
- 1appium安装与配置_appium server gul语言设置
- 22014最新AI智能系统ChatGPT网站源码+Midjourney绘画网站源码+搭建部署教程文档
- 3配置hadoopHA(高可用集群)常见错误解决办法_hadoop集群配置过程出现的问题和解决办法
- 4如何使用C LinkSDK(4.x)快速接入阿里云物联网平台?——实践类_link sdk
- 5使用国内镜像安装Docker-compose_国内安装docker-compose
- 6Java -枚举的使用_java枚举的使用
- 7支付宝 android 2.3,app被拒记录-2.3-包含支付宝
- 8vue el-form-item :rules动态校验实现_el-form-item动态表单拿到后端的正则校验
- 9计算机设计大赛人工智能实践赛材料填写模板
- 10CentOS 7.6 搭建cobalt strike教程_centos后台运行cobalstrika
nlp(贪心学院)——实体消歧、实体统一、指代消解、句法分析_实体消歧和实体对齐的方法
赞
踩
任务212:Entity Disambiguation (实体消歧)介绍
小米是公司还是吃的?
苹果是公司还是吃的?


根据左边的上下文找出左边的James Craig到底是右边(1)(2)(3)哪个James Craig

有一个描述库(1)苹果:一种水果(2)苹果:一家公司

(1)问题的句子,实体前找20个词,实体后找20个词,然后用tf-idf
(2)解释整句话使用tf-idf
(3)比较相似度
或者在不同上下文中,计算苹果的词向量,然后计算余弦相似度
任务214:Entity Resolution(实体统一)
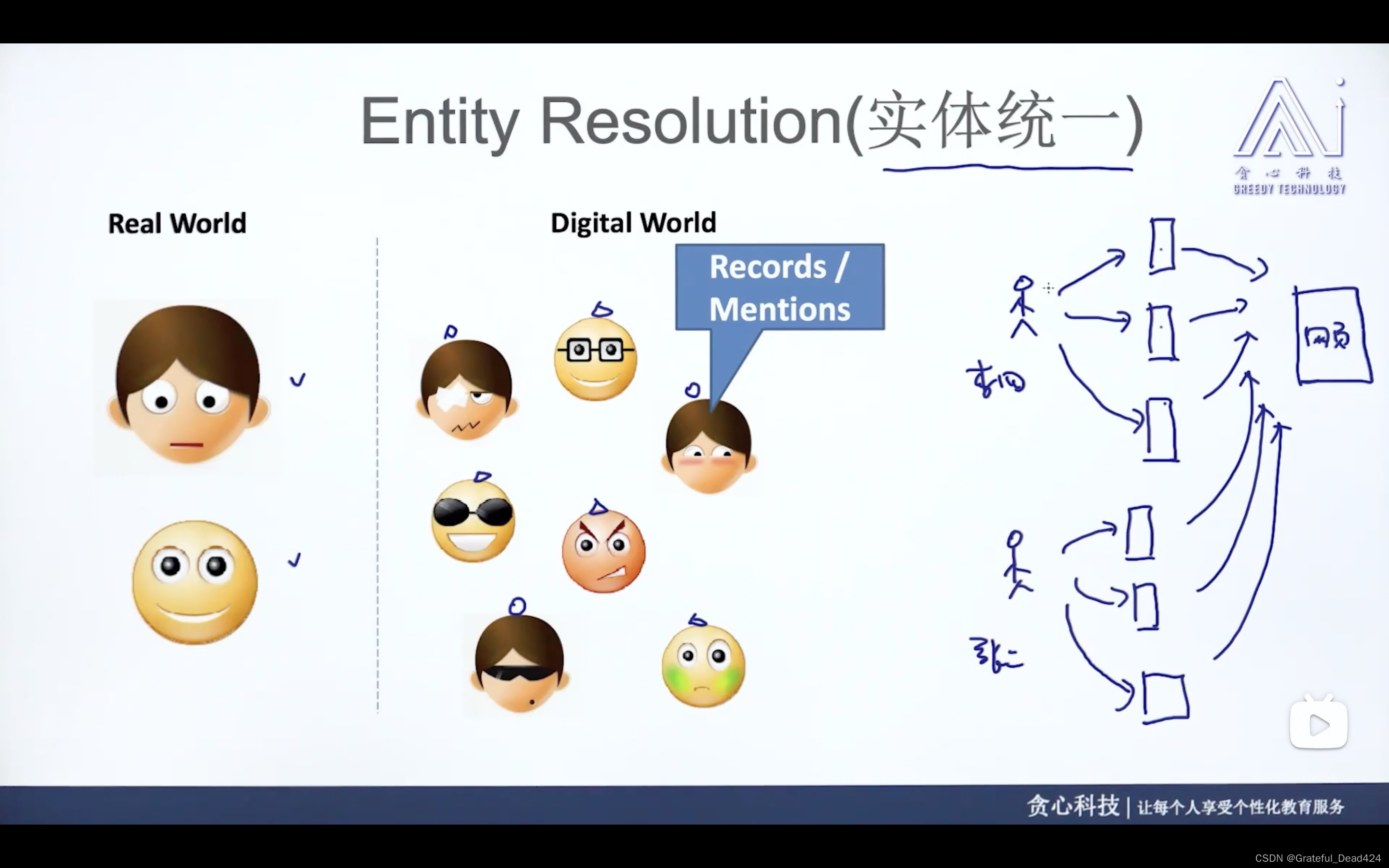
一个人有不同的手机,如何知道不同手机是否属于同一个人?——发现组团欺诈
百度和百度有限公司?
同一个地址不同的写法?
任务215:实体统一算法
第一种方法:

