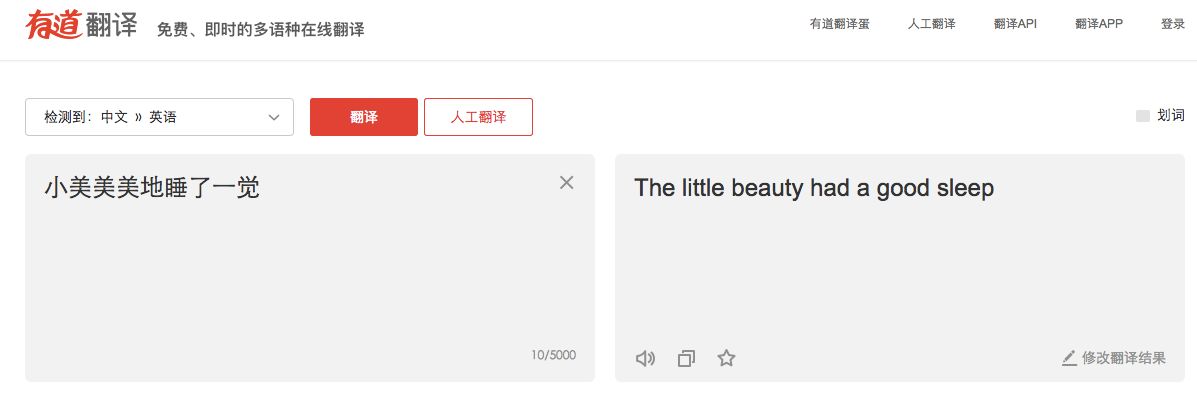
可以看出,有道翻译基本遵循了人类的逻辑进行分词,而谷歌翻译则是一个字一个字的进行分词。谷歌曾在公开资料表示他们是逐字处理,而实际上,这种逐字的处理问题在于,一旦遇到复杂的内容,翻译内容就会造成损失,而这种损失反应在结果中会被放大,造成内容丢失或不通顺。

人脑vs机器的“断句”模式
领域适配技术 让机器彻底战胜人类?
除了语料、“断句”,还有一个因素会很大程度上影响翻译的质量:领域的问题。
打个比方说,一个经常写网络小说的作家,让他去写纯技术文章,他可能无从下笔,因为大家所涉猎的领域不同。同样一个经常翻译新闻的模型,突然遇到一段医学内容,也可能会翻译得非常蹩脚。
在判断一个模型的翻译能力时,主要有三个维度:种类、领域和质量。
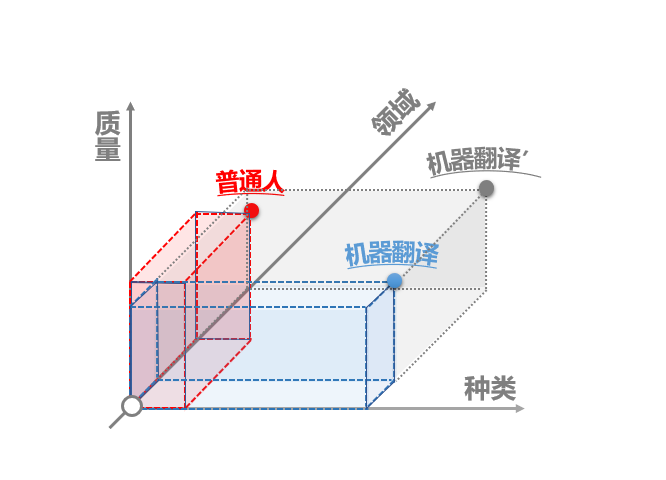
在这个象限中,人类处于 “高质量、高领域、低种类”,例如小方是中国人、二十岁、普通话一级甲等、涉猎领域广泛,但他或许只会说中文,其他语言一概不通。
而机器处于“高质量、低领域、高种类”,因为机器有大量的数据和语言库,市面上随便一个翻译软件都至少能翻译10种以上的语言,并且随着人工智能的发展,机器翻译的质量大幅提升。但所涉猎的领域明显没有人类多,因为每个领域都需要不同的语料训练和模型。
所以,如果机器要全面战胜人类,必须在领域上下功夫;而人类要战胜机器,必须在种类上下功夫。显然,后者有点难以做到,因为没有哪个人可以学会世界上所有语言。
但机器在领域上开始有了新的突破,在有道神经网络翻译中,工程师们已经开始让系统能够自动适配不同领域的内容,称之为“领域适配技术”。
在有道翻译中,系统会默认给出一种翻译结果。但这是否是最优结果呢?未必。因此系统在默认结果基础之上,系统还给出了 “领域适配”之后最优翻译结果,这就很大程度上的提高了翻译的准确性。
比如下面这段话,是一段专业领域的内容:
“The converter is installed at the correct position when the special tool locating pin can be inserted through the opening in the converter bell housing in front of the converter . ”
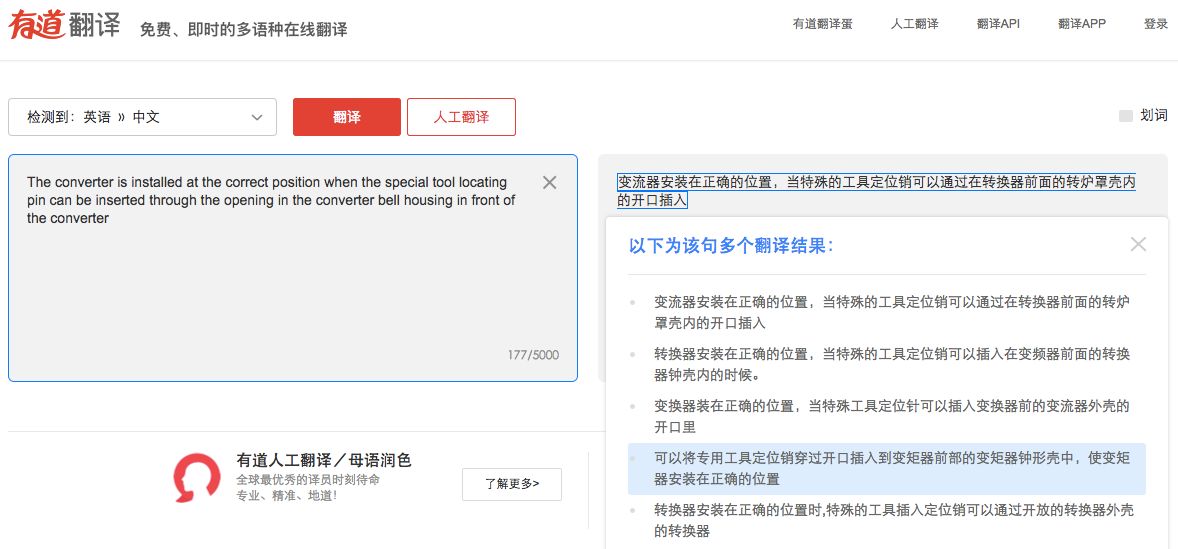
在有道翻译通用模型中,翻译结果并不是最佳的,而点击“更多翻译结果”之后,针对机械领域适配过的模型,翻译出来的效果更好(上图中更多结果的第4个)。
人工智能的热潮还刚开始,对于机器翻译而言,人工智能为其打开了一扇新的大门,但是未来“机器翻译”是否能够更聪明,并彻底超越人类,其实还有很长的一段路要走;
而无论是有道还是谷歌,他们的每一次技术革新和进步,都将为整个人类的生产、生活带来巨大的便利;比如现在出国旅行不会英语,就完成不用担心,直接用翻译软件就能解决。

