
- 1大语言模型LLM_llm 大语言模型
- 2tp5使用workerman实现异步任务_tp5 workerman开发异步任务分发
- 3【论文笔记合集】TimesNet之TimesBlock详解_out.reshape .permute
- 4【Android】【Bluetooth Stack】蓝牙电话协议之拨打电话分析(超详细)
- 5安装Spacy问题一览_安装spacy报错
- 6Flink流计算之聚合函数_flink聚合函数
- 7QML 布局
- 8亚马逊aws深度学习_AWS速查表:Amazon Web Services入门时首先要学习的5件事
- 9微软/edge文本转语音API接口_microsoft speech api
- 10LDA主题模型原理解析与python实现_lda python csdn
NLP | Transformer 中的关键知识点附代码_transformer中的关键词
赞
踩
Transformer是seq2seq的模型,也就是数据有顺序,输出的是序列。
本文主要结合代码理解Transformer。
1.Tokenization
标记化的演变 – NLP 中的字节对编码
自然语言处理的主要组成部分
NLP系统有三个主要组件,可以帮助机器理解自然语言:
- 标记化
- 嵌入
- 模型架构
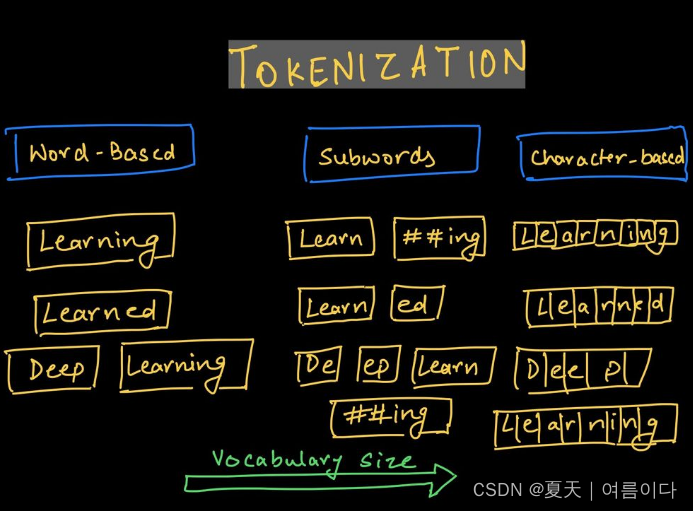
在这节中我们主要关注标记化。标记文本有三种不同的方法,一般为了使深度学习模型从文本中学习,需要两个过程:
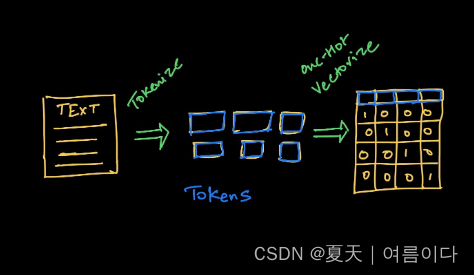
- Tokenization – 决定将用于生成token的算法。
- 将token编码为向量
1.1.基于单词的标记化
如上图,需要决定如何将文本转换为token。多数人会提出的一种简单明了的方法是使用基于单词的标记,按空格拆分文本。在英文,德语法语等语言中中我们当然可以按照空格划分,但是中文的话无法划分。
1.2.基于字符的标记化
为了解决与基于单词的标记化相关的问题,数据科学家尝试了一种逐个字符标记化的替代方法。
这确实解决了缺少单词的问题,因为现在我们正在处理可以使用ASCII或Unicode编码的字符。现在,它可以为任何单词生成嵌入。
每个字符,无论是空格、撇号、冒号还是其他字符,现在都可以分配一个符号来生成向量序列。
缺点:
- 这种方法需要更多的计算资源。基于字符的模型会将每个字符视为一个标记。更多的token意味着更多的输入计算来处理每个token,这反过来又需要更多的计算资源。
- 它还缩小了NLP任务和应用程序的数量。对于长序列字符,您只能使用特定类型的神经网络架构。这限制了我们可以执行的NLP任务的类型。对于实体识别或文本分类等应用程序,基于字符的编码可能是一种低效的方法。
- 存在学习不正确语义的风险。使用字符可能会生成不正确的单词拼写。此外,没有内在意义,与字符一起学习就像没有有意义的语义的学习一样。
1.3.子词标记化
使用基于字符的模型,我们有可能失去单词的语义特征。对于基于单词的标记化,我们需要一个非常大的词汇量来包含每个单词的所有可能变体。
因此,目标是开发一种算法,可以:
- 保留token的语义特征,即每个token的信息。
- 标记化,而不要求使用有限的单词集获得非常大的词汇量。
要解决此问题,您可以考虑根据一组前缀和后缀来分解单词。例如,我们可以编写一个基于规则的系统来识别子词, 等,其中双哈希的位置表示前缀和后缀。"##s""##ing""##ify""un##"
因此,使用子词(如 、 和 )对类似 词的类似词进行标记化。"unhappily""un##""happ""##ily"
该模型只学习相对较少的子词,然后将它们放在一起以创建其他单词。这解决了创建大型词汇所需的内存要求和工作量的问题。
缺点:
- 首先,根据定义的规则创建的一些子词可能永远不会出现在您的文本中以进行标记化,并且最终可能会占用额外的内存。
- 此外,对于每种语言,我们都需要定义一组不同的规则来创建子词。
- 为了缓解这个问题,在实践中,大多数现代标记器都有一个训练阶段,用于识别输入语料库中重复出现的文本并创建新的子词标记。对于罕见的模式,我们坚持使用基于单词的令牌。
- 在此过程中起关键作用的另一个重要因素是用户设置的词汇量的大小。较大的词汇量允许对更常见的单词进行标记化,而较小的词汇表需要创建更多的子单词,以便在不使用标记的情况下创建文本中的每个单词.
1.4.字节对编码 (BPE) 算法
BPE 最初是一种数据压缩算法,用于通过标识公共字节对来查找表示数据的最佳方式。我们现在在NLP中使用它来使用最少数量的token找到文本的最佳表示形式。
- 在每个单词的末尾添加标识符 () 以标识单词的结尾,然后计算文本中的单词频率。
</w> - 将单词拆分为字符,然后计算字符频率。
- 对于预定义的迭代次数,从字符标记中计算连续字节对的频率并合并最常出现的字节对。
- 继续迭代,直到达到迭代限制(由您设置)或达到token限制。
实现代码
STEP 1:添加单词标识符并计算单词频率
- text = "There is an 80% chance of rainfall today. We are pretty sure it is going to rain."
-
-