第二种方法:
基于规则的方法——通常见于地址、公司名的消歧
定义描述库——利用描述库把同一公司不同表示方法的公司名转化为原型(类似stemming)

第三种方法:监督学习方法
选取实体、实体上下文转化成特征
转化为二分类问题

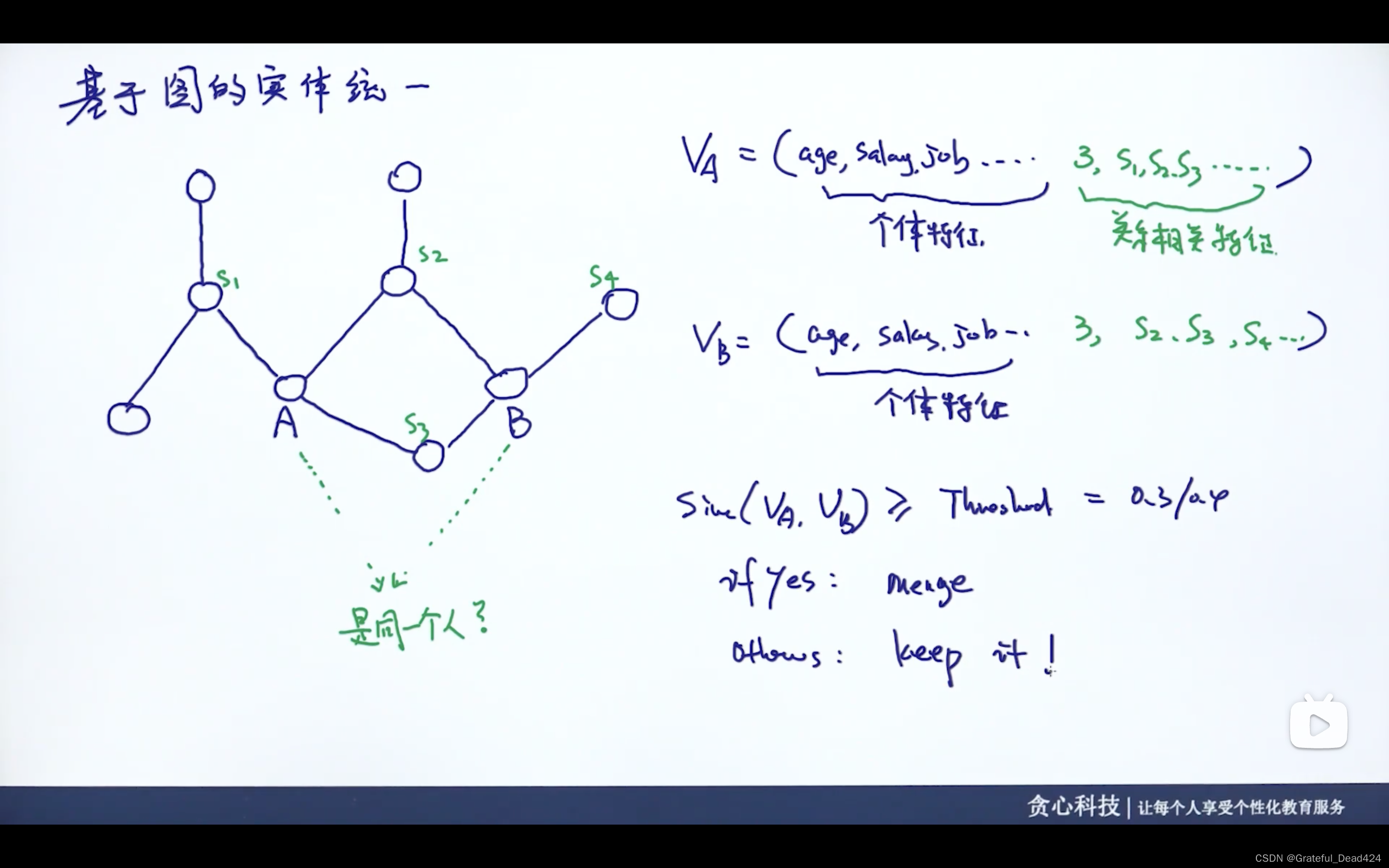
第四种方法:基于图
任务216:Co-reference Resolution(指代消解)介绍

