
- 1收藏!最详细的Python全栈开发指南 看完这篇你还不会Python全栈开发 你来打我!!!_web全栈开发教程 pdf
- 2Python——理论学习笔记_表达式len
- 3《Python+Kivy(App开发)从入门到实践》自学笔记:第三章 图形绘制目录及知识点概览_kivy从入门到实践pdf
- 4Stable Diffusion Prompt用法
- 5yarn、npm设置淘宝国内镜像
- 6[AI视频-suno-V3音乐-AI绘画-AI文本生成-配音]
- 7运动估计算法的程序实现_[磕盐Survey-光流估计]
- 8浅谈serverless/云原生 及 IaaS PaaS SaaS Caas FaaS/BaaS 小白文理解_业界认为serverless=iaas+paas。
- 9c++二分算法_c++二分法
- 10OSG 节点访问器(NodeVisitor)_osg::nodevisitor
经典图像分割网络:Unet 支持libtorch部署推理【附代码】_libtorch 分类推理
赞
踩
深度学习中图像分割是属于像素级的分类,与目标检测和图像分类一样,经过卷积网络提前特征,只不过分割需要对这些特征在像素层面进行分类。
图像分割常应用于医学和无人驾驶领域,基于深度学习的图像分割以Unet为代表,也是很经典的网络,更是很多初学者接触的网络【也包括我】。这篇文章会大致讲一下Unet网络原理和代码,最终实现pytorch环境下python的推理和Libtorch C++推理(支持GPU和CPU)。
说明:
支持python与Libtorch C++推理
python版本支持支持对于单类别检测,C++暂不支持
python板支持视频检测,C++暂不支持(仅图像)
增加网络可视化工具
增加pth转onnx格式
增加pth转pt格式
环境
windows 10
pytorch:1.7.0(低版本应该也可以)
libtorch 1.7 Debug版
cuda 10.2
VS 2017
英伟达 1650 4G
Unet网络
先来看一下网络结构
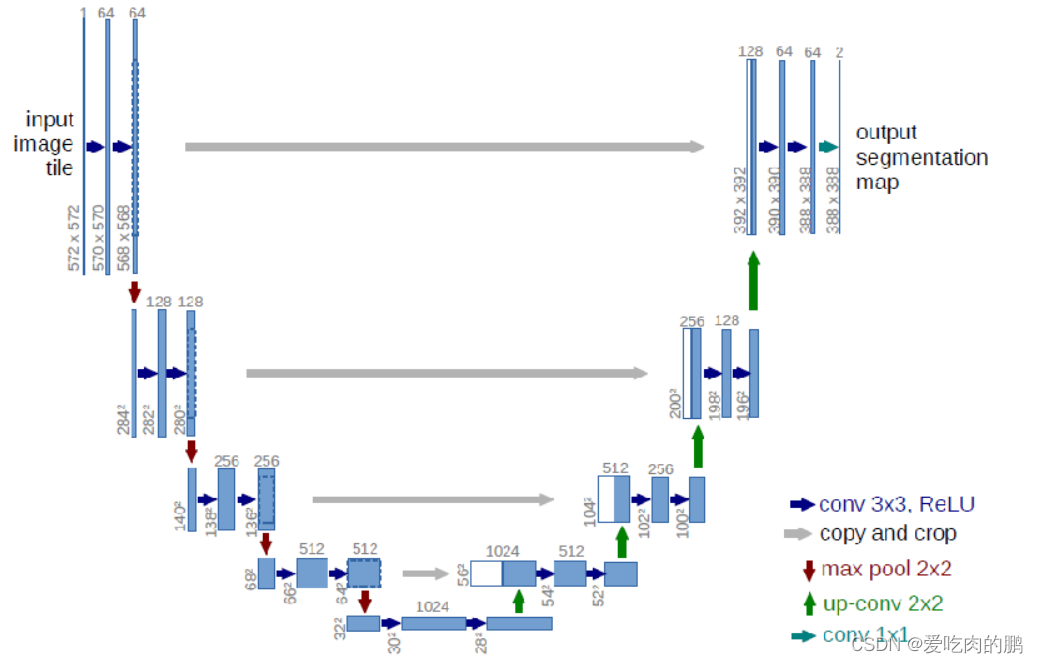
可以看到上面的网络,因为形状是U型,因此称为Unet网络,Unet网络实际也属于encode-decode网络,网络的左边是encode部分,右边则是decode部分。
Unet分为三个部分:
- 主干特征提取网络(与VGG很像):可以获得5个初步的有效的特征层;
由卷积和最大池化构成
- 加强特征提取:通过对主干特征提取网络的5个有效特征层进行上采样(也可以进行反卷积),并且与右边网络特征进行特征融合,获得一个最终的,融合了所有特征的有效特征层;
- 预测部分:利用最终的特征层对每个特征点进行分类,相当于对每个像素点进行分类,而输出的通道数为自己的类别数+1(这个1是包含了背景分类);
最后得到这个特征层相当于是前面特征的特征浓缩,预测过程是对通道数的调整,把最后特征层的通道数调整成需要分类的个数,相当于对每个像素进行分类
有关Unet视频讲解可以看b站Up主:Bubbliiiing
数据集制作
本项目采用数据格式为VOC数据集格式,文件形式如下。
VOCdevkit/
|-- VOC2007
| |-- ImageSets
| | `-- Segmentation
| |-- JPEGImages
| `-- SegmentationClass
`-- voc2unet.py
其中JPEGImages放原始图片.jpg,而SegmentationClass存放是标签文件,格式是png格式。比如像下面这样子。图中红色部分实际上有值的,比如我这个类别是对应1类,那么红色区域内像素则都为1