- words = text.strip().split(" ")
-
- print(f"Vocabulary size: {len(words)}")
STEP 2:将单词拆分为字符,然后计算字符频率
- char_freq_dict = collections.defaultdict(int)
- for word, freq in word_freq_dict.items():
- chars = word.split()
- for char in chars:
- char_freq_dict[char] += freq
-
- char_freq_dict
STEP 3:合并最常出现的连续字节对
- import re
-
- ## create all possible consecutive pairs
- pairs = collections.defaultdict(int)
- for word, freq in word_freq_dict.items():
- chars = word.split()
- for i in range(len(chars)-1):
- pairs[chars[i], chars[i+1]] += freq
STEP 4:迭代n次以找到要编码的最佳(在频率方面)对,然后连接它们以查找子词
将代码构建为函数。这意味着我们需要执行以下步骤:
- 查找每次迭代中最常出现的字节对。
- 合并这些令牌。
- 使用添加新的对编码重新计算字符令牌的频率。
- 继续这样做,直到没有更多的对或你到达循环的末尾。
2.Embeddings
机器学习中,为了学到合适的文字表达,序列中的各个token编码后,通过嵌入转换,可视为神经网络层的一种。 由于嵌入的权重与Transformer模型的剩余部分一起学习,它包含词(vocabulary)中每个单词的向量,这些权重在正态分布N(0,1)中初始化。初始化时词汇(vocab)的大小及模型=512) 需要指定维度(dimension)。 最后是归一化(normalization)阶段, 模型权重相乘。
- import math
- import torch
- from torch import nn
- class Embed(nn.Module):
- def __init__(self,vocab:int,d_model:int=512):
- super(Embed,self).__init__()
- self.d_model=d_model
- self.vocab=vocab
- self.emb=nn.Embedding(self.vocab.self.d_model)
- self.scaling= math.sqrt(self.d_model)
-
- def forward(self,x):
- return self.emb(x)*self.scaling
3.Positional Encoding
详情参考 Transformer | DETR目标检测中的位置编码position_encoding代码详解_夏天|여름이다的博客-CSDN博客
- import torch
- from torch import nn
- from torch.autograd import Variable
-
- class PositionalEncoding(nn.Module):
- def __init__(self, d_model: int = 512, dropout: float = .1, max_len: int = 5000):
- super(PositionalEncoding, self).__init__()
- self.dropout = nn.Dropout(dropout)
-
- # Compute the positional encodings in log space
- pe = torch.zeros(max_len, d_model)
- position = torch.arange(0, max_len).unsqueeze(1)
- div_term = torch.exp(torch.arange(0, d_model, 2) * -(torch.log(torch.Tensor([10000.0])) / d_model))
- pe[:, 0::2] = torch.sin(position * div_term)
- pe[:, 1::2] = torch.cos(position * div_term)
- pe = pe.unsqueeze(0)
- self.register_buffer('pe', pe)
-
- def forward(self, x):
- x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)
- return self.dropout(x)

在该代码中,定位编码是在对数空间(log space)中运算的,以防止数字溢出(numerical overflow)。
4.Multi-Head Attention
transformer之前,使用循环(RNN,LSTM).
Atention layer可以学习查询(Q)和密钥(K)值(V)对之间的映射。 这些名称的意义可能会混淆,因为它们取决于特定的NLP应用程序。 在文本生成的背景下,查询(query)是输入的嵌入,值(value)和键(key)可视为目标。