(1)最简单的方法,离哪个实体近就指代谁
(2)有监督的方法
先打标签(张三,A)——>1
(李四,A)——>0
(张三,B)——>1
(李四,B)——>0
以张三、A为例,张三、张三左边的字符串、张三和A中间的字符串、A、A右边的字符串,全部用来提取特征(所有信息转化为向量的形式)
指代消解本身比较难还没有解决,实体消歧、实体统一比较简单,已经解决的问题
任务217: 什么是句法分析

语言模型:看到前面一系列单词,预测下一个单词
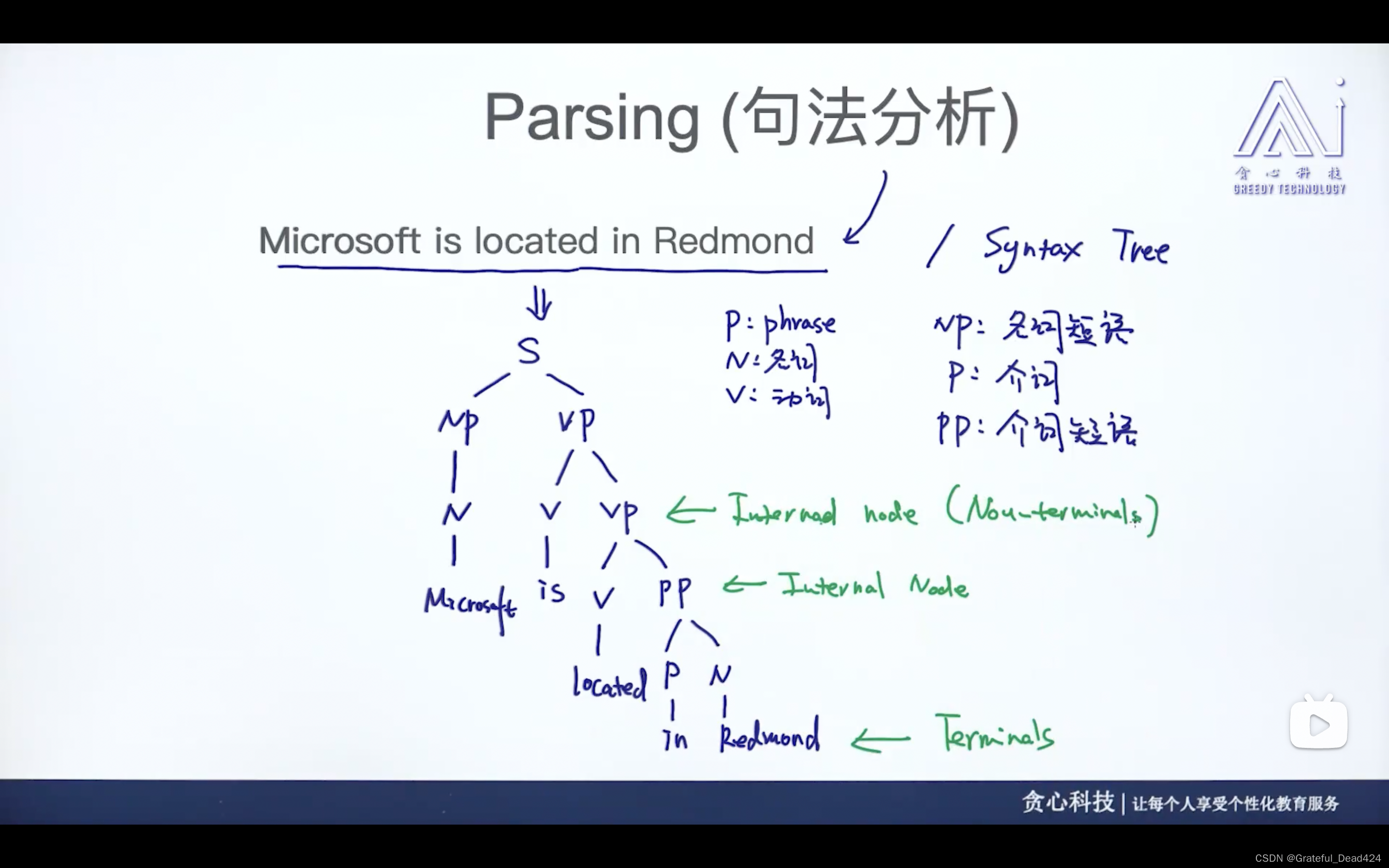
句法树、语法树
任务218: 句法分析的应用