png图像标签文件
接下来讲怎么制作数据集。
图像分割数据集制作:用labelme工具制作,保存成json格式,再通过json格式进行转化成png格式
安装命令:
pip install labelme==3.16.7首先将自己的数据集放在datasets文件下,目录形式如下:
datasets/
|-- JPEGImages
|-- SegmentationClass
`-- before
其中before文件夹是存放自己原始图像的 。
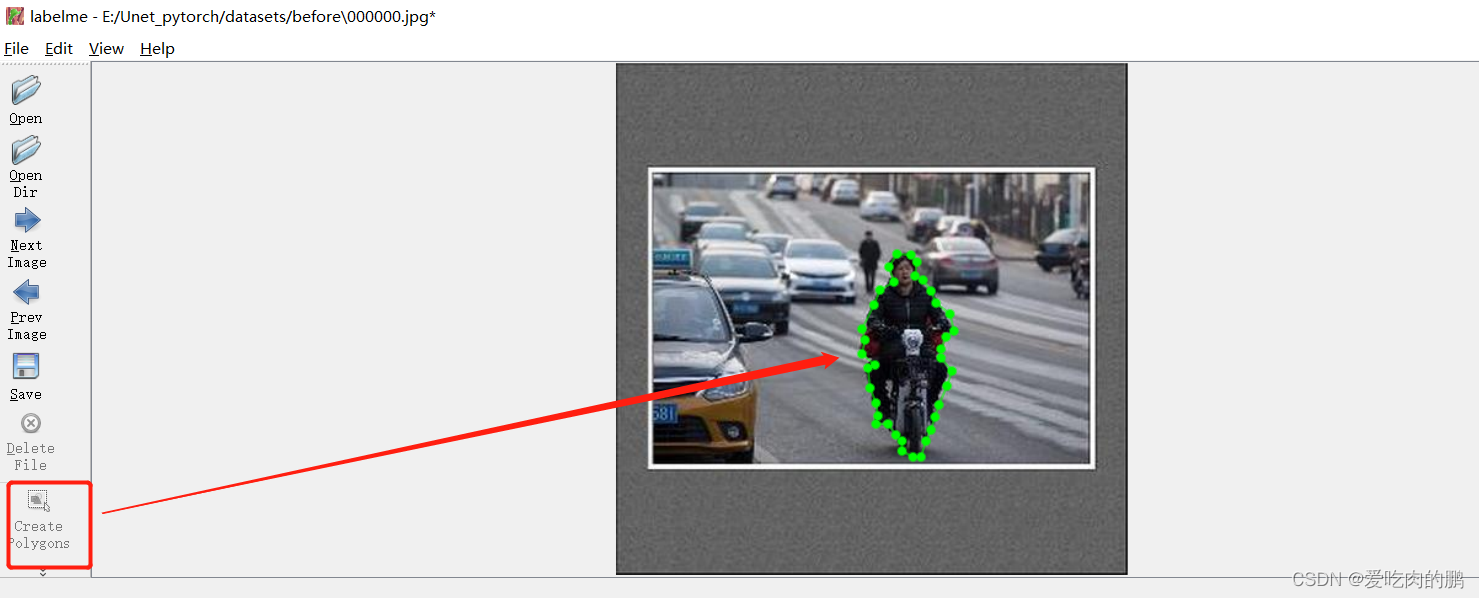
打开cmd,输入labelme【前提是已经安装好了】。界面如下,样子和labelimg很像对不对,但功能是有区别的。

然后通过右边的open dir打开图像路径,开始标注数据集,点击右下方的Create Polygons可以标注关键点(主要要闭环),你标注点越多当然就越好。然后会在你当前目录下生成一个Json文件。
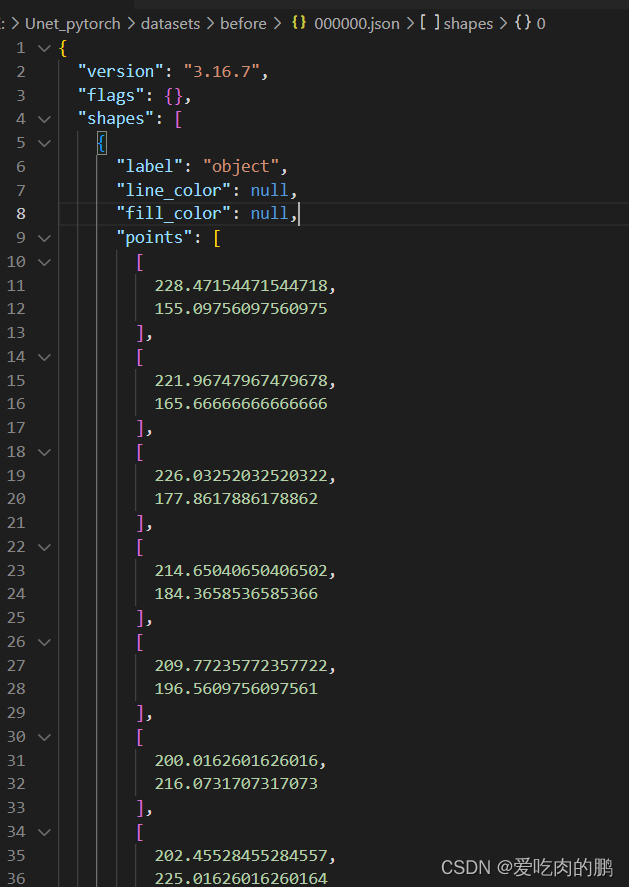
Json内容看下图,可以看到label就是我们自己标注的类,下面的points就是你标注时的关键点信息。
训练
然后进入json_to_dataset.py,修改classes,加入自己的类,注意!不要把_background_这个类删掉!!
运行以后,程序会将原始图copy到datasets/JPEGImags下,然后生成的png标签文件生成在datasets/SegmentationClass文件下。接下来就是这两个文件复制到VOCdevkit/VOC2007/中。
接下来是运行VOCdevkit/voc2unet.py,将会在ImageSets/Segmentation/下生成txt文件。
接下来就可以运行train.py进行训练了,这里需要主要更改 NUM_CLASSES 。
训练的权重会保存在logs下。
损失函数
训练过程中可以利用交叉熵作为损失函数(大多数有关分类的任务都会用这个损失函数),还可以加入dice_loss,可以更好的对样本进行平衡,而这个loss就是一个求FN、TP等这些东西[相信学目标检查测的同学很熟悉了吧],和它有关的则是召唤率与精确率了。该loss代码如下:
- def Dice_loss(inputs, target, beta=1, smooth = 1e-5):
- # inputs是网络的output (batch_size, num_classes, input_shape[0], input_shape[1])
- # target是真实的png (batch_size, h,w, num_classes)
- n, c, h, w = inputs.size()
- nt, ht, wt, ct = target.size()
-
- if h != ht and w != wt: # input和target是w h 是否相等
- inputs = F.interpolate(inputs, size=(ht, wt), mode="bilinear", align_corners=True)
- # temp_inputs shape(batch_size, w*h, c)
- temp_inputs = torch.softmax(inputs.transpose(1, 2).transpose(2, 3).contiguous().view(n, -1, c), -1)
- # temp_target (batch_size, w*h, c)
- temp_target = target.view(n, -1, ct)
