
热门标签
热门文章
- 1Windows10环境下,设备进入fastboot状态,fastboot无法识别到设备_.\fastboot devices没反应
- 2第三十六讲:神州无线AP胖AP模式配置与管理_胖ap怎么设置上网啊
- 3opencv仿射变换GetAffineTransform的总结
- 4ArrayList、LinkedList和vector_arraylistlinkedlist vector
- 5k8s 集群重启报错:The connection to the server 192.168.92.26:6443 was refused
- 6CCF CSP 202209_csp 202209-5
- 7Elasticsearch 7.X 聚合查询 及 ElasticsearchRestTemplate 操作
- 8Android SharedPreferences数据存储工具类。需要用到Application类,这个是全局启动类。_android sharedpreferences工具类
- 9Python基于Pytorch Transformer实现对iris鸢尾花的分类预测,分别使用CPU和GPU训练_pytorch 鸢尾花分类
- 10基于shared_preferences的本地存储操作_got socket error trying to find package shared_pre
当前位置: article > 正文
2022钉钉杯A题思路及代码:银行卡电信诈骗危险预测_钉钉杯 电诈
作者:小小林熬夜学编程 | 2024-04-03 14:09:17
赞
踩
钉钉杯 电诈
1、题目背景
一、问题背景:
数字支付正在发展,但网络犯罪也在发展。电信诈骗案件持续高发,消费者 受损比例持续走高。报告显示,64%的被调查者曾使用手机号码同时注册多个账户,包括金融类账户、社交类账户和消费类账户等,其中遭遇过电信诈骗并发生 损失的比例过半。用手机同时注册金融类账户及其他账户,如发生信息泄露,犯 罪分子更易接管金融支付账户盗取资金。
随着移动支付产品创新加快,各类移动支付在消费群体中呈现分化趋势,第三方支付的手机应用丰富的场景受到年轻人群偏爱,支付方式变多也导致个人信 息也极易被不法分子盗取。根据数据泄露指数,每天有超过 500 万条记录被盗, 这一令人担忧的统计数据表明 - 对于有卡支付和无卡支付类型的支付,欺诈仍 然非常普遍。