从句法树提取一些特征出来
效果一般,特征太少的时候可以用
任务219: 语法
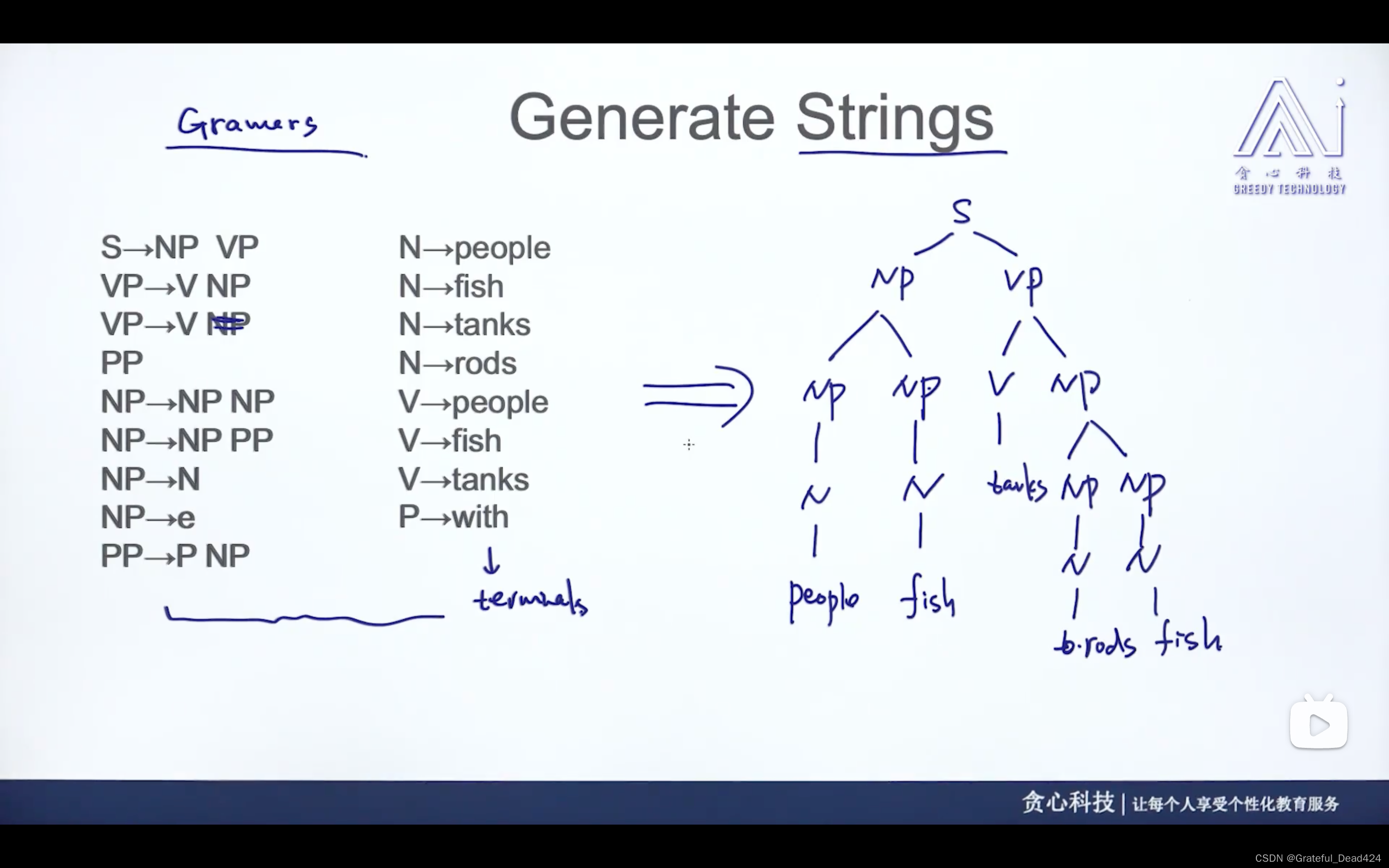
给定语法(左边),给定句子的情况下,如何生成好的语法树?