- import torch
- from torch import nn
- class Attention:
- def __init__(self, dropout: float = 0.):
- super(Attention, self).__init__()
- self.dropout = nn.Dropout(dropout)
- self.softmax = nn.Softmax(dim=-1)
-
- def forward(self, query, key, value, mask=None):
- d_k = query.size(-1)
- scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
- if mask is not None:
- scores = scores.masked_fill(mask == 0, -1e9)
- p_attn = self.dropout(self.softmax(scores))
- return torch.matmul(p_attn, value)
-
- def __call__(self, query, key, value, mask=None):
- return self.forward(query, key, value, mask)
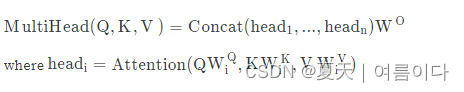
- from torch import nn
- from copy import deepcopy
- class MultiHeadAttention(nn.Module):
- def __init__(self, h: int = 8, d_model: int = 512, dropout: float = 0.1):
- super(MultiHeadAttention, self).__init__()
- self.d_k = d_model // h
- self.h = h
- self.attn = Attention(dropout)
- self.lindim = (d_model, d_model)
- self.linears = nn.ModuleList([deepcopy(nn.Linear(*self.lindim)) for _ in range(4)])
- self.final_linear = nn.Linear(*self.lindim, bias=False)
- self.dropout = nn.Dropout(p=dropout)
-
- def forward(self, query, key, value, mask=None):
- if mask is not None:
- mask = mask.unsqueeze(1)
-
- query, key, value = [l(x).view(query.size(0), -1, self.h, self.d_k).transpose(1, 2) \
- for l, x in zip(self.linears, (query, key, value))]
- nbatches = query.size(0)
- x = self.attn(query, key, value, mask=mask)
-
- # Concatenate and multiply by W^O
- x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)
- return self.final_linear(x)
5.编码-解码
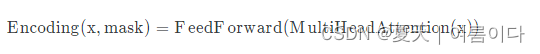
- from torch import nn
- from copy import deepcopy
- class EncoderLayer(nn.Module):
- def __init__(self, size: int, self_attn: MultiHeadAttention, feed_forward: FeedForward, dropout: float = .1):
- super(EncoderLayer, self).__init__()
- self.self_attn = self_attn
- self.feed_forward = feed_forward
- self.sub1 = ResidualConnection(size, dropout)
- self.sub2 = ResidualConnection(size, dropout)
- self.size = size
-
- def forward(self, x, mask):
- x = self.sub1(x, lambda x: self.self_attn(x, x, x, mask))
- return self.sub2(x, self.feed_forward)
原论文中会有有些差异
- class Encoder(nn.Module):
- def __init__(self, layer, n: int = 6):