-
- #--------------------------------------------#
- # 计算dice loss
- # temp_target[...,:-1]去除背景类的真实值
- # tp=Σ真实值*预测值
- # fp = Σ预测值 - tp
- # fn = Σ真实值 - tp
- #--------------------------------------------#
- tp = torch.sum(temp_target[..., :-1] * temp_inputs, axis=[0,1])
- fp = torch.sum(temp_inputs , axis=[0,1]) - tp
- fn = torch.sum(temp_target[...,:-1] , axis=[0,1]) - tp
- # 3TP+smooth/(3TP+2FN+FP + smooth)
- score = ((1 + beta ** 2) * tp + smooth) / ((1 + beta ** 2) * tp + beta ** 2 * fn + fp + smooth)
- dice_loss = 1 - torch.mean(score)
- return dice_loss

FN:错误的负样本
TN:正确的负样本
TP:正确的正样本
FP:错误的正样本
精确度(P):在所有正样本中,被正确识别的正样本比例
P=TP/(TP+FP)
召回率(R):识别正确的正样本占正确的正样本和被识别成正样本的负样本比例
R=TP/(TP+FN)
F1:召回率和精确率的调和平均数
F1=2TP/(2TP+FN+FP)
预测
说明:本项目可以对所有类进行检测并分割,同时也支持单独某个类进行分割。
网络采用VGG16为backbone。在终端输入命令:
可以对图像进行预测:
python demo.py --predict --image
如果你想和原图进行叠加,在命令行输入:
python demo.py --predict --image --blend
视频预测:
python demo.py --predict --video --video_path 0预测几个类时,用逗号','隔开:
python demo.py --predict --image --classes_list 15,7
参数说明: model_path:权重路径 num_classes:类别数量(含背景),默认21 cuda:是否用GPU推理 predict 预测模式 image:图像预测 video:视频预测 video_path:视频路径,默认0 output:输出路径 fps:测试FPS blend:分割图是否和原图叠加 classes_list:预测某些类,如果是多个类,用','隔开,例如:15,7
libtorch 推理
libtorch环境配置和一些遇到的问题可以参考我另一篇文章,这里不再说:
使用TorchScript和libtorch进行模型推理[附C++代码]_爱吃肉的鹏的博客-CSDN博客_libtorch 推理
进入tools文件,在pth2pt.py中修改权重路径,num_classes,还有输入大小(默认512).运行以后会保存.pt权重文件
将pt权重文件放在你想放的地方,我这里是放在了与我exe执行程序同级目录下。
打开通过VS 2017打开Libtorch_unet/Unet/Unet.sln,注意修改以下地方:(VS 配置libtorch看上面链接)
在main.cpp中最上面修改两个宏定义,一个是网络输入大小,一个是num_classes根据自己的需要修改。