原先翻译是中文句子,句法分析成为中文语法树,然后转化为英文语法树,再句法分析转化为英文句子。(缺点是中间需要很多语言学家)
现在直接端到端(中文句子——>英文句子)
任务220: PCFG

PCFG更常用,它考虑了转化的概率,概率可以从训练数据里面计算出来
任务221: 评估语法树
给定语法(PCFG),和一个句子,会生成不同的语法树,如何评判生成树的好坏?
给语法树打分!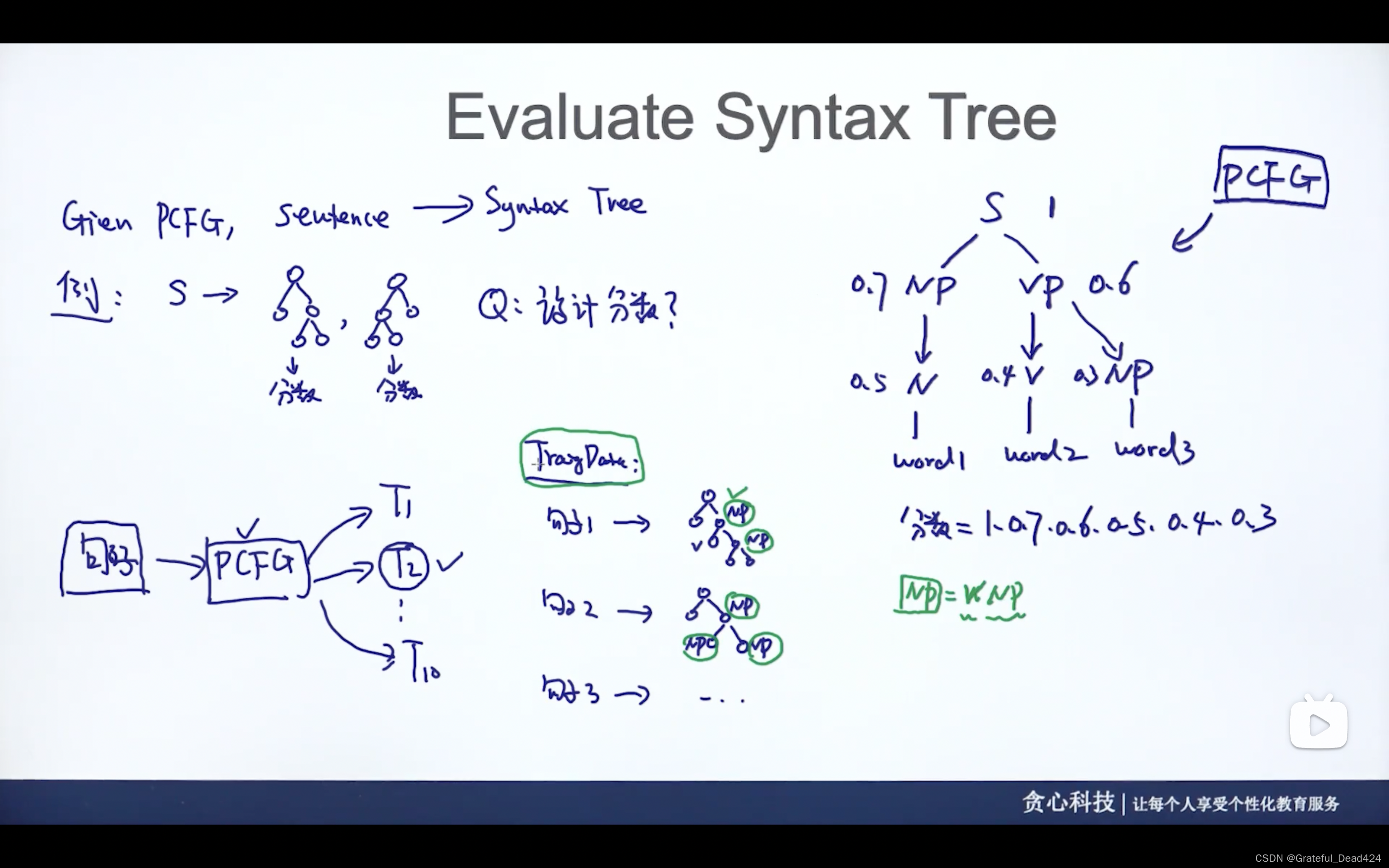
Training data人工标记好树结构,统计的方式计算概率
任务222: 寻找最好的树