- super(Encoder, self).__init__()
- self.layers = nn.ModuleList([deepcopy(layer) for _ in range(n)])
- self.norm = LayerNorm(layer.size)
-
- def forward(self, x, mask):
- for layer in self.layers:
- x = layer(x, mask)
- return self.norm(x)
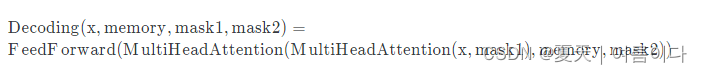
- from torch import nn
- from copy import deepcopy
- class DecoderLayer(nn.Module):
- def __init__(self, size: int, self_attn: MultiHeadAttention, src_attn: MultiHeadAttention,
- feed_forward: FeedForward, dropout: float = .1):
- super(DecoderLayer, self).__init__()
- self.size = size
- self.self_attn = self_attn
- self.src_attn = src_attn
- self.feed_forward = feed_forward
- self.sub1 = ResidualConnection(size, dropout)
- self.sub2 = ResidualConnection(size, dropout)
- self.sub3 = ResidualConnection(size, dropout)
-
- def forward(self, x, memory, src_mask, tgt_mask):
- x = self.sub1(x, lambda x: self.self_attn(x, x, x, tgt_mask))
- x = self.sub2(x, lambda x: self.src_attn(x, memory, memory, src_mask))
- return self.sub3(x, self.feed_forward)
最终如下
- class Decoder(nn.Module):
- def __init__(self, layer: DecoderLayer, n: int = 6):
- super(Decoder, self).__init__()
- self.layers = nn.ModuleList([deepcopy(layer) for _ in range(n)])
- self.norm = LayerNorm(layer.size)
-
- def forward(self, x, memory, src_mask, tgt_mask):
- for layer in self.layers:
- x = layer(x, memory, src_mask, tgt_mask)
- return self.norm(x)
通过的编码器和解码器的表达,可以很容易地制定最终编码器-解码器块。
- from torch import nn
- class EncoderDecoder(nn.Module):
- def __init__(self, encoder: Encoder, decoder: Decoder,
- src_embed: Embed, tgt_embed: Embed, final_layer: Output):
- super(EncoderDecoder, self).__init__()
- self.encoder = encoder
- self.decoder = decoder
- self.src_embed = src_embed
- self.tgt_embed = tgt_embed
- self.final_layer = final_layer
-
- def forward(self, src, tgt, src_mask, tgt_mask):
- return self.final_layer(self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask))
-
- def encode(self, src, src_mask):
- return self.encoder(self.src_embed(src), src_mask)
-
- def decode(self, memory, src_mask, tgt, tgt_mask):
- return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
参考文献
【1】[1706.03762] Attention Is All You Need (arxiv.org)
【2】 The Evolution of Tokenization – Byte Pair Encoding in NLP (freecodecamp.org)