在今天的数字世界,每天有数万亿的银行卡交易发生,检测欺诈行为的发生 是一个严峻挑战。
二、数据描述:
该数据来自一些匿名的数据采集机构,数据共有七个特征和一列类标签。下 面对数据特征进行一些简单的解释(每列的含义对我们来说并不重要,但对于机 器学习来说,它可以很容易地发现含义。它有点抽象,但并不需要真正了解每个 功能的真正含义。只需了解如何使用它以便您的模型可以学习。许多数据集,尤 其是金融领域的数据集,通常会隐藏一条数据所代表的内容,因为它是敏感信息。 数据所有者不想让他人知道,并且数据开发人员从法律上讲也无权知道)
➢ distance_from_home:银行卡交易地点与家的距离;
➢ distance_from_last_transaction:与上次交易发生的距离;
➢ ratio_to_median_purchase_price:近一次交易与以往交易价格中位数的比率;
➢ repeat_retailer:交易是否发生在同一个商户;
➢ used_chip:是通过芯片(银行卡)进行的交易;
➢ used_pin_number:交易时是否使用了 PIN码;
➢ online_order:是否是在线交易订单;
➢ fraud:诈骗行为(分类标签);
三、解决问题:
1) 使用多种用于数据挖掘的机器学习模型对给定数据集进行建模;
2) 对样本数据进一步挖掘分析,通过交叉验证、网格调优对不同模型的参数进行调整,寻找最优解,将多个最优模型进行进一步比较;
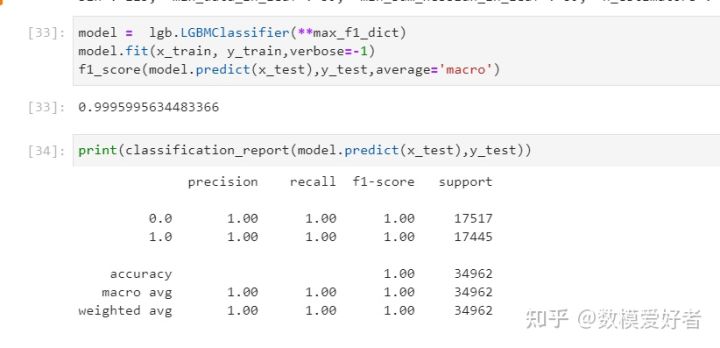
3) 通过对 precision(预测精度)、recall(召回率)、f1-score(F1 分 数值)进行计算,给出选择某一种预测模型的理由;
4) 将模型性能评价通过多种作图方式进行可视化
2、整体思路与得分点讲解
这道题就是一个分类题,没有其他问题,因此就是一个标准的机器学习回归流程,具体流程如下所示:
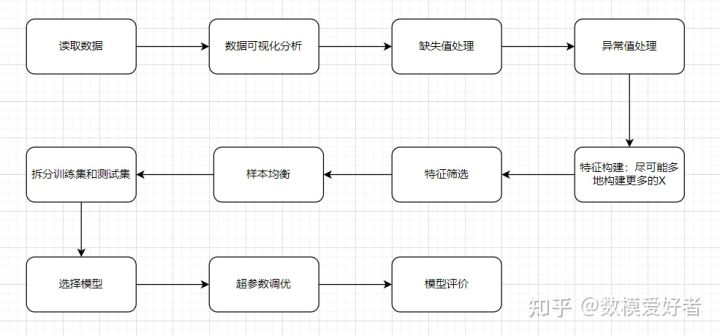
重点注意一些加分项:
- 【选择模型】使用多个模型进行比较
- 【超参数调优】利用启发式算法寻找最优解
- 【样本均衡】合理性与效果
3、具体求解步骤