任务223: CNF Form
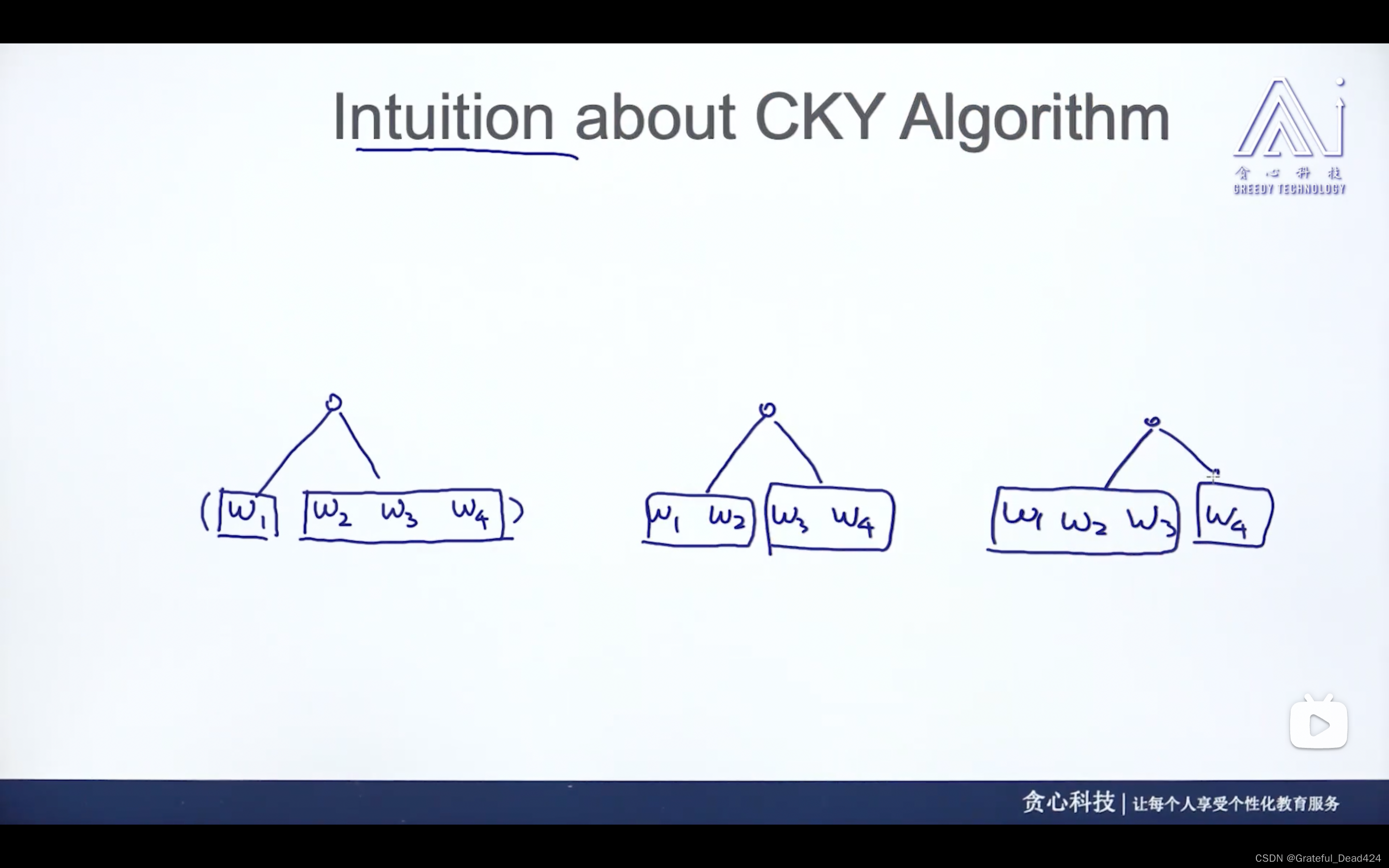
dp算法:大问题转化为若干个子问题,子问题里面再选择其中最好的组合

CKY算法:为了控制复杂度,只能转化成两个符号(三个符号不行,一个符号、空都是可以的)