COLOR Classes是我写的一个结构体,每个类对应的颜色,如果你自己的数据集小于21个类,那你不用修改,只需要记住哪个类对应哪个颜色即可。如果是大于21个类,需要自己在定义颜色。
在main.cpp torch::jit::load()修改自己的pt权重路径(如果你没和exe放一个目录中,建议填写绝对路径),当然,如果你希望通过传参的方式也可以,自己修改下即可。
argv[1]是图像路径(执行exe时可以传入)。
然后将项目重新生成,用cmd执行Unet.exe 接着输入图像路径,如下:
Unet.exe street.jpg
将会输出以下内容:
可以看到C++推理结果和python是一样的,此刻就已经成功了。

不过我这里并没有计算libtorch的推理时间,但感觉好像是有点慢的,还需要进一步优化,而且应该是要用加速处理的。
一些注意事项
在libtorch推理中需要用到的一些代码,比如Mat转tensor,tensor转Mat等。
Mat转tensor
input是经过resize和转RGB的输入图像,转的shape(1,512,512,3)
torch::Tensor tensor_image = torch::from_blob(input.data, { 1,input.rows, input.cols,3 }, torch::kByte);推理:
在实际验证中,如果在送入模型之前用tensor_image.to(device)即将张量放入cuda,在下面cuda推理中会报关于内存的错误,但在cpu下不会,感觉是libtorch的一个bug吧,但如果在forward函数中将tensor_image放入cuda就可以正常推理。这点需要注意。
output = module.forward({tensor_image.to(device)}).toTensor(); //The shape is [batch_size, num_classes, 512,512]C++中张量的切片:
指的是对最后一个维度的第0维度进行操作
seg_img.index({ "...", 0 })CUDA FLAOT32-->CUDA UINT8转CPU UINT8(GPU->CPU数据转换)
在cuda 32 float转cuda UINT 8再转cpu uint8时(因为最后需要CPU进行推理计算数据),也发现了一个问题,如果你在cuda上转uint8,然后用to(torch::kCPU)后,发现最终显示结果全黑,没有结果,但打印seg_img是有值的,后来打印了一下res这个矩阵,发现里面像素值全为0,且值为cpu float 32,但我要的是uint8,明明我前面转过了。即没有tensor数据没有拷贝到Mat中,解决方法是先将cuda放在cpu上,在转uint8,而不是在cuda上转uint8后再迁移到cpu。
- //在放入CPU的时候,必须要转uint8型,否则后面无法将tensor拷贝至Mat
- seg_img = seg_img.to(torch::kCPU).to(torch::kUInt8);
tensor转Mat
cv::Mat res(cv::Size(input_shape, input_shape), CV_8UC3,seg_img.data_ptr());其他一些报错见我另一篇文章,链接在上面~
 https://github.com/YINYIPENG-EN/Unet_pytorch_libtorch.git
https://github.com/YINYIPENG-EN/Unet_pytorch_libtorch.git