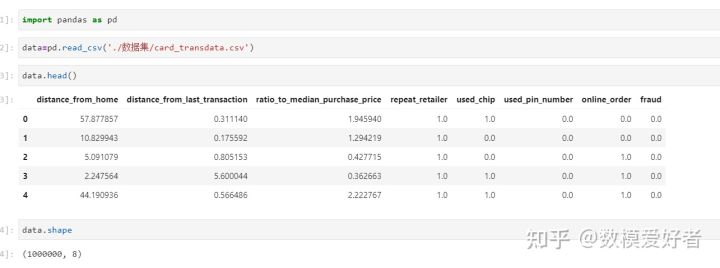
step1:读取附件数据;
可以用pandas读取附件数据,数据很标准,可以看到一共有100W行数据,8列数据
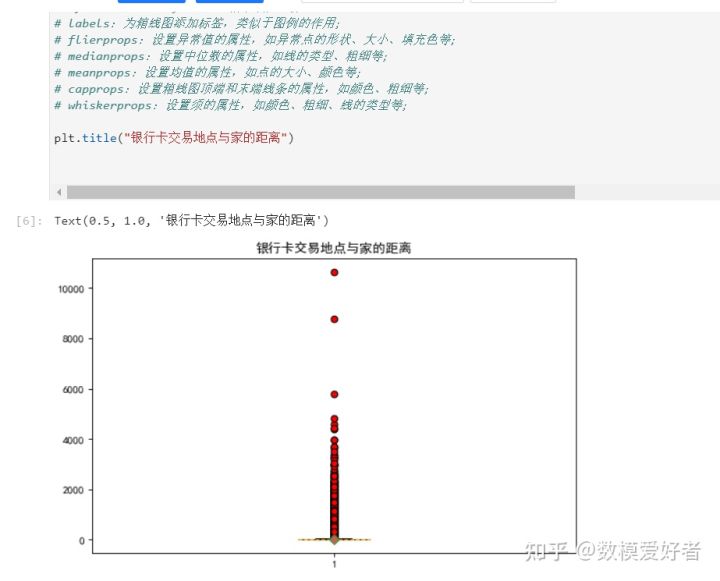
step2:数据可视化分析;
这里大家可以通过饼图、频率分布直方图、箱线图自行绘图,查看数据分布
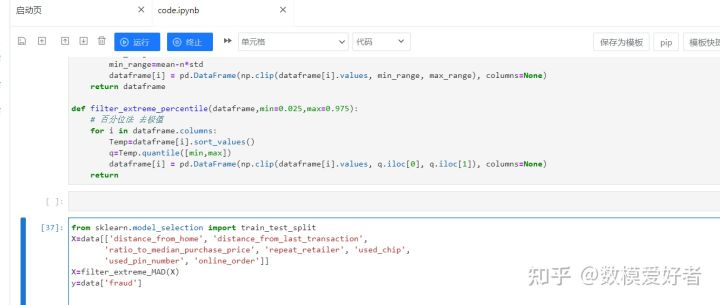
step3&4: 缺失值处理&异常值处理;
进行缺失值与异常值处理,一般广义上,缺失值也被认为是异常值(空值不就是异常数值么),可以先识别出异常值,通过百分位识别法、3σ识别法均可,然后再采用填充。
step5:特征构建
可以采用分箱和分区
有时候,将数值型属性转换成类别呈现更有意义,同时能使算法减少噪声的干扰,通过将一定范围内的数值划分成确定的块。举个例子,我们预测一个人是否拥有某款衣服,这里年龄是一个确切的因子。其实年龄组是更为相关的因子,所以我们可以将年龄分布划分成1-10,11-18,19-25,26-40等年龄段,分别表示 幼儿,青少年,青年,中年四个年龄组,让相近的年龄组表现出相似的属性。此外,我们还可以对分箱,分区做一些统计量字段作为数据的特征。
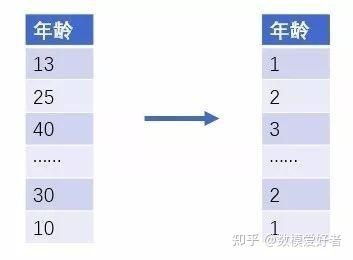
step6:特征筛选
可以参考SPSSPRO的特征筛选
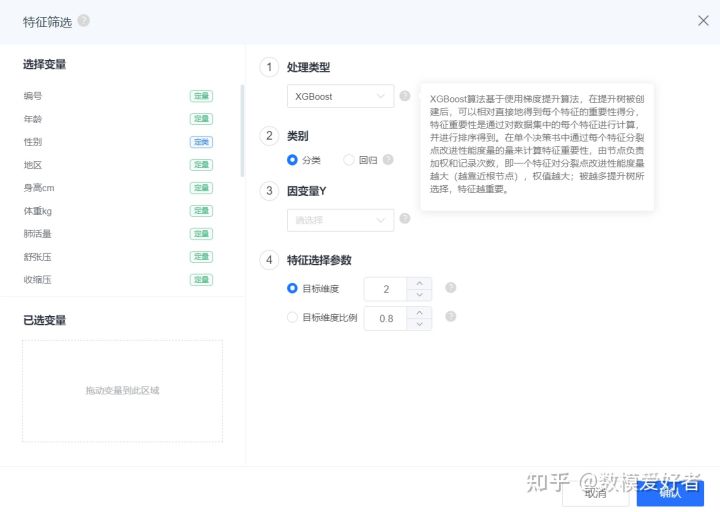
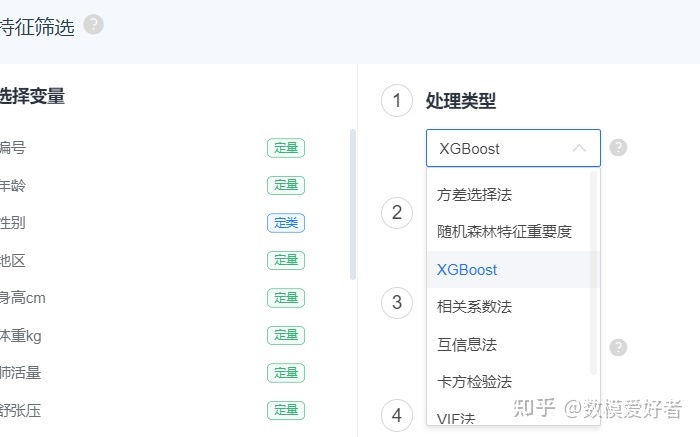
step7:样本均衡
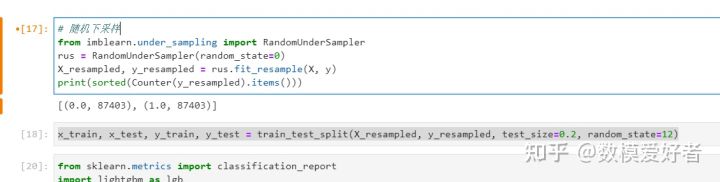
step8:拆分训练集和测试集
、

step9:选择模型
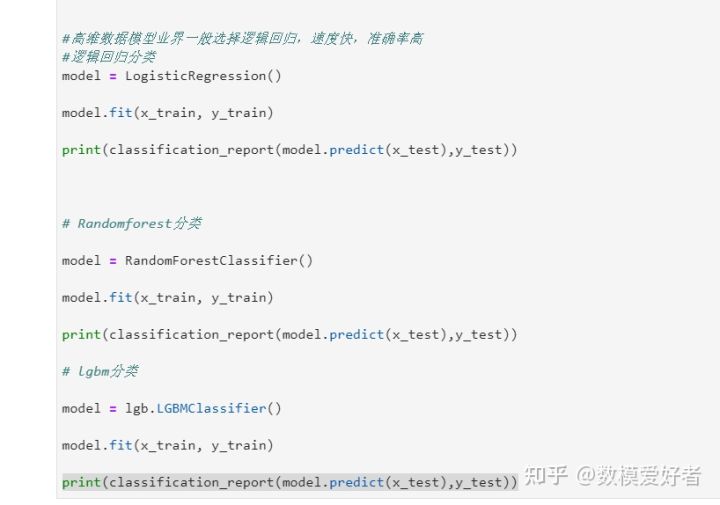
step9:超参数调优
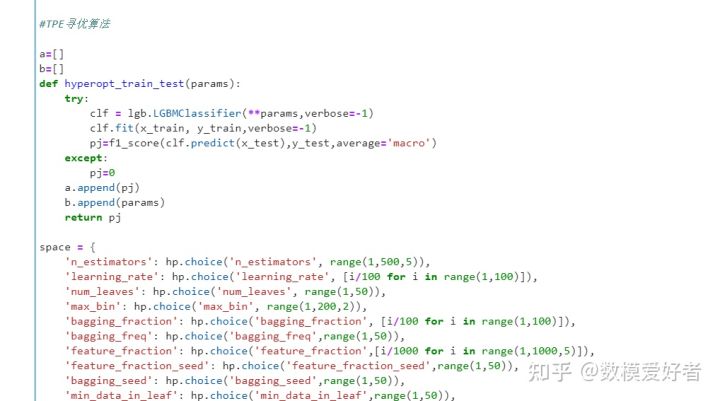
step10:模型评价
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小小林熬夜学编程/article/detail/355813
推荐阅读
相关标签