CNF不仅仅包括二值化,CNF比二值化的条件更加严苛
(1)CNF不能出现e(空)
(2)不能出现两个以上的符号
(3)也不能出现一个符号
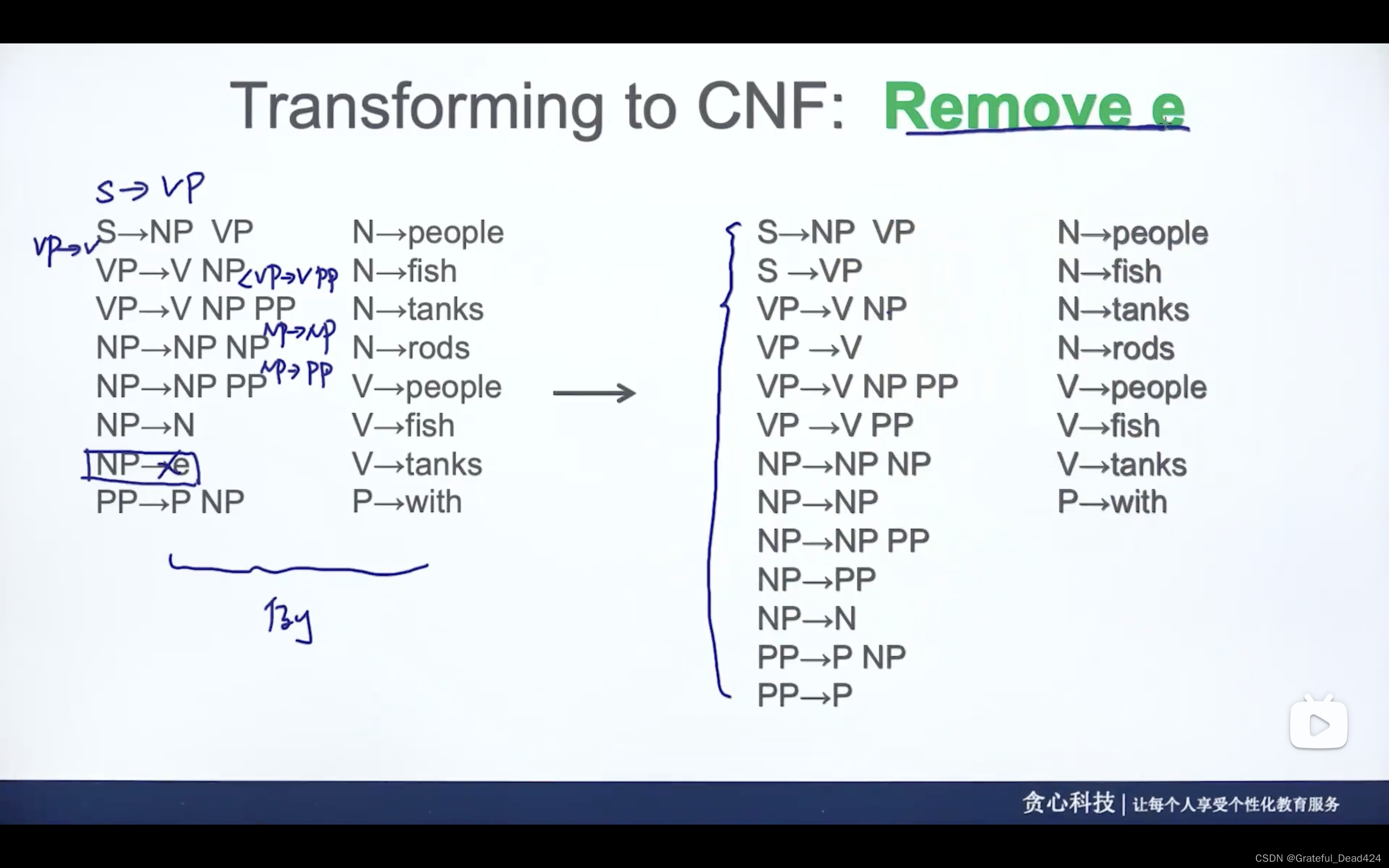
去掉e,即NP为空,带入原来的规则又创造了一系列的规则

去掉一个符号,S—>VP,可以把S看成VP,创造一系列规则
接下来持续做

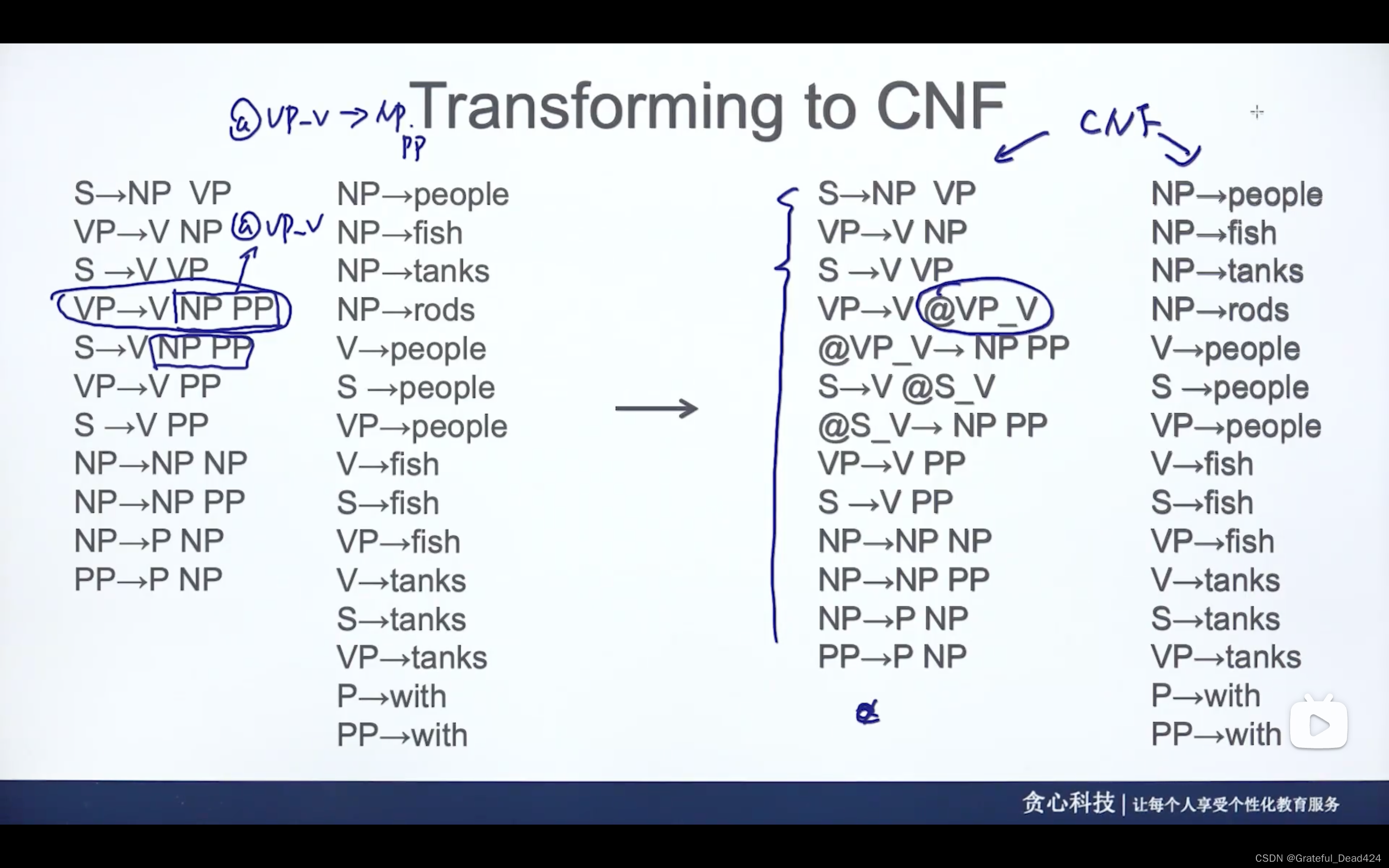

总结
CKY必须要符合Binarization,CNF不是必须的
任务224: CKY算法
这里的树向右转了45度

在填写第一行第二列这个格子的时候的时候要同时考虑左下边的fish和people(第一行第一列这个格子、第二行第二列这个格子)
在填写第二行第三列这个格子的时候的时候要同时考虑坐下边的people和fish(第二行第二列这个格子、第三行第三列这个格子)
在填写第三行第四列这个格子的时候的时候要同时考虑坐下边的fish和tanks(第三行第三列这个格子、第四行第四列这个格子)
最后要连乘。。。并且当有两个分支左边一样的时候,考虑概率最大的!
在填写第一行第三列这个格子的时候的时候要同时考虑左下边的fish和people和fish(第一行第一列这个格子、第二行第二列这个格子,第三行第三列这个格子)(考虑上一步转化为同时考虑第一行第二列这个格子、第三行第三列这个格子或者是第二行第三列这个格子、第一行第一列这个格子)。。。
填第一行第四个格子的时候,考虑:
(1)第一行第三列这个格子、第四行第四列这个格子
(2)第一行第一列这个格子、第二行第四列这个格子
(3)第一行第二列这个格子、第三行第四列这个格子
正推过去,反推回来

